
基于无监督深度学习的图像拼接实验设计与实现
2024-04-18 03:49孙彦景王兴兴张晓光
实验室研究与探索 2024年1期
孙彦景, 王兴兴, 云 霄, 张晓光, 周 玉
(中国矿业大学信息与控制工程学院,江苏徐州 221116)
0 引 言
随着智慧城市建设的深入和数字化改造的推进,视频监控涉及的领域越来越广泛[1]。在对大型空间进行监控或摄像头与目标物体距离过近时,仅采用单一摄像头难以获取宽视野的图像,一般解决方法是采用多个摄像头分别监控独立显示,这种方法获取的视频不直观,视角之间联系不大,难以满足医学图像处理和虚拟现实等应用场景对高分辨率宽视野图像的要求。利用图像拼接技术将多摄像头拍摄的多张具有重叠区域的图像转化为一张具有宽视野的图像。另外,图像拼接技术在汽车导航、军事领域等方面都有着广泛的应用,其相关的研究层出不穷。目前图像处理实验类型单一且主要介绍传统方法,致使学生掌握的方法与现实脱节,理论与实践能力不符。有必要在实验环节加入图像拼接相关内容,将教学内容与实际场景相结合,增强学生对课程的整体理解,提高学生的工程实践能力。
不同摄像头获取的图像视角具有随机性,造成图像之间存在不同程度的视差,图像拼接方法应具有处理视差图像的能力。传统图像拼接方法基于手工特征实现。此类方法的拼接效果严重依赖特征点的质量与数量,在图像视差较大以及人工设计的特征提取算法质量不佳时难以获得质量良好的拼接图像。近几年基于深度学习方法在图像处理领域取得了较好的效果[2-4]。相比于传统方法,深度学习模型自动学习数据的特征,其多层次结构可从原始数据学习抽象和复杂的特征,在处理图像、音频和文本方面表现出色。无监督学习是深度学习的分支,近几年在单应性估计[5]、目标检测[6]、语义分割[7]等任务中崭露头角。无监督学习不需要对数据进行标记,可节省大量的人力、物力,并且相对于监督学习有限的标签,能学习到更丰富和更通用的特征。图像拼接方法逐渐从传统方法向无监督深度学习方法过渡。现有的教学也应与时俱进,在教学实践中加入新兴技术,引导学生从传统方法向主流技术过渡。
