
基于改进人工蜂群参数寻优的网络行为分类
2015-01-15 05:53王晓锋周长喜
服装学报 2015年5期
杨 宇, 毛 力 , 王晓锋, 周长喜
(江南大学 物联网工程学院,江苏 无锡214122)
随着互联网络的发展,网络规模的扩大,网络中的各种不良行为对用户的安全造成越来越多的威胁。面对网络中的海量数据,网络行为分类需要处理和重要信息同等数量甚至更多的数据,同时还要在不影响网络性能的前提下实现实时监控。这就对系统的运算时间和运算空间提出来了更高的要求。Vapnik 提出的基于支持向量机(Support Vector Machine,SVM)的分类算法是对样本数据进行预测和分类问题的一种有效方法,在网络行为分类领域得到广泛应用[1-3]。为了满足实际应用的需要,在SVM 做分类识别时需要调节相关参数(主要是惩罚因子C 和核函数参数g)才能得到比较理想的预测分类准确率[4]。
近年来,在SVM 参数寻优领域出现了一种新型的全局随机搜索方法——人工蜂群算法(Artificial Bee Colony,ABC)[4-6]。ABC 算法具有计算简单、参数设置少的优点,因此与其他参数寻优算法(如粒子群算法、遗传算法、蚁群算法)相比,具有比较明显的优势[4-6]。然而,传统的ABC 算法在用于SVM算法参数寻优的过程中容易陷入局部最优解,无法达到最优分类效果[7]。很多学者对传统ABC 算法做出了改进:王鑫等[8]通过自适应的位置更新、信息素与灵敏度配合选择模型以及最差解替代等方法改进了传统ABC 算法收敛速度慢和容易陷入局部最优的缺点;赵丹亚等[9]引入文化算法双层进化结构和多种群并行进化思想,提出基于双层进化的多种群并行人工蜂群算法以克服传统ABC 算法容易陷入早熟收敛的不足;毕晓君[10]通过设计新的选择策略和收敛策略,利用基于反向学习的变异策略代替侦查蜂的行为达到避免陷入局部最优的效果;王冰[11]和Anan B 等[12]采用基于当前局部最优解的搜索策略,加快了收敛速度;向万里等[13]提出基于轮盘赌的反向选择机制以保持蜂群个体的多样性而使算法保持较好的进化能力;银建霞等[14]、WU R 等[15]在传统人工蜂群算法中跟随蜂更新蜜源的阶段,引入混沌序列更新蜜源,以提高跟随蜂在此阶段的局部搜索能力。
针对使用传统参数寻优方法的SVM 算法识别网络行为分类效率低和准确率不高的问题,文中提出了一种高效的基于人工蜂群参数寻优的网络行为分类方法,即基于当前最优解的局部搜索策略并引入基于混沌序列的动态搜索因子改进传统的人工蜂群算法(改进后的算法记作CABC),寻找SVM最优参数,以达到快速准确进行网络行为分类的目的。
1 基于人工蜂群的SVM 算法参数寻优
1.1 传统SVM 及其寻优原理
支持向量机的基本思想是将非线性可分的样本通过非线性变换映射到一个高维空间。在这个高维空间中,寻找一个最优分类超平面作为决策曲面,使得正类和反类之间的分类间隔最大。将SVM的学习过程转化为优化问题,给定训练样本集(xi,yi),i = 1,2,…,l,x ∈Rny ∈{± 1},超平面记作ωTx + b = 0。寻找最优超平面即转化为最小化公式
