
高正确率的双语语块对齐算法研究
2015-04-25 09:56俞敬松王惠临吴胜兰
中文信息学报 2015年1期
俞敬松王惠临,吴胜兰
(1. 北京大学 信息管理系,北京 100871;2. 中国科学技术信息研究所,北京 100038;3. 北京大学 软件与微电子学院,北京 100871)
高正确率的双语语块对齐算法研究
俞敬松1,3王惠临2,吴胜兰3
(1. 北京大学 信息管理系,北京 100871;2. 中国科学技术信息研究所,北京 100038;3. 北京大学 软件与微电子学院,北京 100871)
高质量的自动对齐双语语块,对于机器翻译系统,特别是计算机辅助翻译系统的性能提高有重要作用,而且对于人工翻译以及辞典编纂也都有巨大的应用价值。该文提出基于单词间粘合度与松弛度的语块划分评分方法以及双语语块划分的双向约束算法,使得源语言和目标语言的语块的划分与对齐能相互促进。与传统方法相比,因为无需事先进行双语语块划分,而是在搜索最佳对齐时动态地考察划分效果,故可以减少边界划分错误对对齐结果的影响。该算法获得了远超过传统算法的高正确率。
语块对齐;机器翻译;平行文本;双语对齐
1 概述
英语语块(chunk)的概念最早由Abney[1]提出,代表句子的非递归核心成分,具有句法相关性和不可嵌套性。周强等[2]提出的汉语句子组块分析体系可能是最早的关于汉语语块的研究。对齐的双语语块是在机器翻译研究工作中发展起来的语块扩展形式,程葳等[3]认为双语语块有同样的语义,在翻译上可以互相转换。
双语语块对齐任务可以描述为: 给定输入双语句子,自动进行语块划分并按语义对齐。目前多数算法都是基于统计方法的,输出的对齐概率结果面向机器翻译,人工无法解读。
语块对齐工作缺乏标准规范[4],也没有公开的大规模的标准训练和评测数据。单语语块都很难严谨定义,双语环境中更难。我们认为语块划分要兼顾对齐。从根本来说,语言现象的复杂性是最大的困扰。翻译过程中存在的大量省译、增译、语序调整、意译、兼类、指代等现象加大了双语对齐难度。
我们提出的高质量语块互译对齐,要求系统输出的是人可辨识的有意义结果。译员们获得的是来自计算机的准确的有意义的提示,降低专业译员们的认知负担。在本篇论文中判定是否是语块,除了形式化规则外,主要以人的主观判定为依据:首先语块必须有明确的意义;其次在其他语句中可以重复使用。符合这两条就认为语块划分且对齐正确,没有遵从任何预定义的语法体系。这一点上,本文与其他论文有较大的不同。
本文工作服务于交互式机器翻译等场合[5]: 当人类译员在输入完成一个句子的时候,系统依据原文、机器翻译的假设及概率、目标语言模型等进行可能的提示,译员可判断接受从而加速正确译文的产出速度。这里的译文是人的工作成果,与机器翻译没有可比性。高质量双语语块库作为语言资源之一加入模型体系中,提高译员接受猜测的概率。侧重高正确率的算法将依赖更大规模的语料来保证召回。
高质量语块对齐结果对于机器翻译系统来说也是高价值资源。基于短语的机器翻译系统中,过长的句子由于训练时间太耗时而常常被丢弃,利用高质量对齐语块将长句子“拆解”为较短的互译片段可减少训练时间并充分利用语料。本文的语块对齐工作具有语言中立性。
关于语块的研究早期多使用规则方法。吕学强等[6-7]总结了链语法的连接因子和E-Chunk的对应关系;刘冬明等[8]在实词对齐的基础上划分语块;屈刚[9]尝试了基于句法深层结构翻译不变性的翻译等价对抽取;Macken[10]的工作则利用了短语构成的语言学知识。近期则是统计方法占主流。姜柄圭等[11]是统计方法为基础,综合运用规则方法抽取语块;刘海霞等[12]将既有的语义资源引入计算过程中;诺明花等[13-14]针对汉藏翻译中藏语语料库规模小,giza++对齐结果不可靠的情况进行了探索;Deng[15]提出了语块对齐的生成模型,本文的工作与之公布的MTTK开源系统进行了对比;Liu等[16]使用PLSI技术计算双语语块相似度;Zhao[17]尝试了基于谱聚类的双语词聚类,并基于隐概念流的思想提出了翻译等价对同步生成的图模型;Ma[18]使用了将若干连续的词打包成一个词后反复迭代的方法;Kim[19]将对数线性模型框架应用到了语块对齐任务。
本文在分析和总结前人工作的基础上,创新提出了粘合度与松弛度的概念,分别衡量语块划分时单词间连接紧密程度和松散程度,针对语块划分及对齐提出了多种平行的计算模型及融合算法,并进一步提出了语块对齐时的搜索及扩展算法。
2 语块切分的数学模型的建立
2.1 语块评分方法
给定一个由N个词组成的句子S=w1w2…wi…wN-1wN,将相邻词对wiwi+1之间的间隙记作切分点gi,其取值1、0分别代表划分语块时在该处是否切开。于是,我们可以使用切分点的取值序列G=g1g2…gi…gN-2gN-1代表语块划分。本文为每个切分点gi设置粘合度与松弛度两个属性(取值均为正整数): 粘合度代表wiwi+1之间的连接紧密程度,记作ai,值越大代表连接越紧密;相反地,松弛度代表相邻词对wiwi+1之间的连接的松弛程度,记作ri,值越大代表连接越不紧密。假设已知wiwi+1之间粘合度ai和松弛度ri,语块划分时在切分点gi处应该切开的概率近似为式(1)。
若切分点gi处不应该切开,即wiwi+1被划分到同一个语块中的概率近似为式(2)。
请注意一点,黏合度和松弛度是独立计算的。不同的计算模型有不同诉求,可能对两者的计算都有贡献,也可能只对其中之一有帮助。对句子经过语块划分后,形成若干语块。对于一个包含M个单词的语块C=wi+1wi+2…wi+m…wi+M-1wi+M,其左侧和右侧的切分点gi和gi+M取值为1,而内部所有切分点取值为0,本文使用式(3)来给C在语块划分结果中的好坏程度评分:

