
一种扩展式CRFs的短语情感倾向性分析方法研究
2015-04-25 09:57乌达巴拉汪增福
中文信息学报 2015年1期
乌达巴拉,汪增福
(1. 中国科学技术大学 自动化系,安徽 合肥 230027;2. 中国科学院 合肥智能机械研究所,安徽 合肥 230031)
一种扩展式CRFs的短语情感倾向性分析方法研究
乌达巴拉1,2,汪增福1,2
(1. 中国科学技术大学 自动化系,安徽 合肥 230027;2. 中国科学院 合肥智能机械研究所,安徽 合肥 230031)
短语情感倾向性分析是文本情感分析的重要研究内容。该文将短语情感倾向性分析问题视作序列标注问题,利用条件随机场模型实现短语的情感倾向性判断。条件随机场模型是利用序列特征处理序列标注问题的经典方法,然而现有条件随机场模型无法将词语的情感倾向性分析与短语的情感倾向性分析相结合,从而造成准确率不高。因此,该文提出一种扩展式条件随机场模型YACRFs。该模型在链式条件随机场模型的基础上进行扩充,将词语情感倾向性分析与短语情感倾向性分析有效地结合起来,引入了情感词汇、短语规则模板以及词性等特征。与传统的规则方法和统计分类方法进行对比实验,该文提出方法取得了最高准确率81.07%。进一步地,在应用于句子情感倾向性分析的实验中得到了94.30%的准确率。实验结果表明,该文所提出的YACRFs模型能够显著提高短语情感倾向性判断结果的准确率。
短语;情感倾向性分析;条件随机场
1 引言
文本情感倾向性分析是对文本信息资源的情感分类“支持、反对或中立”和情绪分类“喜悦、愤怒、悲哀、恐惧、惊慌”等的合称。文本情感分析研究作为自然语言处理、人工智能、信息检索以及数据挖掘等多个领域的重要研究内容,具有广泛的应用前景。例如,在商业领域,销售方可以通过跟踪用户对产品的回馈意见来获得改进产品质量的针对性意见,消费者也可以通过网上真实的产品评论信息来调整个人的购买意向。
就情感分类“支持、反对或中立”的研究而言,文本情感倾向性分析可分为词语级、短语级、句子级以及文档级的研究[1]。具体例子如表1所示。
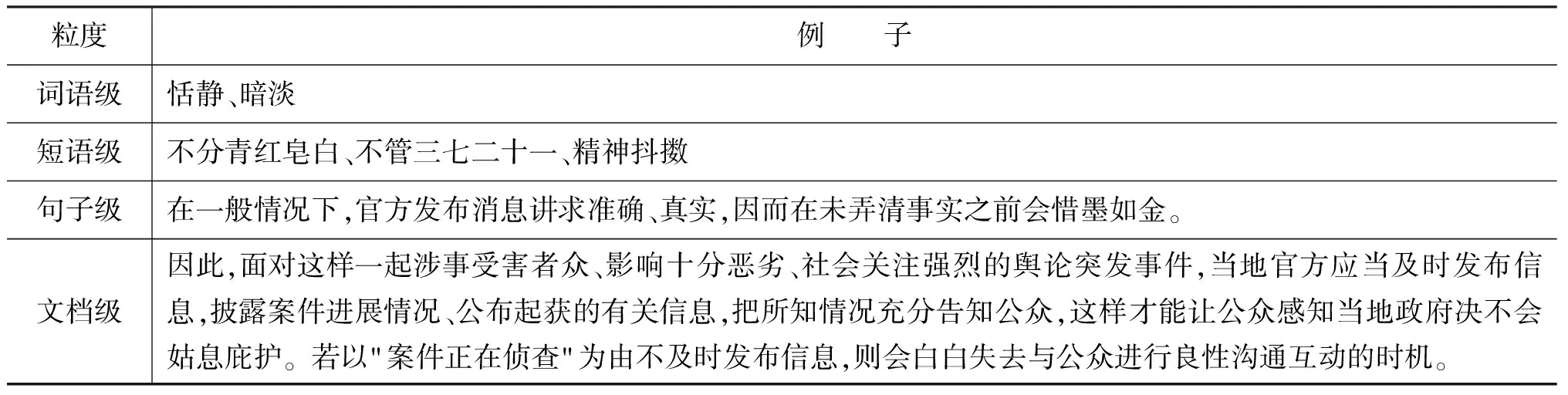
表1 各级文本情感倾向性实例
早期的研究主要集中在词语级的情感倾向性判断,识别新的情感词汇以及确定其语义倾向[2-9]。句子级和文档级的情感倾向判断研究是指将语句和篇章作为一个整体进行情感倾向性的判断[10-13]。然而无论是词语级的、句子级的,还是文档级的情感倾向性分析都存在一定的局限性。就词语级的情感倾向性分析而言,由于自然语言本身的灵活性和复杂性,单个词语的情感极性存在一定的歧义性[例如,句子“Polo车的性能较高,但是价格也较高。”中的前一个词“高”表现出褒义(支持),但是后面的“高”则含有贬义(反对)倾向];此外,随着网络语言的迅速演变,新词、新词义和错词层出不穷,导致未登录词的比例和影响增大。至于句子级或文档级的情感倾向性分析研究,一条句子或一篇文档的情感倾向性并不能只靠所包含的情感词汇决定。一个情感词的极性会受到与它有一定上下文相关性的其他词的影响而改变。例如,否定词可以改变一个情感词的极性(如“这款车的性能不好”),实词之间相互联系也可以改变其极性(如“该配方可扼杀细菌”)等。而且,真实文本往往包含多个对象,不同的对象所涉及到的观点、态度等主观信息是有差异的。相比而言,短语级的情感倾向性分析研究将词语组,即由情感词以及与该情感词相关的词,如修饰它的副词、形容词、连词或它所修饰的目标词等组合而成,作为一个整体来考虑文本的情感极性和情感强度。不仅可以提高词语级情感倾向性分析结果,还可以很方便地应用到句子或文档的情感倾向性判断。
