
Recent Advances on Human-Computer Dialogue
2016-03-20 06:51XiaojieWangCaixiaYuan
Xiaojie Wang*,Caixia Yuan
Center for Intelligence Science and Technology,School of Computer Science,Beijing University of Posts and Telecommunications,Beijing,100876,China
Recent Advances on Human-Computer Dialogue
Xiaojie Wang*,Caixia Yuan
Center for Intelligence Science and Technology,School of Computer Science,Beijing University of Posts and Telecommunications,Beijing,100876,China
Human-Computer dialogue systems provide a natural language based interface between human and computers.They are widely demanded in network information services,intelligent accompanying robots,and so on.A Human-Computer dialogue system typically consists of three parts, namely Natural Language Understanding(NLU),Dialogue Management(DM)and Natural Language Generation(NLG).Each part has several different subtasks.Each subtask has been received lots of attentions,many improvements have been achieved on each subtask,respectively.But systems built in traditional pipeline way,where different subtasks are assembled sequently,suffered from some problems such as error accumulation and expanding,domain transferring.Therefore,researches on jointly modeling several subtasks in one partor cross different parts have been prompted greatly in recent years,especially the rapid developments on deep neural networks based joint models.There is even a few work aiming to integrate all subtasks of a dialogue system in a single model,namely end-to-end models.This paper introduces two basic frames of current dialogue systems and gives a brief survey on recent advances on variety subtasks at first,and then focuses on joint models for multiple subtasks of dialogues.We review several different joint models including integration of several subtasks inside NLU or NLG,jointly modeling cross NLG and DM,and jointly modeling through NLU,DM and NLG.Both advantages and problems of those joint models are discussed.We consider that the joint models,or end-to-end models,will be one important trend for developing Human-Computer dialogue systems.
Human-Computer dialogue system;Natural Language Understanding;Dialogue Management;Natural Language Generation;Joint model
1.Introduction
A Human-Computer dialogue system is a conversation agent.It provides an interface to help human utilize computers by talking with computers in natural language.It is also called spoken dialogue systems since dialogues are often in spoken language.
Dialogue systems are normally divided into two classes. One is goal-driven dialogue systems,another is non-goal driven systems.In the beginning of 1990s,MIT developed an automatic fl ight booking system[1]under the supports of DARPA.It is a typical goal-driven dialogue system.The system analyzed the user utterances and managed multiple turns of dialogue processes in order to extract all necessary information for flights booking,such as departure city, departure time,and so on.Similar systems include telecommunication service system HMIHY[2],climate information query system JUPITER[3],travel plan making system DARPA Communicator[4]and so on.Goal-driven dialogue system is also named task-oriented system.
Non-goal-driven dialogue systems are another class of systems.They usually response user utterances without any specific goal.They are also called chatterbots.ELIZA[5] might be the first chatterbot.Chatterbots have become more and more popular in recent years.Some typical personnel assistant systems,such as Cortana,Google Now,include chatterbots inside.
The border between goal-driven dialogues and non-goal driven dialogues is not strict.They are often mixed in real world dialogues.For example,we occasionally chat with human service staffs when we book a fl ight.A good personnel assistant system therefore should sometimes be able to chatwith users for a non-goal-driven dialogue,and sometimes help people book tickets in a goal-driven way.
Recently,there is a rapidly increasing demands on both customer service robots and personnel assistants.The former helps to reduce the costs of customer service for enterprise,the later helps to get information services in more natural way. Lots of researches have been done on Human-Computer dialogue systems.Greatimprovements on models,algorithms and performances of dialogue systems have been achieved in past decades.Recent years,with the help of rapidly increasing computational capability,more dialogue corpora publicly available as well as some new technologies like deep neural networks,there are also some new trends in the developments of dialogue systems.It is the time to review the variety advances on these topics,especially on the new trends.Limited to the space,this paper will not review all the aspects of Human-Computer dialogue systems.We paid more attentions on goal-driven dialogue,especially on one important recent trend,namely the jointly modeling of multiple tasks in dialogue systems.
The remainders of this paper are organized as follows: Section 2 revisits the architect of goal-driven dialogue systems.A brief survey on each subtask in dialogue systems is given in Section 3.Section 4 is the focus of the paper.Recent research advances on jointly modeling multiple subtasks in dialogues are introduced and discussed,where both goaldriven dialogues and non-goal-driven dialogues are included. We draw conclusions in Section 5.
2.Frames of goal-driven dialogue systems
Fig.1[8]is a basic frame of goal-driven dialogue systems. It includes three parts,Natural Language Understanding (NLU),Dialogue Management(DM),and Natural Language Generation(NLG).The user inputs can be either speech or text.If the inputs are speech(NLU is often called Spoken Language Understanding(SLU)in this case),then an Automatic Speech Recognition(ASR)module should be included in SLU,it might be an independent module before NLU as well.When the system outputs are speech,NLG should include a Text-To-Speech(TTS)module.
NLU(or SLU)aims to extract task related information from user utterances.For example,in a flight booking dialogue,task related information includes the departure city, destination city,time for fl ying and so on.When NLU (including ASR)is assumed to be able to extracts allnecessary information for the task from user inputs correctly at each dialogue turn,the state of dialogue is said to be(fully) observable.
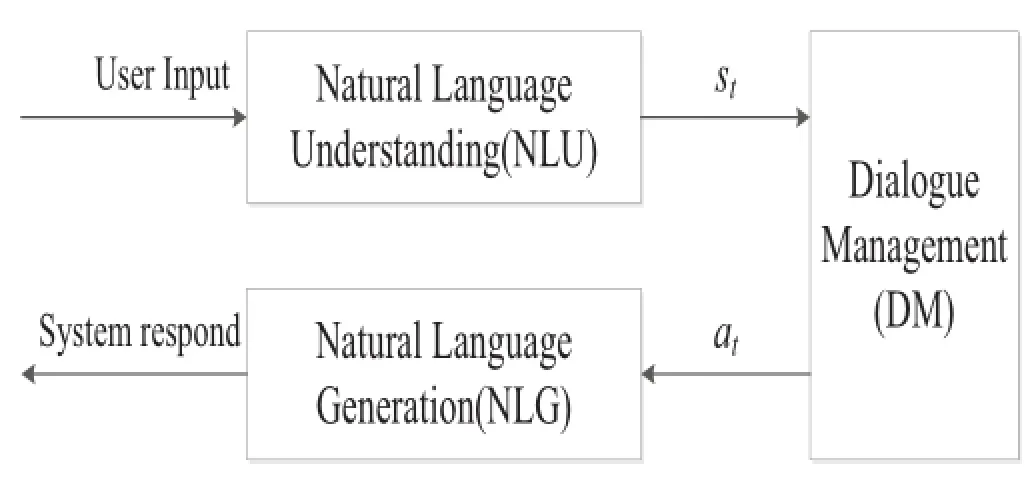
Fig.1.A basic frame for dialogue system when states are fully observable.
