
基于时空信息和非负成分表示的动作识别
2016-09-21 05:21王健弘章品正姜龙玉罗立民
东南大学学报(自然科学版) 2016年4期
王健弘 张 旭 章品正 姜龙玉 罗立民
(东南大学影像科学与技术实验室, 南京 210096)
基于时空信息和非负成分表示的动作识别
王健弘 张旭 章品正 姜龙玉 罗立民
(东南大学影像科学与技术实验室, 南京 210096)
为充分利用时空分布信息及视觉单词间的关联信息,提出了一种新的时空-非负成分表示方法(ST-NCR)用于动作识别.首先,基于视觉词袋(BoVW)表示,利用混合高斯模型对每个视觉单词所包含的局部特征的时空位置分布进行建模,计算时空Fisher向量(STFV)来描述特征位置的时空分布;然后,利用非负矩阵分解从BoVW表示中学习动作基元并对动作视频进行编码.为有效融合时空信息,采用基于图正则化的非负矩阵分解,并且将STFV作为图正则化项的一部分.在3个公共数据库上对该方法进行了测试,结果表明,相比于BoVW表示和不带时空信息的非负成分表示方法,该方法能够提高动作识别率.
动作识别;非负成分表示;时空Fisher向量;视觉词袋
人体动作识别是当前计算机视觉和模式识别领域的研究热点之一,它在视频分析、视频检索、智能监控以及人机交互等领域中有着广泛的应用[1].人体动作识别最关键的问题是如何有效并具有区分性地表示动作视频片段.目前广泛应用的方法是提取视频中的局部特征并采用视觉词袋(BoVW)给出视频表示.该方法采用码书中的视觉单词对动作视频中的每一个局部特征进行编码,然后统计整段视频的视觉单词直方图作为该视频的表示向量.已有许多学者针对局部特征进行了研究,提出了一些行之有效的特征,如HOG/HOF[2],HOG3D[3],Gist3D[4],以及密集轨迹[5]等.同时,也有学者从改进编码方式角度来提高识别精度,包括局部软分配[6]、稀疏编码[7]以及局部约束线性编码[8]等.
但BoVW方法仍存在一些缺陷:基于BoVW给出的表示向量仅统计了视觉单词的出现频次,却未考虑视觉单词之间的关系;该方法还忽略了局部特征的位置分布信息.有效利用这些信息对于提高动作识别率是有益的.
为解决上述问题,本文提出一种基于时空位置信息和非负成分表示的动作识别方法.非负成分表示是一种中层表示方法,采用动作基元作为词典基本单元,每个动作基元由若干相关的底层视觉单词构成,通过非负矩阵分解(NMF)从训练样本的BoVW底层特征表示中学习得到.时空信息采用时空Fisher向量(STFV)表示,时空Fisher向量描述每一个视觉单词所对应的所有底层局部特征位置的时空分布.将时空Fisher向量在计算非负成分表示时加入,得到结合时空分布信息的非负成分表示向量,称之为时空-非负成分表示(ST-NCR).采用时空-非负成分表示作为动作视频的最终表征来训练SVM分类器,实现动作识别.
1 时空Fisher向量
考虑到由同一视觉单词所描述的底层局部特征的时空位置分布具有一定的规律性,本文利用混合高斯模型和Fisher向量描述底层局部特征时空位置分布以及该分布和视觉单词之间的关系.
