
基于迭代两步CRF模型的评价对象与极性抽取研究
2015-04-25 08:24张盛,李芳
中文信息学报 2015年1期
张 盛,李 芳
(上海交通大学 计算机科学与工程系,上海 200240)
基于迭代两步CRF模型的评价对象与极性抽取研究
张 盛,李 芳
(上海交通大学 计算机科学与工程系,上海 200240)
微博作为一种新兴媒体,已经在人们生活中扮演了一种不可或缺的角色。如何从大量微博中抽取出有意义的评价对象并识别出正确的情感倾向显得越来越重要。本文在传统的CRF模型基础上,提出了两步CRF模型及迭代两步CRF模型,对评价对象和极性进行抽取。两步CRF模型在COAE2014评测语料上取得了0.505的F值,迭代两步CRF模型通过不断增加训练语料,提高了召回率,使得F值达到了0.513,同时提高了模型的稳定性。实验对比了当前主流的几种方法,结果证明了本文提出的方法是行之有效的。
迭代;两步CRF;评价对象
1 引言
随着时代的发展,互联网慢慢地融入了人们的生活,发挥着不可替代的作用。作为新型社交平台的代表,微博被人们所认识、熟悉和广泛使用。CNNIC的统计报告显示[1],截至2013年12月底,我国网民规模达到6.08亿, 微博用户规模为2.81亿,网民中的微博用户比例达到45.5%。手机微博用户规模1.96亿,接近总体人数三分之二。如此大规模的用户群体加上方便快捷的移动通信设备,必然会导致微博上海量信息的日益膨胀。同时,相对于传统的社交平台,微博信息的传播更加迅速。总的来说,微博已经远非一个单纯的社交平台,它同时也是一个有着巨大潜力的信息源。
曾经稀缺的评论信息在互联网上唾手可得。无论对于政府、企业还是个人来说,对这些评论信息的研究都具有重大的意义,可以辅助其进行某些重要的决策。而微博作为一种新媒体也给评价对象抽取带来了新的挑战。相比具有正规语法和措辞的新闻文本,微博文本更加口语化,里面充斥着大量的错别字和不规则语法,此外还包含着大量的广告信息和垃圾信息,这些都给我们的研究工作带来了很大的困扰,如何行之有效地在给定的微博文本中抽取出重要而有用的信息也变得越来越重要。
本文主要研究以下两个问题:
1) 对于给定的微博,如何正确有效地抽取出用户所评价的对象?
2) 对于抽取出的评价对象,如何判断用户所表达的情感倾向?
在传统CRF模型的基础上,本文提出了一种两步CRF模型,将极性判断的过程与评价对象的抽取结果相结合,使得评价对象抽取达到了0.623的F值,评价对象抽取与极性判断的结果达到了0.505的F值,然后使用迭代的方法提高了1%的召回率,同时增加了模型的稳定性。
本文的主要结构如下: 第2节介绍相关工作,第3节是研究方法的描述,第4节是实验的数据和结果分析,第5节是结论和展望。
2 相关工作
