
基于并列结构的部分整体关系获取方法
2015-04-25 09:57曹馨宇符建辉曹存根
中文信息学报 2015年1期
夏 飞,曹馨宇,符建辉,王 石,曹存根
(1. 中国科学院计算技术研究所智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100049)
基于并列结构的部分整体关系获取方法
夏 飞1,2,曹馨宇1,2,符建辉1,王 石1,曹存根1
(1. 中国科学院计算技术研究所智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100049)
部分整体关系是一种基础而重要的语义关系,从文本中自动获取部分整体关系是知识工程的一项基础性研究课题。该文提出了一种基于图的从Web中获取部分整体关系的方法,首先利用部分整体关系模式从Google下载语料,然后用并列结构模式从中匹配出部分概念对,据此形成图,用层次聚类算法对该图进行自动聚类,使正确的部分概念聚集在一起。在层次聚类基础上,我们挖掘并列结构的特性、图的特点和汉语的语言特点,采用惩罚逗号边、去除低频边、奖励环路、加重相同后缀和前缀等5种方法调整图中边的权重,在不损失层次聚类的高准确率条件下,大幅提高了召回率。
部分整体关系;图模型;并列结构;层次聚类;边权重
1 引言
WordNet和HowNet之类的语义词典在解决自然语言处理问题时发挥着越来越重要的作用,自动文摘、信息检索、自动问答等系统常常需要借助这些词典确定概念之间的语义关系。语义关系是构建语义词典的基础,例如,WordNet中的概念之间就有上位(hypernym)、下位(hyponym)、部分(part-meronym)、整体(part-holonym)等关系[1]。人工编纂这类语义词典费时费力,因此,有必要研究如何从文本中自动获取语义关系。
部分整体关系是一类基础而重要的语义关系,人造物及其部件、组织及其成员、化学试剂及其成分,这些都包含着部分整体关系。研究部分整体关系,不仅有助于解决一系列自然语言处理问题,在人造物的设计、生化试剂的配置等实际问题中也有重要应用。
近年来网络迅猛发展,电子文档越来越多,其中蕴含的信息越来越丰富,从Web中挖掘知识成为热门研究课题。基于此,本文提出了一种基于并列结构的从Web中获取部分整体关系的方法,利用部分整体关系模式从Google获取语料,匹配出具有并列结构的句子,从中获取出给定整体概念的部分概念,用层次聚类算法对候选的部分概念进行自动聚类。在此基础上,重点研究了利用图的特点和汉语的语言特点,对图中边的权重进行调整而提升层次聚类算法的实验效果。
本文结构如下: 第2部分将介绍国内外相关工作,第3部分给出了从Web中初步获取部分整体关系的方法,第4、5部分研究利用并列结构特点和汉语语言特点的改进方法;第6部分给出实验结果并做分析,最后是总结并展望下一步工作。
2 相关工作
基于词汇—句法模式获取语义关系,这种方法的依据是人们经常用一些特定的句法结构(即模式)来表述某种语义关系,因此可以从满足某些模式的句子中获取出对应的语义关系。这种方法由文献[2]提出。文献[3]首先将这一方法用于部分整体关系的获取,使用模式获取候选的部分概念,再根据统计函数likelihood选取正确的部分概念,然而受限于使用的模式,他们获取的部分整体关系的实例很少,准确率较低。
