
Twitter中重复消息的分析和处理
2014-09-12 11:17徐凯沙瀛李阳单既喜王晓岩
计算机工程与应用 2014年21期
徐凯,沙瀛,李阳,单既喜,王晓岩
1.江西农业大学计算机与信息工程学院,南昌 330045
2.中国科学院信息工程研究所,北京 100093
3.中国科学院计算技术研究所,北京 100190
Twitter中重复消息的分析和处理
徐凯1,2,沙瀛2,李阳3,单既喜2,王晓岩2
1.江西农业大学计算机与信息工程学院,南昌 330045
2.中国科学院信息工程研究所,北京 100093
3.中国科学院计算技术研究所,北京 100190
Twitter已经成为微博中的代表性应用,但是通过分析发现twitter上的消息(推文)有很多完全一致或相似,这对后续对推文的分析和存储都带来很大的问题。为了处理这些内容完全一致或相似的消息(推文),针对推文特有的短文本的特点,基于规则处理完全一致的推文,采用simhash的方法来处理相似性的推文。实验采用实际抓取的240万条推文数据进行分析和处理,分别对中文和英文的推文重复情况进行了分析,实验结果发现重复的推文占总推文的10%左右。
推特;微博;Simhash;短文本去重
1 概述
在WEB 2.0的时代里,用户之间的交互变得非常广泛,任何时间,任何地点的用户之间都可以进行通信。微博把WEB 2.0时代推向了一个更加快捷,更加开放的时代;微博的传播速度非常快,用户之间可以互相关注,微博的信息非常短,每条微博的信息不允许超过140个字。
Twitter[1](http://www.twitter.com)是微博中最具有代表性的平台之一。一条消息的发布,在twitter里面被称为一条推文,在twitter上,用户不仅可以发布推文,用户之间还可以互相关注,如果你被别人关注了,那么这些关注你的人就叫做你的跟随者,如果你发布一条推文,那么你的跟随者可以在他们自己的twitter主页面看到你的推文,并对他们感兴趣的推文进行回复;反之,如果你关注了别人,那么他们发布的推文你同样可以在自己的twitter主页面看到,你同样可以对自己感兴趣的推文进行回复。
Twitter中用户除了可以对自己感兴趣的推文进行回复,还可以对该推文进行转发[2],也就是说一条相同的推文被其他感兴趣的用户重新发布一次;这个过程好比一棵树的数据结构,从根节点一直向后发展,最终推文所描述的事情变成了热点,有的时候一条推文可以在几分钟内被转发几百万次。
如此多的转发可以让一件事迅速变成热点;但造成了大量重复的消息,不仅给系统带来了沉重的负担,而且给推文的阅读者带来了一定的麻烦,浪费了大量时间。
为此,本文提出一种方法来处理这些大量重复相似的推文,twitter中重复相似的推文一般有两种形式,一种是官方的转发方式,另一种是非官方的转发方式。
官方转发方式的推文可以快速转发别人的推文,但是不允许用户修改推文的内容。