鉴于以上分析,本文研究基于短语的文本情感倾向性分析。然而截至目前,国内外在短语级的情感倾向性分析方面的研究较少。目前的研究主要分为两类: 一类是利用预先定义的种子词集、规则(例如,由褒义词+中性词的组合构成的词语组的情感倾向为褒义)以及预先定义的短语情感信息等来判断,并未进行更深入的算法分析[13]。并且这些研究也并非专门针对短语进行分析,而只是将短语情感类别信息作为句子或是文档的情感倾向判断分类器的一类特征;另一类是采用有监督的统计学习方法,如支持向量机(Support Vector Machine, SVM)和条件随机场(Condition Random Fields, CRFs)等,对短语进行情感类别标注[14-17]。尽管SVM或CRFs等统计模型可以挖掘真实文本中蕴含的用户提供的知识,但是它们在挖掘更为复杂的、潜在的关联任务(例如,词语级情感倾向性判断与短语级情感倾向性判断的关联)时表现得力所不及。
据此,本文提出一种扩展式的条件随机场模型YACRFs (Yet Another Condition Random Fields) 对短语进行情感倾向性分析。YACRFs是在CRFs模型的基础上进行扩展,将词语级与短语级的情感倾向性判断问题有效地关联起来,同步实现词语级的倾向性判断与短语情感倾向性判断,通过词语级情感倾向性对短语级情感倾向性产生的直接或间接影响提高短语情感倾向性判断的结果。由于目前没有公开的短语情感倾向性标注语料库,因此首先构造小规模的短语情感倾向性类别信息标注语料库。在此基础上,对该语料进行句法分析,获取短语。本文所指短语亦由具有某种特定句法关系的连续或非连续的词语组构成。例如,表1例子中的句子“在一般情况下,官方发布消息讲求准确、真实,因而在未弄清事实之前会惜墨如金”就由“在一般情况下”、“官方发布消息”、“讲求准确、真实”、“在未弄清事实之前”、“惜墨如金”等几个短语构成。进而,本文将短语情感倾向性分视作对短语的情感倾向性类别信息的标注问题,即给定任意一条短语NP或VP,判定它的情感倾向性为(0/-1/1)。本文采用了3类特征,包括情感词汇特征、规则模板特征、词性特征。实验结果证明,本文提出方法有效提高了短语情感倾向性判断的准确率。相比传统的情感倾向性分析方法取得了最高准确率81.07%的值。模型中使用的3类特征对提高短语情感倾向性的判断具有显著帮助。进一步,将短语级的结果应用于句子情感倾向性分析的实验,得到了94.3%的准确率,从而证明了本文提出方法的实际应用价值。
本文的贡献包含以下两点: (1)本文率先提出将短语情感倾向性分析问题作为序列标注问题加以解决。由于短语情感倾向性的复杂性,单一地对短语进行情感倾向性分析或是通过词语的情感倾向性分析间接想得到短语的情感倾向性分析往往准确率不高。而在条件随机场模型的框架下我们可以方便地对其进行扩展,融合多种特征,实现多层级的情感倾向性的标注,从而更好地解决短语情感倾向性的问题;(2)本文人工构造了小规模的短语情感倾向性标注语料库供实验所用,望该语料库对后期实验有所贡献。
2 模型
2.1 短语获取
短语是由两个或两个以上的词语组合构成的。在计算语言学中,短语可以是具有一定句法关系的词语组,也可以是不具有任何关系的连续词语组。在短语识别及获取的研究中,研究者多是针对具有一定句法关系的词语组开展相应的研究。本文亦是针对具有一定句法关系的短语,开展情感倾向性的分析。本文采用Stanford Parser句法分析器*http://nlp.stanford.edu/software/lex-parser.shtml来获取相应的短语。如图1所示为本文抽取的短语示例(树状表示) 。

图1 短语表示示例(树状表示)
2.2 特征选取
本文在实现短语情感倾向性分析过程中,共使用了三类特征。具体包括:
(1) 情感词汇特征(Polarity): 情感词汇特征是指由情感词汇构成的特征集。情感词汇是指那些能够表达支持/反对或者喜欢/厌恶等意见或情感倾向的词。情感词汇的极性包含正(即支持/喜欢)、负(即反对/厌恶)和中性等3种。以动词极性词为例,高兴、欣赏、快乐等词的极性为正;而讨厌、失败、憎恨等词的极性为负;写、做、工作等词的极性为中性。一般而言,除非包含改变一个词或者短语情感极性的另外的词,否则,包含情感极性词的短语与该情感词汇的极性一致。
由于目前情感词汇词典收录有限,本文考虑将同义词或同类词也纳入到情感词汇特征行列,即假设同义词或同类词具有相同的情感倾向。在同义词或同类词的计算中,许多学者利用WordNet等类义词典计算词的语义相似度。最简单的一类计算语义相似度的方法便是计算两个词在该树状结构上的距离。简单地讲,两个词之间的距离越短,则相似度越大。本文采用潜在语义分析(Latent Semantic Analysis, LSA)算法实现两个词之间的距离。
(2) 规则模板特征(Pattern)。规则模板特征是指由本文设计的具有一定句法关系的词语组构成的连续或非连续的模板构成的特征集。因此,此处规则并非语言学意义上的规则,而是根据设计的具有一定的句法关系的模板抽取出大量的特征。初始设计的模板包含改变一个词或者短语情感极性的另外的词,即词之间相互影响情感倾向性。比如由否定词构成的规则模板。因此,规则模板特征所表现的既是词语之间的直接关联关系,也是短语内部词语之间的隐含关系。
规则模板的构造是在选取一定的产生情感倾向性改变词的基础上,在指定的窗口内与其具有一定的句法关系的词构成。
(3) 词性特征(Part of Speech, POS): 词性特征是指由词语的词性构成的特征。词性作为词语本身固有的特性也将会影响一个词语的情感倾向。比如,形容词多为带有情感色彩的词语,一般而言,形容词的情感倾向不是正就是负。而且有些词取不同的词性时其情感倾向性不一样,例如,“对”这个词当作为介词时其情感倾向为中性,而当作动词时其情感倾向为正。而词语的情感倾向性是直接影响短语情感倾向性的一个重要因素。因此,在短语的情感倾向性判断过程中词语的词性也是一个重要的特征之一。
2.3 情感倾向类别标注模型
本文将短语的情感倾向性判断问题转化为序列标注问题。目前应用于自动标注的模型有很多,例如,自动转换机、隐马尔可夫模型、最大熵模型、支持向量机和条件随机场模型等。条件随机场模型在目前的应用中得到了state-of-the-art的结果[18]。
CRFs是一个无向图模型的框架,它能够被用来定义在给定一组需要标记的观察序列的条件下,求解一个标记序列的概率分布。
定义1 假设X={xt},Y={yt}(t=1,…,T) 分别表示需要标记的观察序列和它相应的标记序列的分布随机变量,那么CRFs(X,Y)就是一个以观察序列X为条件的无向图模型。在给定观察序列X的条件下, 标记序列Y的概率分布如式(1)~(2)所示。
(1)
(2)
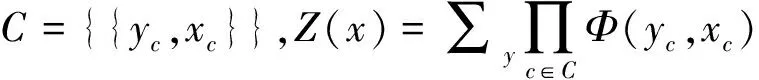
链式条件随机场模型(Linear-Chain Condition Random Fields, LCRFs) 是目前在自然语言处理任务中比较常用的一种CRFs模型,可以说是条件随机场模型中的一个特例。但是目前的LCRFs模型无法同步实现词语级的情感倾向性和短语的情感倾向性判断任务,而词语级和短语级的情感倾向性存在复杂的关联关系,相互影响其情感倾向性的判断。为此,本文提出采用一种扩展式的条件随机场模(Yet Another Condition Random Fields, YACRFs) 来处理该问题。图2显示了链式CRFs与扩展式CRFs的简单例子,图2(a)为LCRFs模型,图2(b)为YACRFs模型。

