
基于数据流挖掘的网络边界防护技术研究*
2016-08-10 03:43姜洪海王婷婷
计算机与数字工程 2016年7期
姜洪海 王婷婷 左 进
(1.海军北海舰队司令部机要处 青岛 266000)(2.海军工程大学信息安全系 武汉 430033)
基于数据流挖掘的网络边界防护技术研究*
姜洪海1王婷婷1左进2
(1.海军北海舰队司令部机要处青岛266000)(2.海军工程大学信息安全系武汉430033)
摘要针对网络边界安全检测与防护问题,提出了基于数据流挖掘的网络边界防护模型。该模型从数据流的角度出发,首先对网络数据进行抽样并预处理,然后应用数据流挖掘技术进行规则挖掘,最后根据挖掘结果对网络进行分析和控制。仿真实验表明,在网络安全检测中,数据流挖掘方法比传统的模式匹配方法更具有优势。
关键词网络边界; 防护; 数据流; 挖掘
Class NumberTP393
1引言
网络安全问题一直是互联网技术领域热点问题之一,尤其是不同网络之间的边界安全,其所受到的安全威胁来源呈日益增长态势。近年来,随着网络技术的发展,部分网络出口流量就达到百G甚至更高,在超大规模网络之间交换的数据量则更高,甚至达到千G[1]。如何维护高速网络边界安全己成为一个现实问题。现有网络之间交换的数据往往呈流式状态,针对如此大规模的数据流安全检测问题,传统的边界安全检测与防护手段存在诸多问题:需要多次访问数据,无法处理潜在无限的数据流;计算复杂度太高,难以一次性处理所有数据流;空间复杂度太大,有限内存难以计算[2]。
为了从大量冗余的信息中提取出潜在有价值的信息,衍生出了一个全新的领域—数据挖掘。数据挖掘就是从海量的、模糊信息中获取有效的、潜在有用的信息和知识的过程[3~4]。而数据流挖掘就是在流式数据上提取有效的、有价值的信息和知识的过程。数据流挖掘技术能够在大规模流式数据中发现特征或规则。在网络异常行为分析和入侵检测领域,利用数据流挖掘技术可以从大量的审计数据中找出正常或入侵性质的行为模式,从而构建自动检测模型。基于数据流挖掘的网络安全检测方法具有自适应强、无监督和检测效率高等优点。本文从数据流挖掘的角度出发,研究基于数据流挖掘的网络边界行为检测和防护技术。