目前图像拼接相关研究主要是针对双摄像头拍摄的图像[8-9],双摄像头拍摄范围有限,难以完全包含感兴趣的区域。相较于双摄像头,多摄像头不受摄像头数量限制,包含的区域更广,且实际场景中一般为多摄像头。因此,有必要进行多摄像头图像拼接相关的研究。本文基于景深-彩色图像融合及无监督深度学习,设计了一种多图深度拼接网络(Deep Multi Image Stitching Network,DMISNet)。将景深图像与彩色图像融合后增加了图像的结构形状信息,有效解决了大视差图像拼接中伪影、模糊等问题。在校园场景和工业场景下对多视角图像进行拼接,验证了算法的鲁棒性。该案例可用于图像拼接相关的研究和教学,并具有一定的扩展性,学生可在本方法的基础上做出改进。
1 单应性变换原理
单应性变换是将一个平面内的点映射到另一个平面内的二维投射变换[10]。如图1(a)所示,红点为两幅图像中的对应点,图中显示了4 种不同颜色的对应点。利用单应性矩阵能将一幅图像中的点映射到另一幅图像的对应点。

图1 单应性变换前后图像
单应性矩阵
该矩阵有9 个未知数,只有8 个自由度。一般在求解时令h22=1,则只需4 组不共线的点对便可求得单应性矩阵。
以图1(a)中的红色对应点为例,对应点之间的单应性变换
式(2)适用于图像中所有对应的点集,换言之,可将单应性矩阵应用于整张图像。将单应性矩阵作用于图1(a)左图使之与右图对齐,结果如图1(b)。实际应用中可将图像分为多个网格,分别对每个网格求取单应性矩阵,获得精细对齐的图像[11]。
2 无监督图像拼接
无监督图像拼接网络总体结构如图2 示,包括无监督单应性变换和无监督图像重建两个级联模块。通过单一单应性变换粗略对齐输入图像,与现有的拼接方法不同,本文将景深图与彩色图像融合作为输入,提取图像的多模态特征,以获得更好的拼接效果。图像重建分为低分辨率分支和高分辨率分支。对图像进行下采样,通过通道注意力模块获得各通道权重后再进行结构拼接。在高分辨率变形分支中,因随着分辨率的提高感受野相对变小,本文采用扩张卷积代替普通卷积,增大图像的感受野。

图2 无监督图像拼接网络结构
2.1 无监督单应性变换