图2(a) LCRFs模型简单例子
定义2 设G=
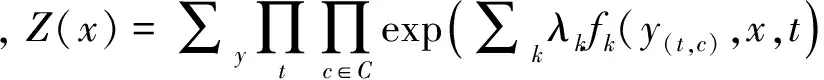
YACRFs仍是一个无向图模型,图中节点表示随机变量,边是节点与节点之间的某种概率依赖关系。如图2(b)所示节点构成了3个链式结构,其中x链是可观察的词语序列(xij表示第i个短语的第j个单词),y链是词语的情感倾向类别,z链为短语的情感倾向类别。同时,x,y,z之间又构成了一个团(Clique),即C为由这三个链中节点构成的一个集合。而在LCRFs模型中xi表示第i个短语,yi表示第i个短语的情感倾向类别。可以看出,YACRFs模型中短语的情感类别信息被更细致化,在模型的构建中考虑到了词语的情感倾向性类别信息对其产生的影响。词语情感倾向类别的值与特征fi以及yi-1相关,而短语的情感倾向类别zi的值与特征fi与yi有关。
2.4 参数估计与推理
进一步对上述公式(4)求偏导数,得到式(5)。
为了减少过度拟合造成的损失,往往通过减去一个估计量λk/σ2实现。利用L-BFGS(LimitedMemoryBFGS)算法可对参数训练过程进行进一步的优化。
推理(Inference)过程也称为解码(Decoding)过程,即根据已知训练模型,对未知变量的解释或推理。在本文中,即根据已知训练模型,获取短语的情感倾向类别。本文采用Viterbi算法实现整个解码过程。
3 实验
3.1 实验数据准备
目前,尚未发现有可供公开评测短语情感倾向性的语料库。因此,本文首先需要构造训练和测试的语料库。本文采用的中文语料来源于网络产品评论文本。
语料库的构造步骤包括: 首先整理评论文本语料,并对评论文本进行预处理,包括去除语言不规范、繁体以及内容重复的内容;然后将篇章级的文档转换为句子级的文档,以一句一行的格式存储;最后,利用句法分析器抽取短语。本文共抽取了28 000条短语。
短语情感倾向性标注语料库的构造流程包括: (1)由两名标注者分别对抽取的短语进行独立标注,每条短语被标注为三个值{1,-1,0}(0:中性,1: 褒义/正,-1: 贬义/反);(2)计算两名标注者的一致性,通过计算Kappa值来选取结果,如果Kappa值超过0.8,则说明两者标注结果的一致性很高,保留该短语的情感信息,否则去掉该短语。依照上述过程,本文共从上述候选的短语中得到25 000条短语。
本文采用的评价指标仅为准确率P。具体定义为P=|A∩B|/|A|。其中A表示分类器识别为正例的数据集合,B表示人工标注为正例的数据集合。
3.2 实验设计及结果分析
本文实验包括3部分: (1)为验证本文提出方法的有效性,开展了与传统的情感倾向性分析方法的对比实验;(2)为了验证本文提出统计分类方法的有效性以及不同特征对统计模型产生的影响,开展了几类统计计算模型以及在其基础上加入不同特征的对比实验;(3)将抽取得到的短语结果应用到句子情感分析,以验证本文提出方法的实际应用价值。
3.2.1 与传统的情感倾向性分析方法的比较
本文实验共设计了三组模型供对比分析。(1) 分层模型(CascadedModel)。第一层是对词语进行情感倾向性判断,首先根据HowNet情感词汇库中的词为基本词汇,去掉停用词以及不常用的词汇;第二层对短语进行情感倾向性判断,此时第一层的词语情感倾向性判断的结果是该层的输入,会根据第一层的结果和相应的规则,对短语进行情感倾向性判断;(2) 投票竞争(Voting)模型。短语的情感倾向通过词语的情感倾向性投票竞争而产生。Voting模型需要设置Voting规则。本文简单设置了Voting规则,即包含1值的高则短语的倾向值取1,包含-1值的高则短语情感倾向值取-1,否则短语的情感倾向值为0;(3)统计分类模型(StatisticalModel)。统计模型对数据进行建模,可以挖掘真实文本中潜在的关联模式。此处实验中采用的统计模型是本文提出的YACRFs模型,该模型采用的特征是本文设计的所有三类特征。
