
ARM+FPGA双核计算的配电自动化终端设计
2024-03-14 09:08郑军生杨俊哲许文秀吴宏伟
自动化仪表 2024年1期
郑军生,杨俊哲,许文秀,吴宏伟
(内蒙古电力(集团)有限责任公司乌海电业局,内蒙古 乌海 016000)
0 引言
随着我国科学技术的不断进步、发展,社会对电力资源的需求量也日益提高。为了满足社会的需要,我国现有的电力系统亟需提升、完善。配电自动化系统是我国电网行业架设系统中非常重要的一部分。该系统的稳定性直接影响电力系统的整体运行情况。但是现有的自动化终端无法进行高效的运维管理,工作效率不理想。因此,如何实现配电自动化终端调试,成为亟待解决的技术问题。
为了优化配电自动化终端的效率,文献[1]提出一种对开关设备的检测设计方法。该方法通过对线路数据的分析判断实现故障检测。该方法虽然能够在一定程度上实现故障的迅速定位,但是无法实现调配数据信息的分析。文献[2]结合硬件设计和人工智能技术,对传统的自动化终端进行升级,但是无法满足目前电力行业对精确度的要求。文献[3]所设计的技术方案引入了新兴的大数据算法,但其终端大数据处理能力较差、数据分析能力滞后、整体工作效率不高。
针对以上问题,本文提出了ARM+现场可编程门阵列(field programmable gate array,FPGA)双核计算的配电自动化终端。在计算过程中,该终端能够在常规堆叠式自动编码器(stacked autoencoder,SAE)深度学习模型的基础上进行改进设计。该设计融合无限深度神经网络(neural network,NN)结构,在应用过程中改善了传统NN对分层节点数目的限制,提高了配电网数据信息的分析精度,大幅提升了电网应用对数据信息处理的准确度和效率。
1 配电自动化终端硬件设计
为了提高调试硬件结构的设计能力,本文设计的配电自动化终端核心采用TI公司的ARM Cortex-A8系列32位芯片和FPGA模块。其数据处理能力较快,工作效率较高。配电自动化终端调试硬件结构如图1所示。
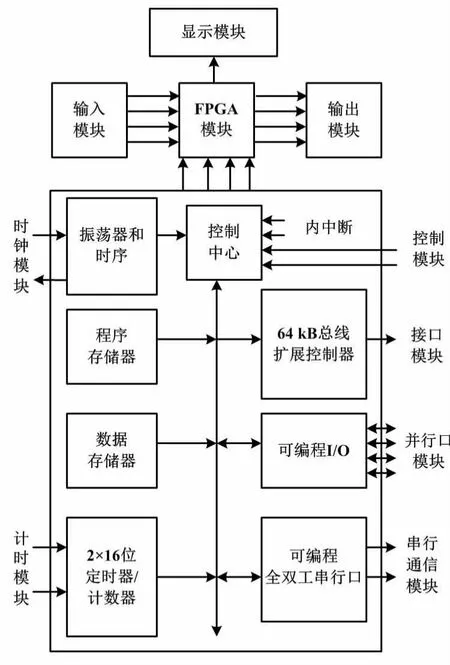
图1 配电自动化终端调试硬件结构示意图
在图1设计中,控制中心采用中央处理器(central processing unit,CPU)模块,以实现原始配电数据信息的采集、处理、上送以及控制、执行等功能。设置CPU板的目的在于实现调度数据信息的采集、控制和交互。CPU模块的主处理器采用TI公司生产的ARM Cortex-A8系列单片机。该单片机采用32位精简指令集计算机(reduced instruction set computing,RISC)微处理器芯片AM3359。在运行过程中,该芯片采用的主频信息最高为720 MHz。该芯片的接口资源信息比较多。在诸多接口设计中,通过XILINX公司的Spartan-3系列芯片XC3S250E,接口芯片FPGA可以实现快速计算。