
Design and development of real-time query platform for big data based on hadoop①
2015-04-17 05:33LiuXiaoli刘小利
High Technology Letters 2015年2期
Liu Xiaoli (刘小利)
(*Key Laboratory of Earthquake Geodesy, Institute of Seismology, CEA, Wuhan 430071, P.R.China)(**Jiangxi Branch of China Telecom, Nancang 330046, P.R.China)(***The Chinese Institute of Electronics, Beijing 100036 P.R.China)(****International School of Software, Wuhan University, Wuhan 430079, P.R.China)
Design and development of real-time query platform for big data based on hadoop①
Liu Xiaoli (刘小利)②
(*Key Laboratory of Earthquake Geodesy, Institute of Seismology, CEA, Wuhan 430071, P.R.China)(**Jiangxi Branch of China Telecom, Nancang 330046, P.R.China)(***The Chinese Institute of Electronics, Beijing 100036 P.R.China)(****International School of Software, Wuhan University, Wuhan 430079, P.R.China)
This paper designs and develops a framework on a distributed computing platform for massive multi-source spatial data using a column-oriented database (HBase). This platform consists of four layers including ETL (extraction transformation loading) tier, data processing tier, data storage tier and data display tier, achieving long-term store, real-time analysis and inquiry for massive data. Finally, a real dataset cluster is simulated, which are made up of 39 nodes including 2 master nodes and 37 data nodes, and performing function tests of data importing module and real-time query module, and performance tests of HDFS’s I/O, the MapReduce cluster, batch-loading and real-time query of massive data. The test results indicate that this platform achieves high performance in terms of response time and linear scalability.
big data, massive data storage, real-time query, Hadoop, distributed computing
0 Introduction
The era of petabyte has come and almost gone, leaving us to confront the exabytes era now[1]. In particular, with the maturity of related technologies, more and more spatial data and non-spatial data have been applied[2]. Geographic Information System (GIS) mostly relates to the calculation of high-density data, bringing new problems that such vast amounts of data are hardly saved or processed by any single institutions. In addition, geospatial data, non-spatial data, and logical data requested by GIS processing and analysis are mostly distributed in different computing institutions, either spatially, or logically. The challenge with these applications is how to guarantee satisfactory performance for real-time analysis, while at the same time, supporting millions of location updates per minute[3]. Obviously, it was “too big, too fast, and too hard” for existing database management systems (DBMS) and tools[4]to satisfactorily handle. To address these requirements, DBMS must scale up while maintaining good load balancing and high up-time[5]. These challenges call for a new stack (or many alternate stacks) of highly scalable computing models, tools, frameworks and platforms, etc., being capable of tapping into the most potential of today’s best parallel and elastic computing facility-cloud computing.
Apache Hadoop is a framework for supporting data intensive applications on a cluster[6]. The Hadoop ecosystem consists of three main components: Hadoop Distributed File System (HDFS), Hadoop MapReduce and HBase[7,8]. A Hadoop framework and its major subprojects are shown in Fig.1. The HDFS is a distributed file system designed to be deployed on low-cost commodity hardware with high fault-tolerance[9]. HDFS is widely used in research for its open-source feature and advanced architecture. It mainly settles the massive storage problem and data consistency[5,10]. MapReduce is a distributed computing framework for large datasets and has two computation phases: map and reduce. For a complex computation task, several MapReduce phase pairs may be involved. Hbase is an open-source implementation of BigTable, and uses HDFS as its underlying data-storage platform. Unlike the two-dimensional tables of traditional RDBMS, HBase organizes data in a three-dimensional cube.

Fig.1 Major subprojects and their relation of Hadoop framework
With this in mind, this paper proposes a real-time query architecture that fits big data cloud computing based on the Hadoop ecosystem. By comprehensive design, experiments, and analysis, we study the key technologies used for the architecture. The experimental results indicate that the new architecture is quite efficient and suitable for huge data processing situation, such as GIS processing and analysis cases.