非官方的转发方式是用户自己定义了一些好用的,被大多数人认可的转发格式,通过使用这些转发格式,转发者可以复制感兴趣的别人的推文,经过一些小小的修改然后发布出去,正是因为这些小小的修改,使得这些推文和原始作者的推文产生了不同,但其实这些推文所表达的意思都是一样的。
实验过程如下:
(1)分析数据,总结出官方和非官方的转发格式。
(2)建立官方格式的正则表达式,提取出官方格式转发的推文,通过字符串比较的方法得出相同的推文。
(3)建立非官方格式的正则表达式,对推文进行预处理,然后通过基于simhash[3-5]的方法来得出每条推文的指纹,比较这些指纹的海明距离来得出推文的相似性。
本文对抓取的240万条推文数据进行实验,本文中仅对中文和英文的推文进行实验,经过实验处理,其中中文的推文46万条,英文的推文170万条。发现重复相似的推文占总推文的10%左右。
2 基本概念及相关工作
判断推文是否相同的最简单的办法是,对推文进行两两比较,对两条推文每个字符进行逐个比较,如果全部的字符都相同的话那么这两条推文就是相同的,但是这个办法只能判断完全相同的推文;正如前面所说的,twitter中很多的用户使用的并不是官方的转发功能,这导致被转发的推文可能是用户经过复制和修改后的推文,这种推文和原创推文相似,但是不相同。
需要判断文本相似的算法,判断文本相似的算法有很多,如,Bloom Filter[6]去重算法,shingling去重算法[7-8],曹鹏等[9]在他们的论文中介绍了通过统计字符类型算法和最短编辑距离算法[10]相结合的方法来解决文本之间的相似性,首先通过统计字符类型算法,把每条消息转换成一个向量,然后通过余弦定律[11]计算两个向量之间的距离,得出消息(推文)之间的距离,为了确保结果的精确性,提出再计算一次消息的最短编辑距离,最后把两个算法得到的距离相加,得到两个消息(推文)的距离,设置一个阀值,如果最终距离小于这个阀值,那么消息(推文)相似。
文本相似度比较还有一种方法,即Simhash,Simhash是google专门为它的搜索引擎发明的文本相似度计算方法,google每天需要抓取处理的文档是上百亿的,这些新抓取的文档中很多都是和以前存储在数据库中的相同或者相似的,为了准确高效地对重复的文档进行去重操作,这就是Simhash。
Simhash的主要思想是:降低文本向量的维度,将高维度的文本向量的维度降低到一个m(本文中m取64)位的一个整数中,这个整数称为指纹,每个指纹代表一个文档,最后计算两个文档的相似度就是计算它们对应的指纹相似度,指纹之间的差异位个数称为海明距离。
Simhash的好处在于它高效的处理速度,由于Simhash对哈希函数的要求比较高(哈希函数的碰撞率越低,Simhash的准确度越高),本文中引入google的哈希函数cityhash(http://code.google.com/p/cityhash/),该哈希函数能快速生成一个64位的签名。
3 推文去重