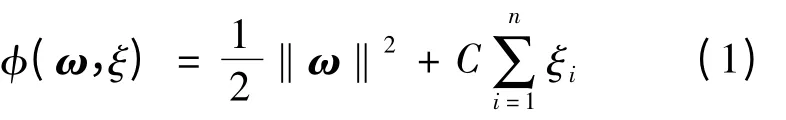
st

其中:ω 为超平面的法向量;C >0 为错分样本的惩罚因子;ξ 为松弛变量;b 为阈值,b ∈R。
引入Lagrange 函数,将二次规划问题转化为相应的对偶问题,即求解公式

其中,K(xi,xj)为核函数,其值受核函数参数g 的影响。文中选用的核函数为 RBF(Radial basis function,径向基核函数)。
RBF 核函数是一个普遍适用的核函数,对参数敏感,通过参数选择,可以适用于任意分布的样本。它的一般表示为
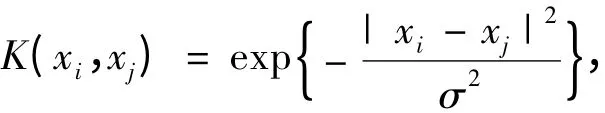
其中,σ(σ >0)为核函数的半径。Vapnik 等在研究中发现,不同的核函数对SVM 性能的影响不大,核函数的参数g 和误差惩罚因子C 是影响SVM 性能的关键因素[16]。
由此可见,问题的关键就是在最优核函数下寻找最优的惩罚因子C 和核函数参数g,从而使正确分类率最大[4]。传统的SVM 参数寻优需要对参数C和g 在给定范围内进行穷尽搜索,总的搜索时间为O(I × N),I 为训练样本个数,N 为搜索次数[17]。对于小样本数据而言,穷尽搜索的运行时间尚能够接受,但是一旦数据规模增大,算法的运行时间将会呈几何级数增长,故无法适用。所以文中使用改进的ABC 算法迅速准确地获取优化参数C 和g,从而避免穷尽搜索耗费的巨大计算量。
1.2 人工蜂群算法原理
人工蜂群算法[18]通过模拟蜜蜂的采蜜机制求解函数优化问题,把每个蜜源视为问题的一个解,花蜜数量对应解的适应度值。将蜜蜂分为3 类:雇佣蜂(employed bees)、跟随蜂(onlookers)和侦查蜂(scout bees)。为每个雇佣蜂初始化一个随机的蜜源位置,雇佣蜂负责在各蜜源附近搜索新蜜源,根据前后蜜源的花蜜数量选择较优蜜源并标记;跟随蜂在以上部分较优蜜源附近作局部搜索,与标记蜜源进行比较,选取较优异的蜜源作为本次循环的最终标记蜜源;如果在局部搜索过程中,雇佣蜂标记的蜜源经过若干次搜索比较后仍不变,相应的雇佣蜂变成侦查蜂,随机搜索新蜜源。每个雇佣蜂利用下式更新蜜源,即雇佣蜂更新蜜源
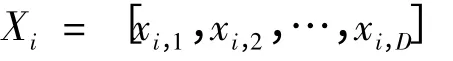
到新蜜源
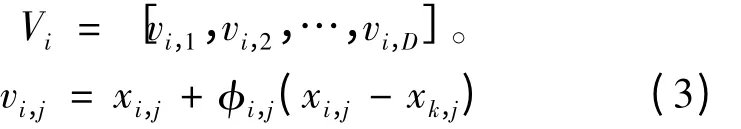
其中,xi,j和vi,j为个体Xi和个体Vi的第j 维分量;k ∈{1,2,…,NSN},j ∈{1,2,…,D},k 和j 都是随机选择的,且k ≠i,φi,j∈[-1,1]的随机数,控制xi,j邻域的生成范围;NSN为蜜源的数量;D 为蜜源位置向量的维度。
跟随蜂根据轮盘赌的方式选择部分优质蜜源进行局部搜索,根据