2.2 黏合度与松弛度计算方法
本文使用了多种模型分别计算黏合度和松弛度,包括多种自然语言问题的研究成果,例如,依存句法分析,特定成分识别(如时间表达、命名实体)等,其中双语划分镜面约束是利用GIZA++词语对齐结果矩阵让互译句子对的语块划分互相约束、互相促进,这是其他人的工作中没有讨论过的创新做法。
由于每一种特征模型都可以给出每一个词间切分点gi黏合度和松驰度,由此构成了一个巨大的状态空间,我们的任务就变成了对每种特征权重进行寻优,然后进行融合。在本文工作中,判定经验公式定义的合理与否及取值方法,还有不同影响因素之间的权重关系,均主要靠参数寻优过程来解决。
以命名实体识别特征模型为例,假如句子S内部有包含M个单词的连续单词串wiwi+1…wi+M-2wi+M-1构成一个命名实体,如人名、地名、机构名等,使用公式(4)计算受影响的各个切分点的黏合度,ai,λ,θ为比例因子。
其中WNE为命名实体权重,使用公式(5)计算各个切分点的松弛度ri。
r′k=rk+WNE·θ,
2.3 语块划分评分方法
假设包含N个单词的句子S经过语块划分(用G表示)得到了K(1≤K≤N)个语块S=C1C2…Ck…CK-1CK,使用公式(6)评估语块划分G的好坏程度。