同一物体在不同视角拍摄的影像中可能会出现较大范围的变形,导致后续影像拼接效果不理想或无法拼接。为解决这些问题,设计了一种基于景深-彩色图像融合的单应变换网络。将景深图与彩色图像融合后作为输入,获得具有图像结构形状的特征。图3 所示为单应性变换总体结构,将参考图像、目标图像以及对应的景深图作为输入,针对参考图像的重叠区域,对目标图像变形处理,使参考图像和目标图像的重叠区域处于同一视角。
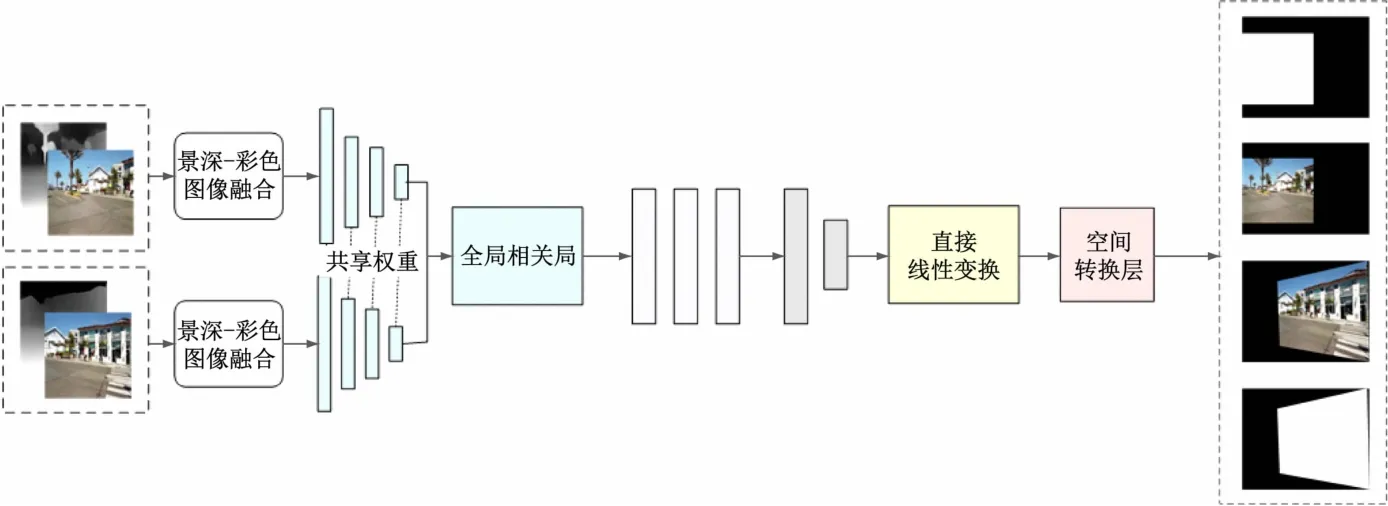
图3 无监督单应性变换网络结构
多模态融合策略有直接融合,张量融合网络(Tensor Fusion Network,TFN)[12]等。如图4(a)所示,直接融合是直接在特征维度将不同模态的特征进行拼接后送入后续的推理模块。TFN融合策略不仅考虑了各模态之间的特征融合,且有效地利用了各特定模态的特征。首先对每个模态进行维度扩充,然后对不同模态求笛卡尔积。如图4(b)所示。维度扩充后,既计算了两个模态间的特征相关性,又保留了特定模态的信息。为得到最好的效果,对两种融合策略分别进行测试,采用文献[13]中提出的重叠区域的峰值信噪比(Peak Signal-to-noise Ratio,PSNR)和结构相似性指数(Structure Similarity,SSIM)评估模型在UDIS 数据集的配准性能,对比结果见表1、2,根据实验结果选择TFN融合作为融合方式。
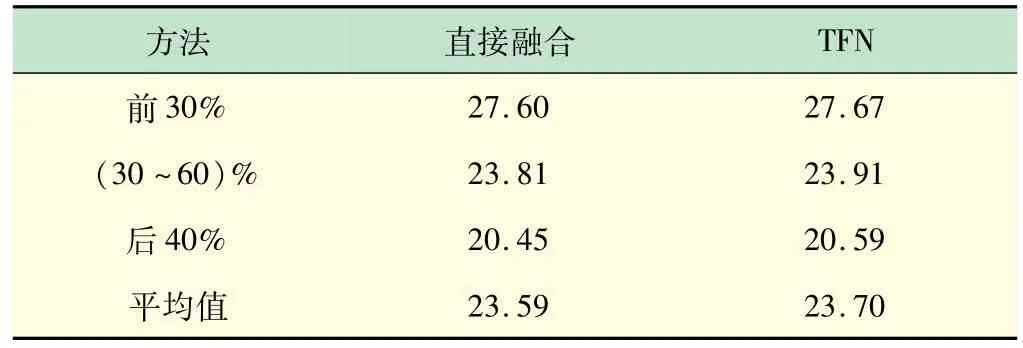
表1 不同融合方式PSNR对比

表2 不同融合方式SSIM对比
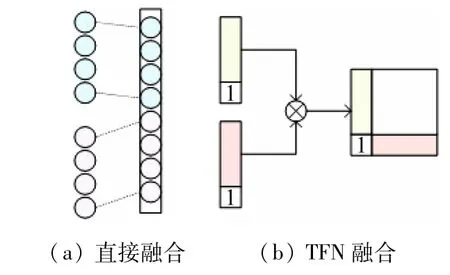
图4 不同融合方式对比
用一个共享权值的特征提取网络对融合后的图像提取特征,特征提取网络包含4 个模块,每个模块包含2 个卷积层和1 个池化层,获得图像的多层次特征。特征提取之后,通过全局相关层计算图像之间的相似度

用一个由3 个卷积层和2 个全连接层组成的回归网络来处理相关性,并预测与单应性一一对应的偏移量f。直接线性变换(Direct Linear Transform,DLT)可通过一组匹配特征点获得单应性变换。本文采用DLT将不同视角的图像转换为同一视角。经过前置网络后得到两幅图像的特征匹配,将两个点集分别标记为X和X′,利用单应变换拟合它们之间的关系:
式中:[xy1]T为特征点在X′中的坐标;[uv1]T为特征点在X中的坐标;H为目标图像到参考图像的单应性变换。
空间转换层(Spatial Transformer Layer,STL)[14]利用单应性模型保证梯度反向传播的条件下进行空间转换。在框架中STL代替了图像融合模块,将单应性变换转换为结构拼接结果。
2.2 无监督图像重建
由于图像中存在不同的平面,仅采用单一单应性对齐可能会出现重影、模糊等现象。为突破单应性的限制,采用图像重建网络来对图像进行细对齐,网络结构如图5 所示。
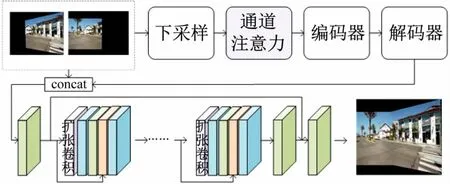
图5 无监督图像重建网络结构
感受野随着分辨率的增加相对变小,只在高分辨率重建图像会导致拼接效果不佳。为保证网络能完全感知差异区域,特别是在高分辨率和大视差的情况下,本文设计了一个低分辨率分支先学习图像拼接的变形规律。如图5 上半部分所示,将扭曲的图像下采样到低分辨率(256 ×256)。通过通道注意力的经典模型压缩和激励网络(Squeeze-and-Excitation Networks,SENet)[15]得到各通道权重。SENet 分为压缩和激励两个部分,输入特征经压缩操作,将跨空间维度H×W的特征映射进行聚合,生成通道描述符。将全局空间信息压缩到上述通道描述符中,输入层便可利用这些通道描述符。每个通道通过一个基于通道依赖的自选门机制来学习特定样本的激活,使用全局信息有选择地增强有效特征,抑制无效特征。将获得通道权重的特征输入卷积层和反卷积层分支学习图像的变形规律,生成结构化拼接结果。
经低分辨率分支后得到初步拼接结果,此时图像仍然存在亮度不一致和模糊问题。为解决这一问题,本文设计了优化网络来提高图像的分辨率。将上一步的拼接结果上采样后与高分辨率图像相结合作为该分支的输入,如图5 下半部分所示。该分支全部由卷积层组成,可以处理任意分辨率的图像。具体来说,它由两个卷积层和8 个残差块组成。为防止低级信息随网络层数的加深逐渐丢失,在第1 层的特征中加入倒数第2 层的特征。