
面向网络论坛话题发现的文本处理技术研究
2011-10-20 05:58吴伊萍
赤峰学院学报·自然科学版 2011年11期
吴伊萍
(1.华侨大学 计算机科学与技术学院,福建 泉州 362021;2.泉州师范学院 数学与计算机科学学院,福建 泉州 362000)
面向网络论坛话题发现的文本处理技术研究
吴伊萍1,2
(1.华侨大学 计算机科学与技术学院,福建 泉州 362021;2.泉州师范学院 数学与计算机科学学院,福建 泉州 362000)
论坛、博客、微博、QQ空间等都是重要的网络社交载体,但各自的网页结构和语言风格又有差异.本文根据网络论坛的网页结构和数据特点,阐述了应用于话题检测的网络论坛数据处理的相关技术,包括文本预处理和特征选择技术.介绍了这些技术的发展现状和研究成果,论述了命名实体信息在论坛话题检测中的作用,讨论了论坛中时间信息的识别与规范化处理.
网络论坛;话题检测;特征选择;命名实体
互联网是把双刃剑,它既提供了大量进步、健康、有益的信息,也滋生了不少反动、迷信、低级的误导性言论.互联网的开放性、虚拟性、隐蔽性和随意性等特点,使得越来越多的网民通过互联网传播信息,表达观点,互联网已成为最草根、最有效的监督平台.在当前动荡的政治、经济环境下,论坛、博客、微博和各种聊天工具成为当今网络信息传播的主要载体.地方网络论坛聚焦着当地的各类信息,且具有传播快速、反映强烈、影响大的特点,是当地网络舆情的“晴雨表”.对本地论坛进行有效监测,有利于快速了解地方信息,对一些人民群众关注度高的问题予以及时疏导和解决,有利于地方经济、政治和社会环境的稳定.
网络论坛具有不同于普通网页的网页结构,数据噪音大,用户语言主观性强.近年来对网络论坛的研究主要集中在论坛数据爬取与自动抽取,论坛影响力发现,论坛热点话题发现,网络论坛舆情监测,BBS观点挖掘等.本文根据网络论坛的网页结构和数据特点,阐述了面向热点话题检测的论坛数据处理的相关技术,其中包括文本预处理和特征选择技术.文章介绍了这些技术当前国内外的相关研究方法、进展和工具.在特征选择方面,突出了命名实体中地名和机构名的重要作用,对时间信息的识别与规范化处理进行了探讨.
1 相关研究工作
1.1 TDT简介
话题发现研究最初起源于TDT(话题检测与追踪),它是1996年美国国防高级研究计划委员会发起的,联合卡内基梅隆大学、Dragon系统公司和马萨诸塞大学一起开展的.TDT的研究目标是从连续的广播、电视新闻节目的语音或文字记录中识别出系统未知的话题以及与该话题相关的报道,或发现与某一已知话题有关的新报道.TDT评测提供了新闻方面的语料TDT2和TDT4,研究者可从LDC(Linguistic Data Consortiun)网站[10]上申请获得.
最初,话题检测是对新闻报道流依据不同的话题做聚类,使用的是文本聚类技术.之后,随着网络的发展,TDT的方法和技术应用于各大门户网站取代人工完成自动专题生成和热点新闻生成等任务,以及QQ空间、网络论坛、博客等的热点话题生成.如腾讯为每位QQ空间用户提供热点话题的服务,Google推出的新闻推荐等个性化的内容服务.
1.2 相关定义
定义1 舆情是指一定时期一定范围的社会群体对某些社会现象的主观反映,是民众思想、情绪、心理、意见和要求的综合表现.
定义2 网络论坛又称为Internet Forum[1],BBS,网络社区.维基百科[]里简称为论坛或讨论区或讨论版,它是一种提供在线讨论的程序,或由这些程序建立的以在线讨论为主的网站.虽然在技术上代替BBS服务,很多论坛还保有BBS的名称.国内著名的论坛有天涯论坛、西祠胡同、猫扑等.
定义3 话题在TDT中指由一个种子事件或活动以及与其直接相关的事件或活动组成的.根据话题的定义,一篇报道只要描述的事件或活动与种子事件有直接联系,就与该话题相关.在论坛中,话题又称为线索(thread),它由首贴和回帖组成.首贴的标题为主标题及整个话题的标题,回帖即为副标题.
