
自动标引技术的回顾与展望
2009-07-13 09:41张静
现代情报 2009年4期
张 静
〔摘 要〕本文论述了在目前全文检索广泛应用的背景下,自动标引的重要性;把近五十年发展起来的自动标引技术按照采用的理论依据,分为统计分析方法、语言分析方法、人工智能法和混合方法,并阐述了每类自动标引技术的特征及其优劣势;最后,总结分析了现有自动标引技术的不足,并对其发展前景做出展望。
〔关键词〕自动标引;统计分析方法;语言分析方法;人工智能法;混合方法
〔中图分类号〕G252 〔文献标识码〕A 〔文章编号〕1008-0821(2009)04-0221-05
Review and Prospect of Automatic IndexingZhang Jing1,2
(1.National Science Library,Chinese Academy of Sciences,Beijing 100190,China;
2.Graduate University of Chinese Academy of Sciences,Beijing 100190,China)
〔Abstract〕Firstly this paper explained why automatic indexing was also important when full text search was widely used.Then it classified automatic indexing as statistical analysis,language analysis,artificial intelligence and mixed approaches.The advantages and disadvantages of each approach were described.At last,the limitations of the existing automatic indexing were summarized,and the future research topics and applications were discussed.
〔Key words〕automatic indexing;statistical analysis;language analysis;artificial intelligence;mixed approaches
随着互联网的发展,人们生成、获取信息的速度大大加快。面对海量的信息,人工标引效率偏低,也不能满足数据一致性的要求,自动标引技术随之发展起来。
自动标引(Automatic indexing)是指利用计算机系统从拟存储、检索的事实情报或文献(题目、文摘、正文)中抽取检索标志的过程[1]。1957年,美国人卢恩(H.P.Luhn)提出了基于词频统计的抽词标引法,由此开始了自动标引的探索。从60年代后期到70年代末,自动标引研究取得了很大进展,提出了概率统计标引法和各种加权模型等。80年代以来,研究人员开始从语言学角度研究标引技术。近年来,自动标引技术开始向人工智能方向发展。
1 全文检索时代自动标引的重要性
现在人们已经可以实现全文检索,但这并不意味着标引的重要性降低了。与之相反,面对海量信息的检索与挖掘,标引反而显得愈发重要:
1.1 标引是信息过滤的必要方法
无论是电子环境还是印本环境,信息过滤都是非常必要的。尤其在充斥着大量信息的网络环境下,对不同的信息价值进行过滤与甄别是必然的,而标引正是信息过滤的必要组成部分[2]。
1.2 标引是对信息的精炼与提升,对信息本身有智能贡献虽然Odlyzko在几年前表示,图书馆和学术期刊至少在传统模式上会过时[3],但他却认为标引的前途是光明的。他表示,标引能够为信息提供重要智能贡献,而这种贡献的成本并不高[3]。
1.3 标引可以使检索更有效率,更为准确
Jacsó表示,全文数据库通过文摘可以获得更有效的使用[4]。显而易见,浏览检索列表的关键词与文摘能更快的选出需要的文章。其次,检索关键词与文摘比检索海量全文的结果更准确,也更有效率,能更大程度的节省用户获取有用信息的所用的时间。
总之,人目前的全文检索效率与质量并不能很好的满足人们准确检索的需求,关键词自动标引技术成为了必然的发展趋势。
2 自动标引技术的分类及其优劣势
2.1 自动标引技术的分类