随着网络层数的增加,感受野相对减小。扩张卷积也被称为空洞卷积,如图6 所示,扩张卷积在标准卷积核中加入间隔,在不牺牲特征图尺寸的情况下使卷积核的尺寸变大。卷积核尺寸变大,感受野也就自然变大。所以残差块的第1 个卷积使用扩张卷积,之后是激活层、卷积层、相加层和激活层。将低分辨率的输出与第1 阶段的输出合并作为高分辨率的输入,输出高分辨率的拼接图像。
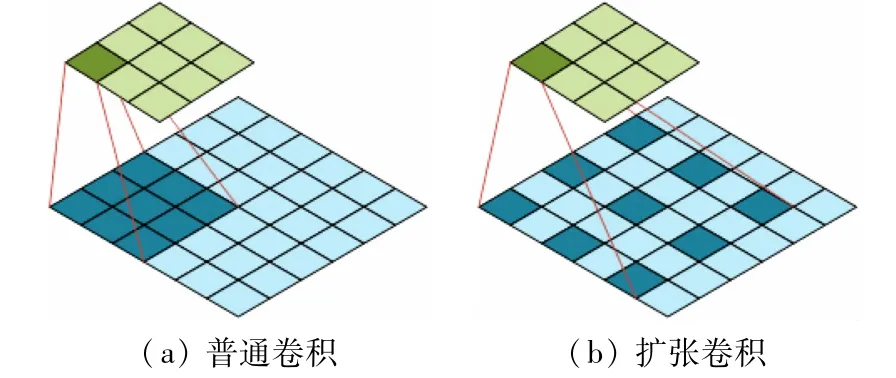
图6 普通卷积与扩张卷积感受野对比
3 实验流程与结果分析
3.1 实验流程
实验分为训练和测试两个部分,整体流程如图7 所示,首先对训练集训练得到模型参数,其次进行测试得到输出图像。
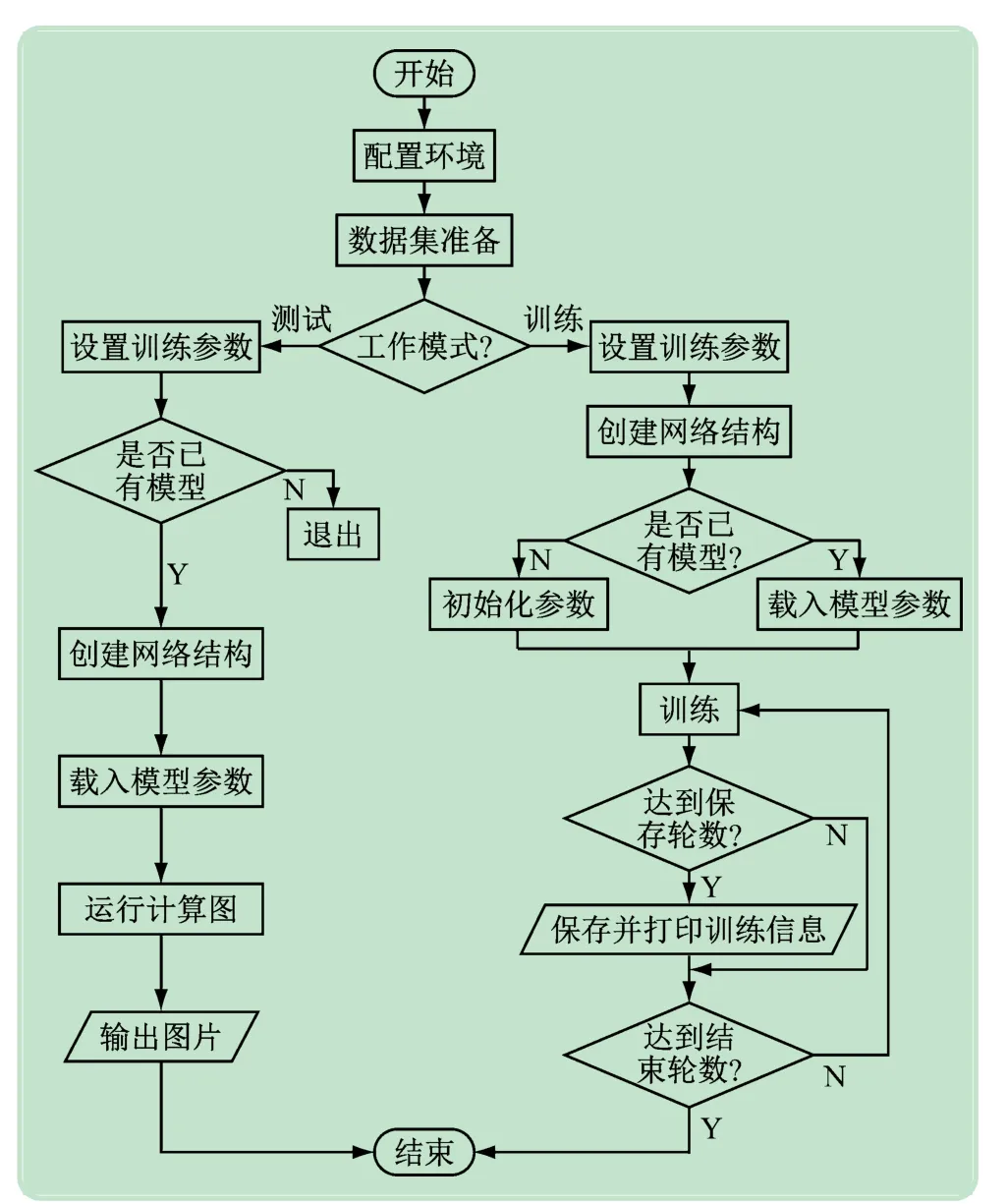
图7 实验流程
本文使用2 种数据集进行实验,第1 种是针对双摄像头图像的UDIS[13]真实数据集,含有多种场景的图像对。第2 种是包含多摄像头图像的真实数据集(自己拍摄的),主要包含校园场景和矿下场景。采用文献[16]中预训练模型获得对应的深度图像。为提高学生对实验的兴趣,训练和测试的数据集可由学生自己拍摄。构建数据集首先要确保数据集中的图像之间包含重叠区域,其次要获得与彩色图像对应的景深图。拼接框架基于Tensorflow 实现,训练和测试均在单个NVIDIA RTX2080 ti上运行。
3.2 性能分析
由于数据集缺乏真值,本文采用重叠区域的PSNR和SSIM 评估算法的性能。将DMISNet 与传统拼接方法SIFT +RANSAC、有监督拼接方法DHN和无监督拼接方法UDISNet[13]在UDIS 数据集进行比较。DHN采用公开预训练模型测试,UDISNet 和DMISNet训练批次大小均设为4,采用Adam 优化器,初始学习率设为10-4,训练100 个epoch(见表3、4)。为验证DMISNet在拼接效果上的优越性,将它与SIFT +RANSAC和UDISNet在不同场景下的拼接结果图进行对比,如图8 所示。为使结果更容易对比观察,将拼接效果不同的区域用红框框出。
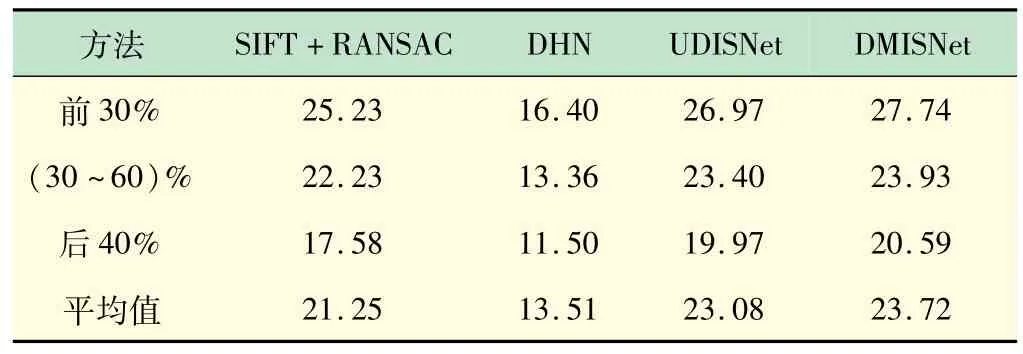
