
A review on Gaussian Process Latent Variable Models
2016-03-20 06:51PingLiSongcanChen
Ping Li,Songcan Chen*
College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China
A review on Gaussian Process Latent Variable Models
Ping Li,Songcan Chen*
College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China
Gaussian Process Latent Variable Model(GPLVM),as a flexible bayesian non-parametric modeling method,has been extensively studied and applied in many learning tasks such as Intrusion Detection,Image Reconstruction,Facial Expression Recognition,Human pose estimation and so on.In this paper,we give a review and analysis for GPLVM and its extensions.Firstly,we formulate basic GPLVM and discuss its relation toKernel Principal Components Analysis.Secondly,we summarize its improvements or variants and propose a taxonomy of GPLVM related models in terms of the various strategies that be used.Thirdly,we provide the detailed formulations of the main GPLVMs that extensively developed based on the strategies described in the paper.Finally,we further give some challenges in next researches of GPLVM.
GPLVM;Non-parametric method;Gaussian process
1.Introduction
In many machine learning tasks,we are often faced with various complex,particularly high dimensional,data/observations[1-3]for which our goal is to learn the low dimensional underlying patterns from those observations[4,5].For example,in classification task[6-9],we want to identify a category of a new observation by a classifier learned from a set of training data.In clustering task,the goal is to group a set of observations in such a way that observations in the same group (called a cluster)are more similar(in some sense or another) to each other than to those in other groups[10,11],achieving to understand inherent(low dimensional)structure of a given data set.
Recently,many machine learning models have been proposed to address the above problems[1,3,12,13].Among those models,latent variable models(LVMs)[3,14,15]as a kind of underlying patterns extraction methods,have been widely used in image recognition[16],information retrieval[17],speech recognition[18]and recommender systems[19].A latent variable model generally refers to a statistical model that relates a set of variables(so-called manifest variables)to a set of latent variables under the assumption that the responses on the manifest variables are controlled by the latent variables. Furthermore,we can provide latent variables with various meanings for specific tasks.InDimension Reduction(DR),we assume that the latent variables are the low dimensional representations of high dimensional samples.In clustering,the latent variables can be defined to represent the clustering membership of samples[20].This fl exible definition of latent variables has made LVMs widely be used in many machine learning tasks.
LVMs have a history of several decades and many machine learning models can be actually considered as its special cases or variants,e.g.,neural networks[18],PCA[21],latent graphical models[3]and so on.Among these models,Gaussian Process Variable Models(GPLVMs)[15],as a large class of LVMs,have been explored and applied in many machine scenarios.They can be considered as the combination of LVM and a Bayesian non-parametricGaussian Process(GP) [22]model.GP is a probabilistic model and has been extensively applied in many machine learning tasks such as regression[23-25],classification[6-8]and clustering[26].In general,we can consider these GP-based models to be a set of LVMs where each observed variable is the sum of the corresponding latent variable and noise.Different from other LVMs,these latent variables can be thought of as functional variables which are the noise-free form of observed variables. In LVMs,our goal is to learn the latent variables or the underlying pattern of data.While the above GP-based models try to infer the targetvariable ofnew sample by integrating outthe latent variables.This is a major difference between GP-based model and other LVMs.
In order to infer the latent variables,GPLVM assumes that the functional variables are generated by GP from some low dimensional latent variables.It is these latent variables that we should inferred from data.In model inference,we can learn the latent variables by integrating out the functional variables and maximizing the log marginal likelihood.Although originally proposed for dimension reduction,GPLVM has been extended and widely used in many machine learning scenarios,such as Intrusion Detection[27],Image Reconstruction [28],Facial Expression Recognition[29],Human pose estimation[30],Age Estimation[31]and Image-Text Retrieval [32].
We can analyze the advantages of GPLVM from two aspects.Firstly,GPLVM can greatly benefit from the non-linear learning characteristic of GP which uses a non-linear kernel to replace the covariance matrix.Moreover,as a non-linear DR model,GPLVM has a strong link withKernel Principal Components Analysis(KPCA)[33](a popular DR method) and can be considered as aProbabilistic Kernel Principal Components Analysis(PKPCA).For such a link,we will discuss in next section.Secondly,most of the existing LVMs are parametric models in which there is a strong assumption on the projection function or data distribution.Such a parametric construction form partly loses flexibility in modeling. Therefore,in the past decades,many non-parametric machine learning methods have successively been proposed,such as Nearest Neighbor methods[34,35]and kernel estimates of probability densities[36,37].GP and GPLVM can be treated as a class of Bayesian non-parametric model whose distribution-free form makes the models have a flexible structure which can grow in size to accommodate the complexity of the data.
Besides widely used in DR,GPLVM can also be extended to other machine learning tasks due to its characteristics below.Firstly,its distribution-free assumption on prior of latent variables provides us a lot of opportunities to improve it. Secondly,its generation process can be amenable to different tasks.Thirdly,we can also exert classical kernel methods for a further expansion of GPLVM,such as enhancing the scalability of the model,automatic selection of the feature dimension and so on.Despite GPLVM has been widely studied and extended,to our best knowledge,there has actually had no survey for those related models.So in this paper, we try to present a review and analysis of both GPLVM and its extensions.
The rest of this paper is organized as follows:In Section 2, we formulate the GPLVMs and discuss its relation toKernelPrincipal Components Analysis(KPCA).In Section 3,we summarize its improvements or variants and propose a taxonomy of GPLVM related models.A specific review of GPLVM that extensively developed in the past decade is given in Section 4.Finally,in Section 5,we further give some challenges in next researches of GPLVM.
2.Gaussian process and Gaussian Process Latent Variable Model
2.1.Gaussian process
GP,as the a flexible Bayesian nonparametric model and the building block for GPLVM,has been widely used in many machine learning applications[38-40]for data analysis.In GP,we model a finite set of random function variables f=[f(x1),…,f(xN)]Tas a joint Gaussian distribution with meanμand covariance K,where xiis theith input.If the functionfhas a GP prior,we can write it as

where in many cases we can specify a zero mean(μ=0)and a kernel matrix K(with hyper-parameterθ)as covariance matrix.GP has been widely used in various machine learning scenarios such as regression,classification,clustering.In this section,we detailed the formulation ofGaussian Process Regression(GPR)to demonstrate the use of GP.
In GPR,our goal is to predict the responsey*of a new input x*,given a training datasetofNtraining samples,where xiis the input variable andyiis the corresponding continuous response variable.We model the response variableyias a noise-version of the function valuef(xi)