按照标引词的来源,自动标引可以分为自动抽词标引和自动赋词标引。自动抽词标引即由计算机自动从文本中抽取词或短语来表达信息资源的主题内容。自动赋词标引就是从某种形式的受控词表中选取词语来表达文献资源的主题内容。自动抽词标引的标引词来自文献资源本身;而自动赋词标引已经超出了单纯自然语言的范围,是自然语言与受控语言的结合。目前绝大部分的自动标引方法都是基于抽词思想的。
按照标引技术采用的理论依据来看,自动标引可以分为统计分析方法、语言分析方法、人工智能法和混合方法。
2.1.1 统计分析方法
统计分析方法的基本原理在于术语具有一些显著的统计特征,如共现、逆文档词频、熵、互信息等[5]。统计分析方法是目前应用最多的标引方法。在这类方法中,可以分为一般统计法、加权统计法和分类判别统计法。
(1)一般统计法是指通过对文献中词的出现频率、共现频率等统计指标进行统计排序,找出处于临界域(Critical Region)内、能真正表达文献主题内容的词,再根据情况选取适当数量的词作为标引词。
(2)加权统计法是在一般统计法的基础上引入了加权的概念,以获得更理想的标引结果。换言之,人们不仅观察词在文献的标题、文摘或全文中出现的统计信息,而且考虑词在文献中出现的位置或含有该词的文献的长短等因素。加权统计法根据不同的加权办法又可派生出不同的处理方法。
(3)概率统计法的原理有二:第一,标引词在文献中的出现频数的概率有规律可循;第二,标引词是否反映文献主题内容在检索中可以通过概率表示。概率统计法通过分析整体文献各类词的概率分布,找到能表达主题内容的标引词的概率分布状况,从而判定标引词。概率统计法根据概率统计模型的不同可以派生出不同的处理方法。
(4)分类判别统计法的主要特点是以词的频数或权值为基点,然后利用统计学中的数值分类法(如聚类分析(Cluster Analysis)、因子分析(Factor Analysis),多维排列(Multidimensional Scaling))或判别分析法(Discriminate Analysis)确定词在含义上的相近和疏远关系,同时也从统计的角度解决近义词、同形异义词、异形同义词等问题。这类方法在自动赋词标引中用得较多,在对标引文献进行语义分析时也有所应用[6]。Stokolov在美国生物科学情报服务处(BIOSIS)采用分类统计法进行了自动赋词标引试验,发现自动标引与手工标引之结果的吻合程度可达80%~90%[7]。
统计方法不依赖标引词的领域特征,能够比较方便地在不同领域使用。但其忽略的词语的语义信息,主要关注多词关键词,容易忽略有意义的单词关键词,标引效果不是太好[8]。
2.1.2 语言分析方法
标引的对象是由自然语言构成的文献,人们便从语言学的角度去探索自动标引的方法。语言分析标引法是对被标引的对象从词、句、语义、篇章等层次进行语法分析,从而达到标引的目的。语言分析法可以分为词法分析(Lexical Analysis)、句法分析(Syntactical Analysis)、语义分析(Semantic Analysis)和篇章分析(Text Analysis)。
(1)词法分析主要是词性标注和获得词汇的详细特征,对中文来说,还包括词汇切分的工作[9]。词法分析的主要任务是把接收到的自然语言进行切分,并为每个切分的词加上词性标记。为了能够达到快速准确的自动分词和词性标注,在词法分析各环节中还要考虑以下问题:切分歧义的消除、未登录词的识别以及兼类词性的消除。
(2)句法分析是从语法角度上确定句子中每个词的作用(如主语还是谓语)和词之间的相互关系(如是修饰还是被修饰)而实现的[6]。句法分析一般通过与事先准备好的解析规则或语法相比较而实现。经验证明,这一自动标引方法从整体上讲效果欠佳。另外,句法分析本身很难消除词义的模糊性。为此,Salton指出,所有的句法分析必须辅以语义分析,才能保证标引效果的准确性[10]。
(3)语义分析是分析词在特定的上下文中的确切含义。和句法分析相比,语义分析在自动标引的使用范围和效果都强于前者。学术界对从语言学角度研究自动标引的做法颇有争议,反对者的主要理由包括:语法太复杂、使用限制多;语言学领域的研究成果对促进自动发展帮助甚微。
(4)篇章分析是通过计算机找出篇章中内容相关的片断(词、句、句群、段、篇等)并在它们之间建立各种索引,如超媒体和超文本结构中链接索引,以便用户能快速检索出所需要的内容,或者跳段浏览最感兴趣的部分[11]。目前篇章分析已有许多理论和方法,如框架(Frame)理论、基于规划的方法等。
总的来说,目前的语言分析法对设定的关键词构成模式依赖较大,识别效率有限,在词间关系的识别上尚欠缺有力试验的验证。