早期的观点挖掘工作主要出现在产品的评价领域,主要目的是为了获取用户评价中正向评价与负向评价的比例,从而帮助购买者进行决策。随着产品评价领域的日趋完善和微博的兴起,观点挖掘工作也开始逐步向微博平台转移,与产品领域不同的是,微博上的信息较为驳杂,用户的用词也较为多样化,不像产品领域里的评价,所有评价都可以找到一个明确的评价对象。
在早期的评价对象抽取研究工作中,Hu和Liu两人提出了一种基于Apriori算法来挖掘产品评论中频繁出现的评价对象的方法[2]。同样,倪茂树也通过统计词频的方法来抽取商品评论中的产品属性[3]。文献[4]中,刘鸿宇提出了基于句法分析的评价对象抽取技术。对于给定语料,首先对其进行分词、词性标注以及句法分析等处理,然后提取其中的名词(NN)和名词短语(NP)得到候选评价对象;继而对候选评价对象使用频率过滤、PMI(point-wise mutual information) 算法和名词剪枝等算法进行筛选得到最终的评价对象集合。Qiu等人[5]使用了依存规则,从一些初始的种子词汇开始,通过使用依存关系进行不断迭代,从而抽取出文档中的评价对象和评论词。这些方法都属于非监督学习的方法,本文同样采用了一种基于规则的方法作为对比实验,该方法在COAE2013评测中在评价对象的抽取工作中取得了最好的结果。借鉴于这些方法,本文采用了词性、句法属性和依存关系作为CRF模型的特征,而最终实验结果也证明了本文的方法相对基于规则的方法在准确率和召回率方面均有所提高。
条件随机域模型[6](Conditional Random Fields,CRFs) 是一种建立切分和标注序列数据概率模型的框架,它用特征函数的方式综合使用各种互相影响的语言特征,集合了最大熵模型和HMM模型的特点,回避了传统HMM方法处理长距离关联的不足和MEMM等模型中的标注偏置问题。在语义角色标注任务中,CRF模型表现非常良好,所以在近年的研究中屡次被使用到。Jakob等人[7]使用CRF模型在单领域和交叉领域的评价对象抽取工作中均取得了较为不错的结果,但是该方法只是对评价对象进行了抽取,并没有判断用户对于评价对象的情感倾向。曾冠明[8]使用了单个CRF模型,在命名实体识别任务上系统F值达到了93.49。Yang等人[9]首先使用CRF模型对评价对象和评价词进行了标注,然后提出了一种联合推理的方法来判断评价对象和评价词之间的关系。王智强等人[10]根据汉语的依存关系,提出了框架的概念,将评价对象的抽取任务转化为框架语义角色的标注任务,然后使用了TCRF(Tree Conditional Random Field)模型进行评价对象的抽取工作。 郑敏洁等人[11]提出了一种层叠CRF模型,分别对评价对象和属性进行了抽取。郭剑毅[12]和胡文博[13]分别使用了多层CRF模型对评价对象进行抽取,先在第一步中抽取出基础的评价对象,然后在之后的CRF模型中对这些评价对象进行拓展。而本文中同样使用了多层CRF模型,只是将第二步的CRF模型从评价对象的拓展转变为了评价极性的判断。
