
复杂网络K-紧密概率属性子图高效挖掘算法
2016-08-05 07:39刘凤春王立亚刘保相
湖南师范大学自然科学学报 2016年4期
关键词:复杂网络
刘凤春,王立亚,刘保相
(华北理工大学理学院,中国 唐山 063009)
复杂网络K-紧密概率属性子图高效挖掘算法
刘凤春,王立亚,刘保相
(华北理工大学理学院,中国 唐山063009)
摘要针对复杂网络中节点和边及其属性值均可能存在不确定性的实际,以及采用传统的紧密子图挖掘算法挖掘出的紧密子图实际上并不一定紧密的问题,在已提出的概率属性图基础上,提出紧密概率属性子图的概念,将其分为紧密概率I型属性子图和紧密概率II型属性子图,并用期望紧密度对其进行度量,同时给出了相应的紧密子图判定定理;进一步提出K-紧密概率属性子图高效挖掘算法,以快速发现复杂网络中联系紧密且顶点和边的存在概率最高的K个子图;最后通过蛋白质网络和虚拟网络中的数据对算法进行了模拟实验,验证了算法在不同大小的复杂网络中具有较好的适应性及较高的挖掘效率.
关键词复杂网络;K-紧密子图;概率属性图;图挖掘
无论是生物网络、社会网络还是无线传感网络等复杂网络,顶点和边及其属性的存在性在现实中往往并不明确,它们通常都以一定的概率存在或关联[1-2].概率图是在传统图基础上考虑边的不确定性而提出来的,目前的研究主要是基于概率图模型计算可靠子图[3]、挖掘子图模式[4-5]、子图查询[6-8]、不确定推理等,这些研究只关注到结点之间关系的不确定性,而并未考虑到边和结点的属性特征以及这些属性的不确定性.所以,单单依靠概率图同样无法全面描述复杂网络的结点和边的属性及其不确定性.
实际上,以图模型描述的数据对象中,结点和边的属性值与边的存在性一样,通常在一定值域内满足某种概率分布.基于此,作者在文[9]中提出了概率属性图,同时考虑顶点、边以及它们的属性的概率性.然而,概率属性图的研究工作刚刚开始,远远不能满足实际应用中的广泛需求.