2.1.3 人工智能法
人工智能(Artificial Intelligence,AI)是计算机科学的一个分支,它专门研究怎样用机器理解和模拟人类特有的智能系统的活动,探索人们如何运用已有的知识、经验和技能去解决问题。实现自动标引的目的是让机器从事标引工作中的脑力劳动,即让计算机模拟标引员完成标引文献的工作[12],因此,人们把人工智能法运用于自动标引研究既顺应自然,又带来新的活力。有不少人认为,人工智能法代表着自动标引研究的未来。机器学习法可以分为一般机器学习法、集成学习法和专家系统。
(1)一般机器学习法采用数值建模的方法,通过对训练数据进行训练获得参数,从而进行自动标引。
(2)如果将Madaline理解为多个线性分类器,则这个模型应该是集成机器学习最早的雏形了。因此,集成学习法要构建多分类器,来进行自动标引。
(3)专家系统是人工智能法应用于自动标引的具体体现。专家系统标引法是让一个智能计算机程序系统,内部含有大量标引专家水平的知识与经验,能够利用标引员的知识和解决问题的方法来进行标引。也就是说,专家系统是一个具有大量的标引专门知识与经验的程序系统,它应用人工智能技术和计算机技术,根据标引专家提供的知识和经验,进行推理和判断,模拟人类标引员的决策过程,以进行标引。
人工智能法进行标引的效果取决于人工智能研究自身进展。人工智能法实施的前提都是要建立数据量足够大的训练库或知识库,其效果的提升有赖于于机器学习的能力与速度的提高。尽管人工智能法进行自动标引比其他方法要困难,但它能从标引员的角度去了解标引过程,模拟标引员的行为。可以预见,随着技术的进步,人工智能标引法会有长足的发展空间。
2.1.4 混合方法
上述方法各有缺陷,因此可以将上述几种方法根据情况混合使用,或加入启发式知识使用。可以先利用统计分析方法获取初步标引结果,再基于语言分析方法利于语法过滤器处理统计分析结果;也可以先用语言分析方法处理文本获取候选标引词,再利用统计模型确定标引词。同时,各种抽词算法也越来越多地采用人工智能的方式,来加强语义理解,提高标引效果。
2.2 各类自动标引技术的优劣势
下表描述了以上各种标引方法的代表方法及其优劣势:
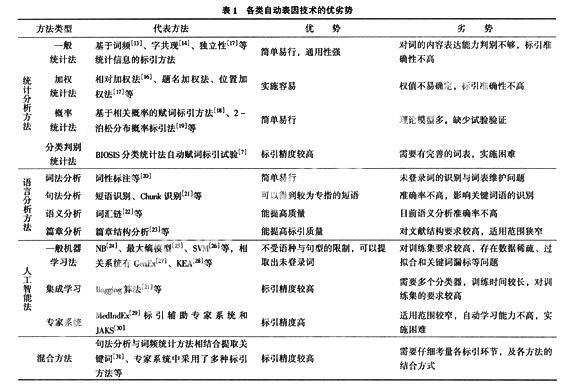
3 自动标引技术存在问题与展望
3.1 自动标引技术存在问题
信息标引(Indexing),是根据文献的特征,赋予文献检索标识的过程,包括两个主要环节:一是主题分析,即在了解和确定文献的内容特征及某些外部特征的基础上,提炼出主题概念;二是转换标识,即用专门的检索语言(标引语言)中的标识表达主题概念[32]。
主题分析阶段,自动标引技术需要解决的难点就在于采用怎样的过程能让计算机形成一种类专家的主题判断过程。理想的自动标引技术主题分析阶段应该能够形成类人的思维过程,同时也需要吸收专家判断的经验,才能达到专家标引的深度与广度。目前自动标引技术存在的问题有:
(1)分词算法存在缺陷。找出各意义单元,是进行思考和标引判断的第一步,而汉语的分词问题一直存在,到目前为止各种分词算法对歧义切分都还设有好的解决方法。这就导致进行自动标引基础存在问题。
(2)分类主题词表跟不上科学的发展。现代社会各学科发展异常迅猛,分支学科、边缘学科不断涌现。词表的编制总是落后于科学的发展。使得基于词典的切分算法总会有一些新词切分不出,也极大的影响了基于词表进行语词控制的自动标引系统的准确性。
(3)语义分析应用范围狭窄。人工标引的重要主题判断过程是对各意义单元进行语义判别,目前的计算机语义分析应用范围多局限于结构化文档,对自由文档的分析准确程度偏低,不足以支撑广泛的语义判别。
(4)知识库规模不够。人工智能技术是将专家经验融入标引过程的重要技术,但目前尚未能从根本上解决知识学习的问题,知识库更新慢,跟不上学科的发展。经验证明,开发一个适用的专家系统至少需5人/年[33]。而目前的自动标引专家系统与这个要求尚有距离。
(5)标引结果评价。人工标引结束都会有一个判别、修正的过程,自动标引同样需要进行相应的评价。传统的自动标引评价是对照人工标引结果判别或者由专家打分,这种方法主观性大,一致性程度较差,成本也比较高。因此,构建一个自动标引的通用评价模型,以减少自动标引的主观性,节省评价成本,是一项有意义的工作。
而转换标识阶段,只要转换规则设定足够细致,自动标引的标识转换就能非常精准。因此,此阶段的主要问题与难点在转换规则的设定上。