模式的方法也被引入中文领域的部分整体关系获取。文献[4-5]利用基于图论的方法构造部分整体图,将所有候选概念从全局的角度进行分析验证,形成可供使用的知识库。文献[6-7]利用中文语义特征和部分整体关系的特性,构造一系列启发式规则,对获取的部分整体关系进行验证。这些方法都是在发现模式方法的局限性下,希望加强后期的验证以提高获取效果。
文献[8]利用模式的方法获取到部分整体关系后,借助WordNet标注概念的语义特征,构建大量的训练集实例,使用C4.5算法学习关于部分整体关系的分类规则,利用这些规则验证候选的部分整体关系。在包含10 000条句子的语料中进行实验,最终获取结果的准确率为83%,召回率为98%。然而这一方法对外部资源和工具的依赖较大,并且需要手工标注大量的训练集。
随着互联网的发展,Web开始替代传统的语料库作为知识获取的资源。文献[9]利用Google从Web中获取表示部分整体关系的模式,再利用Google和获取到的模式从Web中获取已知部分概念的部分整体关系。他们将这种方法应用在食品安全领域,取得了较好的实验结果。但是这种方法非常依赖相关领域的词典,扩展不易。
以并列结构形式出现的概念往往是语义相似的,文献[10-11]利用这种特性构建和扩充语义词典,首先对于某一类别选出一些种子概念,然后从语料库中找出与种子概念并列出现的概念,利用一些统计方法从中筛选出新的种子概念,循环迭代,最后对获取到的所有概念进行统计排名,得到属于选定类别的概念。
文献[12]利用并列关系对获取到的概念建图,以概念为点,以并列关系为边,通过增量的聚类算法对该图进行聚类,将语义相似的概念聚在一起,最终得到了82%的准确率。他们更进一步将这种方法用于语义消歧,对于一个概念的多个义项,利用并列结构找出与这些义项的语义关系相近的概念,用这些概念作为消歧的依据。
并列结构也被用于语义关系的获取,文献[13]在初步获取到的上下位关系基础上,利用并列结构从语料中抽取新的上下位关系,将召回率提高了5倍。文献[16]将并列结构用于同义词集的自动获取上,通过并列关系作图,使用聚类方法和一些语言学特征提高获取精度,取得了很好的结果。
3 部分整体关系初步获取
3.1 部分整体关系的定义
目前,对于部分整体关系的定义和分类,研究者们并没有统一的认识。Winston et al.在大量语言心理学实验的基础上提出将meronymic关系分为6类,分别是: component-integral object、member-collection、portion-mass、stuff-object、feature-activity、place-area[14]。这种分类在以后的研究中被广泛使用。本文获取的部分整体关系主要集中在component-integral object这一类,其中的整体通常有一个结构,它们的组成部分是可分离的并且有特定的功能。这是一类常见的部分整体关系,主要体现在物体与其部件的关系上,例如,汽车和轮胎,桌子和桌腿。
一般来说,对于两个概念X与Y,如果它们的关系可以由“X是Y的一部分”、“Y的组成部分中包括X等”、“Y由X等构成”等句子描述,那么可以认为它们满足部分整体关系,记作partof(X,Y)。例如,partof(发动机,汽车),表示发动机是汽车的部分。
3.2 部分整体关系的模式
表述部分整体关系的句法模式有很多,例如,“X是Y的一部分”、“Y包含X”、“Y由X等组成”,这些句子可能都预示着X与Y之间存在部分整体关系。然而,有些部分整体关系模式具有很大的模糊性,例如,常用的“<整体>的<部分>”这一模式,既可以表示部分整体关系(如,汽车的发动机),也可以表述属性(如,汽车的速度)。
