
基于满意模糊聚类的热工过程多模型建模方法
2016-11-21 01:02朱红霞沈炯李益国
电机与控制学报 2016年10期
朱红霞, 沈炯, 李益国
(1.南京工程学院 能源与动力工程学院,江苏 南京 211167;2.东南大学 能源与环境学院,江苏 南京 210096)
基于满意模糊聚类的热工过程多模型建模方法
朱红霞1,2, 沈炯2, 李益国2
(1.南京工程学院 能源与动力工程学院,江苏 南京 211167;2.东南大学 能源与环境学院,江苏 南京 210096)
由于热工过程往往具有非线性和不确定性,传统的线性建模方法难以精确表达其复杂特性。因此提出一种改进的基于满意模糊聚类的多模型建模方法。该方法不需要预先指定局部模型的个数即聚类数,它基于样本协方差矩阵的奇异值分解来确定初始聚类中心和新增聚类中心,并利用聚类有效性指标结合建模精确度要求来确定最佳聚类数。根据聚类结果可快速确定出局部模型网络的模型结构参数,进而采用基于加权性能指标的多模型辨识算法可得到各局部模型参数。对两个典型非线性系统和Bell-Åström锅炉-汽轮机系统的建模结果表明,这种多模型建模方法具有辨识精确度高、子模型数少等优点。
模型辨识;多模型;局部模型网络;满意模糊聚类;热工过程
0 引 言
火电厂热工过程具有周期性重复运行的特点,机组的运行数据中充分包涵了其在不同工况范围内的动态特性信息。因此,可充分利用这些运行数据,采用基于数据驱动的建模策略来建立热工过程的模型,从而为机组的优化控制奠定基础。但由于热工过程的非线性和时变性,传统的线性建模方法难以精确表达其复杂特性。近年来,基于“分解-合成”法则的多模型建模方法受到广泛关注,它将整个复杂系统分解,用若干个简单的线性子模型实现对原系统的逼近,具有众多优点[1]。多模型建模的关键问题是系统子区间的划分以及模型结构和参数的辨识,子区间划分个数决定了模型复杂度。
在数据信息充足的情况下,利用模糊聚类算法进行子区间的划分是一种最常用的方法,被广泛应用于分段仿射模型[2-3]、T-S模糊模型[4-13]等多模型建模方法中。但模糊聚类算法一般都需要事先给定聚类个数c(对应于子区间和局部模型个数),若对系统没有充分的了解,准确的c值很难直接确定。比较法和融合法是较常见的c确定方法,但它们的计算量较大且初始聚类信息的随机性大。针对该问题,李柠[13]和薛振框[14-15]等提出了基于满意聚类的多模型建模方法,以模型精确度是否满意为准则确定最佳聚类个数,它从初始聚类个数c=2开始递阶增加新的聚类,聚类过程中能充分利用以往聚类的结果。满意聚类思想比单纯依据某个聚类有效性指标最优来确定聚类个数即局部模型个数,更符合工业过程的实际要求,因为模型集的优化要考虑的是能否用最少的模型数目满足控制系统设计对模型精确度的要求,而不是单纯追求某个优化指标的绝对最小。但现有的基于满意聚类的多模型建模方法存在不足:1)初始(包括新增)聚类中心的确定未能充分利用样本集包含的特征信息,容易误选噪声数据;2)聚类终止条件设计不合理,若建模精确度指标要求过高,会导致聚类过程无法正常终止;3)完全抛弃了聚类有效性评价指标,单纯根据建模精确度确定局部模型个数,这有可能造成模型冗余。
为此,本文以局部模型网络作为多模型表达形式,提出一种新的基于满意模糊聚类的多模型建模方法,以克服现有方法的不足,更快速地获取最优模型。并通过对2个典型非线性系统和机炉协调系统的建模仿真来验证这种新建模方法的优越性。
1 局部模型网络
局部模型网络(local model networks,LMN)是一种典型的多模型表示形式[16-17]。在局部模型网络中,系统的输出描述为调度函数与其对应的局部模型乘积的总和,以反映系统输入输出之间的非线性关系。不同于一般的神经网络“黑箱”模型,LMN的结构简单,可解释性强。LMN的一种基本结构如图1所示,u(k)和y(k)分别为当前k时刻系统的输入与输出。对于R维输入S维输出的多变量系统,可用LMN描述为