1 The architecture of real-time query platform for big data
1.1 The overall architecture
The overall objective of this paper is to deal with two aspects on the basis of existing database deployments: (1) a scalability and elasticity of data management software for heterogeneity, distribution, diversity and constant increase of massive data, and (2) an efficiently and effectively operational platform for real-time query and computing. Based on the scale-out theory, we propose a framework for distributed storage of multi-source spatial data on an infrastructure (Hadoop cluster) using a column-oriented database (HBase). This platform should be extensible for new data dimensions, flexible for data updating and query, and accord with spatial data characteristics for load balancing, and efficient for public and professional users on the Web. The cloud computing architecture for massive spatial data is depicted in Fig.2, and consists of four tiers: distributed data tier, data storage tier, data processing tier, and data display tier.

Fig.2 An overall architecture for big data cloud computing platform
1.2 Distributed ETL data tier
For big data storage, there must be more than one kind of databases running concurrently when accessing data. This tier would shield different data sources provided by various databases, and provide database access services, so that the system can adapt to handle storage requirements of massive data, and has good scalability and completeness. Distributed ETL data tier is a basis of the entire platform for collecting, cleaning, migrating, transforming and consolidating in the open and distributed web environments. It ensures that structured or unstructured data are loaded and distributed to the file directories of the storage structure in batch; and most importantly, it supports real-time query to data sources including spatial data distributed onto different relational database servers and the Internet log sets.
1.3 Data storage tier
Data storage tier is the core of the whole system to provide the main functions for massive spatial data, such as parallel loading-storage module, parallel query module, etc. These functions on the Hadoop platform can achieve best efficiency by optimizing corresponding components. Based on the distributed database technology, this tier is constructed by the distribution HDFS file system, Hive and Hbase for persistent storage of spatial data.
On this tier, the massive data are parallel processed; the processing results are stored into the distributed database of the system. Parallel loading-storage module provides parallel loading, processing and storage capabilities for massive spatial data, and is divided into the parallel loading module, the parallel ETL module, the parallel storage module, and so on. Parallel loading module imports data from other platforms into HDFS. The parallel ETL module is used for processing the raw data of HDFS to obtain storage data. The parallel storage module provides storage function for the processed data. The parallel query module provides functions for massive spatial data, such as parallel query module, user-defined transaction processing and other functions.
1.4 Data processing tier
Data processing tier mainly provides various models for data analysis according to specific needs. In the processing, the distribution MapReduce computing model and data tools, such as Pig and Hive, are mainly used for bulk processing of mass data[11]. The storm streaming computing system can meet the needs of real-time data computing with high performance. According to the different thematic applications and special needs, analysis models which should be established include mainly as follows: the top model of application download, user location model, user online navigation model, spatial statistical model, spatial analysis model, thematic mapping model, and so on.
1.5 Data display tier
The data display tier provides convenient, easy and friendly interface for users. Ordinary users can browse and query the data through the pages, and advanced users can use open data by the open API platform. It is also responsible for responding to user query operations, submitting query requests, receiving and presenting the query results. Besides, the data display tier also provides management support service to ensure the normal operation of the system for the cluster and system administrator, such as ETL task management, the cluster hardware and software management, cluster monitoring and system management.
2 Functional design of real-time query platform for big data
2.1 Functional design of distributed ETL data tier
Distributed ETL data tier is a universal integrated model that provides components for data importing, data pre-processing, batch processing, data statistics, data query, and so on. By calling the generic integrated model, parameters of various different modules can be filled for configuring corresponding applications. This tier mainly consists of the following functions:
(1) The front Web management interface is responsible for ETL task monitoring, and ETL service scheduling.
(2) The ETL scheduling clusters are responsible for task scheduling. The data files must be stored into local tasks which are saved on NFS file system or the HDFS file system for unified management.
(3) The ETL meta-database is responsible for managing all task information. The primary backup is built by MySQL in order to ensure high availability of meta-database. ETL scheduling clusters perform scheduled tasks by calling the tasks from the ETL meta-database.
When a traditional DBMS is migrated to the cloud computing Hadoop, existing database becomes data source. There are different types of data sources, of which implementation ways in detail are quite different. For example, there is a variety of connection ways to Hbase. So, it is necessary to extracting, transforming and loading for different sources. Workflow of the distributed ETL includes the following:
(1) Data extraction. Massive log data of the data acquisition system, structure data of the ODS system, and text files or the image data are extracted by the distributed ETL.