3.1 Twitter消息的官方转发格式
如表1所示为twitter官方推文的转发格式,Retweeted by表示转发符号,编号1中,Retweeted by jasongod之前的是推文的内容,jasongod表示转发这条推文人的名字,一般Retweeted by跟随在推文的末尾,如果还有其他人转发了这条推文,如编号2中的推文,该推文首先被用户renyuan619转发,然后又被用户cwxm37转发,被转发了2次。

表1 官方转发格式
3.2 Twitter消息的非官方转发格式
Twitter中除了有官方的转发格式还有非官方的转发格式,这些非官方转发格式被大多数用户所认可,经过研究分析发现以下这些常用的非官方推文转发符号,如表2所示。
3.3 twitter中推文的预处理
原始的推文中包含很多额外的特殊符号,这些特殊符号有些表示转发某人的推文,有些表示回复某人的推文,或者自己发的推文。例如表3中的推文,这些推文没有经过预处理。

表2 非官方转发格式
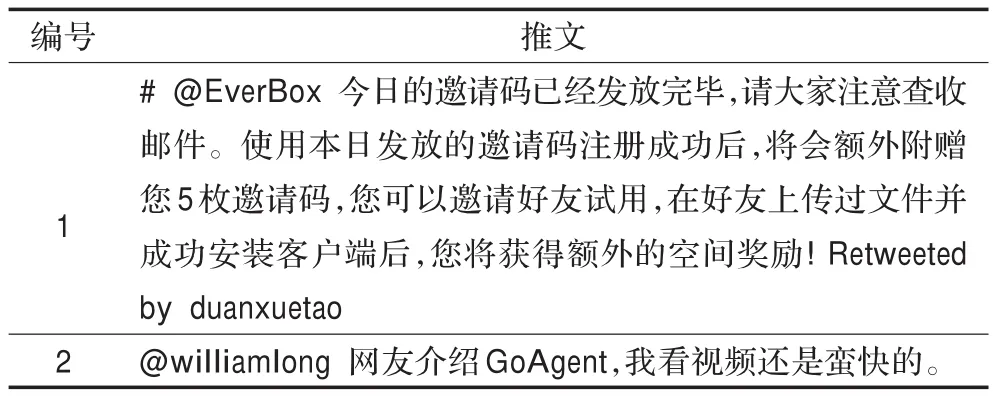
表3 未经预处理的推文
编号1的推文中有转发符号RT@zhangweiguo:,RT@uponsnow和Retweeted by lyfwww需要去掉。
编号2推文中的特殊符号@williamlong有可能是自己发送的推文,也有可能是回复别人的话,无论是哪种,需要把它去掉。
这些特殊符号,可以通过构建不同的正则表达式把它们去掉,如表4里面的正则表达式,去掉后推文如表5所示,算法如下:
(1)构造指定以上这些转发符号格式的字符串正则表达式,为了提高准确率,把@用户名这种正则表达式所表示的字符串也考虑进去。
(2)按照表1中编号1中表格格式对应的正则表达式的顺序循环匹配推文,如果匹配成功那么删除推文中匹配好的正则表达式对应的字符串,保存推文,匹配下一个正则表达式,直到匹配完表格中最后一个正则表达式为止。
(3)下一条推文继续表1中编号2中的处理过程,直到所有的推文处理完成。

表4 转发格式的正则表达式
3.4 消息去重的方法
在设计simhash算法过程中,simhash需要文档的特征集合,特征集合包括能代表该文档意思的词组集合和集合中每个词的权重,为了得到词组集合,使用中科院的分词系统ictclass(http://ictclass.org/),考虑到推文的短文本特点,把分词后的所有词都作为特征词,并对词组进行去重操作,给每个词分配权重1,例如如下两条推文:

表5 预处理后的推文
推文1:毛主席伟大、伟大,伟大。
推文2:毛主席伟大。
假设为推文1中的毛主席分配1的权重,伟大分配3的权重,那么毛主席在推文1中权重比率是1/4;推文2中的权重比率是1/2,这样就造成simhash后的两个推文的指纹偏差较大,但实际上推文1和推文2表达的意思是一样的,综上考虑把推文中每个词的权重设置为1。