首先采用混合高斯模型对每个视觉单词所包含的底层特征时空位置分布进行建模,设ln∈R3(n=1,2,…,N)为特征xn∈Rd(n=1,2,…,N)所对应的时空位置坐标,视觉单词总数为K,则第k个视觉单词所对应的特征位置分布可表示为
(1)
式中,N(·)表示高斯分布;G为高斯模型的个数;ωkg,μkg和σkg分别为第g个高斯模型的混合权重、均值向量和协方差矩阵.基于式(1),位置ln的全局分布可表示为
(2)
式中,γn(k)为特征xn分配到视觉单词k的权重.得到位置ln的全局分布后,求取时空Fisher向量.对位置ln的全局分布p(ln)求对数似然函数关于μkg和σkg的梯度,位置ln关于μkg和σkg的归一化梯度向量Gμ,kg和Gσ,kg可由如下公式得到:
(3)
(4)
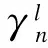
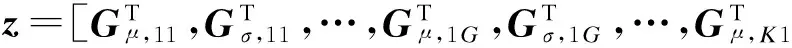
(5)
2 非负成分表示
非负成分表示是采用非负矩阵分解[9]对BoVW底层特征表示进行分解得到的.非负矩阵分解是一种矩阵分解方法,它将一个非负矩阵分解为2个非负矩阵的乘积.非负矩阵分解能够降低数据维度,同时,相对于其他矩阵分解方法,由于有非负约束的存在,数据由基向量叠加表达,具有一定的物理意义和可解释性,并且合乎大脑感知的直观体验.
令yi∈RM(i=1,2,…,N)为第i个视频的一个M维的底层特征表示向量,Y=[y1,y2,…,yN]∈RM×N为由所有视频的底层特征表示组成的矩阵.对Y进行非负矩阵分解,即最小化以下目标函数:
(6)
式中,U=[u1,u2,…,uK]∈RM×K和V=[v1,v2,…,vN]∈RK×N为非负矩阵.若将U的每一列定义为一个动作基元,则列向量中每一个元素对应一个底层特征的视觉单词,动作基元可以看成是由多个相关的底层特征视觉单词共同构成的中层特征表示.矩阵V中的列向量vi则可以看作是第i个视频基于动作基元词典U的中层表示向量,本文将vi称之为视频i的非负成分表示.
非负成分表示相对于BoVW底层特征表示而言更加简洁.通过非负矩阵分解可以找出视觉单词间的关联,同时提取出真正有效通用的视觉单词,抑制一些仅存在于少数样本,对后续分类作用不大的视觉单词.
2.1时空-非负成分表示
常用的特征融合方法有特征表示融合和核融合.特征表示融合是在底层或中层特征表示时将2种特征向量拼接.由于时空Fisher向量维数较大,特征表示融合方法得到的表示向量维数过大,不利于后续计算,而且会导致结果主要受时空Fisher向量的影响.核融合首先分别求取底层特征和时空Fisher向量的非负成分表示,在SVM分类前计算核矩阵,将2个核矩阵融合后再进行分类.对于核融合,由于2种特征非负成分表示分开求取,因此同一样本中底层特征和时空Fisher向量之间的相互关系在中层表示中得不到体现.
为解决以上问题,本文提出一种新的融合方法,即采用基于图正则化的非负矩阵分解(GNMF)[10]计算动作基元矩阵U以及非负成分表示矩阵V,同时将时空Fisher向量作为图正则化项的一部分,与底层特征在图正则化项内融合.该方法不仅有效融合了时空分布信息,而且非负成分表示的向量维度也没有增加.由此得到的非负成分表示被称为时空-非负成分表示.该方法的目标函数如下:
(7)
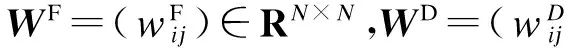
(8)
(9)
式中,δ为宽度参数.
式(7)中的β用来调节WF和WD所占比重,当β=1时,式(7)退化为标准形式的GNMF.GNMF通过添加图正则化项保证了数据在变换前后的空间结构具有相似性,即式(7)保证了如果2个同类样本底层特征表示和时空分布相似,那么两者的时空-非负成分表示也依然是相似的.
2.2时空-非负成分表示计算方法
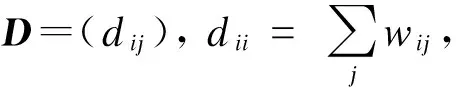
(10)
该目标函数与标准GNMF简化后的形式相同,可采用交替迭代的方法求解U和V,迭代规则如下:
(11)
(12)
式中,符号⊙表示两矩阵对应元素相乘;除法表示两矩阵对应元素相除.