(2) Thematic processing. For the massive data from multi-resource systems, it is necessary to pre-process according to different thematic needs on the ETL tier. When only computing resources are needed, the open kettle tool is acceptable. With increasing amounts of data, complex operations on the source data, such as progressive scan, filter, and convert are difficult to complete by a single server, but easy to accomplish by batch processing from the distributed ETL. For higher performance of real-time processing, Strom is also integrated into the platform, and is the perfect complement to the Hadoop.
(3) Data loading. The pro-processed data is loaded into the distribution HDFS file system. Data pre-processing can be implemented by statistical indicators defined by Pig scripts or SQL-like language to dynamically generate MapReduce tasks. These tasks are used to compute and assemble mass spatial data, and the processing results will be stored into HDFS by file format, which can be exported as the desired format through the ETL tool at any time.
2.2 Functional design of data storage tier
The data storage tier provides components for distributed storage for data loaded by the ETL platform, supplied for the data processing tier and the data display tier, compressed storage for the processing results from the data processing tier. With the huge spatial data and log data, it is precipitously difficult for data storage, data computing and data query; many inevitable advantages of traditional relational database limit itself performance. The HDFS is a basic storage infrastructure of distributed computing with high fault tolerance, and can be deployed on cheap hardware device. Thus, the HDFS can be used to store massive spatial data sets in the Reduce way and provide high throughput of concurrent read/writes.
According to application requirements, the carriers of the data storage tier include the HDFS, HBase clusters, Hive clusters, ODS, and EDW. Unprocessed source datasets will be stored into HDFS by ETL tools. As the underlying storage for Hbase and Hive, HDFS is responsible for data cleaning, data conversion, data pre-processing, and storage of transformed source data and the result data to display. User data and web log data will be stored into the Hbase as a column family. The HBase clusters can also deposit the result data which should be queried in real time, no matter it is structured or unstructured. Hbase is to provide Bigtable-like[7]storage (designed to scale to very large databases) for HDFS. HBase stores column families physically close on disk, so that items in a given column family have roughly the same read/write characteristics. As a result, query efficiency of HBase is so high that it is mainly used to real-time query and display of mass spatial data. Hive can be used to map structure data to a table, which can be queried and counted by the HiveQL language. The Hive clusters are used to store structured data which is mainly used for data analysis. If the processing results of the data processing tier is low volume, they can be returned into ODS and EDW, and are used for data analysis and report display.
2.3 Functional design of data processing tier
The data processing tier provides components for table association, data statistics and analysis, etc, and forms the terminal application data. The Hadoop platform makes use of MapReduce programming model to effectively segment and reasonably allocate massive data in order to realize high efficient parallel processing. This platform uses preloaded Hive and Pig tools to initially perform data processing requests from users. That is, we use the Pig language to complete initial processing network log files and multi-source spatial data, and use the HiveQL language to complete statistics of these data. Then the above two execution languages are transformed into MapReduce programs to perform data analysis.
MapReduce has two computation phases: task decomposition and result collection. Map is responsible for regularly shredding a large task into multiple tasks, Reduce is responsible for gathering all processing results of partitioned tasks and getting the final result. That is, massive data read from HDFS is partitioned firstly by Map into many small data clusters, and then respectively and parallelly processed by corresponding TaskTracker nodes of the Hadoop clusters. The processing results will be distributed to the file directories of HDFS.
A complex data analysis task usually includes many functions which need to be linked together by much MapReduce homework according to the linear or nonlinear ways[9]. Design idea of this paper includes two steps: (i) to deal with requests submitted by users into Pig or HiveQL languages; (ii) to call MapReduce program to process corresponding data. The entire data processing of MapReduce programs have been packaged. In order to improve the efficiency of cluster computing and task scheduling, computing nodes and data storage nodes should be laid on the same nodes or the same racks.
For data processing tasks which are periodically executed and scheduled, and the case in particular that the execution of a task dependent on the completion of other tasks, it is necessary to control execution orders and adaptive to different conditions of multiple MapReduce programs[12]. Data processing tasks are usually performed by asynchronous ways before the workflow reaches the next node; it is to wait until the task of the next node is on the end[13]. Therefore, a trigger mechanism has been designed to judge whether the task of each node is completed. That is, the module makes use of multiple MapReduce jobs connecting through ETL tools to complete the detection of node task.