where the distribution of noise is Gaussian N(0,σ2)with varianceσ2.From the above definition,we can get the joint probability of the response variables and latent function variablesp(y,f)=p(y|f)p(f).Then we can know that the distribution of the latent function valuef*is a Gaussian distribution with meanμ(x*)and variancevar(x*):
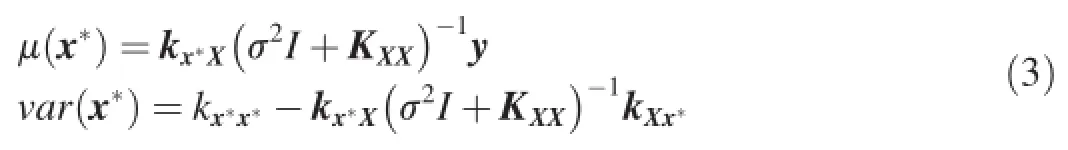
where kx*X=k(x*,X)is an-dimensional row vector of the covariance between x*and theNtraining samplesdenotes the kernel matrix of theNtraining samples.
2.2.Gaussian Process Latent Variable Model
GPLVM[15]is originally proposed for dimension reduction of high dimensional data.Its goal is to learn the low dimensional representation XN×Qof the data matrix Y∈ℝN×D, whereNandDare the number and dimensionality of trainingsamples,respectively.GPLVM assumes that the observed data is generated from a lower dimensional data X whereQ≪D. The generation process of theith training sample yiis

whereεis the noise with gaussian distributionε~N(0,σ2).fis a nonlinear function with GP priorAs a probabilistic model,GPLVM can also be represented by a directed graph as shown in Fig.1.In this paper,we use gray and white circles to denote the observed and latent variables, respectively.From the this graphical representation,we can know that the marginal likelihoodp(Y|X,θ)can be obtained by using Bayesian theorem and integrating outf,
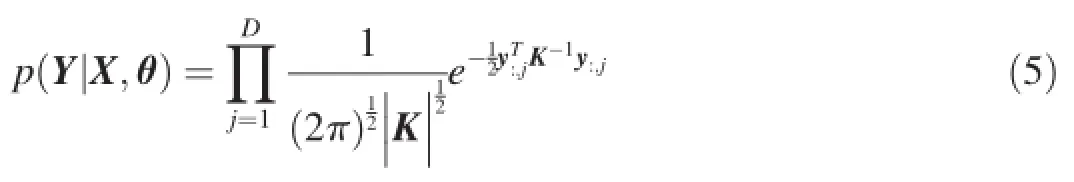
whereθdenotes the hyper-parameters of both kernel function and noise,y:,jdenotes thejth column of matrix Y.Thus,we can maximize the marginal likelihood with respect to X and the hyper-parameterθ,
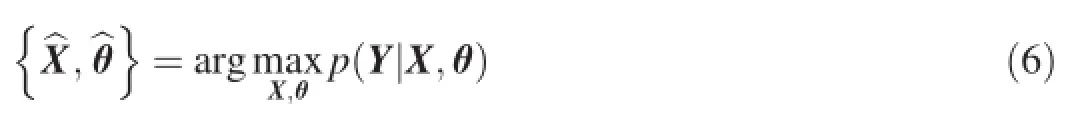
The object function of GPLVM can also be derived fromProbabilistic Kernel Principal Components Analysis.In PKPCA,we aim to learn a low-dimensional representation X of original data Y and assume that the projection(parameter) matrix W follows a spherical Gaussian distribution prior below:


Fig.1.Gaussian process as a latent variable model:we use arrows to denote the dependency relations between variables.The gray and white circles denote the observed and latent variables,respectively.
Then,we can get the marginal likelihood by integrating out W:

As we can see from Eq.(8),GPLVM can be equivalent to PKPCA by replacing XXTin Eq.(8)with a kernel matrix K.
Besides be used in DR,GPLVM has also been extended to adapt to many other machine learning problems,such as Image Reconstruction[28],Human pose estimation[30],Age Estimation[31]and so on.In addition,there have been many open-source softwares that are available for the implementation of GPs and GPLVMs.We give a brief description as follows:
·GPML1http://www.gaussianprocess.org/gpml/code/matlab.is an excellent GP toolkit.It contains a large number of GP-related codes such as various kernel functions,likelihood functions and inference methods.
·GPy2https://github.com/SheffieldML/GPy.is a Gaussian Process framework written in python, from the Sheffield machine learning group.It provides a set of tools for the implementation of GP-based methods.
·Matlab Toolbox for Dimensionality Reduction4http://lvdmaaten.github.io/drtoolbox/.is a dimension reduction toolkit.It provides the implementations of many techniques for dimensionality reduction and metric learning.It also contains an implementation of GPLVM.
3.Extensions of GPLVM
As shown in Section 2.2,due to its flexible structure in modeling,GPLVM has been adapted to various learning scenarios and led to corresponding learning methods.In this section,we first classify these methods into three types in terms of the variousstrategiesthat used and then provide a taxonomy of the main existing GPLVMs as shown in Fig.2. For more typical examples of specific applications refer to Section 4.
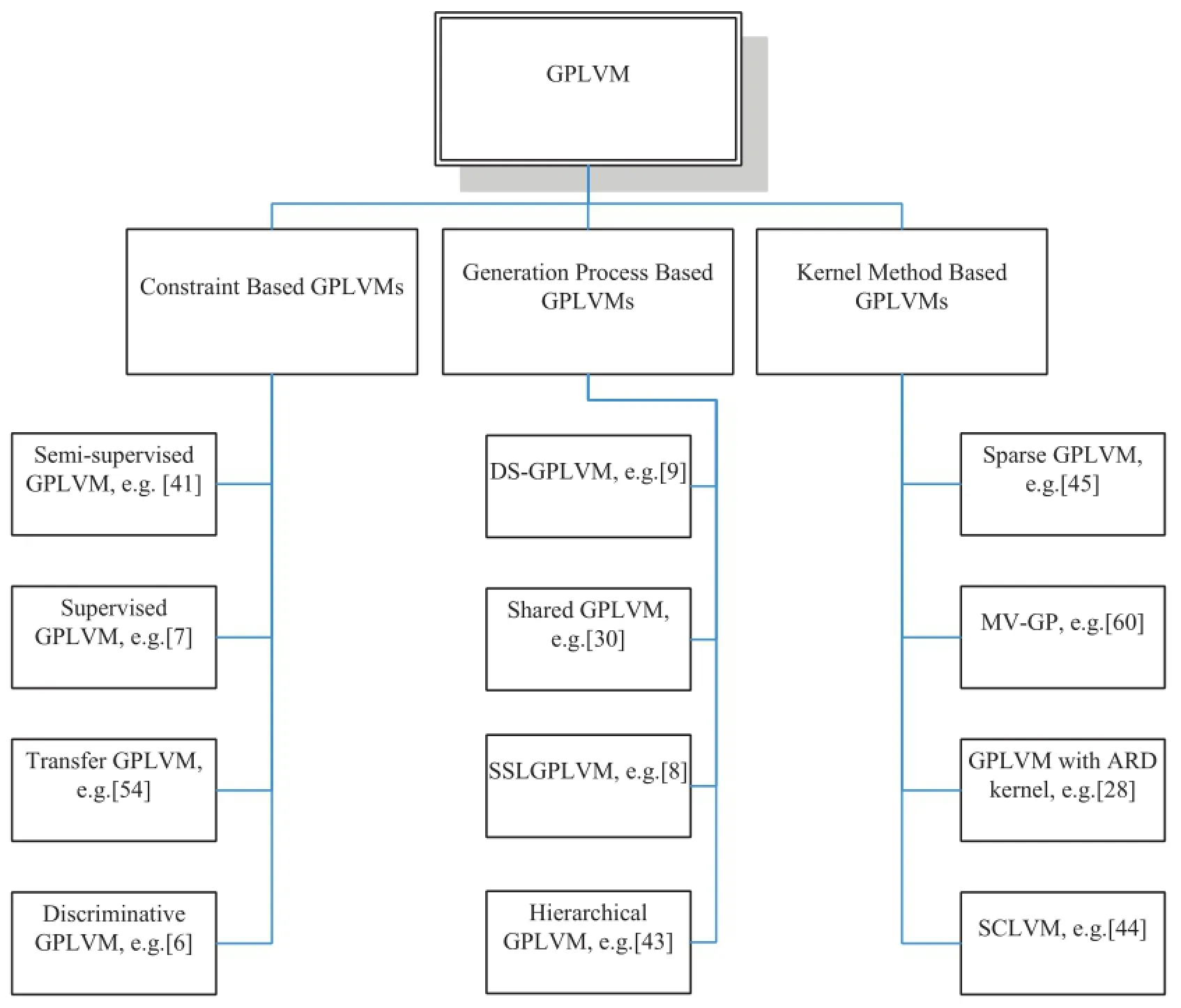
Fig.2.A taxonomy of the GPLVMs.
3.1.Constraint based GPLVMs
From the generation process of GPLVM in Section 2.2,we can know that the conventional GPLVM needs not make any assumptions on the prior of latent variables.However,lack of such assumption makes the model inferred by justmaximizing the log marginal likelihood in Eq.(6)prone to over fitting.To tackle this problem,one of effective approaches is to impose a specific prior onto the latent variables for a posterior estimation.Thus,we can introduce various constraints into the prior for the estimation the latent variables in different tasks[41,6]. Specifically,we assume thatp(X)denotes the imposed prior. By using the Bayesian theorem,we can formulate the posterior probability of the latent variables X
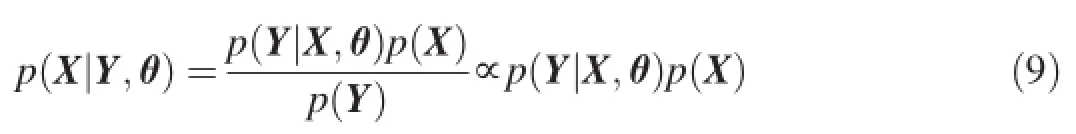
Thus,we get the posterior estimation of X by maximizing Eq.(9)instead of the marginal likelihoodp(Y|X,θ).
In practical applications,many constraints can be introduced and embedded into the priors for problem at hand.In [41],pairwise constraints(which indicates whether two samples belong to the same class or different classes)are utilized to construct a specific prior of X for semi-supervised learning [6,7].Construct a discriminative prior based on the label information of data and use this prior directly predict the label of a new sample.In general,all these priors described above can be considered as such a set of constraints derived from given problems,which can be used to learn the latent variables of GPLVM.In some other learning scenarios,we can even also impose explicit constraints on the latent variable[42]for construction of the proper prior.
3.2.Generation process based GPLVMs
学霸寝室是高校学风建设中的稀有资源,对高校学风建设弥足珍贵,经过充分开发应用,可发挥重要作用。因此,在学风建设中,要将学霸寝室的发掘、打造和宣传融为一体,让学霸寝室成为学风建设的启明星。同时,学霸寝室也要有高度责任感,主动帮助后进寝室,在帮扶中提升自我政治素质,成长为政治修养高、综合素质强的寝室。
The conventional GPLVM just defines the generation process of high dimensional data for dimension reduction. However,for more complex data,such as multi-view and/or multi-modal data,such a single generation process fails to fit the data.Therefore,we need to redefine the generation process to deal with differenttypes of data.By this approach,GPLVM is extended to be capable to model various complex data.
In[30],aShared Gaussian Process Latent Variables Model(Shared GPLVM)is proposed to define the generation process of data from multiple sources and learn a low dimensional shared representation for these data.Besides the Shared GPLVM,there are yet many other methods to define the generation process from inputs to outputs for different learningtasks,for example[7]and[8]define the discriminant form generation processes to implement the prediction of labels [43].Construct the hierarchical GPLVM to learn more complicated functions.
3.3.Kernel method based GPLVMs
As described in Section 2.2,GPLVM can in fact also be considered as a kernel method,in which the selection of kernel can greatly influence its performance.In general,we can select various kernel to meet the demands of different tasks.For example,in order to automatically select the subset of the latents pace,we can use the automatic relevance determination (ARD)kernel in the construction of GPLVM[28].The definition of the ARD kernel is as follows,
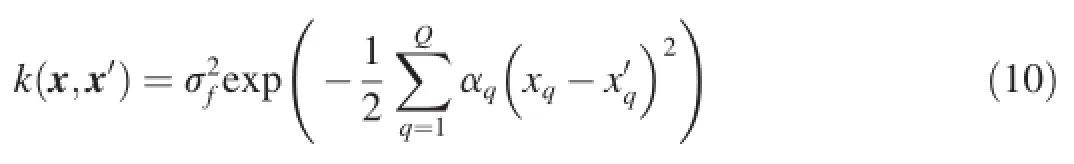
Besides ARD kernel,many other kernels can also be used to handle different tasks.In theStructure Consolidation Latent Variable Model(SCLVM)[44],a compositional kernel is used to solve the problem of label imbalance.In some situations, we can even learn the kernel matrix from data directly.Sparse GPLVMs[45-49]try to learn areduced-rank approximationsof the kernel matrix to improve the scalability of GPLVM. Specifically,they use the following equation to estimate the kernel matrix K,

whereNdenotes the number of training samples andM≪N. With this method,the computation of GPLVMs when inverting the kernel matrix has a time complexity of O(M2N)other than O(N3),which makes GPs and GPLVMs able to effectively solve problems with large scale data.
4.Typical examples
In Section 3,we summarized the main strategies for the extension of GPLVM.In this section,we will give a review and detailed formulations of the typical GPLVMs that extensively developed based on these strategies.Moreover,we also give a brief description of some other GPLVMs that proposed for special application scenarios.
4.1.GPLVMs with various constraints
As described in Section 3.1,various constraints can be imposed into the prior of latent variables according to the specific tasks.In general,the existing GPLVMs mainly utilize the following constraints:semi-supervised constraints[41,50], supervised constraints[6,7],cross-task constraints[51].
4.1.1.Semi-supervised GPLVM
In some machine learning scenarios,we assume that user can get both input data described in Section 2.2 and some semi-supervised information,such as pairwise constraints [41].Proposes the Semi-supervised GPLVM which utilizes such pairwise information to construct a specific prior of X. Firstly,it defines a weight matrix W∈ℝN×N


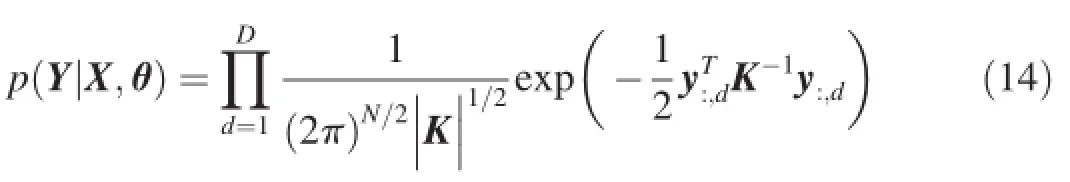
Then,we use the Bayesian theorem in Eq.(9)to get the posterior probability of the latent variables X.Thus,maximizing marginal likelihood can be replaced by maximizing the log posterior given by