定义4 帖子是指论坛中的会员发表的公开的单个信息,它可以是一个发起讨论话题的首贴,也可以是回复某一话题的回帖.
1.3 网络论坛的网页结构与数据特点
1.3.1 网络论坛的网页结构
论坛采用层次的树形结构,一般分为三层页面:版块页面、帖子列表页面、帖子内容页面.论坛版块页面为一个论坛的总入口,用户可以从不同的版块入口进入相应的帖子列表页面.帖子列表页面是各个帖子的集合,它包括:帖子主题、帖子作者、帖子回复数、帖子浏览数、最后回帖时间和作者,以及是否为精华帖、置顶帖及热帖等属性.帖子内容包括首帖和回帖内容.
论坛中站长拥有论坛的所有权,按照不同讨论题材分成不同的版块,各个版块由版主管理,为鼓励会员发言设有会员积分系统.
1.3.2 网络论坛的数据特点
论坛中主要包含两类数据,一是系统自动生成的,如作者、发表时间、标签等;二是用户创建的,如帖子标题、内容.网络论坛中的数据多为短文本,具有以下特点:(1)实时性非常强,数量巨大.(2)以发表时间排序.(3)同一话题常出现在不同的版块,内容交叉、杂乱.(4)每一条消息包括正文(帖子)、标题、作者、发帖时间等特征.(5)回帖信息多为短为本,且用语不规范,主观性词语多,噪音大,存在大量省略、缩写、指代及拼写错误等现象.(6)网络论坛数据之间存在回复关系,源消息为新发布的帖子,回复消息为一个帖子的回帖.例如A为源消息,B、C、D直接回复 A,E、F直接回复D,构成的回复关系树如图1.(7)语义漂移:随着消息数量的增加,消息序列上不可避免地出现语义漂移的现象,即用户讨论的中心议题发生转变[7].
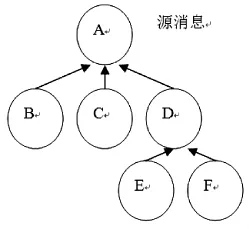
图1 回复关系树
2 面向网络论坛话题发现的文本处理技术
本节介绍了文本预处理中的常用工具和主要思想,分析了网络论坛特征选择中的国内外思路,归纳出面向本地网络论坛的基于命名实体的话题检测方法,并对时间信息的识别和规范化进行了描述.
2.1 文本预处理
文本预处理是指对抽取出的帖子进行分词、去除停用词、词项归一化,建立文档的向量空间模型.停用词可以使用停用词表.论坛中的短文本数据的文本预处理与长文本相似.论坛数据文本预处理的具体的步骤如下:
2.1.1 分词
词是文档的最小组成单位[9].在英文中,词之间由空格或标点符号分开,因此英文的分词较容易实现.而中文文本除了标点符号之外词语之间没有明显的分隔符.我们可以借助一些中文分词工具.在中文分词领域,研发的分词系统有“庖丁解牛”Poading Analysis①,中科院的ICTCLAS分词系统②,北京语言大学的GWPS系统③,以及哈工大的语言技术平台LTP④.
2.1.2 去除停用词
停用词(stop word)是指在文本中出现频率高但含义虚泛的词语,如英语中的a,an,the,and等,中文中的“的,得,地,这,那,但是,和,然而”等.一个常用的生成停用词表的方法是,将词项按照文档集频率(每个词项在文档集中出现的频率)从高到低排列,然后手工选择那些语义内容与文档主题关系不大的高频词作为停用词.
此外,一些词项在整个文档集中出现的频率很低,也不适合作为文本的特征项,通常设定一个词频阈值,只要词项频率低于词频阈值的词即被去除.
2.1.3 词项归一化
词项归一化指将看起来不完全一致的多个词项归纳成一个等价类,以便在它们之间进行匹配.英文可以使用Wordnet,中文可以使用Hownet语义资源得出词之间的语义相似度从而识别同义词对,也可以使用同义词词典扩展.除近义词、同义词外,英文中还存在大小写转换、词干还原和词形归并等问题.