由于推文通常较短,每个词都表示了重要的信息,且彼此之间没有较明显的差异性,因此选择每个词的权重为1,即每个词的贡献都是一样的。
之后使用cityhash函数分别计算每个词的签名(64位的无符号整数),cityhash由google提出是一种非加密性质的哈希算法,主要面向生成唯一的指纹,该算法源自于murmurhash(https://sites.google.com/site/murmurhash/)算法的改进,64位的cityhash算法不但减少了碰撞率,而且在64位的CPU上进行了优化,在字符串的移位操作过程中,综合了字符串的长度因素,函数接口格式如下所示:
uint64 CityHash64(const char*buf,size_t len);
接收2个参数,第一个参数表示需要计算指纹的字符串内容,第二个参数表示该字符串的长度,函数接口返回值是64位的无符号整数签名。
得到每个推文的指纹之后,就可以进行求海明距离,海明距离[12]定义是:两个长度相等字符串的海明距离是在相同位置上不同字符的个数,也就是将一个字符串替换成另一个字符串需要的替换的次数。在这里把64位整数的指纹的二进制形式来表示这个字符串。假设指纹是64位的整数,那么两个64位整数之间的海明距离就是不同的二进制位的个数。
不同位的个数越多,认为两个推文之间越不相似,实验中设置海明距离为3,这个阀值来区分相似的推文和不相似的推文,当计算出来的指纹海明距离大于3认为这两条推文是不相似的,当计算出来的指纹海明距离小于等于3,认为推文之间是相似的。
选择3的原因:实验中针对234个simhash指纹,分别设置阀值为1到10,对于每个阀值,从234个指纹中随机取样选取一定对数的相似的推文,然后进行人工标示,如果这两条推文真的相似,那么标记1,如果不相似,那么标记0,这样就统计出阀值从1到10这个区间中,真正相似推文的比率,结果发现当阀值在3的时候推文的相似性正确率是最大的。

表6 两条推文
例如:表6中两条推文经过处理后相似。
Simhash去重如图1所示。
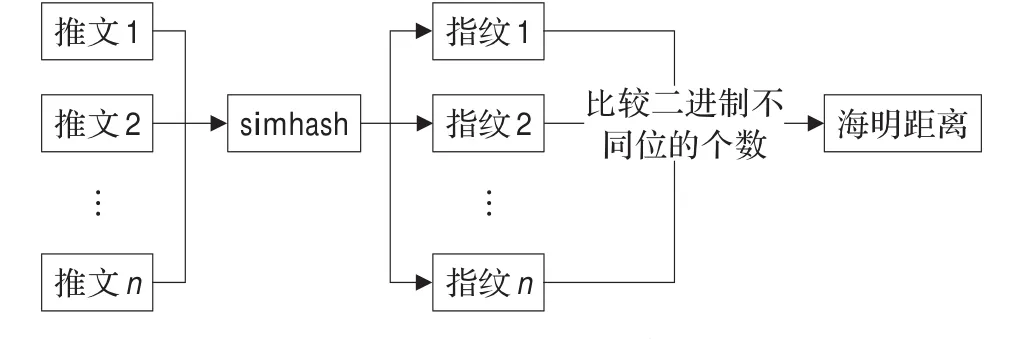
图1 simhash去重
4 去重及其分析和实验数据
本实验中使用2012/7/1到2012/8/1日这一个月采集的大概240万条的推文,推文的内容主要涉及政治和军事,实验中中文推文占总推文比率的19%,英文推文占总推文比率的53%,其他语言的推文占总推文比率的28%,可见英文推文的比率是最大的。下面就这些推文展示实验结果。
4.1 统计推文语言分布
分析各种语言在推文中的比例。实验中过滤推文,只保留英文和中文的推文。英文推文占总推文的比率是最大的。
4.2 推文长度分布统计
分别统计英文推文和中文推文的长度分布。
图2是英文推文长度分布图和中文推文长度分布图,从图中可以看出推文长度在140的推文的个数是最多的。
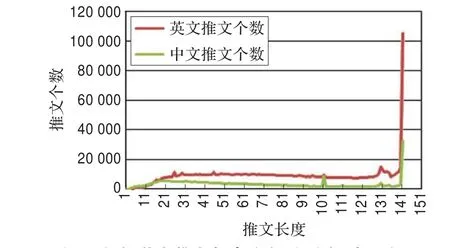
