
基于中介语语料库的日本留学生论证性语篇信息结构习得研究
2015-03-20 06:57张迎宝
海外华文教育 2015年4期
张迎宝
(广州大学人文学院/语言服务中心,中国 广州510006)
一、引 言
篇章信息结构,又称篇章宏观结构(van Dijk,1980:1 -15)、篇章宏观信息结构(郭纯洁,2006:70 -75)是负载不同功能的各种高层次信息单元之间建构起的一种功能关系网络,是语篇宏观结构组织建构的核心要素之一(郑贵友,2002:215)。总体来看,国内外学者对篇章信息结构的研究主要集中于以下三个方面。一是针对某一单一语言本体进行的探索分析。内容主要包括:篇章信息结构的性质、构成与特征(van Dijk,1980:75 -90;Brown& Yule,1983:125 -179;Gee 1999:80 -98;郑贵友,2002:204 -254;徐赳赳,2010:364 -479);篇章信息结构的生成过程及其与微观线性信息结构之间的关系(van Dijk,1980:99 -106;Lambrecht,1994:36 -65;Mann & Thompson,1987:20-75);不同语体语篇宏观信息结构的组织模式(廖秋忠,1988;黄国文,2001:229 -244;Büring,2003;杜金榜,2007)。二是从跨语言角度对不同语言篇章信息结构模式进行的对比研究。该类研究中比较具有代表性的是Kaplan(1966)以国际学生的篇章习作为研究母本,对英汉语篇的信息结构进行的对比分析,研究表明英语语篇呈直线型结构而汉语语篇呈螺旋型结构,两者存在很大的不同。之后的研究大致可以分为两派:一类是支持派,如Matalene(1985)、Ricento(1986)、刘礼进(1999)等学者,基本支持Kaplan 的观点;另一反对派,如Mohan&Lo(1985)、郭纯洁(2006:70 -104)等学者,认为Kaplan 的研究存在很大的问题,英汉语篇信息结构的语种倾向性并不明显。三是针对语言教学以及中介语语篇进行的应用型研究。该类研究着力于从语言教学或习得的角度对留学生篇章信息结构建构中出现的偏误进行分析并以此为基础提出相应的教学原则与策略(吴丽君,2002:249 -268;郑贵友,2002:250 -259;彭小川,2004;孙新爱2004:24 -29)。
综上,三个研究方向中,前两个的研究成果较多,研究较为充分,最后一个方向的研究成果较少,相对薄弱。尤其是针对汉语中介语的研究,从已收集到的文献来看,还主要停留在对中介语篇章信息结构模式与特征的静态描写上,对其习得过程、特点以及机制的研究较为欠缺。同时,从研究方法来看,多数研究采用的是“个案分析+主体思辨”的分析模型,对可用于篇章信息结构研究的一些实证与定量分析方法未做到有效利用。
鉴于以上现状,本文拟在以往研究成果的基础上,依托HSK 动态作文语料库,尝试采用定量统计的方法,从动态角度观察日本留学生论证性语篇信息结构的习得过程与特点。
二、研究设计
本文的前期研究分为语料的收集与处理、论证性语篇信息结构的形式化、信息结构构成参项的提取与数据收集分析三个部分。下面我们依次进行说明。
(一)语料的收集与处理
本文使用的语料分为两部分。
一部分是日本留学生制作的汉语中介语语篇,该部分语料来自北京语言大学“HSK 动态作文语料库”。为了保证语料内部的均衡性,我们以语料库中日本留学生对《吸烟对个人健康和公众利益的影响》这一测试题目写成的515 篇成品作文作为总样本库[1],依据分值[2],从高到低进行了随机抽取。最后,我们从样本总库中选取了90 篇,其中90 分、85 分、80 分、75 分、70 分与65 分的各10 篇,60 分、55 分的各15 篇,并按照表达水平把90 个抽样分为三个组,分别是:低级水平组(55 ~60 分),30 篇;中级水平组(65 ~75 分),30 篇;高级水平组(80 ~90 分),30 篇。为了便于称说,我们将这三个组分别简称为:IJL 组(Interdiscourse of Japanese Students of low level)、IJM 组(Interdiscourse of Japanese Students of Middle level)和IJH 组(Interdiscourse of Japanese Students of High level)每组内的样本按从1 到30 进行编号。比如,日本留学生汉语中介语篇高级水平组的第一个样本编号为IJH1,第三十个样本编号为IJH30。