4.1.2.Discriminative GPLVM
In supervised learning scenarios,the goalis to learn models from labeled data and predict the labels of new samples directly[6-8].As described in Section 3.1,we can also introduce label constraint information into GPLVM for supervised learning.Discriminative Gaussian Process Latent Variable Model(Discriminative GPLVM)[6]imposes a discriminative prior to the latent variables which can significantly improve the discriminant property of GPLVM.Specifically,this discriminative prior is constructed by borrowing the idea ofLinear Discriminant Analysis(LDA)[21],as shown in the following equation,

where Swand Sbdenote within-class and between-class divergence matrices,respectively.The definition of Swand Sbis as follows,

where Miis the mean of the elements of classi,M0is the mean of all the training points of all classes,are theNitraining points of classi.By maximizing the object function of LDA,we can find a transformation that maximizes between-class separability and minimizes within-class variability.Inspired by this motivation, Discriminative GPLVMconstructs a prior over latentvariables that forces the latent points of the same class to be close together and far from those of other classes,as shown in Eq. (19)

By using Bayes theorem described in Eq.(9),we can get the posterior distribution of latent variable X.Then,we can minimize the negative log posterior in Eq.(20)to learn these latent variables,

where Lrrepresents the negative log likelihood of GPLVM,denotes the prior of hyper-parameters,can be c onsidered as the coefficient that balances the discriminant capability and the fitness to data Y.Furthermore,since the kernel matrix learned in the discriminative GPLVM is more discriminative and fl exible,it can directly be used inGaussian Process Classification(GPC)[22]forsupervised learning tasks.
4.1.3.Supervised GPLVM
Gao et al.[7]proposes aSupervised Gaussian Processes Latent Variables Model(Supervised GPLVM)by using latent variables to connect observations and their corresponding labels.Specifically,it assumes that X∈ℝN×D,Y∈ℝN×L, Z∈ℝN×Qdenote the matrices of inputs,labels and the corresponding latent variables,respectively.The graphical representation is shown in Fig.3.As we can see,Supervised GPLVM assumes that both X and Y are generated from the same latent variables Z by GPs.The latentvariable Z can serve as a bridge between two observed matrices.This approach has already been extensively studied in many machine learning models such as joint manifold model[52]and supervised probabilistic PCA (SPPCA)[53].As shown in Fig.3,each dimension of X and Y is independent conditioned on Z.Thus,the log marginal likelihood of the model can be obtained the following equation,

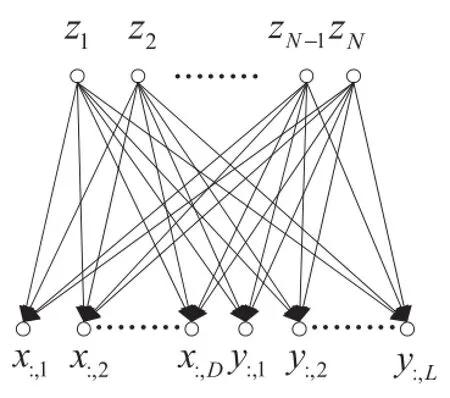
Fig.3.The graphical representation of Supervised GPLVM.The latent variable Z can serve as a bridge between two observed matrices X and Y.
4.1.4.Transfer Latent Variable Model
When using GPLVM to predict new samples,we make a strong assumption that both training and testing samples are drawn from anindependent identity distribution(iid).However,when these two data sets are drawn from different distributions,the GPLVM trained by using training data set will have a poor performance on the new test samples.One useful tool for this problem is the transfer learning strategy[51]. Transfer learning is widely studied by researchers in machine learning,which focuses on storing knowledge which gained when solving one problem and applying it to a different but related problem.
Gao et al.[54]proposes a transfer learning framework for GPLVM(Transfer Latent Variable Model,TLVM)based on the distance between training and testing data sets.Specifically,it assumes that the training set Y=[y1,…,yN]Tand testing set Yt=[yt1,…,ytM]Tare drawn from two different distribution and their corresponding latent variables matrix are X and Xt,respectively.TLVM uses KL-divergence to measure the distance between the training and testing data set,
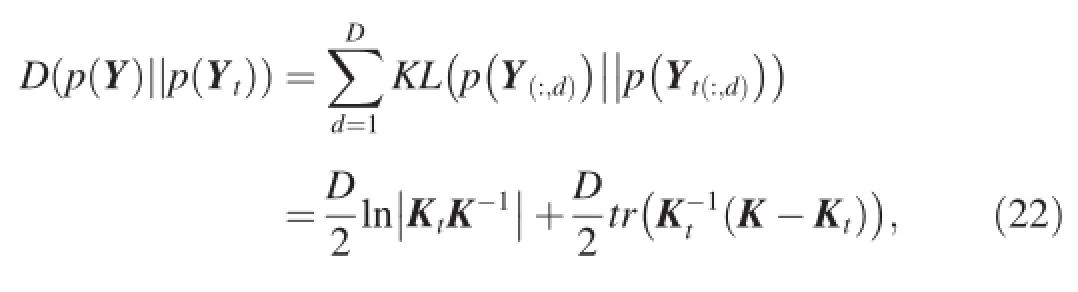
where K and Ktare the kernel matrices of X and Xt,respectively.The object functionF(X,θ)can be written as
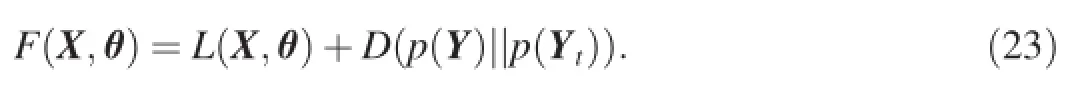
Then,we can minimize Eq.(23)to find the optimal values of latent variable X and hyper-parameterθ.
4.2.GPLVMs based on generation process
reconstruction
In general,there are mainly two strategies to reconstruct the generation process,data-driven approaches and task-driven approaches.In data-driven approaches,we can reconstructthe generation process of GPLVM with respect to the characteristics of the data,such as the works in[30,9]for multi view learning.In task-driven approaches,the generation process is reconstructed to meet the demands of the tasks[8].In this section,we will demonstrate the concrete examples of these two approaches.
4.2.1.Shared GPLVM
In computer science,many tasks are associated with data coming from multiple streams or views of the same underlying phenomenon[9,29,30,42,55].In video processing,there may be many cameras each of which focus on objects from different viewpoints.In user-centric social networks,information from different sources(text,image,video,audio and social information)can be obtained[56].Our goal is to utilize these complementary information to fulfill machine learning tasks such as person re-Identification[57],human pose estimation[30],facial expression recognition[9]and so on.
Shared GPLVM[30]can efficiently capture the correlations among different sets of corresponding features and is applied in machine learning tasks.Specifically for two data views, Y=[y1,…,yN]T∈ℝN×Dand Z=[z1,…,zN]T∈ℝN×L(where ynand zndenote the representations of thenthsample in the two views,respectively),the goal of Shared GPLVM is to learn a common low-dimensional representation X for Y and Z. Its graphical representation is shown in Fig.4.As we can see, it assumes that both Y and Z are generated by GP from a shared latent variable X and its corresponding generation processes can respectively be written as
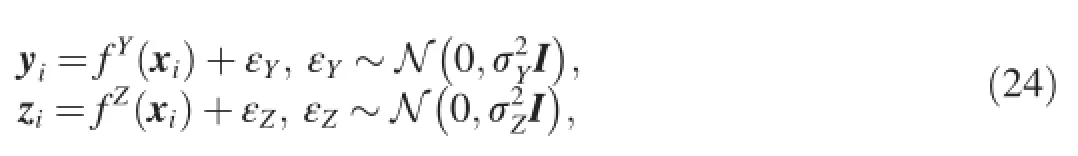
wherefYandfZdenote the functions with GP prior,εYandεZdenote the noises,respectively.According to the assumption that Y and Z are independent conditioned on X,the likelihood of Shared GPLVM is formulated as,
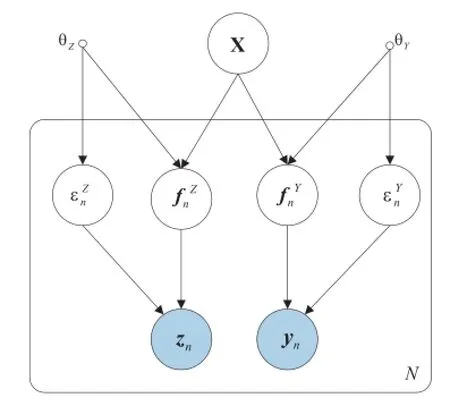
Fig.4.The graphical of Shared GPLVM.The generation process is redefined by assuming that both Z and Y are generated by GP from X.Z and Y are independent conditioned on X.
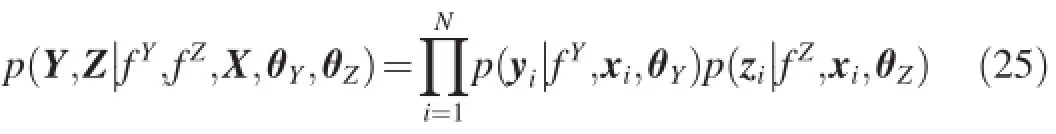
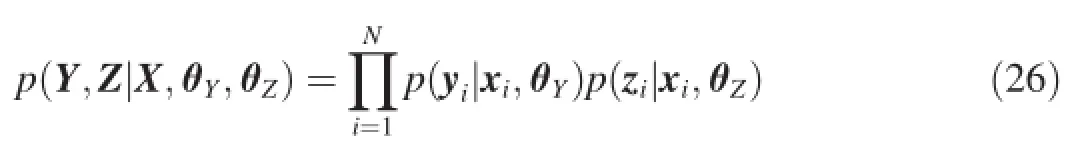
4.2.2.Discriminative shared GPLVM
By redefining the generation process,Shared GPLVM that described in[30]can efficiently capture the correlations among different sets of corresponding features and is applied in many machine learning tasks[9,58][9].ProposedDiscriminative Shared Gaussian Processes Latent Variable Model(DS-GPLVM)by considering the situation in which user has observed the label information of each view.It uses such label information to construct a discriminant prior based on the Laplacian matrix[59].Specifically,the joint Laplacian matrix has the following form:

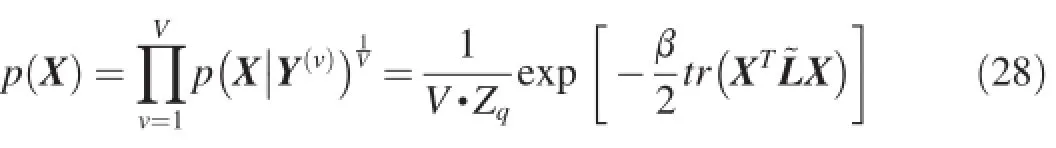

4.2.3.Supervised Latent Linear GPLVM(SLLGPLVM)
The work in[8]implements supervised learning of GPLVM by redefining the generation process.Specifically,as shown in Fig.5,the model assumes that the latent variable Z is generated by a linear transformation of X.Then,the target variable Y is generated by a GP with latent variables as inputs.The whole generation process is as follows:

where W represents the projection(parameter)matrix from input space to latent space.The functiong(·)denotes themapping that transforms the latent variables to the output variables andThus,the prior distribution of g can be written as

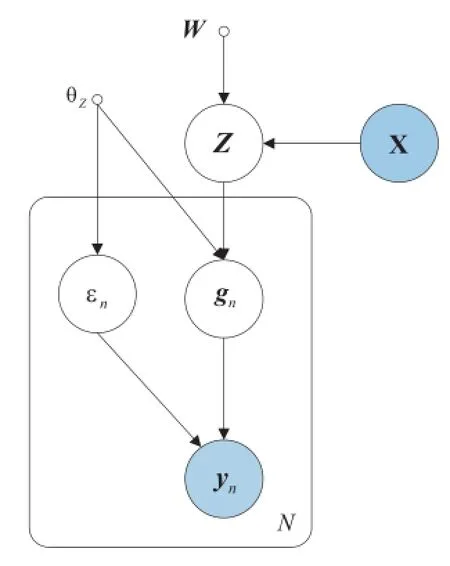
Fig.5.The graphical representation of Supervised Latent Linear GPLVM.As we can see,both X and Y are observed.Our goalis to learn the project matrix W for prediction.
where KZ,Zdenotes the kernel matrix of latent variables Z=XW.Based on this prior,we can construct GPLVM and maximize the log marginal likelihood to learn the matrix W as in Section 2.2.
4.3.GPLVMs based on specific kernels
As a kernel method,GPLVMcan utilize various kernels for specific tasks.Firstly,many existing kernels can be introduced into GPLVM to address different problems[28,60].Secondly, we can also construct kernels by combining multiple kernels [44]or learning the kernel matrices directly[45-49].
4.3.1.Structure consolidation latent variable model
As described in Section 3.3,many kernels can be introduced into GPLVM to meet the demands of different tasks. The SCLVM[44]uses a compositional kernel to address the problem of labe limbalance.Specifically,it separates the latent space into a shared space with the dimensionalityQsand a private space with the dimensionalityQp.Thus,the latent representation can be denoted asandare the latent representations in shared and private space respectively.Then,the compositional kernel can be defined as follows:
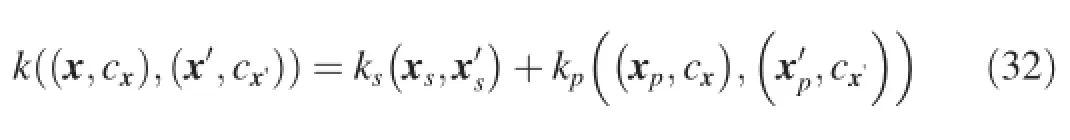
whereksis the kernel function for the shared space andkpis the kernel function for the private space.The private kernel is defined as follows:
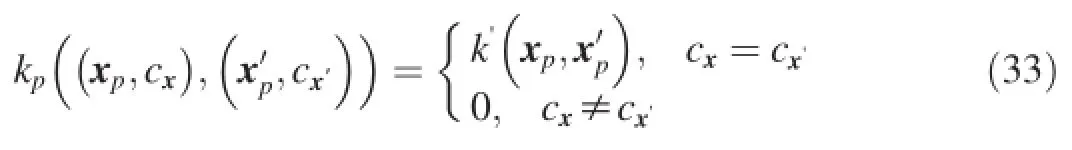
wherek′is a common kernel function andcxis the label of data point x.By such a definition the shared space can capture the common regularities among categories and the private spaces can model the variance specific to individual categories.Thus the data in each category can be modeled appropriately to solve the problem of label imbalance.
4.3.2.Matrix-valued Gaussian process
Recently,transposable data(such as proteins interaction networks in biology and movies rating data in recommendation system)which describes the relationships between pairs of entities,has been analyzed.Such data can often be organized as a matrix,with one set of entities as the rows,the other set of entities as the columns[60].Proposes aMatrixvalued Gaussian Process(MV-GP)to model such data.Specifically,it assumes that Y∈ℝN×Ddenotes the transposable data matrix withNrows andDcolumns.It models Y as a matrix-variate normal distribution with iid Gaussian observation noise.
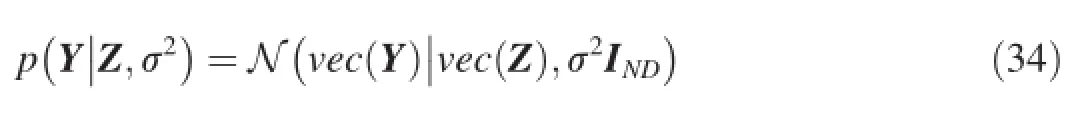
where latent variables Z can be thought of as the noise-free observations andvec(Y)denotes the vector obtained by concatenating the columns of Y.
A further assumption is that Z is drawn from a MV-GP,
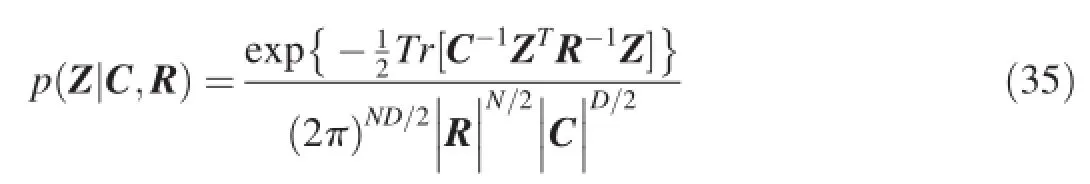
where matrix C is aD×Dcolumn covariance matrix and R is anN×Nrow covariance matrix.Obviously,MV-GP can be considered as a multivariate normal distribution by writing the MV-GP as