Hadoop is not as good at real-time computing as we expect, but the Storm computing frame is very suitable for streaming data processing. Therefore, this paper uses YARN that is a new Hadoop Explorer to integrate the Storm frame. Storm computing is mainly used for low-latency processing, while Map/Reduce is used for batch processing. Meanwhile, the data will be shared between them.
2.4 Functional design of data display tier
The data display tier is mainly used for effective and unified management, configuration, monitoring of the big data computing platform, query and analysis of the network traffic. The module contains the following six components: task management, cluster monitoring, cluster hardware management, comprehensive inquiry, system management and open APIs.
(1) The module of Task management is responsible for unified scheduling, monitoring and management of cluster tasks, and consists of three sub-modules: ETL task flow diagrams, MapReduce task scheduling and MapReduce task monitoring. The module of ETL task flow diagrams is used to create ETL tasks, task execution series, and task running loops. The module of MapReduce task scheduling is used to adjust the allocation of resources, time distribution, and the executing order of tasks by its own task scheduling management tool of resolving scheduling algorithm to realize customized task scheduling management. The module of MapReduce task monitoring is used to realize monitoring task execution progress for different users.
(2) The cluster monitoring module is used to monitor the whole cluster system, and consists of three sub-modules: Ganglia, Nagios, and Hadoop monitoring module.
(3) The cluster hardware management module is mainly used for asset registration of hardware information of cluster machines to provide help for running maintenance and capacity upgrade of the platform. It consists of five sub-modules: information, the information of the CPUs, hard disks, memory cards, network, and hardware.
(4) The comprehensive query module is mainly used to provide the RowKey range of the Hbase tables in the big data platform by calling the HBase API according to the query conditions, and then HBase returns and displays data specified by the RowKey range.
(5) The system management module is mainly used to set user roles of the system and access permissions of modules, and management of the traffic detail query log and Hbase source table. It consists of four sub-modules: the traffic detail query log, directory management, organization management and table query management.
(6) The open API module provides data interface of the big data platform to specific user groups, allowing other users to make full use of these data by developing their own APIs.
3 Implementation of real-time query platform for big data
3.1 Implement of distributed ETL data layer
The distributed ETL model is implemented by Kettle tools which is open ETL software. How to quickly load log data and multi-source spatial data from the data acquisition system into big data platform is the key of the distributed ETL. LFTP is an FTP mirror technology from Kettle tools of the ETL family, and is a file transfer program based on the command line, and support protocols such as FTP, FTPS, HTTP, HTTPS, HFTP, FISH and SFTP, etc. Obviously, LFTP supports heterogeneous data sources, such as relational database, files, FTP, etc. In addition, it is worth noting that it has a practical characteristic of supporting FXP. That is, file transfer operation between two FTP servers can be performed by passing clients.
In this paper an FTP mirror technology is used to keep pace with data source of FTP. That is to say, the FTP group is responsible for acquisition of the log data and multi-source spatial data, and ensures the timeliness and stability of data acquisition. The ETL group is responsible for loading log files and spatial information files saved on the FTP server into the big data platform, and ensure loading efficiency by parallel loading ways. The implementation consists of four steps:
(1) To deploy LFTP software in the FTP server group;
超声弹性成像检查是影像学检查方式中的一种,在临床中应用广泛。然而从实际工作情况来看,不同的检查方式可能得到不同的诊断结果[1]。有研究指出,超声弹性成像检查的感兴趣区域大小会对诊断结果造成一定的影响,若要提高诊断准确性,则需明确不同感兴趣区域大小对诊断结果的具体影响[2]。本研究以120例乳腺疾病患者的154个乳腺病灶作为研究对象,探讨了小于病灶大小的两倍和大于等于病灶大小的两倍这两种不同的超声弹性成像感兴趣区域大小对诊断结果的影响。具体情况如下。
(2) To create synchronization scripts of log data;
(3) To obtain log data and multi-source spatial data from the data acquisition system;
(4) To store obtained data into local storage space of the FTP group server.
The LFTP technology can not only keep pace with data source of FTP in real time, but also configure corresponding synchronous frequency and storage period according to special needs of the timeliness and stability of data acquisition.