需要指出的是,由于本文重点探索的是论证语体中介语篇的信息结构,为了纯化语料,提高研究结论的信度,我们在评测分组前对抽样语篇进行了核查,剔除掉了其中个别的非论证性语篇。此外,为了保持样本的原貌,我们只对语篇中的错别字进行了修正,其余部分(标点、词、句子、段落划分、篇章整体结构等)一律未做改动。
另一部分语料是母语为汉语的中国大学生的汉语语篇。这部分材料来自现场测试。参加测试的是38 名大学生,其中男生18 名,女生20 名。这些被试的母语均为汉语,具有较好的汉语书面表达能力和良好的合作态度。测试题目摘自HSK 试卷(细节有所改动),下面是试题的全文:
某市政府最近出台了一项规定,根据该规定,在公共场所边走边抽烟的人将被罚款。这是迄今为止对吸烟者最为严厉的惩罚措施。这一新措施在人口密集的商业中心已经开始实施。
测试要求:(1)请以“吸烟对个人健康和公众利益的影响”为题目写一篇完整的议论文来谈一下你对该措施的看法。(2)使用汉语进行写作。(3)限时30 钟[3]。
测试结束后,我们对收集到的汉语语篇进行了评估,剔除了其中的非论证性语篇,并从中选取了30 篇综合评估良好的作文作为本文的研究素材。为了研究的方便,我们将这30 篇汉语语篇按CT1~CT30(CT 代表Chinese Text)进行了编号。
(二)信息结构的形式化
1.篇章小句的切分。小句是篇章构建的基本成分,也是进行篇章分析不可或缺的单位。因此我们语料分析的第一步就是将所有语篇的小句切分出来,并用专门的符号Cn(n 表示小句在语篇中的编号)进行标注。在具体操作中,我们以徐赳赳(2003:58)提出的“主谓结构(包括主语为零形式)”“停顿和功能”两条标准作为主要的切分依据。其中,前者是主要标准,后者是辅助标准。
2.篇章信息结构树形图的绘制。为了更清晰地勾勒论证性语篇的宏观组织结构,更准确地观察信息的分布与组配,也为了方便后期的量化统计与对比分析,我们不但需要按层次切分出所有样本的宏观信息模块,还需要在此基础上对其进行形式化描写。廖秋忠(1988)的研究指出,论证结构的核心是论题和论据,除此之外还经常有引论和结尾部分,前者提供背景与缘由,后者概括论据、重述论题。在此基础上,他将论证结构的宏观信息结构形式化为(1)廖文提出的这种形式化模式直观、简明,对汉语论证性语篇具有较强的概括性。但也存在一些缺点,那就是对结尾部分“C”与论据部分“E”的处理过于简单。因为根据我们信息结构分析的经验,在篇幅较长的语篇当中,结尾与论据部分,尤其是论据部分,往往会包含多个信息模块,简化处理存在形式化不彻底、遗漏信息点的隐患。鉴于此,我们结合本文使用的语料,对廖文提出的模式进行了修正,将论证语篇的信息结构形式化为:
(1)T→[I]A[C] (2)A→PE 或EP (3)C→[S][AD]
(4)AD→AD1AD2……ADN(N≥1) (5)P→P[CI]
(6)E→[I]{E {E1E2……EN}}[S](N≥1)
(7)EN→EN.1EN.2……EN.n(n≥1)
其中,T 代表整个语篇;I 代表T 中的引言部分或E 中的总提部分;A 代表核心论证部分;C 代表结尾;P 代表论点(论题);E 代表论据;S 代表C 中总结论据重申论题的部分或E 中的总结部分;AD 代表C 中与论题有关的引申部分或与论题无关的题外事项,这其中既可以包括作者提出的解决问题的措施、办法也可以包括作者发出的号召,提出的期望、忠告、建议等;CI 代表说明澄清部分;E1E2……EN代表一级分论据,其中N 表示一级分论据的数量,取大于等于1 的整数;EN.1EN.2……EN.n代表某一一级分论据的下位分论据,即二级分论据,n 表示二级分论据的数量,取大于等于1 的整数。{{}}表示信息模块之间存在上下位关系,内外括号间的成分为上位信息,内括号中的成分为下位信息。[]表示该成分为可缺失成分。
下面我们以IJL6为例进行简要说明。
“在公共场所、不允许抽烟”这个措施,我个人认为很有道理(C1)。
首先,从吸烟的利弊来看,吸烟明明是有害无益的(C2)。至今,连自己吸烟的人也知道吸烟对身体有害(C3)。但是,长年养成的嗜好,他们难以离开(C4),在公共场所有人吸烟的话(C5),他吐出的烟雾至少损害他的周围好几个人的健康(C6)。对他个人的健康不用说了(C7)。