计算每个蜜源被选择的概率Pi。其中,NSN与雇佣蜂或跟随蜂数量的值相等;fiti为第i 个蜜源的适应度值。由于优化SVM 的主要目的在于获得更高的分类正确率,而SVM 算法在使用交叉验证时,svmtrain 的返回值是交叉验证下的平均分类准确率,记作fi,所以fiti可由下式得到。
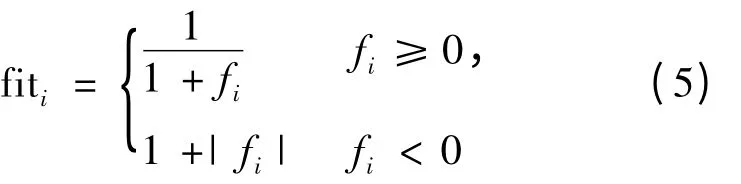
跟随蜂在每个被选中的蜜源邻域按照式(3)进行局部搜索产生新的蜜源。如果新的蜜源优于旧的蜜源则替换,否则保留。
若蜜源经过limit 次循环没有被更新,则侦查蜂通过下式
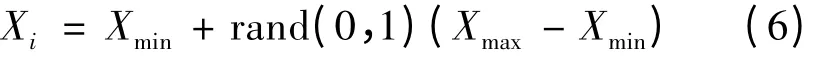
随机搜索新蜜源。其中,Xmax和Xmin为解空间的上、下边界。
1.3 基于当前最优解和混沌序列的局部搜索策略
ABC 算法中雇佣蜂和跟随蜂执行相同的搜索策略。在式(3)和式(6)中,xk,j是随机选择的任一个体的一维分量,rand(0,1)和φi,j也是随机数。这样的随机性导致搜索效率下降,尤其在训练数据集较大和样本属性较多时,算法的寻优精度和收敛速度都会受到很大的影响。蜂群可以根据蜜源的位置信息比较蜜源的优劣,选择当前最优蜜源并在其周围进一步进行寻优,以此达到加快收敛速度的目的。
同时,利用混沌序列具有随机、遍历、非周期、不收敛的特性,引入混沌序列算子作为动态收缩因子的组成部分,与参数α 共同控制新解的搜索范围。设
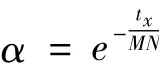
其中,tx为当前迭代次数。α 的值可以适时调节步长,有助于雇佣蜂和跟随蜂寻找新蜜源,提高寻优性能。在迭代初期,由于新解的调整值较大,可有效扩大搜索范围、确保种群的多样性,提高算法跳出局部极值的能力,防止早熟收敛现象的产生;随着迭代次数的增加,α 变小,新解的调整部分逐渐变小,有助于算法进行深度寻优并能快速寻找到最优解。根据Logistic 方程
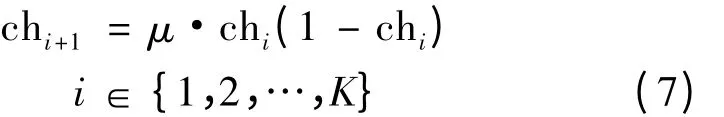
生成混沌序列。式中:混沌状态控制参数μ 取4,使Logistic 方程完全进入混沌状态;chi为属于[0,1]的均匀分布的随机数,且chi≠0.25,0.5 和0.75;K为混沌序列的长度。
雇佣蜂和跟随蜂每次迭代更新蜜源时,通过下式

采用基于当前最优解的局部搜索策略并引入基于混沌序列的动态搜索因子,逐维更新蜜源每一维度的值,以增加可行解在搜索空间中的多样性。其中:vi,j为新产生的蜜源Vi的第j 维分量;xi,j为上一个被搜索的蜜源Xi的第j 维分量;xb,j为当前最优解Xb的第j 维分量;j,k 均随机选择,且k ≠b,用于将当前最优解引入蜜蜂更新蜜源的公式;通过φi,j引入混沌搜索因子chi和参数α,控制xi,j邻域的生成范围。
1.4 算法流程
改进后的人工蜂群算法实现的具体步骤如下:
1)初始化算法参数:混沌序列长度K,最大迭代次数Nmax,判断蜜源更新是否陷入停滞的控制参数limit;