对于测试集的视频样本,首先计算所有样本的底层特征表示Yt={yt1,yt2,…,ytNt}以及时空Fisher向量Zt={zt1,zt2,…,ztNt},其中Nt为测试视频样本的数目.最简单的求取中层表示的方法是根据词典U直接计算Vt=U†Yt,符号†表示伪逆.但是这种方法求出的中层表示无法保证非负特性,同时该方法忽略了测试样本的时空分布信息以及测试集与训练集之间的关系.本文考虑依然采用GNMF求取测试集的非负成分表示Vt,将测试集和训练集的数据同时代入式(7),则目标函数变为如下形式:
(13)
式中,符号^表示矩阵同时包含训练集和测试集的数据.对于式(13),U和V已知,测试集的非负矩阵Vt=(vt(ij))为变量,求解Vt使目标函数最小化.采用拉格朗日乘子法求解,设φij为约束vt(ij)≥0所对应的拉格朗日乘子,Φ=(φij).构造如下拉格朗日函数L:
(14)
将拉格朗日函数L对Vt求一阶偏导,可得
(15)
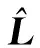
(16)
进一步推导,可得到Vt的迭代更新规则:
(17)
式中,W2和D2为与L2相对应的矩阵分块.式(17)体现了测试集的时空-非负成分表示计算不仅依赖于动作基元字典U,同时也考虑了时空分布信息以及测试集与训练集各样本间的相关性,这保证了训练集和测试集时空-非负成分表示的一致性.图1给出了整个方法的实现流程图.
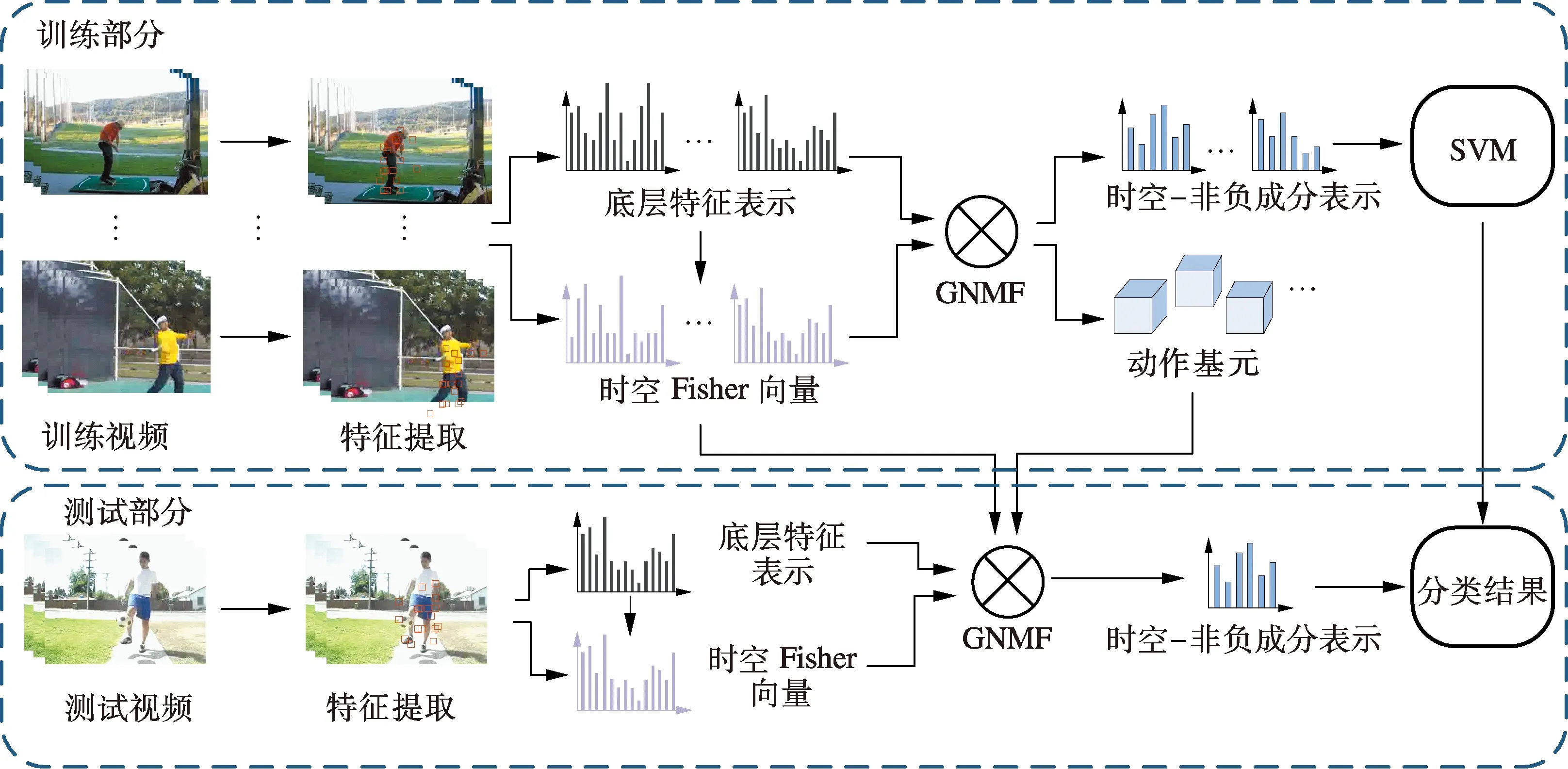
图1 本文方法的实现流程图
3 实验结果与分析
3.1数据库及参数设置