其次,我们要考虑吸烟者和不吸烟的人的权利(C8)。这样的措施很有可能引起吸烟者的反对(C9)。那么我们应该保护谁的权利呢(C10)?我们不得不承认吸烟也是一种享受(C11)。可以算是一种爱好(C12)。但是,给别人添麻烦而且损害别人的健康的爱好不被承认是个爱好(C13)。
总之(C14),我赞成“在公共场所边走边不允许吸烟”这个措施(C15)。吸烟对人们的健康根本没有好处的(C16)。我希望(C17)不久的将来没有烟雾的世界会实现(C18)。(IJL6)
IJL6中,C1是论点,C2~C13中使用了两个论据从两个不同的角度来论证自己的观点:一是论据E1(C2~C7),吸烟对身体健康的危害;二是论据E2(C8~C13),吸烟对他人权利的侵犯。最后一段(C14~C18)为整个论证结构的结尾部分:作者一方面总结上文重述论点,另一方面就公共场所的吸烟现象提出了自己的希望。
通过对IJL6的分析、拆解,我们将该语篇的信息结构形式化为图一。
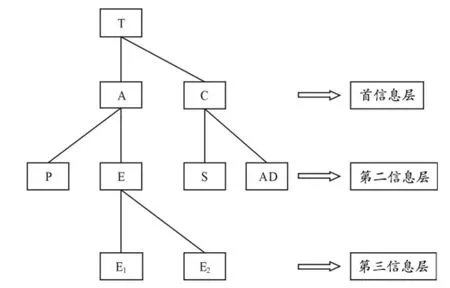
图一 IJL6 篇章信息结构的树形图
3.篇章信息结构模块间功能结构关系的确定。篇章信息结构从本质上讲是由多种信息功能模块编织而成一种关系网络。这就要求我们不仅要切分出其中的各类功能模块,还要通过分析确定出信息结构树形图中模块与模块之间的功能结构关系。从分析结果来看,论证性语篇使用到的功能结构关系主要有背景、重述、综述、增述、证据、总提、说明、题解、联合、对比等。
(三)研究参项与数据收集分析
1.研究参项
结合论证性语篇的特点与树形图,我们提取出信息结构的六个构成参项。
(1)信息层,指篇章信息结构系统中负载各种信息的不同层级。篇章宏观信息结构系统是一个层级系统,底层较小的信息模块相互组配,构成上一级的、较大的信息模块,这些模块再相互组合,构成更高一级的、更大的模块,直至最终构建起整个篇章的宏观信息系统。
(2)信息点,指的是篇章信息结构中负载不同信息的各类功能模块。
(3)信息量,指的是各类信息结构模块,即各种不同类型的信息点,携带的已知信息与未知信息的量。本文中,我们主要以小句的数量作为判断宏观信息模块信息量的标准。
(4)信息配列,指篇章底层树形层级式的信息结构通过信息模块间的定位组配所实现的表层线性序列。
(5)信息模式,指篇章制作者在对各类信息模块进行筛选、分层、组配、排序等一系列认知操作之后会最终形成的各具特点的层级化信息模型。
(6)信息模块间结构关系,指篇章信息结构同一信息层上两个或多个信息模块之间存在的功能结构关系。
2.数据收集与分析
本文收集的主要是日本留学生三个不同水平组(IJL、IJM、IJH)内90 个语篇以及目标语对比组(CT)内30 个语篇宏观信息结构六个参项的数据。数据分析过程中,本文使用的主要分析工具是Excel 和SPSS 18.0 for Windows。
三、结果与讨论
(一)信息层的习得特点
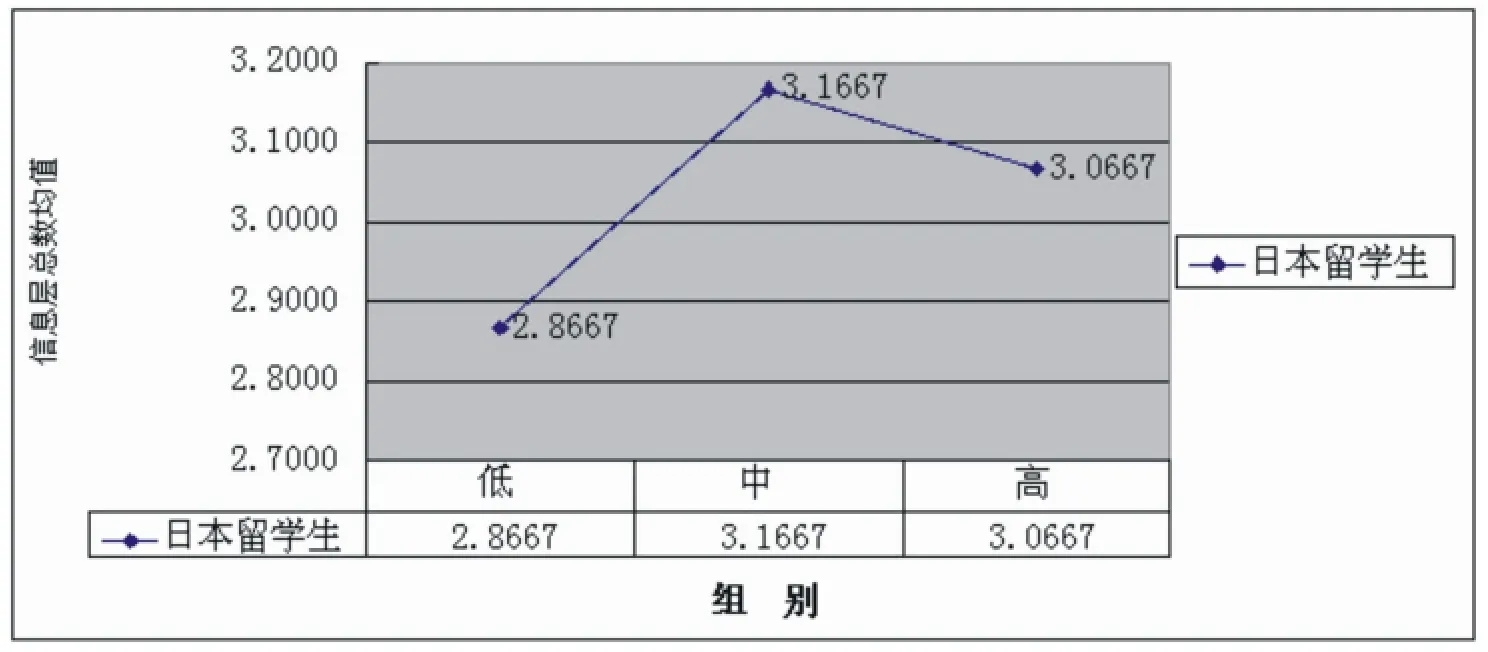
图二 低、中、高水平组日本留学生样本的信息层数均值
根据图二信息层数均值折线图的变化情况,可以看出日本留学生篇章信息结构层级建构能力的发展存在以下特点:
第一,篇章信息结构层级建构能力由低到高,逐渐向汉语母语者靠拢。根据图二,日本留学生低、中、高三个水平的信息层数均值分别为2.8667、3.1667 和3.0667,虽然与中级水平相比高水平阶段的均值略有下降,但从总的发展趋势来看,整个折线仍然呈现为一种上扬态势。对CT 组的分析显示,汉语母语者篇章信息结构信息层数的均值为3.5667。即,日本留学生的篇章信息结构层级建构能力随着其水平的进展,呈现出由低到高逐渐向目标语靠拢的趋势。
第二,层级建构能力的获得呈现出先快后慢的特点。从图二折线的轨迹来看,其前半段的上行倾斜度均比较大,但后半段的轨迹呈现下行态势。这说明日本留学生在“低-中”阶段层级建构能力的发展速度与变化幅度均高于“中-高”阶段,或者说,日本留学生获得层级建构能力时呈现出“先快后慢”的特征。这一点可以从信息层数均值的变化上得到进一步地证明:“低-中”阶段,均值增加了0.3000;但“中-高”阶段均值下降了0.1000。
(二)信息点的习得特点

图三 日本留学生及汉语母语者样本的信息点数均值
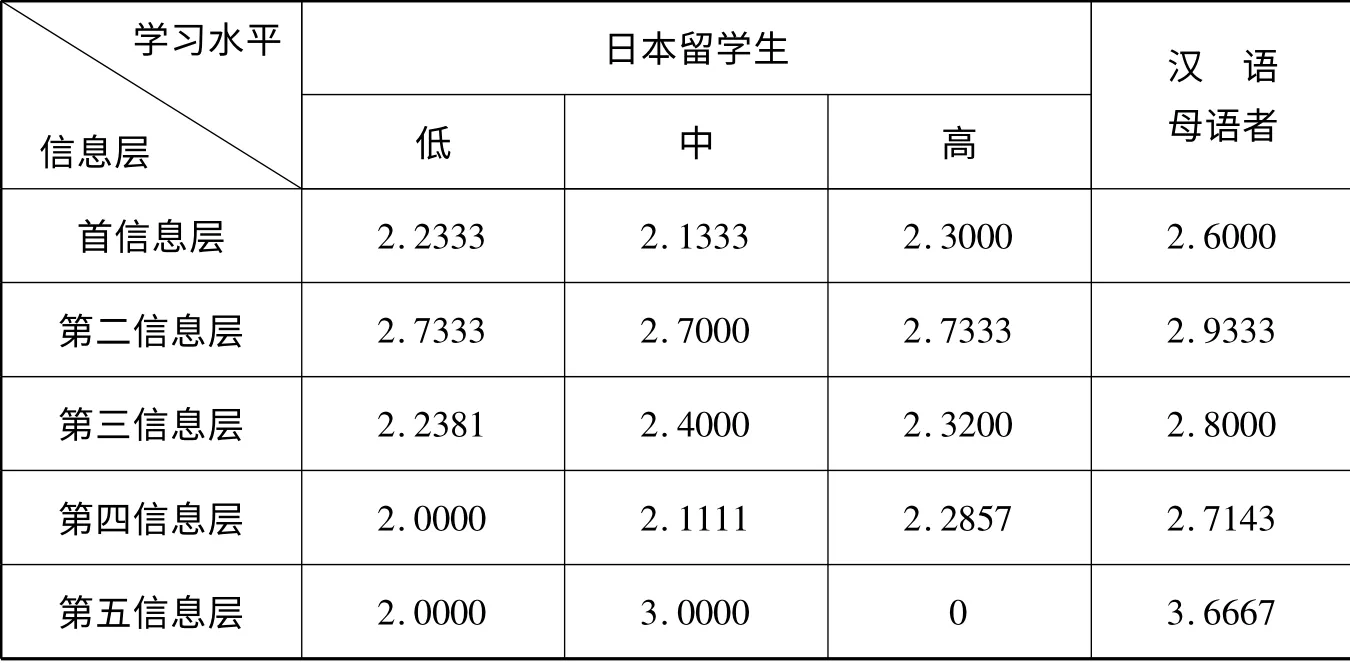
表1 日本留学生及汉语母语者样本的不同信息层信息点数的均值
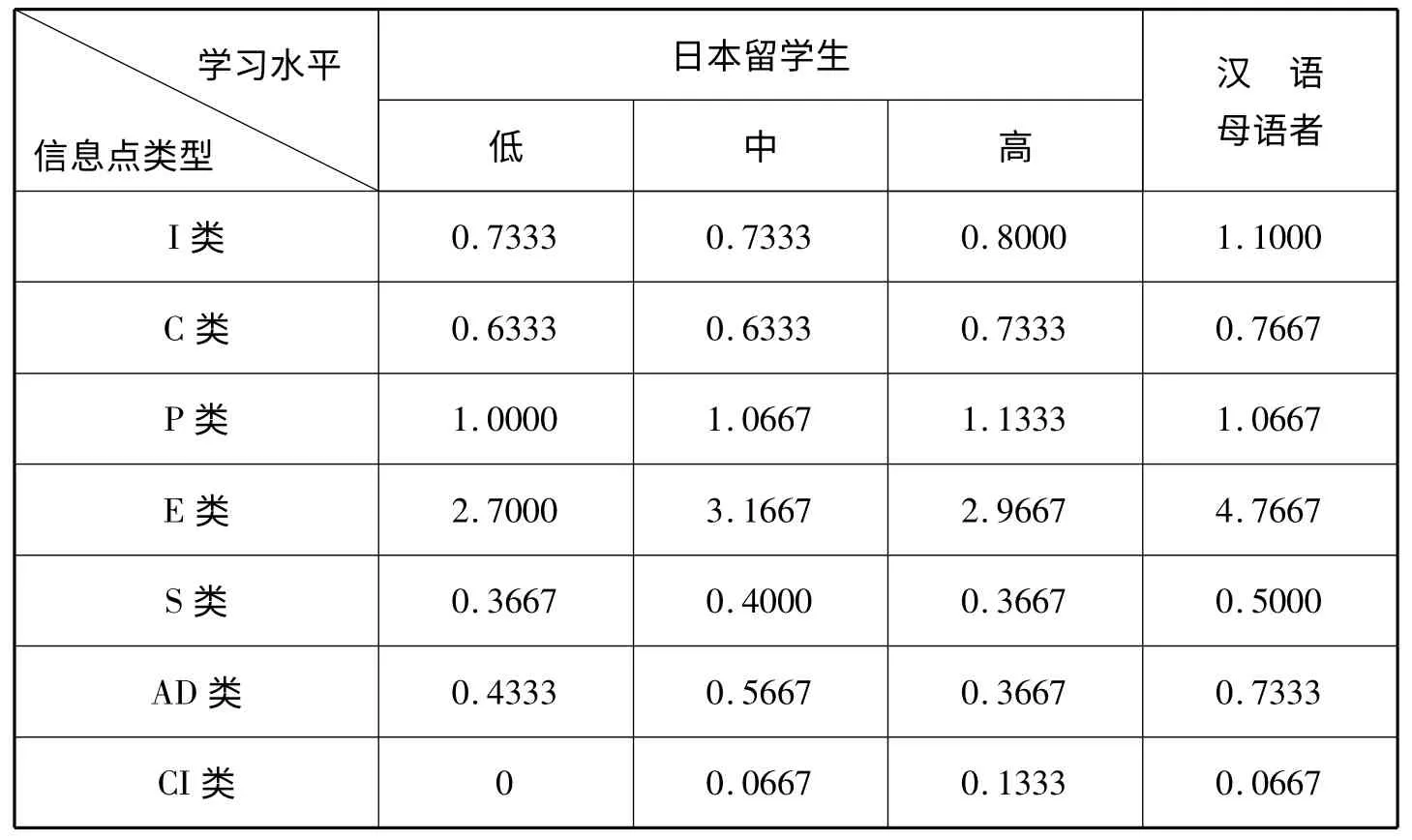
表2 日本留学生及汉语母语者样本不同类型信息点数量的均值