关于极性的判断,传统的方法使用了情感词典的方法。而Pang B[14]和Liu B[15]都直接使用文本分类的方法,对整个句子判断极性,文本分类使用机器学习的方法,并将情感词作为其中的一个特征。本文同样将情感词作为其中的一个特征,然后结合评价对象的抽取结果对其极性进行判断,从而提高了最终的实验结果。
3 方法介绍
本文方法包括两步CRF模型和迭代部分。两步CRF模型中先后训练两个CRF模型分别对评价对象进行抽取和对评价对象的极性进行判断,而迭代部分则对整个两步CRF模型进行迭代,下面将分别介绍这两个部分。
3.1 预处理
微博预处理包含微博文本中URL的过滤,这些URL会对分词器进行干扰,所以需要预先对其进行处理。在微博中会出现“@”符号表示引用“@”符号后的对象或通知该对象,但是这种用法同样可以用来表示对该对象进行评价,所以需要对这种符号进行处理,在这里直接使用空格对“@”进行替换。然后对微博进行分词和语法分析。分词采用中科院的分词工具ICTCLAS*ICTCLAS: http://www.ictclas.org/,语法分析采用Stanford parser*Stanford Parser: http://nlp.stanford.edu/software/lex-parser.shtml,对分词得到的词语序列建立语法树,同样使用Stanford parser对语法树进行依存句法分析,从而得到句中的依存关系,将语法树和依存关系保存到文件,并对这些文件建立索引,索引的建立采用Lucene工具*Lucene: http://lucene.apache.org/。
3.2 两步CRF模型
3.2.1 两步CRF模型
对于给定的输入序列W={wt},本文会输出两个标注序列: 评价对象标注序列Y={yt},yt∈{B,I,L,O,U},分别表示评价对象开始(B)、评价对象内部(I)、评价对象结束(L)、非评价对象(O)、单个评价对象(U),和评价极性序列Z={zt},zt∈{1,-1,0},分别表示正向、负向和中性。如图1所示。

图1 两步CRF模型串标注序列
对于评价对象标注序列Y的求解公式如式(1)所示:
其中,mk(yi-1,yi,W,i)和nk(yi,W,i)是特征函数,λk和μk是其对应的权重,由训练样本学习得到,Z(W)为归一化因子,i为相应特征的下标。
对于评价极性标注序列Z的求解公式如式(2)所示:
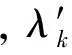