之所以选择以上三类模型进行对比实验是因为它们分别代表了不同的思想。首先本文设计的情感倾向性分析模型YACRFs的主旨思想是基于概率统计的思想,而且就目前而言,概率统计模型在自然语言处理、人工智能和模式识别等领域的应用相当广泛;其次本文设计的分层模型Cascaded的主要思想是基于规则的方法,而基于规则的方法是基于语言学基础的,在面向自然语言信息处理的研究过程中其份量仍然是不可小视;投票竞争(Voting)模型是最为简单的方法,可以说是一种折中的方法。利用词语的情感倾向性结果,通过投票决定短语的情感倾向性。

表2 三组模型对比实验结果
从表2三组模型的对比实验结果可以看出以下结论: 本文设计的统计计算模型得到了最高的值,其次为Cascaded 模型,Voting模型的结果最为差。Cascaded 模型和Voting模型都较强地依赖情感词典,首先通过搜寻情感词汇判断词语的情感倾向性,而本文实验中设计的语料中26%的短语隐含情感词汇,还有35%的短语中的情感词汇属于未登录词(Out of Vocabulary, OOV),因此在第一步得到的结果就可能达不到令人满意的效果。在下一步Cascaded 模型将会根据本文设计的规则模板,最终确定短语的情感倾向,只要符合规则模板的词语组将会得到正确的情感倾向。但是Voting模型完全是通过投票,即谁的(正、负以及中性)投票结果多,短语的情感倾向性将会跟谁一致。这样的判断不可以说完全错误,但是针对隐含情感词汇的短语而言是无法得到正解的。例如,“坐不住”该短语的情感倾向性为“负”,但是投票过程中“坐”和“住”的情感倾向为“中性”,即便“不”的情感倾向为“负”,该短语的情感倾向仍为“中性”而不是“负”。统计模型之所以可以得到较好的结果,是因为在一定规模的训练集内,对数据进行建模,可以挖掘真实文本中隐含的信息。因此,针对具有隐含情感信息的词汇以及未登录词汇的问题,统计模型较之规则方法和投票竞争的折中方法可以得到更好的效果。
3.2.2 与典型的几类统计计算模型以及在其基础上分别加入不同的特征的对比
除了上述三种方法的对比实验之外,本文还分别采用四种统计计算模型进行对比实验: 隐马尔可夫模型(Hidden Markov Model, HMM)、支持向量机(SVM*http://www.csie.ntu.edu.tw/~cjlin/libsvm/)、条件随机场(CRFs*http://mallet.cs.umass.edu/grmm/index.php)以及一种扩展式条件随机场模型(YACRFs)。HMM是典型的产生式模型,而实验中采用的其他三个模型(SVM, CRFs, YACRFs)属于判别式模型。同时为了验证不同特征对统计模型产生的影响,在实验中针对本文设计的三类特征: 情感词汇(Polarity)、规则模板 (Pattern)以及词性类别信息(POS)分别作了相应的实验。之所以设计该实验首先是因为本文设计的情感倾向性分析模型的主旨思想是基于概率统计模型,为了验证本文提出方法的优越性,与几种典型的概率统计模型进行了对比实验。其次是验证统计模型在采取不同特征时的不同效果以及本文选取特征的优越性。实验结果如表3所示。
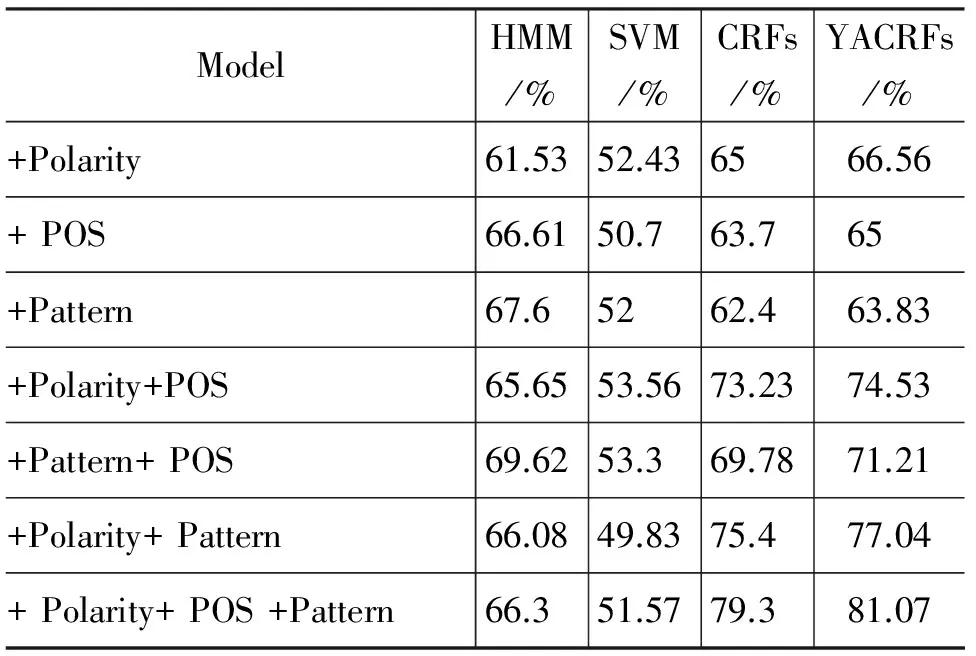
表3 四种统计模型对比实验结果
