
天津地区雾霾的成因及预测模型建立的研究
2014-09-17 06:28
天津职业院校联合学报 2014年8期
(天津海运职业学院,天津 300350)
2013年,“雾霾”成为年度关键词. 这一年的1月,4次雾霾过程笼罩30个省(区、市),在北京,仅有5天不是雾霾天. 有报告显示,中国最大的500个城市中,只有不到1%的城市达到世界卫生组织推荐的空气质量标准,与此同时,世界上污染最严重的10个城市有7个在中国. 2014年1月4日,国家减灾办、民政部首次将危害健康的雾霾天气纳入2013年自然灾情进行通报.
雾霾天气主要由氮氧化合物、二氧化硫和粉尘等造成,由于我国冬季冷空气活动常年偏弱,冬季溶胶背景浓度高,城市高层建筑的增多导致的静风现象和逆温层的存在,使雾霾的主要成分细小粉尘不易消散,进而加重了雾霾天气的影响. 雾霾之害表面看是一种环境生态现象,实质与经济社会的严重失衡高度相关.
天津是雾霾的多发区和重灾区,为有效的控制雾霾的形成,有必要对研究该地区雾霾的形成原因做出分析. 本文根据天津实际的空气质量污染指数作为参考,以建筑尘与扬尘、化工厂的排放、煤的燃烧、汽车尾气排放、化石燃料的燃烧数据作为依据利用灰色关联度模型辅以excel表格进行了关联度分析,指出与雾霾关系影响关系最大的因素. 并构建基于灰色预测GM(1-1)、BP神经网络组合预测模型,对模型进行检验后,确定最终预测方程.
一、天津地区雾霾形成的主要因素
(一)数据的来源
本文主要通过互联网,在中国统计年鉴上查找天津2013年11月、2013年12月、2014年1月、2014年2月、2014年3月、2014年4月时间段内的PM2.5、PM10、CO、NO2、SO2数据.
(二)问题的分析
主要分析AQI指数与其他因素之间的关系并建立相应的数学模型,同时指出与“空气质量指数(AQI)”关系最大的因素.
灰色系统理论提出了对各子系统进行灰色关联度分析的概念,意图透过一定的方法,去寻求系统中各子系统(或因素)之间的数值关系. 因此,灰色关联度分析对于一个系统发展变化态势提供了量化的度量,非常适合动态历程分析.
(三)雾霾成因模型的建立
1.灰色系统关联分析的具体计算步骤如下:
(1)确定反映系统行为特征的参考数列和影响系统行为的比较数列
反映系统行为特征的数据序列,称为参考数列. 影响系统行为的因素组成的数据序列,称比较数列.
(2)对参考数列和比较数列进行无量纲化处理
由于系统中各因素的物理意义不同,导致数据的量纲也不一定相同,不便于比较,或在比较时难以得到正确的结论. 因此在进行灰色关联度分析时,一般都要进行无量纲化的数据处理.
(3)求参考数列与比较数列的灰色关联系数ξ(Xi)
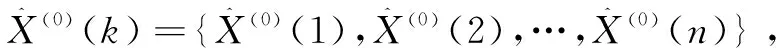
所以关联系数ξ(Xi)也可简化如下列公式:
(4)求关联度ri
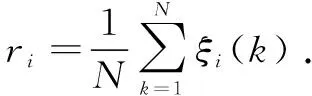
(5)关联度排序
因素间的关联程度,主要是用关联度的大小次序描述,而不仅是关联度的大小. 将m个子序列对同一母序列的关联度按大小顺序排列起来,便组成了关联序,记为xi,它反映了对于母序列来说各子序列的“优劣”关系. 若r0i>r0j,则称xi对于同一母序列x0优于xi,记为xi>xj.
2.模型的求解与结果分析
利用Matlab编程得到下列所需的相关数据,下图为解题步骤.