两步CRF模型的流程图如图2所示。首先从训练语料中抽取出评价对象特征集与评价极性特征集,分别进行CRF模型的训练,得到两个CRF模型: 评价对象模型与评价极性模型。对于测试数据,首先抽取出其评价对象特征集和评价极性特征集,再根据评价对象模型进行评价对象的抽取,然后将得到的评价对象标注序列加入评价极性特征集,再使用评价极性模型进行评价极性的判断,从而得到最终的结果。
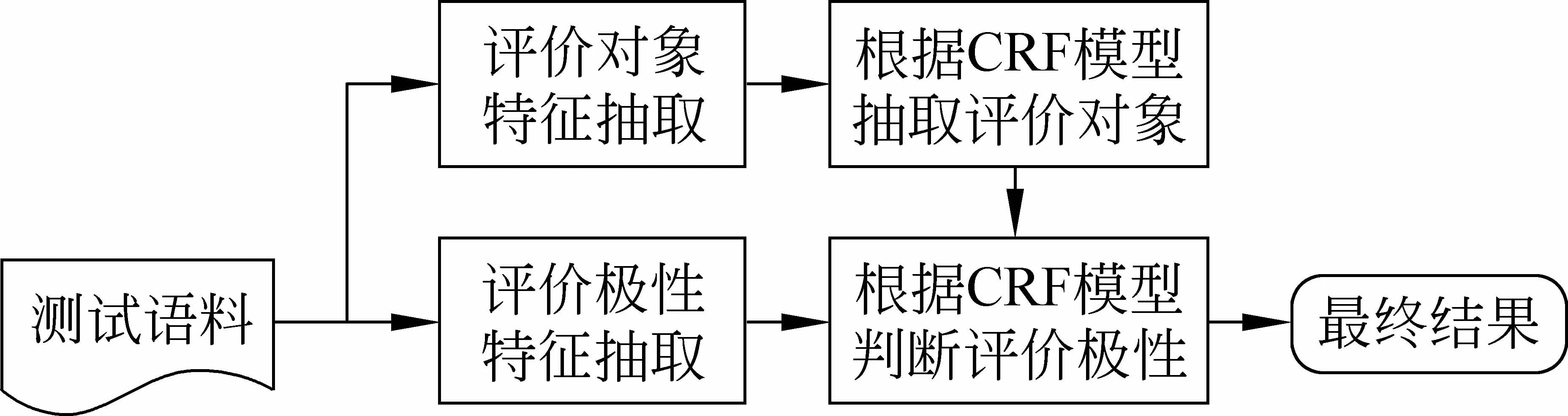
图2 两步CRF模型流程图
3.2.2 评价对象特征选择
评价对象模型训练采用的特征如表1所示。对于给定的语料,评价对象通常不会只出现一次,特别是对于给定领域的语料,评价对象出现频率较高,倪茂树[3]等人采用了基于词频的方法作为抽取评价对象的标准,所以本文将词语本身作为一个特征。从词性来看,大部分评价对象是名词或名词短语,有些评价对象前还有修饰短语,因此本文加入了词性特征。单字或双字的词更容易和其他词语组合成评价对象,故加入词长这一特征。

表1 评价对象抽取特征选择
从语法方面来看,评价对象出现的位置更倾向于主语或者宾语,在语法树上节点多为NN或者NP,与此同时,依存关系也显得尤其重要,当评价对象是由两个或多个名词组成时,这多个名词之间会存在NN的依存关系,而且评价对象多被形容词所修饰,故常出现在NSUBJ(名词性主语)关系中。因此本文在加入了语法特征的基础上,加入了NN和NSUBJ两个依存关系作为特征的一部分。
评价对象多与评价词距离较近,而评价词多为情感词,所以评价对象抽取模型中加入情感特征。
3.2.3 评价极性特征选择
评价极性模型所采用的特征如表2所示。与评价对象模型相同的考虑,本模型加入词特征和情感特征。为确保极性判断只针对评价对象,因此引入评价对象抽取模型的标注结果作为一组特征。在一个充满褒义词的句子中,一个否定词往往会令句子的极性反转。微博语料中的标点符号通常带有一定的情感倾向,例如常用多个感叹号“!!!!”表示惊讶,或省略号“……”表示无奈或者无语。因此在评价极性判断模型中加入否定词和标点符号的特征。

表2 评价对象极性判断特征选择
3.3 迭代模型
训练语料的选取始终是机器学习方法所关注的一个重点。为提高本文方法的召回率,在两步CRF模型的基础上加入了迭代的方法,对每次实验结果进行筛选,选取其中置信度大于阈值的结果加入训练语料,剩余的继续作为测试语料,进行重新训练和测试,如此迭代反复,来提高两步CRF模型的召回率。迭代流程图如图3所示。

图3 迭代模型流程图
在迭代模型中,对于每条微博的抽取结果计算置信度C,计算方法如式(3)所示,其中c1表示评价对象抽取时CRF工具给出的句子置信度,c2表示极性判断时CRF工具给出的句子置信度。
选择置信度大于M的微博加入训练集,剩余的继续作为测试数据,然后重新训练模型,并对结果进行抽取,如此循环N次,从而得到最终的结果。
4 实验与结果
4.1 实验数据与实验设置