where⊗denotes theKronecker product.Furthermore,it can also be considered as a GPLVM in which the common kernel function is replaced with the product of two kernel functions. Based on this formulation,the MV-GP has been applied in many machine learning tasks[61-64]which try to learn the relation between pairwise entities.
4.4.Other GPLVMs for special applications
Apart from the various GPLVMs that described above, there are also many other GPLVMs that try to address the special problems in machine learning.These GPLVMs can be considered as a set of self-contained models that are difficult to be accommodated to one of the three strategies described in Section 3.In this section we just give a simple description for these models.
4.4.1.Bayesian Gaussian Process Latent Variable Model
GPLVM can also be used in the situation with uncertain inputs.In this case,we can take a Bayesian estimation of GPLVM whose latent variables are integrated out instead of optimized[28].However,as described in[28],the main difficulty is that,to apply Bayes inference to GP-LVM,we need to approximately integrate out the latent variables nonlinearly in the inverse kernel matrix of the GP model[28].Proposes a variational Bayesian GPLVM model by using variational inference[65]in an expanded probability model to tackle the above problem.This model and its extension have been widely used in many machine learning tasks,such as gaussian process regression with uncertain inputs[66],hybrid discriminativegenerative approach[67]and so on.
4.4.2.Gaussian Process Dynamical Systems
In robot control,computer vision,computational biology, users are often faced with high dimensional time series data [68].By assuming x as a multivariate gaussian process indexed by timet,GPLVM can be extended to a dynamical model which are called Gaussian Process Dynamical System (GPDS)[43,68-70]to adapt such dynamic environment.In fact,this model can be considered as Hierarchical GPLVMand obtain a satisfactory performance in analysis of data with time series information.Models based on GPDS have been used in many tasks such as human pose recognition[69],modeling raw high dimensional video sequences[68],video repair[71] and some other related applications.
4.4.3.Deep GPLVM
Although Gaussian Process Latent Variables Modelprovides a fl exible,non-parametric,non-linear dimension reduction strategy,their representation ability is still restricted by the kernelfunctions[72].In general,GPLVM,as a shallow model, can be stacked to a deep architecture[73].This structure has been widely used in many deep models[74,75].And some deep models based on GPLVM have been proposed such as autoencoded deep gaussian processes[72],deep gaussian processes[76],deep gaussian processes for regression[77].
5.Conclusion and discussion
In this paper,we first give a detail formulation of GPLVM and its relation to PKPCA.Then,we summarize the main strategies to improve GPLVM and a taxonomy is constructed in terms of the various strategies used.We also review the main GPLVMs that extensively developed based on the methods described in Section 3.In this section,we will draw some promising lines for future researches of GPLVM.
5.1.GPLVM for discrete variables
The conventional GPLVMand its extensions are suitable for analysis of continuous data.However,in many machine learning task such as naturallanguage processing and medical diagnosis, users often get discrete variables.Although[78],has proposed a GPLVM for the estimation of multivariate categorical data,its inference is based on the variational approximation and sampling approaches which have a high computational complexity. To overcome the difficulty,we mainly should consider two factors:the construction of likelihood and the inference method of latent variables,which deserve more attentions.
5.2.Scalable inference in GPLVM
During the inference of GPLVM,we should evaluate the distributionp(Y|X)which has a time complexity of O(N3)by computing the inversion of theN×Nkernel matrix.Although, there have been many methods for the sparse estimation of GP and GPLVM[45-49],they can not improve the scalability of GPLVM without the risk of accuracy loss.For this reason,the scalable inference of GP and GPLVM has become a popular research content recent years and will be paid more attention in the future.
5.3.Similarity Gaussian Process Latent Variable Model
Recent years,metric learning methods are widely studied. Its goal is to learn a suitable metric by using the distance constraints of pairwise samples[42].To our best knowledge, there is only one model[32]that uses GPLVM to construct a similarity learning model(m-SimGP)of multi-modal data. This modelcan be applied to various tasks to discover the nonlinear correlations and obtain the comparable low-dimensional representation for heterogeneous modalities.This kind of GPLVM-based metric learning model has a more flexible structure than the conventional metric models and is likely to receive increasing interest in the near future.
[1]G.Darnell,S.Georgiev,S.Mukherjee,B.E.Engelhardt,Adaptive randomized dimension reduction on massive data,arXiv preprint arXiv: 1504.03183.
[2]A.Sarveniazi,Am.J.Comput.Math.04(2)(2014)55-72.
[3]D.M.Blei,A.Y.Ng,M.I.Jordan,J.Mach.Learn.Res.3(2003) 993-1022.
[4]M.A.Carreira-Perpin,M.A.Carreira-Perpin,Perpinan(1997)1-69.
[5]S.T.Roweis,L.K.Saul,Science 290(5500)(2000)2323-2326.
[6]R.Urtasun,T.Darrell,Discriminative gaussian process latent variable model for classification,in:Proceedings of the 24th International Conference on Machine Learning,ICML’07,2007.
[7]X.Gao,X.Wang,D.Tao,X.Li,IEEE Trans.Syst.Man Cybern.Part B 41(2)(2011)425-434.
[8]X.Jiang,J.Gao,T.Wang,L.Zheng,IEEE Trans.Syst.Man Cybern.Part B 42(6)(2012)1620-1632.
[9]S.Eleftheriadis,O.Rudovic,M.Pantic,IEEE Trans.Image Process.24 (1)(2015)189-204.
[10]A.K.Jain,M.N.Murty,P.J.Flynn,ACM Comput.Surv.31(3)(1999) 264-323.
[11]J.A.Hartigan,M.A.Wong,Appl.Stat.28(1)(2013)100-108.
[12]M.M.Adankon,M.Cheriet,Support Vector Machine,Springer,US, 2015.
[13]S.C.Kothari,H.Oh,Neural Networks for Pattern Recognition,MIT Press,1993.
[14]C.M.Bishop,Pattern Recognition and Machine Learning(Information Science and Statistics),Springer-Verlag New York,Inc.,2006.
[15]N.Lawrence,J.Mach.Learn.Res.6(3)(2005)1783-1816.
[16]J.Philbin,J.Sivic,A.Zisserman,Int.J.Comput.Vis.95(2)(2011)138-153.
[17]B.Brosseau-Villeneuve,J.Y.Nie,N.Kando,Inf.Retr.17(1)(2014) 21-51.
[18]G.Hinton,L.Deng,D.Yu,G.E.Dahl,A.Mohamed,N.Jaitly,A.Senior, V.Vanhoucke,P.Nguyen,T.N.Sainath,IEEE Signal Process.Mag.29 (6)(2012)82-97.
[19]S.Maneeroj,A.Takasu,Hybrid recommender system using latent features,in:International Conference on Advanced Information NETWORKING and Applications Workshops,2009,pp.661-666.
[20]X.Y.Liu,Z.W.Liao,Z.S.Wang,W.F.Chen,Int.Conf.Mach.Learn. Cybern.(2006)4155-4159.