2.4 语块互译对相似度计算方法


2.5 语块对齐表示方法
给定源语言句子S和目标语言句子T,假设对S和T完成了语块划分和对齐后,S由K个语块组成,用X1X2…Xk…XK-1XK表示,其中Xk代表S的第k个语块,T由L个语块组成,用Y1Y2…Yl…YL-1YL表示,其中Yl代表T的第l个语块。语块对齐结果可以用一个目标语块偏移向量A=A1A2…Ak…AK-1AK来表示,向量的长度与源语言语块个数相同,并满足:
1. 如果第k个源语言语块有对应的目标语言语块,则Ak代表第k个源语言语块与第Ak个目标语言语块对齐。
2. 如果第k个源语言语块没有对应的目标语言语块,则约定Ak=0。
3. 如果第l个目标语言语块没有对应的源语言语块,则l的值不应该出现在对齐向量所有元素的取值集合中,即l∉{Ak|1≤k≤K}。
图1为一个使用目标语块偏移向量A来表示语块对齐结果的例子。

图1 一个用语块偏移向量表示语块对齐的例子
上图中,横坐标从左到右为源语言词序列,纵坐标自上而下为目标语言词序列,粗线条形成的单元格划分语块序列X1,X2,…,X8以及Y1,Y2,…,Y7。最下面的一行单元格代表目标语块偏移向量A1,A2,…,A8,取值代表对齐,A6=0代表该列上的语块没有译文语块。我们研发了专门的Excel程序,以图1为模版辅助语料的人工标注及修改以及对齐数据的自动回收和展示,其标注效率和用户亲和程度超过其他方案。
2.6 语块对齐评分方法
在源语言句子S和目标语言句子T的语块划分分别是GS、GT的情况下,将语块对齐用目标语块偏移向量 A 表示,本文使用公式(10)计算语块对齐A的分数。

由于本文将语块划分与对齐当整体考虑,故将划分与对齐的综合评分函数定义为源语言划分分数、目标语言划分分数、二者对齐分数的乘积,如式(11)所示。
3 搜索寻优算法
本文提出语块对齐搜索算法关键数据结构是一个限长N-Best列表,列表的每一项用以存储当前划分GS、GT,当前对齐A,以及划分与对齐总分数FAll。 向N-Best列表插入新的元素时,新插入的元素自动按照总分数FAll排序,列表饱和时,排名最靠后的元素则被自动剔除。算法流程如下:
1. 构造初始对齐对(3.1节),计算其总分数,插入N-Best列表;
2. 随机选取出候选对齐,修改候选对齐(3.2节),计算新对齐与候选对齐之间的总分数增益;
3. 若增益大于0,则将新的对齐也插入N-Best列表;
4. 若不满足终止条件,转到第2步。
算法设置的默认N-Best列表长度为10 000,默认的终止条件为了N-Best列表前三名总分数的平均值连续1 000次不变。新对齐与候选对齐之间的总分数增益定义为式(12)。
其中A′,G′S,G′T,K′,L′分别为修改对齐后形成
的新的对齐、新的源语言语块划分、新的目标语言语块划分、新的源语言语块个数,新的目标语言语块个数。
3.1 构造初始对齐
GIZA++词语对齐工具*http://www.statmt.org/moses/giza/GIZA++.html能产生两个方向词语对齐结果,对称化处理可以得到合并的词语对齐结果。但在本文工作的语境下, 我们期望的是在正确的前提下得到更长的对齐对。图2带有“@”符号的单元格矩阵为GIZA++词语对齐结果。