(1)
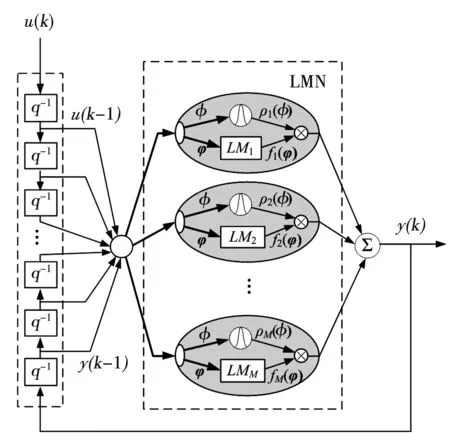
图1 局部模型网络的一种基本结构Fig.1 A basic structure of Local Model Networks
式中:M为局部模型个数;ρi(·)称为基函数,它是调度向量φ(k)∈RL的函数,因此也称为调度函数,L为φ的维数;fi(·)是输入向量φ(k)∈Rr的局部模型,r为φ的维数;调度向量φ(k)和输入向量φ(k)通常采用系统当前时刻已知的输入输出来描述;φ(k)可以取为与φ(k)相同,也可以不同。LMN的设计工作主要集中在3个方面:调度函数的选择,局部模型的选择以及模型参数的辨识。
调度函数一般选用高斯函数

(2)
式中:ci为高斯函数的中心,σi为高斯函数的宽度。
为了保证输入空间划分的统一性,调度函数需要进行归一化处理

(3)
局部模型fi(·)一般选为线性模型或仿射模型。例如,对于MIMO系统,局部模型若采用CARMA(controlledauto-regressivemovingaverage)形式
Ai(z-1)y(k)=Bi(z-1)u(k-1),
i=1,2,...,M。
(4)
其中:Ai(z-1)=I+Ai1z-1+…+AinAz-nA;Bi(z-1)=Bi0+Bi1z-1+…+BinBz-nB;Aij∈RS×S;j=1,2,…,nA;Bij∈RS×R;j=0,1,…,nB;nA和nB分别为模型输出y和输入u的阶次。
可令φT(k)=[-yT(k-1),…,-yT(k-nA),uT(k-1),…,uT(k-nB-1)]T,θi=[Ai1,…,AinA,Bi0,…,BinB]T,则式(4)可改写为

(5)
式(5)代入式(1),可得到

(6)
由式(6)可知,采用LMN描述形式的多模型建模问题,即为模型结构参数(M、ci、σi)和局部模型参数θi的辨识问题。
2 基于满意模糊聚类的多模型建模方法
考虑一R维输入单输出的MISO系统P(u,y),其中u∈RR为系统输入,y为系统输出。用于聚类的数据样本集由系统的调度向量和输出数据组成,可表示为{zk=[φT(k),y(k)]T,k=1,…,N},其中N为样本个数。调度向量φ(k)=[uT(k-1),y(k-1)]T∈RL可以理解为实际过程中的当前工况,一般选用系统当前时刻已知的输入输出来描述。这里选取G-K模糊聚类作为基本聚类算法。
2.1 初始聚类中心的确定
不同于文献[13-15]中选择数据样本集合中最不相似的两个样本作为初始聚类中心(这种方式很容易将噪声数据选为初始聚类中心导致聚类结果不理想),这里从数据样本集的内部特征信息出发,基于奇异值分解方法来确定初始聚类中心。首先计算出数据样本矩阵的单位特征向量和相应的标准差,然后在偏离整个样本集中心点的两侧确定两个新的初始聚类中心,这种方法能够在数据扩张的方向上抓住数据样本集的主要特征,通过迭代聚类快速找到最优聚类中心。
由原始样本数据构成原始数据矩阵Z

(7)
其中:矩阵中的元素


(8)
通过奇异值分解(SVD)方法计算出协方差矩阵F0的单位特征向量p0j和相应的特征值λ0j(j=1,2,…,L+1)
F0= [p01,…,p0(L+1)]diag(λ01,…,λ0(L+1))
[p01,…,p0(L+1)]-1。
(9)

(10)
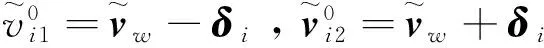
(11)
2.2 模型结构参数的确定
局部模型个数M即为聚类个数c
M=c。
(12)

