
帧长可配置Turbo码编译码器的设计与实现*
2010-09-26 09:06赵旦峰1朱铁林1
电讯技术 2010年9期
赵旦峰1,朱铁林1,刘 渊
(1.哈尔滨工程大学 信息与通信工程学院,哈尔滨 150001;2.西北工业大学 电子信息学院,西安 710129)
1 引 言
1993年,在瑞士日内瓦召开的国际通信会议上,C.Berrou等人提出了一种新型的信道编码方案——Turbo码[1]。经过近20年的研究与发展,Turbo码已广泛应用于深空通信、移动通信[2]等各个领域。然而,传统编译码器的硬件设计都是根据仿真结果选择单一的参数进行固化设计[3],指标变化时则需要对程序进行大幅度修改及重新配置,甚至更换系统方案,缺乏通用性。因此,如何在不同的应用场合,根据系统对信息可靠性和数据实时性不同的指标要求,由用户对两者进行灵活地折衷选择以适应不同目标背景具有重要的现实意义。
Turbo码的误码性能和延时在很大程度上取决于信息帧长,帧长越长,译码性能越好,随之而来的是译码延时的增大。因此,设计一种帧长可配置的Turbo码编译码方案,使译码延时与译码性能在不同信道环境下均能达到最佳平衡,具有广泛的应用价值。
基于此,本文将二次置换多项式(QPP)交织器集成于FPGA内部,在系统初始化时计算交织地址、映射交织图样;同时,对数据存储模块进行深度可调设计,并将编译码电路中涉及到帧长参数的变量连接于IO电路,由用户自行输入,完成了一种帧长可配置的Turbo码编译码器的硬件方案,为其专用集成芯片的开发与改进提供了参考。
2 可配置Turbo码编译码器的系统设计
Turbo码译码过程中需要多次循环迭代运算(一般为4~8次),每次迭代都需要对整帧信息进行软输入软输出(SISO)算法处理,每增加1 bit,就会增加相应的运算时延,因此帧长对系统吞吐率有重要影响。同时,由于帧长直接关乎到交织后信息的汉明距离和码重分布[4],从而影响码字抗突发错误的能力,因此帧长也是影响译码性能的关键因素之一。
帧长可配置Turbo编译码器的设计思想是:在编译码之前,首先由键盘电路输入帧长等参数,系统根据指标要求对编译码器进行初始化,该过程主要是设置电路中存储器的深度,进行交织地址的计算、映射,并通过显示设备输出状态信号;初始化过程结束后,编译码器进入准备状态,一旦有数据输入,即启动编译码流程。由此得到Turbo编译码器系统框图如图1所示。
图1 改进的Turbo码编译码系统框图
图1的Turbo码编译码器中,所有有关信息长度的参数均设置为输入变量,包括存储器深度、计数器周期、状态机控制等。根据系统框图,接下来进行模块化设计。
3 FPGA功能模块的设计实现
3.1 交织器设计模块