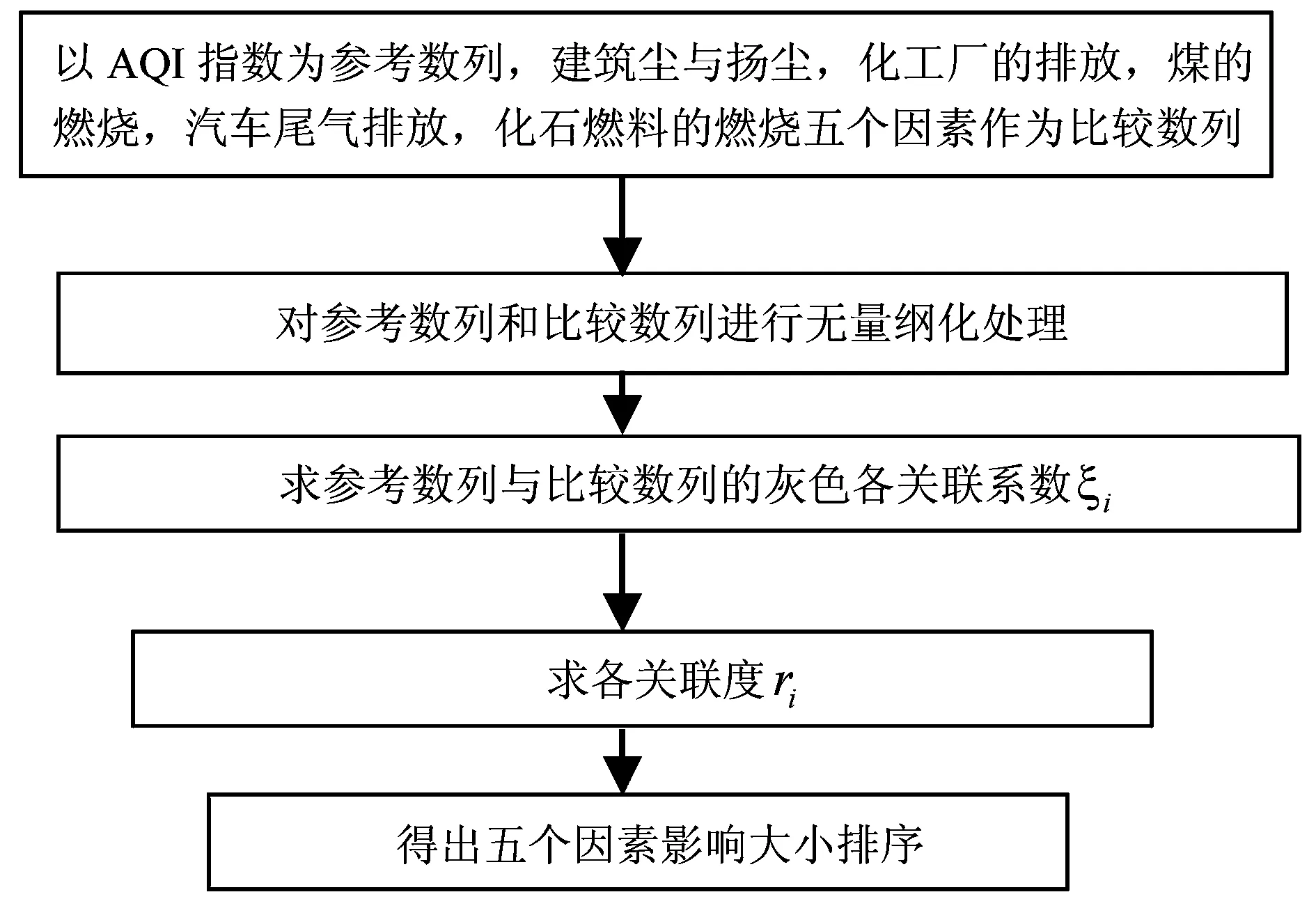
从而可以计算出关联度ri排序

PM10PM2.5SO2NO2CO0.72230.66230.60410.55110.3563
由关联度分析可得影响空气污染指数的最重要原因是PM10,即化工厂的污染废弃大量排放是雾霾天气形成的重要原因.
二、雾霾的预测模型
(一)问题的分析
由数据显示可知,雾霾天气变化大,且无迹可寻,随机性很强,因此建立灰色预测和BP神经网络组合模型,对模型进行了检验,提高预测的准确度.
(二)灰色预测模型的构建
运用2013年11月到2014年4月的数据进行模型拟合,构造累加生成序列、数据矩阵和数据向量. 运用GM(1,1)预测方法对雾霾天气的大致趋势进行初步预测.