For variable-length file data, filtering and conversion operations are achieved through pig scripts. For fix-length file data, they are firstly loaded into External Hive tables, and then processed by Hive scripts. For real-time ETL processing, the topology of the storm frame can be designed by any language, such as the Java language.
Because this platform is to address multi-source data, including the web log data, user data and multi-source spatial data, etc., it is necessary to create a table for each data. If we import data into Hbase by the record inserting way, the efficiency will be very low, due to the facts that daily data are quite huge. Therefore, this platform adopts a strategy which includes two steps: (i) bulk-loading daily synchronization data into the distributed HDFS file system; (ii) importing these data into HBase table by the Bulkload way.
3.2 Implement of data storge layer

Fig.3 The structure of data storage tier
Data of the big data computing platform need to be imported into the HBase tables in order to query in real time from the data display tier. When data query is performed by Hbase, it is necessary to design the structure of Hbase table according to query requests. Records of Hbase table are stored orderly by row-keys, which is equivalent to a traditional database index. Thus, the key of real-time query is to design HBase row-keys according to query conditions. Characteristics of this storage may lead to problems. For example, if the row-key is designed to be monotone increasing or directly according to the timestamp, when multiple clients import data in the table at the same time, all client requests should enter into the same region server node. In order to avoid the above case and ensure that the design of the row-key meets query conditions and that data of Hbase table is evenly scattered in more than one region of the clusters, the paper uses completebulkload Tool to transform HDFS data to Hfiles which are loaded into the compression tables of Hbase. This design is well-suited to improve the efficiency of bulk loading of massive data.
3.3 Implement of data processing layer
As mentioned above, this system adopts the ETL tool to connect much MapReduce homework in order to finish detection and processing of the task nodes. The process of calling MapReduce by ETL is as shown in Fig.3. The calculation model of the MapReduce is realized mainly by four steps: (1) to establish communication of Kettle and JobTracker, and to submit MapReduce tasks; (2) to initialize a Map task by JobTracker; (3) to create multiple MapReduce tasks on the Hadoop; (4) to exit the startup process after creating a successful task. After a successful startup, the next step is to implement specific computing tasks.
Once a MapReduce task is started up, if callback information of nodes is not received by the ETL polling, this operation of the task will end and rerun. The process which ETL calls MapReduce is as shown in Fig.4.

Fig.4 Workflow diagram of invoking the MapReduce by ETL tool
For data analysis of mass data by Hive, it is necessary to integrate Hive and HBase. In this platform, we use their external API interface of Hive and HBase to communicate with each other. This interface is mainly implemented by the hive_hbase - handler.jar tool class which is as shown in Fig.5. There are two implementation ways of data sharing between Hive and Hbase. The first includes (1) creating an HBase table and importing data into the HBase table, (2) creating a mapping table of Hive and HBase; (3) reading data of the HBase table through accessing the mapping table by Hive. The second consists of (1) creating a Hive table and importing directly data into the Hive table when massive data are imported into the HDFS; (2) creating a mapping table of HBase and Hive; (3) importing data of the local Hive table into the mapping table, and reading data of the Hive table through accessing the mapping table by HBase.
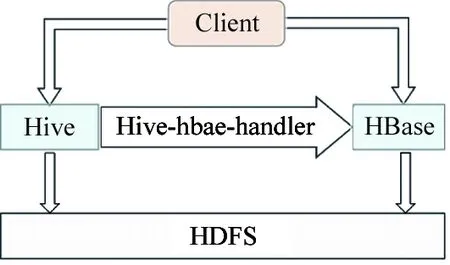
Fig.5 System architecture of HBase and Hive
3.4 Implement of data display tier
In the data display tier, the user’s specific query requests are submitted mainly by web forms and the result is fedback in the form of web pages to the user. To solve interaction between the web protocols and the HBase platform, it is necessary to choose an appropriate interactive language supporting with HBase. JSP is definitely a good choice for our purpose. In this paper the Java language is used to implement the interaction between the data display tier and HBase, and integration of task management, cluster monitoring, cluster hardware management, comprehensive query and system management.
