
基于迁移学习的心音心脏疾病检测算法
2024-03-27 16:21冯辰凡陶青川
现代计算机 2024年1期
冯辰凡,陶青川
(四川大学电子信息学院,成都 610065)
0 引言
在当今时代,机器学习、人工智能等技术已经在各个领域产生了巨大的影响。研究者们不断创造出高效且可靠的算法,将这些算法应用到各行各业,以解决各式各样的现实问题。在健康领域中,尤其是医学领域,先进技术的应用一直处于前沿。心脏疾病作为健康领域的一项重要挑战,早期的诊断对于患者的生存和健康至关重要[1]。近年来,越来越多的研究者开始将机器学习的知识应用于实现高效、精确的心脏疾病检测的目标。例如,一些研究者尝试使用心电图(ECG)[2]或核磁共振仪的三维扫描结果[3]作为数据集和诊断依据,并设计了相应的算法。尽管这些方法在某些情况下取得了一定的成效,但这些仪器通常昂贵且耗时。相比之下,基于心音(PCG)的心脏疾病检测算法因其器材开销小,且数据集收集简单而备受关注,成为当前心脏病诊断领域的主要研究方向。
当前,已经存在许多心音识别方法。例如,Pantea 等[4]对传统的机器学习算法,模糊推理系统(ANFIS)进行了改进,取得了良好的识别结果。随着深度学习和神经网络的兴起,越来越多的研究人员开始采用深度学习方法来实现这一目标。Potes 等[5]采用卷积神经网络(CNN)来进行心音识别,而在Sujadevi 等[6]的研究中,构建了长短期记忆网络(LSTM)来实现同样的目标。在深度学习模型的众多变种中,HTS-AT[7]网络是最近引起广泛关注的一种,它融合了Swin Transformer[8]架构的优点,同时高效提取了局部性特征,在声音识别领域取得了显著的成绩。本文旨在对该网络进行改进和优化,提出了HTS-AT V2 模型,以提高模型的推理速度和其在特定领域或任务上的性能,尤其是在心音心脏疾病检测算法的应用方面。
此外,随着任务复杂性的增加和跨领域的需求,单一领域训练的模型面临一些挑战。为了充分发挥深度学习的潜力,研究人员开始关注迁移学习(Transfer Learning)[9]方法。迁移学习允许在一个领域训练的模型在另一个领域进行任务迁移,从而提高性能。本文将采用迁移学习方法,将知识从一个领域迁移到另一个领域,以提高模型的性能并减少训练过程中的损耗。
本文的结构如下:
第一部分介绍了本文所用方法和模型的基础理论;第二部分将详细介绍本文提出的模型,即HTS-AT V2 的网络结构,并探讨相关评价指标。我们将通过设计不同的实验来证明模型的有效性,并探讨迁移学习对于训练过程的优化作用;第三部分将对本文的研究成果进行总结,并展望未来的研究方向。
1 论文涉及方法介绍
本部分主要对论文中使用到的方法理论进行介绍,主要包括HTS-AT 网络模型、Swin Transformer V2和迁移学习。
1.1 HTS-AT
HTS-AT(Hierarchical Token-Semantic Audio Transformer)是由Chen等[7]于2022年提出并发布的一种全新的声音识别的方法。网络结构如图1所示。可以看到,此方法分为三个部分:第一部分是以梅尔频谱图(Mel Frequency Cepstral Coefficient)为主要思想的语音特征提取编码部分,用来提取声音中重要特征,并将一维的时序数据编码整合成满足模型输入要求的二维多通道数据;第二部分则是模型的主干部分,从图中可以看出,HTS-AT 借鉴了Swin Transformer的思路:使用层次化的金字塔设计,一共包含了4 个Group,每个Group 的末尾都会使用Patch-Merge 模块缩小输入图像的分辨率以达到逐层扩大感受野、减少数据量的目的,而Group 中的核心部分则是直接使用了以Windows Attention 为核心的Swin Transformer Block;第三部分是模型的输出部分,将第二部分的数据解码并映射到目标类型上,以满足任务对数据格式的需要。
1.2 Swin Transformer V2
Swin Transformer V2 是由Liu 等[10]在Swin Transformer V1提出八个月后提出的,Swin Transformer 网络的2.0 版本。经过改进,相较于V1,V2 使得模型规模更大并且能适配不同分辨率的图片和不同尺寸的窗口。Swin Transformer V2 和Swin Transformer V1的对比如图2所示。在V1的基础上,作者提出了一种新的归一化方式,称为残差后归一化(residual-post-normalization)。该方法将归一化层从每个残差分支的开始移到末尾,这样每个残差分支的输出在合并回主分支之前都会被归一化,当层数加深时,主分支的幅度将不会被累加,这种新的归一化方式使得网络各层的激活值变得更加温和。同时,为了缓解V1 中某些层的注意力权重会被几个特定的点支配的问题,作者还提出了缩放的余弦注意力机制(scaled cosine attention),它可以取代之前的点乘注意力机制。在缩放的余弦注意力机制中,自注意力的计算与输入的幅值无关,从而可以产生更平衡的注意力权重。