因此,我们选择那些包含并列结构的模式,实验发现,这样的模式获取到的概念较多,其中的概念较易抽取,且概念之间可以相互验证。
例如,对于模式“<整体>由<部分>等组成”,可以匹配出下面的句子
1) 汽车由发动机、底盘、变速箱等组成。
从句子1)中,我们可以很容易抽取出汽车的3个部分概念: 发动机、底盘和变速箱。我们使用的模式如表1所示。

表1 部分整体关系模式
其中,(?整体)是整体概念区,构造查询串时会用给定的整体概念去替换;(?部分)是部分概念区,表示所要获取的部分概念,这部分会替换成通配符“*”;(!部分词)是一些可以表示部分关系的词,例如,“部件”、“零件”、“器件”等,搜索时会替换成这些词。经过这些转化,我们就可以得到查询串。
例如,获取“汽车”的部分概念时,模式Com003将转化为下面的查询串
查询串: 1)“(等|之类)汽车(部件|零件|器件|元件|组件|构件|配件|零部件|元器件)”。
查询串1)就可以提交给搜索引擎进行网页搜索。
3.3 部分整体关系的初步获取
我们使用上面的模式获取给定整体概念的部分概念,步骤如下:
1) 利用给定的概念将模式转化为查询串;
2) 到Google中查询,将搜索出的页面摘要切割成句子,形成语料;
3) 筛选出满足模式的句子,并且要求句子中包含并列结构;
4) 用并列符号和并列词从句子的并列结构中切割、抽取出概念。
例如,对于模式Com001和给定的概念“电脑”,我们首先将它转化为下面的查询串。
2) “电脑(是由|由)”“(组成|构成)”。
Google利用查询串2)获取到很多的页面摘要(snippets),我们抓取出其中的前1 000项,将它们用句号、问号、感叹号等标点符号切割成句子,再次利用模式Com001从中筛选出可以匹配的句子,并且要求句子中包含并列符号(顿号、逗号)或者并列词(和、与、及等),最后对句子中的并列结构进行切割,抽取出其中的词或短语。
例如,Com001匹配到下面的句子,
2) 大家知道,电脑是由主机、显示器以及键盘、鼠标等外设构成的。
利用模式中的关键词“由”、“构成”以及并列符号和并列词,我们可以从句子2)中抽取出“主机”、“显示器”、“键盘”和“鼠标等外设”4个部分。
我们用一些规则对这些初步获取到的词或短语进行简单的预处理,例如切去头部的数量词,如“四个轮胎”切成“轮胎”,“一些车灯”切成“车灯”;或者剥离尾部多余的词,如“鼠标等外设”剥离为“鼠标”。最后得到的概念作为候选的部分概念。
我们的评价指标包括准确率(P)、召回率(R)和F值,定义如式(1)、(2)、(3)所示。
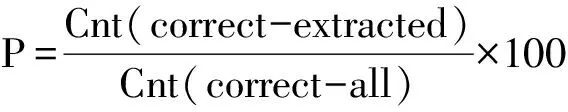

其中,Cnt(correct-extracted)表示获取结果中正确的部分概念数,Cnt(all-extracted)表示获取结果中总的概念数,Cnt(correct-all)表示语料库中正确的部分概念数。我们选取了“冰箱”、“电脑”、“汽车”等27个常见的人造物做实验,除了“U盘”、“电熨斗”没有获取到相关的部分概念,“摄像头”只获取到了3个部分概念无法继续后面的实验外,其他概念的初步获取都取得了较好的结果。初步获取实验中,我们的模式对部分整体关系的覆盖率达到了88.89%,部分实验结果如表2所示。可以看出,使用并列结构模式获取部分整体关系,准确率较高,获取的结果数也很多。下面的实验将以初步获取的结果为基准进行对比。
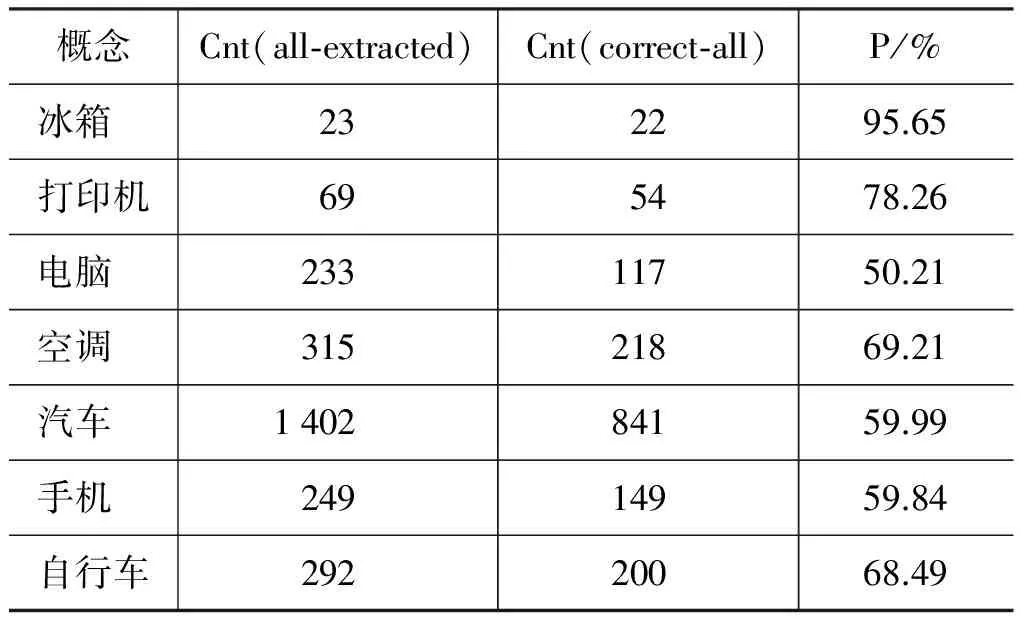
表2 初步获取部分实验结果
4 基于层次聚类的部分整体关系分析