DM controls the process of a dialogue.Markov decision process(MDP)is widely used for modeling DM for a dialogue with observable states.It accepts the output of NLU at time t (and updates information in a frame which records the goal of the task accordingly)as state at time t which is denote byst, then outputs an act,denoted byatin Fig.1,and receives a rewardrtat the same time.Let us continue to take the fl ight booking dialogue as an example.When DM obtains the information of departure city from MLU(and fill it in the goal frame of the task),it should decide its next act to do.For example,to confirm the departure city,or to ask user departure time if it is unknown,or to do both of them in next sentence. DM selects the optimal act sequence to maximum long-term reward.
NLG transfers the acts of DM into natural language sentences.For example,if DM decides to ask user destination city.NLG will transfer the decision to a sentence like“please tell me your destination city”.
The state of dialogue shown in Fig.1 is assumed fully observable at each time.It therefore cannot take the uncertainty of NLU into consideration.But the uncertainty of NLU is practically unavoidable due to current performances of ASR and NLU.It should be covered in a workable system.Therefore,frame like Fig.2[6]has received major attentions currently.Where,A Partial Observable Markov Decision Process(POMDP)model is used for DM.The outputs of NLU,denoted byotin Fig.2,is observations of dialogues att. The state is a probabilistic function of outputs.Belief state, which keeps a distribution of the states,is used to cover the uncertainty of NLU instead of states themselves,it is denoted bybtin Fig.2.
As shown in Fig.2,NLU can be further divided into domain identification,intent identification(dialogue act classification)and semantic labeling(it is often called slot filling which means to labelslotnames for words in sentences,words labeled by slot names are the value of those slots.Slot names are usually task specific semantic tags,like departure city, destination).DM includes state tracking(dialogue model)and act generation(policy model).NLG includes sentence planning and surface realization.
Basing on this frame,lots of work has been done on each subtask in NLU,DM and NLG,a brief review is given as follows.
3.Modeling each subtask separately
Human-Computer dialogue systems are traditionally constructed in a pipeline style.Each subtask is modeled separately as an independent module,and then assembled sequently according to Figs.1 or 2.Lots of work has been done on each subtask to improve their performances,respectively.Since itis notthe focus of this paper,we only give a brief review on them in this section.For a more comprehensive survey ontraditionally dialogue systems,especially on POMDP based pipeline dialogue systems,please read the excellentreviews by Young,Gasic,&Thomson,et al.[6]and Yu,Chen,&Chen, et al.[7].
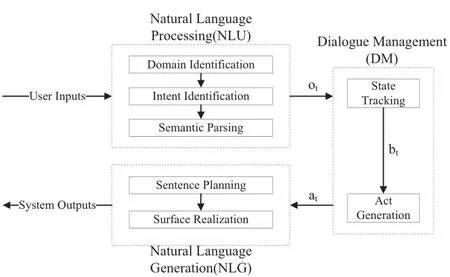
Fig.2.A basic Frame for Human-Computer dialogue systems when states are partially observable.
3.1.Subtasks in NLU
NLU provides dialogue information for DM.It includes domain identification,intent identification,and semantic parsing.For a user input“I want to book a flight to Beijing”, its domain is flight service,the user intent is to book a fl ight, Beijing is the value for destination slot.
Both domain identification and intent identification are often modeled as classification.Lots of supervised classifiers, including Support Vector Machine(SVM)[9],Maximum Entropy(ME)[10],Deep Neural Network(DNN)[11]were used for identifying user intent.More than 90%of accuracy had been achieved in some dialogue corpora.However,supervised methods suffered from the lack of large number of labeled data,especially in new domains.Some unsupervised methods were proposed[12].But,the performances of current unsupervised methods were more than 10%lower than those in supervised methods[13].
Slot filling was often considered as one kind of sequence labeling for words in sentence,where the label set included all slot names designed for the specific task.Both supervised methods and unsupervised methods were employed on the subtask.Conditional Random Field(CRF)and Recurrent Neural Network(RNN)were the mostly used models. Experimental results on ATIS data[14,15]showed that RNN or its variants performed better than CRF,the labeling accuracy exceed 90%.But Vukotic,Raymond,&Gravier,et al. [16]showed that there was no significant difference between different models on ATIS data.Since ATIS data was simple, all methods achieved good performance.While on MEDIA data which was more challenging,CRF performed better than RNN.
Similar to that in intent identification,performances achieved by unsupervised methods on slot filling[18,19,21]were lower than those in supervised methods.Ref.[17]was one of the earliest works on unsupervised slot filling.They made use of task-related query logs for slot filling.Tur,Celikyilmaz,& Hakkani-Tur[18]made us of Latent Dirichlet Allocation (LDA)model to improve slot filling.Chen et al.published a series work on unsupervised slot filling.Chen,Wang,& Rudnicky[20]proposed an unsupervised slot induce by combining Frame-Net and distributed representation.Chen, Wang,&Gershman,et al.[19,21]learned latent features by matrix factorization,Chen,Wang,&Rudnicky[22]considered knowledge graph based random walk for slot induction.
3.2.Subtasks in DM
Most of current researches on DM tried to manage dialogue with partial observable states.In this case,POMDP is the most popular frame for DM which consisted of state tracking and act or policy generation.Lots of work has been done separately on the two subtasks.
Researches on state tracking were primarily under the frame of generation models.But POMDP based belief state update was especially difficult when the task is complex.N-best approximate,factorization approximate and other such kind of methods were therefore proposed.Williams[23] pointed out some weakness based on experimental results on two publicly available dialogue systems,and suggested that discriminative models could achieve better performance for belief state update.Williams,Raux,Ramachandran,etal.[24] organized the 1st Dialog State Tracking Challenge(DSTC), the challenge was held each year[25,26],strongly promoted research on dialogue state tracking.Lots of discriminativemodels including structure discriminative model[27],multi domain learning model[28],deep neural network[29]and some models combining rules and statistics[30]were proposed on DSTC and achieved performance improvement.