实验数据采用COAE2014评测数据*COAE2014: http://www.liip.cn/CCIR2014/pc.html,采用最终评测结果的5 000条微博作为实验数据。评价对象正负向极性分布如表3所示。
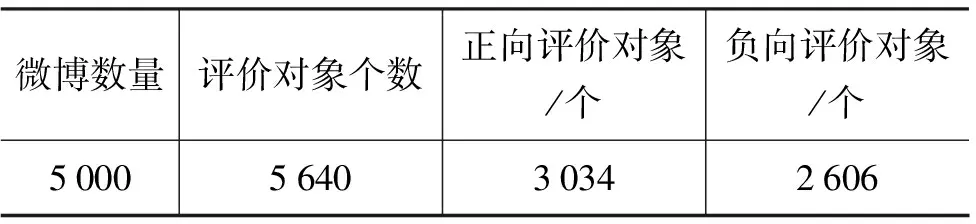
表3 微博评价对象及正负向统计
实验中采用的情感词典主要来自NTUSD(台湾大学)情感词集合*NTUSD: http://nlg18.csie.ntu.edu.tw:8080/opinion/#和Hownet(知网)情感词集合*Hownet: http://www.keenage.com/,同时加入了一些手工标注的网络新词,例如,“坑爹”、“伤不起”等等。
在实验中特征窗口设置为3,即在CRF模板中,将左右三个词的特征同时加入进来作为一个词的特征,同时将这些特征进行组合作为新的特征,实验采用的CRF工具为CRF++*CRF++:http://crfpp.googlecode.com/svn/trunk/doc/index.html。迭代模型选定阈值M=0.8,迭代次数N选取为4。
4.2 对比实验
本文对当前抽取评价对象比较常用的几种方法进行了对比试验。对于非机器学习的方法,本文选取了基于规则的方法。机器学习的方法,本文选取了一种传统的方法,即先进行CRF训练,然后使用情感词典的方法进行极性判断,另一种是联合的方法,collapsed方法。同时本文对于是否进行迭代进行了对比,具体方法说明如下:
1) 基于规则的方法。作者使用该方法在COAE2014评测中评价对象的抽取与极性判断任务中宏观F值达到了0.339,取得了第一名的成绩。该方法对不同领域的评价对象建立不同的规则,进行了评价对象的抽取。
2) Collapsed方法。Mitchell M等人[16]提出的一种方法,通过在CRF模型中将评价对象标签与极性标签相结合的方法从而对评价对象和极性进行同步抽取。采用特征为评价对象抽取特征和极性判断特征的结合。
3) CRF+情感词典的方法。先使用CRF对评价对象进行抽取,然后使用情感词典的方法对评价对象进行极性的判断。
4) 两步CRF模型的方法。仅使用两步CRF模型对评价对象和极性进行抽取。如图2所示。
5) 迭代两步CRF模型的方法。在两步CRF模型的基础上进行迭代,如图3所示。
4.3 实验结果
实验每次随机选取数据中的2 000条进行训练,剩余3 000条进行测试,循环多次取平均值进行对比。
4.3.1 迭代模型参数实验
实验首先对于迭代两步CRF模型中的参数进行了对比实验。实验结果如图4所示。本文对于置信度M和迭代次数N进行了对比实验,由实验得知,当M取0.9和0.95时,由于加回的数据太少,所以导致F值提升较小。M取0.8时,加回语料有所增加,所以最终的结果也是最好的,但是随着迭代次数的增加,实验中必然会引入一些噪声,所以实验结果反而有所下降。四种M值随着迭代次数的增加,都慢慢趋向于稳定,原因是大于该M值的微博已全部被加入训练语料,训练语料不再增加,所以模型也趋于稳定状态。
