
基于机器学习的分布式的故障诊断系统研究
2024-04-06 10:04陈园琼孟玉佳李智豪
电脑知识与技术 2024年3期
陈园琼 孟玉佳 李智豪

关键词:机器学习;故障诊断;分布式系统
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2024)03-0022-03
0 引言
大数据时代,分布式系统成为信息存储和处理的主流系统,Cassandra、MongoDB、HBase等系统应运而生,通过水平扩展和分区存储等技术,满足了大规模数据管理和访问的需求。相对于传统系统而言,分布式系統更为庞大和复杂,故障发生的平均概率比较高。因此,如何对分布式系统进行高效、准确的运维,成为保障信息系统高效、可靠运行的关键问题。
传统的故障诊断是通过人工经验来进行检测的, 需要耗费巨大的人力和时间[1],无法应对系统复杂性的问题。随着机器学习技术的飞速发展,研究者们开始探索将机器学习引入故障诊断领域[2]。一些研究在单一节点[3]上取得了显著成果,但在真实的分布式环境中,涉及的问题更为复杂。尽管有关分布式故障诊断的研究[4]正在逐渐增多,但仍然存在对大规模系统的有效建模、实时性要求和模型可解释性等方面的挑战。该系统的目标是设计和实现一种基于机器学习的分布式的故障诊断系统,并提供了对原始数据特征的预处理、特征提取和对故障的分类,以提高系统故障诊断的准确性和实时性。
1 实验环境
1.1 数据来源
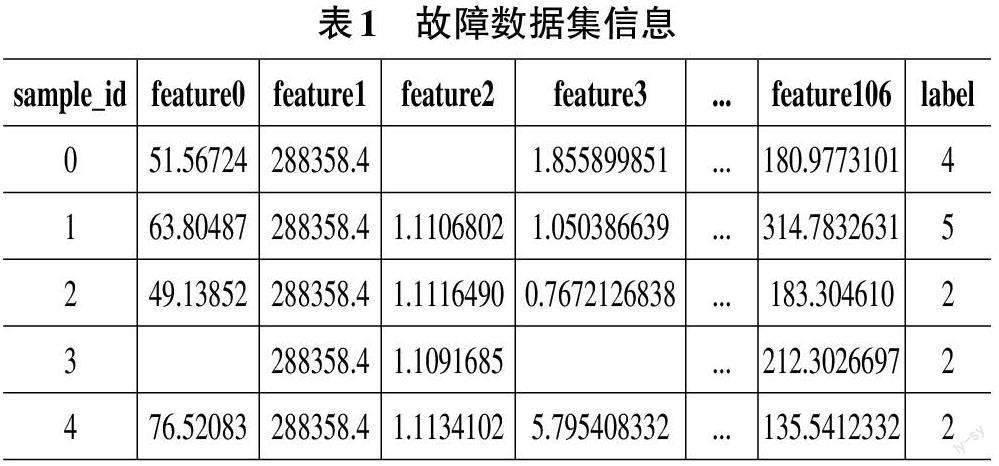
本研究所有的数据来自中国软件杯设计大赛中的训练、验证和测试数据集(http://www.cnsoftbei.com/software/bstm/A/824.html) 。该训练数据集和验证数据集包含了分布式数据库[5]的故障特征数据和标签数据,其中特征数据是系统发生故障时的KPI 指标数据,KPI 指标包括由feature0、feature1 ...feature106 共107个指标,标签数据为故障类别数据,共6个类别,用0、1、2、3、4、5分别表示6个故障,其中0类别为正常类别,具体的故障部分数据集信息见表1,而测试集是只有特征而没有标签的数据集,用于预测故障的属于哪个类别。
2 实验过程
2.1 数据处理
特征数据的预处理主要采取了机器学习中的数据清洗、归一化、欠采样和标准化处理等方法。
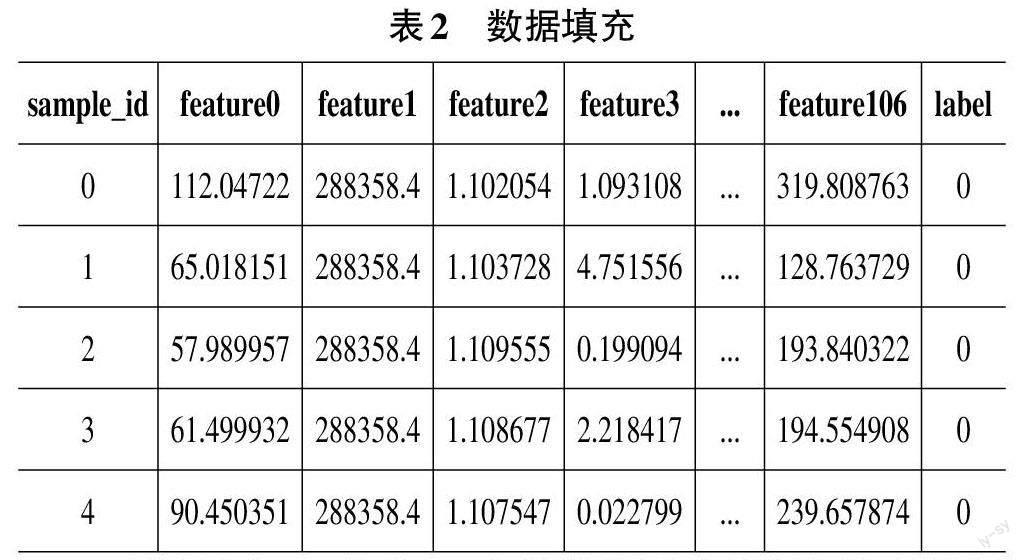
1) 针对特定列的缺失值进行了数据清洗,并计算每列的众数,然后使用该列的众数填充指定的列的缺失值,对整个数据集使用均值填充剩余的缺失值,并调整标签序列如表2所示,确保模型在训练过程中能够充分利用可用的数据信息。
2) 通过归一化处理确保数据在相同的尺度范围内,避免某些特征对模型训练的影响过大。
3) 由于数据类别较为不平衡,这种数据分布可能在故障诊断的时候造成一定的影响,因此,根据欠拟合原理,用RandomUnderSampler对数据进行欠采样,以解决数据类别不平衡的问题,使得每个类别的样本数量较为均衡。
4) 采用数据标准化的计算方法,通过应用一个lambda函数,对数值特征进行标准化处理。将每个特征值减去其均值并除以标准差,公式如下:X* = x - μ/σ ,以使特征值的尺度更加一致,并将整个训练集以及验证集的数据都放入了一个文件里面,用这个文件来当作训练集来训练。
2.2 基于XGBoost 算法的故障诊断系统