2)随机产生NSN个D 维解,作为初始种群,初始化迭代次数t = 0;雇佣蜂对每个蜜源Xi使用式(8)在它的邻域附近逐维进行变异和更新。
3)计算邻域内搜索到的每个蜜源Xi的适应度函数值fiti和选择概率Pi。
4)跟随蜂根据概率Pi选择部分适应度较好的蜜源,然后每个跟随蜂再根据式(8)在它的邻域附近进行逐维局部搜索,并记录其未更新次数。
5)判断是否存在连续limit 次都未被更新的蜜源,若存在则由侦查蜂通过式(6)随机搜索新蜜源。
6)记录到目前为止的最优解。
7)判断是否达到最大迭代次数MN,若满足,则输出最优解,否则转到2)。
1.5 算法的时间复杂度分析
2 仿真实验
2.1 实验测试函数和对比算法
文中将CABC 算法与标准ABC 算法和文献[12]中BSABC 进行比较以评估CABC 算法的鲁棒性、寻优精度和收敛速度。
为了分析CABC 算法的性能,文中选定4 个经典测试函数对其进行测试,测试函数的定义、搜索区间和理论最优值见表1。其中,Step 是单峰函数,在定义域内只有一个最优解,用来测试算法的寻优精度和收敛速度;Griewank 函数和Rastrigin 函数是
ABC 算法的时间复杂度为O(MN × SN)[19],文献[12]中的Best-so-far ABC(以下简称BSABC)算法的时间复杂度也为O(MN × SN)。文中提出的CABC 算法对雇佣蜂和跟随蜂的局部搜索策略进行了改进,ABC 算法中的两种蜜蜂只是随机选择任意一维分量进行变异,而CABC 算法中的雇佣蜂和跟随蜂则是在当前最优解的周围逐维进行局部搜索,故其时间复杂度增加了O(MN ×SN ×(D -1)),其中D 为个体的维数。而在搜索时加入的混沌算子是一个长为K 的序列,所以对算法的时间复杂度没有影响。CABC 算法的时间复杂度为O(MN × SN +MN × SN ×(D - 1)),故经过约减后CABC 算法的时间复杂度也为O(MN×SN),即这3 种算法的时间复杂度相同。多峰函数,具有多个分布均匀的最优解,但Griewank 函数的局部最优解随着维度的增加而增加,用于测试算法全局寻优的性能和避免早熟的能力;Rosenbrock 函数的全局最优解分布在一个又长又窄的抛物线形的平坦的山谷里,很难收敛到全局最优解,通常用以评价优化算法的性能[20]。
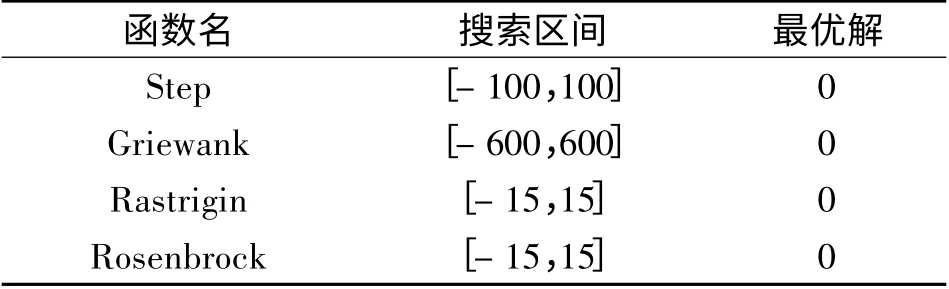
表1 测试函数Tab.1 Test function
表1 中,Step 函数表示为i=1
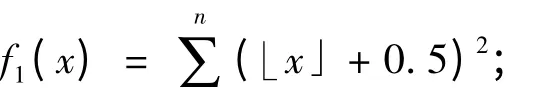
Griewank 函数表达式
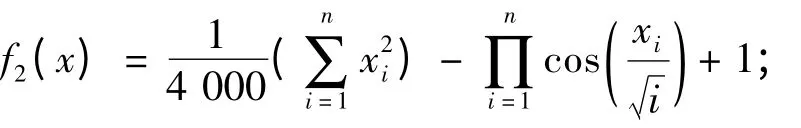
Rastrigin 函数表达式
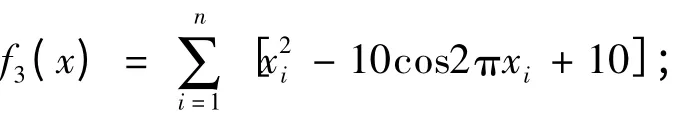
Rosenbrock 函数表达式
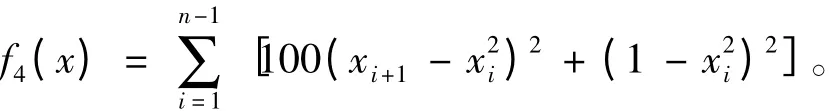
2.2 实验结果分析