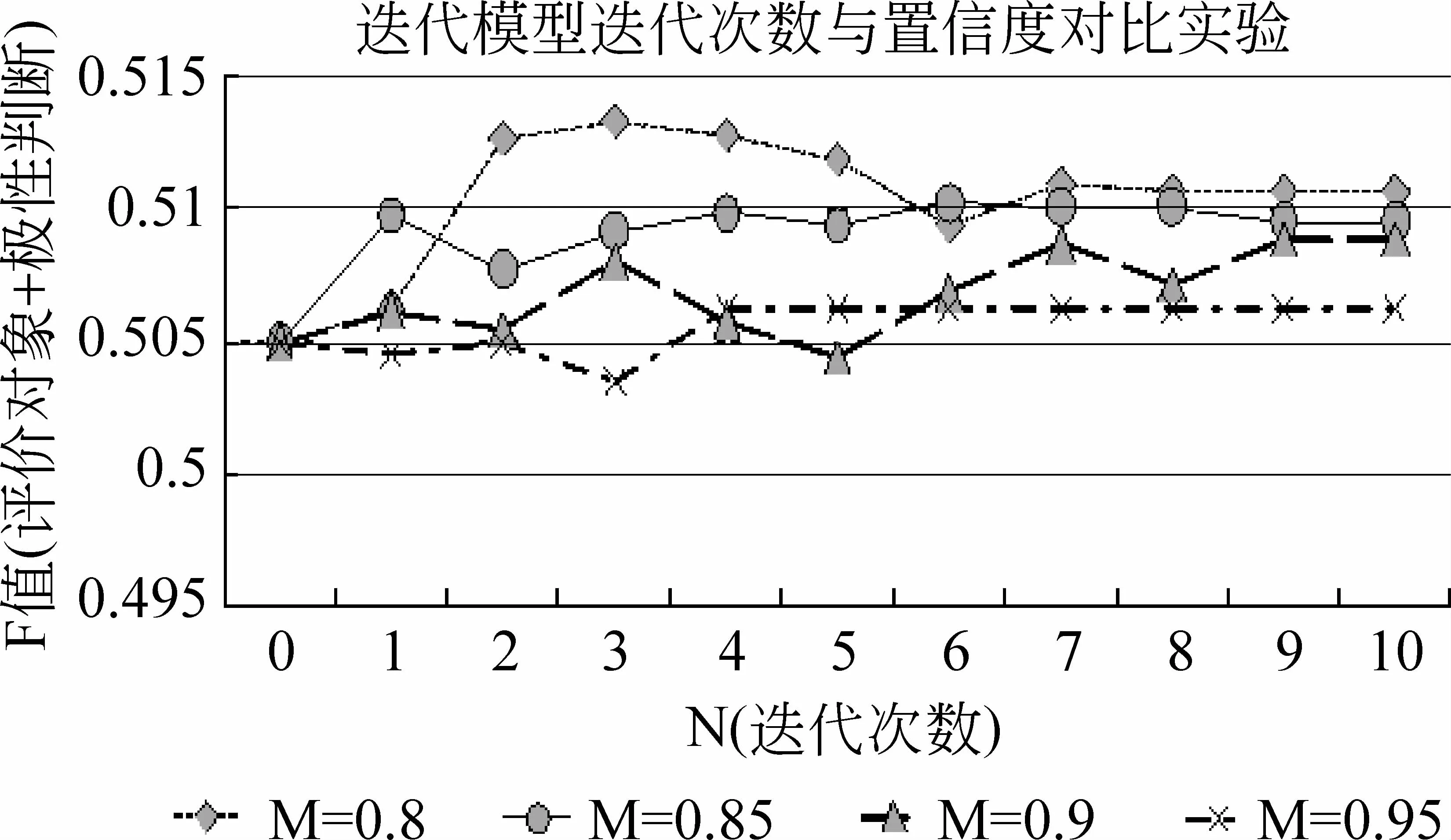
图4 迭代两步CRF模型中迭代次数与置信度对比实验
4.3.2 评价对象以及极性抽取实验
评价对象的抽取结果如表4所示。评价对象与极性的抽取结果如表5所示。通过对比可得,CRF+情感词典的方法与两步CRF模型的第一步,即评价对象的抽取表现相同,但是都相对于基于规则的方法有了大幅度提高。Collapsed方法虽然相对于基于规则的方法在实验结果上有所提高,而且在准确率上要稍高于两步CRF模型,但是在召回率方面明显低于两步CRF模型,从而导致F值也比两步CRF模型要低。迭代两步CRF模型的方法在保持两步CRF模型的准确率的前提下提高了召回率,从而提高了F值。

表4 评价对象抽取结果对比
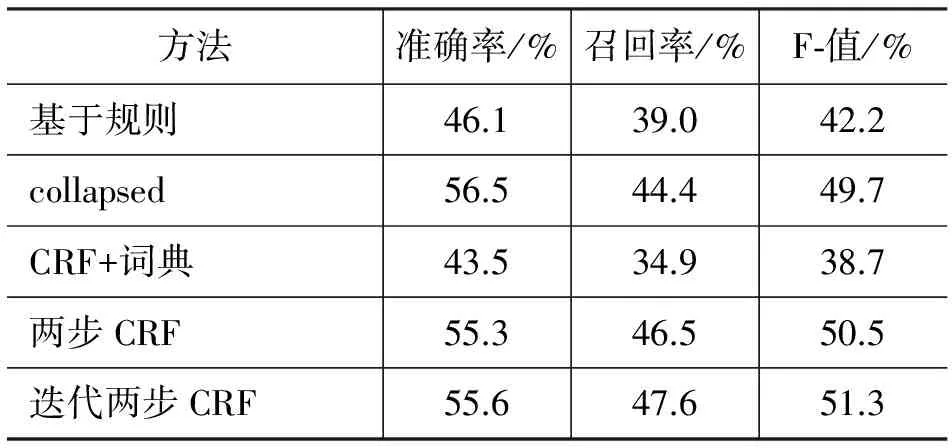
表5 评价对象+极性抽取结果对比
4.3.3 不同训练集实验结果
本文对于训练语料大小进行了对比实验,实验结果如图5和图6所示。由于两步CRF模型的第一步实验结果与CRF+情感词典法相同,所以在图5 中仅对基于规则的方法、collapsed方法、两步CRF模型和迭代两步CRF模型进行了评价对象抽取的对比实验,而在图6中则对基于规则的方法,CRF+情感词典的方法、collapsed方法、两步CRF模型和迭代两步CRF模型进行了对比。
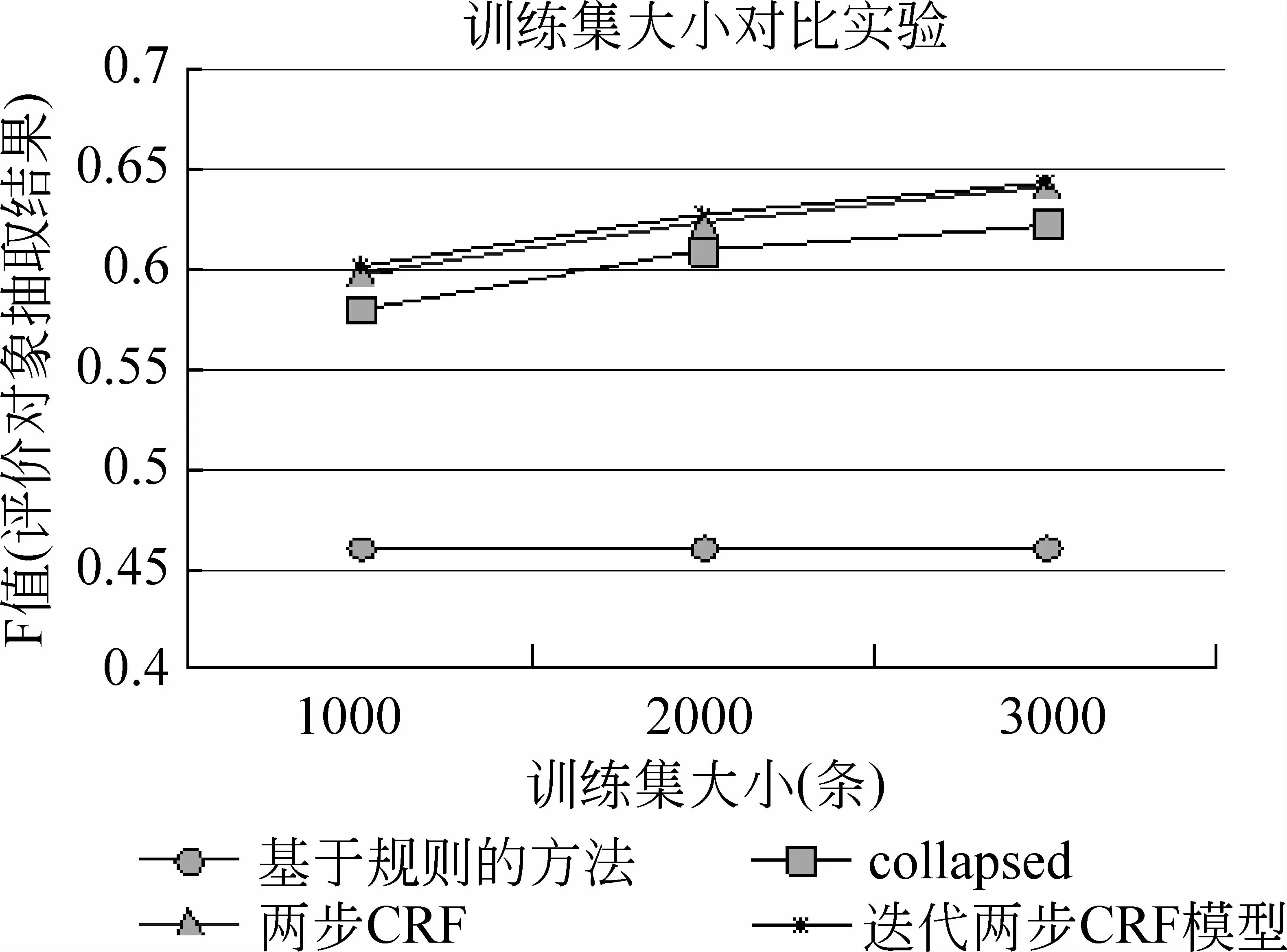
图5 不同训练集大小下迭代两步CRF,两步CRF,collapsed,基于规则的方法关于评价对象抽取的对比实验

图6 不同训练集大小下迭代两步CRF,两步CRF,collapsed,CRF+词典,基于规则的方法关于评价对象抽取与极性判断的对比实验
由图中可知,由于基于规则的方法并不依赖于训练集,所以随着训练集大小的变化并无相应变化,而collapsed模型和两步CRF模型随着训练集的增加,结果有了明显的提升,说明训练集的大小有助于实验结果的提升,在此前提下,本文加入了迭代的方法,将测试语料中得到的置信度较高的结果加入训练数据,进行迭代,从而提升了实验的F值。此外,在实验中还可看出,随着语料的增加,两步CRF模型始终要比collapsed模型结果偏高一些,证明了两步CRF模型是行之有效的。同时可以看到训练集为3 000时,迭代模型对于实验结果的提升明显不如训练集为2 000时的效果,说明训练模型已经趋向于稳定。
4.4 错误分析
在实验中,选取其中一次实验结果进行分析,分析得知当前模型存在三种问题。
