
XML并发异构数据库跨库检索技术应用于区域卫生信息平台建设
2013-05-07 09:51莫智懿
科学导报·学术论坛 2013年2期
莫智懿

【关键词】XML,跨库检索,并发,异构数据库
引言
区域卫生信息平台是一个集城镇医保系统、新型农村合作医疗管理信息系统、区域内各级医疗机构HIS系统和区域疾病防控系统想结合的卫生信息平台,在该平台内。该平台内将不同类型、不同结构、不同环境、不同用法的各种异构数据库纳入统一的区域卫生信息平台,对各信息点异构数据库进行跨库检索。
一、系统设计的基本思想
区域卫生信息平台的建设使医疗服务人员在任何时间、任何地点都能及时获取必要的信息,以支持高质量的医疗服务;使公共卫生工作者能全面掌握人群健康信息,做好疾病预防、控制和健康促进工作;使居民能掌握和获取自己完整的健康资料,参与健康管理,享受持续、跨地区、跨机构的医疗卫生服务;使卫生管理者能动态掌握卫生服务资源和利用信息,实现科学管理和决策,从而达到有效地控制医疗费用的不合理增长、减少医疗差错、提高医疗与服务质量的目的。通过区域卫生信息平台,将分散在不同机构的以人为核心的健康数据整合为一个逻辑完整的信息整体,满足与其相关的各种机构和人员需要。这是一种全新的卫生信息化建设模式。
建立这样一个区域卫生平台,需要对建立一种跨系统、跨数据库的数据检索技术,从而使各医疗卫生信息点数据能集成于区域卫生平台,同时也方便各医疗卫生信息点查询相关数据,实现对不同数据库的检索的关键是建立一种通用的开放的数据库中间件来屏蔽各系统数据库之间的异构差异。为了使得区域卫生信息平台具有良好的扩展性,能在该平台中任意增加信息采集点,本文所研究的一种基于XML技术的数据库中间件用于区域卫生信息平台对连接平台的各信息点进行信息采集。这种基于XML技术的数据库中间件不仅多种异构数据库,同时提供一个开放透明的数据环境,当增加信息点时,只需要通过简单配置中间件就能将信息点加入区域卫生平台。
构建一个数据库中间件,区域卫生信息平台统计数据时将检索命令拆分到各信息点的检索表达式中,利用命令检索表达的方式进入各自信息点,再把检索到的结果用XML数据格式取回,在设计过程中采用双线程技术,一个线程负责向各数据信息点分发检索命令,分发完成后即撤销,一个线程负责监听返回结果,结果返回完成后负责整装XML文件,对其数据进行去重和排序。这种设计思想在执行检索过程中两个线程异步执行,可大幅提高检索速度。
二、系统模型分析和设计
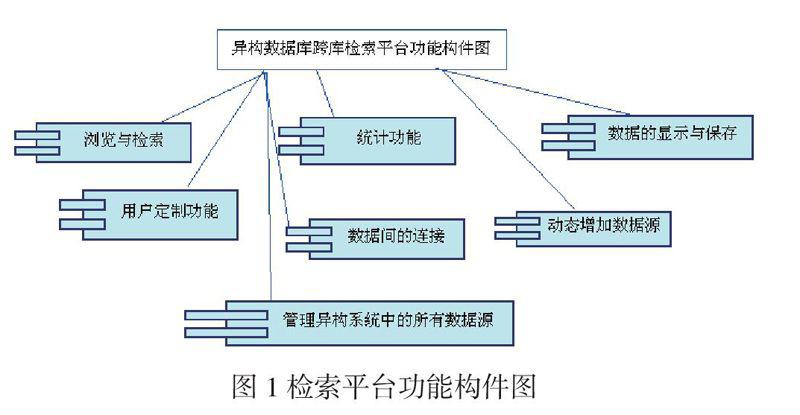
在区域卫生信息平台中,信息检索较为广泛,以病患信息为基础的各相关信息,如各医院系统中的入院相关信息,检查相关信息,农合系统中的补偿相关信息,健康档案系统中的相关信息。跨库检索技术不等同于搜索引擎,跨库检索主要是检索各大异构数据库的整体信息资源,帮助用户定位资源,并且通过知识元的搜索得到用户想要的信息,在区域卫生信息平台中异构数据库跨库检索系统应该具有以下的功能:
(1)浏览与检索
系统应提供主题树等索引系统,帮助用户以浏览的方式选取合适的检索词进行查询。检索应包括简单和高级检索,简单检索应包括自然语言、短语检索及布尔算符、位置算符、截词符和通配符等检索。高级检索应提供多字段检索和多种限制选项。同时,系统还应提供检索策略的保存及定题跟踪服务,以方便用户再次检索。
(2)数据间的连接
系统应兼容CrossRef、OpenURL、SFX等数据库无缝链接技术或标准,使不同数据库之间的各种记录能互相链接,包括书目数据库、文摘数据库、全文数据库中各种数据之间的互连。
(3)数据的显示与保存