为了从候选的部分概念中抽取出正确的概念,本节将介绍一种基于层次聚类的部分整体关系分析方法。
4.1 层次聚类方法
聚类分析是数据挖掘中一种重要的学习方法,它按照事物的某些属性,把事物聚集成类,使类间的相似性尽可能小,类内的相似性尽可能大。层次聚类是一种常用的聚类方法,按照层次的形成方式,又分为凝聚的方法和分裂的方法。本文采用的是分裂的方法,它又称为自顶向下的方法,一开始将所有的对象都置于同一个类中,然后通过不断的迭代,一个类被分裂为更小的类,直到每个对象被归入某个单独的类中,或者达到某个终止条件[15]。
层次聚类算法描述如下:

算法4⁃1 层次聚类算法输入:包含n个对象的数据库,阈值λ输出:k个类(1)将所有对象置于同一个类中(2)DoBegin(3)在所有类中挑选出具有最大基数的类Cmax;(4)从Cmax里找出与其他点平均相似度最小的一个点,记该相似度为Simmin,将该点放入新类Cnew,剩余的放入旧类Cold中。(5)从Cold里找出与Cnew中点的最小相似度不小于Cold中点的最小相似度的点,并将这些点放入Cnew,直到没有新的Cold的点被分配给Cnew(6)Cnew和Cold为Cmax分裂成的两个类,与其他类一起组成新的类集合(7)Repeat(2)~(6)UntilSimmin<λ(8)End
4.2 实验结果
我们在初步获取的部分概念集上采用分裂的层次聚类方法,是基于以下假设。
假设1 初始结果中正确的部分概念占多数。
假设2 大多数正确的部分概念可以通过某些联系聚集在一个类中。
假设3 错误的结果会聚集成其他不同的类。
其中,假设1已经在初始获取结果中得到验证,后两个假设则有待后面实验的验证。因此,一开始我们假定初始结果中所有的概念都是正确的部分概念,即将它们置于同一个类中,然后通过每次迭代,将错误的概念划分出去,最后留下所有我们认为正确的结果。
我们定义部分概念共现图G(V, E),其中V为结点的集合,每一个结点即为初步获取到的一个部分概念;E是边的集合,结点间是否有边连接取决于它们所代表的概念是否以并列结构的形式出现在同一个句子中,边的权重为共现次数。即,对于两个概念Pi、Pj,若它们以并列结构“Pi+ /c + Pj”的形式出现了w次,则它们所在边的权重weight(Pi, Pj)=w。在权重基础上,我们定义两个概念Pi、Pj的相似度为它们边的权重与其中度较小的点的度的比值,即式(4)。
simWeight(Pi, Pj)=
对于聚类过程中的某个类Ci,我们定义它的基数为其中对象的个数,即Card(Ci)=| Ci|。基于这样的定义,分裂聚类时每次都将基数最大的类,即具有最多对象的类别分开,将错误的概念划分出去,最后留下的是我们认为正确的结果。这与我们上文的假设是一致的。这样做虽然会降低召回率,并造成F值偏低,但可以大大提高准确率。通过观察研究这一部分准确率较高的结果,我们提出后文的改进方法,将“散落在外”的其他正确概念吸收回来,以提高最终的F值。
例如,初步获取到的“汽车”的部分概念可以构成如下概念共现图(图1),省略的概念用加矩形框的省略号表示。

图1 “汽车”的部分概念共现图
我们用算法4-1对该图进行聚类,最后输出的k个类中基数最大的类为实验结果。表3给出了实验结果,可以看出层次聚类对准确率的提升较明显,对比初步获取59.9%的准确率,在λ的不同取值下“汽车”的准确率均提升了超过20%。其中,λ越小,聚类算法分裂次数越多,对象越“分散”,准确率高,召回率则相应较低;λ越大,聚类算法分裂次数越少,对象越“集中”,准确率降低,召回率则相应提升。λ取0.4时,F值最大,所以我们的实验将在λ=0.4下进行。总的来看,实验结果显示出召回率的不足,接下来的实验将逐步改进层次聚类的效果。