其中,通信接口包括以太网、RS-485、RS-232、通用分组无线通信服务(general packet radio service,GPRS)以及控制器局域网络(controller area network,CAN)等。在这些接口中,采用的通信规约有Modbus、IEC 61850、IEC 104以及自定义通信规约。通过设计CPU和FPGA双核控制模块[4-5],提高了数据计算能力。采用这种硬件结构的优势在于现场逻辑可编程,灵活度和扩展性较强。
为了更好地处理电力数据、保证配电自动化的准确度,本文设计了带通滤波器。带通滤波电路如图2所示。

图2 带通滤波电路图
由图2可知,带通滤波电路能够将电阻和电感相互配合,从而选取系统所需频率段的电力信号,并通过放大器对信号进行放大。通过这种带通滤波电路设计可以滤除杂波,进而实现整体系统的信号检测。带通滤波在电路图中经过一次滤波、放大后,还能够经过二次滤波、放大,以进一步实现对电力信号的处理,大幅提高系统计算准确度、减小配电自动化终端的误差。
为了加强系统的数据通信功能,本文设计了高效通信模块。高效率串口通信电路系统中的串口通信模块在具体工作过程中,采用MAX232AEJE芯片作为基础,通过电容对电流数据进行处理。而MAX232AEJE芯片的端口能够支持高速串行、并行字节等数据信息接口,并且通过多排转换接口实现多设备要素的接入;同时,对多组设备的数据流进行交接可大幅提高保护电力数据的稳定性、提升整个配电自动化终端的数据处理效率。高效率串口通信电路如图3所示。
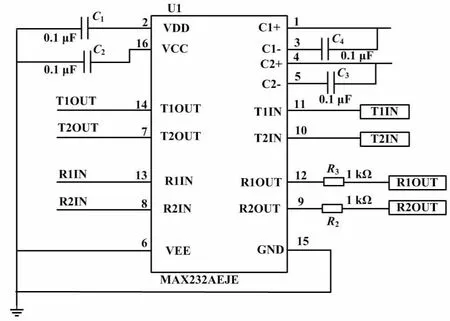
图3 高效率串口通信电路图
2 改进型SAE-NN深度学习模型数据分析方法
在调试配电网数据信息时,本文采用了改进SAE-NN深度学习模型的方法。这种方法能够通过微观分析的方式处理输入的多维度数据信息,以此提升系统整体的处理和分析能力,具有很高的适用性。该方法需构建改进 SAE-NN深度学习模型。改进SAE-NN深度学习模型如图4所示。
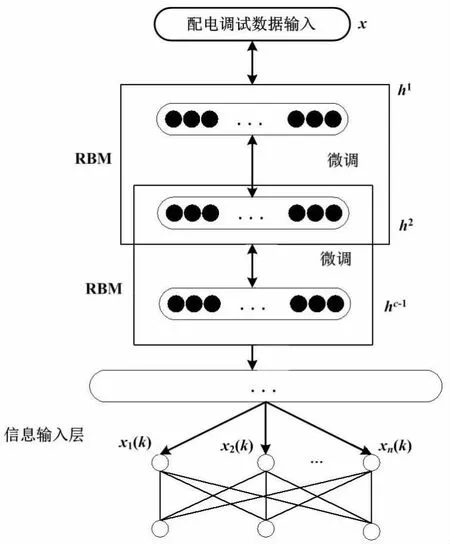
图4 改进SAE-NN深度学习模型示意图
图4中,受限波尔兹曼机(restricted Boltzmann machine,RBM)电力系统在对配电网上的数据信息进行调度时,很容易受外界多种因素影响而导致电力负荷出现故障。本文在常规SAE-NN深度学习模型的基础上加入无限深度NN结构。采用该结构的目的是模拟出拥有人脑神经结构的机器学习方法,从而改善传统NN对分层节点数目的限制。改进SAE-NN深度学习模型[6]主要包括SAE和NN模型。
本文设置当前学习模型自编码隐藏层为l、其输出信息为h(l)、下一个自编码隐藏层(l+1)的数据信息输入为x(l+1),则输入信息为:
x(l+1)=h(l),l=1,2,…,n-1
(1)
式中:n为底层SAE模型中自编码器的数量。