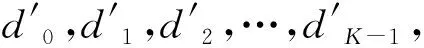
(1)
交织地址Π(i)由如下公式计算得到:
Π(i)=(f1i+f2i2)modK
(2)
式中,参数f1和f2取决于交织长度K,具体值可参考文献[2]。
传统交织器的FPGA设计一般采用软件编程(C语言)的方法,根据通信协议,将系统所需帧长的交织图样预先计算出来,生成存储器初始化文件载入到ROM中[5]。这样虽然降低了硬件复杂度,却不能自行配置编码帧长,缺乏灵活性和通用性。因此,设计中将交织算法集成于FPGA内部,帧长改变时启动交织器重新计算交织地址存储于RAM中。因为并不是每帧信息编译码时都需要运行交织算法模块,只是在初始化阶段载入交织地址,使交织算法与编译码器分时工作,在编译码交织时只需读双口RAM即可,不会增加译码延时。QPP交织器的硬件结构框图如图2所示。
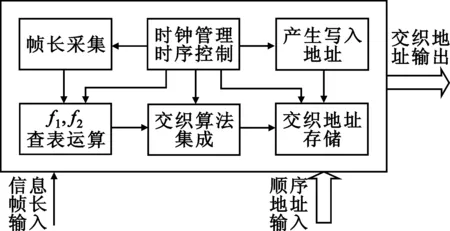
图2 QPP交织器的硬件结构框图
在编译码器初始化阶段,首先从外部输入信息帧长K,经过防抖动处理,由帧长采集电路传送到f1、f2运算单元,查表得到f1、f2的值,提供给交织运算模块。
交织算法集成单元是交织器设计的核心单元。主要功能是根据LTE协议标准以及参数K、f1、f2,在时序控制模块的约束下,计算交织地址。
计算中涉及到FPGA不支持的对任意整数取余的操作,均转化为固定次数的加减循环操作,采取小时钟计算、大时钟输出的措施,保证交织数据的正确读取。
计算交织地址的同时产生写入地址,将交织地址顺序存储到双口RAM中,由此完成了交织器的主体设计。整个交织计算过程是在时序控制模块下有条不紊地管理运行的。随后发送握手信号,可以开始Turbo码编译码流程。调用交织器模块时只需将顺序地址输入到双口RAM的读地址端,便能得到既定的伪随机交织地址。Turbo码编译码器中交织、解交织的实现流程框图如图3所示。

图3 交织、解交织工作原理框图
图3中时序控制模块的管理下,读/写地址产生器产生顺序地址,将信息序列顺序写入到数据存储双口RAM中,同时用此顺序地址去访问存储有交织地址的双口RAM,将此双口RAM的输出作为数据存储双口RAM的读地址,将信息序列按照交织地址读出,即得到交织后信息序列,完成数据的交织[6]。
而解交织为交织的逆过程,即先将交织后信息序列按照交织地址写入双口RAM中,然后按照顺序地址将数据读出,即得到原始信息序列,完成数据的解交织。
3.2 Turbo码编码器的设计
Turbo码编码器由递归系统卷积码(RSC)子编码器、交织器、复接电路等构成,实现框图如图4所示。

图4 Turbo码编码器实现结构图