图2 中文/英文推文长度分布图(未经过预处理)
4.3 预处理后推文长度的分布
分别统计预处理前后中英文推文的长度并比较其变化。
经过推文预处理操作后,重新统计消息的个数随长度的分布,从图3~5中可以发现以下几点:
(1)预处理后推文长度在0~20区间的推文数量有所增加,说明推文长度在0~20区间的推文很多被转发过,短推文转发很多。
(2)推文长度在140个字符的推文在预处理后大量减少,说明这些推文中大部分具备转发格式,长推文也很多被转发。
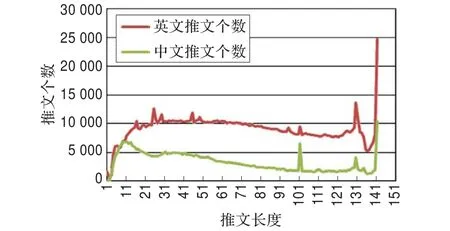
图3 中文/英文推文长度分布图(预处理后)
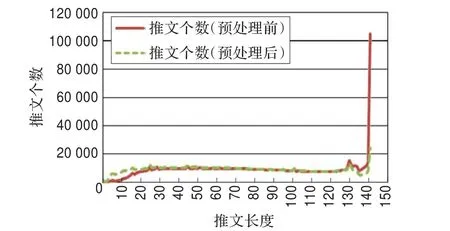
图4 预处理前和预处理后的英文推文长度分布图
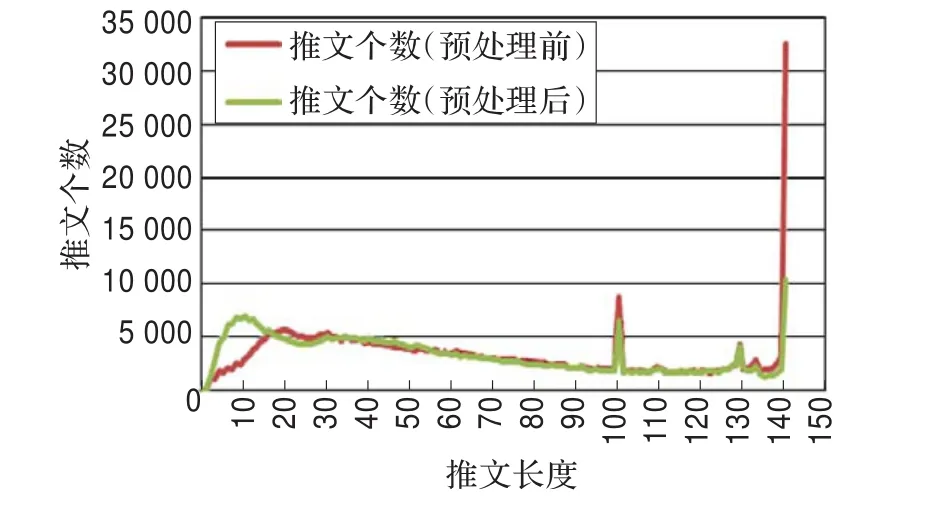
图5 预处理前和预处理后的中文推文长度分布图
4.4 推文去重
分别统计中英文推文的去重比率和重复推文的重复次数分布。
经过分析统计英文推文中相似的推文占英文推文总个数的9%,中文推文中相似的推文占中文推文总个数的7%,可见推文中消息的重复比率还是很大的。

图6 英文推文重复次数对数分布图

图7 中文推文重复次数分布图
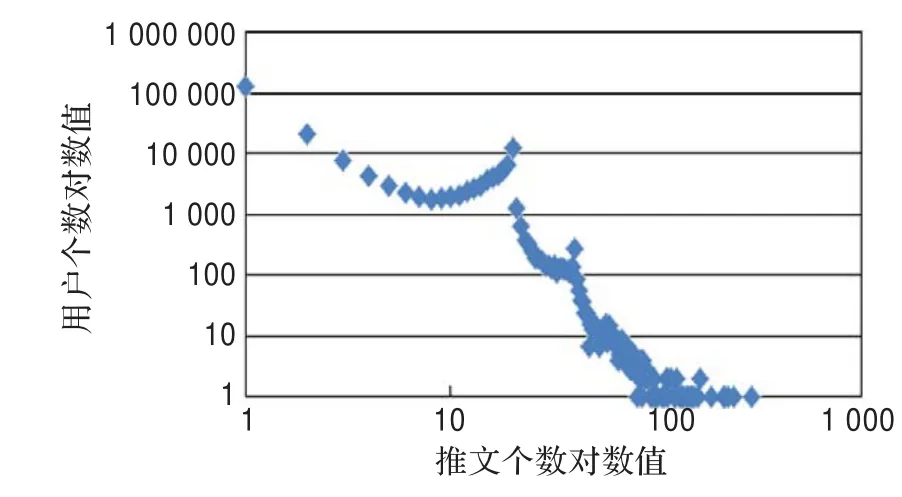
图8 英文用户推文个数统计对数分布图
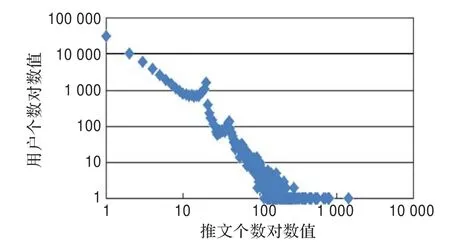
图9 中文用户推文个数统计对数分布图
如图6和图7所示,统计那些重复推文的重复次数,从图中可以看出,当重复次数为1的时候,推文数量是最多的,随着重复次数的增加,推文的个数迅速减少,可见大多数推文不是热点推文。
4.5 用户发送消息
分别统计中英文推文的用户个数和推文个数的分布。
从图8和图9中可以看出,只发送了一条推文的用户是最多的,其次集中在发送20条推文的用户也是挺多的,之后发送了100条以上的用户非常少,可见twitter中活跃的用户还是集中在少数用户中,大部分用户还是不活跃的。
5 结论
本文提出针对twitter平台的消息去重方法,不但可以减轻twitter平台存储消息的压力,而且给分析twitter消息带来了方便;对推文的分析分两种情况,转发关系和相似。对转发关系采用预处理检测关键字retweeted的方法,对相似关系采用预处理后simhash的方法。通过实验证明,simhash能有效处理类似于twitter平台上的短消息之间的相似度,实验中对采集的240万条推文数据进行过滤,分析中文和英文的推文,分别对中文和英文的推文长度分布、推文去重率、用户发送的推文个数进行统计。
[1]Stone B,Williams E.Chirp:Twitter’s developer conference [EB/OL].[2010-04-14].http://chirp.twitter.com/.