该系统基于中国软件杯平台给出的故障数据集,提出了一种基于XGBoost的故障诊断系统,提供了对故障的分类。首先对原始的数据特征进行预处理和特征提取,设计一个基础的XGBoost模型,设置模型的参数,对模型进行训练,在训练过程中逐步对参数进行优化和泛化处理,最后生成故障诊断模型。该系统提出的基于XGBoost算法的故障诊断模型建模流程,如图1所示。
故障诊断模型建立之后,结合系统平台对模型进行测试,该系统平台实现了训练模型、验证模型、下载模型、模型添加和故障服务等多方面功能,通过平台给出的测试集作为模型的新的数据集,实现故障的分类,得出分类结果,并进行可视化展示。
3 结果与分析
3.1 预测结果
选取已经预处理的验证集对XGBoost模型进行验证,验证结果得出故障各个类别的F1_score值分别为0.93、0.84、0.85、0.94、0.97、0.95,该系统的集成学习模型 XGBoost 的预测准确性高达 91%,预测结果的分类数据报告如表3所示。
其中,Precision(精确度)表示模型在每个类别中的预测准确性,Recall(召回率)则衡量模型识别每个类别的能力。F1-score综合了Precision 和Recall,提供了对模型整体性能的评估。支持度(Support) 代表每个类别在数据集中的实际样本数量。总体准确度(Accuracy) 表示模型正确分类的样本比例。Macro avg 对每个类别的指标进行算术平均,而Weighted avg则根据每个类别样本量的权重进行平均,提供了对整体性能更全面的评估。
3.2 对比分析
为了验证XGBoost模型的可行性和有效性,采取逻辑回归算法和随机森林算法[7]进行对比实验。通过趋势分析图(如图2)可以看出,XGBoost模型在数据集上的表现呈现出一种上升趋势,而逻辑回归和随机森林模型的表现则相对较为波动。
经过多次实验,从表4中的结果可以得到,该系统的集成学习模型XGBoost 模型的预测准确性高达91%,随机森林(RandomForest) 模型和逻辑回归(Logis?ticsRegression) 模型的预测准确率分别为88%和80%,逻辑回归模型在故障类别2中准确率只有55%,而在XGBoost模型中准确率达到了84%,其余故障类别也同样得到了提升。总体来看,XGBoost相较于逻辑回归和随机森林,呈现出更为一致且卓越的性能,特别在面对极端或难以分类的故障情形下表现更为出色。
4 结论
本研究采用XGBoost算法构建了故障诊断系统,该算法通过整合多个弱学习器,形成了一个强大的学习模型。通过对真实数据集的实验和分析,验证了该系统的卓越性和可行性。实验结果表明,基于XGBoost 模型的故障诊断系统具有较高的准确,能够快速识别出异常数据和故障,并实现准确的分类。接下来的研究将聚焦在人工智能对故障的诊断[8],以及特征工程、模型训练和参数优化等方面,通过更精细的特征选择、交叉验证、超参数调整等手段,可以使故障诊断模型更加准确和稳健,以适应更多实际场景的应用。
【通联编辑:谢媛媛】
猜你喜欢
装备制造技术(2020年3期)2020-12-25
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
北京航空航天大学学报(2016年6期)2016-11-16
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
科教导刊·电子版(2016年10期)2016-06-02
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
振动、测试与诊断(2014年5期)2014-03-01
机械与电子(2014年1期)2014-02-28
