
基于粗糙集的海量数据挖掘算法研究
2016-07-09 15:39牛咏梅
现代电子技术 2016年7期
牛咏梅
摘 要: 针对传统数据挖掘算法在数据量级方面的局限性,提出在粗糙集理论的基础上,采用类分布链表结构改进传统的基于属性重要性的数据离散化算法、属性约简算法以及基于启发式的值约简算法。讨论了基于动态聚类的两步离散化算法,当算法适应大数据处理之后,采用并行计算的方法提高算法的执行效率。算法测试结果表明,改进算法能有效地处理大数据量,同时并行计算解决了大数据量处理带来的效率问题。
关键词: 数据挖掘; 粗糙集; 大数据处理; 并行计算
中图分类号: TN911?34; TQ028.1 文献标识码: A 文章编号: 1004?373X(2016)07?0115?05
Abstract: Since the traditional data mining algorithm has the limitation in the aspect of data magnitude, on the basis of rough set theory, the class distribution list structure is used to improve the traditional data discretization algorithm based on attribute importance, attribute reduction algorithm and heuristic?based value reduction algorithm. The two?step discrete algorithm based on dynamic clustering is discussed. When the algorithm adapts to the big data processing, the parallel computing method is used to improve the execution efficiency of the algorithm. The test results of the algorithm show that the improved algorithm can effectively process the big data size. The parallel computing can solve the efficiency problem causing by big data size processing.
Keywords: data mining; rough set; big data processing; parallel computing
0 引 言