本实验采用3个通用的动作识别评估数据库KTH,YouTube和HMDB51来验证本文方法的有效性.KTH数据库[11]包含25人在4个不同场景下的6类动作(Walking, Jogging, Running, Boxing, Waving, Clapping),共计600个视频.实验设置同文献[11],600个视频分为2 391段,将16人的动作片段作为训练集,其余9人的动作片段作为测试集.YouTube数据库[12]包含11类动作,每一类动作被分为25个独立的组,每组4~8个视频,不同组的视频是在不同环境下拍摄的,共计1 168个视频片段.视频全部取自YouTube网站,分辨率低,背景复杂.实验采用留一法交叉验证[12],每次一组视频用作测试,其余24组作为训练集,取25次结果的均值作为最终识别率.HMDB51数据库[13]包含51类动作,共6 766个视频片段,视频来自电影片段和视频网站,由于动作种类多、场景复杂,HMDB51数据库非常具有挑战性.按照文献[13]将6 766个视频分为3组,在3组视频上分别进行训练和测试,取3组结果的平均值作为最终识别率.图2为从3个数据库中部分视频截取的图像.
密集轨迹方法[14]是最有效的底层局部特征提取方法,近年来得到广泛应用.本文选用3个基于密集轨迹的特征作为底层特征,分别为HOG,HOF和MBH.底层特征字典大小统一为4 000,底层特征表示统一采用局部软分配的编码方式.相比于BoVW方法中采用的硬分配编码方式,局部软分配具有更好的精度和鲁棒性,同时能保证底层特征表示非负,这是本文方法后续处理的前提条件.

(a) KTH数据库

(b) YouTube数据库

(c) HMDB51数据库
时空Fisher向量计算过程中,每个视觉单词所对应的混合高斯模型中高斯模型数目设置为9.由于底层特征视觉单词非常多,直接训练混合高斯模型将非常耗时,实验中,简化为所有视觉单词采用相同的混合高斯模型.该统一模型的生成方式为:将单位立方等分为8个小立方,连同自身共9个立方,设每个立方内底层特征时空位置分布都是均匀分布,计算均值和方差,由此得到9个高斯模型,将这9个模型的等权重组合作为实验中使用的混合高斯模型.
