
基于机器学习的网络异常流量检测
2024-02-27 06:45沈徳松
安徽科技学院学报 2024年1期
沈徳松
(安徽文达信息工程学院,安徽 合肥 231201)
随着互联网的快速发展和普及,网络安全问题日益突出。网络异常流量是指在网络通信中出现的与正常通信模式不符的数据流,可能是由于网络攻击、硬件故障或配置错误等原因引起的[1-2]。网络异常流量的存在给网络运营商和用户带来了严重的安全风险和经济损失。为了及时发现和应对网络异常流量,网络异常流量检测成为了网络安全领域的重要研究方向。机器学习算法能够通过学习大量的网络流量数据,自动发现其中的模式和规律,并能够对未知的异常流量进行准确的分类和识别。其中,XGBoost作为一种强大的分类模型,以其高效的训练速度和优秀的预测性能,在网络异常流量检测中得到了广泛的应用和研究[3-4]。
本研究基于机器学习的网络异常流量检测,采用XGBoost分类模型,对136.4万条异常流量样本的数据集进行研究和实验。通过对网络流量数据进行特征提取和预处理,构建合适的特征向量表示,并利用XGBoost模型进行训练和预测,以实现对网络异常流量的准确检测和分类,有助于提高网络异常流量检测的准确性和效率,为网络安全领域的相关研究和实践提供有益的参考和借鉴。
1 理论基础
1.1 XGBoost算法
机器学习从数据中学习模式和规律,从而实现自主决策和预测,其基本原理是通过训练算法来构建一个模型,该模型能够从输入数据中学习,并根据学习到的知识对新的未知数据进行预测或分类。在监督学习中,算法通过已标记的训练数据来学习输入和输出之间的映射关系,以便对新的输入数据进行预测。
XGBoost是一种基于梯度提升树的监督学习算法[5]。其由多个弱分类器组合构建一个强分类器,其核心思想是通过多轮迭代来逐步优化模型的预测能力。在每一轮迭代中,XGBoost算法通过计算损失函数的梯度和二阶导数,来确定当前模型的残差和权重更新方向。接着,使用一棵新的决策树来拟合残差,并将其加入到当前模型中。通过多次迭代,XGBoost算法逐步减小模型的预测误差,提高模型的泛化能力。在XGBoost算法中,对于二分类问题,XGBoost算法的损失函数采用二元逻辑损失函数(Logistic Loss);对于多分类问题,常用的损失函数是多元逻辑损失函数(Softmax Loss),如式(1)所示:
(1)

1.2 主成分分析
主成分分析(Principal Component Analysis,PCA)用于将高维数据转换为低维表示,同时保留数据的主要信息。PCA的原理基于数据的协方差矩阵和特征值分解,包括数据标准化、计算协方差矩阵、特征值分解、特征值排序和投影。
首先,对原始数据进行标准化处理,使得每个特征的均值为0,方差为1,从而消除不同特征之间的量纲差异,确保每个特征对降维的贡献度相同。协方差矩阵反映了不同特征之间的相关性,因此计算标准化后的数据的协方差矩阵。对于一个d维数据集,协方差矩阵的大小为d×d。接着,对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征值表示了数据在特征向量方向上的方差,而特征向量则表示了数据在新的特征空间中的方向。将特征值按照从大到小的顺序进行排序,选择前k个特征值对应的特征向量作为主成分。最后,将原始数据投影到选取的主成分上,得到降维后的数据,如图1所示。

图1 PCA降维过程Fig.1 Dimensionality reduction process

(2)
对于标准化后的数据,计算协方差矩阵并进行特征值分解,如式(3)所示:
(3)
最终选择15个特征值对应的特征向量作为主成分,并将原始数据投影到选取的主成分上[6],如式(4)所示:
Y=X×Vk
(4)
其中,Y为降维后的数据;X为原始数据;Vk为前k个特征向量组成的矩阵。
1.3 网络异常流量
网络流量是指在网络通信中传输的数据量,包括IP数据包、TCP/UDP数据包、HTTP请求和响应、DNS查询和响应、ICMP数据包等。网络流量来源于用户设备、服务器、网络设备等。如个人电脑、手机、平板等用户终端设备;提供各种网络服务的服务器,如网站服务器、邮件服务器;路由器、交换机、防火墙等网络设备。