另外,自动标引技术作为一种计算机的实际应用,其应用效果同样受到程序本身的制约。各系统的研制者由于其个人知识、技术水平的限制,缺少合作,不能做到集思广益,使得自动标引系统局限性大,低水平重复现象比较普遍。
3.2 自动标引技术展望
从上面的叙述可以看出,理想的自动标引系统能够形成类人的思维过程,同时也需要吸收专家判断的经验。因此,自动标引技术的发展方向必然是向着语言分析和专家系统的方向发展。另外,多种方法集成学习,也将是今后自动标引技术发展的方向。
(1)语言分析。这方面的研究可以解决3.1描述的前3个问题,在目前的计算机技术条件下,要把理解自然语言所需的“数量”众多、同时在“度”的方面具有高度不确定性和模糊性的知识都用规则形式表达出来是不可能的。这也是语言分析只能在受限的领域获得成功的原因。但是毋庸置疑,语言分析是取得良好标引效果的必要条件,也是人工智能发展的必然阶段。因此,寻求更加理想的语言分析方案,是今后自动标引研究的趋势之一。
(2)专家系统。完全不用或少用人工参与的自动标引系统必然要能借鉴专家经验,而专家系统将是解决3.1第4个问题,并提高标引准确率与全面程度的解决方案。如何提高专家系统的学习能力,如何集成多学科专家系统都将是今后自动标引研究的趋势之一。
(3)多种标引方法的集成学习。利弊总是相对的,因此各标引方法也总会存在其优劣势,将多种标引方法集成,进行互补的集成学习,将是提高标引质量的重要手段。目前还没有一种方法能完全能模拟并达到标引员的标引能力。多种模型或方法的集成,能在一定程度上提高自动标引的质量。而如何进行这种集成学习,很好的将各种标引方法的优劣势进行互补,将是今后自动标引研究的重要趋势之一。
4 结 语
总的来说,随着网络的发展,信息的无序状态加剧,信息量成几何级数增长,这都使得自动标引不仅是图书情报业需要,而是成为了一种广泛而迫切的社会需求。计算机及信息技术的发展及应用,将为自动标引技术的研究带来更大的变化,最终方便用户,减少用户获取有用信息的时间和精力。
目前,虽然自动标引技术多种多样,但由于技术的限制,小规模试验的效果较好,大规模应用的标引质量还是不高,标引过程中也少不了人的参与。正如Lancaster和Warner所说,自动标引技术距离完全实际应用仍有很长的距离,只有机器具有足够智能,才能完全替代人类完成这项重要工作[34]。
参考文献
[1]自动标引[EB/OL].http:∥baike.baidu.com/view/853543.htm,2008-09-12.
[2]F.W.Lancaster.Do Indexing and Abstracting have a Future?[J].Anales de Documentación,2003,(6):137-144.
[3]Odlyzko,A.M.Tragic loss or good riddance?The impending demise of traditional schol-arly journals.International Journal of Human-Computer Studies,1995,42:71-122.
[4]Jacsó,P.Document-summarization software.Information Today,2002,19(2):22-23.
[5]Buitelaar P,Cimiano P,Grobelnik M.Ontology Learning from Text[C].In:the ECMI/PKDD 2005 Workshop on:Knowledge Discovery and Ontologies,Porto,Protugal,2005.
[6]储荷婷.索引工作自动化:自动标引的主要方法[J].情报学报,1993,(3):218-229.
[7]Vledutz-Stokolov,N.Concept Recognition in an Automatic Text Processing System for the Life Science[J].Journal of the American Society for Information Science,1987,(4):269-297.
[8]Alegia I,Arregi O,Balza I.Linguistic and Statistical Approsches to Basque Term Extraction[EB/OL].http:∥ixa.is.ehu.es,2008-05-13.