图2 使用Excel 作为语块对齐的人工标注和结果检查交互界面
词语对齐矩阵中所有的实词(主要包括名词、动词、形容词)暂可看作互译语块,所有剩余单词看作翻译为空的语块。初始对齐从GIZA++词语对齐开始,放弃了句子对中意译对齐语块带来的计算量和搜索空间,提高了搜索速度,但代价则是包含意译现象过多的实例中受GIZA++词语对齐错误影响较大。
本文利用以下规则对不满足语块对齐要求的部分进行冲突消解处理,提高初始语块对齐质量:
1. 词语对齐矩阵中的词在水平或者垂直方向上连续多个对齐时,例如,“assault on”、“exchange rate”,则将其绑定为语块,否则,每个单独的词语独立看待,没有对应的则对空。
2. 对齐冲突时,分别尝试当前源语块与每个目标语块对应,保留相似度最高者,删除的语块看做空译语块。本例中“的”与“the”的词语对齐关系被删除,最终“the”构成空译语块,“的”与 “of an”构成互译对。
3. 对齐矩阵中词对齐单元格形成“+”形、“T”形、“L”形或更复杂的连通区域时绑定对齐,例如,“越来越 充分”与“are increasingly convincing”的词语对齐信息构成“L”形,可构成对齐。
4. 反复重复上述过程,直到不存在冲突。
3.2 修改与扩展候选对齐
在以上计算结果的基础上,首先利用相邻词扩展互译语块,其次合并相邻互译语块。相邻词扩展时,从互译语块的边界出发,向相邻的八个方向扩展,如图3所示。
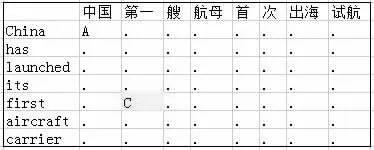
图3 选取互译语块示例
其中“第一”和“first”是一对可以通过查询词典得到的互译实词,初始候选已对齐,其扩展方式有8种如图4。如某方向上有属于其他互译语块的词,则放弃扩展。合并相邻互译语块的方法为随机选择两个相邻的互译语块,将二者以及夹在二者之间空译语块合并,如图5所示。

图4 互译语块向周围八个方向扩展示例
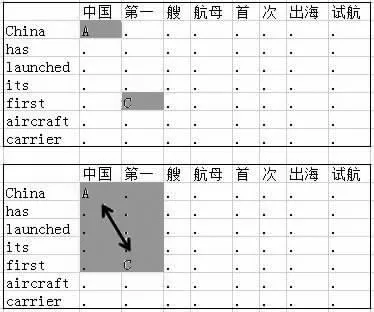
图5 随机合并两个相邻互译语块示例
3.3 减小搜索空间的剪枝策略
为了减小搜索开销,本文进行状态空间剪枝:
1. 设置合适的N-Best列表长度,利用N-Best列表自动删除最差元素的机制过滤;
2. 针对每个候选对齐计算hash,避免重复处理同一个候选对齐;
3. 根据源语言和目标语言句子长度估算出各自的可能语块个数,约束状态扩展的进程;
4. 包含标点符号的语块一般不再与任何语块合并;
5. 优先选择所有候选中增益最大的互译语块以及相应的方向进行扩展;
6. 如果每个方向的增益都小于0,则做标记及下次不再选择。
4 基于人工标注语料库的权重参数优化方法
多种特征模型分别给出了对切分点gi的黏合度和松弛度的独立贡献,融合这些模型需要确定对应的权重参数。我们在人工标注语料库上均匀抽取102个句子对,作为训练集,试图找出一组局部最优的权重参数来优化语块划分的评分值:
(1) 根据经验构造一个初始参数集合,用参数序列W=W1W2…WN表示,并用另一个N-Best自动排序列表存放最多10 000个最佳参数集合。
(2) 利用本文提出的方法计算小规模人工标注的训练集的划分分数的平均值,将初始参数序列W以及对应的平均分数插入N-Best列表。
(3) 从N-Best列表随机选择一组参数,并记录这一组参数在列表中的排名Rank,随机选择其中的一个参数进行一定幅度的变化,变化的幅度与Rank呈正相关。即如果这组参数距离N-Best列表的第一名越近,则变化的幅度越小(在局部最优解附近寻优),否则,变化的幅度越大(放弃当前解,跳跃到一个新的解)。
(4) 在变化后的参数集合W′的基础上计算小规模人工标注的训练集的平均划分分数和对齐总分数,并插入到N-Best列表。
(5) 反复重复步骤(3)、(4),直到N-Best列表的前3名的平均分数连续若干次不变。
5 实验结果与分析