图1 在不确定图中发现紧密子图Fig.1 Finding dense subgraph in uncertain graph
在社会网络[10]中寻找交流频繁的群体可帮助广告商更有效地投放发布信息,具有重要的商业价值[11].在蛋白质交互网络中,发现重要的功能团同样有重要的应用价值[12].在传统的不确定图中,一类重要问题是发现顶点联系密切的紧密子图[13-15],基本定义是在图G中发现子图g,使g的稠密度即边个数除以点个数的值最高.如图1所示.
子图Ⅰ(a,b,c,d,e,g)6个顶点间共有9条边,其稠密度为9/6,是整个图中最稠密的子图.但是,当图存在边不确定性时,如图1中的边(a,b)和(b,c),虽然有边相连,但其存在概率仅为0.1,实际连通关系并不明显.这样的稠密度无法表示子图内各顶点的紧密情况.只有当整个子图内各点都以较高概率连通时,如图1中的子图Ⅱ,该子图才是概率图中真正的紧密子图,也才在概率图中更有实际意义.
同样,在概率属性图中,不仅仅存在边不确定性,顶点也可能存在不确定性,如此,即使边的存在概率很高,而顶点存在概率很低的话,则该子图的稠密度仅依赖前面的定义也不能完全表达.只有当顶点和边的存在概率都很高时,才是真正意义上的紧密子图,如图1中的子图Ⅲ.
由于概率属性图中蕴含着丰富的属性及结构信息,以致对紧密子图特性进行评价和度量的模型非常复杂,如果使用可能世界模型,一个仅有10个顶点50条边的概率Ⅰ型属性图,其蕴含的可能属性图实例将达到210×250个之多.除此之外,复杂网络抽象出的图通常具有成千上万甚至更多的顶点,这使问题更加难于处理,而原用于传统图和概率图上发现紧密子图的方法不能直接适用于概率属性图.因此,如何有效地在概率属性图上发现紧密子图,具有非常重要的实际意义.
本文在无向概率属性图上分析与讨论,但只需对不同方向的边加以标识并分别计算,即可将本文方法扩至有向的概率属性图中使用.
1概率属性图
在复杂网络中,由于数据的庞大,结点数据的不确定性问题也会存在,关于结点和关系以及它们的属性值都有可能是不确定的.因而作者在文[9]中给出了概率属性图的概念及其结构,由概率Ⅰ型属性图和概率Ⅱ型属性图构成.
1.1概率Ⅰ型属性图
在复杂网络图中,当顶点和边的属性值确定的情况下,考虑顶点或边的不确定性,分别给出边概率属性图和顶点概率属性图.
定义1一个边概率属性图定义成一个二元组GAE=((V(VA,LV),E(EA,LE)),PE).
其中,(V(VA,LV),E(EA,LE))是一个属性图,PE:E→(0,1]是边的概率函数,∀e∈E,P(e)表示边e存在的概率.即,边是以一定概率出现的,边的属性及顶点和它的属性是确定的.
定义2一个顶点概率属性图定义成一个二元组GAV=((V(VA,LV),E(EA,LE)),PV).
其中(V(VA,LV),E(EA,LE))是一个属性图,PV:V→(0,1]是顶点的概率函数,∀v∈V,P(v)表示v存在的概率.即,顶点是以一定概率出现的,顶点的属性和边及它的属性是确定的.
定义3三元组GAⅠ=((V(VA,LV),E(EA,LE)),PE,PV)其中,(V(VA,LV),E(EA,LE))是一个属性图,PE:E→(0,1]是边的概率函数,PV:V→(0,1]是顶点的概率函数,则称这个三元组为概率Ⅰ型属性图.
在社会网络中,社会成员之间的关系呈现出概率Ⅰ型属性图的形式,比如在社会网络中,每个成员对朋友的要求不同,这些要求就是顶点的属性,关系就是朋友.按照每个成员的要求类型,成员存在的概率就是顶点的概率;若这样的成员存在,在社会网络中成为朋友的可能性是不确定的,即边的存在是以一定概率形式出现的.
1.2概率Ⅱ型属性图
针对顶点或边的属性值的不确定性,来讨论属性图的不确定,分为顶点属性级概率属性图和边属性级概率属性图以及二者同时包含不确定的概率属性图.
定义4顶点属性概率属性图定义成一个二元组GAVA=((V(VA,LV),E(EA,LE)),PVA).
其中,(V(VA,LV),E(EA,LE))是一个属性图,PVA:VA→(0,1]是顶点属性的概率函数集合,对应顶点的每个不确定属性值的概率.即,顶点的某些属性值是以一定概率出现的,而边及其属性是确定的.
定义5边属性概率属性图定义成一个二元组GAEA=((V(VA,LV),E(EA,LE)),PEA).
其中,(V(VA,LV),E(EA,LE))是一个属性图,PEA:EA→(0,1]是边属性值的概率函数.即,边的属性值是以一定概率出现的,边和顶点及它的属性是确定的.
定义6概率Ⅱ型属性图定义为一个三元组GAⅡ=((V(VA,LV),E(EA,LE)),PEA,PVA).
其中,(V(VA,LV),E(EA,LE))是一个属性图,PEA:EA→(0,1]是边属性的概率函数,PVA:VA→(0,1]是顶点属性的概率函数.
概率Ⅱ型属性图强调的是边和顶点的属性值的不确定性,概率函数是相互独立的.
1.3概率属性图
定义7概率Ⅰ型属性图和概率Ⅱ型属性图统称为概率属性图,记为GAP=((V(VA,LV),E(EA,LE)),P).
其中,(V(VA,LV),E(EA,LE))表示属性图,P是边、顶点及它们属性的概率函数.P=PE∪PV∪PEA∪PVA,且PE:E→(0,1],PV:V→(0,1],PEA:EA→(0,1],PVA:VA→(0,1].
性质1当P=1时,即PE=1,PV=1,PEA=1,PVA=1,则概率属性图GAP=((V(VA,LV),E(EA,LE)),P)退化成属性图.
性质2当P≠1时,但PE=1,PV=1 ,则概率属性图GAP=((V(VA,LV),E(EA,LE)),P)退化成概率Ⅱ型属性图.
性质3当P≠1时,但PEA=1,PVA=1,则概率属性图GAP=((V(VA,LV),E(EA,LE)),P)退化成概率Ⅰ型属性图.
结论1概率属性图是属性图的推广,属性图是概率属性图的特例.
2概率属性图的K-紧密子图
2.1K-紧密概率Ⅰ型属性子图
在概率Ⅰ型属性图中,由于顶点和边都是以概率的形式存在,判断子图的稠密程度,只有通过子图内顶点与其连接的边乘积的期望和与顶点个数的比才能体现子图内顶点间的相互连通状况.
定义8给定概率Ⅰ型属性图GAⅠ,gaⅠ是GAⅠ的子图,定义期望紧密度函数(expectdensityfunction)为:

(1)
子图在期望紧密度函数下对应的函数值就是期望紧密度,用ExDegree来表示,在概率Ⅰ型属性图GAⅠ中,期望紧密度最高的子图gaⅠM成为最紧密子图.
定理1给定概率Ⅰ型属性图GAⅠ,子图最小限制阈值s,在GAⅠ中发现最紧密子图是一个NP-Hard问题.
证在确定属性图上发现不小于m的稠密子图(Dalms)问题具有NP-Hard复杂性,对于确定属性图GA上的任意实例图〈GA,m〉,可在多项式时间内归结至概率Ⅰ型属性图GAⅠ紧密子图发现实例〈GAⅠ,s〉.Dalms问题是在确定图中发现大小至少包含m个顶点的最稠密子图,与Dalms问题任一实例〈GA,m〉对应点实例〈GAⅠ,s〉的构造过程非常容易,只需令m=s,且GAⅠ=((V(VA,LV),E(EA,LE)),PE,PV)中每条边e∈E,每个顶点v∈V,如果PE=1,PV=1,则GA中Dalms问题的一个解当且仅当其是GAⅠ的最紧密子图,归约成立,定理得证.
由定理1,概率Ⅰ型属性图获取至少包含s个顶点的最紧密子图是NP完全问题.
定义9给定概率Ⅰ型属性图GAⅠ,对于GAⅠ中期望紧密度函数值最高的子图gaⅠM,其期望紧密度为TM,则gaⅠC为紧密子图,当且仅当:
gaⅠM⊆GAⅠ,E(gaⅠM)=TM,
∀gaⅠ⊆GAⅠ,E(gaⅠ)=T≤TM,


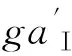
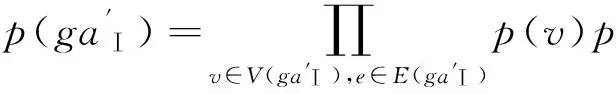
(2)
证P是概率Ⅰ型属性图GAⅠ的概率分布,则:
(3)
其中gaⅠ k是概率Ⅰ型属性图中的第k个可能实例图,其存在概率为:
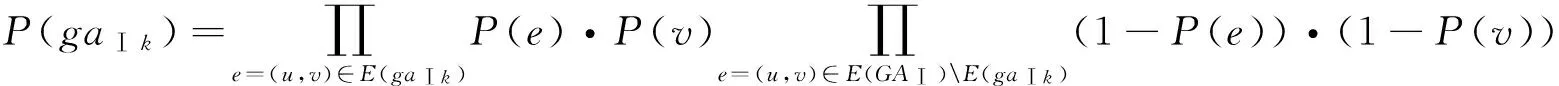


