
多目标联盟竞赛算法
2015-12-29 05:09卢协平刘秉瀚
福州大学学报(自然科学版) 2015年2期
卢协平,刘秉瀚
(福州大学数学与计算机科学学院,福建福州 350116)
0 引言
联盟竞赛算法[1](league championship algorithm,LCA)是一种基于迭代的群体智能优化算法.该算法的思路来源于体育团队在联盟竞赛中的比赛现象.文献[1]中的实验结果表明,联盟竞赛算法相比粒子群优化算法,无论从计算效果还是计算效率都有一定的优势.目前国内外对该算法的研究主要包括:将算法扩展为能够解决约束优化问题的算法[2-3]和解决组合优化问题的离散算法[4].
多目标优化问题(multiobjective optimization problems,MOP)是指同时优化多个目标的问题.一般情况单个目标之间相互矛盾,使得不可能存在单个绝对最优解,而是存在一个解集,称为Pareto最优解集(pareto optimal set)或非支配解集(nondominated set).目前解决多目标优化问题的常见方法是使用进化算法,较为经典的有Horn等提出的NPGA[5],Knowles等提出的AGA[6],Deb等提出的快速非支配排序遗传算法NSGA-Ⅱ[7]以及近年Zhang等提出的一种新颖的基于分解的多目标进化算法MOEA/D[8].这些算法使用Pareto支配关系指导算法搜索MOP的最优解集,对一些测试问题能够取得不错的效果.但也存在不足,普遍表现在收敛速度慢,且求解非凸多峰多目标测试函数(如ZDT4或DTLZ1)时效果较差.
本文提出多目标联盟竞赛算法(multiobjective league championship algorithm,MOLCA),将联盟竞赛算法扩展为解决多目标优化问题的算法,根据Pareto支配关系重新定义原算法在团队阵型比赛输赢的判断,并提出优解扩散策略使算法不轻易陷入局部最优解.最后结合优解扩散策略开关和分布性指标使算法自动停止运行,避免不必要的算法迭代.实验结果表明,多目标联盟竞赛算法在求解大部分测试函数时,其收敛性指标、分布性指标和函数评价次数普遍比NSGA-Ⅱ和MOEA/D算法更有优势.
1 多目标优化问题
以最小化多目标问题为研究对象.一个无约束的具有n维决策变量,m维子目标的多目标优化问题可表述为:
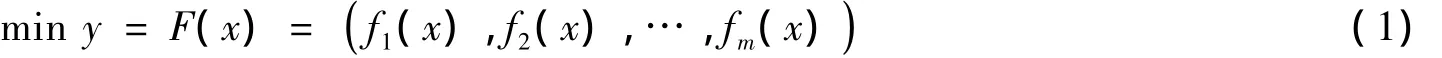
其中:x=(x1,…,xn)∈X⊂Rn为n维决策矢量,X为n维决策空间;y=(y1,…,ym)∈Y⊂Rm为m维目标矢量,Y为m维的目标空间,给出几个重要定义.
定义1 Pareto占优.设x1,x2∈X是式(1)的两个可行解,则称x1Pareto占优x2,当且仅当
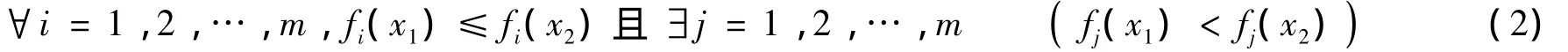
记作x1>x2,也称x1支配x2.
定义2 Pareto最优解.解x*∈X称为Pareto最优解(或非支配解),当且仅当:

定义3 Pareto最优解集.即所有Pareto最优解的集合,定义如下:

Pareto占优机制是目前最具代表性的占优机制,且当前大部分多目标进化算法都是基于该占优机制,即把寻找Pareto最优解集作为多目标算法的最终目标.本文的算法也不例外.