本文采用RBF-χ2核的非线性SVM作为分类器,由于动作识别是多分类问题,采用一对多方法,对每一类动作训练一个分类器,样本测试时选择分数最高的动作类别作为最终分类结果.
3.2实验结果与分析
为验证本文提出的时空-非负成分表示方法的有效性,将本文方法ST-NCR与BoVW底层特征表示以及不带时空信息的非负成分表示(NCR)方法在相同条件下进行比较.ST-NCR和NCR均以BoVW底层特征表示结果为基础,ST-NCR是通过在NCR中增加时空分布信息改进得到的.NCR和ST-NCR的基元词典大小设置为500,ST-NCR的权重参数β设置为0.55.ST-NCR与其他方法在KTH,YouTube和HMDB51数据库上的识别率比较结果如表1~表3所示.
从表1~表3可看出,在3个数据库上,NCR和ST-NCR的结果均明显好于BoVW的结果.这表明采用非负成分的中层表示方法相比于BoVW底层表示方法能够更有效地表征运动视频.同时还可以看出,ST-NCR的识别率要优于NCR,这显示了本文方法的有效性.

表1 3种方法在KTH数据库上的识别率比较 %

表2 3种方法在YouTube数据库上的识别率比较 %
表33种方法在HMDB51数据库上的识别率比较 %

方法HOGHOFMBH BoVW37.339.546.4 NCR38.643.448.5 ST-NCR40.244.851.3
为进一步研究权重参数β对ST-NCR结果的影响,选用底层特征HOG和HOF,选择不同的β值,在KTH和YouTube数据库上分别进行实验,结果如图3所示.从图中可看出,随着β值的增大,识别率的趋势基本是先增大然后回落,在β值为0.5附近取得峰值.这一结果显示引入时空分布信息后能够提高识别率,同时时空分布信息与HOG和HOF特征所描述的信息是互为补充的,联合使用的识别率高于使用单一信息的识别率.
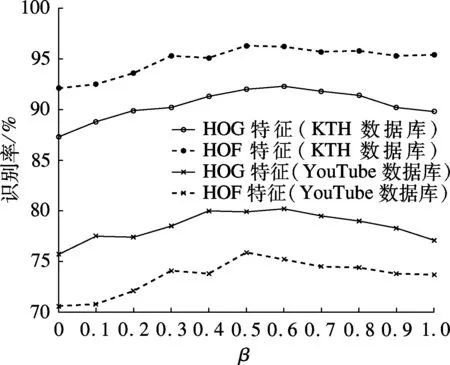
图3 不同权重参数β对ST-NCR结果的影响
为进一步提高识别率,将基于3个底层特征(HOG,HOF和MBH)所得到的ST-NCR进行融合.在3个测试数据库上,将融合后的中层表示所得识别率与其他文献的识别率数据进行比较,结果见表4.由表可看出,本文方法在KTH数据库上的识别率与文献[15]的识别率接近,但高于其他方法;在YouTube和HMDB51数据库上,本文方法的识别率已经超过其他所有方法.