从表3四种统计模型对比实验结果可以得到如下的结果: (1) 本文设计的YACRFs模型的结果最好,HMM的效果比SVM的效果好,但是不及CRFs;(2)不同的特征对不同模型有不同的贡献度。具体而言,HMM模型采用规则模板特征的效果要比引入情感词汇特征的要高,但是判别式模型的结果却是采用情感词汇特征的效果要比利用规则模板特征的要高。从这一结果分析,判别式模型(SVM, CRFs, YACRFs)对粒度细致的特征有更好的效果;而产生式模型(HMM)可以能更好地抓住内在联系。从分别采用三类特征的结果来看,判别式模型在采用情感词汇特征时的效果最好,而产生式模型采用规则模板特征时的结果最好;从联合使用三类特征的结果来看,并非所有模型在使用三类特征时都取得了较好的结果。从结果可以看到的一点是“情感词汇特征”与“规则模板特征”的联合使用并没有得到预想的效果。HMM模型和SVM模型在此两种特征的混合特征的情况下得到的结果都比分别采用的结果低。而CRFs和YACRFs模型在三类特征混合的情况下都得到了最高值。可以说明条件随机场模型在特征使用过程中的优越性。
3.2.3 应用于句子情感倾向性分析中的实验
本文为了验证短语情感倾向性分析结果对句子情感倾向性分析过程中产生的影响,将词语级(word)的结果对句子产生的影响以及短语级(phrase)的结果对句子产生的影响进行了对比。本节采用的模型是Voting模型以及CRFs模型。本部分采用的句子级的测试数据包括2 000条句子,来源于构造短语情感倾向性语料时用到的网络产品评论文本的句子级结果。

表4 词语级和短语级的结果对句子级的情感分析产生影响的对比实验
对表4实验结果纵向分析,CRFs的结果相差5.05%,而Voting系统的结果差异比较大,准确率相差19.63%。很明显,句子情感倾向分析结果由于短语级的应用得到了更高的值。Voting系统是直接利用正、负或中性的个数竞争来决定情感倾向。显然,将句子划分成几个短语,再通过短语的情感倾向判断句子的情感倾向比以词为单位通过单个词显示的情感信息判断句子的情感倾向更有利;从横向分析的话,就基于短语的系统(Voting和CRFs)之间的差异相比应用词语而言要小不少。说明,短语级的情感倾向性分析对系统性能的提高都有一定的帮助,尤其是针对一些弱势的系统。将句子投影到短语空间时,可以说是通过建立词与词之间的关系,再到词与短语之间的关系,然后到短语与短语之间的关系,最后确定句子的情感倾向性。这样的过程,可以解决词与词之间的相互关系改变其情感倾向的问题,而将句子投影到词与空间是无法做到这一步的。
4 结论
本文提出了一种扩展式条件随机场模型进行短语的情感倾向性分析的研究。该模型扩展了传统的条件随机场模型,解决了词语和短语不能同步标注的问题,并综合使用了3类特征,即: 情感词汇特征、规则模板特征以及词性特征。实验结果表明,本文采用的情感倾向性类别标注模型和 3类特征对于短语情感倾向性判断都是有效的。进一步地,应用于句子级情感倾向性的实验证明了本文方法更具实际意义。
[1] Bo Pang, Lillian Lee. Opinion mining and sentiment analysis[J]. Foundations and Trends in Information Retrieval, 2008,2(1-2):1-135.
[2] Turney Peter. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classi?cation of reviews[C]//Proceedings of 40th Meeting of the Association for Computational Linguistics, Philadelphia, PA.2002: 417-424.