2 联盟竞赛算法
2.1 联盟竞赛算法基本流程
步骤1:初始化团队数量、团队阵型、比赛轮数S等,令当前迭代次数t=0;
步骤2:产生一个赛季的比赛赛程;
步骤4:根据第t轮的比赛赛程进行比赛,并按照一定规则判断比赛输赢;
步骤5:t=t+1,若t>S,执行步骤9;
步骤6:更新团队阵型:每个团队产生一个新阵型,若新阵型适应值比当前阵型适应值更优,则替换当前阵型;
步骤7:若要产生新赛程,则根据某种规则产生新赛程并替换旧赛程,否则继续使用旧赛程;
步骤8:转步骤3;
2.2 联盟竞赛算法的主要步骤
设:L为参赛团队数量,S为最大比赛轮数,t为迭代轮数,n为团队的成员数(维数).Xti=(xti1,xti2,…,xtin)为团队i在第t轮比赛的团队阵型,f(Xti)为团队i在第t轮比赛的适应值.主要步骤如下:
2.2.1 产生比赛赛程
常见的单循环赛制方法是逆时针轮转法.设有8个团队,团队编号从1开始.一个赛季有7轮比赛,赛程如下所示.(LCA允许在每个赛季后生成新赛程或继续使用旧赛程)

2.2.2 判断比赛输赢
假设团队Xti和Xtj在第t轮比赛中是对手,适应值分别是f(Xti)和f(Xtj).令pti是团队i赢得这场比赛的概率,则pti满足以下式子

若pti≥r0,则团队i赢、j输;否则团队j赢、i输.r0为[0,1]区间随机数.
2.2.3 更新团队阵型
LCA使用SWTO分析法对团队阵型进行更新,该方法包括内部因素(优势或弱势)和外部因素(机会或威胁).设第t轮比赛中,团队i和j是对手,团队l和k是对手;第t+1轮比赛,团队i和l是对手.使用sti和stl分别保存团队i和l在第t轮比赛的成绩,值为1表示赢,-1表示输.Xti=(xti1,xti2,…,xtin)的更新公式如下:
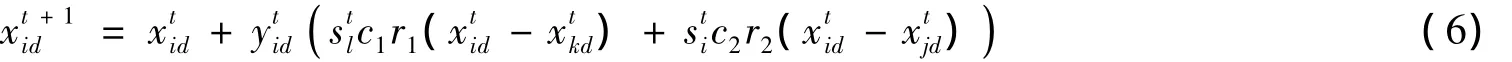
其中:d=1,…,n表示维数;c1和c2是权重系数;r1和r2是随机数;c1、c2、r1和r2∈[0,1].ytid是二进制数,为1表示允许第d维值更新,为0表示不允许更新.Yti=(yti1,yti2,…,ytin)为n维二进制向量,qti用于控制团队i在第t轮比赛后团队队员更新幅度,规定Yti集合中元素值之和为qti,即Yti中值为1的元素个数.式(6)第二项为外部因素,若stl为1(即团队k在上一轮比赛中输了)则团队i往团队k的反方向发展,反之同理;第三项为内部因素,若sti为1则团队i往团队j的反方向发展,反之同理.式中参数较多存在不合理性,但并非本文目的,期待后续论文对其改进.LCA中使用截断几何分布[9]来定义qti的值,公式如下,其中r3是[0,1]区间的随机数,pc∈(0,1)是输入参数.
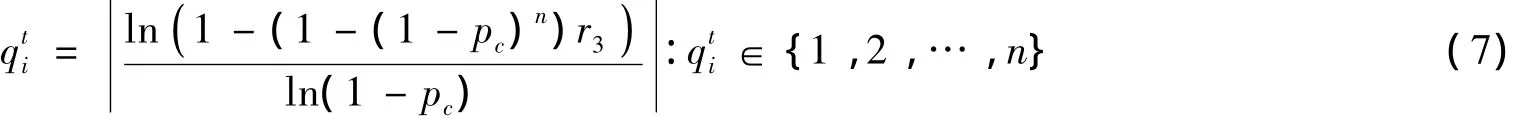
3 多目标联盟竞赛算法
Deb等提出的快速非支配排序遗传算法NSGA-Ⅱ是近几年来众多多目标进化算法中较为优秀和经典的一个.因此本文的多目标联盟竞赛算法使用了该算法的框架,继承了其优点.在其算法框架基础上,首先根据Pareto占优机制重新定义了联盟竞赛算法在团队阵型比赛输赢上的判断,并提出优解扩散策略改进算法框架中生成子代群体的步骤,最后使用分布性指标作为算法终止的依据.