[21]A.M.Martínez,A.C.Kak,IEEE Trans.Pattern Anal.Mach.Intell.23(2) (2001)228-233.
[22]D.Petelin,Int.J.Neural Syst.14(6)(2006)3011-3015.
[23]R.Calandra,J.Peters,C.E.Rasmussen,M.P.Deisenroth,Manifold gaussian processes for regression,arXiv preprint arXiv:1402.5876.
[24]Z.Qiang,J.Ma,Automatic Model Selection of the Mixtures of Gaussian Processes for Regression,Springer International Publishing,2015.
[25]E.V.Bonilla,K.M.A.Chai,C.K.I.Williams,Multi-task gaussian process prediction,in:Conference on Neural Information Processing Systems, Vancouver,British Columbia,Canada,December,2007.
[26]H.C.Kim,J.Lee,Neural Comput.19(11)(2007)3088-3107.
[27]B.Abolhasanzadeh,Gaussian process latent variable model for dimensionality reduction in intrusion detection,in:ElectricalEngineering,2015.
[28]M.K.Titsias,N.D.Lawrence,Bayesian gaussian process latent variable model,in:Proceedings of the Thirteenth International Workshop on ArtificialIntelligence&Statistics Jmlr W&Cp,vol.9,2010,pp.844-851(9).
[29]S.Eleftheriadis,O.Rudovic,M.Pantic,Shared gaussian process latent variable model for multi-view facial expression recognition,in:International Symposium on Visual Computing,2013,pp.527-538.
[30]C.H.Ek,P.H.S.Torr,N.D.Lawrence,Gaussian process latent variable models for human pose estimation,in:Machine Learning for Multimodal Interaction,International Workshop,Mlmi 2007,Czech Republic,Brno, 2007,pp.132-143.June 28-30,2007,Revised Selected Papers.
[31]L.Cai,L.Huang,C.Liu,Multimedia Tools Appl.(2015)1-18.
[32]G.Song,S.Wang,Q.Huang,Q.Tian,Similarity gaussian process latent variable model for multi-modal data analysis,in:IEEE International Conference on Computer Vision,2015,pp.4050-4058.
[33]B.Schlkopf,A.Smola,K.Mller,NeuralComput.10(5)(1998)1299-1319.
[34]T.Cover,P.Hart,IEEE Trans.Inf.Theory 13(1)(1967)21-27.
[35]M.L.Zhang,Z.H.Zhou,Pattern Recognit.40(7)(2007)2038-2048.
[36]P.Hall,T.C.Hu,J.S.Marron,Ann.Stat.23(1)(1995)1-10.
[37]L.Devroye,A.Krzyak,Stat.Prob.Lett.44(3)(1999)299-308.
[38]F.Bohnert,I.Zukerman,D.F.Schmidt,Using gaussian spatial processes to modeland predictinterests in museum exhibits,in:The Workshop on Intelligent Techniques for Web Personalization&Recommender Systems,2009.
[39]W.Herlands,A.Wilson,H.Nickisch,S.Flaxman,D.Neill,W.V. Panhuis,E.Xing,Scalable gaussian processes for characterizing multidimensional change surfaces,arXiv preprint arXiv:1511.04408.
[40]A.Datta,S.Banerjee,A.O.Finley,A.E.Gelfand,J.Am.Stat.Assoc. (2015)(just-accepted).
[41]X.Wang,X.Gao,Y.Yuan,D.Tao,J.Li,Neurocomputing 73(10-12) (2010)2186-2195.
[42]C.Kang,S.Liao,Y.He,J.Wang,W.Niu,S.Xiang,C.Pan,Cross-modal similarity learning:a low rank bilinear formulation,in:Proceedings of the 24th ACM International on Conference on Information and Knowledge Management,CIKM’15,2015.
[43]N.D.Lawrence,A.J.Moore,Hierarchicalgaussian process latentvariable models,in:Machine Learning,Proceedings of the Twenty-Fourth International Conference,2007,pp.481-488.
[44]F.Yousefi,Z.Dai,C.H.Ek,N.Lawrence,Unsupervised learning with imbalanced data via structure consolidation latent variable model,arXiv preprint arXiv:1607.00067.
[45]E.Snelson,Z.Ghahramani,Adv.Neural Inf.Process.Syst.18(1)(2006) 1257-1264.
[46]E.Snelson,Z.Ghahramani,Local and global sparse gaussian process approximations,in:Proceedings of Artificial Intelligence and Statistics (AISTATS 2),2007,pp.524-531.
[47]T.V.Nguyen,E.V.Bonilla,Fastallocation of gaussian process experts,in: In International Conference on Machine Learning,2014.
[48]Y.Gal,M.V.D.Wilk,Variational inference in sparse gaussian process regression and latent variable models-a gentle tutorial,arXiv preprint arXiv:1402.1412.
[49]N.D.Lawrence,J.Mach.Learn.Res.2(2007)243-250.
[50]N.D.Lawrence,J.Qui~nonero Candela,Localdistance preservation in the gp-lvm through back constraints,in:Proceedings of the 23rd International Conference on Machine Learning,ICML'06,2006.
[51]S.J.Pan,Q.Yang,IEEETrans.Knowl.Data Eng.22(10)(2010)1345-1359.
[52]S.Roweis,Adv.Neural Inf.Process.Syst.10(1999)626-632.
[53]S.Yu,K.Yu,V.Tresp,H.P.Kriegel,M.Wu,Supervised probabilistic principal component analysis,in:Twelfth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Philadelphia, PA,USA,August,2006,pp.464-473.
[54]X.Gao,X.Wang,X.Li,D.Tao,Pattern Recognit.44(10-11)(2011) 2358-2366.
[55]Y.Fu,L.Wang,Y.Guo,Comput.Sci.12(7)(2014)717-729.
[56]P.Xie,E.P.Xing,Multi-modal distance metric learning,in:Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence,IJCAI'13,2013.
[57]T.Wang,S.Gong,X.Zhu,S.Wang,IEEE Trans.Pattern Anal.Mach. Intell.(2016),1-1.
[58]A.P.Shon,K.Grochow,A.Hertzmann,R.P.N.Rao,Adv.Neural Inf. Process.Syst.(2005)1233-1240.
[59]R.K.C.Fan,Spectralgraph theory,Published forthe Conference Board of the Mathematical Sciences by the American MathematicalSociety,1997.
[60]O.Stegle,C.Lippert,J.M.Mooij,N.D.Larence,K.Borgwardt,Adv. Neural Inf.Process.Syst.(2011)2011.
[61]F.Yan,Z.Xu,Y.A.Qi,Sparse matrix-variate gaussian process blockmodels for network modeling,arXiv preprint arXiv:1202.3769.
[62]O.Koyejo,C.Lee,J.Ghosh,Mach.Learn.97(1-2)(2014)103-127.
[63]O.Koyejo,L.Cheng,J.Ghosh,The trace norm constrained matrixvariate gaussian process for multitask bipartite ranking,arXiv preprint arXiv:1302.2576.
[64]N.Houlsby,J.M.Hernndez-Lobato,F.Huszr,Z.Ghahramani,Adv. Neural Inf.Process.Syst.3(2012)2096-2104.
[65]M.J.Wainwright,M.I.Jordan,Found.Trends Mach.Learn.1(12)(2010) 1-305.
[66]A.C.Damianou,M.K.Titsias,N.D.Lawrence,Variationalinference for uncertainty on the inputs of gaussian process models,arXiv preprint arXiv:1409.2287.
[67]R.Andrade Pacheco,J.Hensman,M.Zwiessele,N.Lawrence,Hybrid discriminative-generative approach with gaussian processes,in:Proceedings of the Thirteenth International Workshop on Artificial Intelligence&Statistics Jmlr W&Cp,2014,pp.47-56.
[68]J.M.Wang,D.J.Fleet,A.Hertzmann,Gaussian process dynamical models,in:In NIPS,MIT Press,2006,pp.1441-1448.
[69]J.M.Wang,D.J.Fleet,A.Hertzmann,IEEE Trans.Pattern Anal Mach. Intell.30(2)(2008)283-298.
[70]A.C.Damianou,M.K.Titsias,N.D.Lawrence,Variational gaussian process dynamical systems,in:Advances in Neural Information Processing System,IEEE Conf.Publications,2011,pp.2510-2518.
[71]H.Xiong,T.Liu,D.Tao,H.Shen,IEEE Trans.Image Process.25(8) (2016),1-1.
[72]Z.Dai,A.Damianou,J.Gonzlez,N.Lawrence,Comput.Sci.14(9) (2015)3942-3951.
[73]Y.Bengio,Found.Trends Mach.Learn.2(1)(2009)1-127.
[74]G.E.Hinton,Scholarpedia 4(6)(2009)786-804.
[75]J.Masci,U.Meier,J.Schmidhuber,Stacked convolutionalauto-encoders for hierarchical feature extraction,in:In International Conference on Artificial Neural Networks,2011.
[76]A.C.Damianou,N.D.Lawrence,Comput.Sci.(2012)207-215.
[77]T.D.Bui,D.Hernndezlobato,Y.Li,J.M.Hernndezlobato,R.E.Turner, Deep gaussian processes for regression using approximate expectation propagation,arXiv preprint arXiv:1602.04133.
[78]Y.Gal,Y.Chen,Z.Ghahramani,Statistics(2015)645-654.