对比实验的参数设置如下:最大迭代次数Nmax为1 000,控制参数limit 为50,初始化蜜源的数量NSN为50,维度D 为30。
3 种算法分别对4 个测试函数独立运行30 次的测试结果见表2。
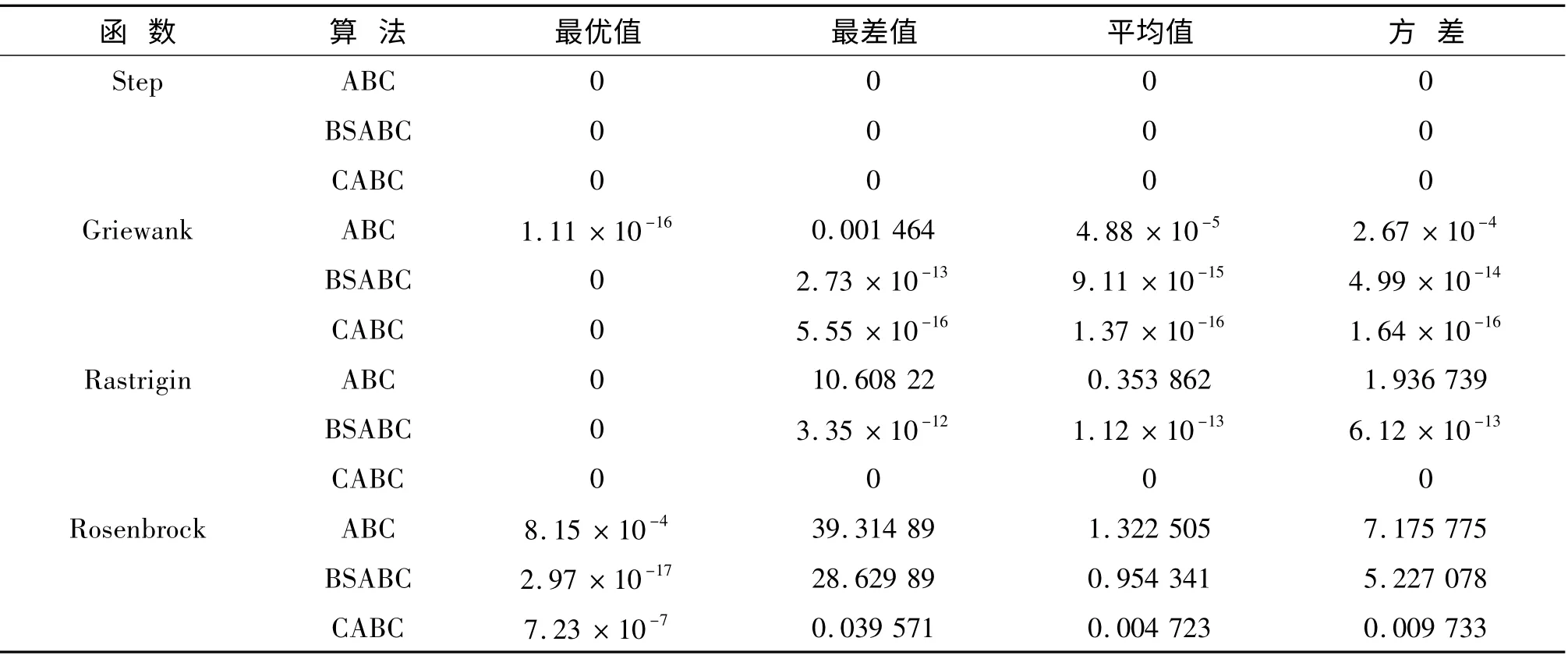
表2 30 维函数测试结果比较Tab.2 Comparison of the 30-dimensional function test results
表3 反映了在表2 实验条件下,3 种算法运行时间的对比情况,平均运行时间即为不同算法分别对不同测试函数在各自独立运行30 次时,达到收敛稳定精度所需要时间的平均值。图1 ~图4 分别给出了3 种算法对测试函数在各自独立运行30 次时的平均适应值的进化曲线。

表3 30 维函数达到稳定精度的运行时间Tab.3 Runtime of the 30-dimensional function to stable precision
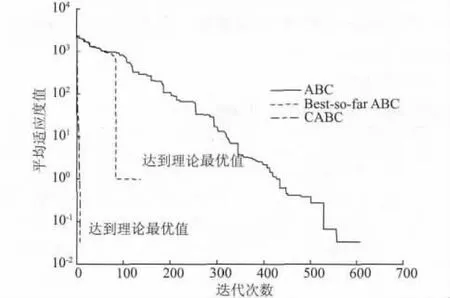
图1 Step 在ABC,BSABC 和CABC 算法下进化曲线Fig.1 Evolution curves of ABC,BSABC and CABC by Step function

图2 Griewank 在ABC,BSABC 和CABC 算法下进化曲线Fig.2 Evolution curces of ABC,BSABC and CABC by Griewank function
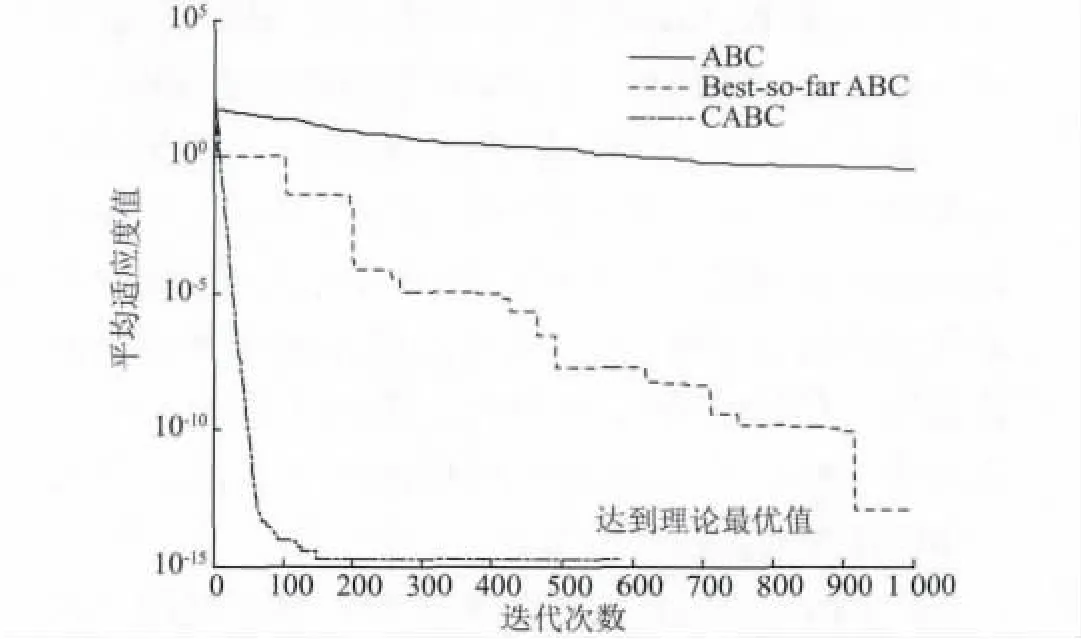
图3 Rastrigin 在ABC,BSABC 和CABC 算法下进化曲线Fig.3 Evolution curves of ABC,BSABC and CABC by Rastrigin function
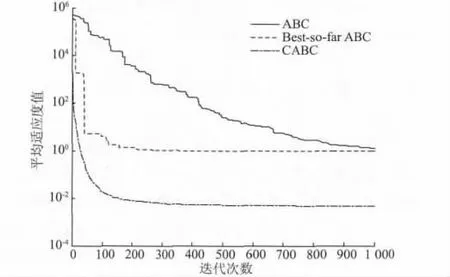
图4 Rosenbrock 在ABC,BSABC 和CABC 算法下的进化曲线Fig.4 Evolution curves of ABC,BSABC and CABC by Rosenbrock function
由表2 中的数据可以看出,CABC 算法在4 种测试函数上的最优值和最差值的精度与标准ABC 算法和BSABC 算法相比都有明显的提高。而且,由图1可知,尽管在3 种算法下Step 函数都达到了理论最优值,但CABC 算法所需的迭代次数明显小于标准ABC 算法和BSABC 算法。由图2 和图3 可知,CABC算法在Griewank 和Rastrigin 函数上均在200 次迭代内就达到了稳定精度,尤其是Rastrigin 函数,CABC算法可以快速的收敛到理论最优值0,与ABC 算法和BSABC 算法完成1 000 次迭代后仍不稳定相比明显更优。