3.1 算法基本流程
步骤1:初始化当前(或父代)团队数量pop、当前(或父代)团队阵型数组fatherpop、比赛轮数S等,令当前迭代次数t=0,并产生比赛赛程;
步骤2:根据第t轮的比赛赛程进行比赛,并按照一定规则判断比赛输赢;
步骤3:根据比赛结果产生子代团队群体数组childpop;
步骤4:将子代团队与当前团队合并,并进行快速非支配排序和拥挤距离计算[7];
步骤5:按非支配等级和拥挤距离选择pop个团队作为下一轮的父代种群,保存于fatherpop数组[7];
步骤6:t=t+1,判断是否满足算法终止条件,若满足转步骤7,否则转步骤2;
步骤7:将当前所有团队作为最优解集打印输出.
其中步骤4和步骤5中的快速非支配排序、拥挤距离计算及选择下一轮的父代种群均采用NSGA-Ⅱ算法中的方法.
3.2 团队输赢判断
与LCA不同,MOLCA是多目标算法,因此团队输赢的判断需重新定义.本文根据Pareto占优机制定义团队输赢判断规则,设x1,x2∈X,规则如下:

当x1和x2无支配关系时,设两者均为输,以便于产生子代团队.
3.3 产生子代团队
首先引入优解扩散规模参数vscal,具体步骤如下:
步骤1:若本轮比赛结果全标记为输(全为平局),且vcount<vscal,转步骤2,否则转步骤3;
步骤2:根据优解扩散策略产生下一代群体;
步骤3:若vcount≥vscal,关闭优解扩散策略,且后续迭代中不能再采用优解扩散策略,转步骤4;
步骤4:根据比赛结果每个个体均按式(6)产生一个子代个体,共产生规模为pop的子代团队群体.
其中vcount值为连续开启优解扩散策略的迭代次数,且每次在采取优解扩散策略前一轮迭代的fatherpop与采取优解扩散策略当前轮的fatherpop有0.9×pop个个体的所有目标值一样.依据是,如果连续多次采用优解扩散策略,且每次群体的目标值均无明显变化,算法认为群体基本收敛到Pareto前沿面.
优解扩散策略可理解为维多样性搜索,目的是保证群体多样性,防止在优化多峰多目标函数时陷入局部Pareto前沿面,matlab代码如下:
(1)vi=1;
(2)for i=1:vscal
(3)for j=1:n
(4)vlen=(maxvalue(j)-minvalue(j))/(4*vscal);
(5)for k=1:vscal
(6) childpop(vi,:)=fatherpop(i,:);
(7) childpop(vi+1,:)=fatherpop(i,:);
(8) childpop(vi,j)=fatherpop(i,j)+vlen*k;
(9) childpop(vi+1,j)=fatherpop(i,j)-vlen*k;
(10) vi=vi+2;
(11)end
(12)end
(13)end
(14)childpop=region(childpop).
其中:vi为子代种群下标值,vlen为维搜索步长,n为决策矢量维数,maxvalue(j)和minvalue(j)分别保存决策矢量第j维的决策上限和下限.
代码第(2)行用于选取fatherpop的前vscal个团队个体;第(3)行遍历每个个体的每一维;第(4)行是计算维搜索步长;第(5)行至第(11)行对每个个体的每一维以该维原来的值为基准值以vlen为步长分别递增和递减产生vscal个子代个体,共产生2×vscal个子代个体,覆盖区间为2×vscal×vlen即占该维决策空间的一半;第(14)行用于限制childpop每个个体每维都在决策区间内.优解扩散策略执行一次将产生2×n×vscal2个子代团队,而vscal为常量,因此时间复杂度为O(n).