表4本文融合后识别率与其他文献方法识别率比较 %
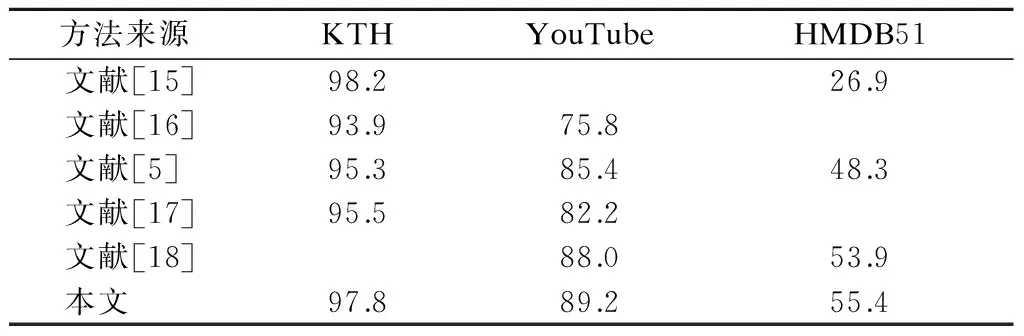
方法来源KTHYouTubeHMDB51 文献[15]98.226.9 文献[16]93.975.8 文献[5]95.385.448.3 文献[17]95.582.2 文献[18]88.053.9 本文97.889.255.4
4 结语
本文提出了一种新的中层动作表示方法用于动作识别,该方法基于动作基元表征动作视频,同时融合了底层特征时空分布信息.首先,基于BoVW表示,利用混合高斯模型对视觉单词所包含特征的时空位置分布进行建模,计算时空Fisher向量;然后,将时空Fisher向量作为图约束的一部分,利用GNMF对BoVW底层特征表示结果进行分解,得到动作基元以及基于动作基元的时空-非负成分表示.实验结果表明,与BoVW表示以及不带时空信息的非负成分表示方法相比,本文所提出的时空-非负成分表示方法能提高动作识别率.
References)
[1]Turaga P, Chellappa R, Subrahmanian V S, et al. Machine recognition of human activities: A survey[J].IEEETransactionsonCircuitsandSystemsforVideoTechnology, 2008, 18(11): 1473-1488. DOI:10.1109/tcsvt.2008.2005594.
[2]Laptev I, Marszalek M, Schmid C, et al. Learning realistic human actions from movies[C]//IEEEConferenceonComputerVisionandPatternRecognition. Anchorage, USA, 2008: 1-8. DOI:10.1109/cvpr.2008.4587756.
[3]Klaser A, Marszalek M, Schmid C. A spatio-temporal descriptor based on 3d-gradients[C]//19thBritishMachineVisionConference. Leeds, UK, 2008: 995-1004. DOI:10.5244/c.22.99.
[4]Solmaz B, Assari S M, Shah M. Classifying web videos using a global video descriptor[J].MachineVisionandApplications, 2012, 24(7): 1473-1485. DOI:10.1007/s00138-012-0449-x.
[5]Wang H, Kläser A, Schmid C, et al. Dense trajectories and motion boundary descriptors for action recognition[J].InternationalJournalofComputerVision, 2013, 103(1): 60-79. DOI: 10.1007/s11263-012-0594-8.
[6]Liu L Q, Wang L, Liu X W. In defense of soft-assignment coding[C]//IEEEInternationalConferenceonComputerVision. Barcelona, Spain, 2011: 2486-2493.
[7]Yang J, Yu K, Gong Y, et al. Linear spatial pyramid matching using sparse coding for image classification[C]//IEEEConferenceonComputerVisionandPatternRecognition. Miami, USA, 2009: 1794-1801.
[8]Wang J, Yang J, Yu K, et al. Locality-constrained linear coding for image classification[C]//IEEEConferenceonComputerVisionandPatternRecognition. San Francisco, CA, USA, 2010: 3360-3367. DOI:10.1109/cvpr.2010.5540018.
[9]Lee D D, Seung H S. Learning the parts of objects by non-negative matrix factorization[J].Nature, 1999, 401(6755): 788-791. DOI:10.1038/44565.
[10]Cai D, He X, Han J, et al. Graph regularized nonnegative matrix factorization for data representation[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2011, 33(8): 1548-1560. DOI:10.1109/TPAMI.2010.231.
[11]Schuldt C, Laptev I, Caputo B. Recognizing human actions: A local SVM approach[C]//Proceedingsofthe17thInternationalConferenceonPatternRecognition. Cambridge, UK, 2004: 32-36. DOI:10.1109/icpr.2004.1334462.