图1 HTS-AT网络结构图

图2 Swin Transformer V1与Swin Transformer V2对比图
1.3 迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,其主要思想是将从一个任务中学到的知识或模型应用到另一个相关任务中,以提高学习性能。迁移学习的概念最早在领域自适应(Domain Adaptation)和多任务学习(Multi-Task Learning)的研究中有所体现。领域自适应关注如何将一个领域中学到的知识迁移到另一个相关领域,而多任务学习关注如何同时学习多个相关任务,以提高性能。在当前的深度学习领域,迁移学习可以帮助模型加快收敛、学习的过程,也能够提高模型的泛化能力和适应能力,从而在目标领域数据稀缺或噪声较多的情况下,也能取得较好的训练效果。在由Tan 等[11]提出的综述中,将深度学习中的迁移学习分成了四个类型:基于实例的深度迁移学习、基于映射的深度迁移学习、基于网络的深度迁移学习和基于对抗的深度迁移学习。
2 基于迁移学习的HTS-AT V2算法
本节主要介绍HTS-AT V2 的网络结构、训练过成、评价指标以及实验结果。
2.1 本文方法介绍
本文是对Chen 等[7]提出的HTS-AT 进行改进,改进后的新网络命名为HTS-AT V2。主要的改进是:在主干网络中添加了Liu等[10]所提出的Swin Transformer V2 Block,网络结果如图3所示,图中模型的主体,也就是Training部分,原来使用的是Swin Transformer Block,而经过改进,本文使用了更加优越的Swin Transformer V2 Block。相比之下,V2版本通过引入残差后归一化和缩放的余弦注意力机制,让模型更加稳定,注意力权重更加平衡。
同时,由于本文所使用到的数据集为心音数据集,相比于文献[6]中的数据集,心音最大的特点为其周期性,所以对原网络的Encode 部分进行改进,对声音使用小波变换去噪后,按心动周期进行切割,再将切割后的声音分别进行编码后进行合并。而且,由于心音数据集中的数据类型较少,识别场景较为简单,所以在合并后通过二维卷积的方式来减少通道数量,以实现参数量的减少。
改进后的编码方式,不仅帮助网络在训练时更好地利用心音周期性的特点,减少无用特征的干扰;而且通过减少通道数降低了网络训练时的参数量,提高了心音识别的实时性。另外,为了进一步提高模型的泛化能力、减少训练过程的开销,本文的训练过程还使用了基于网络的深度迁移学习[11]。HTS-AT V2 网络会先在“源领域”,即ESC-50 数据集上进行训练,之后会在“目标领域”,也就是心音数据集上进行微调,以适应心音数据集的数据分布和任务,以提高在这个领域上的性能。
2.2 数据集介绍
本文涉及到的数据集主要有两个:ESC-50数据集和心音数据集。
ESC-50 数据集是著名的声音数据集,该数据集由5 s 长的记录组成,这些记录被组织成了50 个不同的语义类,松散地排列成5 个主要类别,总共有2000 条数据。本文用该数据集作为迁移学习过程中的“源领域”数据集。
心音数据集是本文自制的数据集,从成都、绵阳、自贡三个城市,五家不同的医院、医疗机构收集而来。其中共3500 条数据,2500 条正常心音,1000 条异常心音,包括了儿童、青少年、成年人、老年人不同年龄阶段的心音数据。详细的数据集信息见表1,表中的“其他”表示患者不只患有一种疾病,或存在心脏疾病但暂无法确定具体病种。