图4中,系统初始化完毕后,交织器已存储有对应帧长的交织图样,编码器首先接收到一帧信息存储于RAM中,开始信号启动编码过程。在时钟管理模块和时序控制模块的指引下,计数器产生顺序地址,再以此顺序地址访问交织器得到交织地址,分别以顺序地址和交织地址从存储有信息序列的RAM中读取数据进入对应的RSC进行编码,同时复接电路对信息位和校验位进行串并转换,一帧信息编码完毕对子编码器做归零处理。编码器的工作流程图如图5所示。

图5 Turbo码编码器工作流程
图5中,编码器默认处于空闲状态(IDLE),信息存储结束后,开始信号(start)启动编码器进入CODE(交织、编码、复接)状态,当一帧信息编码完毕(cover=1)分别对两个子编码器进行归零处理(TAIL、TAIL2状态),归零结束后返回IDLE状态,等待下一帧信息数据的到来。
3.3 Turbo码译码器的设计
根据译码原理和交织器实现方式,得到译码器实现结构图如图6所示。
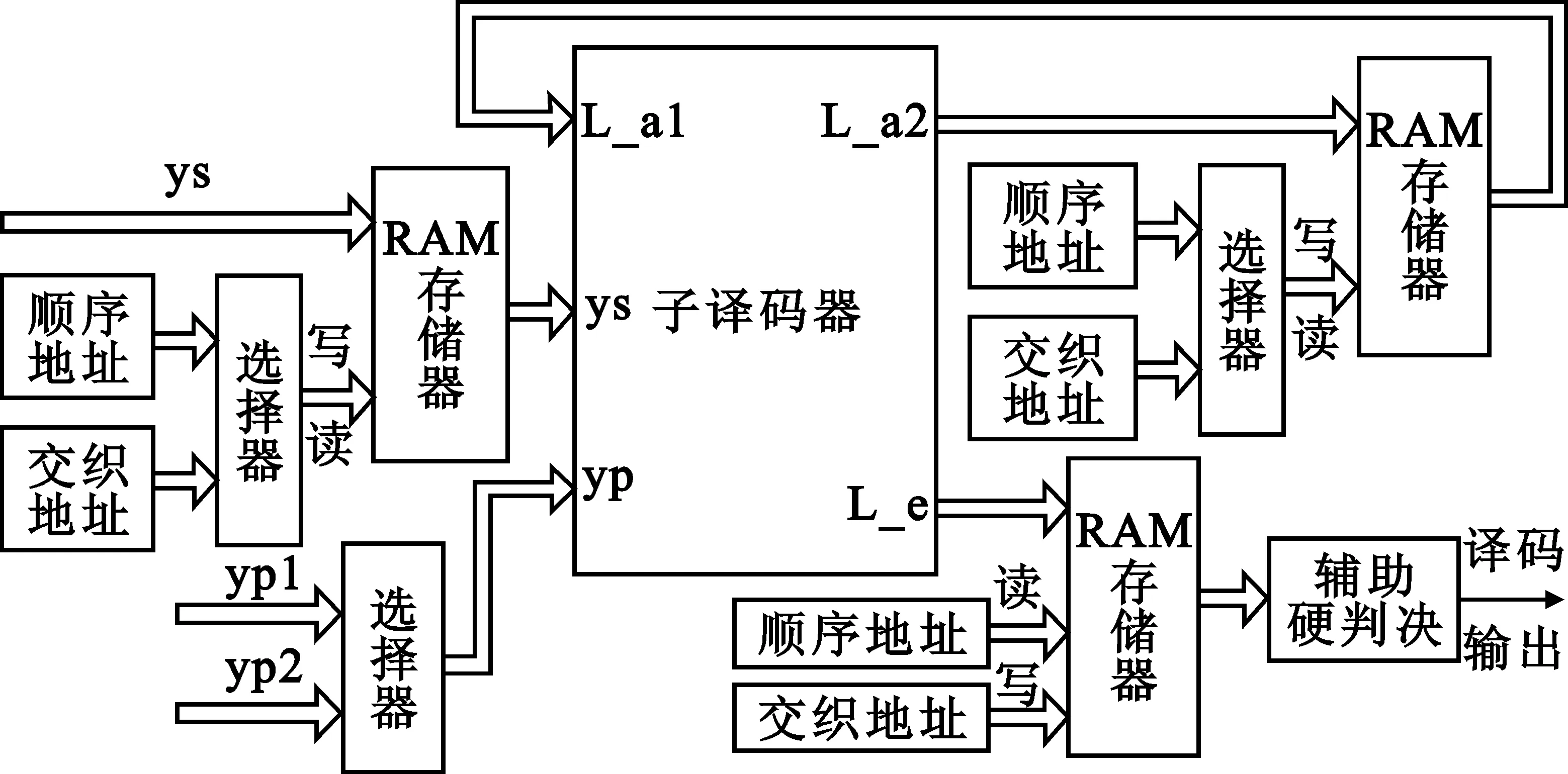
图6 Turbo码译码器结构图
图6中,为节省硬件资源,采用子译码器单核复用的结构模式。当子译码器模块作为子译码器1时,信息比特ys顺序写入存储器后顺序读出到子译码器中,L-a2以交织地址写入存储器,顺序地址读出作为子译码器1的先验信息,同时校验位选择yp1,子译码器1根据3个输入进行软输入软输出(SISO)译码运算,得到新的L-a2及L-e;此后子译码器作为子译码器2,以交织地址将ys从存储器中读出,L-a2以顺序地址写入存储器,交织地址读出作为子译码器2的先验信息,同时校验位选择yp2,子译码器2根据3个输入进行SISO译码运算,得到新的L-a2及L-e,完成一次迭代。在达到指定的迭代次数后,将L-e解交织后进行硬判决,得到译码序列。设计中,子译码器采用复杂度与性能折衷的Max-Log-MAP译码算法,计算过程如下:根据输入的信息位、校验位及先验信息的软信息,在时序控制模块的管理下,分别进行分支转移度量、前向状态度量、后向状态度量和对数似然比的计算及存储,以备下次译码运算调用。
4 系统实现与仿真结果分析
在Xilinx ISE开发工具上,用Verilog HDL语言对上述各功能模块进行编程描述;在对整体系统进行时序设计及算法优化的基础上,用ModelSim SE 6.2a进行布局布线后仿真。
编译码系统初始化时,可配置帧长QPP交织器的时序仿真图如图7所示。

图7 帧长128的交织图样波形图
图7为输入帧长K=128时,交织模块输出的交织地址波形图。在每个大周期内将交织地址计算出来并在每个大时钟周期的最后一个小时钟周期将此交织地址写入双口RAM,完成交织模块的设计。
