
利用项编码方法改进aPriori算法
2009-03-23 02:40高振中杨小劲
计算机时代 2009年1期
高振中 杨小劲
摘要:在众多的关联规则挖掘算法中Apriori算法是最为经典的一个,但Apfiofi算法有两个缺陷,即:需要扫描多次数据库以及生成大量的侯选集。文中对该算法进行改进提出了一种对项进行编码的方法,通过对项编码来减少扫描数据库次数并通过删除项来减少生成候选集的数量,从而提高算法的效率。实验结果表明,优化后的算法能有效地提高关联规则挖掘的效率。
关键词:数据挖掘;关联规则;Apfiofi算法;编码
0引言
数据挖掘的关联规则挖掘算法用于寻找数据项中的有趣联系,决定哪些事情将一起发生。例如:事务1中出现了物品A,事务2中出现了物品B,事务3中则同时出现了物品A和B,那么物品A和B在事务中的出现是否有规则可循呢?在数据挖掘中,关联规则就是描述这种在一个事务中物品之间同时出现的规律的知识模式。更确切地说,关联规则就是通过量化的数字描述物品A的出现对物品B的出现有多大的影响。
在众多的关联规则挖掘算法中,Agrawal提出的Apriori算法是最为著名的关联规则算法,已经为大部分商业产品所使用。该算法利用大项目集性质来生成规则,其基本思想是生成特定规模的候选项目集,然后扫描数据库,并进行计数,以确定这些侯选项目集是否是大的。该算法思想简单,实用,但是,在实现过程中会出现两个缺点:一个是会产生大量的侯选集;另一个是需要多次的扫描数据库。因此针对Apriori算法的这两个缺点有人提出了利用HASH表和布尔矩阵的方法。而本文提出一种通过对项进行编码的算法来改进Apfiofi算法可能更简单实用,本算法可以大量减少侯选项目集数和数据库扫描次数,在一定程度上优化Apfiofi算法。为了使介绍的条理更为清晰,本文首先引入相关概念,具体介绍一下关联规则;然后在此基础上介绍通过对项编码的方法来优化Apnofi算法的改进算法;接着举例描述改进算法挖掘关联规则的过程;最后将实验结果绘制成曲线图来直观地对比两个算法的执行效率。
1关联规则描述
设I={i1,i2,…,in}是项集,其中的元素称为项(item)。记DB为交易T(transaction)的集合,这里交易T是项的集合,并且T∈I。对应每一个交易有唯一的标识,如交易号,记作TID。设x是—个I中项的集合,如果x∈T,那么称交易T包含x。
一个关联规则是形如x=>Y的蕴含式,这里x∈I,Y∈I并且X∩Y=φ。
规则x=>Y在交易数据库DB中的支持度(support)是交易集中包含x和Y的交易数与所有交易数之比,记为Support(X=>Y)=P(X∩Y);
规则x=>Y在交易集中的可信度(Confidence)是指包含x和Y的交易数与包含x的交易数之比,记为:
Confidence(X=>Y)=P(Ylx)
给定一个交易集DB,挖掘关联规则问题就是产生支持度和可信度分别大于用户给定的最小支持度(min—sup)和最小可信度(min--conf)的关联规则。
Apfiofi算法把挖掘关联规则的过程分为两个阶段:
(1)获取频繁集。这些项集出现的频繁度至少和预定义的最小支持度一样。
(2)由频繁集产生关联规则。这些规则必须满足最小可信度。
第一阶段的任务是迅速高效地找出DB中全部频繁项目集,这是关联规则挖掘的中心问题,也是衡量关联规则挖掘算法的标准,一旦找到了频繁集,就可以用文献[4]提供的算法快速生成相应的关联规则。
2对项编码算法描述
本算法的主要思想是对所有的项,根据它在交易中出现的记录进行编码,在编码的同时就可以统计出项的支持度并生成频繁1一项集。然后通过对不同编码进行“与”的运算来得到频繁二项集,并根据Apriori算法的大项目集性质修改简化编码。如此循环最终得到符合关联规则的频繁项集。从以上描述可以看出本算法只需要扫描一遍数据库,并且大幅减少了侯选集数量。下面详细介绍该算法。