另外,由表3 可知,CABC 算法的平均运行时间明显小于ABC 算法和BSABC 算法。虽然CABC 算法的每次迭代中在雇佣蜂和跟随蜂搜索阶段引入了混沌序列,尝试均匀地向各个方向游动增加了计算量,从而增加了每次迭代的运行时间;但是从图1 ~图4 可以看出,CABC 算法达到稳定收敛精度所需要的迭代次数远小于ABC 算法和BSABC 算法。显然,从总体上来看,CABC 算法表现出比ABC 算法和BSABC 算法更高的收敛精度和更快的收敛速度。
表2 中显示,CABC 算法的均值和方差都优于另外两种算法,而且存在数量级级别的提升。尤其是Rosenbrock 函数,与BSABC 算法结果相比,虽然在最优值精度上稍差,但是就平均值体现的鲁棒性而言仍然明显优于BSABC 算法的优化结果。而图1 ~图4 中CABC 算法在迭代后期曲线的平滑更说明CABC 算法的鲁棒性较高。
4 个函数的仿真结果表明,CABC 算法利用当前最优解和具有混沌特性的动态收缩因子改进了雇佣蜂和跟随蜂的局部搜索方式,从而增强了该算法的局部搜索能力,显著提高了最优解的精度;同时使算法的鲁棒性和收敛速度得到明显提高,在一定程度上防止了算法的早熟收敛。
3 CABC 参数寻优的网络行为分类
为了证明算法的有效性,文中在Matlab 环境下用真实的网络数据进行实验。采用的KDDCUP99 数据集是MIT 林肯实验室模拟美国空军局域网网络环境并从中采集的网络连接数据和系统审计数据。其中,测试数据集和训练数据集有不同的概率分布,使得网络行为分类实验更具有现实性。
实验以训练数据集中的部分记录作训练集,测试数据集中的部分记录作测试集,取得C 和g 最优值后用 KDDCUP99 数据集的其他数据(Dataset1-Dataset4)评估CABC 算法在网络行为分类方面的应用效果。实验参数设置如下:最大迭代次数MN 为30,控制参数limit 为5,初始化蜜源的数量为10。
分别把两种算法得到的最优参数和Libsvm 默认参数(C 默认1,g 默认为属性数目的倒数)运用在其他4 组同源的训练和测试数据集上,训练和测试数据集都分别包含30 000 条记录,运行结果比较见表4。
由表4 可以看出,在预测准确性基本一致的前提下,经过CABC 算法参数寻优后再进行检测,模型的训练时间和应用模型的检测时间都有大幅度提高,仅为原来默认参数下的11% ~35%,为标准ABC 算法的20% ~50%。由此表明,CABC-SVM 可以成功应用到网络行为分类领域,并且比ABC-SVM和默认参数的SVM 更快地取得分类结果,识别率稳定,可靠性好。
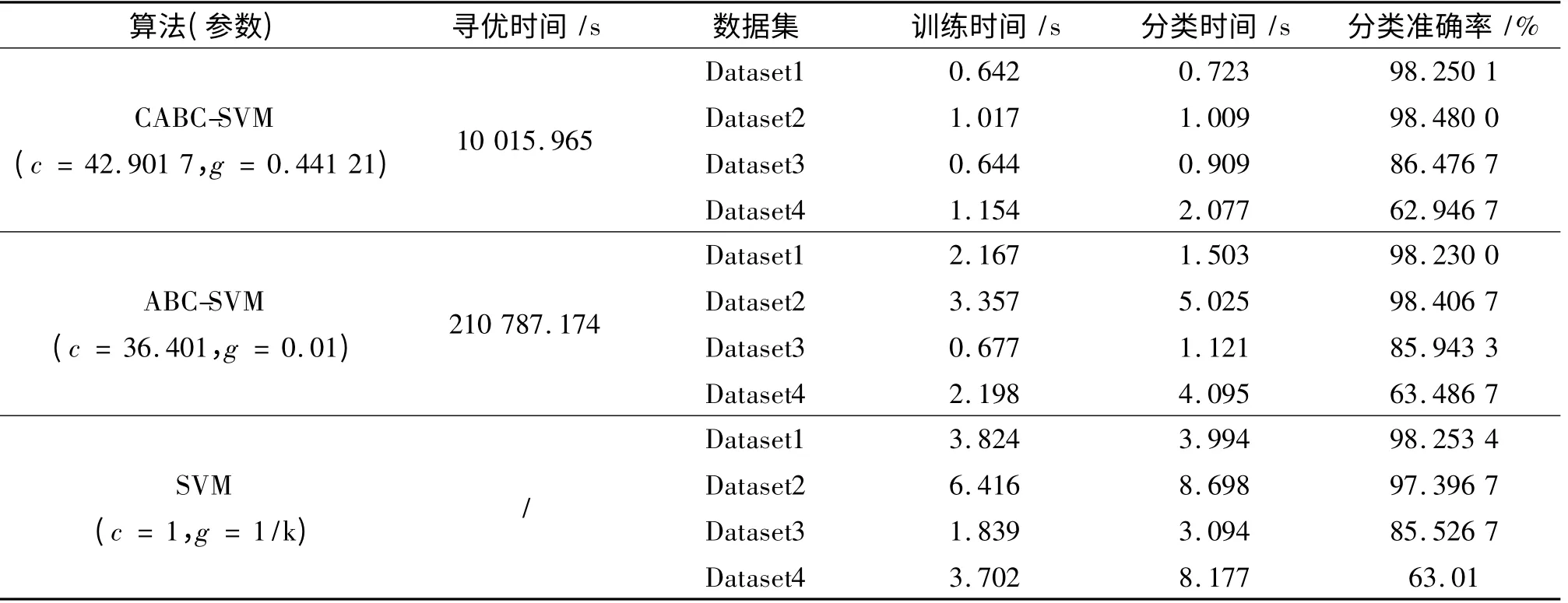
表4 3 种参数下的分类效果比较Tab.4 Comparison of the classification results under three kinds of parameters
4 结 语