优解扩散策略是针对优化多峰多目标函数,其有效性表现在抽取前vscal个个体遍历其每维一半的决策空间,使原来的种群个体更加分散,因此不会带来局部性;且该维的全局最优值落在这一半决策空间内的可能性较大,若该维陷入全局最优区域,则其会将其它个体在该维上的决策值导向全局最优值.因此每次使用优解扩散策略均会使每一维找到全局最优值区域概率大大增加.
3.4 算法终止条件
首先介绍实验中采用的两种多目标优化算法的评价指标.收敛性指标(convergence metric)和分布性指标(spacing metric).
收敛性指标:令P*=(p1,p2,…,p[P*])为理想Pareto前沿面上均匀分布的Pareto最优解集合,A=(a1,a2,…,a[A*])是通过算法得到的近似Pareto最优解集合.
收敛性指标被定义为集合A中每个解ai距离P*的最小归一化欧氏距离di的平均值,如式(9)所示,其中,fmaxm和fminm是集合P*中第m个目标函数值的最大值和最小值.
分布性指标:令集合A是通过算法得到的近似Pareto最优解集合.分布性指标S定义如式(11)所示,
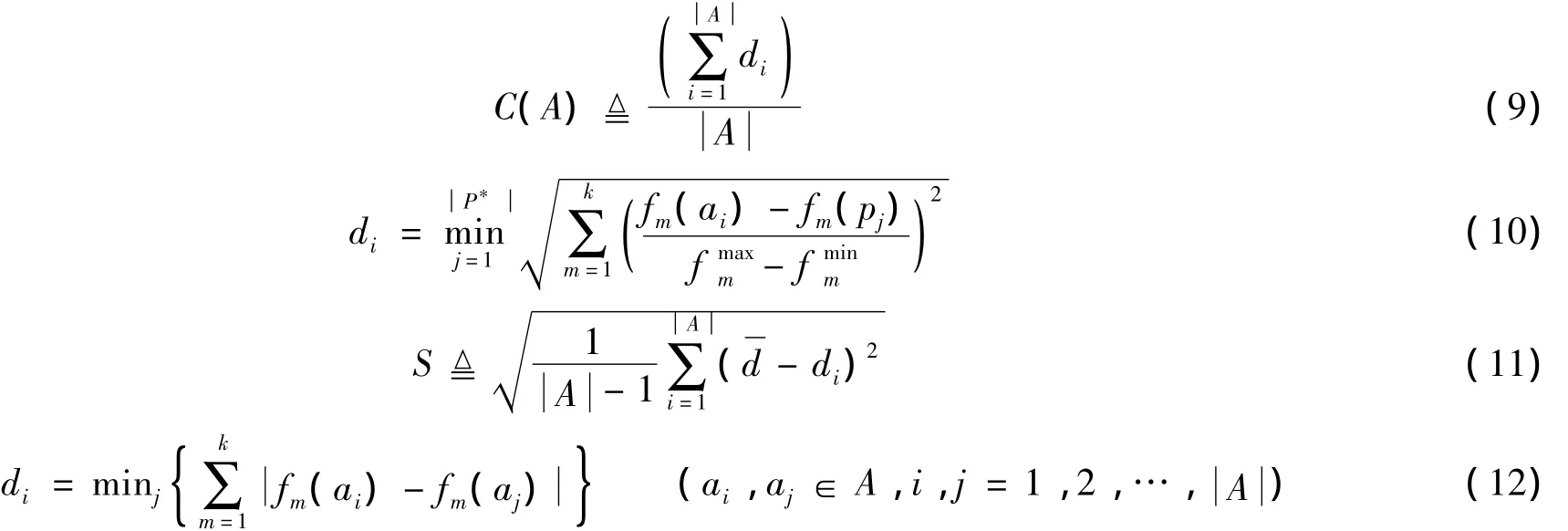
收敛性指标越小意味着算法搜索到的近似Pareto最优解集合越接近理想Pareto最优解集合,分布性指标越小意味着算法搜索到的近似Pareto最优解集合分布越均匀.