2网络边界防护难点
网络边界是指具有不同安全策略的网络连接处或者是逻辑隔离的不同网络之间分界线。网络边界内涵丰富,不仅包含传统的物理边界,还包括网络之间的逻辑边界。网络边界的复杂性与广泛性决定了其所受的安全威胁来源多样,如网络内外部的信息泄露、针对网络边界设备或系统服务器的网络攻击、内嵌在软件中的网络病毒、盗用网络信息的木马入侵等。目前针对网络边界的防护主要是配备边界路由器、边界防火墙、边界防病毒设备、边界流量监控等。如此多的边界防护软硬件容易产生安全信息过载现象,造成管理的混乱。网络边界的防护关键是能够对各种网络安全威胁进行快速有效的检测,对检测到的威胁进行及时隔离与处理,从而才能够确保网络安全。
3数据流挖掘在网络行为分析中的优势
网络中的程序或用户在网络中的各种行为,往往可以通过其产生的网络行为数据来反映。从捕获的网络行为数据中,选择合适的有代表性的行为属性进行模式挖掘处理,构建网络的正常行为特征库,通过实时比较网络的当前行为和行为特征库,可以实现对网络异常的检测和分析,维护网络的安全。
数据流挖掘就是从大量流式数据中挖掘出潜在的有价值的信息知识过程。数据流挖掘包括对数据流的频繁模式挖掘、分类挖掘、聚类挖掘和关联规则挖掘[5~7]。该技术主要根据流式数据本身的固有属性进行挖掘分析,从数据之间的差异发现价值信息,挖掘模型不依赖专家系统,不需要过多的人工参与。将数据流挖掘技术应用到网络异常行为分析和网络防护,具有智能性好、自动化程度高、检测效率高、自适应性强和误报率低等优点。
4基于数据流挖掘的网络边界防护模型
图1为基于数据流挖掘的网络边界防护模型,主要分为三个模块:数据流抽样与预处理模块、数据流挖掘与规则输出模块、网络边界安全控制模块。下面对其进行详细介绍。
