
偏最小二乘法(PLS)在体育科研中的应用与实践
2010-03-03 14:29李江华范叶飞刘文锋
中国体育科技 2010年6期
李江华,范叶飞,刘文锋
1 前言
计算机的普及与发展使得对海量数据进行分析与处理成为可能,与此相适应,采用“系统论”的方法从系统、整体的角度进行研究也日渐成为 21世纪科学研究的主流趋势。体育科研也不例外,尤其是运动人体科学、基因组学、蛋白质组学、代谢组学等主流的系统生物学研究方法已开始频繁用于相关的研究中。由于对系统性和整体性的追求,系统论指导下的研究方法往往会产生大量的数据,要想解读如此复杂的信息,或者说从中提取有用的信息,就必须借助以计算机信息技术为基础发展起来的模式识别技术。偏最小二乘法 (PLS)是 20世纪 80年代才发展起来的一种新型的模式识别方法,它集多元线性回归法(MLR)和主成分分析法 (PCA)的基本功能于一体[7]。在高维数据处理中,如果样本类别已知,PLS不但比传统降维方法“PCA”的降维效果更好,而且以此为基础发展起来的偏最小二乘法判别分析 (PLS-DA)也比传统的线性判别分析 (LDA)具有更好的预测识别能力[10,12];另外,PLS进行降维的同时还可以轻松实现“奇异样本”的发现与剔除和自变量因子 (各观测指标)的重要性程度分析,而其他类似的数据处理方法功能相对比较单一,难以同时实现这些分析。因其对高维度数据强大的处理能力,PLS已在生物信息学、药学、社会科学等领域得到了广泛的应用,而在体育界,PLS的研究与应用相对缓慢,其功能还有待于更多的研究与开发。为此,本研究以参加第 15届亚运会中短距离比赛的中国游泳队男运动员的核磁共振 (NMR)数据为例,通过与 SPSS软件中常用的 PCA降维及 LDA数据处理效果进行比较,阐述 PLS分析的优越性以及如何利用PLS进行降维、发现奇异样本、分析自变量因子 (各观测指标)的重要性程度和实现判别分析。
2 研究方法
2.1 数理分析
通过简单分析 PLS的计算过程,阐述 PLS分析的基本原理与思路。
2.2 案例分析
利用 SIMCA-P 10.0软件,以参加第 15届亚运会中短距离比赛的中国游泳队男运动员的核磁共振 (NMR)数据为例,阐述 PLS分析的基本功能与实现过程,并通过与SPSS软件中的 PCA降维及 LDA数据处理效果进行比较,阐述 PLS分析的优越性。
2.2.1 取样与测试
亚运会赛前一个月内,每周 1次,连续收集运动员晨尿 3次。运动员根据亚运会的比赛成绩是否进入前 8名,分为决赛运动员组 (FG)和非决赛运动员组 (NF),其中, FG样本 19个,NF样本 30个。所有样品进行预处理后,在500.13MHZ磁场共振频率下进行一维核磁共振氢谱(1H NMR)测试。
2.2.2 数据处理
