
基于K武装决斗土匪问题的排序器在线评估算法
2015-11-04 06:19邓晓军满君丰欧阳旻
计算机工程 2015年9期
邓晓军,满君丰,欧阳旻
(湖南工业大学计算机与通信学院,湖南株洲412007)
·开发研究与工程应用·
基于K武装决斗土匪问题的排序器在线评估算法
邓晓军,满君丰,欧阳旻
(湖南工业大学计算机与通信学院,湖南株洲412007)
对各种不同的排序器进行评估可以选出较优的排序器,从而为用户的个性化检索提供更好的排序结果。因此,为提高排序器评估结果的性能,根据现有研究结果将排序器评估形式化描述为K武装决斗土匪问题,提出一种基于采样的高效K武装决斗土匪算法,并分析2种模式下的求解目标。通过采样的方式模拟赛事并选出获胜者,根据置信上界在剩余排序器中选出挑战者,并将获胜者与挑战者进行交错比较,得出评分矩阵。实验结果表明,与SAVAGE算法及RUCB算法相比,该算法不仅准确性高,累计失望值小,而且具有较好的稳定性。
信息检索;排序器;失望最小化;K武装决斗土匪检测;在线评估算法
1 概述
排序器评估是在给定的若干个排序器中确定哪个性能是最优的,是信息检索领域的重要研究内容之一[1]。离线排序器评估可以追溯到早期的Cranfield实验[2]。该实验通过人工的方式对排序器进行评估,评价的标准基于一个固定的查询和文档集合。这种人工判别的方式代价高,并且容易出错。由于评估者没有对查询进行形式化描述,他们的评估并不能准确地反映这些文档在何种程度上满足真实用户的需求[3]。
排序器在线评估通过真实用户的点击反馈来评价排序器的性能,可以有效地解决上述问题。排序器在线评估通常采用交错比较法[4],即对于给定的查询,将2个候选排序器的结果交错在一起构成一个文档列表展现给用户,通过用户的点击反馈来推导2个排序器的性能[5]。交错比较法面临的一个关键问题是如何通过成对比较在多个排序器中选出最优的,该问题可以形式化地描述为K武装土匪问题[6]。在K武装土匪问题中,最优的排序器预计在与其他排序器的成对比较中都会胜出。
在探索后开发模式中,在线评估算法在一个固定的时间段(称为horizon)内完成,并评价出最优的排序器[7]。这种方法的评价指标为算法选出的最优排序器的准确性和horizon时间段内累计的失望(regret)值。失望是交错比较中排序器的次最优(相对于最优)的度量标准。在探索后开发模式中,排序器在线评估采用的方法有交错过滤法[6]、打败均值法[8]、通用探索变量的敏感性分析[9]等。在持续失望最小化(ongoing regretm inim ization)模式中,不需要预先指定固定的时间段,通过最小化累计失望值进行排序器的评估,如RUCB算法[10]。
本文基于采样方法,提出一种高效的排序器在线评估算法。通过采样的方式模拟赛事并选出获胜者,根据置信上界在剩余排序器中选出挑战者,并将获胜者与挑战者进行交错比较。
2 问题描述
K武装土匪问题中存在K个排序器{ρ1,ρ2,…,ρK},每一个时间步根据未知稳态分布的期望值μi(即用户的点击率)对排序器ρi进行测试,并产生相应的收益值。K武装决斗土匪问题是K武装土匪问题的变体形式,通过交错比较法对排序器进行评估,并对用户的反馈进行建模。
K武装决斗土匪是一个比较概率矩阵P=[Pij]。在每一个时间步中,通过交错比较法对2个排序器ρi和ρj进行比较,得到ρi打败ρj的概率Pij。本文假设K个排序器中存在Condorcet获胜者[9]:存在排序器ρi,使得将Condorcet获胜者与任意一个排序器进行交错比较,Condorcet获胜者都将获胜。