2.2 特征选择
经文本预处理后建立的词项-文档矩阵是一个高维的向量空间,使用特征选择的方法以达到降维的目的.特征选择是从原始特征集合中选出它的一个子集来构成新的特征空间.
Zhang Zhonghui等人[2]认为网络论坛中的文本特征选择,一需要突出话题信息丰富的词语;二为克服论坛文本信息长度差异显著的不良因素,按照文本特征——人物或机构、地点、名词、动词和其他五类表示,基于不同类别主题抽取特征.Hila Bechker等人[3]从社交媒体中挖掘出描述事件的文本,社交媒体中的文本内容具有的核心特征包括:作者、标题、标签、日期或时间、地点.通过这些特征识别出与某事件相关的社交站点的文本.张卫[7]在网络论坛数据的特征提取方面,考虑帖子标题的重要性,修改权重计算TF×IDF,增加帖子标题中单词的权重;其次鉴于网络论坛回帖多为短文本,存在关键词稀疏、信息不完备,他根据帖子之间的回复关系构建回复关系树,根据树上特征的传递调整权重.吴昊等人[8]提出基于聚类的主题发现,使用潜在语义分析计算回帖的相似度,结合时空因素对BBS中的主题进行聚类,发现主题.
简而言之,在论坛数据的特征提取中,需根据主题类别抽取特征.一要突出话题信息丰富的词语,如标题、作者、人物或机构、日期或时间、地点、动词和名词等.二需鉴别回帖与首贴之间的相关性,不能盲目认为回帖数高和浏览数量高就是热点话题.
2.3 网络论坛中的命名实体
2.3.1 命名实体识别简介
命名实体包括人名(People)、地名(Locations)、机构名(Organizations)、日期(Date)、时间(Time)、数字(Digit)等.命名实体的识别是从文本中识别出现的专有名称和有意义的数量短语并加以归类.命名实体识别已有二十年左右的发展历史,主要的方法有基于规则的方法、基于统计的方法和二者结合.常用的模型有隐马尔科夫模型(HMM)和条件随机场模型(CRF).
命名实体的识别工具有中科院的ICTCLAS②,哈工大的LTP④、OpenNLP⑤、Stanford Named Entity Recognizer⑥等.ICTCLAS和LTP适用于中文命名实体识别,而OpenNLP和Stanford Named Entity Recognizer适用于英文命名实体识别.ICTCLAS除可以进行中文分词外,还具有识别人名、地名和机构名的功能.LTP中的命名实体识别模块可识别人名、地名、机构名、专有名词、日期、时间和数量短语等七类实体.它采用统计和规则相结合的方法,先使用最大熵(ME)方法对文本初始标注,再使用规则的方法对错标或漏标结果进行修正.OpenNLP能够识别人名、地名、机构名、日期、时间、财务数据和百分数.Stanford Named Entity Recognizer使用条件随机场(CRF,Conditional Random Field)序列模型从文本中抽取出机构名、人名和地名.
2.3.2 基于命名实体的论坛话题检测
在新闻报道的话题检测中,同一话题内的相关新闻报道往往被时间、地点、人物等命名实体要素所连接,合理使用命名实体有助于提升话题检测的性能.Giridhar Kumaran等人[4]深入研究命名实体在话题检测中的应用效果,发现在不同类别的文档中命名实体的使用效果不同.对于科技类的报道,人名和机构名的作用更强;对于自然灾害类的报道,地名更为重要.余军和陈晓鸥[6]对人名、地名、机构名等中文命名实体的识别进行研究,使用CRF(条件随机场)模型和特征模板获得不错的识别效果.
本地网络论坛主要聚焦地方基础设施建设、公共医疗、教育、住房、出行等问题,例如,温陵社区⑦中的品读泉州子论坛,主要版块有:城市建设管理大家谈,城市论坛,民生民声,报料曝光,天下泉商,楼市大家谈,闽南文化,新闻时评等.其中城市论坛的主题是关注发展、关注城市,反映弊端、建言献策;民生民声的主题是客观反映、理性建言,关注民生、倾听民声.在这些版块中,主要的话题都集中在当地百姓生活、教育、医疗、出行等相关的问题,因此当地地名、机构名在帖子中出现的概率也就大于其他命名实体.如图2所示,2011年7月25日温陵社区截图.在网络论坛的话题检测中,合理使用命名实体将有助于改善论坛话题检测的效果.