4.1数据流抽样与预处理模块
网络数据流的抽样是对大量、高速、时变的网络数据包按一定比例进行约减抽取。通过对网络数据流的抽样,可以降低网络分析与测量的实现代价,从而实现对网络的安全检测和性能监控等目的。对网络数据流的抽样,最重要的是利用样本能够恢复出原有数据的特性即保真,但同时也需要追求抽样方案的简单性与可行性以提高效率[8]。
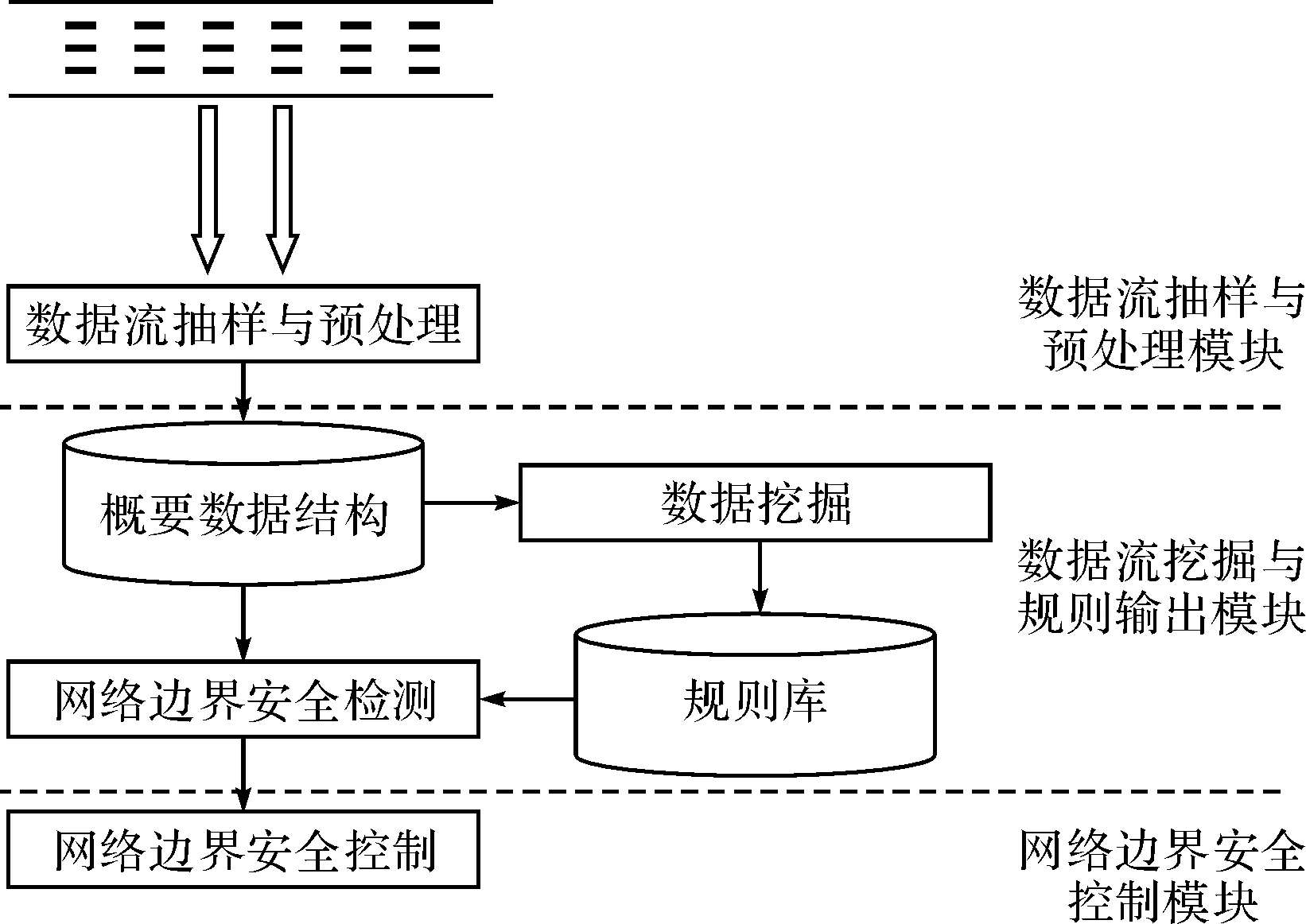
图1 基于数据流挖掘的网络边界防护模型
网络数据流的抽样样本为网络数据包,将数据包统计为网络连接记录,仍然不能直接用于数据挖掘,需要对其进行预处理。预处理过程主要包括特征属性项的选取、属性值的数值化和属性值的标准化。
4.1.1特征属性项的选取
鉴别并选取关键属性项作为数据流挖掘算法的输入,对于数据分析来说意义重大。不仅可以降低算法的复杂度和所需存储空间,而且可以提高算法的准确率。以KDD99数据集为例,对于数据集中每一条网络连接记录的41个特征属性,文献[9]根据PFRM算法(基于效能等级的重要特征排序算法)筛选出了对应于不同网络攻击行为的重要特征属性子集,如表1所示。表中数字对应KDD99数据集中各特征属性项编号,即1~41个特征属性项。
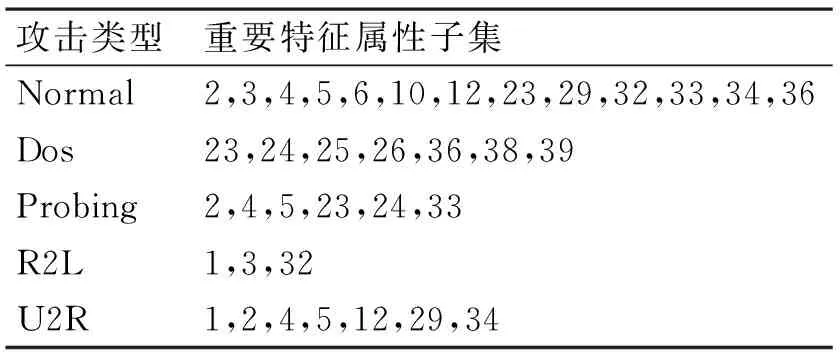
表1 PFRM算法重要特征属性子集列表
综合得出PFRM算法可选择的特征属性项个数为19个,即特征属性项集F1={1,2,3,4,5,6,10,12,23,24,25,26,29,32,33,34,36,38,39}。文献[10~11]利用RS粗糙集理论对数据集的属性进行约简,并和SVDF、LGP、MARS算法进行比较,选出了六个最为重要的特征属性项。各算法选择的重要特征属性项如表2所示。

表2 RS、SVDF、LGP、MARS算法重要特征属性子集列表