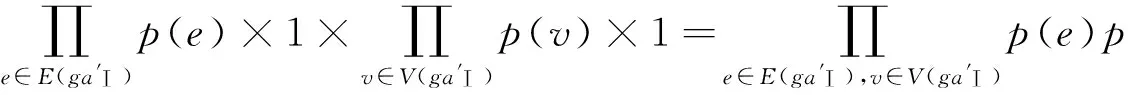
推论1在紧密子图边数和顶点数确定的条件下,期望紧密子图函数的值越大,则该子图的存在概率越大.
2.2K-紧密概率Ⅱ型属性子图
与概率Ⅰ型属性图不同的是这里强调的是顶点和边的属性的不确定性,所以在概率Ⅱ型属性图中,定义子图的期望紧密度函数时有所不同.

定义10给定概率Ⅱ型属性图GAⅡ,gaⅡ是GAⅡ的子图,期望紧密度函数(expectdensityfunction)为:

其中S为子图gaⅡ中可能拥有的顶点个数;w,t为其可能存在的顶点或边;而P(w),P(t)为其存在概率.
子图在期望紧密度函数下对应点函数值就是期望紧密度,用ExDegree来表示,在概率Ⅱ型属性图GAⅡ中,期望紧密度最高的子图gaⅡM成为最紧密子图.
定理3给定概率Ⅱ型属性图GAⅡ,子图最小限制阈值s,在GAⅡ中发现最紧密子图是一个NP-Hard问题.
显然,这是个完全NP问题,在此证明略.
定义11给定概率Ⅱ型属性图,对于中期望紧密度函数值最高的子图gaⅡM,其期望紧密度为TM,则gaⅡC为期望紧密子图,当且仅当:
gaⅡM⊆GAⅡ,E(gaⅡM)=TM,
∀gaⅡ⊆GAⅡ,E(gaⅡ)=T≤TM,

2.3K-紧密概率属性子图
概率属性图是概率Ⅰ型属性图和概率Ⅱ型属性图的综合,所以概率属性图关于期望紧密子图的定义也由概率Ⅰ型属性图和概率Ⅱ型属性图综合得到.
定义12给定概率属性图GAP,gap是GAP的子图,期望紧密度函数(expectdensityfunction)为:

子图在期望紧密度函数下对应点函数值就是期望紧密度,用ExDegree来表示,在概率属性图GAP中,期望紧密度最高的子图gapM成为最紧密子图.
定理4给定概率属性图GAP,子图最小限制阈值s,在GAP中发现最紧密子图是一个NP-Hard问题.
定义13给定概率属性图GAP,对于GAP中期望紧密度函数值最高的子图gapM,其期望紧密度为TM,则gapC为期望紧密子图,当且仅当:
gapM⊆GAP,E(gaPM)=TM,
∀gap⊆GAP,E(gap)=T≤TM,

即期望紧密子图为不确定属性图GAP中期望紧密度不小于TM/δ(δ为大于1的整数),且存在概率大于0的顶点个数不小于s的子图.
本文使用期望紧密度函数衡量子图中顶点的紧密程度,在给定的概率属性图GAP中,发现子图中期望紧密度函数值不小于G的最紧密子图函数值的1/δ,且不重叠的子图中存在概率最高的K个子图.
3K-紧密概率属性子图挖掘算法
3.1算法描述
对概率属性图进行紧密子图的挖掘,快速估计概率属性图中最高期望紧密度.算法返回概率属性图中最坏情况下期望紧密函数值不小于最紧密子图1/2的子图,由该子图可以确定挖掘紧密子图的期望紧密函数值的阈值.算法描述如下:
输入:不确定属性图GAP,不小于1的整数s,δ,K.
输出:GAP中不小于最紧密子图期望紧密度1/δ,不小于s的子图中存在概率最大的K个子图.
(1)初始化图队列Ran,使Ran[n]=GAP.
(2) 计算Ran[n]中每个顶点和边的概率,找到边与顶点概率乘积之和最小的顶点v,删除v及其所有边,存储至Ran[n-1]中.
(3) 重复运行步骤(2),直到Ran队列头存储的图大小至2为止,则Ran中存储了大小为n, n-1,…,2的最紧密子图.
(4) 计算Ran中每个子图的期望紧密度函数值,找出期望紧密度最高的子图MaxC,并将其期望紧密度函数值作为紧密度阈值ET*.