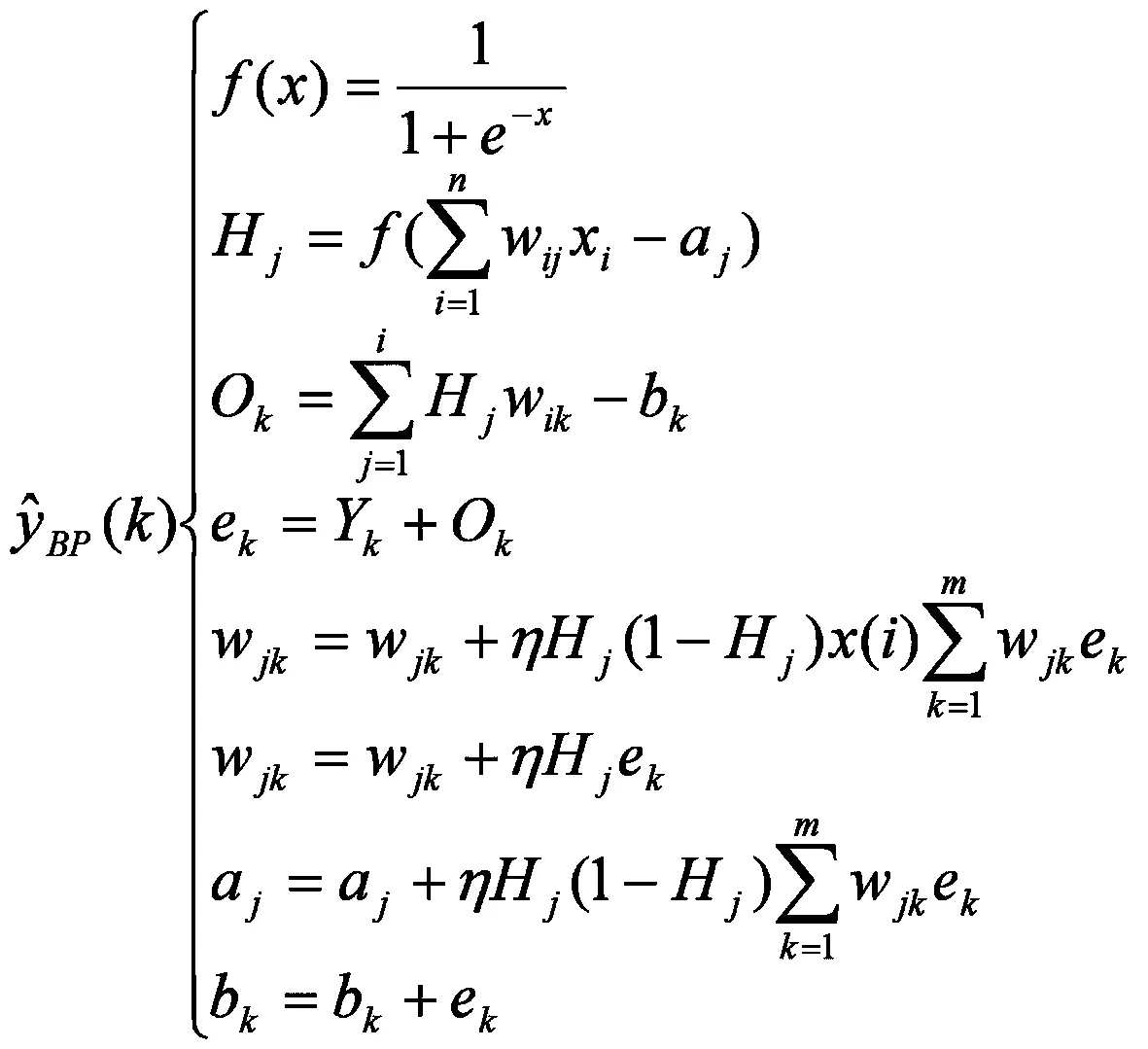
(三) BP神经网络构建
采用2013年11月到2014年4月的AQI指数数据,构建函数预测函数,将上述数据进行反归一化后,可以得到模型预测的实际结果值,预测出2014年5月1日到5月7日的数据,将其与实际值进行比较.