考虑到RS选择的特征属性子集能够很好地判断入侵,且特征属性项的个数较小,容易实现,本文采用的是RS算法对数据集属性约简筛选出的特征属性项子集F3={3,4,5,24,32,33}。
4.1.2属性值的数值化
在网络连接记录中的所有特征属性中,还包含一些非数值数据,如flag、service、Protocol_type等属性值是字符串类型。为了能够对其运算,需要将这些字符串变为数值型。连接正常或错误的状态—flag属性,取值有S0,S1、S2、S3、SF、SH、OTH、REJ、RSTO、RSTOSO、RSTR,一共11个,可分别将其转换对应为整数1~11;协议类型—Protocol_type属性的取值有icmp、tcp、udp可对应为整数1~3,其他协议类型一律对应为4;对于目标主机的网络服务类型—service一共有70种取值,可分别对应于整数1~70。
4.1.3属性值的标准化
大多数的数据流挖掘算法是根据相似度对算法的输入即特征属性项进行挖掘分析的,将相似度小的数据聚为一类,相似度大的数据分开。而相似度对特征属性项的值域范围是非常敏感的。例如,相似度采用欧式距离进行运算时,对如下两组数据进行相似度的判断:
第一组:{(1,1,2,3),(2,2,3,2)};
第二组:{(180,340,320,120),(280,240,420,220)};
第一组中两个数据的相似度:
第二组中两个数据的相似度;
=200
如果算法以数值3为相似度的度量标准,则根据得到的结果,第一组应该归为一类,第二组应该被划分开。但事实上,第二组两个数据之间的距离与第一组两个数据之间的相对距离等同。直接用特征属性的值进行计算势必造成很大误差,必须对数据进行标准化。
对于包含m个特征属性项的L个数据的数据集DS,由式(1)~式(3)将其转换到新的标准化空间NEW_DS。mean_vector[i]和std_vector[i]分别是数据集DS中第i个特征属性项的均值和标准方差。
(j∈(1,2,…,L),i∈(1,2,…,m))
(1)
(2)