日本留学生块状信息配置能力的发展特点表现在以下几个方面:
第一,日本留学生块状信息配置能力呈现由低到高逐渐向汉语母语者靠拢的趋向。具体来说,这种趋向主要表现在两个方面:一是样本信息点总数的均值。根据图三,日本留学生在三个水平段上的均值分别为6.8667、7.5667 和7.5000,高水平阶段的均值虽然稍有下降,但整体仍呈现向汉语母语者逐步靠拢的趋势(CT 组的均值为10.000);二是各信息层信息点数的均值。根据表1,各信息层的信息点数均值皆呈上扬态势。
第二,日本留学生块状信息配置能力的发展均呈现先快后慢的特点。根据图三,日本留学“低-中”阶段上,均值增加了0.7000,增幅为9.25%,但在“中-高”阶段上,均值不仅未增长,还下降了0.0667。“低-中”阶段上的能力发展速度与变化幅度显著高于“中-高”阶段。
第三,P 类信息点的配置数量基本不受块状信息配置能力发展的影响;E 类信息点的配置数量随学习者水平的变化而产生较大幅度的变化。根据表2,不同发展水平的日本留学生配置在样本上的P 类信息点的均值与汉语母语者之间基本持平。即,学习者信息配置能力的提升并没有对P类信息点的配置数量产生影响。与P 类信息点不同,日本留学生E 类信息点的数量均值随学习者水平的提升产生了较大幅度的变化。
(三)信息量的习得特点
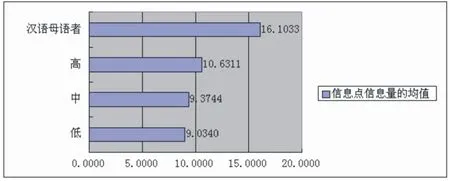
图四 日本留学生及汉语母语者样本的信息点信息量均值
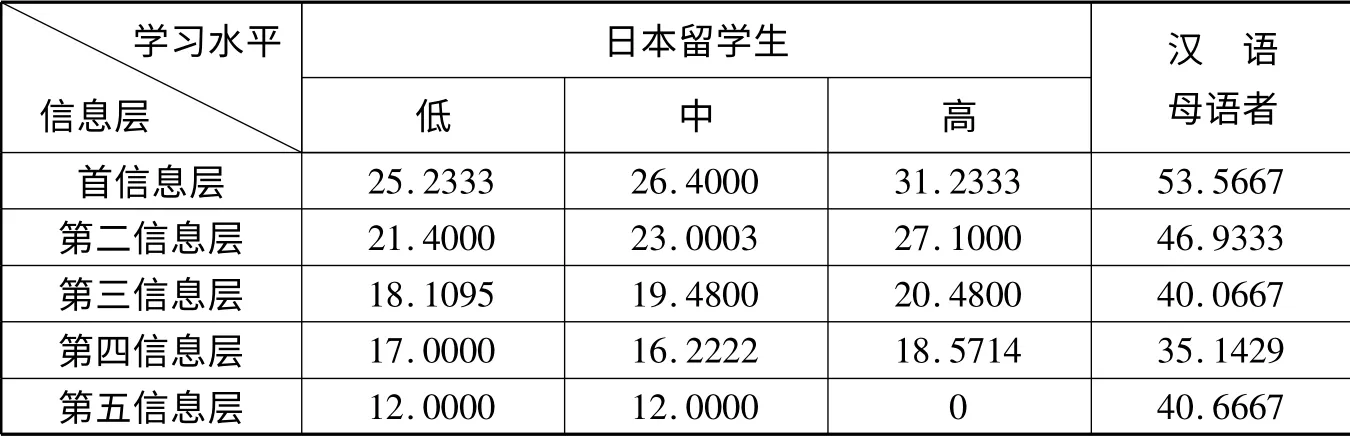
表3 日本留学生及汉语母语者样本的信息层信息量均值
日本留学生信息量输出能力的发展表现在以下几个方面:
第一,日本留学生的信息量输出能力显著低于汉语母语者,与汉语母语者之间存在显著差异。汉语母语者信息点的信息量均值为16.1033。根据图四,日本留学生在三个不同水平段上的均值分别为9.0340、9.3744、10.6311 均值均显著低于汉语母语者。表3 中不同水平日本留学生各个信息层的信息量也与汉语母语者存在显著差异。
第二,信息量输出能力发展的总体倾向是由低到高逐渐向汉语母语者靠拢。具体体现在:信息点信息量均值随着日本留学生水平的提升逐渐向汉语母语者靠拢;各信息层信息量均值随学习者水平的进步逐步向目标语靠拢。
第三,日本留学生信息量输出能力的总体发展态势呈现先慢后快的特点。据图四,日本留学生在“低-中”阶段上,均值增加了0.3404,增幅为3.77%,但在“中-高”阶段上,均值增值为1.2567,增幅为13.41%。即,日本留学生在“中-高”阶段的能力发展速度与变化幅度均高于“低-中”阶段。
(四)信息配列的习得特点
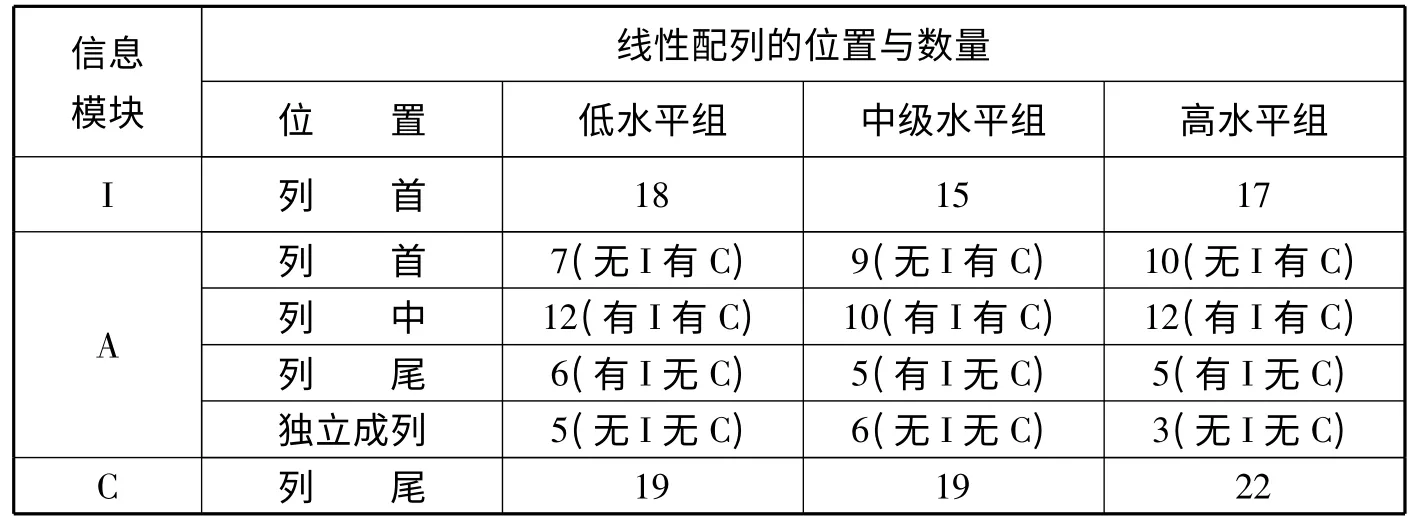
表4 首信息层信息模块线性配列的位置与数量
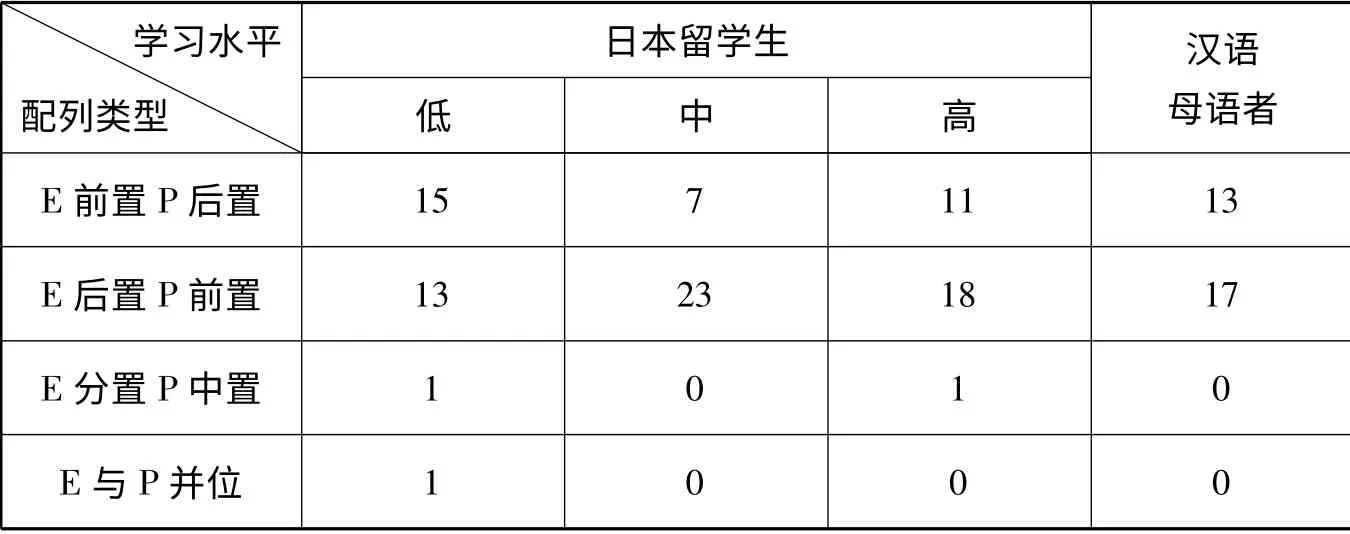
表5 日本留学生及汉语母语者P、E 类信息的配列类型与数量分布
日本留学生信息配列能力的发展特点如下:
第一,不同发展阶段的日本留学生在配列各种不同类型的信息模块时,遵循着与汉语母语者相同的配列原则,拥有着与汉语母语者基本相同的信息配列能力。具体来说,他们都遵循着以下四条原则:一是,核心模块居中原则,即除非辅助信息缺失,核心信息模块及其下位子模块总被配置于线性序列的中部,而辅助信息模块及其下位子模块总被配置在线性序列的首部与尾部,并且辅助信息子模块与核心信息模块的功能关系越紧密,其位置就越靠近线性序列的中部;二是,同质模块类聚原则,即功能相同、性质相同的信息模块倾向于在表层线性序列中毗邻配置;三是,功能关系趋近原则,即功能关系紧密的模块倾向于毗邻配置;四是,P、E 排序可选原则,即论证结构中P 类模块与E类模块的线性排序具有多样性与可选性。因为遵循着共同的配列原则,所以无论是不同发展水平的学习者之间还是学习者与汉语母语者之间,他们的信息配列能力都表现出较强的一致性。比如,当他们在对第一信息层的I、A、C 模块进行配列时,除非I、C 模块缺省,他们都会将I 模块配置在列首,而将C 模块配置在列尾;在对第二信息层的S、AD 模块进行配列时,他们都会把AD 模块配置在紧邻S 模块之后的位置上;而当同质模块(最常见的是EN 类模块)出现时,他们则会倾向于将其毗邻接续配置。