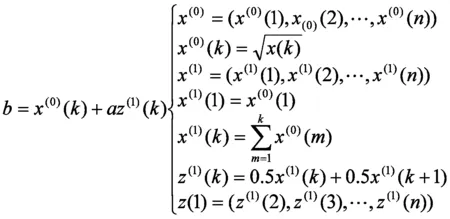
(四)数据预处理
在构建神经网络以及灰色预测前一般需要对数据进行预处理,一种重要的预处理手段是归一化处理.
1.数据归一化
数据归一化,就是将数据映射到[0,1]或[-1,1]区间或更小的区间,比如(0.1,0.9).
2.归一化原因
(1)输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间较长;
(2)数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小;
(3)由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域;
(4)S形激活函数在(0,1)区间以外区域很平缓,区分度太小.
3.归一化算法
一种简单而快速的归一化算法是线性转换算法,
y=(x-min)/(max-min),
其中,为某变量的指标的最小值,为某变量的指标的最大值,某变量的实际指标为x,归一化后的输出向量为y. 另一种归一化算法为,
y=2*(x-min)/(max-min)-1,
这条公式将数据归一化到 [ -1 , 1 ] 区间. 当激活函数采用双极S形函数(值域为(-1,1))时这条式子适用.
三、模型的求解与结果分析
分别用灰色预测,BP神经网络对AQI值进行预测.
(一)GM(1,1)灰色预测模型求解
取2014年4月份的后15个数据进行数据处理,运用MATLAB编程处理生成GM(1,1)灰色预测方程,带入数值求解出预测值,如下图,
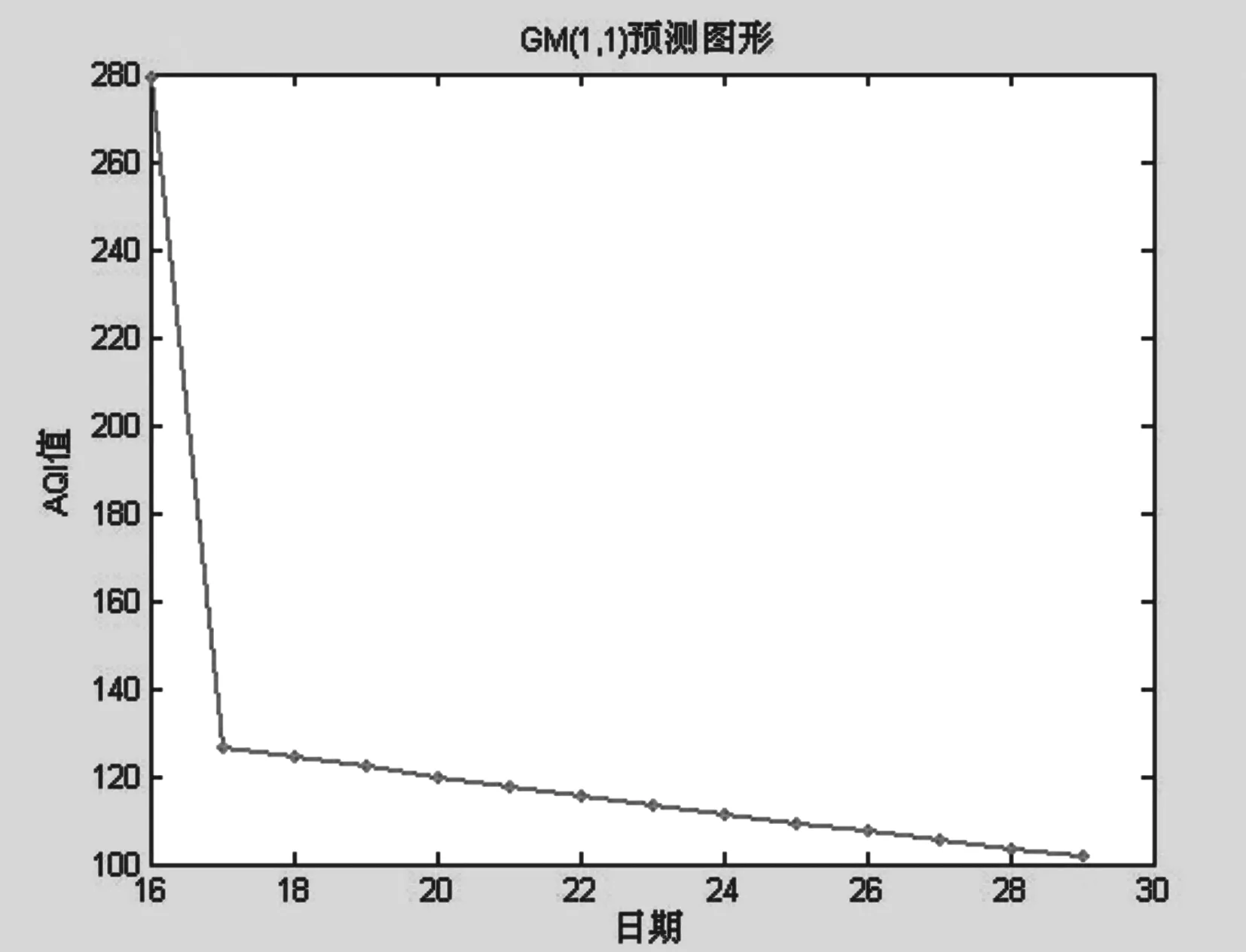
GM(1-1)预测值图
(二)BP神经网络预测模型求解
步骤为:1.读取训练数据;2.数值归一化处理;3.构造输出矩阵;4.创建神经网络;5.设置训练参数;6.开始训练;7.测试数据合理性验证正确率。
取最近半年的AQI指数作为原始数据,取原始数据的后30个作为训练数据,通过MATLAB编程实现预测求解,并且通过所有预测值与实测值进行比较,并且列出神经网络预测误差百分比,和神经网络误差图。各图如下:
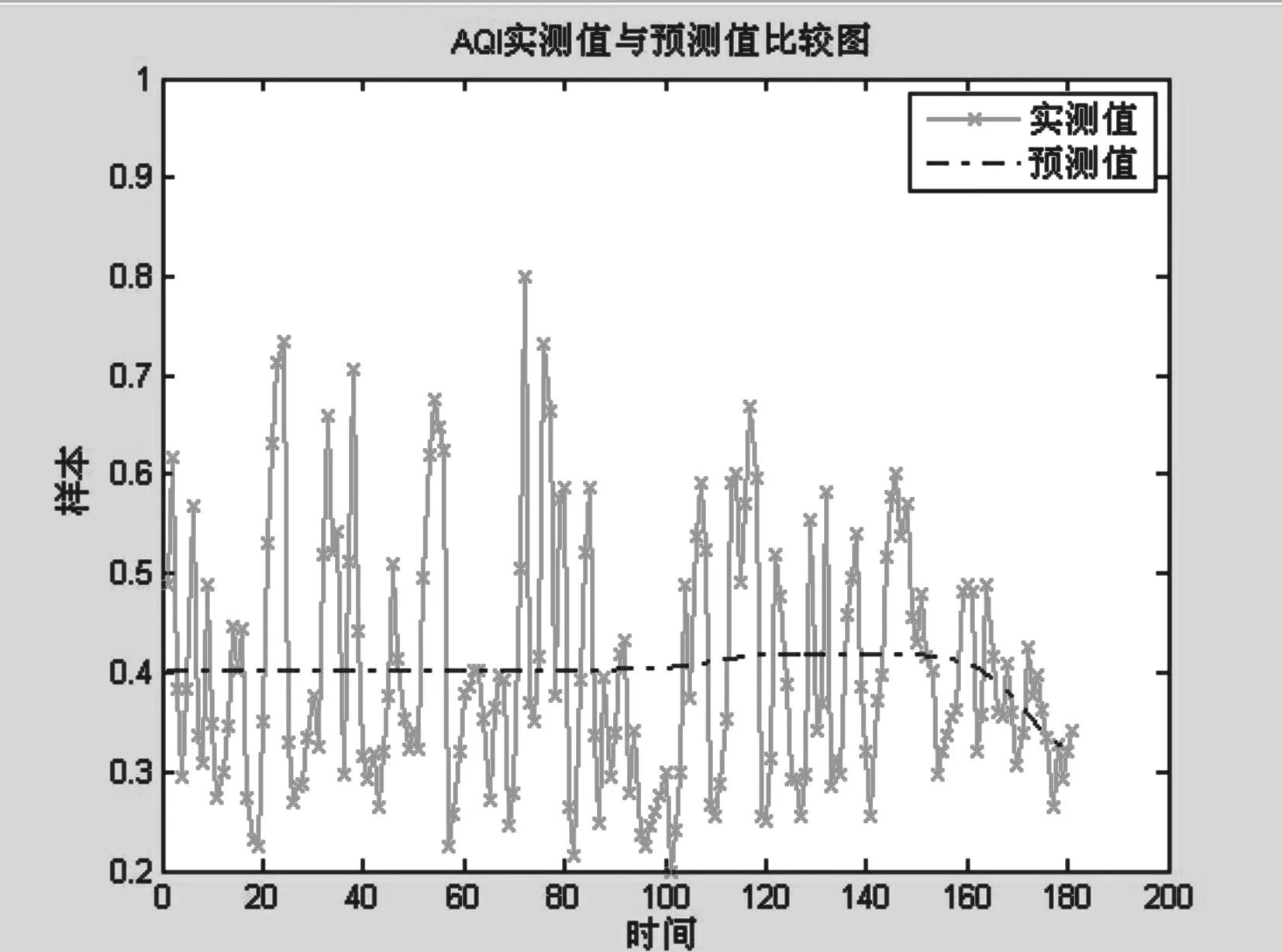
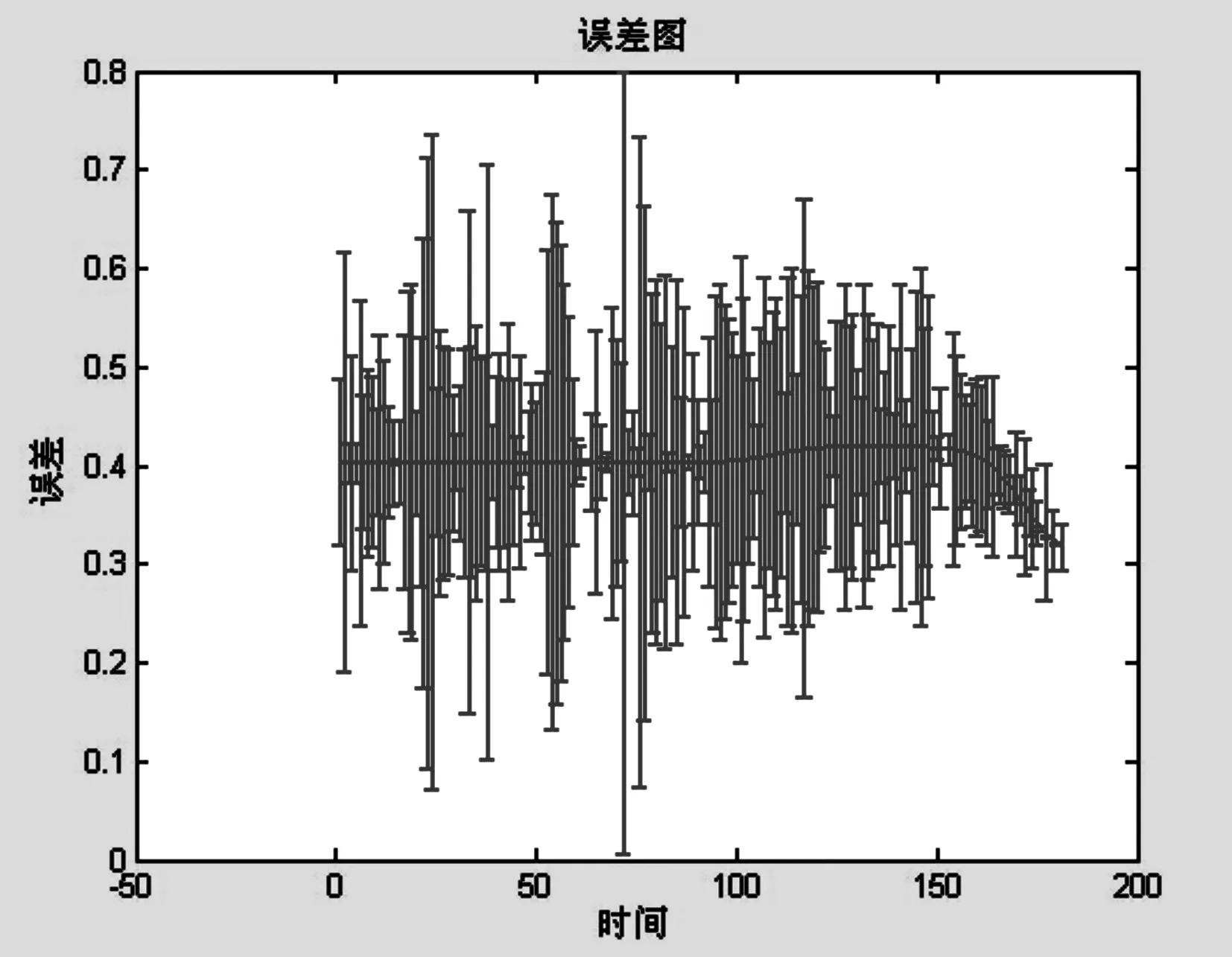
(三)时间序列组合模型求解
