
基于人工智能方法的火电厂热工过程模型辨识
2012-12-07 01:10王守会杨耀权闫飞朝杜之正
山东电力高等专科学校学报 2012年5期
王守会 杨耀权 闫飞朝 杜之正
华北电力大学 河北 保定 071003
0 引言
传递函数是描述热工对象动态特性的一种常见模型,在控制系统设计、调试、检验及参数优化中起着重要的作用。如何根据现场操作信号直接求得热工对象传递函数一直是控制领域研究的重要课题之一[1]。获得对象传递函数模型的辨识方法很多,如阶跃响应法、频率响应法、相关分析法、最小二乘法[1-2]、极大似然估计法[3]等。 但是很多辨识算法由于对输入信号有一定的要求或算法过于复杂,一直难以在生产实际中得到推广。而系统建模或辨识又是进行系统优化控制的基本前提,因此系统辨识问题的研究显得尤为重要。
作为一种非传统的表达方式,人工智能方法可用来建立系统的输入输出模型,它们或者作为被控对象的正向或逆动力学模型,或者建立控制器的逼近模型,或者用以描述性能评价估计器。人工智能是智能机器所执行的通常与人类智能有关的智能行为,有广泛的研究和应用领域,可以把人工智能看成若干个研究子学科的组合。计算智能的提出和兴起,使人工智能发展成为一门具有比较坚实理论基础和广泛应用领域的学科。
热工过程具有多变量、非线性、慢时变特性,使得传统的辨识方法很难建立精确的热工过程模型[8]。本文将神经网络和粒子群算法两种人工智能算法引入热工对象模型辨识,并设计出了通用的热工对象模型辨识算法。这两种方法都可以归为计算智能,此外,模糊计算、遗传算法、蚁群算法、免疫计算[4-5]等也都可以归为计算智能。
1 热工过程辨识特性
确定目标函数是进行寻优的前提。热工过程模型传递函数可用下面通式表示:
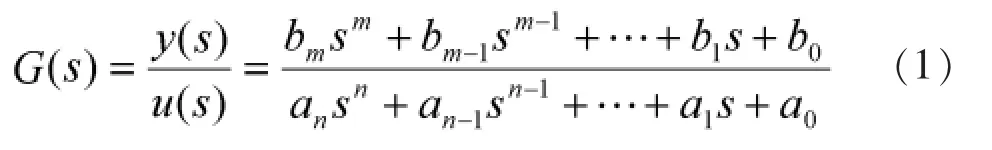
对于热工对象采用该模型时不易确定寻优区间并且a1…an的许多组合没意义,进行参数辨识时,难以获得好的效果。为此,可以结合热工过程的特性,采用如下的传递函数结构代替。
对于有自平衡的对象:
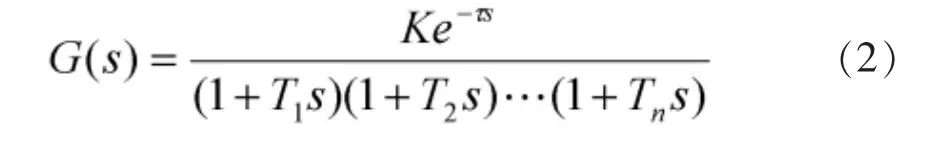
对于无自平衡的对象:
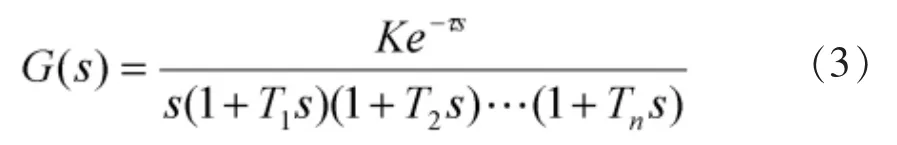
式中:K为对象静态增益,Ti(i=1,2,……,n)为过程时间常数;τ为对象的纯迟延时间,对于无纯迟延的对象τ=0。模型辨识的任务就是寻找最优参数T1、T2……Tn及τ和K,使目标函数最小的过程。 本文取模型辨识的目标函数为:

式中:y′i、yi分别为实际对象输出和模型输出。
2 人工神经网络辨识原理
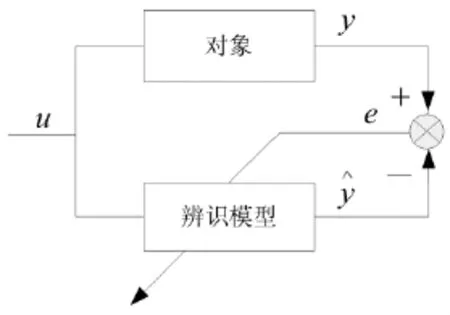
图1 系统辨识原理结构
2.1 BP网络学习算法
BP网络是一种单向传播的多层前向网络,是一种具有三层或三层以上的神经网络,包括输入层、隐含层和输出层。上下层之间实现全连接,而每层神经元之间无连接。当一对学习样本提供给网络后,神经元的激活值从输入层经各隐含层向输出层传播,在输出层的各神经元获得网络的输入响应。接下来,按照减少目标输出与实际误差的方向,从输出层经过各隐含层逐层修正各连接权值.最后回到输入层,这种算法称为“误差逆传播算法”,即BP算法。BP网络结构如图2所示:
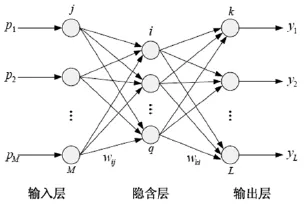
图2 BP神经网络结构
隐含层和输出层的激活函数采用对数—S型激活函数:
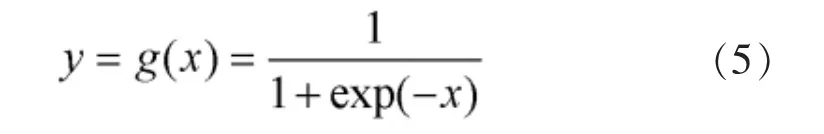
2.2 BP网络权值的附加动量调整规则
BP学习算法的基本原理是梯度最速下降法,它的中心思想是调整权值使网络总误差最小。对于每一样本的输入模式对的二次型误差函数为:
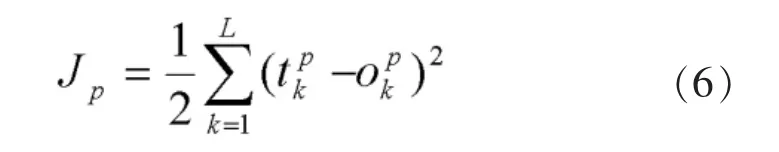
学习过程按使误差函数Jp减小最快的方向调整加权系数直到获得满意的加权系数为止。因此,权系数应按Jp函数梯度变化的反方向调整,使网络逐渐收敛。利用附加动量的作用则有可能滑过局部极小值。修正网络权值时,不仅考虑误差在梯度上的作用,而且考虑在误差曲面上变化趋势的影响,其作用如同一个低通滤波器,它允许网络忽略网络上微小变化特性。该方法是在反向传播法的基础上在每一个权值的变化上加上一项正比于前次权值变化量的值,并根据反向传播法来产生新的权值变化。
带附加动量因子的输出层神经元权系数调节公式:
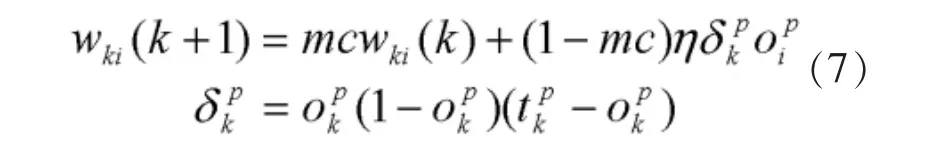
隐含层的神经元权系数调节公式:
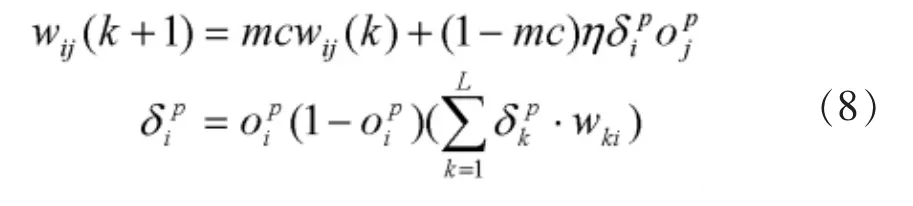
其中k为训练次数,mc为动量因子,一般取0.95左右,附加动量的实质是将最后一次权值变化的影响,通过一个动量因子来传递。