4 Test and analysis
Experiments are designed for two purposes, one for examining the function and the other for testing performance of the proposed real-time query platform. As we are not able to provide an analytical cost model for the GRHM model, empirical results are important in understanding the efficiency of the data structure in real applications. The experiments are performed using a real dataset cluster made up of 39 nodes which include 2 master nodes and 37 data nodes. The tests include functional testing of data importing function and real-time query function, and performance testing of HDFS’s I/O performance, the MapReduce performance, and importing and real-time query performance of massive data.
4.1 Testing of HDFS’s I/O performance
To evaluate the performance of hard disks and HDFS’s I/O, high strength test program of I/O operations is used including TestDFSIO: org.apache.hadoop.fs.TestDFSIO to test reading and writing speeds of the HDFS cluster. TestDFSIO is performed by a MapReduce assignment to read or write files in parallel. All the files is to read or write in a separate Map task, the output of the Map task will produce some statistic results for just processed files. The Reduce task is implemented to gather these statistic results and create a total report.
10 Map tasks are simulated writing respectively 10 files, the size of each file is 1000Mb. The test results are illustrated in Fig.6. We can see that the overall spent time of writing operation is about 14 minutes, 29 seconds, and the average I/O rate is 3.71Mb/s. The same method is also adopted to simulate 10 Map tasks reading respectively 10 files. The test results are illustrated in Fig.7. It can be seen that the average I/O rate is 94.53Mb/s. The results indicate that our design for the HDFS cluster achieves high performance in terms of the average I/O rate.

Fig.6 HDFS I/O writing test

Fig.7 HDFS I/O reading test
4.2 Testing of MapReduce performance
To evaluate the efficiency of MapReduce cluster, the total volume of test data is about 1Gb. We adopt TeraSort:org.apache.hadoop.examples.terasort.TeraSort to implement global ordering of input files according to the Row Key. The complete test includes three steps: (1) Teragen program creates 1Gb data; (2) the created 1Gb data is sorted by Terasort program; (3) the accuracy of sorted 1Gb data is tested by Teravalidate program. The sorted result is right, and the average response time of sorting 1Gb random data is about 56 seconds. The test results indicate that our design for the MapReduce cluster achieves high performance in terms of response time.
4.3 Testing of importing function for massive data
Importing function of massive data is mainly implemented through Hbase’s complete bulkload tool. Therefore, the complete bulkload tool is used to test the function and performance of bulk importing of massive data into HBase database. The ETL tool is adopted to load 1Gb data into HDFS and the complete bulkload tool is used to import these data into HBase table. The Jobtracker can record and display response time of the importing process by monitoring the header.
At present, log data for online users are about 2.7 billion records each hour, the total data volume is approximately 50Gb/h. These data are imported into four different tables at the same time. The whole cluster can handle about 62.8 billion records which requests 1.17 terabytes local disk space every hour. The test results are illustrated in Fig.8. We can see that the response time of importing of massive data into the HBase database is about 1 minute and 30 seconds. The results indicate that our design for the HBase database achieves high performance in terms of response time and linear scalability.

Fig.8 Workflow diagram of importing data into HBase table by completebulkload tool
4.4 Testing of real-time query function
Test of Real-time query function is performed by data query interface of the data display tier. Therefore real-time query is tested at the same time with importing test of Web log data into HBase database. The Web log data are simulated in one hour which is about 2.7 billion records importing into HBase database and queries these data by query interface of the data display tier. In order to compare, data in the first hour are firstly queried, and then data in the second hour are imported into the HBase table, and then queried, and so on, the 7 day data are eventually imported. The query results and response time of each hour are almost the same. Laterly, the same data are imported into the Oracle database, and then queried according to the same query condition. The test results indicate that the design based on the HBase real-time query system achieves higher performance in terms of response time than traditional database.
5 Conclusions
Real-time query operation is the precondition of statistical analysis of spatial data. This paper proposes a real-time query platform of massive spatial data based on the hadoop cloud computing platform. This model is scalable, flexible, efficient and low-cost. To obtain high efficiency, we propose a physical storage structure which uses the file systems to store spatial information files. This storage structure is suitable for Web servers. A parallel computing method based on MapReduce and HBase technology is also adopted for distributed storage and multi-line processing in order to improve the highly concurrent performance. According to the simulation results, this system achieves higher performance in terms of response time and linear scalability than traditional database. So the proposed platform meets the demands of long-term storage and real-time query of massive spatial data, and be efficient for large number of concurrent users.