信息时代,数据(尤其是海量数据)已被各企业、各研究机构当成重大的知识来源、决策的重要依据[1],对于数据的急速增长,如何有效地解决数据挖掘过程中空间和时间的可伸缩性已经成为数据挖掘领域中迫切需要解决的难题[2]。从知识发现的过程中可以看到,数据挖掘不仅面临着数据库中的庞大数据问题[3],而且这些数据有可能是不整齐的、不完全的、随机的、有噪声的、复杂的数据结构且维数大[4]。传统的数据挖掘算法还限制于单机内存的容量[5],当一次性需要分析的数据不能全部进入内存时,算法的性能就会严重降低[6],甚至得不到预期的结果,使用基于粗糙集理论的算法策略将有效解决这个问题[7]。
本文针对传统数据挖掘算法在数据量级方面的局限性,提出了结合类分布链表,把数据挖掘算法推广到可以处理更高数据量级,最后采用并行计算的方法提高基于动态聚类的两步离散化算法适应大数据处理之后的执行效率。
1 改进的Rough Set知识约简算法
许多经典的Rough Set知识约简算法都可以通过引进CDL(类分布链表)改进,CDL可以反映某个条件属性组合对论域的分类情况。CDL分为不相容类分布链表(ICDL)和相容类分布链表(CCDL)两部分,CCDL根据链表中每个分类的样本数目又可分为单例相容类分布链表(SSCDL)和多例相容类分布链表(MSCDL)[7]。引进CDL后相对于原始的经典算法,改进后的算法将具有更好的可伸缩性,能够更好地处理海量数据集。以下通过引入CDL对包括离散化、属性约简和值约简的一组Rough Set知识约简算法进行改进。
1.1 改进的离散化算法
数据离散化是Rough Set知识获取方法中的重要组成部分。在此采用基于属性重要性的离散化算法,在原算法的基础上通过引入CDL,使得该算法能够处理海量数据。
算法1.1 基于属性重要性的离散化算法
算法输入:一个完备的决策表信息系统DT
算法输出:离散化后的决策表信息系统DT
算法步骤如下:
(1) 循环遍历每一个连续的条件属性,并且通过生成[ICDLai]计算属性[ai]的条件信息熵。
(2) 根据条件信息熵降序排序,排列所有连续的条件属性。
(3) 针对排序后的DT,循环遍历每一个连续的条件属性[ai,]生成[ICDLC\ai;]设置[Szone=null,]其中[Szone]是属性[ai]的值域的一个子集。
(4) 循环遍历区间[Sa,Sb]上的每一个断点。其中[Sa]和[Sb]是属性[ai]上两个连续的属性值;令[Szone=Szone+Sa。]
(5) 循环遍历DT中满足[SVjai=Sh]的每个样本[SVj,]其中[Sh∈Szone。]
(6) 循环遍历DT中满足[SVkai=Sb]的每个样本[SVk;]如果样本[SVj]和[SVk]出现在[ICDLai]中的同一个条件分类中而且它们之间存在符号“@”,则选择[Sa,Sb]的断点,并把 [Szone]重新置为空。
1.2 改进的属性约简算法