文中在深入分析算法的基础上,基于当前最优解和混沌序列,提出了具体的改进方案以克服标准ABC 算法的缺陷。基于经典测试函数的仿真结果表明,在求解函数最优解优化问题上,文中给出的CABC 算法具有较强的鲁棒性,能有效避免算法陷入局部最优,并具有更高的寻优精度和更快的收敛速度。将改进的算法用于网络行为分类领域,通过与ABC-SVM 算法和默认参数的SVM 算法的对比,实验证明CABC 算法在具体应用上能够取得更为理想的效果。
[1]熊刚,孟姣,曹自刚,等.网络流量分类研究进展与展望[J].集成技术,2012,1(1):32-42.
XIONG Gang,MENG Jiao,CAO Zigang,et al. Research progress and prospects of network traffic classification[J]. Journal of Integration Technology,2012,1(1):32-42.(in Chinese)
[2]王涛,余顺争.基于机器学习的网络流量分类研究进展[J].小型微型计算机系统,2012,33(5):1034-1040.
WANG Tao,YU Shunzheng.Advances in machine learning based network traffic classification[J].Journal of Chinese Computer Systems,2012,33(5):1034-1040.(in Chinese)
[3]顾成杰,张顺颐.基于改进SVM 的网络流量分类方法研究[J].仪器仪表学报,2011,32(7):1507-1513.
GU Chengjie,ZHANG Shunyi. Network traffic classification based on improved support vector machine[J]. Chinese Journal of Scientific Instrument,2011,32(7):1507-1513.(in Chinese)
[4]于明,艾月乔.基于人工蜂群算法的支持向量机参数优化及应用[J].光电子·激光,2012,23(2):374-378.
YU Ming,AI Yueqiao. SVM parameter optimization and application based on artificial bee colony algorithm[J]. Journal of Optoelectronics·Laser,2012,23(2):374-378.(in Chinese)
[5]Mandal S K,Chan T S,Tiwari M K.Leak detection of pipeline:an integrated approach of rough set theory and artificial bee colony trained SVM[J].Expert Systems with Applications,2012,39 (3):3071-3080.