K武装决斗土匪问题的目标可以通过多种方式进行形式化描述,不同的目标形式化方法决定不同的求解算法。本文考虑如下2个目标:
(1)explore-then-exploit[6]:在该模式下,算法需要预先指定探索的时间段,在探索时间段结束后,探索过程选取一个最优的排序器,该排序器在后续阶段被使用。算法的准确性通过指定时间段内找出Condorcet获胜者的概率来评估,以及探索过程累积的失望值。在每一步探索过程中,失望值的定义为:如果在时间t选取ρi和ρj进行比较,那么失望值为:

(2)ongoing regret minimization[11]:该模式下并不需要指定探索的时间段,评估过程连续执行,因而算法的评价指标不再是指定时间段后最大化准确性和最小化失望值。该模式的目标可以形式化为最小化随时间变化的累积失望值。
3 排序器在线评估方法
本文提出了一种基于采样的高效K武装决斗土匪算法,该算法在通过竞争移除排序器时可以明显减少累积失望值,可同时应用于explore-then-exploit和ongoing regret minimization2种模式。
本文提出的算法与RUCB算法都适用于ongoing regret minimization模式,其区别在于本文算法通过循环赛选取获胜者时进行采样操作。该采样操作的目的是:维护每个排序器期望值的后验分布,并对这些后验分布进行采样来选取最优的排序器。通过采用Thompson采样[12],该算法的性能明显优于RUCB算法。RUCB算法依赖于期望值的估计,该估计值可能与真实值有很大偏差,然而采样方法依赖于后验分布,并且后验分布不会导致期望值趋向极值,因而不会导致可能的选项经常被选取。
在排序器评估中对后验分布的采样更加合理,并且会提高算法的效率。RUCB算法在候选获胜者的选择中很保守,除非确认ρi明显低于其他排序器外,否则ρi仍有可能为潜在的获胜者。本文提出的采样方法认为,一个排序器打败其他排序器的概率越高,那么这个排序器成为获胜者的概率越大。
本文提出的基于采样的K武装决斗土匪算法的基本思想如下:根据K武装决斗土匪规则应用采样方法在排序器之间进行赛事模拟,依据采样得到的结果判断每2个排序器获胜的概率大小;当某个排序器打败其他所有的排序器时,认为该排序器为获胜者,如果不存在获胜者,那么令获胜者为上述选取过程中选为获胜者次数最少的排序器;根据采样次数的增加逐渐移除性能较弱的排序器,最终用Condorcet获胜者作为最优的排序器。算法详细描述如下:
算法 基于采样的K武装决斗土匪算法
输入 排序器集合{ρ1,ρ2,…,ρK};交错比较器C

该算法的输入为排序器集合{ρ1,ρ2,…,ρK}和交错比较器C,交错比较器对任意2个排序器进行比较并选出获胜者以及获胜的概率。由于算法没有预先指定时间段,因此该算法没有输出结果,最优排序器的频率会随着时间的推移越来越大。该算法包含一个参数α(第1行)控制算法的探索行为的能力,α值越大,算法落在单个排序器上的速度越慢。该算法同时维护一个评分矩阵W(第2行)用于保存排序器之间的两两比较结果。
算法的初始化部分为第1行~第2行,循环体部分为第3行~第11行。循环体内部可以分为如下3个部分:
(1)赛事模拟部分(第4行~第7行)。基于当前的评分矩阵W进行赛事模拟。对于任意一对排序器ρi和ρj,令维护的后验概率Pij符合参数为Wij+ 1和Wji+1的β分布,并对Θij(t)进行采样。由于Pji=1-Pij,令Θji(t)=1-Θij(t)。对于所有的排序器,其与自身的比较胜率为所以在得到上述采样结果后,如果那么ρi打败ρj。在获胜者的选取过程中存在以下2种情况(第7行):