网络异常流量具体表现[7]:网络流量突然大幅增加,超过正常范围;网络通信的延迟明显增加,导致数据传输速度变慢;网络服务无法正常提供,如网站无法访问、邮件无法发送等;网络中出现异常的数据包,如异常的IP数据包、TCP/UDP数据包等;网络中出现大量的连接尝试,可能是恶意攻击或扫描行为。网络攻击、硬件故障、软件错误和网络拥堵都可能造成网络异常流量。其中,网络攻击包括DDoS攻击、恶意软件、网络蠕虫等,如图2所示。攻击者通过大量的请求或恶意代码导致网络流量异常增加;网络设备的故障或配置包括路由器故障、交换机端口错误配置;软件错误指程序崩溃、内存泄漏等;网络流量超过网络带宽容量,导致网络拥堵,也会影响正常通信。通过对网络异常流量的检测和分析,可以及时发现和应对网络安全问题,保障网络的正常运行和数据的安全。异常流量检测通常包括数据采集、特征提取、异常检测算法和异常流量报警。XGBoost基于梯度提升树的机器学习算法,在异常网络流量检测中具有高性能、鲁棒性、特征重要性评估和可解释性的优势,因此被广泛应用于该领域。
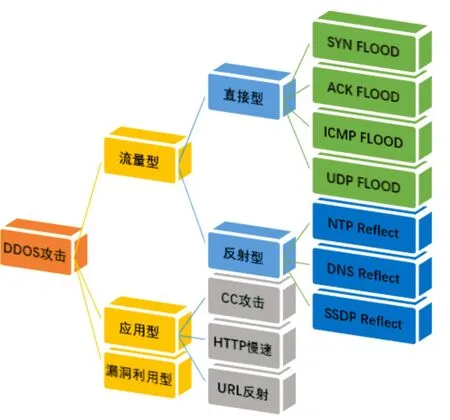
图2 DDos攻击类型Fig.2 Type of DDos attack
2 基于机器学习的网络异常流量检测
2.1 数据预处理
采用天池阿里云的CICIDS2017数据集,样本量为136.4万条,有77个特征列和1个标签列。特征属性有Active Std、Active Max、Idle Min、Subflow Fwd Packets、SYN Flag Count等。标签列的取值有8类,即需要构建八分类的XGBoost模型,如表1所示。其中,“BENIGN”表示正常网络流量,“DoS Hulk”“DDoS”等则表示不同类型的网络异常流量。在136.4万条样本中,正常网络流量的比例为71.08%;DoS Hulk导致的异常流量占比为16.94%;DDoS导致的异常流量占比为9.38%;DoS GoldenEye导致的异常流量占比为0.75%;FTP-Patator导致的异常流量占比为0.58%;FTP-Patator导致的异常流量占比为0.43%;SSH-Patator和DoS Slowhttptest导致的异常流量占比均为0.42%。
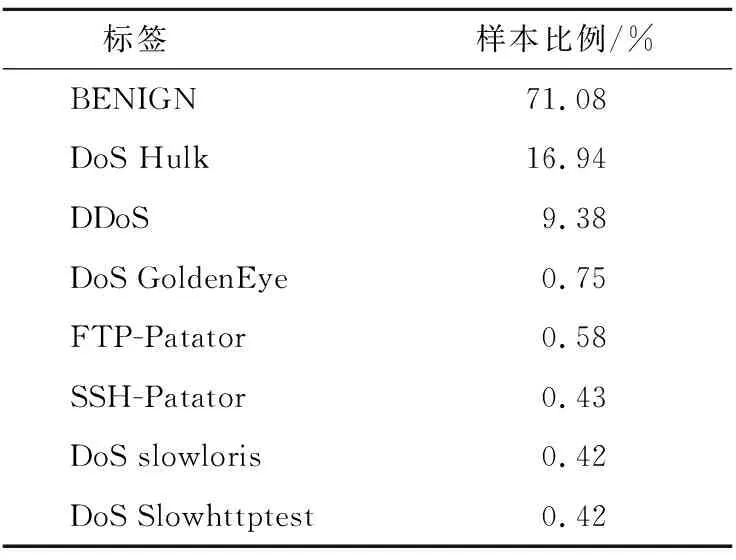
表1 样本分布Table 1 Sample distribution
对136.4万条网络流量进行数据清洗和检测,数据无缺失值和异常值,即数据集的完整性和可用性较高。对77个特征列做PCA降维处理。将降维后的特征数量定义在[1,29]范围内,循环遍历指定主成分的数量。每次循环中,将解释方差比例添加到累积方差贡献率中,并可视化解释方差比例与主成分数量之间的关系,以帮助分析网络异常流量数据,解释方差比例是衡量主成分所保留的信息量的指标,表示降维后的数据集能够解释原始数据集中的多少方差。在实验中,选择15个主成分时,解释方差比例与主成分数量之间的关系接近100%,即保留了大部分原始数据集的信息(图3)。在网络异常流量检测中,PCA将原始网络流量数据从高维空间降维到低维空间,同时保留了网络流量数据的主要信息。并将降维后的数据用于训练XGBoost异常检测模型。
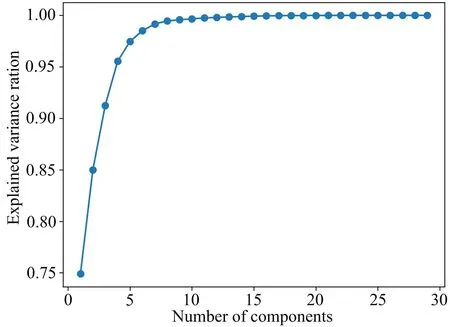
图3 解释方差比例与主成分数量的关系Fig.3 Explaination of the relationship between the proportion of variance and the number of principal components
2.2 构建XGBoost分类模型
将PCA降维后得到的15个特征维度作为训练和测试特征,并对网络流量数据进行划分。其中,70%作为训练集,即95.48万条样本用于训练XGBoost模型;30%作为测试集,即40.92万条样本用于评估XGBoost模型的性能。
对于XGBoost算法而言,标签必须是数值型的,而不是字符串。因此,为了将字符串标签转换为数值型,实验对8个类别的标签进行one-hot编码处理。one-hot编码是将离散特征转换为二进制向量的编码方法。对于每个可能的取值,one-hot编码会创建一个新的二进制特征,该特征只有一个元素为1,其余元素为0。每个离散特征就被表示为一个高维稀疏向量,其中每个维度对应一个可能的取值。对于网络异常流量检测,one-hot编码的步骤如下:
(1)确定标签列的所有取值:确定表1中8种网络流量类型。
(2)创建全零向量:对于每条网络流量样本,创建一个与异常类型数量相等的全零向量。
(3)将对应位置为1:对于每条网络流量样本,根据其异常类型,将对应位置的值置为1。
通过上述one-hot编码将原始的字符串标签转换为稀疏的二进制向量,只有一个位置为1,其余位置都为0。one-hot编码编码可以更好地表示不同的异常类型,并作为输入传递给XGBoost模型进行训练和预测。在训练XGBoost模型时,学习率、树的深度和分类器数量是影响性能的重要参数。学习率控制每棵树对最终预测结果的贡献程度,较小的学习率可以使模型更加稳定,但可能需要更多的树来达到较高的性能。较大的学习率可以加快模型的收敛速度,但可能导致过拟合。通常从较小的学习率开始,然后逐渐增加,直到确认最终值。树的深度决定了每棵树的复杂度,较深的树可以更好地拟合训练数据,但也容易过拟合。较浅的树可以减少过拟合的风险,但可能无法捕捉到复杂的模式分类器数量是使用XGBoost进行多分类任务时的分类器个数。较多的分类器可以提高模型的性能,但也会增加计算成本。在实验中,学习率和树的深度均采用网格搜索方式获得,分类器数量的则设置范围为[120,130,140,150,160,170,180]。
2.3 结果分析
如图4所示,采用XGBoost算法作为网络异常流量识别的分类模型,当XGBoost算法的分类器设置为170个时,分类准确率最高,达到了96.32%。当分类器数量小于140个时,XGBoost算法无法充分学习网络异常数据的复杂模式,导致欠拟合。随着分类器数量由140个增加到170个,XGBoost可以更好地拟合训练数据,准确率随之增加。然而,当分类器数量超过170个时,XGBoost算法出现了过度拟合训练数据,导致在未见过的数据上表现不佳,分类准确率降低。综上,XGBoost算法对网络异常数据特征有较高的学习能力。同时,增加分类器的数量并不总是能够进一步提高性能。在分类器数量超过170个之后,XGBoost可能已经学习到了数据中的大部分模式和规律,进一步增加分类器的数量可能只会引入噪声和冗余,从而降低分类准确率。

图4 基于XGBoost的异常流量检测准确率Fig.4 XGBoost-based abnormal traffic detection accuracy
3 结论
网络异常流量可能是网络攻击的迹象,也可能是数据泄露的指示,会导致网络拥塞和性能下降。如入侵、恶意软件传播或拒绝服务攻击、敏感数据的传输、未经授权的数据访问等。及时检测和监控网络异常流量是保护网络安全、预防攻击和数据泄露、维护网络性能以及遵守合规要求的重要手段[8-11]。通过及时发现和应对异常流量,可以及早发现并采取相应的安全措施,以保护网络免受攻击,有利于提高网络的安全性和可靠性。
基于XGBoost算法的网络异常流量检测是一种有效的方法。对136.4万条网络流量数据的检测实验中,分类准确率达到了96.32%。该指标证明了XGBoost在网络异常流量检测中的有效性和优势。XGBoost在网络异常流量检测中仍然有巨大的潜力。未来可以探索更多的特征工程方法,并结合其他深度学习算法,构建更加强大和鲁棒的网络异常流量检测系统,提高模型的性能。对于异常网络流量带来的危害,仍然需要采取关联防范措施来应对,包括建立实时流量监控系统,对网络流量进行持续监测和分析,加强网络安全措施,使用防火墙、入侵检测系统(IDS)和入侵防御系统(IPS)等技术手段。并定期更新和维护网络设备和软件,及时修复漏洞和弱点以减少网络受到攻击的风险。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
车主之友(2022年4期)2022-08-27
数学物理学报(2021年5期)2021-11-19
微型电脑应用(2021年3期)2021-03-31
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
海峡姐妹(2019年12期)2020-01-14
北京航空航天大学学报(2017年7期)2017-11-24
东北电力大学学报(2015年1期)2015-11-13
四川轻化工大学学报(自然科学版)(2014年3期)2014-04-16
计算物理(2014年1期)2014-03-11