(13)
σi(i=1,2,…,M)可以通过最近邻启发式算法确定,即σi取决于聚类中心viφ到最近邻的K个中心的平均距离

(14)
式中:vlφ(l=1,2,…,K)为与第i个中心viφ距离最近的K个中心,聚类个数较少时K取1或2;γ为一常数,可用于调整高斯函数的宽度。
定义Ie=[1 1 ...1]T,Ie∈Rr,则第i个局部模型的适用域可描述为
Γi∈[ci-σiIe,ci+σiIe],i=1,2,...,M。
(15)
2.3 局部模型参数的辨识
在确定了模型结构参数之后,数据集合Z中各数据样本zk的调度函数值可以通过式(3)计算得出,因此各局部模型参数θi的辨识问题也就简化为线性优化问题。目前一般采用最小二乘法来优化求解局部模型参数,为使辨识得到的模型在全局拟合和局部特性之间取得良好的权衡,这里采用基于全局和局部性能指标加权组合的多模型辨识方法。取加权性能指标[15]
JM(Θ)=αJG(Θ)+(1-α)JL(Θ)=α(Y-ΨGΘ)T(Y-ΨGΘ)+(1-α)(Y-ΨLΘ)TQ(Y-ΨLΘ)。
(16)
式中: JG(Θ)为全局性能指标;JL(Θ)为局部性能指标;α(0≤α≤1)为权重系数;

Y=[y(1),y(2),…,y(N)]T;
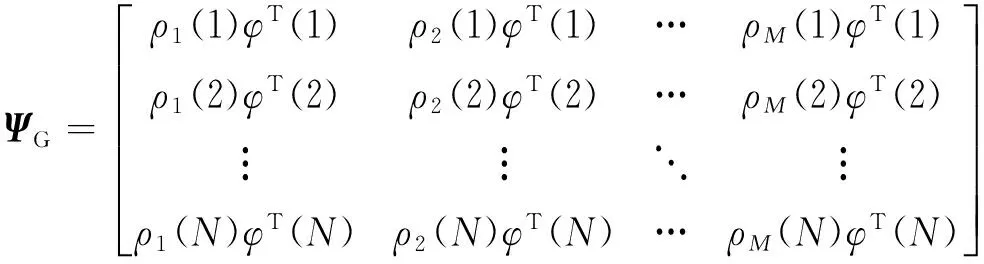


权重系数α的取值可由用户根据实际需求来确定,若更注重多模型系统的全局拟合能力,可以取较大的α值;反之,若更注重系统的局部特性,则取较小的α值。文中的仿真实例选择了α=0.8。
极小化JM可得到Θ的估计值

(17)
2.4 建模终止条件的确定
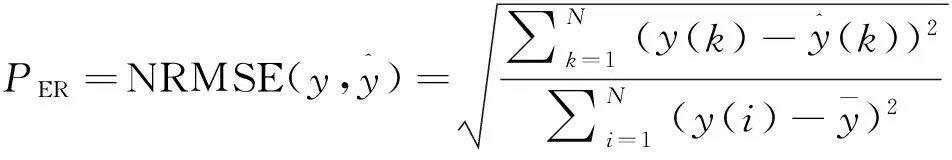
(18)
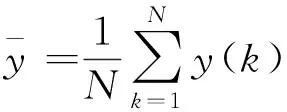
建模过程中,局部线性模型逼近第i个聚类内样本的性能用逼近误差的相对标准差σqi来估计

(19)

若局部模型个数达到某一数值时,系统的总体建模性能未达到要求,则从具有最大相对标准差的最差样本子集中重新选择2个新的初始聚类中心。
采用NRMSE作为模型精确度是否满意的性能指标时,随着局部模型个数的增加,性能指标值将呈单调非增趋势。因此,可由用户设定一个满意的性能指标阈值PER_TH,若当前模型的PER≤PER_TH,则建模过程结束。但要注意到:若用户设置的PER_TH值不合理,例如对模型精确度的要求过高,即使局部模型个数再多也不可能达到要求,此时文献[13-15]中的建模迭代过程将陷入死循环。因此,有必要设置一个允许的最大局部模型个数Cmax,若聚类个数已经达到Cmax,模型精确度仍无法到达用户的要求,则应该终止建模过程,并建议用户降低要求。此外,文献[13-15]中仅根据模型精确度要求来确定模型个数,没有能够有效利用聚类有效性指标,有可能导致出现冗余模型。
实际上在进行控制系统设计时,为了减少局部模型个数从而降低整个控制系统的复杂度,是可以在模型精确度上适当降低要求的。为此,文中建模方法采用以模型精确度指标为主,聚类有效性指标为辅的判别准则来确定最佳局部模型个数及设置建模终止条件。
这里采用XBindex作为聚类个数选择的辅助指标。聚类有效性的度量应该基于类内和类间两方面衡量。XBindex定义为整个模糊聚类方差σ与聚类类间最小分离度sep的比值[18]