交织器通过验证后,对Turbo码编码器进行时序仿真,得到仿真波形图如图8所示。
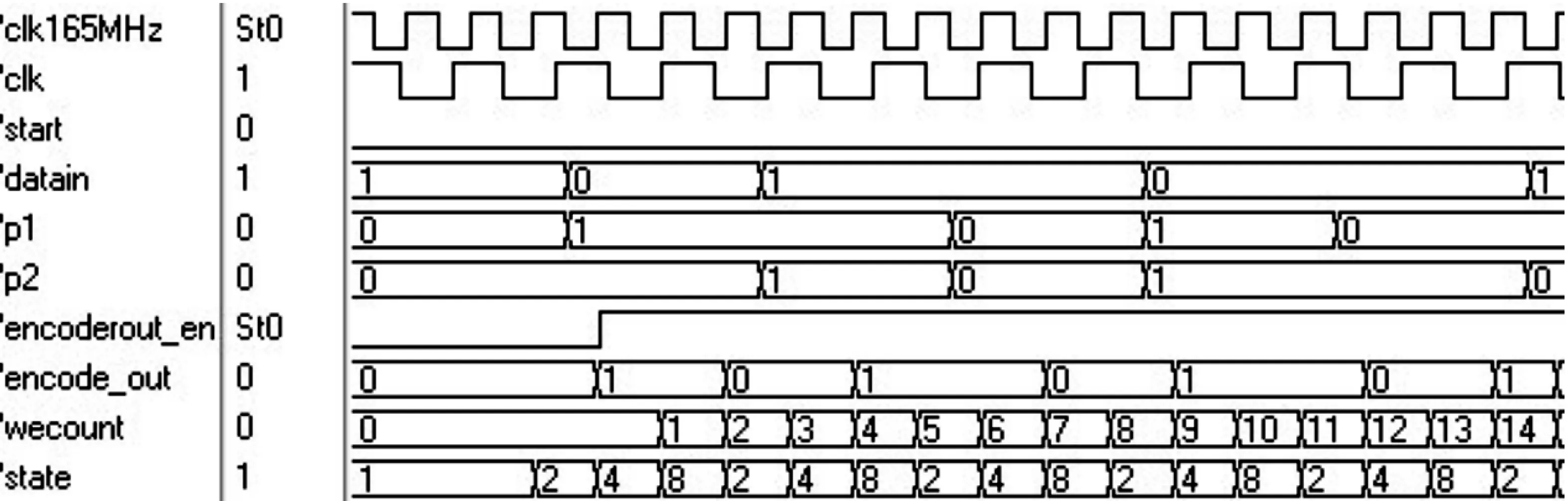
图8 Turbo码编码器仿真波形图
图8中,帧长设置为512,由于没有删余,每输入1个信息位,对应输出3位系统码字。经多次验证,与Matlab仿真数据进行对比,结果正确。
将编码码字量化后传递给译码器,译码迭代6次,帧长设置为512,得到Turbo码译码器时序仿真波形图如图9所示。
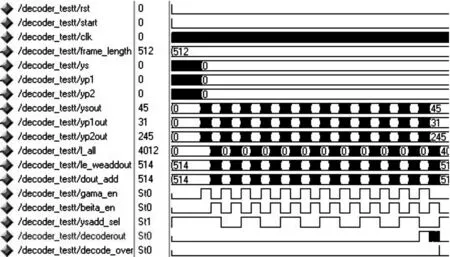
图9 Turbo码译码器波形仿真图
图9中,译码器首先根据帧长设置初始化交织图样,然后对系统码字解复接,得到信息序列(ys)、校验位1(yp1)、校验位2(yp2),与外信息(L-all)一起输入子译码器进行SISO译码运算,迭代6次后判决得到译码结果(decoderout)。多次仿真无误后,将程序下载配置到Xilinx公司Virtex-2 Pro系列的XC2VP30 FPGA中,利用串口调试助手,软件编写测试窗口,进行测试。结果显示,本设计可以利用外围键盘电路自行输入帧长,进行交织运算,得到交织图样,并能依据帧长参数正确实现Turbo编译码功能,达到了设计要求。
5 结语
本文提出并实现了一种可根据具体参数要求现场配置帧长的Turbo编译码器设计方案,与固定帧长系统相比,具有更强的灵活性,是一种比较理想的通用型方案。然而由于FPGA自身特点的限制,即使选择算法相对简单的QPP交织方式,当信息帧长6 144时交织地址初始化过程仍耗时将近40 s,虽然不对后续编译码速率产生影响,但是如何有效缩短初始化时间,根据算法特点简化交织运算电路仍有待进一步研究。
参考文献:
[1] Berrou C,Glavieux A, Thitimajshima P. Near Shannon Limit Error-Correcting Coding and Decoding Turbo-Codes[C]//Proceedings of ICC’93.Geneva:IEEE,1993:1064-1070.
[2] 沈嘉,索士强,全海洋,等. 3GPP长期演进(LTE)技术原理与系统设计[M].北京:人民邮电出版社,2009:92-96.
SHEN Jia,SUO Shi-qiang,QUAN Hai-yang,et al.3GPP Long Term Evolution:Principle and System Design[M].Beijing:Posts & Telecom Press,2009:92-96.(in Chinese)