MOLCA算法的终止条件定义为:当前迭代轮数t≥S或者优解扩散策略已关闭且分布性指标连续迭代2×vscal次无变小.
4 实验
选取NSGA-Ⅱ和MOEA/D算法作为比较算法对8个经典多目标函数进行实验,函数相关数学描述如表1所示.实验中,三个算法均设置种群规模pop=200,优化ZDT函数时最大迭代次数为250、优化DTLZ函数时最大迭代次数为400.对MOLCA设置pc=0.1、c1=c2=1、vscal=5,对NSGA-Ⅱ设置交叉概率0.85,变异概率为0.01,对MOEA/D设置邻居规模T=20.评价指标有收敛性指标、分布性指标和函数评价次数.其中函数评价次数常作为算法终止条件,与最大迭代次数类似.三个算法均对每个测试函数独立运行30次,实验结果如图1、图2和表2所示.图1是算法平均收敛性指标实验结果,图2是算法平均分布性指标实验结果,表2是函数评价次数实验结果,由于MOEA/D和NSGA-Ⅱ算法在独立运行的30次实验中都是迭代到固定轮数后算法才终止,其中测试ZDT时为250轮,即函数评价次数为250×pop=50 000,而测试DTLZ时为400轮,即函数评价次数为400×pop=80 000.

表1 测试函数的相关描述Tab.1 The relevant description of test functions
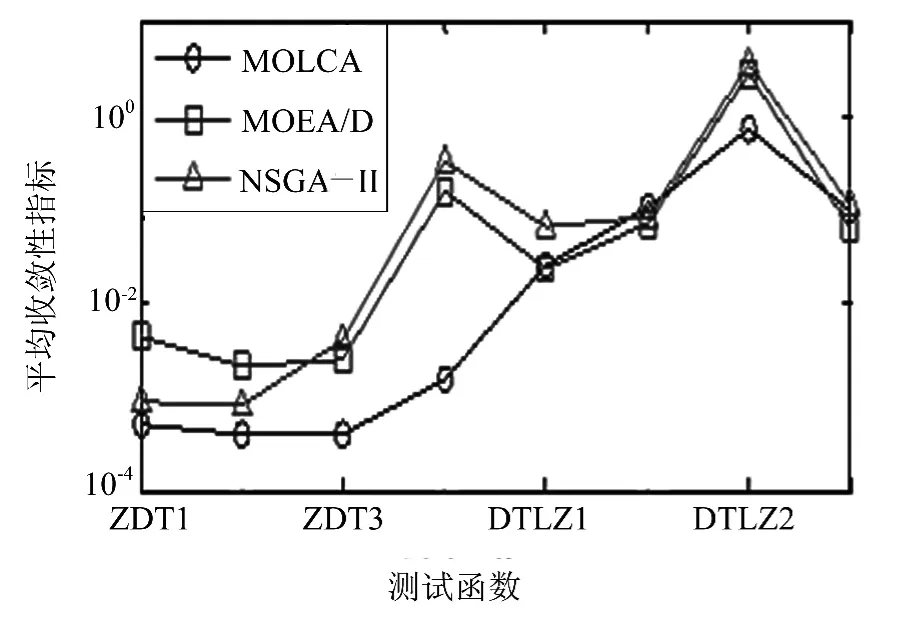
图1 三种算法的收敛性指标Fig.1 The convergence metric of the three algorithms
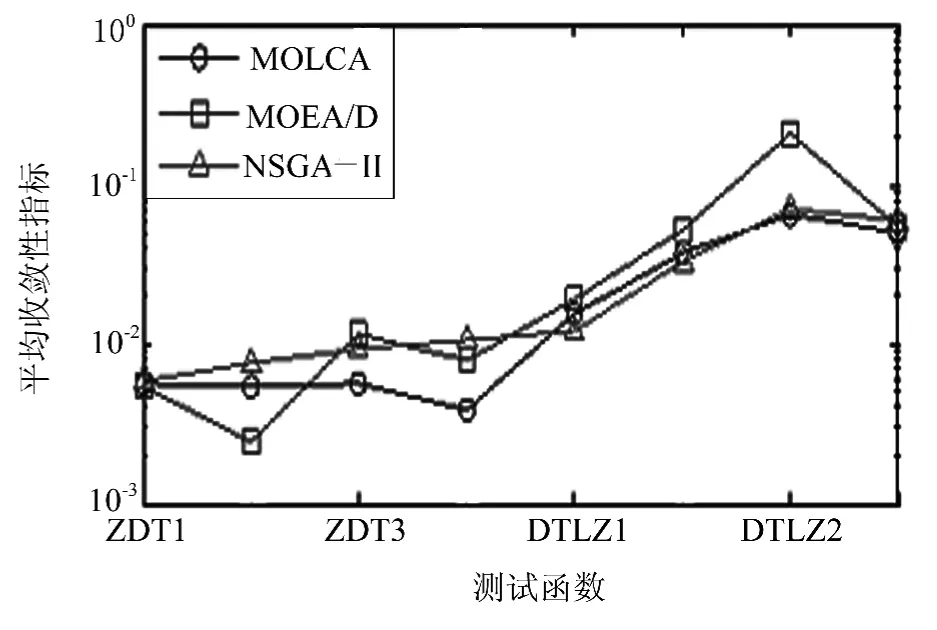
图2 三种算法的分布性指标Fig.2 The spacing metric of the three algorithms

表2 三种算法的函数评价次数Tab.2 The number of evaluations of three algorithms