(6) 输出结果中存在概率最高的K个,算法结束.

3.2实验模拟与分析
利用多组实验考察算法的效率,以及不同数据和算法在不同参数影响下算法的性能和结果质量.由于至今未见概率属性图中K紧密子图发现问题的相关算法,其他问题及确定图上的算法与本文所解决问题缺乏可比性,实验主要验证理论分析的结果及文中所提出算法的执行效率.
本文利用蛋白质交互网络的4组真实数据[13]及两组模拟数据进行实验,如表1所示.算法的目标就是快速发现联系紧密且顶点和边的存在概率最高的K个子图.

表1 用于性能评价的图数据
运行算法,计算得出各图的期望紧密函数值,结果如图2所示.不同网络中最紧密子图的近似度事实上因图数据的不同会有很大差别,由此可以发现,只有根据不同网络环境设定紧密阈值,才能有效获得适合网络的紧密子图.图3是算法在不同图上的运行时间,易见图大小和紧密度的增加会使运行时间显著增加.
图4为在同一图数据δ=3条件下,最小子图参数s对算法运行时间的影响.当s增大时,运行时间显著增加.图5为s=6时,参数δ对算法运行时间的影响.可见δ越小,算法运行时间越长.
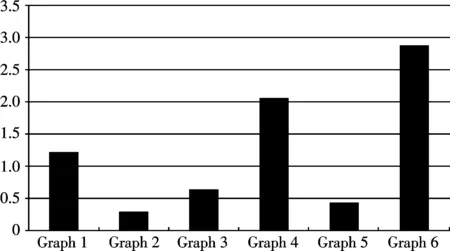
图2 各图的期望紧密函数值Fig.2 Expected dense function value of each graph
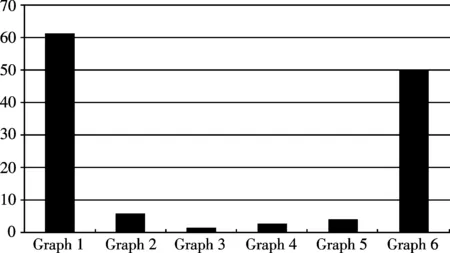
图3 不同的图算法运行时间Fig.3 Running time of different graph algorithm