(20)

好的分类应该是类内的点集中紧凑,类与类的间距尽可能大,因此XB值越小说明聚类效果越好。随着聚类个数的递增,XB可能会出现局部最小值,一般认为第一次出现局部最小对应的聚类个数是最佳的选择。
建模过程中,在每次G-K聚类结束后,计算当前聚类结果的有效性指标XB(c),并与前一次聚类的有效性指标XB(c-1)进行比较,若c=cb+1时出现XB(c)>XB(cb)而PER(c)>PER_TH0,说明数据样本分类在聚类个数为cb时已经达到最佳,而建模性能指标仍未达到要求,此时应该适当降低对建模精确度的要求,在模型复杂度和模型精确度之间进行权衡。例如,可以令PER_TH=(PER(cb)+PER_TH0)/2或者在c>cb后以一定的百分比降低建模精确度阈值。
2.5 建模步骤
这种新的基于满意模糊聚类的多模型建模方法的具体步骤为:
1)获取用户设定的PER_TH0和性能指标(16)中的权值α;设定Cmax(2Cmax;令cb=0;

4)根据M、ci、σi利用式(2)和式(3)计算每个原始数据样本对应的调度函数值ρi(i=1,…,M),同时将系统输入输出数据组合成ΨL、ΨG及Y。利用式(17)计算得到各局部模型的参数θi(i=1,…,M);
5)根据式(18)计算用户给定的模型精确度指标的当前值PER_C;若PER_C

(21)


i=1,2,…,c;k=1,2,...,N。
(22)
式中m>1为模糊度指数,通常取2。
建模过程正常结束后,系统可由局部模型集{LM1,LM2,…,LMM}表征,全局模型可用局部模型与对应的调度函数乘积和表示。
3 仿真实例
3.1 静态非线性系统
考虑一个双输入单输出的静态非线性系统[4]

(23)
采用文献[4]中提供的50组输入输出数据来辨识该非线性系统。选择调度向量和输入向量φ(k)=φ(k)=[x1(k),x2(k)]T,调度向量和输出数据组成样本集{zk=[φT(k),y(k)]T,k=1,2,…,50},图2显示了标准化后的数据样本。
局部模型LMi采用仿射ARX形式
yi(k)=φT(k)θi=
θi0+θi1φ1(k)+…+θirφr(k)。
(24)
式中:r为回归向量φ(k)的维数,θi=[θi0,θi1,…,θir]T为局部模型参数向量。
因本例中样本个数较少,设定允许的局部模型个数最大值Cmax=5。图2中标出了整个样本集的中心“★”、通过协方差矩阵奇异值分解后确定的2个初始聚类中心“●”以及第一次G-K聚类后得到的2个聚类中心“◆”。从“◆”和“●”所在位置可以看出文中提出的初始聚类中心确定方法是合理的,它能在数据扩张的方向上抓住样本集的主要特征,因而可以使算法能够更快地找到最优聚类中心。

图2 静态非线性系统标准化后的样本数据Fig.2 Normalized sample data of the static nonlinear system
若设定初始性能指标阈值PER_TH0=0.15。建模过程中模型精确度指标PER(NRMSE)和聚类有效性指标XB随聚类个数c的变化如图3所示。由于设定的初始性能指标阈值PER_TH0较小,虽然在聚类个数为cb=3时XB已到达局部最小值,但未能满足建模精确度要求,因此之后自动调整性能指标阈值PER_TH=(PER(3)+PER_TH0)/2=(0.26+0.15)/2=0.205。到c=5时,PER(5)=0.187<0.205,建模精确度满足要求,建模过程结束。若不根据聚类有效性指标XB自动调整PER_TH或者初始阈值PER_TH0设得更小,则会在局部模型个数已达到Cmax时仍无法满足模型精确度要求,建模失败。若设定PER_TH0=0.25,则在c=4时建模过程可结束,表1中列出了辨识到的局部模型网络各参数值。