在新型算法模型中,本文选择S型生长曲线非线性神经元作为该模型的输出节点。本文利用SAE对输入配电网数据信息样本x(l)作细化分解,并将输入函数展开多次变换,则数据算法模型输入样本为n阶特征h(n)。本文将这些数据特征作为逻辑回归(logistic regression,LR)模型的数据输入,并通过该模型进行配电网负荷能耗预测。
配电自动化终端调试方法流程如图5所示。

图5 配电自动化终端调试方法流程图
通过SAE模型输出LR模型不同阶层的特征。本文将这些配电网负荷数据信息输入无限深度NN模型[7-8],使得每个神经元数据信息都能够构成自身反馈,并能够根据配电网负荷数据信息的时间特征信息提取输入端输入的配电网负荷数据信息的时序特征。通过时间维度的方式将每个NN上的神经元节点展开,以提高配电网数据信息的分析精度。在所选择的时间维度上,改进 SAE-NN深度学习模型中的网络模型可以“无限深”[9-10]。
基于上述改进型SAE-NN深度学习模型的构建,本文通过具体操作方法对本文调度方法进行详细说明。
①将配电网数据信息通过数据集合表示,则有S={S1,S2,…,Si}。其中,Si为深度卷积NN的输入值。
②设置算法计算参数。其中,h1和h2分别为改进 SAE-NN深度学习模型中第l层卷积核具有的长度与宽度[11]。存在的数据信息为:
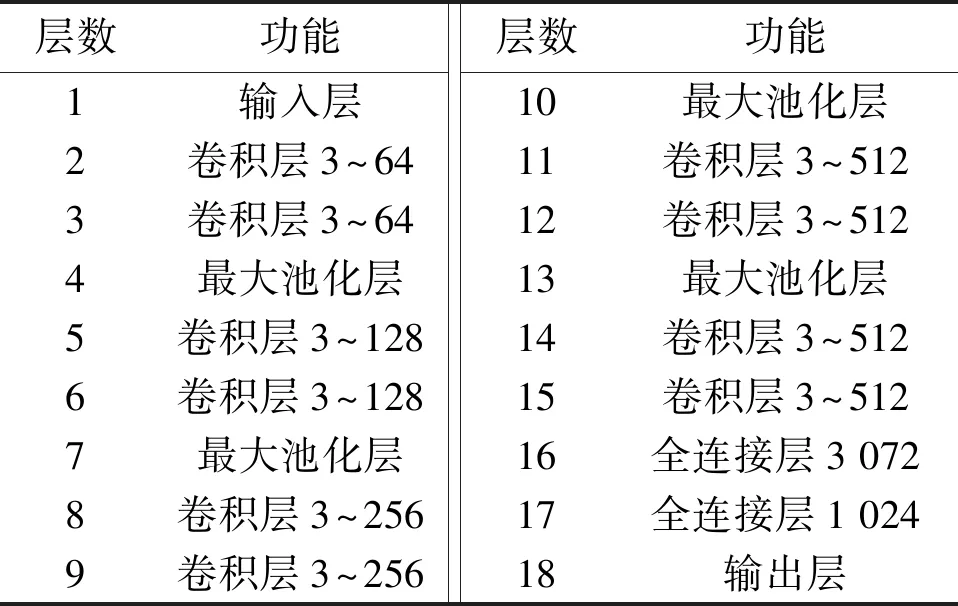
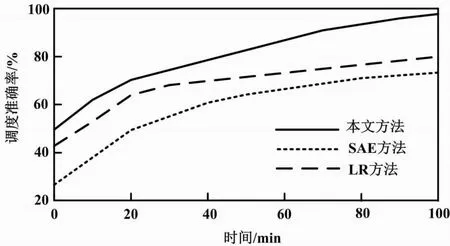
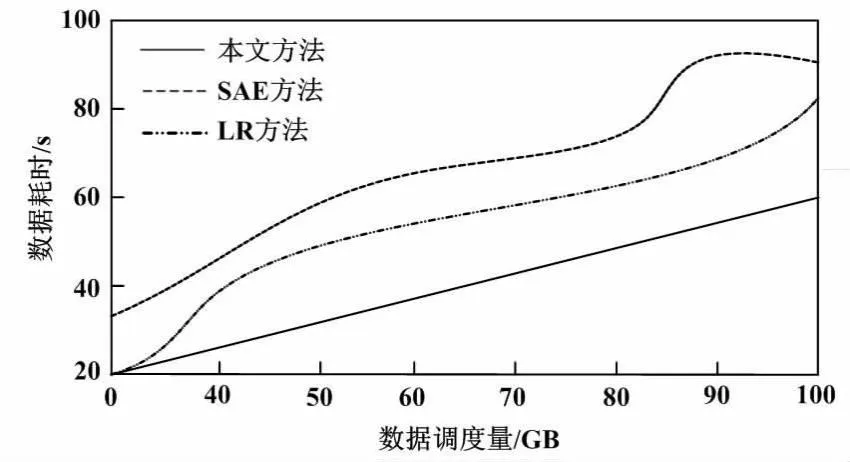
h={(λ,γ)∈N2|0≤λ (2) 式中:λ为数据信息在模型中的长度;γ为数据信息在模型中的宽度。 由数个卷积共同构建的卷积层单元输出结果为: (3) (4) 式中:θ为改进型SAE-NN深度学习模型[14]的采样因子;e为下采样层的上采样操作。 (5) 本文在最大池化条件下计算S={S1,S2,…,Si}区域特征上限值。计算下采样层时,其学习过程通过以下函数表示: (6) 式中:r为上采样层的下采样操作。 ④输出数据结果。在深度卷积NN收敛的条件下,可将最后一层全连接层作为新的配电网数据特征。该数据信息记作Q={Q1,Q2,…,Qi}。根据Q={Q1,Q2,…,Qi}数据集合,可以获取新的配电数据信息标签zi+1。通过不断的数据迭代计算,可以输出深度卷积NN中的数据信息。 ⑤循环上述迭代数据过程,并设置当迭代次数与设置的迭代次数相等时停止输出。 通过上述算法模型的建立,使本文配电自动化终端不仅能够根据需要自主完善数据库,还提升了数据处理分析能力、实现了终端智能化。 仿真试验采用的计算机为Microsoft Windows 2021 64 位;采用的开发工具为Visual Studio 2019 OpenCV 3.0。计算机硬件环境如下:CPU Inter(R)Core(TM)i7,主频为2.59 GHz[15];内存为64 G。