表3 UDIS数据集上重叠部分PSNR对比
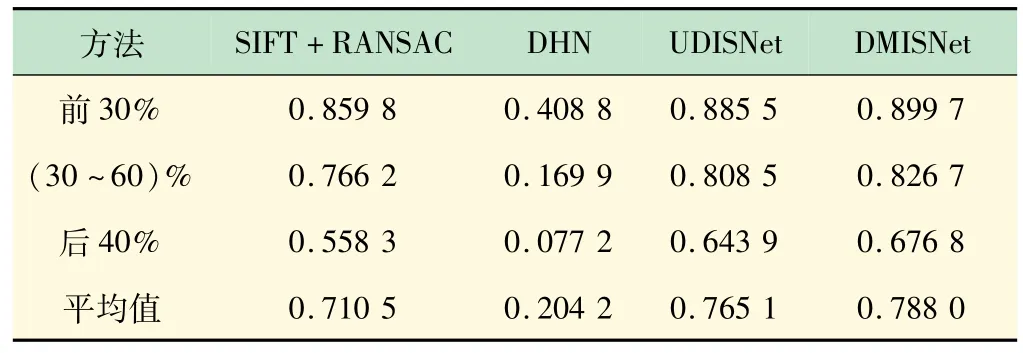
表4 UDIS数据集上重叠部分SSIM对比

图8 不同方法的拼接效果对比
通过分析表3、4 与图8 可知,DMISNet 相对于传统方法SIFT +RANSAC 和现有的无监督深度学习方法UDISNet具有一定的优越性。与参考网络UDISNet相比,DMISNet在视差大的场景下拼接效果更好,这也验证了景深图与RGB图像融合优化了单应性估计,改善了拼接效果。
3.3 多摄像头图像拼接
为验证模型的泛化性和多摄像头图像拼接的效果,直接用预训练模型拼接自制数据集中的图像,该数据集中的场景与训练集中的场景均不一致。图9 显示了拼接的效果。可见,在具有视差的场景下DMISNet具有多摄像头图像拼接的能力,直接使用预训练模型进行拼接能取得不错的拼接效果,拼接效果表明,本方法具有一定的泛化性。

图9 多摄像头图像拼接结果
4 结 语
本文设计了一种基于景深-彩色图像融合的无监督深度学习图像拼接方法,将景深图与彩色图像融合后作为输入,通过无监督单应性变换和无监督图像重建获得宽视野图像。在低纹理、低光照、大视差场景下获得了较好的拼接效果,有效避免了重影及割裂现象,在多摄像头图像拼接中也取得了不错的效果。本案例具有一定的延伸性,学生可基于本方法做出改进,有利于培养学生的实践能力,切实增强学生对新技术的理解。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
汽车工程师(2021年12期)2022-01-18
成都信息工程大学学报(2021年4期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子测试(2018年13期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
汽车维修与保养(2015年8期)2015-04-17
电视技术(2014年19期)2014-03-11
数码摄影(2009年8期)2009-10-14