1. 对于给定微博,抽取评价对象为空。一种原因是因为给定微博中的评价对象在训练语料中大部分情况下为非评价对象,因此在抽取时也未能成功抽取。例如微博“春江水暖,乳燕南飞,晚霞映碧波。好一幅诗情画意的江南美景。这只福寿禄的镯子翠的阳俏,翡的光艳,白的绵柔,三种颜色交融一体,让人观之心生喜爱。三种颜色代表福寿禄,出现在同一块翡翠上的几率不多,具有很高的收藏价值。”中评价对象应为“福寿禄的镯子”,但是由于“镯子”一词在训练语料中大部分情况下为非评价对象,因此未能成功抽取。另一种原因是由于评价对象缺少成分。例如微博“北京前三季保险投诉平安居首。”中评价对象为“平安”,但是在训练语料中“平安”一词多与“保险”一词组成“平安保险”被一并抽取出来,而单个的平安由于词性被划分为形容词,所以未能成功抽取。
2. 抽取结果与答案不匹配。在本次实验中,不匹配有以下几种情况: 第一种情况是经常会抽取出一些非评价对象的答案,这些将在下一步的工作中进行过滤;第二种情况则是会将评价对象及其属性一并抽取出来,例如微博“是义诊,该不是议诊吧?这么多的人,充分说明了国家的医疗保险体系纯粹是扯淡。”中评价对象应为“医疗保险”,而“体系”则是“医疗保险”的一个属性,但是本文提出的方法却将“医疗保险体系”一并抽取了出来,说明本文方法中仍存在着一定的特征冲突,从而不能进行完好的抽取;第三种情况则是由于某个词在训练语料中经常被当做评价对象,从而导致与该词一起的评价对象不能完整抽取,例如微博“在本命年店买的一个翡翠的鸡贵人吊坠,今天让一个懂行的人瞧了,说最多值一百多块。”中评价对象应为“翡翠的鸡贵人吊坠”但是实际抽取结果则是“翡翠”,原因是训练语料中“翡翠”一词作为评价对象的概率非常高,从而导致的抽取错误。
3. 极性判断错误。对于句中存在多个评价对象的情况,评价极性的判断会很容易出现错误。此外,若评价对象附近没有相关情感词,或者距离情感词过远,或附近情感词过多,都会对评价对象极性的判断造成干扰。
5 总结
本文在传统的CRF模型上进行了改进,提出了两步CRF模型及迭代两步CRF模型,有效地使用了词特征、语法特征、依存特征以及情感特征,实验结果也证明了我们的方法是行之有效的,在本文中,将我们的方法和基于规则的方法,传统的CRF加情感词典的方法及collapsed的方法等三种方法进行了对比,实验结果证明了我们的方法相对这些方法取得了一定的优势。但是在和collapsed方法对比时,我们的准确率还有待进一步提高。
与此同时,本文提出的方法还存在着一些问题。例如,部分评价对象不能有效抽取,一些微博的抽取结果仍然为空,特征中存在着一些冲突,这些都是我们下一步研究的重点。目前,我们的模型对于训练语料存在着很大的依赖性,如何将模型进行泛化,将之推广到不同的领域,也是我们以后要努力的方向。
[1] 张紫. 第 33 次中国互联网络发展状况统计报告[J]. 计算机与网络, 2014, 40(2): 5-5.