2)如果不存在获胜者c,那么令c为上述选取过程中选为获胜者次数最少的排序器,即c=
在上述赛事模拟过程中,一旦Condorcet获胜者与其他排序器进行比较的次数足够多时,就会将其与的排序器移除。随着时间的推移,该Condorcet获胜者被选为获胜者的概率会越来越大。
(2)根据c寻找置信上界(第8行~第9行)。本文应用置信上界算法来解决K武装分子问题。对于任意一个j∈{1,2,…,K},计算如下乐观估计:
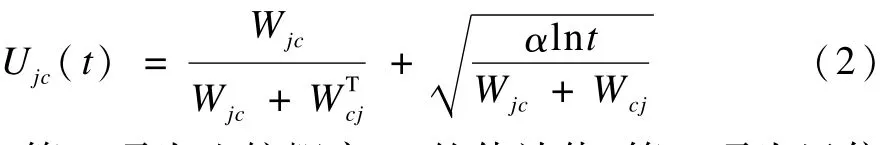
其中,第1项为比较概率Pjc的估计值;第2项为置信区间。该置信区间允许其他排序器与c进行乐观比较,从而保证足够的探索空间。然后,选取排序器d,并且使得Udc>Ujc(c∈{1,2,…,K})。
(3)更新比较结果(第10行)。最后,将获胜者c与挑战者d进行交错比较,并将比较结果更新到评分矩阵W中。
4 实验结果与分析
4.1 数据集与实验设置
实验采用2个公开的学习排序数据集Microsoft[13]和Yahoo![14],其中Yahoo!数据集包含2个不同的数据集,实验选取了较大的数据集。数据集的基本信息如表1所示。在这2个数据集上,应用BM 25[15]算法对每个特征进行排序,并将每个排序结果视为一个排序器。

表1 数据集基本信息
在explore-then-exploit模式中,应用准确率和累积失望值作为评价指标。在ongoing regret minimization模式中,应用累积失望值作为评价指标。准确率为得到最优排序器的比例。失望值的定义如式(1)所示,累积失望值为给定时间内算法的失望值之和。当排序器评估算法进行次最优选择时,会累积失望值,这意味着最优排序器并没有和自身进行交错比较。在实验中,令RUCB算法和本文提出的采样算法的参数α=0.501,这可以确保RUCB算法不必进行太多的探索就可以得到可行解。
4.2 实验结果
首先,在Exp lore-then-exploit模式下,将本文提出的采样算法与SAVAGE算法进行对比。2种算法在Microsoft和Yahoo!数据集下的准确率和累计失望值对比如图1所示。图1(a)和图1(b)为2种算法的准确性对比,随着时间的推移,2种算法的准确性都逐渐提高,然而本文算法的准确性始终高于SAVAGE算法,并且很快就收敛到1。图1(c)和图1(d)为2种算法的累计失望值对比,随着时间的推移,2种算法的累计失望值都逐渐增大,并且本文算法的累计失望值要小于SAVAGE算法。当时间达到103s时,本文算法的累计失望值增长缓慢,然而SAVAFE算法却在时间超过104时才增长缓慢,这说明本文采用的采样算法不仅能快速确定最优排序器,而且具有更小的累计失望值。
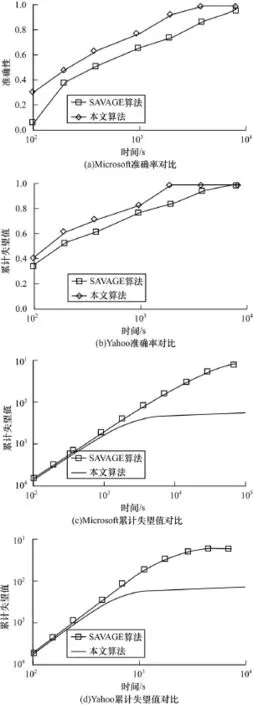
图1 本文算法与SAVAGE算法的性能对比
然后,在ongoing regretm inim ization模式下,将本文提出的采样算法与RUCB算法进行对比。2种算法在Microsoft和Yahoo!数据集下的累计失望值对比如图2所示。该模式下算法连续运行,通过设置时间间隔来观察不同时间下算法的累计失望值。从这2个图中可以看出,虽然本文算法和RUCB算法的收敛时间相近,但是本文算法却具有更小的累计失望值,因而在评估排序器时具有更高的准确性。
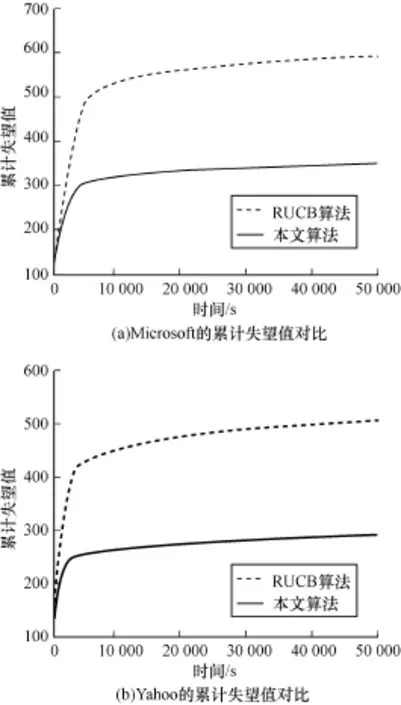
图2 本文算法与RUCB算法的累计失望值对比