图4 参数s对算法运行时间的影响Fig.4 Influence of s on running time

图5 参数δ对算法运行时间的影响Fig.5 Influence of δ on running time
综上,本文通过实验验证了算法可以快速获得概率属性图中近似最紧密子图的基本信息,随着顶点和边个数的增加,算法具有较好的适用性.
4结束语
本文研究了在概率属性图的中发现K紧密子图的问题,并证明无论是概率Ⅰ型属性子图还是概率Ⅱ型属性子图的发现均具有NP-Hard的复杂性.给出了概率属性子图和K紧密子图的概念,并提出了基于期望子图密度函数的K紧密子图发现算法,实验结果表明该算法可以有效完成所需任务,具有重要的实际意义.
参考文献:
[1]CONTE D, FOGGIA P, SANSONE C,etal. Thirty years of graph matching in pattern recognition[J].Int J Pattern Recog Artif Intel, 2004,18(3):256-298.
[2]JORDAN M I. Graphical models (special issue on Bayesian statistics)[J]. Stat Sci, 2004,19(3):140-155.
[3]HAN M, ZHANG W, LI J Z. Ranking: an efficient algorithm for mining maximum frequent patterns in uncertain graph[J].J Comput, 2010,33(8):1387-1395.
[4]ZOU Z N, LI J Z, GAO H,etal. Mining frequent subgraph patterns from uncertain graph[J].J Softw, 2009,20(11):2965-2976.
[5]ZOU Z N, LI J Z, GAO H,etal. Mining frequent subgraph patterns from uncertain graph data[J]. IEEE Trans Know Data Eng, 2010,22(9):1203-1218.
[6]LI W F, PENG Z Y, LI D Y. Uncertainty over the top-kquery processing[J].J Softw, 2012,23(6):1542-1560.
[7]ZHANG S, GAO H, LI J Z. Efficient query processing in uncertain graph database[J].J Comput, 2009,32(10):2066-2079.
[8]YUAN Y, WANG G R. The probability query for uncertain graph[J].J Comput, 2010,33(8):1378-1386.
[9]ZHANG C Y, ZHANG X. Uncertain attribute graph model of web social network and its application[C]//8th International Conference on Computer Science & Education, Colombo, Sri Lanka, April 2013.
[10]LAPPAS T, TEIZI E, GUNOPULOS D. Finding effectors in social networks[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’10). New York, USA: ACM, 2010:1059-1068.
[11]ROTH M, BEN A D, DEUTSCHER D,etal. Suggesting friends using the implicit social graph[C]//Proceedings of the 16th ACM ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’10).New York, USA: ACM, 2010:233-242.
[12]GAO J, LIANG F, FAN W,etal. On community outliers and their efficient detection in information networks[C]//Proceedings of the 16th ACM ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(KDD’10),New York, USA:ACM, 2010:813-822.
[13]HAN M, LI J Z, ZOU Z N. Finding K closely subgraph from uncertain graph[J].Comput Sci Explor, 2011,5(9):791-803.
[14]ZHANG X, HE X N, JIN C Q,etal.KNearest neighbor query for uncertain graph[J]. Comput Res Develop, 2011,48(10):1871-1878.
[15]ZHANG Y L, LI C P, CHEN H,etal. Query processing in uncertain graph[J].Comput Res Develop, 2011,48(10):1850-1858.
(编辑CXM)
DOI:10.7612/j.issn.1000-2537.2016.04.010
收稿日期:2016-01-12
基金项目:国家自然科学基金资助项目(61370168,61472340);湖北省科技厅条件建设项目(149601121)
*通讯作者,E-mail:122314110@qq.com
中图分类号TP391
文献标识码A
文章编号1000-2537(2016)04-0059-07
Efficient Mining Algorithm of K-densely Probability Attribute Sub-graph in Complicated Network
LIUFeng-chun,WANGLi-ya,LIUBao-xiang*
(College of Science, North China University of Science and Technology, Tangshan 063009, China)
AbstractIn complicated networks,the uncertainty of edge, vertex and its attributesexist, and the dense sub-graph mining by the traditional algorithm may be not dense. So the dense probability attribute sub-graph was put forward based on probability attribute graph. Firstly, the dense probability I attribute sub-graph and the dense pro-bability II attribute sub-graph are defined, simultaneously, the expectation tightness function and the corresponding theorems of dense sub-graph were given respectively. Then the efficient mining algorithm of K-densely sub-graph was designed, in order to find K-dense sub-graphs with the highest probability of vertex and edge in complicated networks. Finally, simulation experiment of protein network and virtual network shows that the algorithm has higher mining efficiency and better adaptability in different sizes of complicated networks.
Key wordscomplicated networks; K-densely sub-graph; probability attribute graph; mining graph
猜你喜欢
计算机应用(2016年12期)2017-01-13
对外经贸(2016年11期)2017-01-12
无线互联科技(2016年13期)2017-01-10
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
电脑知识与技术(2016年18期)2016-11-02
科技视界(2016年20期)2016-09-29
电脑知识与技术(2016年16期)2016-07-22
电脑知识与技术(2016年11期)2016-06-17
计算技术与自动化(2015年4期)2016-03-25
软科学(2015年10期)2015-10-28