图3 HTS-AT V2网络结构图

表1 数据集种类及数量
2.3 评价指标
心音识别作为多分类任务的一种,本文主要以宏平均(Marco Average)的F1-Score 作为关注的指标。对于二分类的分类问题,可以将样本分为四类,即真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)。基于分类结果的矩阵见表2所示。
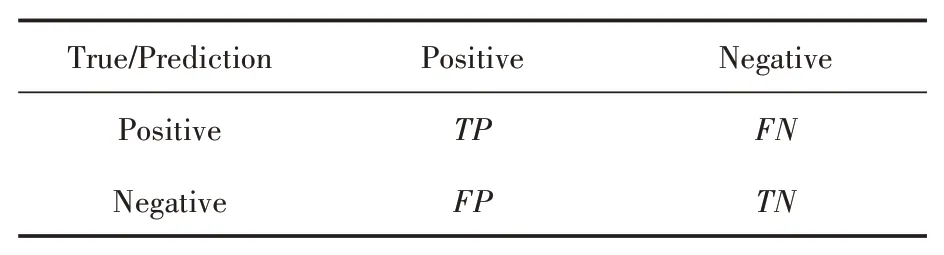
表2 二分类任务结果矩阵
基于表2 的基本属性,我们可以分别得出准确率(Accuracy)、精确率(Precision)和召回率(Recall)的公式:
为了更全面地反映模型的性能,我们一般会考虑F-Score 作为模型进一步的评价指标。由于精确率和召回率指标有时会出现矛盾,因此需要F-Score指标来对这两者进行加权和平均。
一般,我们取a= 1,此时,我们称其为F1-Score。
F1-Score 结合了精确度和召回率,当F1 较高时,我们认为该方法更有效。
在多分类的任务上,为了能够获得模型在多组数据上总体的性能,一般使用宏平均(Marco Average)来做评价指标。宏平均是根据每个类的F1-Score 求得的算数平均,相比于微平均(Micro Average),其可以更平等地对待每一个类别,而数据集中各个类别的重要性相同,故用作此次任务的评价指标。
2.4 实验结果
2.4.1 实验环境
本文代码使用的操作系统为ubuntu18.04,框架环境为PyTorch 1.8.1、Python 3.8、Cuda 11.1。在硬件环境方面,主处理器为12 vCPU Intel(R)Xeon(R)Silver 4214R CPU @ 2.40GHz,运行内存20 GB,使用的显卡为RTX 3090,单卡,显存24 GB。
2.4.2 结果与分析
改进后,模型的实验结果见表3。

表3 实验结果
从表3可以看出,本文改进后的HTS-AT V2算法,虽然在F1-Score 上只是略高于原版网络,但是在参数量和推理速度上,都取得了比较优秀的结果。所以,本文提出的算法更加适合部署在边缘设备上,便于进行快速、便捷的心脏疾病的检测。这与我们的研究初衷相符。
另外,为了更加准确、可靠地对比迁移学习对于模型的影响,分别用迁移学习的训练方式和普通的训练方式对HTS-AT V2 额外进行了10 次实验,其最后的F1-Score 结果区间如图4所示。

图4 传统训练和迁移学习实验结果对比
从图4 可以看出,在10 次实验中,虽然在最好情况下迁移学习训练出来模型的F1-Score相比使用普通方式训练出来的模型只是略有提升,但是迁移学习训练的模型却有着更好的稳定性,其训练结果的波动要小于使用普通训练方式训练出来的模型,这也体现了迁移学习对于训练过程的优化。
3 结语
本文针对心音识别任务,对语音识别网络HTS-AT 进行了改进,将原本模型中使用的Swin Transformer 模型更新为Swin Transformer V2,同时对原网络中声音的特征提取进行了改进,让其更好地适应心音数据集。在心音数据集上的训练结果表明,在识别效果略有提升的情况下,减少了模型的大小并提高了模型的推理速度,大大提高了心音识别算法的实时性,有助于将该模型部署于边缘设备上。也使用了迁移学习这种特殊的训练方法,优化了模型的训练过程。在未来,可以继续根据心音的特性,对网络结构和训练方式进行进一步的改进,从而进一步提升算法效果。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
青年生活(2019年23期)2019-09-10
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
计算机技术与发展(2018年5期)2018-05-28
计算机技术与发展(2017年12期)2017-12-20
无线互联科技(2017年6期)2017-04-26
中共南宁市委党校学报(2015年4期)2015-02-28
图学学报(2014年2期)2014-03-06