高质量语块互译对抽取实验以及与其他工作的对比实验则是在包含150万句对的训练语料及 1 000句对的开放测试集上完成的。正确率评测时,从抽取结果中去重后随机采样5%由封闭语料的标注员依照同样标准审核,其判定标准是: 短语必须人工可辨识(有意义);在翻译其他句子上下文中可复用。表1显示互译语块相似度阈值对结果的影响。

表1 1 000句对开放测试集正确率抽样评测结果
从表1可以看出,随着阈值的提高,抽取结果的正确率逐渐提高,抽取规模逐渐降低。当阈值设置为-10时,正确率达到了我们认为在计算机辅助翻译应用领域内可以接受的水平。
本文的工作成果与词到短语对齐工具MTTK*http://mi.eng.cam.ac.uk/~wjb31/distrib/mttkv1/[15],以及著名开源机器翻译系统MOSES*http://www.statmt.org/moses/生成的短语表进行了对比。
MTTK训练后得到的中文到英文、英文到中文的词到短语对齐结果。GIZA++训练得到双向词到词对齐结果,利用MOSES提供的脚本工具进行对称化及短语抽取,对称化算法使用默认设置grow-diag-final-and,最大短语长度设置为3。MTTK、MOSES以及本文输出结果列在表2中。

表2 使用MTTK、MOSES以及本文算法在1 000句对开放集上的互译对抽取结果统计
结果中MTTK互译对最多,本文最少。本文独有0∶N和N∶0模式的空对齐对;1∶1模式基本上是词语对齐,本文比GIZA++少是因为语块合并等因素; 723个语块长度大于4的对齐对是语块扩展策略做出的独有贡献。
将本文算法与其他方法对比,主要比较了2∶2模式语块对,去重后以10%的采样率进行随机采样后再加人工判定,结果如表3所示。