[3] Jaap Kamps, Maarten Marx, Robert J Mokken, et al. Using wordnet to measure semantic orientation of adjectives[C]//Proceedings of the 4th International Conference on Language Resources and Evaluation (LREC 2004), 2004,4: 1115-1118.
[4] Amit Goyal, Hal Daum’e III. Generating Semantic Orientation Lexicon using Large Data and Thesaurus[C]//Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis, Portland, Oregon, USA, ACL-HLT 2011: 37-43.
[5] 朱嫣岚,闵锦,周雅倩等. 基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[6] 李纯,乔保军,曹元大,等.基于语义分析的词汇倾向识别研究[J]. 模式识别与人工智能,2008,21(4) :482-487.
[7] 杜伟夫,谭松波,程学旗.一种新的情感词汇语义倾向计算方法[J].计算机研究与发展.2009,46(10) : 1713-1720.
[8] Esuli Andrea, Fabrizio Sebastiani. SentiWordNet: A publicly available lexical resource for opinion mining[C]//Proceedings of 5th International Conference on Language Resources and Evaluation (LREC), Genoa. 2006: 417-422.
[9] Delip Rao, Deepak Ravichandran. Sem-Supervised Polarity Lexicon Induction[C]//Proceedings of EACL.2009: 675-682.
[10] Daisuke Ikeda, Hiroya Takamura, Lev-Arie Ratinov, et al. Learning to Shift the Polarity of Words for Sentiment Classification[C]//Proceedings of the 3rd International Joint Conference on Natural Language Processing,2008: 296-303.
[11] Shotaro Matsumoto, Hiroya Takamura, Manabu Okumura. Sentiment classification using word sub-sequences and dependency sub-trees[C]//Proceedings of PAKDD’05, Lecture Notes in Computer Science, 2005: 301-311.
[12] Ryan McDonald, Kerry Hannan, Tyler Neylon, et al. Structured Models for Fine-to-Coarse Sentiment Analysis[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 2007: 432-439.
[13] Tetsuji Nakagawa, Kentaro Inuiand Sadao Kurohashi. Dependency Tree-based Sentiment Classification using CRFs with Hidden[C]//Proceedings of Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the ACL, Los Angeles, California, 2010: 786-794.
[14] Theresa Wilson, Janyce Wiebe, Paul Hoffmann. Recognizing contextual polarity in phrase level sentiment analysis[C]//Proceedings of the 2005 Human Language Technology Conference and the Conference on Empirical Methods in Natural Language Processing (HLT/EMNLP-05), Vancouver, 2005: 347-354.
[15] Theresa Wilson, Janyce Wiebe, Paul Hoffmann. Recognizing Contextual Polarity: an exploration of features for phrase-level sentiment analysis[J]. Computational Linguistics. 2009,35(3): 347-354.
[16] Hiroya Takamura, Takashi Inui, Manabu Okumura. Latent Variables Models for Semantic Orientation of Phrases[C]//Proceedings of 11th Conference of the European Chapter of the Association for Computational Linguistics. 2006: 201-208.
[17] Hiroya Takamura, Takashi Inui. Extracting Semantic Orientations of Phrases from Dictionary[C]//Proceedings of NAACL HLT 2007, Rochester, NY, 2007: 292-299.
[18] Charles Sutton, Andrew McCallum, Khashayar Rohanimanesh. Dynamic Conditional Random Fields: Factorized Probabilistic Models for Labeling and Segmenting Sequence Data[J]. Journal of Machine Learning Research . 2007:693-723.
[19] 李本阳,关毅,董喜双,等,基于单层标注级联模型的篇章情感倾向分析[J].中文信息学报,2012,26(4):9-20.