[9]耿骞,毛瑞.汉语自然语言检索中的词法分析处理[J].情报科学,2004,(4):466-469.
[10]Salton,G.Automatic Text Proceesing:the Transformation,Analysis,and Retrieval of Information by Computer,Reading,MA,Addison-Wisley,1989:281-284.
[11]刘平兰.数字图书馆中基于关系图的篇章分析方法研究[J].情报杂志,2003,(12):88-92.
[12]顾敏,史丽萍,李春玲.自动标引综述[J].黑龙江水专学报,2000,(3):103-104.
[13]Luhn H P.A Statistical Approach to Mechanized Encoding and Searching of Literary Information[J].IBM Journal of Research and Development,1957,(4):309-317.
[14]马颖华,王永成,苏贵洋,等.一种基于字同现频率的汉语文本主题抽取方法[J].计算机研究与发展,2004,40(6):874-878.
[15]Chien L F.PAT-tree—based Keyword Extraction for Chinese Information Retrieval[A].In:Proceedings of the 20th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR1997)[C].Philadelphia,PA,USA.1997:50-59.
[16]Edmundson H P,Oswald V A.Automatic Indexing and Abstracting of the Contents of Documents[R].Planning Research Corp,Document PRC R-126,ASTIA AD No.231606,Los Angeles,1959:1-142.
[17]Edmundson H P.New Methods in Automatic Abstracting Extracting[J].Journal of the Association for Computing Machinery,1969,16(2):264-285.
[18]Maron M E,Kuhns J L.On Relevance,Probabilistic Indexing and Information Retrieval[J].Journal of the Association for Computer Machinery,1960,7(3):216-244.
[19]A.Bookstein,D.Swanson.Probabilistic models for automatic indexing[J].Journal of the American Society for Information science,1974,25(5):312-318.
[20]韩客松,王永成.中文全文标引的主题词标引和主题概念标引方法[J].情报学报,2001,20(2):212-216.
[21]Hulth A.Improved Automatic Keyword Extraction Given More Linguistic Knowledge[A].In:Proceedings of the 2003 Conference on Emprical Methods in Natural Language Processing[C].Sapporo,Japan,2003:216-223.
[22]索红光,刘玉树,曹淑英.一种基于词汇链的关键词抽取方法[J].中文信息学报,2006,20(6):25-30.
[23]Salton G,Buckley C.Automatic Text Structuring and Retrieval—Experiments in Automatic Encyclopedia Searching[A].In:Proceedings of the Fourteenth SIGIR Conference[C].New York:ACM,1991:21-30.
[24]Frank E,Paynter G W,Witten I H.Domain——Specific Keyphrase Extraction[A].In:Proceedings of the 16th International Joint Conference on Artificial Intelligence[C].Stockholm,Sweden,Morgan Kaufmann,1999:668-673.
[25]李素建,王厚峰,俞士汶,等.关键浏自动标引的最大熵模型应用研究[J].计算机学报,2004,27(9):1192-1197.
[26]hang K,Xu H,Tang J,et al.Keyword Extraction Using Support Vector Machine[A].In:Proceedings of the Seventh International Conference on Web—Age Information Management(WAIM2006)[C].Hong Kong,China,2006:85-96.
[27]Tumey P D.Learning to Extract Keyphrases from Text[R].NRC Technical Report ERB—1057,National Research Council,Canada,1999:1-43.
[28]Witten I H,Paynter G W,Frank E,et al.KEA:Practical Automatic Keyphrase Extraction[A].In:Proceedings of the 4th ACM Conference on Digital Library(DL99)[C].Berkeley,CA,SA,1999.
[29]Humphrey,S.M.MedlndEx System:Medical Indexing Expert System[J].Information Processing and Management,1986,(1):73-88.
[30]Driscoll,J.R.,et al.The Operation and Performance of an Artificially Intelligent Keywording System[J].Information Processing and Management,1991,(1):43-54.
[31]Lois L E.Experiments in Automatic Indexing and Extracting[J].Information Storage and Retrieval,1970,(6):313-334.
[32]叶鹰,潘有能,潘卫.情报学基础教程[M].北京:科学出版社,2006:127-131.
[33]陆汝钤.专家系统开发环境[M].北京:科学出版社,1994.
[34]Lancaster,F.W.and Warner A.Intelligent Technologies in Library and Information Ser-vice Applications.Medford,NJ,Information Today,2001.