[2]Boyd D,Golder S,Lotan G.Tweet,tweet,retweet:conversational aspects of retweeting on Twitter[C]//Proceedings of the 43rd Hawaii International Conference on System Sciences,2010:1-10.
[3]Manku G S,Jain A,Sarma A D.Detecting near-duplicates for web crawling[C]//Proceedings of the 16th International World Wide Web Conference,Banff,Alberta,Canada,2007.
[4]Charikar M S.Similarity estimation techniques from rounding algorithms[C]//Proceedings of 34th Annual ACM Symposium on Theory of Computing,2002:380-388.
[5]Jiang Qixia,Sun Maosong.Semi-supervised SimHash for efficient document similarity search[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics,2011:93-101.
[6]徐娜,刘四维,汪翔,等.基于Bloom Filter的网页去重算法[J].微型电脑应用,2011,27(3):48-51.
[7]Broder A Z,Glassman S C,Manasse M S,et al.Syntactic clustering of the Web[J].Computer Networks and ISDN Systems,1997,29(8/13):1157-1166.
[8]马成前,毛许光.网页查重算法Shingling和Simhash研究[J].计算机与数字工程,2009,37(1):15-17.
[9]曹鹏,李静远,满彤,等.Twitter中近似重复消息的判定方法研究[J].中文信息学报,2011,25(1):20-27.
[10]Konstantinidis S.Computing the edit distance of a regular language[J].Information and Computation,2007,205(9):1307-1316.
[11]张振亚,王进,程红梅,等.基于余弦相似度的文本空间索引方法研究[J].计算机科学,2005,32(9):160-163.
[12]李彬,汪天飞,刘才铭,等.基于相对Hamming距离的Web聚类算法[J].计算机应用,2011,31(5):1387-1390.
XU Kai1,2,SHAYing2,LI Yang3,SHAN Jixi2,WANG Xiaoyan2
1.School of Computer and Information Engineering,Jiangxi Agricultural University,Nanchang 330045,China
2.Institute of Information Engineering,Chinese Academy of Sciences,Beijing 100093,China
3.Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China
Twitter has become the representative applications of the micro-blog.By analysis on twitter a lot of messages(tweets)are the same or similar.Those messages bring up a trouble on the analysis and message storage,so it is needed to remove those messages which are the same or similar.According to the characteristics of short text on tweets,this paper proposes the following approach.It processes the same tweets based on the specific format,then uses the simhash to process the similar tweets.It uses 240 million tweets crawled on the Internet to experiment.In the experiment it only processes Chinese and English tweets.The repetition messages(tweets)is 10 percent of all the Chinese and English tweets.
twitter;microblog;Simhash;short text duplicate removal
A
TP391.1
10.3778/j.issn.1002-8331.1212-0115
XU Kai,SHAYing,LI Yang,et al.Twitter repeat messages analysis and processing.Computer Engineering and Applications,2014,50(21):111-115.
国家自然科学基金(No.61070184);中国科学院战略性科技先导专项(No.XDA06030200);国家科技支撑计划(No.2012BAH46B03)。
徐凯(1989—),男,研究生,研究方向:社交网络数据采集和传播路径分析;沙瀛(1973—),男,博士,副研究员,研究方向:P2P网络,网络安全,自然语言处理,舆论分析;单既喜(1989—),男,研究生,研究方向:社交网络关系图;王晓岩(1989—),女,研究生,研究方向:信息安全,社交网络。E-mail:331633025@qq.com
2012-12-10
2013-03-11
1002-8331(2014)21-0111-05
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
文萃报·周五版(2019年46期)2019-09-10
小学生学习指导(低年级)(2018年9期)2018-09-26
环球时报(2018-01-26)2018-01-26
自动化学报(2016年8期)2016-04-16
青少年科技博览(中学版)(2015年7期)2015-08-12