Act generation builds mappings from belief states to system acts.Reinforcement learning is current mainstream technology.Because the real-world problems normally have large scale belief state space,current methods used compressed representation of belief space,such as abstract space,and then made use of approximate methods to learn mappings.Typical methods included Monte Carlo Optimization,Least-squares Policy Iteration,Natural Actor-Critic Optimization,Q-learning,Sarsa and neural network[6].By defining kernel functions related to objective functions,Gaussian Process reinforcement learning[31,32]was shown to be able to reduce the samples needed for learning,and accelerated the optimization of policies.Itmade possible to do act generation in the whole belief state space.Barlier,Perolat,&Laroche,et al. [33]proposed a stochastic game frame for policy learning. They considered several limitations of(PO)MDP.The first one is that the policy is assumed to be stationary in POMDP,that means users do not change the policy through the task. Another is the assumption of cooperation,where all participants of dialogues have same goal in the task.Both of the assumptions are not always true in real world dialogues.For example,participants in a negotiation might have different goal,and could change their policy.Barlier,Perolat,&Laroche,et al.[33]argued that stochastic game was able to deal with both of the limitations.
3.3.Subtasks in NLG
NLG receives dialogue acts from DM as“what to say”,and implements“how to say”by sentence planning and surface realization.
Sentence planning aggregates content to be described into a sentence by lexicalization and referring expression generation. Lexicalization means to choose words to describe concepts and their relationships.Referring expression generation means to select words or phrases to refer entities.Reiter&Dale[34] found there are stable correspondences between semantic representations and sentence structures,and used schema to describe sentence structures.A natural language generator selected schema and filled in schema according to inputs,and got the final sentences.For example,given a representation of“what to say”:“((obj-action fly)(obj-name flight)(attribute time)(attribute-value 10 am))”.Schema“<obj-name>fly at<attribute-value>”was selected for generating sentence“flightfly at10 am”.Stone&Doran[35]used Tree-Adjoining Grammar(TAG)to represent syntactic structure,and used rhetorical structure to gain local coherence of discourse.The leaf nodes of TAG elementary tree could be used for surface realization.Dusek&Jurcicek[36]proposed an algorithm to construct sentence plan tree candidates increasingly from an empty tree basing on A*search with a perceptron ranker,and rank the trees.It finally got a sentence frame according to semantic consistence with inputs.
Surface realization selects function words,word forms and so on,to make the outputs syntactically well-defined,and spelling correctly.Lavoie&Rambow[37]proposed a series of lexicalization process,such as function word insertion,linearization of the tree representation,morphological inflection, and surface formatting(e.g.,adding punctuation).White& Baldridge[38]used Combinatory Categorical Grammar and a bottom-up chart-based decoder,along with argument types, lexical categories and so on to make sure the sentence is generated grammatically.
We can see from above brief survey that there are lots of advances in each subtask.But,there are also lots of spaces to be improved,especially for partially observable model,goaldriven dialogue systems were only applied in some small scale tasks.Young,Gasic,&Thomson,etal.[6]and Yu,Chen, &Chen,etal.[7]have given excellent analysis and survey on the problems of each subtask.
4.Jointly modeling multiple subtasks
Traditionally,dialogue systems were built in a pipeline way.Models for each subtask were built separately and then assembled into a whole system.Pipeline systems are conceptually clear.Each part focuses on its own problems independently,each model is developed independently.But there are also some limitations for pipeline systems.
Firstly,it cannot make use of the interaction information between different parts.There are significant interactions between each subtask,the interactions are helpfulto improve the system performance.Taking the intent identification and slot filling in NLU as an example,slot filling is helpful to intent identification,and vice versa.In a flight booking task,if only the destination slot is labeled in a sentence,then the probability that intent of the sentence is to tell the destination is big, on the contrary,if intent of a sentence is to tell the departure city,then,a departure city will occur in the sentence with a big probability.If the interactions between two subtasks can be modeled properly,it should be helpful to promote both tasks. There are similar situations for other subtasks.
Secondly,models for each subtask are trained separately in a pipeline system.It brings difficulties from two sides.On the one hand,developers of dialogue systems usually only get feedback from the end users,who inform them about final performance of the systems.It is difficult to back propagate or assign final error signals of the system to each subtask.It is also time-consuming and laborious to get labeled data for each subtask.On the other hand,because it is difficult or impossible to ensure fully correct in each subtask,errors in previous subtasks might hurt later subtasks.The errors might be accumulated and enlarged through the pipeline,even become uncontrollable.
Thirdly,interdependences of subtasks in dialogue systems make online adaptation of systems challenging.For example, when one module(e.g.NLU)is retrained with new data,all the others(e.g DM)that depend on it become sub-optimal due to the fact that they were trained on the output distributions of the older version of the NLU module.Although the idealsolution is to retrain the entire pipeline to ensure global optimality,this requires significant human effort[39].
Recent advances are exploring how to overcome above limitations of pipeline system.Jointly modeling has been proven to be an efficient way.There are lots of work on joint models,range from jointly modeling subtasks in NLU,DM or NLG respectively,to jointly modeling subtasks cross NLU and DM,and even jointly modeling cross NLU,DM and NLG.
Here,“joint model”or“jointly modeling”means two or more subtasks are implemented in a single model or in a strongly coupled frame,the model(or frame)is trained as a whole or simultaneously instead of subtask by subtask.
4.1.Jointly modeling subtasks in NLU
In recent years,with the success of deep learning in variety applications,several different types of deep neural networks have been used on jointly modeling of NLU subtasks.
Xu,&Sarikaya[40]described a joint model for intent detection and slot filling based on convolutional neural networks(CNN).The features were extracted through CNN layers and shared by the two tasks.Experimental results on ATIS corpus and other 4 unpublished datasets showed that the joint model outperforms triangular CRF on both intent identification and slot filling.
Guo,Tur,&Yih et al.[41]proposed a RecNN(Recursive Neural Networks)based approach to jointly model domain identification,intent identification and sematic parsing. Compared with some previous methods which modeled the three tasks separately,their model achieved competitive performance on ATIS data and Microsoft Cortana dialogue data.
Shi,Yao,&Chen,et al.[42]proposed a RNN to jointly modelthree subtasks in NLU,and received better performance than previous methods.LSTM(Long Short-Term Memory) was also use for jointly modeling intent identification and sematic parsing[43].It achieved better performance on DSTC2 data than those in separate models.
Besides deep neural networks,traditional CRF were also used as joint models.Lee&Ko[44]proposed a CRF based new tag addition method to joint model different subtasks.The model added three positions for speech act,operator and target,respectively before each input sentence.A single CRF model was used to label Named Entities in the sentence as well as the three labels.Besides,models combining CRF with CNN were also used for joint modeling.All of them achieved better or competitive performance than current state-of-the-art independent models.
Jointly modeling subtasks has been shown a promising way for improving NLU.Although some improvements have been achieved.There also some problems to be made clear or solved.Among them,we think following three problems are even important and interesting.