3 标准粒子群辨识算法
粒子群算法是一种基于迭代模式的优化算法,最初被用于连续空间的优化。一个由m个粒子组成的群体在D维搜索空间中以一定速度飞行,每个粒子在搜索时,考虑到了自己搜索到的历史最好点和群体内(或邻域内)其他粒子的历史最好点,在此基础上变化位置(位置也就是解)。粒子群的第i粒子是由三个D维向量组成[6],其三部分分别为:
目前位置:xi=(xi1,xi2,…,xiD);
历史最优位置:Pi=(Pi1,Pi2,…,PiD);
速度:vi=(vi1,vi2,…,viD);
这里i=1,2,…,n。 目前位置被看作描述空间点的一套坐标,在算法每一次迭代中,目前位置xi作为问题解被评价。如果目前位置好于历史最优位置Pi,那么目标位置的坐标就存在第二个向量Pi。另外,整个粒子群中迄今为止搜索到的最好位置记为:Pg=(Pg1,Pg2,…,PgD)。
对于每一个粒子,其第d维1≤d≤D根据如下等式变化
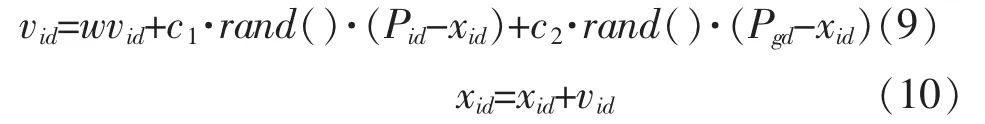
其中加速常数c1和c2是两个非负值,这两个常数使粒子具有自我总结和向群体中优秀个体学习的能力,从而向自己的历史最优点以及群体内或领域内的全局最优点靠近。 rand()是在范围[0,1]内取值的随机函数。vmax是常数,限制了速度的最大值。w为惯性权重,它决定了粒子先前速度对当前速度的影响程度,从而起到平衡算法全局搜索和局部搜索能力的作用。
4 热工过程辨识的仿真研究
4.1 BP网络用于热工过程辨识
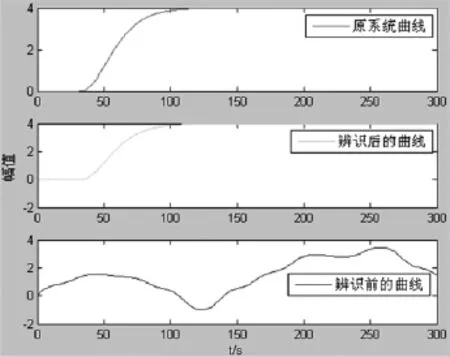
图3 BP网络闭环辨识结果
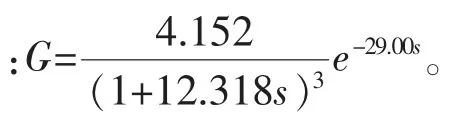
4.2 粒子群算法用于热工过程辨识
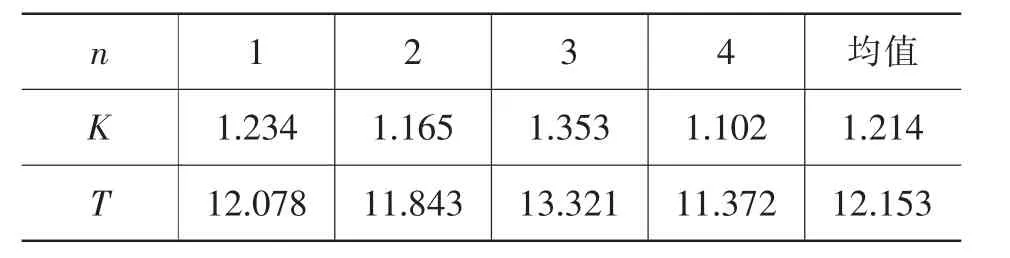
表1 阶跃输入下三阶系统的辨识结果
模型参数设定阶次Nm=3,仿真时取仿真时间为200s,过程时滞t=0,采样时间为1s,优化维数取D=3,初始化种群数目20,惯性权重w取从0.75逐渐下降到0.1,学习因子设定c1=c2=1.5。系统辨识曲线如图4所示:
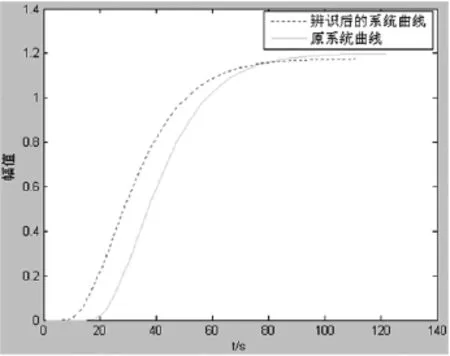
图4 粒子群算法模型辨识结果
5 结论