表3 层次聚类实验结果
5 对部分整体关系获取层次聚类方法的改进
为提高层次聚类方法的效果,我们可以利用各种知识来调整边的权重。本文通过去除原始数据中的噪音,以及利用汉语的语言特点,大幅提升了部分整体关系获取的准确率和召回率。
5.1 惩罚逗号边
汉语中,逗号除了可以表示句子成分之间的并列外,还可以用于分开句内各词语或表示语气的停顿等。相比顿号,逗号连接的两个概念表示并列关系的可能性降低。例如,下面这条句子:
3) 凯翔达汽车配件有限公司,日产公爵前嘴,机盖,车门,叶子板,倒车镜等汽车配件。
“日产公爵前嘴”、“机盖”、“车门”等等都是汽车的部件,此时中间的逗号作并列成分的分隔用;但句首的“凯翔达汽车配件有限公司”并非汽车的部件,后面的逗号用来表示分句的停顿。
因此,对于逗号连接的边,可以施行惩罚,降低它的权重。
设概念Pi和Pj在“Pi+ ,+ Pj”中出现了c1次,在“Pi+ 、+ Pj”中出现了c2次,则式(5)为:
Weight1(Pi,Pj)=λ1×c1+c2
(5)
其中0<λ1<1,即将图中逗号边的权重缩小为原来的λ1倍。惩罚逗号边的实验结果如表4所示。
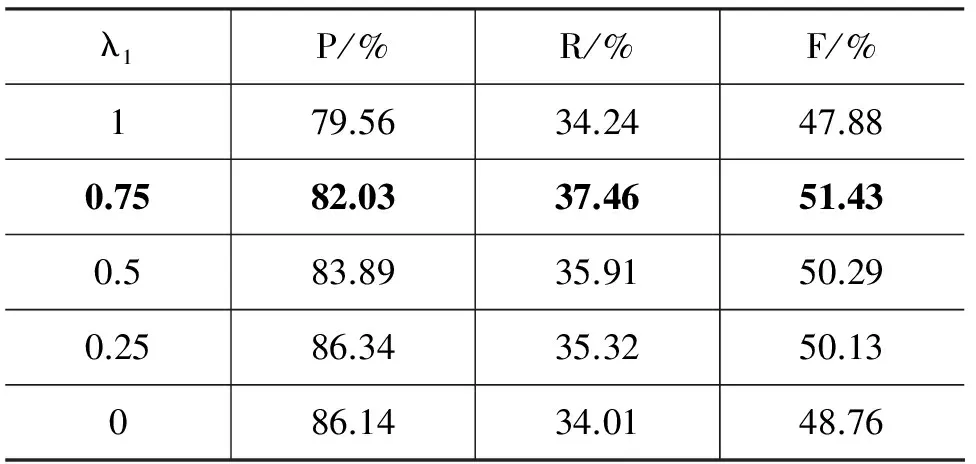
表4 惩罚逗号边实验结果
其中λ1=1时即为表3层次聚类算法的结果。由表中数据看出,惩罚逗号边可以略微提升准确率,λ1越小,准确率提升越多,但召回率也会相应降低。λ1取0.75时,F值最大,所以我们后续的实验将在λ1=0.75下进行。
5.2 去除低频边
当一个错误的概念Pi偶然与一个正确的部分概念Pj共现在并列结构中时,这种关联很有可能会造成错误传染,使得与Pi共现的其他错误概念聚集到表示正确概念的类中。因此,出现次数较少的边有可能是噪音,可以通过切断权重小于某个阈值的边来减少此类错误。
在4.1节惩罚逗号边实验的基础上:
若Weight1(Pi, Pj)≤λ2,则去除边(Pi, Pj);否则
Weight2(Pi, Pj)=Weight1(Pi, Pj)
表5显示了去除低频边的实验结果,其中λ2=0时为表4惩罚逗号边的结果,即不删除任何边。λ2越大,删除的边越多,此时召回率降低较多。λ2取0.75时F值最大,此时去除只用逗号连接的边,后续的实验将在这一取值下进行。这一节实验与上一节结合在一起,显示出逗号在句中作用的模糊性,即通过逗号连接的句子成分不一定是并列的。

表5 去除低频边实验结果
5.3 奖励环路
对于两个概念Pi和Pj,若它们同时出现在对称的并列结构“Pi+ /c + Pj”和“Pj+ /c + Pi”中,则它们之间的联系要比只出现在单向并列结构中的概念要紧密。推而广之,对于概念Pk1, Pk2, … , Pkn(n>=3),若它们形成“Pk1+ /c + Pk2”, “Pk2+ /c + Pk3”, … , “Pkn+ /c + Pk1”这样的环路,则它们之间的联系也更紧密,可以增加这些边的权重。
我们在图上进行搜索,找到所有这样的环路。对于概念Pi、Pj,如果边(Pi, Pj)出现在环路上,则如式(6)所示。
表6显示了奖励环路后的实验结果,其中 λ3=1 时为表5去除低频边的结果,即不增加环路上的边的权重。总的来看,奖励环路对准确率的提升并不明显,原因应当是图中的环路并不多。λ3取3时F值最大,后续的实验将在这一取值下进行。