使用基于信息熵的CEBARKNC算法。根据类分布链表求取条件信息熵的方法[8],通过某个条件属性组合的ICDL很容易求得决策属性相对于该条件属性组合的条件信息熵。因此可以通过ICDL改进CEBARKNC算法的可伸缩性,改进的算法与原算法在计算信息熵的过程不一样。
1.3 改进的值约简算法
在此改进启发式值约简算法,该算法在原算法的基础上加上CDL,使得该算法能够处理海量数据。原算法在执行第一步的时候按照[CDL(a)]中的三部分更新决策表S。
(1) 把[SSCDL(a)]中的样本在属性[a]上的值标记为“?”;
(2) 把[MSCDL(a)]中的样本在属性[a]上的值标记为“*”;
(3) [ICDL(a)]中的样本在属性[a]上的值不变。
由(3)可知[ICDL(a)]中的样本不需要处理,而在处理[SSCDL(a)]和[MSCDL(a)]的样本时,不把生成实际的链表放在内存中处理而是直接在数据库中进行处理。具体的算法描述如下:
算法1.2 改进启发式值约简算法
输入:一个完备的离散的决策表信息系统DT
输出:规则集RT
假设样本标号为Index,决策属性为DA,条件属性集合[C,]则算法步骤如下:
(1) 把RT初始化为DT。
(2) 循环遍历每一个条件属性[ai,]把[SSCDL(ai)]中的所有样本在[ai]上的属性值标记为“?”。
(3) 把[MSCDL(ai)]中的所有样本在[ai]上的属性值标记为“*”。此外剩下的样本都在[ICDL(ai)]中,它们在[ai]上的属性值不需要改变。
(4) 接下的操作步骤与原始的值约简算法相同。
2 基于动态聚类的两步离散化算法的并行化
基于动态聚类的两步离散化算法的第一步是利用动态聚类算法对决策表第一次进行离散化,然后利用断点重要性离散化算法进行再次离散化,从而得到最终的断点集。
算法2.1 基于动态聚类的离散化算法
输入:决策表[S=
输出:决策表[S]首次筛选后的断点集[CUTfirst]循环遍历[S]的每一个条件属性[k,]执行以下步骤:
(1) 计算属性[k]每一断点的重要性,并按断点值从小到大排序,计算结果保存在数组[Importantk[]]中,数组的索引[m]表示最重要的断点在数组中的位置,即:
决策表经过上述的算法离散化之后,其效果仅相当于基于属性重要性离散化算法的局部离散化效果。下面通过把断点集[CUTfirst]输入到断点重要性算法中进行一次全局离散化便得到基于动态聚类的两步离散化算法。
算法2.3对算法2.2进行了并行化处理,得到的离散化结果与算法2.2是一致的,但算法2.3带来的好处是提高了离散化算法的运行效率。
3 算法测试
3.1 改进的Rough Set知识约简算法测试
3.1.1 算法正确性测试
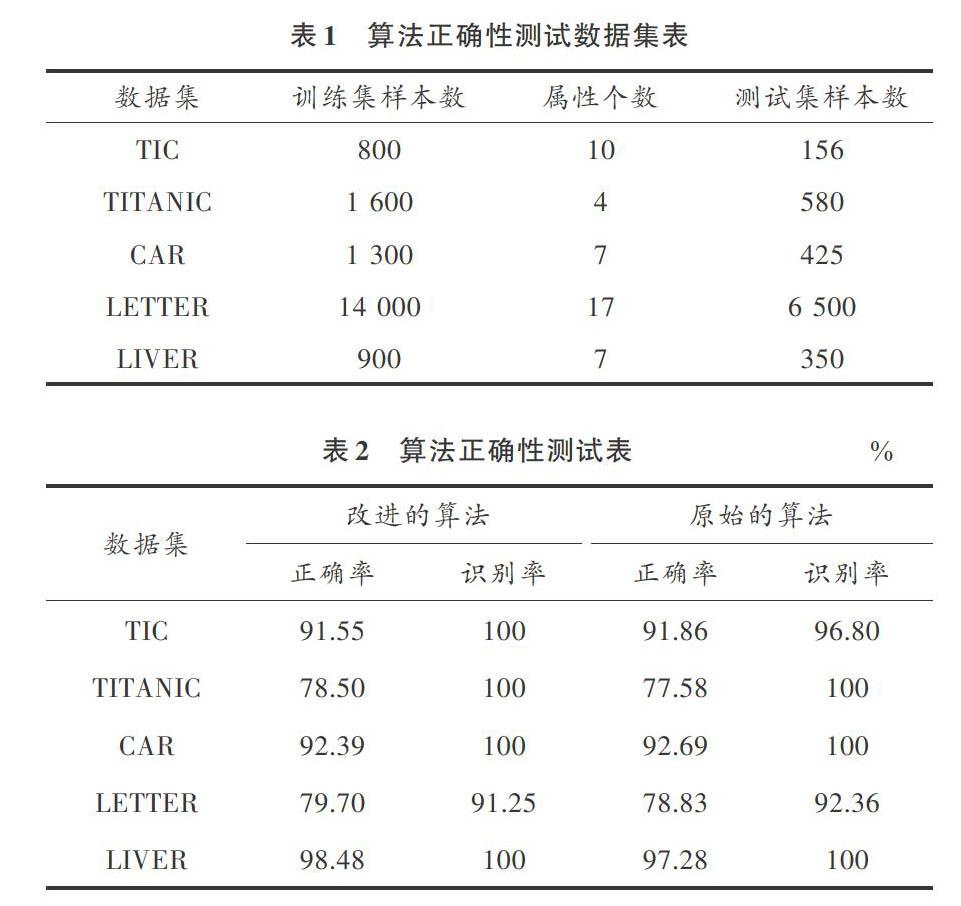
选择UCI数据库中的5个数据集(见表1)来比较经过CDL改进的知识约简算法与原始经典Rough Set算法的正确性,双方都应用了相同的算法组合。比较的结果见表2,从结果中可得出:使用经过CDL改造后的知识约简算法不影响原始的经典Rough Set算法的正确率及识别率等性能。