第二,除P、E 模块以外,其余各类模块的之间的配列均不具可选性,不受学习者母语背景和整体篇章建构能力的影响。在论证结构的各种信息模块当中,除P、E 类异质信息的线性排序具有可选性之外,其余各类异质模块之间的排序都是单向的、不可选的。这也就使得不同水平的日本留学生在对同质模块和除P、E 类模块之外的异质模块进行配列时都遵循着相同的原则,使得这些模块之间的配列模式在不同的发展水平段上表现出强烈的一致性,使得学习者的信息配列能力不会随着他们整体篇章建构水平的变化而变化。
第三,日本留学生配列模式的发展趋势是由“E 前置,P 后置”和“E 后置,P 前置”双式并重,逐渐演变为以“E 后置,P 前置”式作为其主导,日本留学生的主导模式由低级到高级逐渐与汉语母语者趋同。根据表5,在三个发展阶段上,“E 后置,P 前置”式配列类型均所占的比例分别为43.3%、76.7%和60%,日本留学生从低级阶段的“E 前置,P 后置”和“E 后置,P 前置”并重,发展为中高级阶段的“E 后置,P 前置”模式为主。
(五)信息模式的习得特点
日本留学生信息模式的发展趋势:
第一,选择性模式的使用率始终高于全息性模式并且二者的使用率比值无向汉语母语者靠拢的倾向。根据表6,日本留学生选择性和全息性模式在低、中、高三个阶段上的使用率分别为60%、66.7%、60%和40%、33.3%、40%,选择性模式的使用率始终远高于全息性模式,并且二者的使用率比值没有体现出向汉语母语者靠拢的趋势。
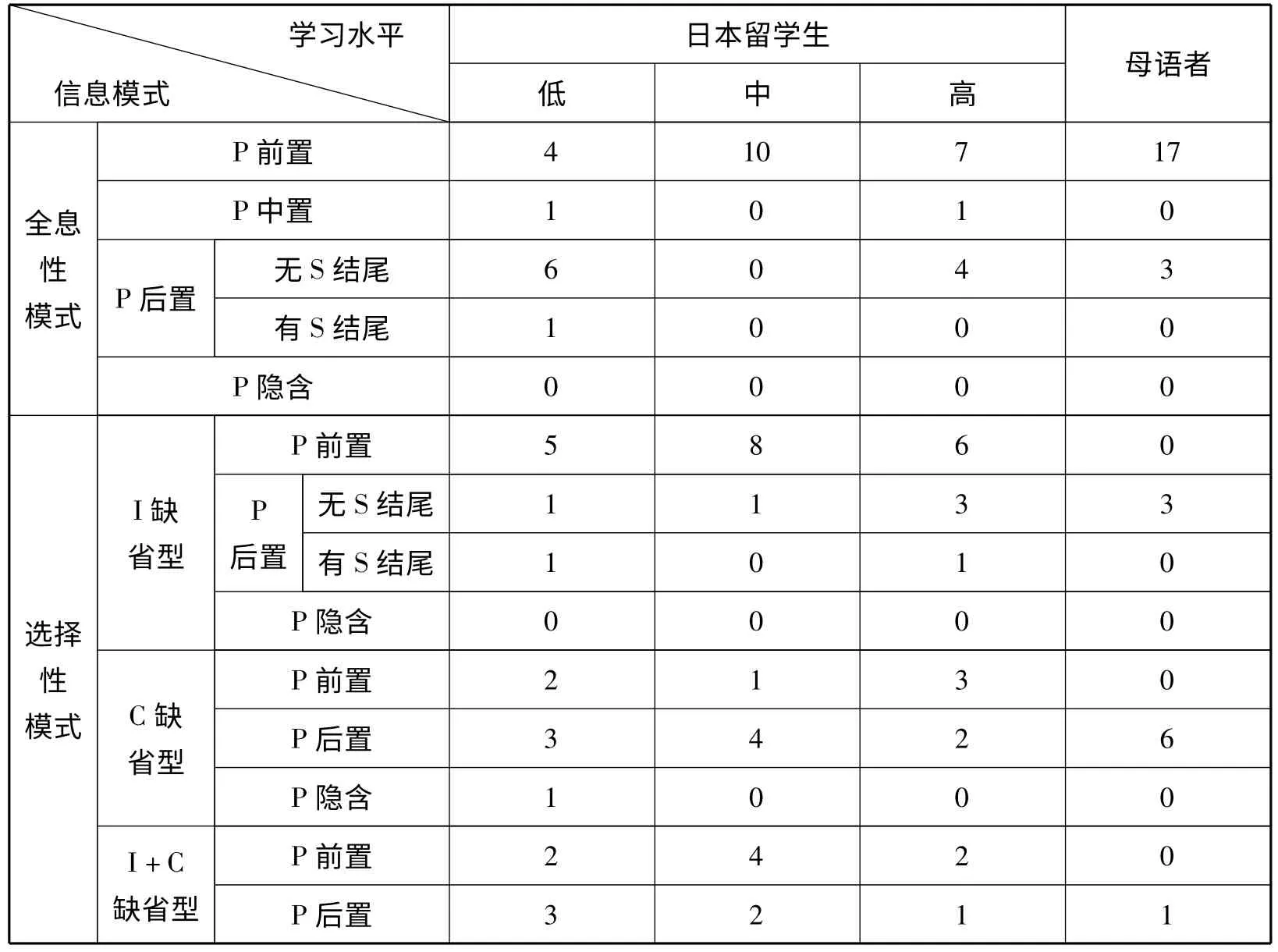
表6 日本留学生及汉语母语者信息模式的类型与数量分布
第二,“I 缺省”型为主导性选择性信息模式,使用数量随留学生水平的发展逐渐增加。日本留学生“I 缺省”式选择性模式在低、中、高三个水平段上占总选择性模式数量的比例分别为38.9%、45%、55.6%,始终是占主导地位的选择性信息模式。从整体的发展趋势看,该模式的使数量逐渐上升,使用率也远高于汉语母语者。
第三,“P 前置”模式的使用率随留学生水平的提升而增加,且为选择性信息模式的主导类型。“P 前置”模式在低、中、高三个阶段上的使用率分别为43.3%、76.7%和60%,其使用趋势为不断上升。具体到选择性信息模式,“P 前置”式的使用率在三个水平段上分别为50%、65%和61.1%是占绝对主导地位的选择性信息模式类型。
(六)信息模块间结构关系的习得特点
日本留学生模块结构关系配置、运用能力习得的特点主要表现在:
第一,日本留学生配置、运用各种结构关系的能力随着学习者水平的提升逐渐向汉语母语者靠拢并且整个发展过程呈现先快后慢的特点。汉语母语者所有结构关系使用量的均值为4.6667。根据图五,日本留学生在三个不同水平段上的均值分别为3.2333、3.4667、3.4333,虽然均值均低于汉语母语者,并且“中-高”阶段均值略有下降,但从总的发展趋势来看,使用量的均值都在随着学习者发展水平的提升逐渐向汉语母语者靠拢。从各阶段均值的变化来看,日本留学生在“低-中”水平段的增幅为7.22%,发展速度相对较快,在“中-高”段则速度放缓,均值略有下降。即,结构关系配置、运用能力的发展呈现出先快后慢特点。
第二,主辅型关系与平列型关系的配置量均值虽低于汉语母语者但均呈上升态势;各个不同水平段上的优势结构关系类型均为主辅型并且其发展水平明显高于平列型。汉语母语者主辅型与平列型关系的配置量均值分别为3.1000 和1.5667。日本留学生主辅型与平列型关系在三个不同水平段上的均值分别为2.4667、2.5000、2.6667 和0.7667、0.9667、0.7667。对比以上几组数据,可以发现日本留学生主辅型关系与平列型关系均值的发展虽均呈上升趋势,但却均未达到汉语母语者的水平。并且,通过主辅型关系与平列型关系的比较,我们也发现日本留学生在各个水平段上,主辅型关系总的配置量以及均值都明显高于平列型关系,其与汉语母语者之间的差距也明显低于平列型关系。这不仅显示出主辅型关系与平列型关系的发展均有向汉语母语者靠拢的倾向,而且也说明主辅型关系的发展水平明显高于平列型,是日本留学生各个发展水平段上的主导结构关系类型。
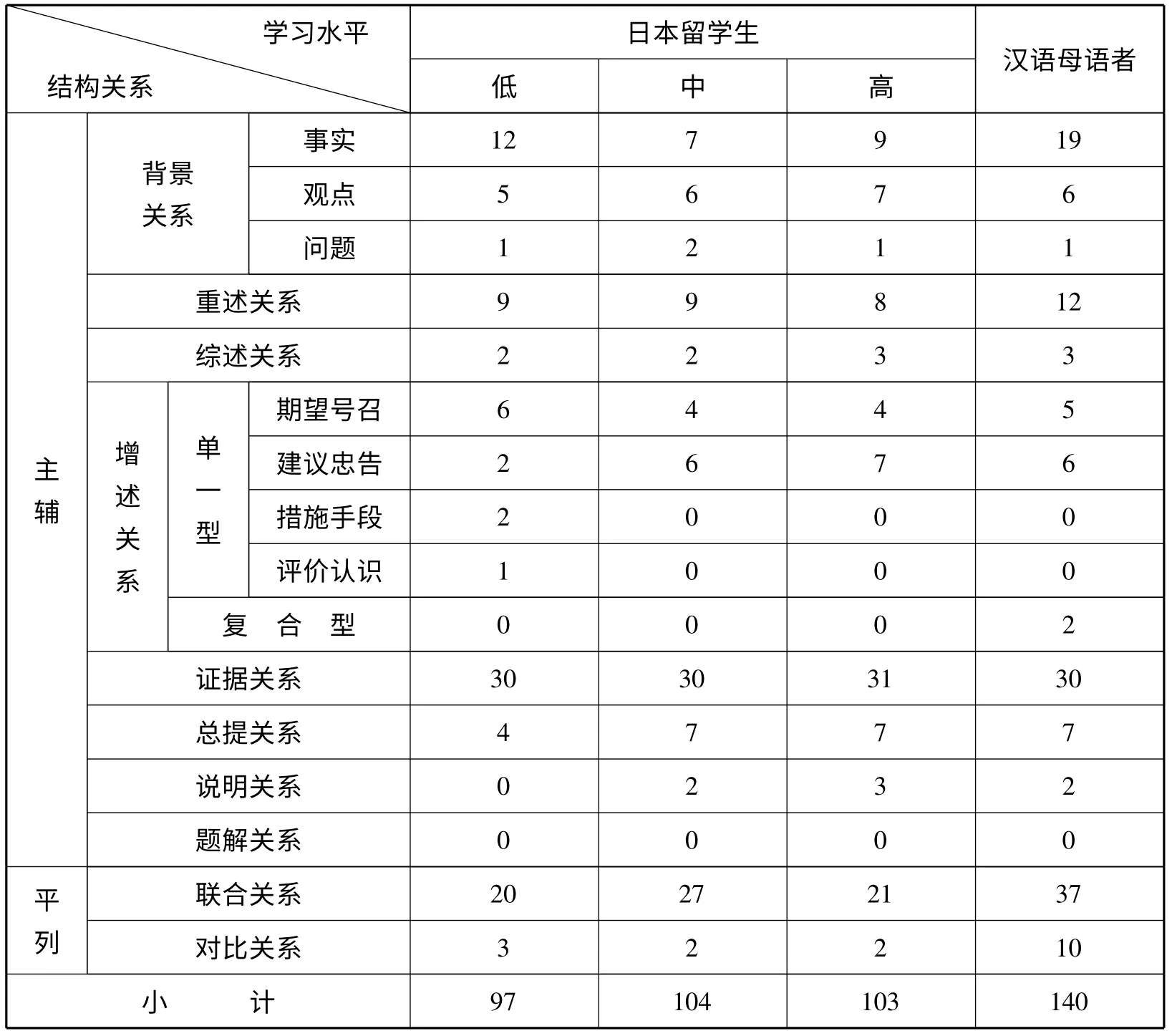
表7 日本留学生及汉语母语者各种结构关系类型的使用频次
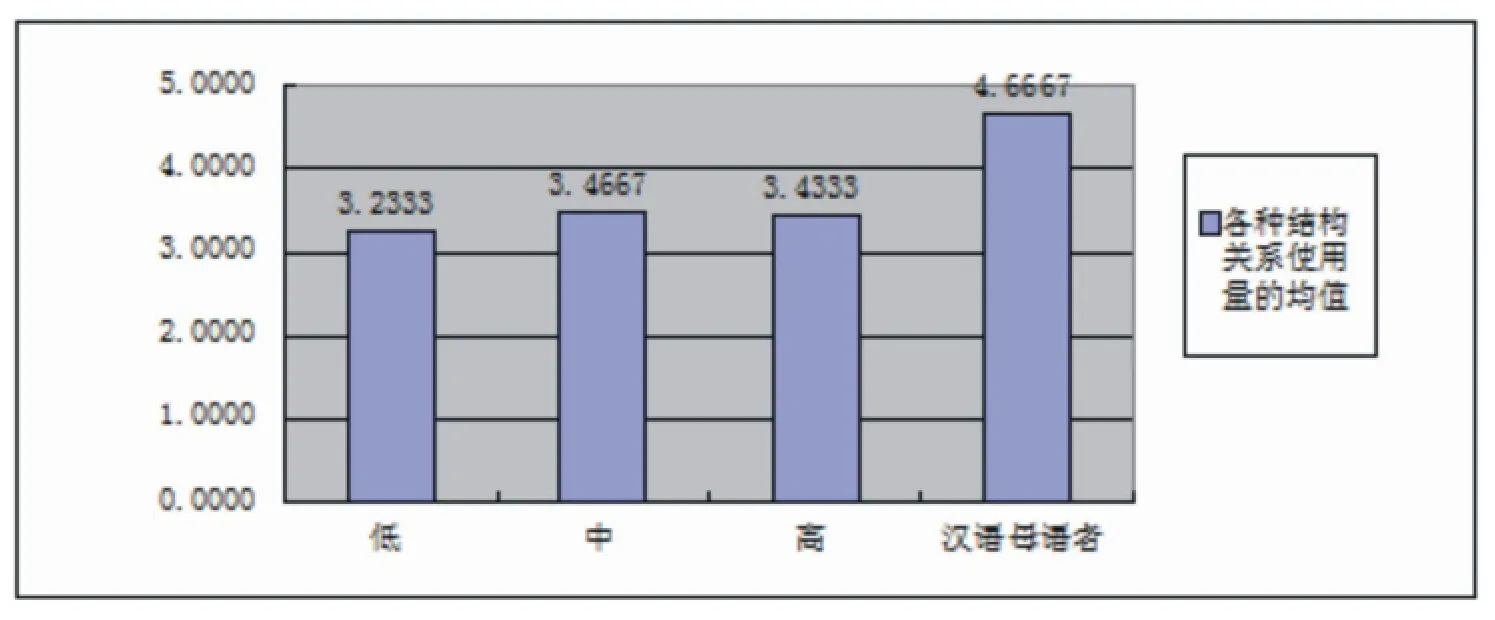
图五 日本留学生及汉语母语者各种结构关系使用量的均值