图2 2011年7月25日温陵社区截图
2.4 网络论坛中时间信息的识别与规范化
论坛的信息是动态演化的,随着时间的变化而发展,每个话题都将经历出现、成长、成熟、消退四个阶段,每个话题在不同的阶段有不同的侧重点,二不同时刻的话题内容之间具有关联性.时序性是话题的另一重要特征.
时间信息包括事件发生的时间、报道或发帖的时间、帖子的最后编辑时间.时间信息的表达包括精确的时间表达式、模糊的时间表达式和指代的时间表达.精确的时间表达,如 2011/7/22,21:34分;模糊的时间表达,如“今年年初”;指代的时间表达,如“昨天,今天下午,去年”时间信息的规范化.时间信息的识别包括时间词语的收集和时间短语边界信息的收集.时间信息的规范化指将所有的时间表达式表示成为统一的、显示的格式.对于模糊的时间表达式和指代的时间表达根据帖子的编辑时间和发帖时间进行时间信息的规范化.规范化要处理的问题涉及:(1)时间规范形式的表达;(2)基准时间的确定,以便规范相对时间信息;(3)时间指代词的消解,以便找到对应的精确显示的时间表达等.规范化形式:“****年**月某**日**时**分**秒”.
由于时间信息的抽取比较困难,通常将数据按照时间目录存放.如文件夹20110701,代表2011年7月1日的帖子.
3 总结
地方网络论坛是当地民生、民情、民意的集中反映,对当地论坛进行话题检测有利于及早发现不和谐因素,进行及时疏导解决问题.文本预处理和特征选择技术是话题检测的基础.根据不同主题,合理使用命名实体和时间信息有助于改善话题检测的效果.今后将继续深入本地网络论坛话题检测的相关技术,如构建人名、地名和机构名本体或数据库,选择合适的聚类技术生成初步的话题簇等.
注 释:
①http://code.google.com/p/paoding/.
②http://ictclas.org/.
③http://democlip.blcu.edu.cn:8081/gpws/.
④http://ir.hit.edu.cn/ltp/
⑤http://incubator.apache.org/opennlp/;
⑥http://nlp.stanford.edu/software/CRF-NER.shtml.
⑦http://bbs.qzwb.com.
〔1〕Internet Forum http://en.w ikipedia.org/w iki/Internet_forum.2011-07-24.
〔2〕Zhang Zhonghui;W u Bin,Document sim ilarity measure for topic detection in BBS,FKSD 2010,2354–2357,2010
〔3〕Hila Bechker,Mor Naaman,Luis Gravano.Learning Sim ilarity Metrics for Event Identification in Social Media[C].WSDM'10,February 4-6,2010,New York City,New York,USA.
〔4〕Giridhar Kumaran,James Allan.Text classification and named entities for new event detection[C].Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval,July 25-29,2004,Sheffield,United Kingdom.
〔5〕网络论坛.http://zh.w ikipedia.org/.维基百科.2011-07-24.
〔6〕余军,陈晓鸥.命名实体识别:One-at-a-time or All-atonce?Word-based or Character-based?[C].第七届中文信息处理国际会议,2007.
〔7〕张卫.网络舆情分析中的特征提取研究[D].中国科学技术大学,2008.
〔8〕吴昊,耿焕同,吴祥.一种基于聚类分析的BBS主题发现算法研究[J].安徽师范大学学报(自然科学版),2009(1).
〔9〕Christoper D.Manning,Prabhakar Raghavan,H inrich Schütze.信息检索导论[M].北京:人民邮电出版社,2010.
〔10〕LDC,http://www.ldc.upenn.edu/DataSheets/.2011-07-24.
TP393.094
A
1673-260X(2011)11-0032-03
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
电子制作(2017年23期)2017-02-02
小雪花·成长指南(2016年11期)2016-12-07
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
振动工程学报(2014年4期)2014-03-01
中国科技术语(2012年5期)2012-03-20
小品文选刊(2009年7期)2009-05-25