最后,对比了RUCB算法和本文算法的稳定性,实验结果如图3所示。
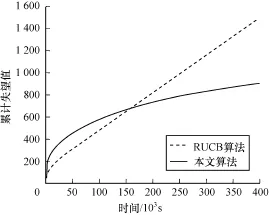
图3 本文算法与RUCB算法的稳定性对比
在该组实验中,取参数α=0.1,采用Microsoft数据集中的10个特征作为排序器集合,算法重复运行30次并且取结果的平均值。从该图可以看出,本文算法在多次运行过程中始终保持收敛的趋势,并且收敛的时间仍为103s;然而RUCB算法经过多次运行取平均值后,算法的累计失望值处于线性增长的趋势。由此可以认定,RUCB算法在评估排序器时具有一定的随机性,算法的稳定性不好,而本文算法的稳定性明显优于RUCB算法。
5 结束语
在信息检索中,随着用户需求的不同需要不同的排序方法。当用户提出个性化检索需求时,系统往往需要对多个排序器进行评估,从而使用最优的排序器为用户服务。本文研究了多个排序器的在线评估方法。根据现有研究结果将排序器评估形式化描述为
K武装决斗土匪问题,并分析了explore-then-exploit和ongoing regret m inim ization 2种模式下的求解目标,提出了一种基于采样的高效K武装决斗土匪算法。该算法通过采样的方式模拟赛事并选出获胜者,根据置信上界在剩余排序器中选出挑战者,并将获胜者与挑战者进行交错比较。实验结果表明,本文算法的检测准确性高,累计矢望值小,稳定性也较好。
[1] 邓 辉.网页学习排序算法研究[D].武汉:华中科技大学,2013.
[2] Cleverdon C W,Mills J,Keen E M.Factors Determining the Performance of Indexing System s[J].Cranfield,UK:College of Aeronautics,1966.
[3] 杨 子,唐 杰,李涓子.异构网络学习排序模型及应用[J].中国科技论文在线,2011,6(4):273-279.
[4] Chuklin A,Schuth A,Hofmann K,et al.Evaluating Aggregated Search Using Interleaving[C]//Proceedings of the 22nd ACM International Conference on Information&Know ledge Management.New York, USA:ACM Press,2013:669-678.
[5] 吴佳金,杨志豪,林 原,等.基于改进Pairwise损失函数的排序学习方法[C]//第六届全国信息检索学术会议论文集.牡丹江:[出版者不详],2010:96-103.
[6] Yue Yisong,Broder J,Kleinberg R,et al.The K-armed Dueling Bandits Problem[J].Journal of Computer and System Sciences,2012,78(5):1538-1556.
[7] 花贵春,张 敏,刘奕群,等.基于查询聚类的排序学习算法[J].模式识别与人工智能,2012,25(1):118-123.
[8] Yue Yisong,Joachim s T.Beat the Mean Bandit[C]// Proceedings of the 28th International Conference on Machine Learning.Haifa,Israel:[s.n.],2011:241-248.