为了消除核磁共振采集信号过程中压水峰所造成的影响,去除了水峰和尿素峰附近 6.2~4.6 ppm这一区段(图 1)。然后对 10~0.2 ppm进行分段积分,每段为 0.02 ppm,结果从每个样本的1H NMR获得了 409个相应的积分数据[1,2]。积分数据经过常规归一化处理后,即可导入SIMCA-P 10.0软件,进行 PLS分析,计算公式如下:
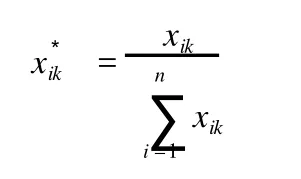
式中,xik为第k个样本,i区段的原始积分数据;为标准化以后的数据。
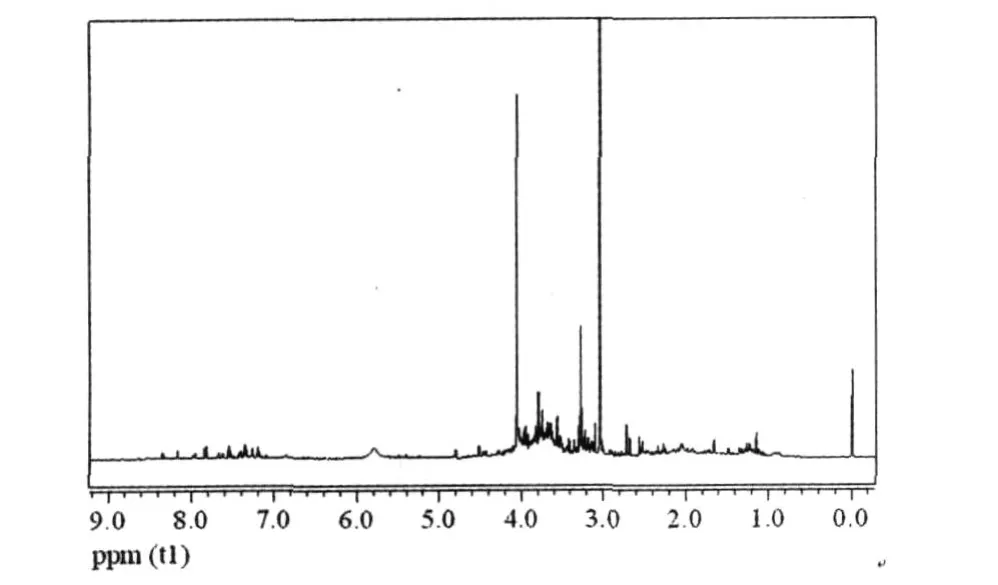
图 1 傅立叶变换后的一维核磁共振氢谱图
3 偏最小二乘法(PLS)分析的基本原理
与主成分分析一样,PLS也是通过提取主成分的方法达到降维的目的,即将原变量进行转换,从而产生少数几个新变量(主成分),这些新变量是原变量的线性组合,同时,这些新变量要尽可能多地表征原变量的数据结构而尽量少丢失信息,并且新变量即主成分互不相关,即正交。如果从数学上进行解释,即为:设有p个原始指标(x1,x2, x3,Λ,xp),用来对n个样本进行评价,则共有np个数据。提取主成分的目的是要将这些原始指标组合成新的相互独立的综合指标:y1,y2,y3,L,yp,这些综合指标表现为原始指标的线性函数[3]:
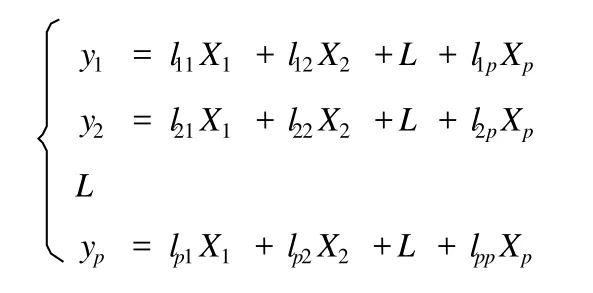
PLS与主成分分析不同点在于主成分分析法只考虑一个自变量矩阵,而偏最小二乘法还有一个因变量矩阵,在各自提取主成分的同时还要考虑两个矩阵之间相关关系。因此,PLS分析的基本思路可以概括为:“同时提取因变量主成分和自变量主成分并使两者的相关性达到最大”。具体要求:1)各主成分必须是原变量的线性组合,为了尽可能多地携带变量的变异信息,要求它们的方差达到最大;2)为了使自变量成分对因变量成分有最大的解释能力或预测能力,要求两者的相关性达到最大[4]。从数学上进行解释,即为:设有因变量Y={Y1,Y2,…,Ym}和自变量集合X={X1,X2,…,Xm},为了研究Y与X间的统计关系,首先在X与Y中提出主成分t1和u1,PLS方法在提取这两个主成分时要求同时满足:1)t1和u1尽可能多地携带它们各自数据表中的变异信息;2)t1和u1的相关程度能够达到最大[9]。综合以上两点要求,可以归结为使两者的协方差达到最大[4]。
4 偏最小二乘法(PLS)分析的基本功能
4.1 降维与发现奇异样本
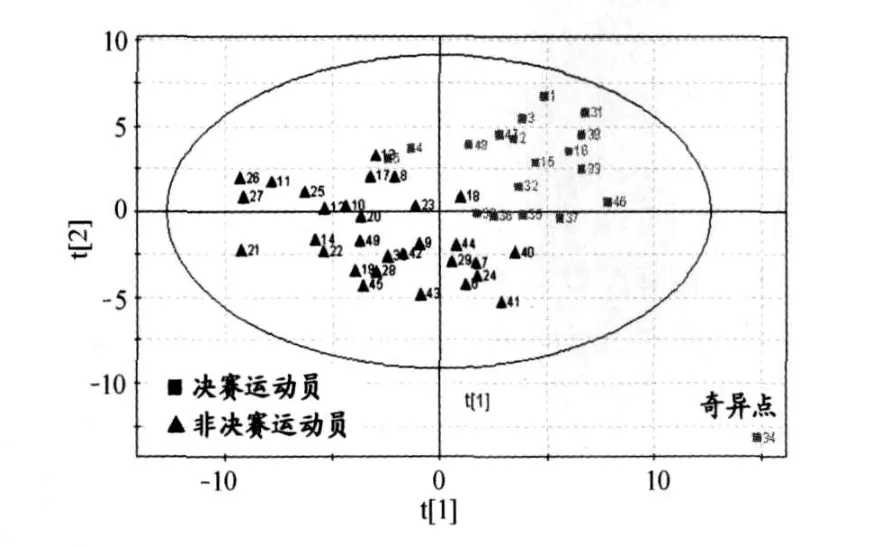
图 2 偏最小二乘法(PLS)降维效果图(t1 vs t2)