The first problem is about how to joint model multiple-task. There were two ways for joint modeling multiple-task in previous methods.One was to transfer different tasks in a same type of problem,then model them in a single model.The typical one is Lee&Ko[44].They transferred intent identification(a normal classification task)into a labeling task by adding a tag position for intent before the sentence.A single labeling model could then be used for intent and slot labeling simultaneously.It might be though as a flat and parallel mode.Another way was to build hierarchical models for classification and labeling separately in different layers.Both Shi,Yao,&Chen,et al.[42]and Zhou,Wen,&Wang[43] employed a hierarchical neural network model for intent classification and slot labeling.While the former put slot labeling in the bottom of hierarchical network,intent identification on the top.The later tried two different arrangements (one was exactly same as that in former,another is inverse) and found the subtask on the top of the network always gained more benefits from the hierarchical structure,no matter which subtasks were put on the top.It was not clear which kind of joint way is better for given subtasks,there is still no full investigation on this problem.
Almost all current joint models were supervised.They needed labeled data for all subtasks.For deep neural network models,they demanded a large amount of data for better performance.So,the second problem is how to get a large number of labeled data,or should we pursue some unsupervised approach?As we have seen,unsupervised models significantly performed worse than supervised models in single subtasks.There is still no unsupervised approach for joint models.Could jointtasks find better unsupervised models than that in single task by utilizing the interaction information between two or more subtasks?If it is possible,the jointly models gain another important advantage compared with pipeline models.
Another problem is domain adaption.It is expensive to build a large number of labeled data.It is even expensive to build a large number of labeled data for each domain.How can we reuse the labeled data in one domain on another domain? We have to deal with new words,new intent,new slot values or even new slots for dialogues in new domains.There are some beginning works on dealing with the problem.For example,Yazdani,&Henderson[45]explored a zero-shot representation learning model for SLU in new dialogue domains.They integrated intents(acts)and slots in a label representation learning model,different domains used common parameters of word embeddings.The experimental results showed that the word vector based model could adapt well to new domains.We will see in next section that word based models could also be a possible way for cross-domain adaption in other joint models.
4.2.Jointly modeling subtasks cross NLU and DM
Normally,DM receives semantic labels of a sentence from NLU as inputs.Some recent work has crossed the gap,and uses the sentence as input of DM directly.
Henderson,Thomson,&Young[46]proposed a word based RNN modelfor state tracking.The model mapped the ngrams of user inputs to dialog states without using an explicit semantic decoder.Each slot was dealt with a separate RNN model.The method was evaluated on the second Dialog StateTracking Challenge(DSTC2)corpus and the results demonstrated consistently higher performances compared with pipeline models.Mrksic&Kadlex,et al.[47]proposed a multi-domain state tracking model basing on work proposed in Ref.[46].The results showed the model could achieve good performance when combined with some delexicalized features.
Reinforcement Learning(RL)was a major tool for policy modeling.Most of current joint models including act generation employed Deep Reinforcement Learning(DRL)which was first proposed in Ref.[48]for playing computer games.
Mnih,Kavukcuoglu,&Silver,etal.[48,49]implemented a screen based game playing agent.The agent selected game actions according to screen images.They proposed a deep Q-learning algorithm on a Deep Q-Network(DQN)with two layers of convolutional network and two layers of full connection forward network for learning Q-function.A mapping from image inputs to game acts was learned.By utilizing DRL,screen understanding was integrated with game operation selection into an end-to-end model.The model achieved better or competitive scores in a number of different games compared with human players.In fact,game playing is very similar to dialogue.Images of screen are analogy to utterances of users,game operators are analogy to dialogue actions.The goal of game agent is to achieve maximum long-term rewards in multiple turns,which is also analogy to the goal in dialogues.The only difference between games and dialogues is: the inputs of games are continuous images,while the inputs of dialogues are discrete language symbols.Narasimhan,Kulkarni,&Barzilay[50,53]proposed a LSTM-DQN model for text based network games,where LSTM was used to decode text inputs into a vector representation which was then fed to a DNN to train a Q-function.It achieved better performance than some previous models.
Due to the great successes in computer games and similarities between games and dialogues,DRL was then rapidly used for building end-to-end joint models for dialogue systems.
Cuayahuitl&Keizer[51]used deep reinforcement learning on a non-cooperated dialogue to generate dialogue policies, they implemented experiments on a card game instead of dialogues.Cuayahuitl[52]tried to construct a joint model from the outputs of ASR to act generation.He used DRL in Cuayahuitl&Keizer[51]for DM.But they just showed some simple DRL results without performance evaluation of the dialogue system.Zhao&Eskenazi[39]jointly modeled state tracking and action generation in a deep reinforcement learning frame. LSTM was used to track history of dialogue.They also proposed a model with supervised information from dialogue state.
Dialogue states were manually designed in past dialogue systems.The design of dialogue states was subjective and time-consuming.DRL provided an efficient way to avoid explicit design of the dialogue states.But it was not so easy to train Q-function networks like DQN or LSTM-DQN.The samples fed to the network was(st,at,rt,st+1),t=1,2,…N or something like that.They were not independent identically distributed(i.i.d.)becausest+1(state at time t+1)was determined by bothstandat.The Q-function networks were therefore prone to oscillation and difficult to converge.For training the DQN,Mnih,Kavukcuoglu,&Silver,et al.[48] used an experience replay mechanism proposed by Lin[54] which randomly sampled previous transitions,and thereby smoothed the training distribution over many past behaviors. Recently,Hasselt,Guez,&Silver[55]leveraged the overestimation problem of standard Q-Learning by introducing double DQN,Schaul,Quan,&Antonoglou,et al.[56] improved the convergence speed of DQN via prioritized experience replay.Although these measures were workable to some extents,and have helped DRL to achieve great successes in computer game.But there was no general guarantee for convergence of DRL.Ma&Wang[57]showed that the Q-function networks could converge well when a dialogue has a small act space,but the situation became worse with the increase of act space of the dialogue.How to train Q-function networks will be still a problem in near future.
4.3.Jointly modeling subtasks in NLG
Lots of work has been done on jointly modeling content selection,sentence planning and surface realization in recent years.These methods mapped acts(semantic frames or meaning representation)from DM to natural language sentences directly,and could mainly be divided into two types:one was syntax based models,another was sequence based models.
Syntax based models took sentence generation as an inverse process of sentence understanding.They adopted syntaxes similar to those in syntactical analysis,generated natural language sentences by rewriting syntactical symbols or semantic symbols continuously tillthe leave nodes(words)of syntactical tree.Most of pervious work has focused on hand-crafted generation grammar.Belz[58]made use of template-based domain specific rules to get CFG(Context Free Grammar)manually. Recent work automatically learned a CFG from aligned corpus. Wong&Mooney[59]proposed an algorithm to learn a synchronous context-free grammar(SCFG)automatically using sentence-semantic frame aligned corpus.The model used left to right Earley chart to map semantic frame to natural language sentences.It re-ranked mapping results using language model in decoding.Lu&Ng[60]proposed a SCFG based forest-tostring generation algorithm.Konstas&Lapata[61]used a bottom-up chart decoder to learn a PCFG from a phrase semantic slots pairs which were harvested from a sentence semantic frame alignment corpus,and re-ranked generative trees combining n-grams and dependency relations,then outputted a sentence with top rank leave nodes.