从图1收敛性指标可以看出,对于优化ZDT1、ZDT2、ZDT3、ZDT4和DTLZ3测试函数时,MOLCA算法较MOEA/D和NSGA-Ⅱ均有明显优势;对于优化DTLZ1和DTLZ4测试函数时,MOLCA稍劣于MOEA/D,但仍优于NSGA-Ⅱ;对于优化DTLZ2测试函数时,MOLCA稍劣于MOEA/D和NSGA-Ⅱ.从图2可以看出,对于优化ZDT3和ZDT4测试函数时,MOLCA的分布性指标较其它算法有优势;对于优化DTLZ2和DTLZ3函数函数时,MOLCA的分布性指标与NSGA-Ⅱ相当,优于MOEA/D;对于优化ZDT1、DTLZ1和DTLZ4,三个算法的分布性指标均相差无几;仅在优于ZDT2函数函数时,MOLCA的分布性指标稍差于MOEA/D.从表2可以看出,除优化ZDT4和DTLZ2测试函数时,函数评价次数略多于其它算法之外,优化其余测试函数时,函数评价次数均明显少于其它算法.
综上分析,多目标联盟竞赛算法在优化大部分多目标测试函数时,在不失解的分布均匀性情况下且使用更少的函数评价次数依然能获得比MOEA/D和NSGA-Ⅱ更加接近于真实Pareto前沿面的解集,因此认为多目标联盟竞赛算法是可行的和有效的.
5 结论
将联盟竞赛算法扩展为多目标联盟竞赛算法,根据Pareto支配关系重新定义团队阵型比赛输赢的判断,并在算法中加入优解扩散策略使算法不轻易陷入局部最优解,最后结合优解扩散开关和分布性指标使算法自动停止运行.通过对8个ZDT和DTLZ测试函数的实验及MOEA/D算法和NSGA-Ⅱ算法的对比分析,验证了新算法具有优良的解搜索能力.
猜你喜欢
中国畜禽种业(2022年8期)2022-09-17
小哥白尼(神奇星球)(2020年5期)2021-01-18
小天使·一年级语数英综合(2017年10期)2017-10-31
物联网技术(2017年5期)2017-06-03
小雪花·小学生快乐作文(2016年11期)2017-01-09
智慧少年(2016年2期)2016-06-24
上海理工大学学报(2016年2期)2016-06-02
冰雪运动(2016年5期)2016-04-16
陕西理工大学学报(自然科学版)(2015年6期)2016-01-25
江苏高职教育(2014年2期)2014-07-16