PLS分析的中心目的是降维,以排除众多信息共存中相互重叠的信息。与传统降维方法相比,由于考虑了样本的类别信息,其后续分类效果较好,并且往往只需提取较少的几个主成分进行分析即可实现对总体的综合评价。这一优点使得数据可视化成为可能,通过 PLS的二维或三维主成分散点图的直观表征,人们可以轻易地对样本类别信息进行观察与分析,有利于进一步挖掘数据的内在特征。经 PLS降维后,第一成分t1对第二成分t2的散点图显示(图2) ,决赛运动员组( FG)和非决赛运动员组(NF)样本各自聚集,分离性较好。这一结果表明,高水平运动员尿液核磁共振 (NMR)数据能在一定程度上反映运动员之间竞技水平的差异,利用 NMR进行尿液分析实现对高水平运动员的状态监控具有一定的可行性。
同时,在实验或观测过程中难免会有偶然误差产生,由此引起某些样本的数据出现异常,PLS在实现降维的过程中还可以实现异常数据的发现与剔除。其基本原理是通过第i个样本点对第h个成分th的贡献率t2hi来发现样本点集合中的异常数据[6]。
在 PLS模型中,定义样本点i对成分t1,t2,…,tm的累计贡献率为:
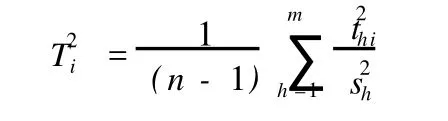
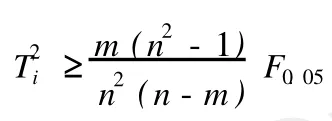
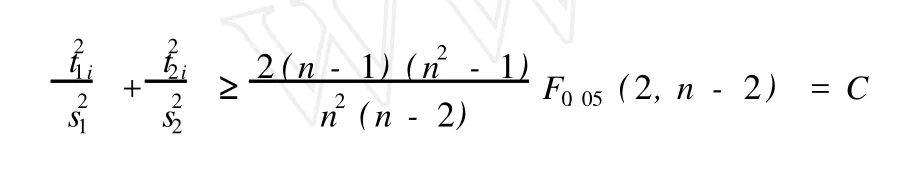
上式表示的图形为一椭圆,在t1/t2二维平面图上,可以做出 T2椭圆图。如果所有的样本点都落在椭圆区内,则认为所有样本点的分布是均匀的,落在椭圆区外的样本点为异常点[6]。
图 2中的绝大多数样本点都落在椭圆区内,第 34号样本落在椭圆区外,可见本研究的案例中,运动员的样本点总体上是分布均匀的,只有 34号样本属于奇异值。至此,一方面,在建模时或进一步进行数据处理时应将此样本剔除;另一方面,还可以据此对实验过程进行回顾,查找奇异值产生的原因。剔除 34号样本后,重新进行 PLS的结果如图 3所示,相对于图 2,决赛运动员组 (FG)和非决赛运动员组 (NF)样本得到了更好的分离效果。而主成分分析 (PCA)的降维效果则明显较差 (图 4),决赛选手和非决赛选手的样本分布散乱,相互交错,没有出现明显的分离。
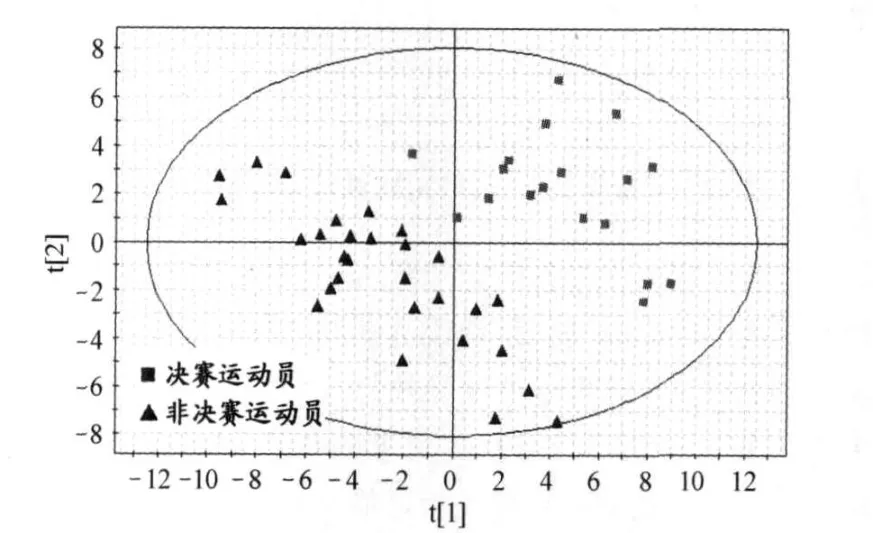
图 3 剔除奇异点后的偏最小二乘法(PLS)降维效果图(t1 vs t2)
4.2 自变量因子 (各观测指标)的重要性程度分析
PLS分析主要用于多维数据的降维,需要进行 PLS的数据往往含有多个观测指标 (也称自变量因子),如本研究所分析的案例,从每个样本的1H NMR就产生了 409个相应的数据,即有 409个自变量因子。那么,这么多的自变量因子对因变量的解释能力都相等吗?因此,在对多维数据进行分析的过程中,往往需要找出对因变量的解释能力较强的自变量因子,即重要性较高的观测指标进行进一步分析。PLS分析中,观测指标的重要性程度可以用变量投影重要性指标VIPj(variab le importance in p rojection,V IP)来量化。从 PLS建模过程可知,若所提取的成分th对Y的解释能力越强,而自变量因子xj在构造th时又起到了相当重要的作用,则xj对Y的解释能力就越大。所以,对于自变量因子x,可计算其重要性指标VIP[8]:
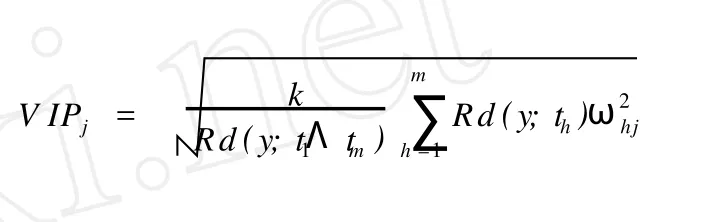
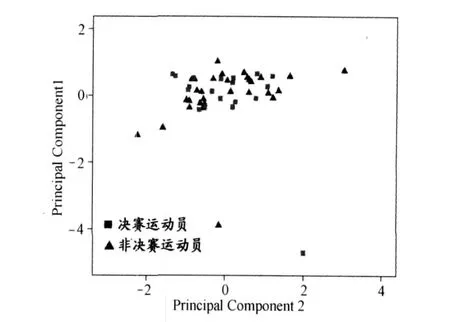
图 4 主成分分析(PCA)降维效果图(PC1 vs PC2)
通过对运动员尿液样本的1H NMR所产生的 409个自变量因子的VIPj进行计算和排序,1H NMR谱中对运动员之间竞技水平差异解释能力较强的各区段及其所代表的代谢产物如表 1所示,对这些代谢产物的进一步的分析与讨论可见笔者前期发表的相关文献[11,12]。

表 1 对竞技水平差异解释能力较强的1 H NM R各区段及其所代表的代谢产物一览表
4.3 实现判别分析 (PLS-DA)
偏最小二乘法判别分析 (partial least squares-discrim iannt analysis,PLS-DA)是基于 PLS回归的一种判别分析方法,由于在构造因素时考虑到了辅助矩阵以代码形式提供的类成员信息,因此,比传统的判别分析法具有更高效的鉴别能力,也使出现假阳极鉴别的概率有所降低[5]。其核心思想是将测试的样本人为地分为“训练集”和“预测集”,其中,“训练集”用来训练建模,“预测集”则用来检验所建模型的预测能力,具体判别过程如下:

表 2 偏最小二乘法判别分析(PLS-DA)与线性判别分析(LDA)对运动员预测集样本类别的识别结果比较一览表
1.利用“训练集”数据对计算机进行训练 (建立模型)。例如,对于两类的情况,在训练集中,有一些样本属于 A类,另外一些样本属于 B类,然后教给计算机,建立分类变量与观测数据间的 PLS回归模型。
2.根据所建立的 PLS模型,输入“预测集”各样本的观测数据,计算机计算识别这些“未知样本 (不输入这些样本的分类信息)”的类别。
本研究的案例共有样本 49个,其中的 33个样本 (约2/3)为训练集,16个样本 (约 1/3)为预测集。计算机经过训练之后,对预测集样本类别的识别结果如表 2所示:3个样本的类别识别错误,13个样本的类别识别正确,总判别正确率为 81.25%。而在所有的数据条件完全相同的情况下,线性判别分析的结果则相对较差,总判别正确率仅为68.75%(表 2)。
5 结论
偏最小二乘法 (PLS)对高维度数据具有强大的处理能力。在体育科研中,同样可以根据 PLS分析的基本原理,利用 PLS进行降维、发现异常数据、分析自变量因子 (各观测指标)的重要性程度和实现判别分析,并且在已知样本类别的条件下,PLS比传统降维方法“PCA”及“LDA”具有更好的数据处理效果。
[1]李江华,刘承宜,徐晓阳,等.2006多哈亚运会短距离游泳男运动员志愿者代谢组学研究[J].体育科学,2008,28(2):42-46.
[2]李江华,刘承宜,沙海燕,等.高水平男子中短距离游泳成绩预测代谢组学模型[J].体育学刊,2010,17(4):103-106.