第三,日本留学生在各个发展阶段上配置的结构关系类型与汉语母语者之间存在较强的一致性。根据表7,日本留学生在各个发展阶段上使用到的结构关系类型共有九种,而汉语母语者使用到的结构关系也是九种。通过母语者与学习者群体之间的对比,可以发现母语者与低水平日本留学生之间的差异主要表现在前者使用了“说明关系”,但后者未使用;中高阶段使用的结构关系类型则完全相同。也就是说,除了“说明关系”以外,日本留学生在各个水平段上配置的结构关系类型与汉语母语者之间存在较强的一致性。
第四,日本留学生各个水平段上的优势结构关系与目标语一致均为“背景关系”、“证据关系”和“联合关系”,但在整个结构关系系统中所占的比重高于目标语。根据表7 三种结构关系在低、中、高三个水平段上的使用率分别为70.1%、69.2%和66.9%,是占绝对优势的结构关系。目标语语篇中三种结构关系的总使用率为66.4%,同为优势结构关系,但比重低于日本留学生。即,与目标语相比较,日本留学生更倾向于高频使用这三类结构关系来构建宏观信息模块之间的功能网络。
第五,“对比关系”在各个水平段上的使用率远低于汉语汉语母语者。“对比关系”在低、中、高三个阶段上的使用比例分别为3.09%、1.92%、1.94%,远远低于母语者7.14%的使用率。这进一步说明日本留学生偏好高频使用某几种核心结构关系来组建论证性语篇的信息网络,对非核心结构关系采取选择性使用的态度。
(七)日本留学生论证性语篇信息结构习得的总体特点
通过对篇章信息结构各个构成参项发展过程与习得特点的分析,我们将日本留学生论证性语篇信息结构的总体习得特点总结为以下几点。
1.习得过程的有阶性与无界性。日本留学生篇章信息结构的习得过程中存在着多个不同的阶。阶与阶之间在构成要素的使用量和型例(type-token)的复现频率上存在一定的差异。篇章信息结构的习得过程是一个由低到高逐渐进阶的过程。无界性表现在日本留学生篇章信息结构不同的阶之间呈连续状态,缺少明晰的界限,无法通过一个或几个排他性的阶特征将不同的阶清晰地划分开来,同时也表现在日本留学生不同的习得阶所拥有的特征、型例不具有阶限制性,可以在不同的阶之间相互渗透、扩散。
2.演进方向的明晰的倾向性与个别要素发展的僵化性特征。篇章信息结构各个参项的发展表现出明显的倾向性,即由低到高逐渐向汉语母语者靠拢。具体来说,日本留学生篇章信息结构的层级建构能力、块状信息配置能力、信息量输出能力以及模块结构关系配置能力均随日本留学生发展水平的上升,呈现从低到高逐渐增强,逐渐向母语者靠拢的倾向。配列模式“E 后置,P 前置”的使用量与使用比重逐渐向目标语靠拢。僵化现象主要体现在信息模式的发展上,具体来说,日本留学生在各个发展阶段上均以选择性模式为主,全息性模式的使用率一直低于选择性模式,并且无向母语者靠拢的倾向。也就是说,对于日本了留学生来说,其论证性语篇的主导信息模式存在“化石化”特征,并没有随其整体篇章能力的发展而向汉语母语者靠拢。
3.发展轨迹的变异性。日本留学生论证性语篇信息结构不同构成参项的发展轨迹不尽相同,发展特点具有一定的变异性特征。具体来说,日本留学生的层次建构、块状信息配置、信息配列、信息模式建构能力以及模块结构关系配置能力的发展特点是先快后慢,而信息量输出能力的发展特点则是先慢后快。
4.习得难易度与发展水平的差异性。不同的构成参项其习得的难易程度与发展水平不尽相同:层级建构能力、信息配列能力以及信息模式组建能力的习得难度较低,发展速度较快,发展水平较高,与汉语母语者之间的差距较小;信息量输出能力发展相对缓慢,发展水平较低,与汉语母语者之间的差异度大;块状信息配置能力和模块结构关系配置能力习得难度与发展水平居中。
5.型例量变的主导性。日本留学生不同的发展水平段共享着大多数的特征与型例,它们之间的差异主要体现在型例的量的增减上,而非型例的有无与特征的损益上,宏观信息结构的发展过程是以量差异为主导的一个阶的连续统。以宏观信息模块之间的功能结构关系选配为例,日本留学生在不同的阶段上共使用到了九种功能关系,其中日本留学生在低水平段上使用到了除“说明关系”之外的八种关系,中、高级水平段上使用到了全部的九种关系。即功能关系类型在各个阶上的变化度是非常有限的。与这种有限的型例增减相反,日本留学生共享的各种功能关系,如背景关系、联合关系、总提关系等,它们的使用频率却随着发展水平的变化呈现出很大的不同。