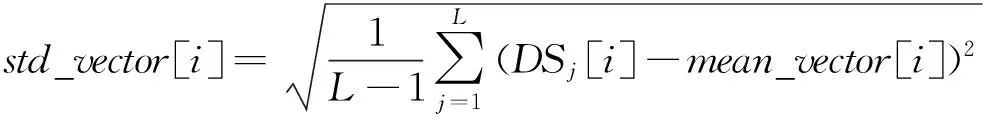
(3)
这样,通过式(1)~式(3)后,可将数据集中不同特征属性项由其初始空间转换到标准空间,消除不同值域范围对挖掘算法的影响。
4.2数据流挖掘分析与规则输出模块
将抽样数据流进行预处理之后,待挖掘数据的真实性、数据量以及数据质量已经可以得到保障,接下来就可以对处理过的数据进行深层次的分析和挖掘了。这部分工作主要是从待挖掘的数据中找到异常数据,挖掘出隐藏在数据中的重要价值信息,并且以规则这种可接收、可理解可应用的形式展示出来。
如图2所示,为数据流挖掘与规则输出的整个流程。首先需要选择合适的挖掘算法对数据进行挖掘分析,同时将分析的结果以图表或文本规则的形式进行总结,最后输出。

图2数据流挖掘与规则输出过程
4.2.1数据流挖掘算法
对数据进行挖掘应用最为广泛的是J.B.MacQueen提出的k-means算法即K均值算法。由于该算法简单、高效、适用于大规模数据集的处理,自提出后就被广泛应用于各种领域。经典的K均值算法属于划分聚类方法,目标是最小化平方误差和函数。算法经过多次迭代,将Rd空间上的数据集X={x1,…,xi,…,xn}划分聚类到K个不同类簇当中,使得类簇间相似度尽可能小,类簇内相似度尽可能大。K均值算法首先随机指派K个数据点作为算法的初始聚类中心,然后采用欧式距离计算所有点到达各个中心的距离,把各个点划分到离其最近的中心点所属类簇。对调整后的类簇重新计算其簇中心,再次更新所有点的所属簇,如此反复迭代,直至聚类准则函数收敛或达到迭代次数,算法结束。具体聚类过程如图3所示。
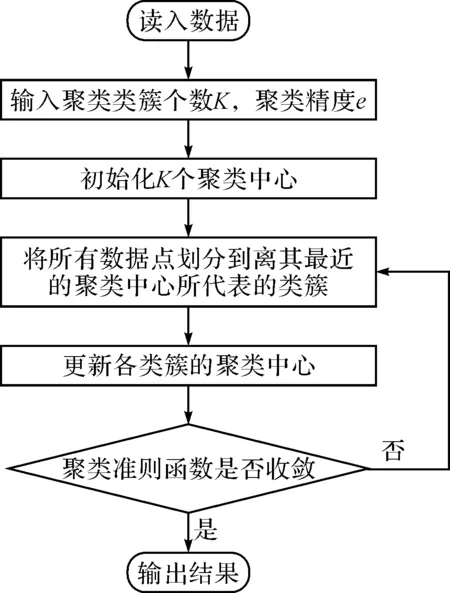
图3 K均值算法聚类过程
4.2.2挖掘结果判断