[6]刘路,王太勇.基于人工蜂群算法的支持向量机优化[J].天津大学学报,2011,44(9):803-805.
LIU Lu,WANG Taiyong. Support vector machine optimization based on artificial bee colony algorithm[J]. Journal of Tianjin University,2011,44(9):803-805.(in Chinese)
[7]GAO W,LIU S. Improved artificial bee colony algorithm for global optimization[J]. Information Processing Letters,2011,111(17):871-882.
[8]王鑫,谭华忠,蒋华.基于改进人工蜂群算法的视频水印[J].计算机工程与设计,2014,35(6):2095-2099.
WANG Xin,TAN Huazhong,JIANG Hua. Video watermark scheme based on improved artificial bee colony algorithm[J].Computer Engineering and Design,2014,35(6):2095-2099.(in Chinese)
[9]赵丹亚,张月.基于双层进化的多种群并行人工蜂群算法[J].计算机工程与设计,2015,36(1):178-183.
ZHAO Danya,ZHANG Yue. Parallel evolution with multi-populations artificial bee colony algorithm based on dual evolution structure[J].Computer Engineering and Design,2015,36(1):178-183.(in Chinese)
[10]毕晓君,王艳娇.加速收敛的人工蜂群算法[J].系统工程与电子技术,2011,33(12):2755-2761.
BI Xiaojun,WANG Yanjiao. Artificial bee colony algorithm with fast convergence[J]. Systems Engineering and Electronics,2011,33(12):2755-2761.(in Chinese)
[11]王冰.基于局部最优解的改进人工蜂群算法[J].计算机应用研究,2014,31(4):1023-1026.
WANG Bing.Improved artificial bee colony algorithm based on local best solution[J].Application Research of Computers,2014,31(4):1023-1026.(in Chinese)
[12]Anan B,Tiranee A,Booncharoen S.The best-so-far selection in artificial bee colony algorithm[J].Applied Soft Computing,2011,11(2):2888-2901.
[13]向万里,马寿峰.基于轮盘赌反向选择机制的蜂群优化算法[J].计算机应用研究,2013,30(1):86-89.
XIANG Wanli,MA Shoufeng.Artificial bee colony based on reverse selection of roulette[J].Application Research of Computers,2013,30(1):86-89.(in Chinese)
[14]银建霞,孟红云.具有混沌差分进化搜索的人工蜂群算法[J].计算机工程与应用,2011,47(29):27-30.
YIN Jianxia,MENG Hongyun.Artificial bee colony algorithm with chaotic differential evolution search[J].Computer Engineering and Applications,2011,47(29):27-30.(in Chinese)
[15]WU B,FAN S H.Improved Artificial Bee Colony Algorithm with Chaos[M].Berlin:Springer,2011:51-56.
[16]John Shawe-Taylor,Nello Cristianini.模式分析的核方法[M].赵玲玲,翁苏明,曾华军,等译.北京:机械工业出版社,2006.
[17]龚永罡,汤世平.面向大数据的SVM 参数寻优方法[J].计算机仿真,2010,27(9):204-207.
GONG Yonggang,TANG Shiping.A novel parameters optimization of SVM for large data sets[J].Computer Simulation,2010,27(9):204-207.(in Chinese)
[18]GAO Weifeng,LIU Sanyang,HUANG Lingling.A global bvest artificial bee colony algorithm for global optimization[J].Journal of Computational and Applied Mathematics,2012,236 (11):2741-2753.
[19]王翔,李志勇,许国艺,等.基于混沌局部搜索算子的人工蜂群算法[J].计算机应用,2012,32(4):1033-1036.WANG Xiang,LI Zhiyong,XU Guoyi,et al.Artificial bee colony algorithm based on chaos local search operator[J]. Journal of Computer Applications,2012,32(4):1033-1036.(in Chinese)
[20]Ratnaweera A,Halgamuge S,Watson H C. Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients[J].IEEE Transactions on Evolutionary Computation,2004,8(3):240-255.
猜你喜欢
林业与生态(2022年5期)2022-05-23
小哥白尼(军事科学)(2020年4期)2020-07-25
计算机工程与设计(2020年4期)2020-04-23
高中生·天天向上(2018年1期)2018-04-14
物联网技术(2017年5期)2017-06-03
上海理工大学学报(2016年2期)2016-06-02
现代计算机(2016年17期)2016-02-28
陕西理工大学学报(自然科学版)(2015年6期)2016-01-25
湖南农业(2015年5期)2015-02-26
吉林建筑大学学报(2014年1期)2014-09-13