Ping Lireceived his B.S.and M.S.degree in Management Science&Engineering from Anhui University of Technology in 2011 and 2014.He is currently pursuing the Ph.D.degree with the College of Computer Science&Technology,Nanjing University of Aeronautics and Astronautics.Her research interests include pattern recognition and machine learning.

Songcan Chenreceived his B.S.degree in mathematics from Hangzhou University(now merged into Zhejiang University)in 1983.In 1985,he completed his M.S.degree in computer applications at Shanghai Jiaotong University and then worked at NUAA in January 1986.There he received a Ph.D.degree in communication and information systems in 1997. Since 1998,as a full-time professor,he has been with the College of Computer Science&Technology at NUAA.His research interests include pattern recognition,machine learning and neural computing.
Available online 14 November 2016
*Corresponding author.
E-mail addresses:ping.li.nj@nuaa.edu.cn(P.Li),s.chen@nuaa.edu.cn(S. Chen).
Peer review under responsibility of Chongqing University of Technology.
http://dx.doi.org/10.1016/j.trit.2016.11.004
2468-2322/Copyright©2016,Chongqing University of Technology.Production and hosting by Elsevier B.V.This is an open access article under the CC BY-NCND license(http://creativecommons.org/licenses/by-nc-nd/4.0/).
Copyright©2016,Chongqing University of Technology.Production and hosting by Elsevier B.V.This is an open access article under the CC BY-NC-ND license(http://creativecommons.org/licenses/by-nc-nd/4.0/).
猜你喜欢
潍坊学院学报(2020年2期)2021-01-18
作文成功之路·小学版(2020年3期)2020-04-21
活力(2019年19期)2020-01-06
时代人物(2019年29期)2019-11-25
四川省干部函授学院学报(2019年2期)2019-08-27
活力(2019年22期)2019-03-16
商周刊(2019年1期)2019-01-31
百科探秘·航空航天(2018年12期)2018-12-29
军事文摘(2018年22期)2018-11-21
太原城市职业技术学院学报(2014年7期)2014-02-27
 CAAI Transactions on Intelligence Technology2016年4期
CAAI Transactions on Intelligence Technology2016年4期
- CAAI Transactions on Intelligence Technology的其它文章
- Social network search based on semantic analysis and learning
- Recent Advances on Human-Computer Dialogue
- Building a click model:From idea to practice
- A survey on rough set theory and its applications
- Evolutionary computation in China:A literature survey
- Research progress of artificial psychology and artificial emotion in China