[3]聂馥霖.浅谈统计综合评价中主成分分析法的应用[J].陕西综合经济,2007,(5):46-48.
[4]钱国华,苟鹏,程陈峰,等.偏最小二乘法降维在微阵列数据判别分析中的应用[J].中国卫生统计,2007,24(2):120-123.
[5]杨忠,任海青,江泽慧,等.PLS-DA法判别分析木材生物腐朽的研究[J].光谱学与光谱分析,2008,28(4):793-796.
[6]杨杰,方俊,胡德秀,等.偏最小二乘法回归在水利工程安全监测中的应用[J].农业工程学报,2007,25(3):136-140.
[7]张琳,张黎明,李燕,等.偏最小二乘法在傅里叶变换红外光谱中的应用及进展[J].光谱学与光谱分析,2005,25(10):1610-1613.
[8]周强,欧阳一鸣,胡学钢,等.数据挖掘中应用偏最小二乘法发现异常值[J].微电子学与计算机,2005,22(1):25-27.
[9]周秀平,王文圣,曾怀金.偏最小二乘与人工神经网络耦合模型在酸雨 pH值预测中的应用[J].水利水电科技进展,2006,26 (4):50-52.
[10]BOULESTEIX A L,PORZEL IUSC,DAUM ERM.M icroarray-based classification and clinical p redictors:on combined c lassifiers and additional p redictive value[J].B ioinformatics,2008,24(15): 1698-706.
[11]L IJH,L IU TCY,YUAN JQ,etal.Performance-enhancing photobiomodu lation[J].Laser Su rgM ed,2007,39(S19):68.
[12]NGUYEN D,ROCKE D M.Tumor classification by partial least squares usingm icroarray gene exp ression data[J].B ioinformatics, 2002,18(1):39-50.
猜你喜欢
车主之友(2022年4期)2022-08-27
汽车实用技术(2022年4期)2022-03-07
小学生学习指导(高年级)(2021年4期)2021-04-29
语数外学习·初中版(2020年11期)2020-09-10
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
小学生学习指导(低年级)(2019年9期)2019-09-25
小猕猴学习画刊(2015年10期)2015-10-26
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