乌达巴拉(1981—),硕士,助理研究员,主要研究领域为自然语言处理、情感分析、模式识别。E⁃mail:hwdbl@126.com汪增福(1960—),博士,研究员,博士生导师,主要研究领域为视听觉信息处理、模式识别、智能机器人。E⁃mail:zfwang@ustc.edu.cn
中国中文信息学会颁发2014年度“钱伟长中文信息处理科学技术奖”“汉王青年创新奖”及“拓尔思优秀博士学位论文奖”
2014年12月20—21日, 中国中文信息学会学术年会暨理事会在北京中国科技会堂隆重举行,会上颁发了“钱伟长中文信息处理科学技术奖”,“汉王青年创新奖”,以及中国中文信息学会优秀博士学位论文“拓尔思优秀博士学位论文奖”;邀请了6位专家进行了学术报告。来自中国科协、民政部、教育部、国家自然科学基金委等部委的领导和中文信息处理领域的专家学者420余人参加了本次会议。
大会开幕式由中国中文信息学会副理事长兼秘书长、中国科学院软件研究所孙乐研究员主持。中国中文信息学会理事长李生教授致欢迎词,中国科协副主席、党组副书记、书记处张勤书记,民政部民间组织管理局廖鸿局长,教育部语言文字信息管理司张浩明司长,基金委刘克处长做了重要讲话,肯定了学会工作所取得的成绩,从不同的角度分析了中文信息处理的应用需求与战略发展。廖鸿局长还向学会颁发了学会在民政部2014年评估中获得的4A等级证书。
“钱伟长中文信息处理科学技术奖”是经科技部批准设立的中文信息处理领域的最高科学技术奖,主要授予该领域在基本方法或关键技术上有原始创新或重大突破,对推动我国中文信息处理事业或行业进步起到重要作用,创造出较大经济效益或社会效益的项目或个人。2014年评选产生了“钱伟长中文信息处理科学技术奖”一等奖两项、二等奖1项,两项一等奖分别授予了中国科学院计算技术研究所程学旗、沈华伟等完成的“社会化媒体数据的分析与检索”,中国科学院自动化研究所宗成庆等完成的“多语种信息采集处理与分析系统”;二等奖授予了西北民族大学于洪志等完成的“云环境的藏语远程教育系统”。
“汉王青年创新奖”设立于2010年,主要授予在中文信息处理领域做出突出贡献的青年学者。2014年该奖项分别授予了清华大学计算机系的刘洋副研究员和中国科学院自动化研究所模式识别国家重点实验室的刘康副研究员。
中国中文信息学会优秀博士学位论文“拓尔思优秀博士论文奖”于今年首次颁发,该奖项专项基金由北京拓尔思信息技术股份有限公司捐资并设立,旨在鼓励中文信息处理领域的博士研究生在读博期间面向前沿方向、立足原始创新、开拓进取,勇创世界领先的研究成果。首届优秀博士论文奖由清华大学计算机系布凡同学获得,论文题目是《文本信息度量研究》;优秀博士论文提名奖分别由北京大学计算机学院的王泉和东北大学计算机学院的肖桐获得,其论文题目分别为《正则化潜在语义索引: 一种新型大规模话题建模方法》和《树到树统计机器翻译优化学习及解码方法研究》。
学术年会上6位国内著名专家进行学术报告,他们分别是上海交通大学副校长梅宏院士、中国社会科学院语言研究所沈家煊学部委员,中国科学院计算技术研究所倪光南院士、北京大学金芝教授、中山大学张军教授以及百度公司沈抖博士,他们从不同角度阐述了中文信息处理领域的前沿动态及未来趋势,深入分析了计算机、语言、认知等学科的充分交叉与融合,有力地促进了中文信息处理领域的理论创新、技术交流与产学研合作。
学术年会后,中国中文信息学会第7届理事会第4次全体会议上,全体理事讨论了2014年度工作报告,研讨了学会工委会和专委会建设,颁发了2014年度“学会工作优秀奖”,获奖者为余正涛教授,增选了周明研究员和李茹教授为学会常务理事。并就学会未来的工作思路开展了讨论。
Phrase-level Sentiment Analysis Approach Based on Yet Another CRFs
Odbal1,2, WANG Zengfu1,2
(1. Department of Automation, University of Science and Technology of China, Hefei, Anhui 230027, China;2. Institute of Intelligent Machines, Chinese Academy of Sciences, Hefei, Anhui 230031, China )
This paper treat the phrase-level sentiment analysis as a sequence annotation problem, and proposes an extension model of conditional random fields, YACRFs, to annotate sentiment orientation of phrases. In contrast to previous works focusing on linear-chain CRFs, which corresponds tonite-state machines wtih efficient exact inference algorithms,we wish to label sequence data in multiple interacting ways—for example, performing word based semantic orientations tagging and phrase-level sentiment analysis simultaneously, increasing joint accuracy by sharing information between them. The proposed model incorporates the word emotional orientation analysis process and the phrase analysis through the incorporation of the features of polarity words, phrase rules template as well as part of speech characteristics. Experiments shows the proposed model performs best with an accuracy of 81.07%. And applied the results in sentence-level sentiment analysis, it brings again the best accuracy of 94.30%.
phrase; sentiment analysis; condition random fields
1003-0077(2015)01-0155-08
2012-08-23 定稿日期: 2012-11-22
TP391
A
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
体育科技文献通报(2022年3期)2022-05-23
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
小天使·一年级语数英综合(2020年4期)2020-12-16
海峡姐妹(2016年2期)2016-02-27
传奇故事(破茧成蝶)(2015年7期)2015-02-28
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