The outputted sentences were grammatical in syntax based methods.But it was difficult to obtain good syntaxes.Manual rules were expensive and domain dependent,while grammar learning relied on a large number of aligned corpus.Limited by syntaxes,all above methods could not deal with semantic frames which did not occur in train data.Sentences generated by these methods were lack of diversity.
Sequence based models took a sentence as a sequence of words or phrases.They predicted the generation probability of next word basing on words already generated.To cover thesemantic frame in generated sentence,the sequence model took the dialogue acts into consider.So,the generation probability ofnth word could be estimated bypθ(wn|w1,...,wn-1;DA),where DA is current dialogue act given by semantic frame,θis parameters for the probability function.
Several neural network based models,especially RNNs, were used to approximate the probability.Zhang&Lapata [62]described a work on using RNNs to generate Chinese poetry.Wen,Gasic,&Kim,etal.[63]jointly trained a forward RNN generator,a CNN and an inversed RNN ranker,to generate natural sentences for specific DA.Wen,Gasic,& Mrksic[64]used a DA controlgate for sentence planning,and a LSTMfor surface realization.Two parts are jointly trained to generate grammatical sentences and semantically insistent with DA.Mei,Bansal,&Walter[65]proposed an end-to-end, domain independent neural encoder-aligner-decoder model to jointly model content selection,sentence planning and surface realization.A LSTM was firstly used for encoding all semantic slots,and then the salient semantic slots were extracted by an alignment model,finally the natural sentence was generated by a decoder.Dusek&Jurcicek[66]proposed an attention based LSTM to encode inputted DA and words already generated, and then a LSTM decoder together with a logistic classifier were used to generate other words in sequence.They demonstrated their model can achieve comparable performance with other RNN based models with less training data.
Compared to syntax based models,sequence based models did not need fine grain level alignment data for training.The flexibility of sequence based models on modeling dialogue history,context and word selection brought a diversity of sentences generated.On the other hand,because the generation process of sequence based models was not controlled by any specific syntax,it was unavoidable for them to generate ungrammatical sentences.It was also possible for them to lose or repeat some slots in DA.
4.4.Joint models for subtasks across NLU,DMand NLG
It is attractive to jointly model all subtasks of a dialogue system,from NLU,DM to NLG.It is a real end-to-end model which receives user input and output a natural language sentence for response.Butfor a goal-driven task,a response is not the only thing that a model should give at each turn.A successful agent should keep and update a task related record through the whole dialogue in order to make proper selection on dialogue actions.For example,in flight booking,an agent should record information such as time,departure city,and so on in order to implement the reservation operation correctly. Such information should be kept and can be updated through the whole dialogue.There is no full end-to-end model for goal-driven task currently.Most of previous end-to-end models jointly modeled parts of the subtasks as above.
While for a non-goal-driven task,it is not necessary for a chatterbot to keep so much information,a response is often the only thing that a model should give.Some full end-to-end models for response generation have been proposed recently.
Data-driven end-to-end response generation has been received many attentions in recent years by borrowing ideas from some other research areas.Among different models for response generation,the model borrowed from machine translation was first proposed by Ritter,Cherry,&Dolan[67]. They made use of phrased based models in traditional statistical machine translation for response generation in social network.The experimental results showed statistical machine translation based models outperformed information retrieval based models.Alone this way,by utilizing the RNN language model,Sordoni,Galley,&Auli,et al.[68]proposed a dynamic-context generative model to address the problem of data sparsity arising when contextual information was integrated into classic statistical models.Serban,Sordoni,& Bengio,et al.[69]extended hierarchical recurrent encoder decoder neural network proposed in Ref.[70],which was original suggested for improving query suggestion,to end-toend dialogue model.
With the recent advances of sequence-to-sequence models in machine translation,some sequence-to-sequence models for non-goal-driven dialogue were also proposed.Shang,Lu,&Li [71]presented a RNN based encoder-decoder Neural Responding Machine with attention signal,Vinyals&Le[72] proposed a LSTM based sequence-to-sequence Conversational Model.Fig.3 is the typical structure of sequence-to-sequence model.Li,Galley,&Brockett,et al.[73]used Maximum Mutual Information(MMI)as objective function to measures the mutual dependence between inputs and outputs.Experimental results showed MMI helped sequence-to-sequence models to produces more diverse responses.
These approaches jointly modeled the process from sentence inputs to generation of responses for non-goal-driven dialogues.They did not include semantic parsing and explicit DM,and therefore could not be applied to goal-driven dialogues directly.Dodge,Gane,&Zhang,et al.[74]also considered the difficulty on evaluation of these models.They therefore proposed a set of tasks,including question answering, recommendation,question answering+recommendation and chatting,to test the ability of end-to-end dialogue systems.It might be an interesting way to bridge non-goal-driven dialogues and goal-driven dialogues.On the other hand,there are lots of advances in sequence-to-sequence machine translation models,which might be borrowed to build more powerful goaldriven dialogues in the future.
It is clear that a fullend-to-end goal-driven dialogue system should not only output a final sentence to respond an input sentence,but also keep and update fruitful internal representations or memories for dialogues.The internal memories can be either explicitly extracted and represented,or validated by some external tasks such as question answering.
5.Conclusions
This paper gave a brief survey on goal-driven human computer dialogue systems,including two often used frames and some recent research work on each subtask of dialogue systems.However,the major concern of the paper was jointmodels,which model multiple subtasks of dialogues simultaneously.