表1 静态非线性系统LMN模型参数

图3 NRMSE和XB随聚类个数c的变化Fig.3 Variation of NRMSE and XB index with the number of clustering
为了与其它文献中建模方法进行对比,这里给出另一个常用的模型评价性能指标——均方差(mean square error,MSE)

(25)
表2给出了针对该系统利用不同建模方法所得模型精确度的比较,可见基于满意模糊聚类的多模型建模方法无论是在模型精确度还是局部模型个数上都具有优越性。
表2 静态非线性系统不同模型的比较
Table 2 Comparison of different models for the static nonlinear system
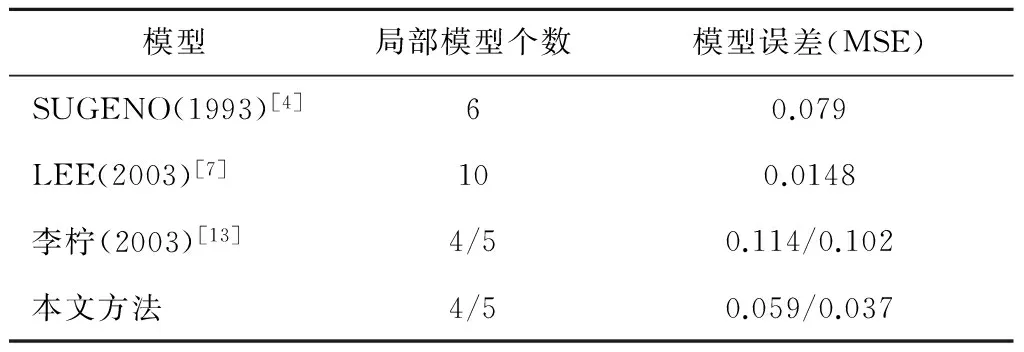
模型局部模型个数模型误差(MSE)SUGENO(1993)[4]60.079LEE(2003)[7]100.0148李柠(2003)[13]4/50.114/0.102本文方法4/50.059/0.037
3.2 Box-Jenkins煤气炉系统
Box-Jenkins煤气炉数据[19]是系统辨识的一个典型实例,这组数据由296组输入输出观测值组成,是一个SISO动态系统,其中输入u(k)为进入煤气炉的煤气流量,输出y(k)为排烟中的CO2浓度。为便于比较,进行了2组不同的测试:
case 1:选择调度向量φ(k)=[y(k-1),u(k-4)]T和输入向量φ(k)=[y(k-1),u(k-4)]T;