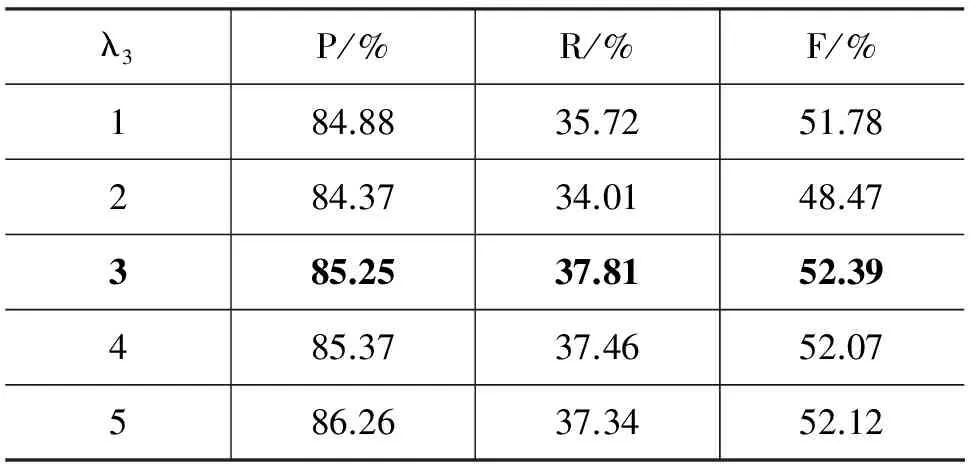
表6 奖励环路实验结果
5.4 加重相同后缀
观察发现,同属一个整体的部件概念常常有相同的后缀,如“汽车”的部件“发动机”、“发电机”、“方向机”、“起动机”有相同的后缀“机”,“车架总成”、“前缸骨架总成”、“转向纵横拉杆总成”有相同的后缀“总成”。这是因为根据汉语的构词特点,如果两个概念的后缀相同,则它们属于同一个语义类的可能性就很大。因此,如果两个概念的后缀相同,可以增加它们的边的权重。
本文在分词后的基础上计算概念的后缀,对于某个概念P,设其分词后的结果为w1w2…wn,则其后缀Suf(P)按式(7)计算:
(7)
其中LC(P)表示取P的最后一个字(Last Character)。例如,“怠速马达”的分词结果为“怠/a 速/a 马达/n”,则Suf(“怠速马达”)=“马达”,同理,Suf(“倒车雷达”)=“雷达”, Suf(“马自达”)=“达”,三者的后缀并不相同。另外,“发动机”作为常见词,其分词结果为“发动机/n”,则Suf(“发动机”)=“机”,同理,Suf(“发电机”)=“机”,Suf(“暖风机”)=“机”,它们具有相同的后缀。
两个概念Pi和Pj基于后缀的相似度定义为式(8)所示。
在5.2节去除低频边实验的基础上如式(9)所示。
Weight4(Pi, Pj)= Weight3(Pi, Pj)+
表7显示了加重相同后缀的实验结果,其中 λ4=0时为表6奖励环路的结果。可以看出,这一步改进对实验结果的影响主要体现在召回率上,λ4不同取值下“汽车”的召回率都有超过30个百分点的提升,显示出“汽车”的很多部件概念都有相同的后缀。λ4取3时F值最大,后续的实验将在这一取值下进行。

表7 加重相同后缀实验结果
5.5 加重相同前缀
在汉语中,概念的前缀常常与概念本身构成部分整体关系。例如,“车把”、“车座”、“车轴”、“车筐”、“车轮”有相同的前缀“车”,它们都是“(自行)车”的部件;“发动机罩盖”、“发动机散热器”、“发动机缸体”有相同的前缀“发动机”,它们都是“发动机”的部件,也是“汽车”的部件。因此,如果两个概念的前缀相同,则它们与同一个概念构成部分整体关系的可能性就很大,可以增加它们的边的权重。
本文在分词后的基础上计算概念的前缀,对于某个概念P,设其分词后的结果为w1w2…wn,则其前缀Pre(P)按式(10)计算:
(10)
其中FC(P)表示取P的第一个字(First Character)。例如,“车把”的分词结果为“车把/n”,则Pre(“车把”)=“车”;“车筐”的分词结果为“车/n 筐/n”,则Pre(“车筐”)=“车”,两者具有相同的前缀。
两个概念Pi和Pj基于前缀的相似度定义如式(11)所示。
在5.2节去除低频边实验的基础上如式(12)所示。
Weight5(Pi, Pj)= Weight4(Pi, Pj)+
表8显示了加重相同前缀的实验结果,其中 λ5=0时为表7加重相同后缀的结果,λ5=1时F值最大,最终的准确率达到了76.87%,召回率更是达到91.68%。这一节与上一节一起,显示出在汉语词汇中,前后缀蕴含了丰富的语义信息。

表8 加重相同前缀实验结果
6 实验结果及分析
我们选择了初步获取结果中可以继续实验的24个概念,用层次聚类算法与上一节提出的改进方法和取值进行实验。因为我们是在获取未知的知识,无法确知某一概念有哪些部分概念,数量多少,理论上我们无法计算实验的召回率。因此,我们在初步获取后,从语料中人工标注出其中的正确与错误的结果,假设其中正确的部分概念数为总的正确概念数,以此为基准计算召回率和F值,结果如表9所示。其中Cnt(correct-all)表示语料中正确的部分概念数。