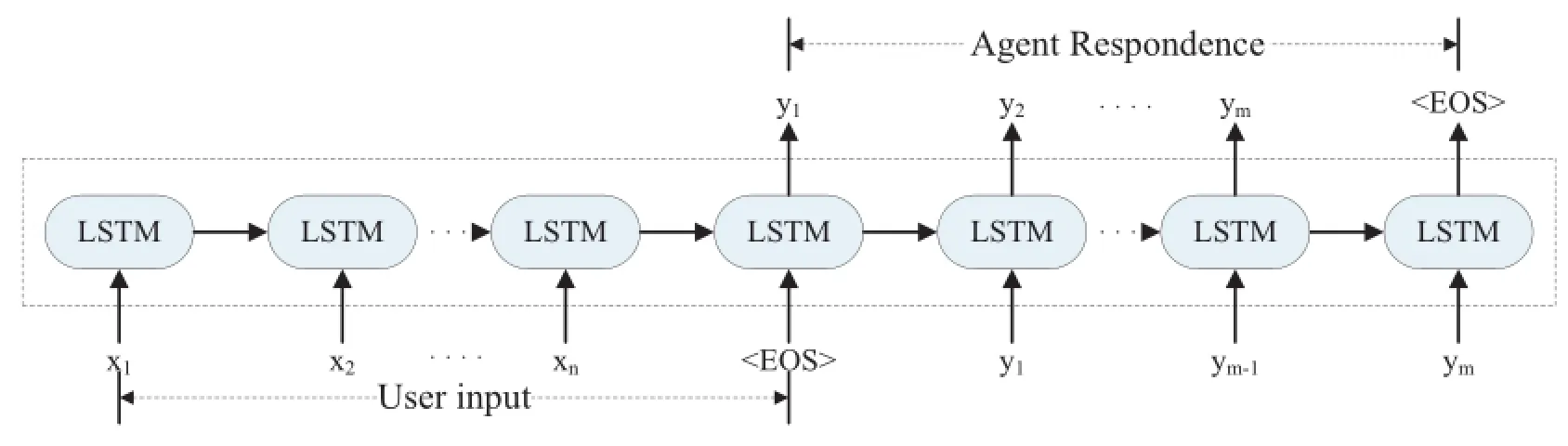
Fig.3.Sequence-to-sequence Conversational Model.
We considered jointly modeling is one important trend of dialogue systems.In fact,there was a rapid increase of work on joint models in recent years.We tried to survey mostof the related work in the paper,classified them according to which subtasks were taken into the joint models.As we have seen, there were several different types of join models,such as fl at or hierarchical type.There were also several different extents of integration,including integration of several subtasks inside NLG,DM or NLG,jointly modeling subtasks crossing NLG and DM,and jointly modeling the process through NLU,DM and NLG.
Although the joint models are at their beginning,they have shown some advantages compared with previous pipeline models.One significant advantage of joint models is that they could model interaction relations between different subtasks in a single model to improve the performance of the whole system.Another practical advantage is that joint models might remove some middle representations which were built manually before.It might reduce the subjective of human design and assign a dialogue model more flexible to adapt different tasks in different domains.
It is not so strange that most of recent joint models were constructed by deep neural networks.Deep neural networks provided some uniform structures and training ways for different subtasks.Reinforcement learning was still the main tool for DM.Although neural networks have long been used in reinforcement learning,it is the recent combination of reinforcement learning and different deep neural networks that brought the deep reinforcement learning,which has pushed the researches on joint models forward greatly.
Finally,there are lots of problems waiting for solutions in joint models.How to get enough data for building a dialogue system?,How to train a joint model efficiently?,How to adapt a joint model in one domain to another?and so on.Some of the problems have theoretical interests,some of them have practical appeals.
Acknowledgements
This paper is partly supported by National Natural Science Foundation of China(No 61273365),discipline building plan in 111 base(No.B08004)and Engineering Research Center of Information Networks of MOE,and the Co-construction Program with the Beijing Municipal Commission of Education.
[1]S.Seneff,L.Hirschman,V.W.Zue,Interactive problem solving and dialogue in the ATIS domain,in:Proceedings of the Workshop on Speech and Natural Language,1991,pp.354-359.Pacific Grove,California,February 19-22,1991.
[2]A.L.Gorin,G.Riccardi,J.H.Wright,How may I help you?Speech Commun.23(1)(1997)113-127.
[3]V.Zue,S.Seneff,J.Glass,et al.,JUPITER:a telephone-based conversational interface for weather information,IEEE Trans.Speech Audio Process.8(1)(2000)85-96.
[4]M.Walker,J.Aberdeen,J.Boland,et al.,DARPA communicator dialog travel planning systems:the June 2000 data collection,in:Proceedings of 2001 European Conference on Speech Communication and Technology, 2001,pp.1371-1374.
[5]J.Weizenbaum,ELIZA-a computer program for the study of natural language communication between man and machine,Commun.ACM 9 (1)(1966)36-45.
[6]S.Young,M.Gasic,B.Thomson,etal.,POMDP-based statistical spoken dialogue systems:a review,Proc.IEEE 101(5)(2013)1160-1179.
[7]K.Yu,L.Chen,B.Chen,et al.,Cognitive technology in task-oriented dialogue system-concepts,advances and future,Chin.J.Comput.37 (18)(2014)1-17.
[8]D.Jurafsky,J.H.Martin,Speech and Language Processing:An Introduction to Natural Language Processing,Computational Linguistics,and Speech Recognition,second ed.,Prentice-Hall,2007.
[9]P.Haffner,G.Tur,J.Wright,Optimizing SVMs for complex call classification,in:Proceedings of International Conference on Acoustics, Speech and Signal Processing,Hong Kong,April,2003,2003.
[10]J.Ang,Y.Liu,E.Shriberg,Automatic dialog act segmentation and classification in multiparty meetings,in:Proceedings of International Conference on Acoustics,Speech and Signal Processing,2005,2005.
[11]R.Sarikaya,G.E.Hinton,A.Deoras,Application ofdeep belief networks for natural language understanding,IEEE Trans.Audio,Speech Lang. Process.22(4)(2014)778-784.
[12]A.Ezen-can,K.E.Boyer,Unsupervised classification of studentdialogue acts with query-likelihood clustering,Int.Conf.Educ.Data Min.(2013) 20-27.
[13]A.Ezen-can,K.E.Boyer,Combining task and dialogue streams in unsupervised dialogue act models,in:Proceedings of 2014 Special Interest Group On Dialogue(SIGDIAL)Conference,Association for Computational Linguistics,2014,pp.113-122.Philadelphia,U.S.A., 18-20 June 2014.
[14]K.Yao,G.Zweig,M.Hwang,et al.,Recurrent neural networks for language understanding,Interspeech(2013)2524-2528.
[15]G.Mesnil,Y.Dauphin,K.Yao,et al.,Using recurrent neural networks for slot filling in spoken language understanding,IEEE/ACM Trans. Audio Speech Lang.Process.23(3)(2015)530-539.
[16]V.Vukotic,C.Raymond,Gravier,et al.,Is it time to switch to word embedding and recurrent neural networks for spoken language understanding?,in:Interspeech2015,2015.
[17]G.Tur,D.Z.Hakkani-Tur,D.Hillard,et al.,Towards unsupervised spoken language understanding:exploiting query click logs for slot filling,in:Proceedings of 2011 INTERSPEECH,2011,pp.1293-1296.