由于单一预测准确率不是很高,我们利用时序组合拟合模型,最终获得综合预测方程:

由方程可以预测5月份前5天的空气质量(AQI)指数值。

各模型预测值与实际值比较
经过不断检验与尝试,两模型拟合:
由模拟方程可以计算出预测AQI指数值,列如下表格,进行比较,可见基本符合实测数值大小,预测方法有效。
利用Matlab编程求得组合模型的预测值如下表:
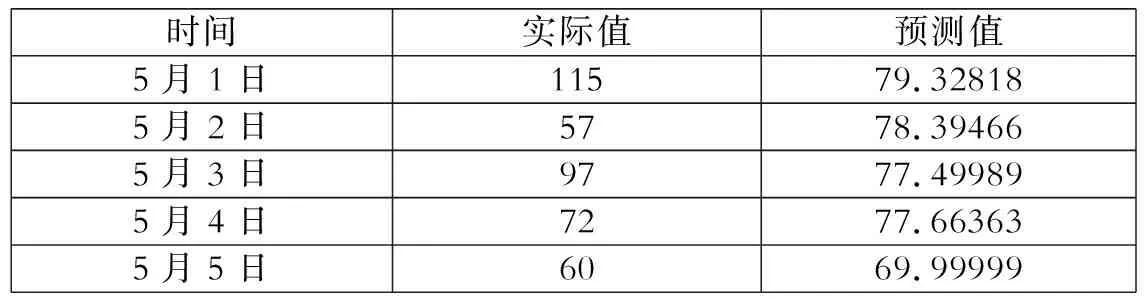
时间实际值预测值5月1日11579.328185月2日5778.394665月3日9777.499895月4日7277.663635月5日6069.99999
经过实际值与预测值的对比,发现我们的模型对空气污染指数能够进行大致预测,模型检验通过。
参考文献:
[1](美)Frank R.Giordano, Maurice D.Weir,WilliamP.Fox著,姜启源等译,数学建模[M].北京,机械工业出版社,2005.
[2]王中群主编.MATLAB建模与仿真应用[M].北京:机械工业出版社,2010.
[3]杨杰主编.数字图像处理及MATLAB实现[M].北京:电子工业出版社,2013.
[4]姚泽清,郑旭东,赵颖主编.全国大学生数学建模竞赛赛题与优秀论文评析[M].北京:国防工业出版社,2012.
[5]韩中庚主编.数学建模竞赛——获奖论文精选与点评[M].北京:科学出版社,2013.
[6]中华人民共和国国家统计局编,中国统计年鉴,http://www.stats.gov.cn/tjsj/ndsj/2013/indexch.htm,(2014年5月30日)
[7]天津近期空气质量指数AQI_PM2.5历史数据,http://www.tianqihoubao.com/aqi/tianjin-201401.html,(2014年5月30日)
猜你喜欢
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
电子产品世界(2021年6期)2021-02-10
小学生学习指导(低年级)(2020年3期)2020-06-02
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
中成药(2018年1期)2018-02-02
Coco薇(2017年2期)2017-04-25
Coco薇(2017年2期)2017-04-25
为了孩子(3~7岁)(2016年8期)2016-05-14