可以看出,我们的层次聚类算法拥有较高的准确率,普遍在70%以上;在聚类基础上的改进研究主要在召回率的提升上发挥了作用,从而提高了F值。综合来看,我们的方法的优点是: 既有效地利用了统计信息(词频、共现度),又结合了语义信息(汉语前后缀)。
对于初步获取得到部件较多的概念,这种优点带来的效果很明显。例如,“打印机”、“手机”、“自行车”等,我们从Web中获取到的对应语料较多,统计出来的词频等信息较丰富,可利用的前后缀等信息也较明显。因此,它们的F值都达到80%以上。
我们的方法也存在不足,数据稀疏是我们面临的一大问题。对于“冰箱”、“收音机”这些概念,我们下载到的对应语料较少,从中获取的部件概念也少,因而可利用的统计信息不明显,前后缀等语义信息也不丰富,导致这些概念的实验结果稍差,尤其是召回率。
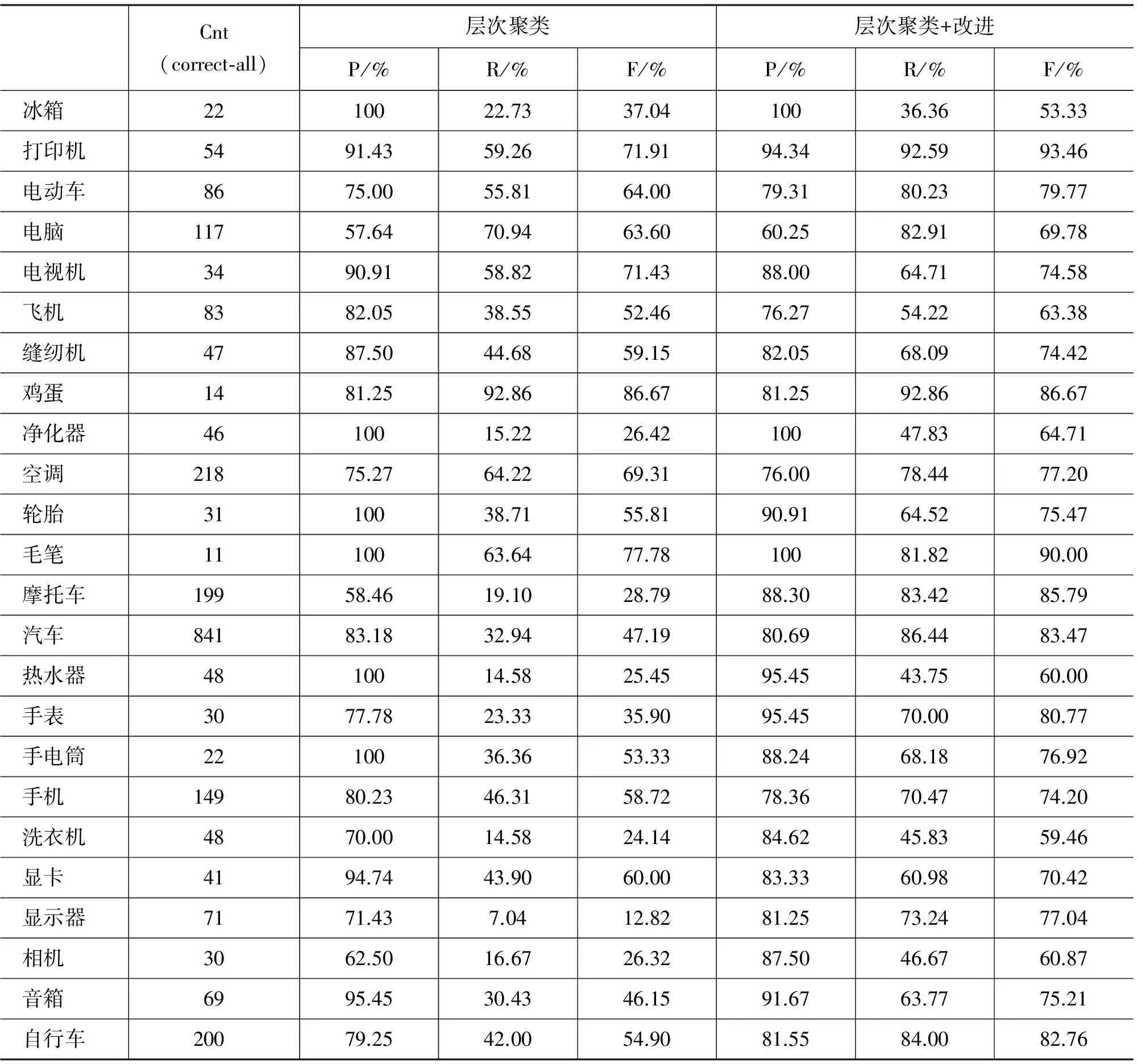
表9 实验结果
除此之外,我们还有其他待解决的问题。
1) 术语识别不干净带来的错误。例如,在获取到的“手机”的部件中,存在“商务电池”、“诺基亚耳机”这样的概念,需要从中识别出“电池”、“耳机”这样的“干净”的术语。达到这样的识别效果,可能需要借助某些领域词典。
2) 配件概念带来的错误。在获取到的部件中,夹杂着一些配件概念。例如,获取“电脑”的部件时,也返回了一些“网线”、“鼠标垫”之类的配件。这既源自于网页文本中表述部分整体关系的不严谨,也与我们下载语料时所用的模式有关。
根据我们实验的初步结果,当这些问题得到解决后,实验结果的准确率可以提升2%~4%。
在将来的工作中,我们会引入其他模式和方法,以获取更多的语料;同时会用迭代的方法获取更多的候选部分概念,以使层次聚类发挥出应有的效果。区分出部件和配件的不同,有赖于对部分整体关系分类的更深入研究。
7 结束语
从文本中自动获取部分整体关系是知识工程的一项基础性研究课题,本文利用Google获取语料,采用并列结构模式从中匹配出部分概念对形成图,用层次聚类算法对候选的部分概念进行自动聚类。在此基础上,重点研究了利用图的特点和汉语的语言特点,对图中边的权重进行调整而提升层次聚类算法的实验效果。我们的方法的优点是既有效地利用了统计信息,又结合了语义信息。我们选择了一些概念,用本文的方法获取它们的部分概念,实验表明,我们的方法是有效的。
当然,我们的方法也存在一些不足,主要表现在以下两个方面。
1) 由于数据稀疏,统计和语义特征不明显,当给定的整体概念在初步获取时得到的候选部分概念较少时,层次聚类和改进方法并没有给出较好的结果;
2) 获取的部件结果中也存在一些术语识别和配件夹杂的问题。
[1] George A Miller. WordNet: A Lexical Database for English[J]. Communications of the ACM, 1995, 38:39-41
[2] M A Hearst, Automatic Acquisition of hyponyms from large text corpora[C]//Proceedings of the 14th International Conference on Computational Linguistics (COLING-92), Nantes,France, 1992: 539-545.