[18]G.Tur,A.Celikyilmaz,D.Z.Hakkani-Tur,Latent semantic modeling for slot filling in conversational understanding,in:Proceedings of 2013 IEEE International Conference on Acoustics,Speech and Signal Processing,2013.
[19]Y.Chen,W.Y.Wang,A.Gershman,et al.,Matrix factorization with knowledge graph propagation for unsupervised spoken language understanding,in:ACL-IJCNLP2015,2015,pp.483-494.
[20]Y.Chen,W.Y.Wang,A.I.Rudnicky,Leveraging frame semantics and distributional semantics for unsupervised semantic slot induction in spoken dialogue systems,in:Proceedings of 2014 Spoken Language Technology(SLT),2014.
[21]Y.Chen,W.Y.Wang,A.Gershman,et al.,Matrix factorization with knowledge graph propagation for unsupervised spoken language understanding,in:Proceedings of 2015 ACL-IJCNLP,2015,pp.483-494.
[22]Y.Chen,W.Y.Wang,A.I.Rudnicky,Jointly modeling inter-slotrelations by random walk on knowledge graphs for unsupervised spoken language understanding,in:Proceedings of 2015 NAACL-HLT,2015.
[23]J.D.Williams,Challenges and opportunities for state tracking in statistical spoken dialog systems:results from two public deployment,J.Sel. Top.Signal Process.6(8)(2012)959-970.
[24]J.Williams,A.Raux,D.Ramachandran,et al.,The dialog state tracking challenge,in:Proceedings of 2013 Special Interest Group On Dialogue(SIGDIAL),2013,pp.404-413.Metz,France,August.
[25]M.Henderson,B.Thomson,J.Williams,The second dialog state tracking challenge,in:Proceedings of 2014 Special Interest Group On Dialogue(SIGDIAL)Conference,Association for Computational Linguistics,2014a,pp.263-272.Philadelphia,U.S.A.,18-20 June 2014.
[26]M.Henderson,B.Thomson,J.Williams,The third dialog state tracking challenge,in:Proceedings of 2014 Spoken Language Technology(SLT), 2014,pp.2-7.
[27]S.Lee,Structured discriminative model for dialog state tracking,in: Proceedings of 2013 Special Interest Group On Dialogue(SIGDIAL), Metz,France,2013.
[28]H.Ren,W.Xu,Y.Zhang,et al.,Dialog state tracking using conditional random field,in:Proceedings of 2013 Special Interest Group On Dialogue(SIGDIAL),Metz,France,2013.
[29]M.Henderson,B.Thomson,S.Young,Deep neural network approach for the dialog state tracking challenge,in:Proceedings of 2013 Special Interest Group On Dialogue(SIGDIAL),Metz,France,2013.
[30]Q.Xie,K.Sun,S.Zhu,etal.,Recurrent polynomial network for dialogue state tracking with mismatched semantic parsers,in:Proceedings of2015 Special Interest Group On Dialogue(SIGDIAL),2015,pp.295-304.
[31]M.Gasic,S.Young,Gaussian processes for POMDP-based dialogue manager optimization,IEEE/ACM Trans.Audio Speech Lang.Process. 22(1)(2014)28-40.
[32]I.Casanueva,T.Hain,H.Christensen,etal.,Knowledge transfer between speakers for personalised dialogue management,in:Proceedings of 2015 Special Interest Group On Dialogue(SIGDIAL),2015.
[33]M.Barlier,J.Perolat,R.Laroche,et al.,Human-machine dialogue as a stochastic game,in:Proceedings of 2015 Special Interest Group On Dialogue(SIGDIAL),2015.
[34]E.Reiter,R.Dale,Building applied natural language generation systems, Nat.Lang.Eng.3(1)(1997)57-87.
[35]M.Stone,C.Doran,Sentence planning as description using tree adjoining grammar,in:Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics,1997,pp.198-205.Madrid,Spain.
[36]O.Dusek,F.Jurcicek,Training a natural language generator from unaligned data,in:Proceedings of the 53rd ACL and the 7th IJCNLP,2015, pp.451-461.Beijing,China.
[37]B.Lavoie,O.Rambow,A fast and portable realizer for text generation systems,in:Proceedings of the Fifth Conference on Applied Natural Language Processing,ANLC,1997,pp.265-268.Washington,DC.
[38]M.White,J.Baldridge,Adapting chart realization to CCG,in:Proceedings of 9th European Workshop on Natural Language Generation, Budapest,Hungary,2003.
[39]T.Zhao,M.Eskenazi,(2016).Towards end-to-end learning for dialog state tracking and management using deep reinforcement learning, arXiv.https://arxiv.org/abs/1606.02560,15 Sep 2016.
[40]P.Xu,R.Sarikaya,Convolutional neural network based triangular crffor joint intent detection and slot filling,in:2013 IEEE Workshop on Automatic Speech Recognition and Understanding(ASRU),2013,pp.78-83.
[41]D.Guo,G.Tur,W.Yih,etal.,Joint semantic utterance classification and slot filling with recursive neural networks,in:Proceedings of Spoken Language Technology2014,2014,pp.554-559.
[42]Y.Shi,K.Yao,H.Chen,et al.,Contextual spoken language understanding using recurrent neural networks,in:Proceedings of 2015 IEEE International Conference on Acoustics,Speech and Signal Processing, 2015,pp.5271-5275.
[43]Q.Zhou,L.Wen,X.Wang,A hierarchical LSTM modelfor joint tasks, in:Proceedings of The Fifteenth China National Conference on Computational Linguistics(CCL 2016),2016.
[44]C.Lee,Y.Ko,A simultaneous recognition framework for the spoken language understanding module of intelligent personal assistant software on smart phones,in:Proceedings of 2015 ACL-IJCNLP Conference, 2015,pp.818-822.
[45]M.Yazdani,J.Henderson,A model of zero-shot learning of spoken language understanding,in:Proceedings of the 2015 Conference on Empirical Methods on Natural Language Processing(EMNLP2015),2015.
[46]M.Henderson,B.Thomson,S.Young,Word-based dialog state tracking with recurrent neural networks,in:Proceedings of 2014 Special Interest Group On Dialogue(SIGDIAL),2014.
[47]N.Mrksic,R.Kadlex,et al.,Multi-domain dialog state tracking using recurrent neural networks,in:Proceedings of 2015 ACL-IJCNLP,2015, pp.794-799.
[48]V.Mnih,K.Kavukcuoglu,D.Silver,et al.,Playing Atari with deep reinforcement learning,Comput.Sci.(19 Dec 2013)https://arxiv.org/abs/ 1312.5602.
[49]V.Mnih,K.Kavukcuoglu,D.Silver,etal.,Human-level control through deep reinforcement learning,Nature 518(2015)529-533.Feb 26,2015.