[9] Urvoy T,Clerot F,Féraud R,et al.Generic Exploration and K-arm ed Voting Bandits[C]//Proceedings of the 30th International Conference on Machine Learning. Berlin,Germany:Springer,2013:91-99.
[10] Zoghi M,Whiteson S,Munos R,et al.Relative Upper Confidence Bound for the K-arm ed Dueling Bandit Problem[Z].2013.
[11] Lai T L,Robbins H.Asymptotically Efficient Adaptive Allocation Rules[J].IEEE Transactions on Automatic Control,1985,6(1):4-22.
[12] Agrawal S,Goyal N.Analysis of Thompson Sampling for the Multi-arm ed Bandit Problem[C]//Proceedings of Conference on Learning Theory,Washington D.C.,USA:IEEE Press,2012:1-26.
[13] Microsoft Learning to Rank Datasets[EB/OL].(2012-06-27).http://research.m icrosoft.com/en-us/projects/ m slr/default.aspx.
[14] Chapelle O,Chang Y.Yahoo!Learning to Rank Challenge Overview[J].Journal of Machine Learning Research,2011,14:1-24.
[15] Robertson S,Zaragoza H,Taylor M.Simple BM 25 Extension to Multiple Weighted Fields[C]//Proceedings of the 13th ACM International Conference on Information and Know ledge Management.New York,USA:ACM Press,2004:42-49.
编辑顾逸斐
On line Evaluation Algorithm of Sorting Device Based on K-arm ed Dueling Bandits Problem
DENG Xiaojun,MAN Junfeng,OUYANG Min
(College of Computer and Communication,Hunan University of Technology,Zhuzhou 412007,China)
According to evaluate various sorting devices,one can choose optimal sorting devices,and provide users with better ordered results for personalized retrieval requests based on these optimal sorting devices.In order to im prove the performance of evaluation of sorting devices,this paper proposes a sam p ling-based efficient K-armed dueling bandits algorithm.According to current researches,it formalizes the evaluation of sorting devices as the problem of K-armed dueling bandits,and analyzes the goals of the problem under both exp lore-then-exploit and ongoing regret minimization models.The algorithm simulates tournament based on sampling and chooses the w inner,then chooses challenger according to upper confidence bound,and at last,com pares the w inner and the challenger using interleaved comparison,and gets the score matrix.Experimental results show that,com pared with SAVAGE algorithm and RUCB algorithm,the proposed algorithm has higher detection accuracy,less cumulative regret,and better stability.
information retrieval;sorting device;regret minimization;K-armed dueling bandits;online evaluation method
邓晓军,满君丰,欧阳旻.基于K武装决斗土匪问题的排序器在线评估算法[J].计算机工程,2015,41(9):271-275.
英文引用格式:Deng Xiaojun,Man Junfeng,Ouyang M in.Online Evaluation Algorithm of Sorting Device Based on K-armed Dueling Bandits Problem[J].Computer Engineering,2015,41(9):271-275.
1000-3428(2015)09-0271-05
A
TP319
10.3969/j.issn.1000-3428.2015.09.050
国家自然科学基金资助项目(61350011);湖南省自然科学基金资助项目(2015JJ2046,2014JJ2115);湖南省教育厅科研基金资助项目(12C0068)。
邓晓军(1974-),男,副教授、硕士,主研方向:信息检索;满君丰,教授、博士;欧阳旻,讲师、硕士。
2014-10-28
2014-11-25 E-m ail:xiaojundengls@163.com
猜你喜欢
民间故事选刊(2021年16期)2021-08-19
影像视觉(2020年11期)2020-11-23
阅读(快乐英语高年级)(2020年6期)2020-08-28
今日农业(2020年13期)2020-08-24
好孩子画报(2019年10期)2019-01-10
意林(2017年8期)2017-05-02
文史春秋(2016年3期)2016-12-01
学习与探索(2016年4期)2016-08-21
医学研究杂志(2015年5期)2015-06-10
意林·少年版(2014年13期)2014-08-27