[12]Liu J, Luo J, Shah M. Recognizing realistic actions from videos “in the wild”[C]//IEEEConferenceonComputerVisionandPatternRecognition. Miami, USA, 2009: 1996-2003.
[13]Kuehne H, Jhuang H, Garrote E, et al. HMDB: A large video database for human motion recognition[C]//IEEEInternationalConferenceonComputerVision. Barcelona, Spain, 2011: 2556-2563. DOI:10.1109/iccv.2011.6126543.
[14]Wang H, Kläser A, Schmid C, et al. Dense trajectories and motion boundary descriptors for action recognition[J].InternationalJournalofComputerVision, 2013, 103(1): 60-79. DOI:10.1007/s11263-012-0594-8.
[15]Sadanand S, Corso J J. Action bank: A high-level representation of activity in video[C]//IEEEConferenceonComputerVisionandPatternRecognition. Providence, USA, 2012: 1234-1241.
[16]Le Q V, Zou W Y, Yeung S Y, et al. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis[C]//IEEEConferenceonComputerVisionandPatternRecognition. Providence, USA, 2011: 3361-3368.
[17]Wang H, Yuan C, Hu W, et al. Action recognition using nonnegative action component representation and sparse basis selection[J].IEEETransactionsonImageProcessing, 2014, 23(2): 570-581. DOI:10.1109/tip.2013.2292550.
[18]Yang X, Tian Y. Action recognition using super sparse coding vector with spatio-temporal awareness[C]//13thEuropeanConferenceonComputerVision. Zurich, Switzerland, 2014: 727-741. DOI:10.1007/978-3-319-10605-2_47.
Action recognition based on spatio-temporal information and nonnegative component representation
Wang Jianhong Zhang Xu Zhang Pinzheng Jiang Longyu Luo Limin
(Laboratory of Image Science and Technology, Southeast University, Nanjing 210096, China)
To make full use of spatial-temporal information and the relationship among different visual words, a novel spatial-temporal nonnegative component representation method (ST-NCR) is proposed for action recognition. First, based on BoVW (bag of visual words) representation, the locations of local features belonging to each visual word are modeled with the Gaussian mixture model, and a spatio-temporal Fisher vector (STFV) is calculated to describe the location distribution of local features. Then, nonnegative matrix factorization (NMF) is employed to learn the action components and encode the action video samples. To incorporate the spatial-temporal cues for final representation, the graph regularized NMF (GNMF) is adopted, and STFV is used as part of graph regularization. The proposed method is extensively evaluated on three public datasets. Experimental results demonstrate that compared with BoVW representation and nonnegative component representation without spatio-temporal information, the method can obtain better action recognition accuracy.
action recognition; nonnegative component representation; spatio-temporal Fisher vector; bag of visual words
10.3969/j.issn.1001-0505.2016.04.001
2016-02-24.作者简介: 王健弘(1984—),男,博士生;罗立民(联系人),男,博士,教授,博士生导师,luo.list@seu.edu.cn.
国家自然科学基金青年科学基金资助项目(61401085)、教育部留学归国人员科研启动基金资助项目(2015).
10.3969/j.issn.1001-0505.2016.04.001.
TP391.4
A
1001-0505(2016)04-0675-06
引用本文: 王健弘,张旭,章品正,等.基于时空信息和非负成分表示的动作识别[J].东南大学学报(自然科学版),2016,46(4):675-680.
猜你喜欢
军民两用技术与产品(2022年2期)2022-06-01
四川党的建设(2022年8期)2022-04-28
小学生学习指导(低年级)(2020年11期)2020-12-14
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
作文大王·低年级(2018年10期)2018-12-06
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
小猕猴智力画刊(2016年5期)2016-05-14
小说林(2014年5期)2014-02-28