3.2 基于动态聚类的两步离散化算法的并行化处理算法测试
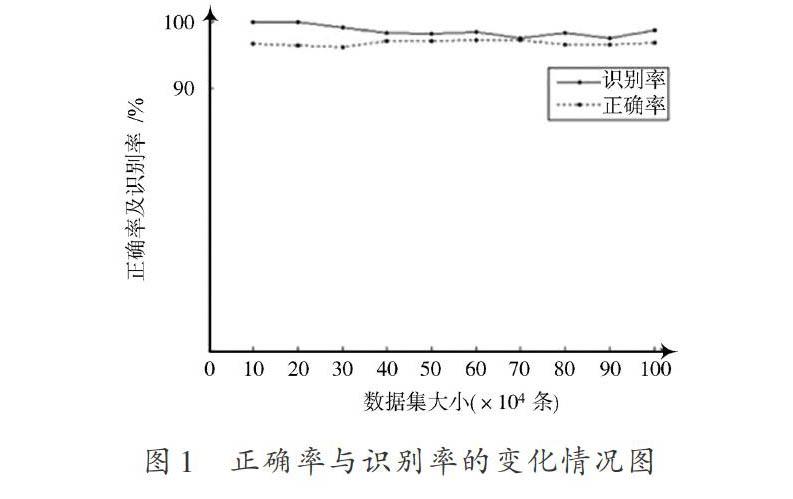
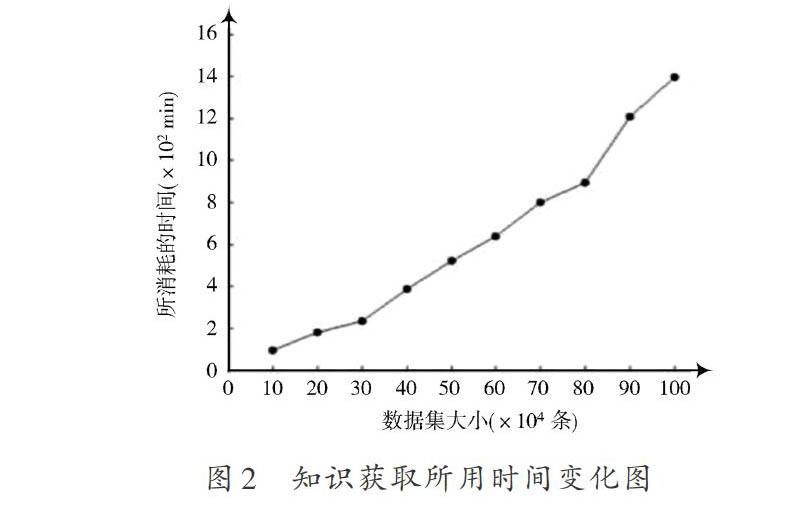
从UCI数据库中选取6组数据集对算法2.2进行测试。表3是实验使用的数据集。表4,表5展示了基于动态聚类的离散化算法、基于动态聚类的两步离散化算法、贪心算法、基于断点重要性的离散化算法等5种算法的运算对比结果。其中,算法的运行时间用符号[T]表示,规则集的正确识别率用符号[P]表示。
4 结 论
从目前常用的数据挖掘算法出发,采用类分布链表来改进传统的数据挖掘算法,使该算法能直接处理海量数据集,实现处理超大规模数据集的目标。系统采用并行计算的核心思想,基于动态聚类的并行离散化算法,提出分布确定类分布链表的方法,有效解决了系统内存限制的问题。同时,提高了基于动态聚类的两步离散化算法的运行效率。
参考文献
[1] 黄朝辉.基于变精度粗糙集的数据挖掘方法研究[J].赤峰学院学报(自然科学版),2014(8):3?4.
[2] 要照华,闫宏印.基于粗糙集的海量数据挖掘[J].机械管理开发,2010,25(1):17?18.
[3] 石凯.基于粗糙集理论的属性约简与决策树分类算法研究[D].大连:大连海事大学,2014:22?25.
[4] 刘华元,袁琴琴,王保保.并行数据挖掘算法综述[J].电子科技,2006(1):65?68.
[5] 陈贞,邢笑雪.粗糙集连续属性离散化的K均值方法[J].辽宁工程技术大学学报,2015(5):642?646.
[6] CORNELIS C, KRYSZKIEWICZ M, SLEZAK D, et al. Rough sets and current trends in soft computing [M]. Berlin: Springer, 2014: 11?15.
[7] 刘建.并行程序设计方法学[M].武汉:华中科技大学出版社,2000:11?13.
[8] 陈小燕.机器学习算法在数据挖掘中的应用[J].现代电子技术,2015,38(20):11?14.
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06
大众投资指南(2021年35期)2021-02-16
电力与能源(2017年6期)2017-05-14
科学与财富(2016年15期)2016-11-24
大经贸(2016年9期)2016-11-16
厦门理工学院学报(2016年3期)2016-11-10
中国新通信(2016年16期)2016-10-18
科技视界(2016年11期)2016-05-23
广东石油化工学院学报(2016年3期)2016-05-17
信息通信技术(2015年6期)2015-12-26