仿真试验通过Matlab软件进行。改进型SAE-NN深度学习模型的参数信息如表1所示。 表1 改进型SAE-NN深度学习模型的参数信息 试验使用配电自动化终端数据信息故障数据的数量为10 000个。本文将日常记录的大量加工数据作为样本,并分别将这些信息故障数据分布在加工数据4组不同的数据样本中。4组数据样本的数据量分别是50万个、80万个、100万个和150万个。以此类推。本文分别通过SAE方法、LR方法和结合了SAE和LR的本文方法进行故障识别的对比试验,得到的数据信息识别如表2所示。 表2 数据信息识别表 由表2可知,在测试时间为100 h、每组测试数据为10 000个的条件下,本文方法的数据信息识别正确数量较多,均达到9 500个以上,而SAE方法和LR方法的数据信息识别数量较少。这进一步验证了本文方法的可行性和有效性。下面通过100 min的试验,观察调度准确率情况。3种方法的调度准确率对比如图6所示。 图6 调度准确率对比示意图 采用这3种不同的方法的原因是为了显示文件在具体应用中与本文的方法具有相似的作用。 由图6可知,3种方法的准确率都随着时间的推移逐步提高,但在整个试验过程中,本文方法的准确率最高。通过10 h的计算,耗时对比如图7所示。 图7 耗时对比图 由图7可知,随着数据调度量的增多,3种方法耗时量都在增加。其中:SAE方法和LR方法耗时量增加较为明显;本文方法数据耗时量增加较为均匀且缓慢。这说明本文方法工作效率高、耗时少。 本文在基于ARM+FPGA双核计算的基础上,设计了带通滤波器以及高效串行口模块,保障了配电自动化终端的准确性与可靠性。本文同时采用由SAE和NN模型结合组成的SAE-NN模型预测能源系统短期负荷,提升了预测精度,为考虑需求响应对能源系统的负荷调整提供了数据基础。仿真试验对比分析结果表明,随着系统运行,本文方法计算精度能达到95%以上,而现有SAE方法仅达到85%左右。由此可知,本文方法使系统具有较高的调度能力,从而显著提高配电网数据信息的分析精度、大幅提升电网应用对数据信息处理的准确度和效率。本文所设计的配电自动化终端硬件以及算法具有优越性,可以有效提升预测精度和预测能力。
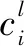

3 仿真试验与分析

4 结论
猜你喜欢
现代装饰(2020年8期)2020-08-24
铁道通信信号(2019年9期)2019-11-25
经济技术协作信息(2018年7期)2019-01-14
经济技术协作信息(2018年32期)2018-11-30
电子制作(2018年18期)2018-11-14
通信电源技术(2018年5期)2018-08-23
电子制作(2016年15期)2017-01-15
电测与仪表(2016年5期)2016-04-22
河南电力(2016年5期)2016-02-06
电测与仪表(2014年17期)2014-04-04