6.型例选用的偏好性。日本留学生在构建汉语论证性语篇的信息结构参项时,不是“一视同仁”地对待所有可用的模式,而是依托自己的母语背景、语言能力、民族文化、思维特点等选择性地高频使用一种或几种型例,以最省力、高效的方式完成参项的合格构建。这一点最明显的例证就是日本留学生偏好选用“E 后置,P 前置”模式进行信息配列,在不同水平段上均偏好高频使用“背景”、“证据”、“联合”这三种结构关系来组合信息模块之间的功能网络,建构论证性语篇的宏观信息结构。
7.演进过程的系统性。为了能够精细地观察宏观信息结构各个构成要素的习得特点,同时为了量化统计的方便,我们在研究过程中将宏观信息结构分解为了多个不同的参项逐一进行分析。实际上,这些要素都不是孤立存在的,它们之间相互联系,相互影响,共同构建起一个复杂的具有系统性的关系网络。一个要素的发展变化会引发其他相关要素产生相应的反应。这种连锁反应主要体现为两种状态:一种是同增共减、彼此协调的要素间的同向依存状态;另一种是此消彼长、相互制约的要素间的异向互补状态。前一种状态在篇章信息结构系统内集中表现为:信息点与信息模块功能结构关系之间的相互依存,如篇章信息结构中配置的各种功能的信息点增多,相应的各种功能结构关系总的使用量也就升高,某一类或几类功能模块的配置量越高,其所对应的功能结构关系使用量也会越高;信息点与信息层之间的相互依存,如论据类信息模块的下位子模块的层次越多、深度越大,宏观信息结构所具有的信息层就会越多;信息点与信息模式之间的依存,如信息结构中I、C 信息点配置量高的发展阶段全息性模式使用率高,配置量少的发展阶段选择性模式使用率高;信息模式与信息配列之间的依存,如“P 前置”式信息模式的使用率与“P 前置,E 后置”配列类型的使用率呈正相关关系,“P 后置”式信息模式的使用率与“P 后置,E 前置”配列类型的使用率呈正相关关系;信息模块间的功能结构关系与信息模式之间的依存,如背景关系、增述关系、重述关系的配置量越高其全息性模式的使用率也会越高,配置量越低其全息性模式的使用率也会越低。后一种状态表现为:信息点与信息量之间的互补关系,处于同一发展水平段上的语篇,在信息总量大致相当的情况下,其信息点配置总量与每个信息点所含的信息量呈反向关系,即各类信息点的配置量越高,每一个信息点的信息含量就越低,各类信息点的配置量越低,每一个信息点的信息含量就越高;信息模式、信息配置与信息量之间的互补关系,如“P 前置,E 后置”信息模式和配列模式使用率升高,P 模块的信息含量均值就会随之下降。总之,无论是依存关系还是互补关系折射出的都是篇章信息结构自身的系统性以及系统内部各要素之间所具有的种种复杂的依存、制约关系。换言之,篇章信息结构的习得不是某一个或几个构建要素孤立演进的过程,而是一个交织着各种复杂关系的系统化进阶的过程。
四、结 语
篇章信息结构是篇章构建的核心要素之一,了解其内在的习得特点与机制,对对外汉语教学,尤其是中高级阶段的篇章、写作教学,具有重要的理论与实践价值。但从以往的研究来看,我们关注较多的是其静态特征,对其动态的历时发展特点探讨并不多。鉴于此,我们以论证性语篇的信息结构为切入点,在提取信息结构相关构成参数的基础上,采用定量统计与对比分析的方法,对日本留学生篇章信息结构的习得过程与特点进行了尝试性探索。需要说明的是,由于信息结构习得的复杂性以及研究者能力的限制,我们观察到的一些现象与特点反映的可能只是日本留学生这一单一群体习得论证语体信息结构的一个侧面,至于二语学习者信息结构习得的内在机制与普通性规律还需要我们付出更多的努力进行研究。另外,受制于研究精力,本文没有对制约篇章信息结构习得过程的因素进行分析。篇章信息结构的习得到底受到哪些要素的影响?哪些是核心制约要素,哪些是附属制约要素?这些要素又是如何对信息结构的习得过程产生影响的?众多的疑问给我们今后的研究留下了空间也提出了挑战。
注释:
[1]选择该测试题目还有两个重要原因。一是,“HSK 动态作文语料库”中以此为题的日本留学生中介语语篇数量较多,并且呈正态分布。这非常有利于样本的随机抽取以及之后的统计分析。二是,该测试题目要求考生对某市政府的禁烟规定从个人健康和公众利益角度发表自己的看法,具有较强的论证色彩,并且从对成品语篇的核查结果来看,大部分中介语篇是典型的议论文。这非常契合本文的研究目的。
[2]因为“HSK 动态作文语料库”中的成品语篇来自各年的HSK 试卷,所以每篇作文都有体现其相应表达水平的得分。
[3]本文使用的日本留学生汉语中介语语篇均选自HSK 作文,这些语篇都是在限时状态下(考试时间为30 分钟)下完成的。为了保持汉语语篇与中介语语篇获取方式的一致性,尽可能地排除外在的干扰要素,本测验同样采用了限时写作,并将测试时间设定为30 分钟。