[3] M Berland, E Charniak. Finding Parts in Very Large Corpora[C]//Proceedings of the the 37th Annual Meeting of the Association for Computational Linguistics (ACL-99). 1999.
[4] J Wu, B Luo, C G Cao,et al. Acquisition and Verification of Mereological Knowledge from Web Page Texts[J]. Journal of East China University of Science and Technology(Natural Science Edition), Shanghai, China, 2006: 1310-1317.
[5] 吴洁. 网络文本中部分关系知识的获取与验证方法[D]. 上海:华东理工大学硕士学位论文. 2006
[6] Xinyu C, Cungen C, Shi W, et al. Extracting Part-Whole Relations from Unstructured Chinese Corpus[C]//Proceedings 4th International Conference on Natural Computation (ICNC’08) and 5th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD’08), Jinan, China. 2008.
[7] 曹馨宇. 部分整体关系的获取与分析研究[D]. 北京: 中国科学院大学博士学位论文. 2012
[8] R Girju, A Badulescu, D Moldovan, Automatic Discovery of Part-Whole Relations[J].Computational Linguistics, 2006,32(1): 83-135.
[9] R H Willem, H Kolb, G Schreiber. A method for learning part-whole relations[C]//Proceedings of the 5th Int. Semantic Web Conf., LNCS, 2006:723-736.
[10] Ellen Riloff, Jessica Shepherd. A corpus-based approach for building semantic lexicons[C]//Proceedings of the Second Conference on empirical Methods in Natural Language Processing, 1997:117-124.
[11] Brian Roark, Eugene Charniak. Noun-phrase cooccurence statistics for semi-automatic semantic lexicon construction[C]//Proceedings of COLING-ACL, 1998:1110-1116.
[12] Dominic Widdows, Beate Dorow. A graph model for unsupervised lexical acquisition[C]//Proceedings of the 19th International Conference on Computational Linguistics,2002:1093-1099.
[13] Cederberg S, D Widdows. Using LSA and noun coordination information to improve the precision and recall of hyponymy extraction[C]//Proceedings of CoNLL, 2003:111-118.
[14] M E Winston, R Chaffin, D Herrman. A taxonomy of part-whole relations[J]. Cognitive Science, 1987,11(4):417-444.
[15] Jiawei H, Micheline K, Jian P. Data Mining: Concept and Techniques[M], Second Edition. Morgan Kaufmann, 2005:408-410.
[16] 吴云芳,石静,金彭.基于图的同义词集自动获取方法[J].《计算机研究与发展》,2011,48(4): 610-616.
Extracting Part-Whole Relations Based on Coordinate Structure
XIA Fei1,2, CAO Xinyu1,2, FU Jianhui1, WANG Shi1, CAO Cungen1
(1. Key Laboratory of Intelligent Information Processing,Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China;2. University of Chinese Academy of Sciences, Beijing 100049, China)
Automatic discovery of part-whole relations from the Web is a fundamental but critical problem in knowledge engineering. This paper proposes a graph-based method of extracting part-whole relations from the Web. Firstly, we download snippets from Google using part-whole query patterns, and then we built a graph by extracting word pairs with a coordinate structure from these snippets, with the co-occurring words as nodes and the frequency count as edges’ weight. A hierarchical clustering method is used to cluster the correct parts, which is optimized by five methods of adjusting the edge weight: reduce the weight of comma-edges, cut the low-frequency edges, enlarge the weight of edges in the loop, enlarge the weight of edges in which two nodes share the same suffix, and enlarge the weight of edges in which two nodes share the same prefix. Experimental results show that the five methods increase the recall substantially.
part-whole relations; graph model; coordinate structure; hierarchical clustering; edge weight

夏飞(1986—),博士研究生,主要研究领域为知识获取、文本挖掘。E⁃mail:xiafei.1986@163.com曹馨宇(1982—),博士,主要研究领域为人工智能、知识工程。E⁃mail:cxy8202@163.com符建辉(1985—),博士研究生,助理研究员,主要研究领域为智能软件和大规模知识处理。E⁃mail:fjh5228203@126.com
1003-0077(2015)01-0088-09
2012-06-07 定稿日期: 2012-10-29
国家自然科学基金(91224006、61173063、61035004、61203284、309737163)、国家社科基金(10AYY003)
TP391
A
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2019年6期)2019-10-08
流行色(2019年7期)2019-09-27
初中生世界·七年级(2019年8期)2019-08-29
神州·下旬刊(2017年6期)2017-10-28
雷达学报(2017年6期)2017-03-26
中国修辞(2017年0期)2017-01-31
互联网天地(2016年1期)2016-05-04
长江学术(2016年4期)2016-03-11