[3] 罗绮丽, 刘应状, 萧奋洛. 一种高效的Turbo码硬件实现算法[J]. 电讯技术, 2006,46(4): 36-40.
LUO Qi-li, LIU Ying-zhuang, XIAO Fen-luo. A High Efficient Implementation Algorithm for Decoding Turbo Codes[J].Telecommunication Engineering,2006,46(4): 36-40.(in Chinese)
[4] 刘东华. Turbo码原理与应用技术[M]. 北京: 电子工业出版社, 2004: 236-238.
LIU Dong-hua. Principle and Application Technology of Turbo Code[M]. Beijing: Publishing House of Electronics Industry, 2004: 236-238. (in Chinese)
[5] 薛礼妮, 崔维新. Turbo码随机交织器的设计与实现[J]. 电讯技术, 2009, 49(10): 70-73.
XUE Li-ni, CUI Wei-xin. Design and Implementation of Turbo Codes Random Interleaver[J]. Telecommunication Engineering, 2009, 49(10): 70-73. (in Chinese)
[6] 罗清华. Turbo码编译码器FPGA设计与实现[D]. 哈尔滨: 哈尔滨工程大学, 2008: 36-37.
LUO Qing-hua. The design and Implementation of Turbo Encoder and Decoder Based on FPGA[D]. Harbin: Harbin Engineering University, 2008: 36-37. (in Chinese)
猜你喜欢
美食(2022年2期)2022-04-19
电气电子教学学报(2021年4期)2021-08-24
女报(2019年3期)2019-09-10
成都信息工程大学学报(2018年4期)2019-01-23
成都信息工程大学学报(2018年6期)2018-03-21
CHINESE JOURNAL OF AERONAUTICS(2017年2期)2017-11-20
时代英语·高一(2017年5期)2017-11-14
华人时刊(2016年17期)2016-04-05
广西科技大学学报(2015年4期)2015-02-27
电子设计工程(2015年11期)2015-01-16