本文给出了BP神经网络和粒子群算法这两种人工智能方法用于火电厂热工过程系统模型辨识的设计方法及其仿真结果。神经网络辨识算法简单,辨识的收敛速度不依赖待辨识系统的维数,只与网络本身及采用学习算法有关。粒子群算法是一种并行全局随机优化算法,辨识方法速度快、精度高。对火电厂热工过程的仿真实验结果表明,两种人工智能方法都有效辨识出了模型参数,对解决火电厂中热工控制系统的辨识问题具有重要的实用价值。
[1]刘长良,于希宁等.基于遗传算法的火电厂热工过程模型辨识[J].中国电机工程学报,2003,(3):170-174.
[2]GOLUB G H,van LOAN C F.An analysis of the total least-squares problem[J].SIAM J Numer Anal, 1980,17(6):883-893.
[3]FELSENSTEIN J.Evolutionary trees from DNA sequences:amaximum likelihood approach [J].J Mol Evol,1981,17(1):368-376.
[4]吕剑虹,陈建勤等.基于模糊规则的热工过程非线性模型的研究[J].中国电机工程学报,2002,22(11):133-137.
[5]姜波,汪秉文.基于遗传算法的非线性系统模型参数估计[ J].控制理论与应用, 2000,17(1):150-152.
[6]刘建华.粒子群算法的基本理论及其改进研究(博士学位论文)[D].长沙:中南大学,2009.
[7]赵黎丽.两种人工智能方法应用于地热热泵系统辨识[J].系统仿真学报,2004,16(7):1378-1379.
[8]李岩,王东风等.采用微分进化算法和径向基函数神经网络的热工过程模型辨识[J].中国电机工程学报,2010,30(8):110-111.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
测控技术(2018年10期)2018-11-25
通信电源技术(2018年5期)2018-08-23
通信电源技术(2018年5期)2018-08-23
浙江工业大学学报(2017年5期)2018-01-22
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
通信电源技术(2016年3期)2016-03-26
自动化博览(2014年9期)2014-02-28