[2] Hu M, Liu B. Mining and summarizing customer reviews[C]//Proceedings of the tenth ACM SIGKDD international Conference on Knowledge Discovery and Data mining. ACM, 2004: 168-177.
[3] 倪茂树.基于语义理解的观点评论挖掘研究[D].大连理工大学,2007.
[4] 刘鸿宇,赵妍妍,秦兵,刘挺.评价对象抽取及其倾向性分析[J].中文信息学报,2010,24(01):84-88,122.
[5] Qiu G, Liu B, Bu J, et al. Opinion word expansion and target extraction through double propagation[J]. Computational linguistics, 2011, 37(1): 9-27.
[6] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the Eighteenth International Conference on Machine Learning, 2001: 282-289.
[7] Jakob N, Gurevych I. Extracting opinion targets in a single-and cross-domain setting with conditional random fields[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2010: 1035-1045.
[8] 曾冠明. 基于条件随机场的中文命名实体识别研究[D].北京邮电大学,2009.
[9] Yang B, Cardie C. Joint inference for fine-grained opinion extraction[C]//Proceedings of ACL. 2013: 1640-1649.
[10] 王智强, 李茹, 阴志洲, 等. 基于依存特征的汉语框架语义角色自动标注[J]. 中文信息学报, 2013, 27(2): 34-40.
[11] 郑敏洁, 雷志城, 廖祥文, 等. 基于层叠 CRFs 的中文句子评价对象抽取[J]. 中文信息学报, 2013, 27(3): 69-76.
[12] 郭剑毅, 薛征山, 余正涛, 等. 基于层叠条件随机场的旅游领域命名实体识别[J]. 中文信息学报, 2009, 23(5): 47-52.
[13] 胡文博, 都云程, 吕学强, 等. 基于多层条件随机场的中文命名实体识别[J]. 计算机工程与应用, 2009, 45(1): 163-165.
[14] Pang B, Lee L. Opinion mining and sentiment analysis[J]. Foundations and trends in information retrieval, 2008, 2(1-2): 1-135.
[15] Liu B, Zhang L. A survey of opinion mining and sentiment analysis[M]. Mining Text Data. Springer US, 2012: 415-463.
[16] Mitchell M, Aguilar J, Wilson T, et al. Open domain targeted sentiment[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013: 1643-1654.
Opinion Target and Polarity Extraction Based on Iterative Two-Stage CRF Model
ZHANG Sheng, LI Fang
(Dept.of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China)
As a new media, Microblogging has been playing an indispensable role in people’s life. To extract sentimental information from the Microblogs, this paper introduces a two-stage CRF model and an iterative two-stage CRF model. The two-stage CRF model reaches an F-score of 0.505 on the COAE2014 evaluation data, and the iterative two-stage CRF model reaches an F-score up to 0.513 by an improvement in the recall.
iteration; two-stage CRF; opinion target

张盛(1992—),硕士研究生,主要研究领域为自然语言处理。E⁃mail:cmy_zs@163.com李芳(1963—)通讯作者,博士,副教授,主要研究领域为自然语言处理、信息检索与抽取。E⁃mail:fli@sjtu.edu.cn
1003-0077(2015)01-0163-07
2014-08-11 定稿日期: 2014-10-24
国家自然科学基金(61375053,60873134)
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
湖南税务高等专科学校学报(2021年4期)2021-08-30
中学生数理化·中考版(2020年10期)2020-11-27
时代英语·高一(2019年5期)2019-09-03
天然产物研究与开发(2018年9期)2018-10-08
意林(2018年3期)2018-03-02
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
航天返回与遥感(2014年1期)2014-07-31
外语教学理论与实践(2014年2期)2014-06-21