[50]K.Narasimhan,T.D.Kulkarni,R.Barzilay,Language understanding for text-based games using deep reinforcementlearning.http://arxiv.org/abs/ 1506.089412,2015.Sep.11,2015.
[51]H.Cuayahuitl,S.Keizer,Strategic dialogue management via deep reinforcement learning,in:NIPS Deep Reinforcement Learning Workshop,2015.
[52]H.Cuayahuitl,SimpleDS:a simple deep reinforcement learning dialogue system.http://arxiv.org/abs/1601.04574,2016.
[53]K.Narasimhan,T.D.Kulkarni,R.Barzilay,Language understanding for text-based games using deep reinforcement learning,Comput.Sci.40(4) (2015)1-5.
[54]L.Lin,Reinforcement Learning for Robots Using Neural Networks, Technical report,DTIC Document,1993.
[55]H.V.Hasselt,A.Guez,D.Silver,Deep reinforcement learning with double q-learning,arXiv preprint,http://arxiv.org/abs/1509.06461,2015.
[56]Y.Schaul,J.Quan,I.Antonoglou,et al.,Prioritized experience replay, arXiv preprint,http://arxiv.org/abs/1511.05952,2015.
[57]Y.Ma,X.Wang,A two layer LSTMbased deep reinforcement learning for goal-driven dialogue system,BUPT CIST Tech Report,No 20161201, 2016.
[58]A.Belz,Automatic generation of weather forecast texts using comprehensive probabilistic generation-space models,Nat.Lang.Eng.14(4) (2008)431-455.
[59]Y.W.Wong,R.Mooney,Generation by inverting a semantic parser that uses statistical machine translation,in:Proceedings of the Human Language Technology and the Conference of the North American Chapter of the Association for Computational Linguistics,2007,pp.172-179.Rochester,NY.
[60]W.Lu,H.T.Ng,A probabilistic forest-to-string model for language generation from typed lambda calculus expressions,in:Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing,2011,pp.1611-1622.Edinburgh,Scotland,UK.
[61]I.Konstas,M.Lapata,A global model for concept-to-text generation, J.Artif.Intell.Res.48(2013)(2013)305-346.
[62]X.Zhang,M.Lapata,Chinese poetry generation with recurrent neural networks,in:Proceedings of the 2014 Conference on Empirical Methods on Natural Language Processing EMNLP(EMNLP2014),2014.
[63]T.H.Wen,M.Gasic,D.Kim,et al.,Stochastic language generation in dialogue using recurrent neural networks with convolutional sentence reranking,in:Proceedings of 2015 Special Interest Group On Dialogue(SIGDIAL),2015.
[64]T.H.Wen,M.Gasic,N.Mrksic,Semantically conditioned lstm-based natural language generation for spoken dialogue systems,in:Proceedings of Conference on Empirical Methods on Natural Language Processing(EMNLP2015),2015.
[65]H.Mei,M.Bansal,M.R.Walter,Whatto talk about and how?Selective generation using LSTMs with coarse-to-fine alignment.http://arxiv.org/ abs/1509.00838,2015.
[66]O.Dusek,F.Jurcicek,Sequence-to-Sequence generation for spoken dialogue via deep syntax trees and strings,in:Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics,2016, pp.45-51.Berlin,Germany.
[67]A.Ritter,C.Cherry,W.B.Dolan,Data-driven response generation in social media,in:Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing,Association for Computational Linguistics,2011,pp.583-593.
[68]A.Sordoni,M.Galley,M.Auli,et al.,A neural network approach to context-sensitive generation of conversational responses,in:Proceedings of 2015 North American Association of Computational Linguistics(NAACL),2015,pp.196-205.
[69]I.V.Serban,A.Sordoni,Y.Bengio,et al.,Building end-to-end dialogue systems using generative hierarchical neural network models.http:// arxiv.org/abs/1507.04808,2016.
[70]A.Sordoni,Y.Bengio,H.Vahabi,et al.,A hierarchical recurrent encoder-decoder for generative context-aware query suggestion,in: Proceedings of the ACM International Conference on Information Knowledge and Management(CIKM),2015.
[71]L.Shang,Z.Lu,H.Li,Neural responding machine for short-text conversation,in:Proceedings of ACL-IJCNLP,2015,pp.1577-1586.
[72]O.Vinyals,Q.V.Le,A neural conversational model,in:Proceedings of 2015 International Conference on Machine Learning(ICML2015),2015.
[73]J.Li,M.Galley,C.Brockett,et al.,A diversity-promoting objective function for neural conversation models.http://arxiv.org/abs/1510.03055, 2015.
[74]J.Dodge,A.Gane,X.Zhang,etal.,Evaluating prerequisite qualities for learning end-to-end dialog system,in:Proceedings of 2016 International Conference on Learning Representations(ICLR2016),2016.

Xiaojie Wangreceived his Ph.D.degree from Beihang University in 1996.He is a professor and director of the Centre for Intelligence Science and Technology at Beijing University of Posts and Telecommunications.His research interests include Natural Language Processing and multi-modal cognitive computing.He is an executive member of the council of Chinese Association of Artificial Intelligence,director of natural language processing committee.He isa member of council of Chinese Information Processing Society and member of Chinese Processing Committee of China Computer Federation.

Caixia Yuanreceived the Ph.D.degree in 2009 from Beijing University of Posts and Telecommunications, China and the University of Tokushima,Japan.She is currently working at Beijing University of Posts and Telecommunications.Her research interests include natural language understanding,man-machine dialogue,and machine learning.
Available online 23 December 2016
*Corresponding author.
E-mail addresses:xjwang@bupt.edu.cn(X.Wang),yuancx@bupt.edu.cn (C.Yuan).
Peer review under responsibility of Chongqing University of Technology.
http://dx.doi.org/10.1016/j.trit.2016.12.004
2468-2322/Copyright©2016,Chongqing University of Technology.Production and hosting by Elsevier B.V.This is an open access article under the CC BY-NCND license(http://creativecommons.org/licenses/by-nc-nd/4.0/).
Copyright©2016,Chongqing University of Technology.Production and hosting by Elsevier B.V.This is an open access article under the CC BY-NC-ND license(http://creativecommons.org/licenses/by-nc-nd/4.0/).
 CAAI Transactions on Intelligence Technology2016年4期
CAAI Transactions on Intelligence Technology2016年4期
- CAAI Transactions on Intelligence Technology的其它文章
- Social network search based on semantic analysis and learning
- Building a click model:From idea to practice
- A survey on rough set theory and its applications
- Evolutionary computation in China:A literature survey
- Research progress of artificial psychology and artificial emotion in China
- A review on Gaussian Process Latent Variable Models