杜金榜:《法律语篇树状信息结构研究》,《现代外语》,2007年第1 期。
郭纯洁:《英汉语篇信息结构的认知对比研究》,南京:南京大学出版社,2006年。
黄国文:《语篇分析的理论与实践——广告语篇研究》,上海:上海外语教育出版社,2001年。
廖秋忠:《篇章中的论证结构》,《语言教学与研究》,1988年第1 期。
刘礼进:《英汉篇章结构模式对比研究》,《现代外语》,1999年第4 期。
彭小川:《关于对外汉语语篇教学的新思考》,《汉语学习》,2004年第2 期。
孙新爱:《主位—述位理论和留学生汉语语篇教学》,暨南大学硕士学位论文,2004年。
吴丽君:《日本学生汉语习得偏误研究》,北京:中国社会科学出版社,2002年。
徐赳赳:《现代汉语篇章回指研究》,北京:中国社会科学出版社,2003年。
徐赳赳:《现代汉语篇章语言学》,北京:商务印书馆,2010年。
郑贵友:《汉语篇章语言学》,北京:外文出版社,2002年。
Brown,G.& Yule,G.Discourse Analysis.Cambridge:Cambridge University Press,1983.
Büring,D.On D-trees,beans,and B-accents.Linguistics and Philosophy,2003,26.
Gee,J.P.An Introduction to Discourse Analysis:Theory and Method.London and New York:Routledge,1999.
Kaplan,R.B.Cultural thought patterns in intercultural education.Language learning,1966,16.
Lambrecht,K.Information Structure and Sentence Form:Topic,focus and the mental representation of discourse referents.Cambridage:Cambridage University Press,1994.
Mann,W.C.& Thompson,S.A.Rhetorical Structure Theory:a theory of text organization.USC Information Sciences Institute,1987.
Matalene,C.Contrastive Rhetoric:An American Writing Teacher in China.College English,1985,47.
Mohan,B.A.&Lo,W.A -Y.Academic writing and Chinese students:Transfer and Developmental Factors,TESOL Quarterly,1985,19.
Ricento,T.Comments on Bernard A.Mohan and Winnie Au - Yeung Lo’s“Academic writing and Chinese students:Transfer and developmental factors”.TESOL Quarterly.1986,20.
van Dijk,T.A.Macrostructures:An Interdisciplinary Study of Global Structures in Discourse Interaction and Cognition.Hillsdale,N.J.:Lawrence Erlbaum Assaciate,1980.
猜你喜欢
草原歌声(2020年3期)2021-01-18
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
草原歌声(2017年3期)2017-04-23
国际汉语学报(2016年1期)2017-01-20
中国人口·资源与环境(2016年4期)2016-05-31
外语学刊(2016年4期)2016-01-23
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
郑州大学学报(理学版)(2014年4期)2014-03-01
短篇小说(2014年11期)2014-02-27