对于网络边界数据流来说,挖掘的结果主要是找出其中具有潜在威胁的信息即异常信息。异常,从某种意义上说是一种模式,这种模式中的数据并不满足我们熟知或者预定义的正常数据范围,在整个数据流中找出符合这种模式的数据称之为异常检测。而在聚类中,对异常的挖掘是基于数据对象与大众数据的偏离程度。所有数据通过无监督的聚类算法按照相似度差异进行聚类划分之后,被分成不同的类簇。对异常的判断基于以下两个原则:在同一个类簇中,正常的数据对象离类簇中心距离较近,而异常数据对象离类簇中心距离较远;在不同的类簇之间,正常的数据对象属于规模较大、数据密集的类簇,而异常数据对象属于娇小的、数据稀疏的类簇。如图4所示,在一个二维数据集中,所有数据被聚类划分为三类。数据集中的大部分数据都聚集在类簇C1和C2中,对于较为稀疏的类簇C3和离类簇中心距离较远的数据点d1和d2都可以被判断为异常数据点。
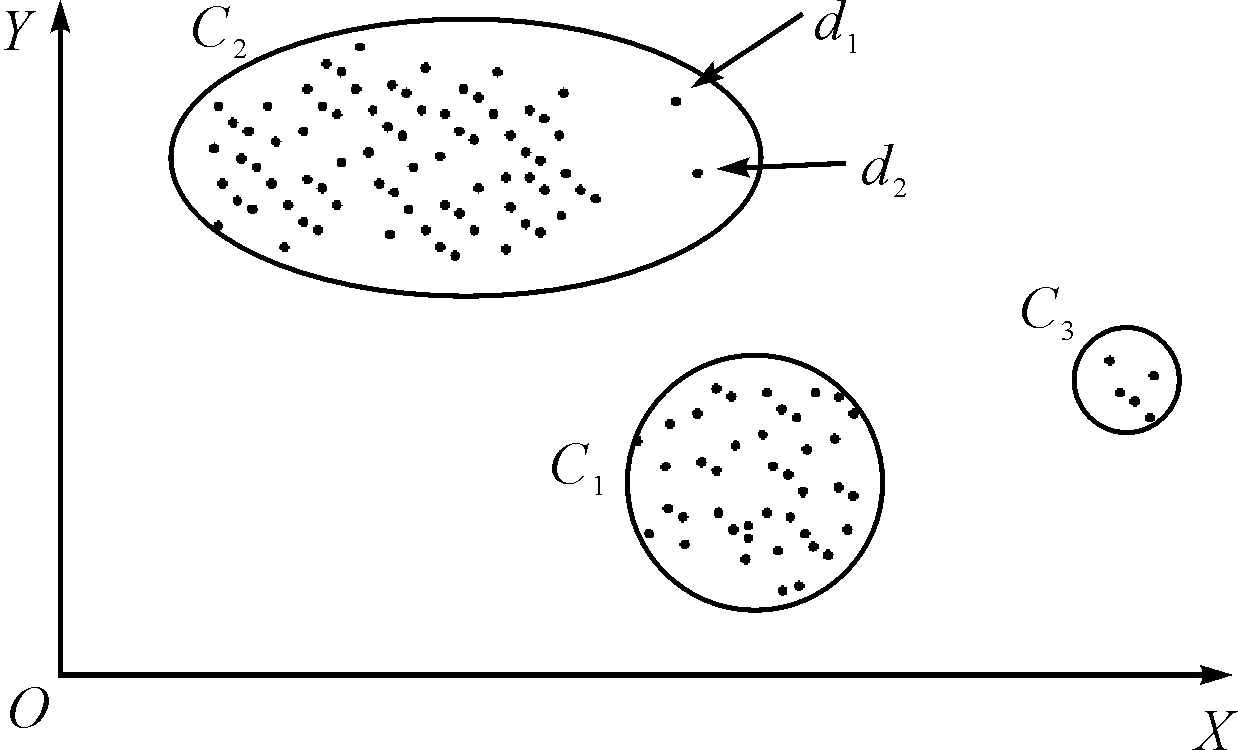
图4 数据挖掘结果判断
4.3网络边界安全控制模块
当利用数据流挖掘技术发现异常数据流之后,需要对该数据流所代表的网络行为进行监控或及时阻断,此功能主要由网络边界安全控制模块来完成。作为网络边界安全控制中心,通过允许、拒绝网络之间流通的数据流,网络边界安全控制模块实现对出入网络的服务、访问进行审计和控制,对用户的行为进行监控,对具有不安全倾向行为早发现早预防,削弱、减少网络中的脆弱点,达到网络防护的目的。具体措施包括断开连接或关闭访问资源、根据相应的安全策略进行响应、向用户告警等。
5仿真分析
在网络边界防护过程中,对网络入侵或者攻击行为的识别是关键,为了分析数据流挖掘在网络行为判断中的优势,本文对数据流挖掘方法和传统入侵检测系统的模式匹配方法进行了仿真对比,主要分析两种方法对网络攻击数据的检测率、误检率和检测时间。
实验配置:Win 7,VC++6.0,Matlab7.1,CPU 2.4 GHz,2.0 GB内存。实验数据来源于UCI机器学习数据库[12]的KDD数据集。其中,KDD数据集有四大类攻击数据即异常数据:Dos(拒绝服务攻击)、Probing(监视与探测)、R2L(远程非法访问)、U2R(普通用户对本地超级用户的非法访问)。该数据集中的每一个连接记录可提供一个完整的网络会话。表3是摘自KDD99数据集的三条网络连接记录,以CSV格式呈现。