系统应对来源于不同数据库的结果进行融合,检索结果输出应具备排序功能,如按病患姓名、就诊时间、疾病代码、检查诊断排序。检索记录应可以打印、下载、Email发送。最好能兼容各种Citation Manager软件,如Reference Manager、Endnote、Refworks等。
(4)动态增加数据源
系统能做到一定的扩展性,能够随时增加一个数据源,无论数据源是本地服务器的还是远程服务器的,而且能够做到对数据源的管理。
(5)管理异构系统中的所有数据源
对于本机上的全部异构数据源,能做到管理它的信息,如果某一数据源发生改变的变化,该检索平台能够迅速地修改数据源使得能够继续访问而不至于瘫痪。能随时删除数据源,从而达到维护检索系统的目的。
(6)数据安全权限管理
医疗数据是一种涉及到病患隐私的数据集,在区域卫生信息平台中对各用户实行严格的权限控制,检索结果一般只定义数据来源列表,详细信息需经患者本人同意和相关医疗机构允许才能调用。
具体的系统功能构件图如图1所示。
三、系统流程
检索系统主要流程可以分为:收集查询数据、处理查询数据、分发查询数据、处理结果数据、显示结构数据。
检索系统具体的流程可以分为以下几步:
1.客户从地址栏访问检索主页面,到达查询页面之后填写检索的关键字。
2.系统内部将会获取用户的数据,如果没有获取成功就重新获取一次,直到获取成功为止。
3.获取数据之后就会整理好数据,整理完毕。
4.此时的数据将会分组,分组的内容是根据数据库来分组的,如果用户想要查询的数据库是5个数据库,那么就会分成5组数据,然后是查询本地数据库与这5个数据库各自相关的信息,其中包括数据库的连接信息、数据库的表的信息、查询字段等信息。
5.查询完毕之后就会利用消息队列向每一个服务器发送查询请求。
6.远程数据库收到查询请求会返回查询结果。
7.本地服务器得到远程数据库的查询结果,做相应的处理(经过本地数据的核对,加入到XML文档)。
8.查询完毕之后,本地服务器从磁盘中取出所有的数据生成XML文档。
9.针对XML文档进行再次去重、排序、分页显示、显示结果。
系统流程详细图如图2所示。
用户登录检索系统的检索页面之后,用户填入检索的关键字以及勾选查询的数据库之后,系统得到用户数据的信息,系统后台此时会建立两个线程,第一个线程的任务是分发检索语句,而不管接受数据,接受数据会交给第二个线程做,两个线程是异步执行的,这样就打破了传统查询常规,提高系统性能。第二个线程主要建立监听程序,会循环检查数据库是否有发回结果文件的请求,有请求就会接收数据库结果文件,没有请求就会一直循环等待,当多个数据库在同一时刻向本系统返回结果,此时会接收结果文件会建立队列接收,第一个先接收结果文件,第二个处于阻塞状态,第一个接收完毕之后会激活第二个接收,然后第三个会处于阻塞状态,一直循环下去直到接收完毕。从分发查询语句起,3秒之后会整合数据库返回的所有XML文件,对于3秒之后返回的结果文件就不在接收(检索时间定义可根据具体网络和各节点硬件环境自定义),整合完毕所有文件之后把再次对结果文件进行查询分页,显示第一页的内容,最后返回第一页的结果文件。
四、结束语
本文设计了一个基于XML的跨库检索系统模型,应用于梧州市区域卫生信息平台中,成功的连接了市内各级定点医疗机构HIS系统,梧州市医保系统和各县市区新型农村合作医疗系统及自身设计的梧州市健康档案管理信息系统。实现了各信息系统的互联互通,在任意系统节点可检索其他业务系统的相关信息,虽然各信息节点的医疗数据已实现信息化管理,但由于涉及到医疗数据的保密性,系统之间检索结果调阅还需要人工审核和人工调取。但是,使用XML技术的区域卫生信息平台初步解决了医疗信息孤岛问题。