2.1编码规则
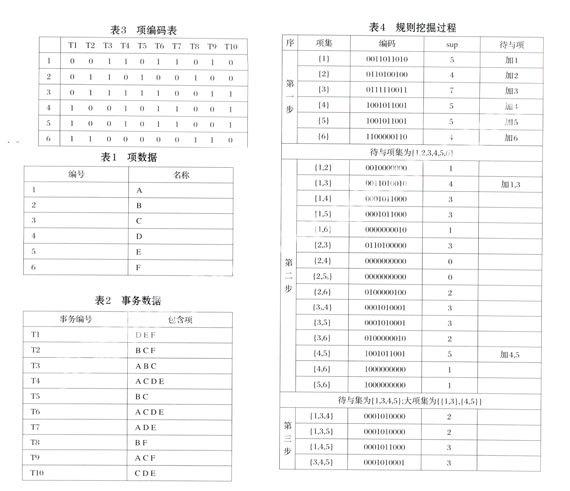
对项编码在算法中起着极其重要的作用。编码原则为:首先根据数据库中存在的交易个数决定编码长度,然后对这些交易顺序进行排序,每一个交易对应编码中的一个位置,如果某个项出现在第一个交易记录中,就相应的将编码的一个位置设为‘l,否则设为‘0。假设某事务数据库中有10条交易记录(T1,T2,…T10),而某一个项出现在交易记录T1,T3,T4,T9,T10中,那么根据编码规则可以得到该项的代码为(1011000011)。
2.2挖掘原理
当每个项都有自己的编码的同时也可以得到该项的编码中‘1的个数,也就是该项在所有事务记录中出现的次数,在所有的编码中‘1的个数大于或等于最小支持度与总事务数的乘积的编码所代表的项的集合就是频繁1一项集。将频繁1一项集中的项的编码两两进行“与”运算,例如项i1的编码为1011000011,项i2的编码为1111000010,那么i1∩2i1∩i2=(1011000011)∩(1111000010)=1011000010;新的编码在生成的同时也可以得到新编码中‘1的个数,并根据‘1的个数判断其是否大于或等于最小支持度和置信度,如果大于或等于则被认为是一条规则,并将参与运算的两个项放入待与项集(即大项集中包含在每一个大项中的单一项的集合),当所有项都完成运算后,未出现在待与项集中的项将被删除。以此类推,直到待与项集为空,则得到规则和频繁n-项集。
2.3算法描述
输入:事物数据库D,最小支持度阈值Vmin_sup。
输出:D中的频繁项集L。
现假设count(I1∩I2∩…∩I2)为计算某个项的编码或某几个项做完与运算后的编码中有多少个‘1的函数。则算法可描述为:
Ll=frequent_1-itemsets(D):
For(i=2;Li-1≠ψ:i++)
{Ci=ψ;
Li=ψ:
for each J1∈Ci-1 dO for each J2≠J1 ∈Ci-1 dO
if count(J1 NJ2n…nJi)≥Vmin_sup;
Lj=LjU(J1∪J2∪…∪Ji);
Ci=Ci∪J1∪J2∪…∪Ji;
}
3举例描述
从上述过程看,算法在第一步就扫描数据库并对每个项完成编码,以后的过程都是针对编码进行与运算,不需要重复扫描数据库,而且提高了挖掘的效率。
4性能比较
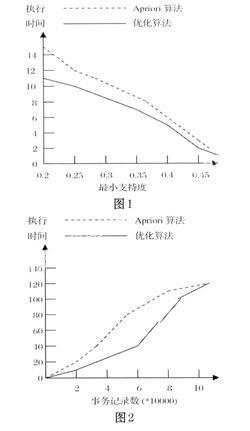
最后,为了验证算法的先进性,在同样的实验条件下,将本文所述的优化算法与Apfiori算法进行了比较。图1给出了当所给支持度不同时两种算法执行时间的差别。由图1可知,最小支持度越小,优化后的算法的执行时间比经典Apriori算法的执行时间少得越多,这说明优化后的算法在给出支持度较小时具有较高的执行效率。
图2给出了当数据库中事务记录数不同时两种算法执行时间的差别。由图2可知,当事务记录适当大时,优化后的算法的效率比经典Apriori算法的效率要高一些,这说明优化后的算法在所给数据库中记录比较大时具有较高的执行效率。
5结束语
本文对挖掘关联算法中的Apriori算法进行了优化和改进,提出了一种对项进行编码并通过对不同项的编码之间进行“与”运算来完成关联规则挖掘的算法。该算法改善了Apriori算法需要多次扫描数据库以及生成大量后选集的缺陷,也因此提高了发现频繁集的效率。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
大众投资指南(2021年35期)2021-02-16
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
电力与能源(2017年6期)2017-05-14
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