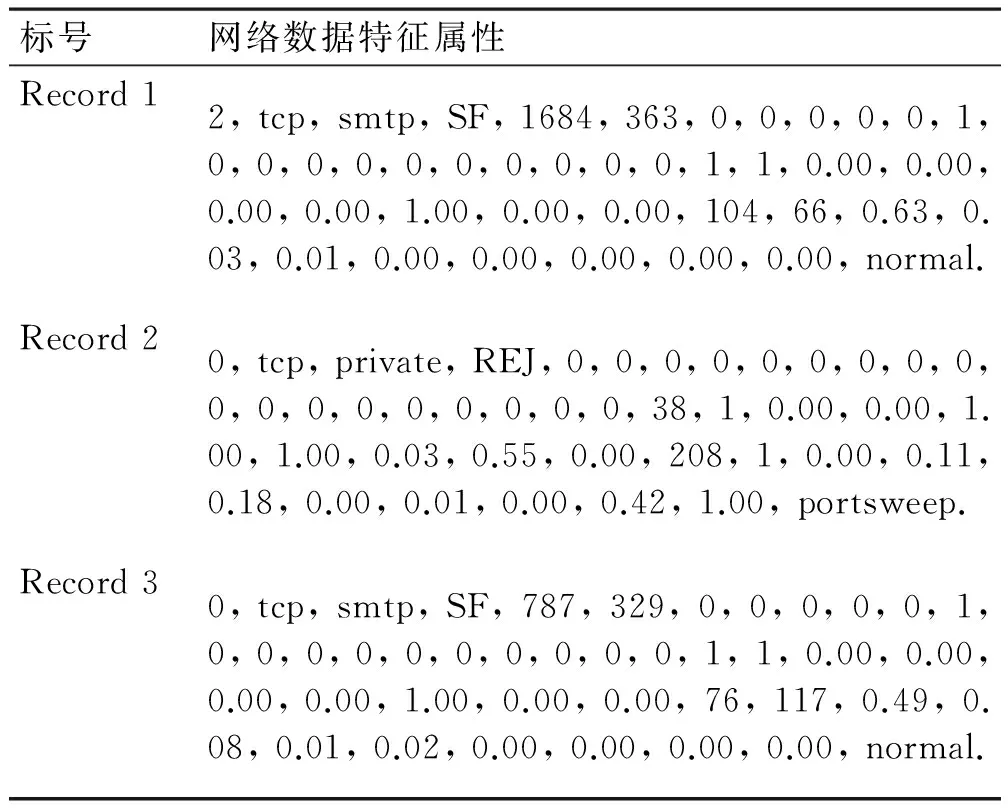
表3 KDD99数据集
结果如表4所示。对于前三种攻击数据,检测率方面,数据流挖掘检测方法平均比传统模式匹配检测方法提高了4%,用时方面平均少了1468ms。这是因为数据流挖掘技术主要根据数据本身的固有属性进行挖掘分析,效率较高。但是在误检率方面,传统模式匹配检测方法根据原有的攻击行为模型进行一一吻合检测,误检率较低。综合来看,在整体数据集的检测中,数据流挖掘检测方法除了在误检率方面稍微落后一些,在检测率和检测时间方面,优于传统的模式匹配检测方法。
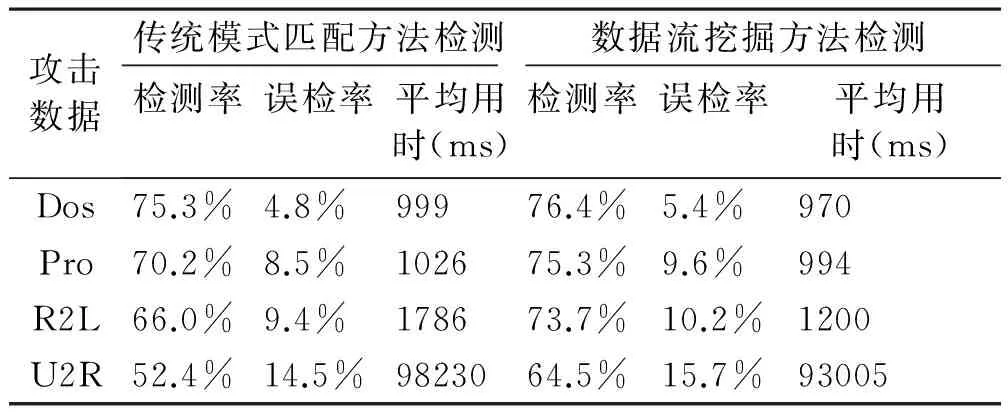
表4 两种方法对攻击数据的检测效果比较
6结语
本文主要研究了基于数据流挖掘的网络边界防护技术。提出了基于数据流挖掘的网络边界防护模型,主要包括数据流抽样与预处理模块、数据流挖掘与规则输出模块、网络边界安全控制模块。并对防护模型中涉及到的关键技术和环节进行了重点介绍。最后利用编程仿真,分析了数据流挖掘技术在网络行为分析中的优势。将数据流挖掘技术应用到网络异常行为分析和网络防护,具有智能性好、检测效率高等优点,如何在真实网络环境中搭建平台与实践应用,将是本文下一步研究方向。
参 考 文 献
[1] 白生江.主动型军用网络边界防护系统研究[D].西安:西安电子科技大学,2010.
BAI Shengjiang. Study of Proactive Military Network Security Border Protection System[D]. Xi’an: Xi’an Electronic and Science University,2010.