[ 1] Che D, Safran M, Peng Z. From Big Data to Big Data Mining: Challenges, Issues, and Opportunities. In: Database Systems for Advanced Applications, Springer Berlin Heidelberg, 2013. 1-15
[ 2] Li W, Wang W, Jin T. Evaluating Spatial Keyword Queries Under the Mapreduce Framework. In: Database Systems for Advanced Applications, Springer Berlin Heidelberg, 2012. 251-261
[ 3] Han D, Stroulia E. HGrid: A data model for large geospatial data sets in Hbase. In: Proceedings of the 2013 IEEE Sixth International Conference on Cloud Computing, 2013. 910-917
[ 4] Madden S. From databases to big data. IEEE Internet Computing, 2012, 16(3): 4-6
[ 5] Nishimura S, Das S, Agrawal D, et al. MD-HBase: A scalable multi-dimensional data infrastructure for location aware services. In: Proceedings of the 12th IEEE International Conference on Mobile Data Management, Lulea, Sweden, 2011. 7-16
[ 6] Apache Hadoop.http://hadoop.apache.org/core/
[ 7] Madden S. From databases to big data. IEEE Internet Computing, 2012, 16(3): 4-6
[ 8] White T. Hadoop: The Definitive Guide. 3nd Edition Publisher. O’Reilly Media/Yahoo Press, 2012. 67-72
[ 9] Armbrust M, Fox A. Above the clouds: A berkeley view of cloud computing: [Technical Report], No. UCB/EECS-2009-28, University of California at Berkley, 2009
[10] HBase: Bigtable-like structured storage for Hadoop HDFS, 2010, http://hadoop.apache.org/hbase/
[11] Floratou A, Patel J M, Shekita E J, et al. Column oriented storage techniques for MapReduce. In: Proceedings of the 37th International Conference on Very Large Data Bases, Seattle, Washington, 2011. 419-429
[12] Nykiel T, Potamias M, Mishra C, et al. MRShare: sharing across multiple queries in MapReduce. In: Proceedings of the 36th International Conference on Very Large Data Bases, Singapore, 2010. 494-505
[13] Lee K H, Lee Y J, Choi H, et al. Parallel Data Processing with MapReduce: A Survey. SIGMOD Record, 2011, 40(4): 11-20
Liu Xiaoli, born in 1977. She received her M.S. and Ph.D. degrees from Wuhan University in 2005 and 2008 respectively. She also received her B.S. degree from Henan Polytechnic University in 2000. Her research focuses on mining and application of massive spatial data.
10.3772/j.issn.1006-6748.2015.02.017
①Supported by the National Science and Technology Support Project (No. 2012BAH01F02) from Ministry of Science and Technology of China and the Director Fund (No. IS201116002) from Institute of Seismology, CEA.
②To whom correspondence should be addressed. E-mail: liuxl.j@163.com Received on Jan. 7, 2014*, Xu Pandeng**, Liu Mingliang***, Zhu Guobin****
猜你喜欢
Chinese Physics B(2022年8期)2022-08-31
军事文摘(2021年18期)2021-12-02
军事文摘·科学少年(2021年9期)2021-10-13
含能材料(2021年1期)2021-01-10
家庭影院技术(2020年2期)2020-03-25
学苑创造·A版(2020年2期)2020-03-23
模具制造(2019年4期)2019-06-24
工业设计(2016年8期)2016-04-16
预防职务犯罪专刊(2015年1期)2015-10-22
语文知识(2015年9期)2015-02-28
 High Technology Letters2015年2期
High Technology Letters2015年2期
- High Technology Letters的其它文章
- MPLPK: A mobile path localization protocol based on key nodes①
- RF energy harvesting system for wireless intraocular pressure monitoring①
- A method for retrieving soil moisture from GNSS-Rby using experiment data①
- Research on suppress vibration of rotor misalignment with shear viscous damper①
- Security analysis of access control model in hybrid cloud based on security entropy①
- Improving wavelet reconstruction algorithm to achieve comprehensive application of thermal infrared remote sensing data from TM and MODIS①