表3 本文与其他研究工作2∶2模式对齐的短语对比
反向估计代表的是根据正确率和过滤后的互译对数,估算出过滤后的互译对中正确互译对的数目,3种方法大致相同,由此也可证明本文工作的正确性。
虽然MTTK和MOSES总抽取的互译对数目远超过本文工作,但正确率较低。实验结果表明本文算法抽取结果少而精,以牺牲召回率为代价提高了准确率。
我们相信,考虑到译员的认知负担的问题,对于实际翻译任务来说,本文的工作对译员的帮助更大,因为过多的杂乱结果会干扰他们的思考。
6 总结
本文的工作存在一些缺点和不足: 首先是没有考虑跨越多个词的搭配,也不允许嵌套,认为语块只是连续的单词片段,这是有缺陷的。语块相似度计算函数目前还比较简单,尝试利用词性、GIZA++产生的词类信息等或可得到更好结果。
本文从GIZA++词语对齐作为工作起点,但是语块划分与词语对齐似乎依然可以做到相互促进,引文语块对齐可以帮助缩小词语对齐的边界,而高质量的词语对齐也是产生高质量语块对齐的先决条件。这一点还需要进一步的实证研究。
附注: 本文的语块对齐部分成果,10万条语块对齐库已经在数据堂网站免费公开,有需要者可以自行下载使用。(http://www.datatang.com/data/46112)公布的数据是对齐程序的直接输出结果,没有再进行其他加工处理。
[1] Abney Steven. "Statistical methods and linguistics."[J]. The balancing act: Combiningsymbolic and statistical approaches to language.1996: 1-26.
[2] 周强,孙茂松,黄昌宁. 汉语句子的组块分析体系[J]. 计算机学报,1999,22(11):1158-1165.
[3] 程葳,赵军,徐波,等. 一种面向汉英口语翻译的双语语块处理方法[J]. 中文信息学报,2003,17(2):21-27.
[4] 李业刚,黄河燕. 汉语组块分析研究综述[J]. 中文信息学报,2013,27(3):1-8.
[5] Ortiz-Martínez D, Leiva L A, Alabau V, et al. Inter-active machine translation using a web-based architecture[C]//Proceedings of the 15th international conference on intelligent user interfaces. ACM, 2010: 423-424.
[6] 吕学强,李清隐,任飞亮,等. 基于统计的汉英法律文献亚句子级对齐[J]. 东北大学学报,2003,24(1):23-26.
[7] 吕学强,陈文亮,姚天顺. 基于连接文法的双语E-Chunk获取方法[J]. 东北大学学报,2002,23(9):829-832.
[8] 刘冬明,杨尔弘. 一种新的双语语块对应算法[J]. 电脑开发与应用,2004,17(3):2-3.
[9] 屈刚. 英汉双语短语对齐[D].上海交通大学,2007.
[10] Macken Lieve. Sub-sentential alignment of translational correspondences[D]. Ghent University, 2010.
[11] 姜柄圭,张秦龙,谌贻荣,等. 面向机器辅助翻译的汉语语块自动抽取研究[J].中文信息学报, 2007,21(1):9-16.
[12] 刘海霞,黄德根. 语义信息与CRF结合的汉语功能块自动识别[J]. 中文信息学报,2011,25(5):53-59.
[13] 诺明花,张立强,刘汇丹,等. 汉藏短语抽取[J]. 中文信息学报,2011,25(1):105-110.
[14] 诺明花,吴健,刘汇丹,等. 汉藏短语对抽取中短语译文获取方法研究[J]. 中文信息学报,2011,25(3):112-117.
[15] Deng Yonggang. Bitext alignment for statistical machine translation[D]. Johns Hopkins University, 2006.
[16] Liu Feifan, et al. Bilingual chunk alignment based on interactional matching and probabilistic latent semantic indexing[J]. Natural Language Processing IJCNLP 2004. Springer Berlin Heidelberg, 2005: 416-425.
[17] Zhao Bing. Statistical alignment models for translational equivalence[D]. Carnegie Mellon University, 2007.
[18] Ma Yanjun, Nicolas Stroppa, Andy Way. Bootstrapping word alignment via word packing[J]. Annual Meeting-Association for Computational Linguistics. 2007,45(1):304-311.
[19] Kim Jae Dong. Chunk alignment for Corpus-Based Machine Translation[D]. Carnegie Mellon University, 2012.
A Bilingual Chunk Alignment Algorithm for Computer Aided Translation
YU Jingsong1,3, WANG Huilin2, WU Shenglan3
(1. Department of Information Management, Peking University, Beijing 100871;2. Institute of Scientific and Technical Information of China, Peking University, Beijing 100038;3. School of Software and Microelectronics, Peking University, Beijing 100871)
Automatic Bilingual Chunk Alignment has important application value for Machine Translation, Computer Aided Translation and other fields. In this paper, a Chunk Partition Scoring method is proposed based on the Degree of Adhesion and the Degree of Relaxation to make the chunk partition of source language and target language benefit each other. A novel bilingual chunk alignment algorithm is proposed. Compared with previouswork, this algorithm does not require bilingual chunk partitions, however, the chunk partition score is dynamically calculated during alignment searching. The importance of precision is far beyond recall of this approach.
chunk alignment; machine translation; parallel corpus; bitext alignment

俞敬松(1971-),博士研究生,硕士,副教授,主要研究领域为自然语言处理、计算机辅助翻译、教育技术等。E⁃mail:yjs@ss.pku.edu.cn王惠临(1948—),博士生导师,博士,主要研究领域为信息管理、机器翻译、自然语言处理等。E⁃mail:wanghl@istic.ac.cn吴胜兰(1987—),硕士,主要研究领域为自然语言处理、购物商品推荐等。E⁃mail:wslgb2010@qq.com
1003-0077(2015)01-0067-08
2014-04-28 定稿日期: 2014-06-16
TP391
A
猜你喜欢
广东教育·综合(2021年11期)2021-12-02
牡丹江教育学院学报(2021年1期)2021-03-23
师道·教研(2020年3期)2020-04-02
中学生英语·教师版(2019年6期)2019-08-01
教育教学论坛(2019年18期)2019-06-17
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
文理导航(2017年25期)2017-09-07
考试周刊(2015年36期)2015-09-10
科学中国人(2014年22期)2014-07-23