[2] 刘本仓.基于采样数据流挖掘的网络行为分析研究[D].西安:西安电子科技大学,2009.
LIU Bencang. Research On Network Behavior Analysis Based on Sampling Stream Data Mining[D]. Xi’an: Xi’an Electronic and Science University,2009.
[3] 李贺玲.数据挖掘在网络入侵检测中的应用研究[D].长春:吉林大学,2013.
LI Heling. Study on Application of data mining in network intrusion detection[D]. Changchun: Jilin University,2013.
[4] 谭林.基于NMHS4C和M-Apriori的Snort入侵检测研究[D].武汉:武汉科技大学,2015.
TAN Lin. Research on Intrusion Detection Based on Snort NMHS4C and M-Apriori[D]. Wuhan: Wuhan University of Science and Technology,2015.
[5] Shie B E, Yu P S, Tseng V S. Efficient algorithms for mining maximal high utility itemsets from data streams with different models[J]. Expert Systems with Applications,2012,39(17):12947-12960.
[6] Li H F. MHUI-max: An efficient algorithm for discovering high-utility itemsets from data streams[J]. Journal of Information Science,2011,37(5):532-545.
[7] Song W, Liu Y, Li J. Mining high utility itemsets by dynamically pruning the tree structure[J]. Applied Intelligence,2014,40(1):29-43.
[8] InMon. sFlow accuracy and billing[EB/OL]. http://www.inmon.com/PDF/sFlowBilling.pdf,2015-10-10.
[9] 田俊锋,王惠然,刘玉玲.基于属性排序的入侵特征缩减方法研究[J].计算机研究与发展,2006,43(Suppl):565-569.
TIAN Junfeng, WANG Huiran, LIU Yuling. Research on Reduction Method of Intrusion Features Based on Ordering Features[J]. Journal of Computer Research and Development,2006,43(Suppl):565-569)
[10] Ivan Bruha. Pre-and Post-Processing in Machine Learning and Data Mining[J]. Machine Learning and Its Applications,2010,18(3):258-266.
[11] 陈才杰.粗糙集理论在知识发现数据预处理中的研究与应用[D].武汉:武汉理工大学,2014.
CHEN Caijie. Research and Application of Rough Set on Data Preprocessing of Knowledge Discovery[D]. Wuhan: Wuhan University of Technology,2014.
[12] Asuncion A, Newman D. UCI Machine Learning Respository[EB/OL].[2015-12-1].http://archive.ics.uci.edu/ml/datasets.html.
收稿日期:2016年1月6日,修回日期:2016年2月14日
作者简介:姜洪海,男,工程师,研究方向:信息安全。王婷婷,女,硕士,工程师,研究方向:网络安全。左进,男,硕士,研究方向:信息安全。
中图分类号TP393
DOI:10.3969/j.issn.1672-9722.2016.07.023
Network Boundary Protection Technology Based on Data Stream Mining
JIANG Honghai1WANG Tingting1ZUO Jin2
(1. Confidential Room, Navy North Sea Fleet Headquarters, Qingdao266000)(2. Information Security Department, Naval University of Engineering, Wuhan430033)
AbstractIn view of the problem of network boundary security detection and protection, a network boundary protection model based on data stream mining is proposed. From the view of data flow, the network data is sampled and processed first, then the data stream mining technology is applied to rule mining. Finally, the network is analyzed and controlled according to the mining results. Simulation experiments show that, in the network security detection, the data stream mining method has more advantages than the traditional pattern matching method.
Key Wordsnetwork boundary, protection, data flow, mining
猜你喜欢
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
散文百家·下旬刊(2016年9期)2016-11-23
文理导航(2016年30期)2016-11-12
文艺生活·中旬刊(2016年9期)2016-11-07
电脑知识与技术(2016年21期)2016-10-18
现代园艺(2016年17期)2016-10-17
科学与财富(2016年28期)2016-10-14
西北工业大学学报(2015年3期)2015-12-14
中国卫生(2014年7期)2014-11-10