case 2:选择调度向量φ(k)=[y(k-1),u(k-1)]T和输入向量φ(k)=[y(k-1),y(k-2),y(k-3),u(k-1),u(k-2),u(k-3)]T。
局部模型采用如式(24)所示的仿射ARX形式,表3列出了case 1建模得到局部模型个数M=4时的LMN参数。表4列出了针对Box-Jenkins煤气炉不同建模方法的效果对比。图4显示了case 2情况下M=4时模型输出与实际数据的对比以及模型误差。
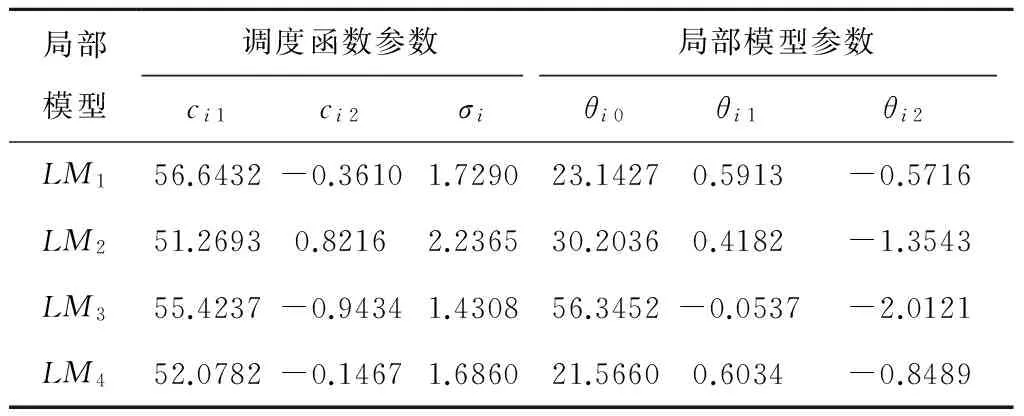
表3 Box-Jenkins煤气炉LMN模型参数(case 1)
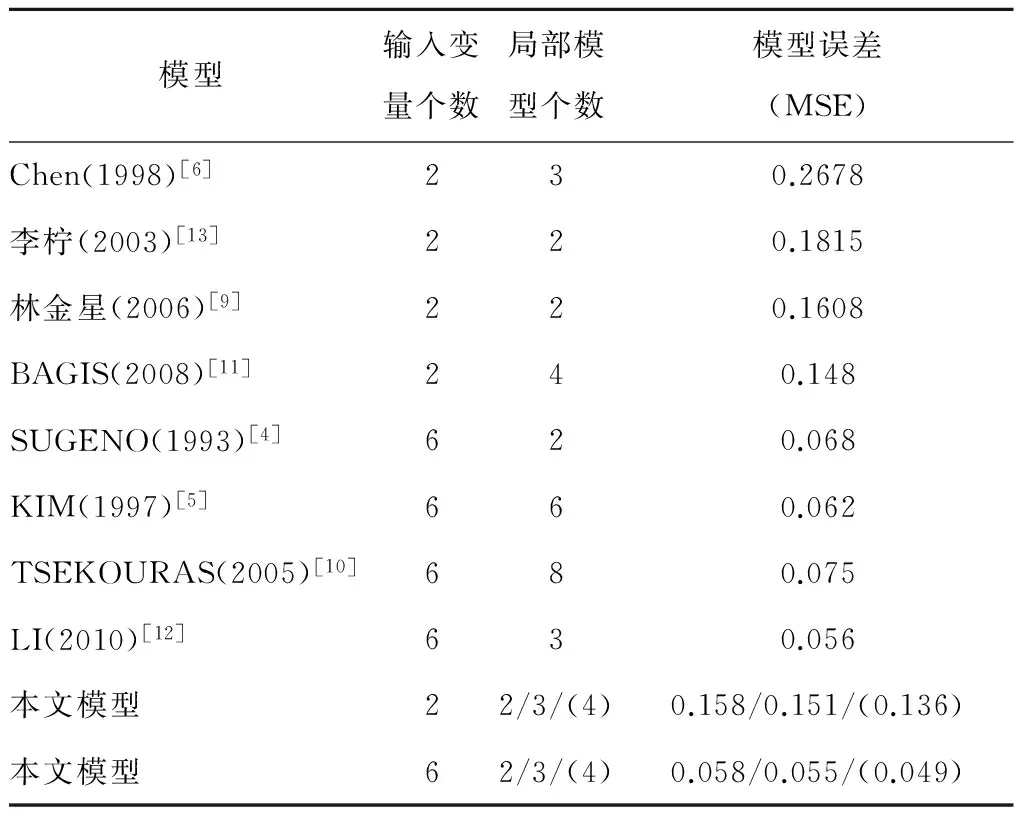
表4 Box-Jenkins煤气炉不同建模结果的比较
4 Bell-Åström锅炉-汽轮机系统的建模
Bell-Åström锅炉-汽机模型描述了瑞典Malmö Sydvenska Kraft AB电厂某160 MW燃油汽包炉机组的动态特性,该模型被大量用于验证各种先进控制方法应用于火电机组控制的有效性。该系统的非线性数学模型为[20]:



H=0.05(0.13073ρf+100αs+qe/9-67.975),

qe= (0.854u2-0.147)P+45.59u1-
2.514u3-2.096。
(26)
式中:P是锅炉汽包压力(kg/cm2);E是机组发电功率(MW);ρf是流体密度(kg/cm3);H是汽包水位(m);αs和qe分别为蒸汽质量系数和蒸发率(kg/s);u1、u2、u3分别为系统的3个控制输入,即燃料流量阀门开度、蒸汽流量阀门开度和给水流量阀门开度。u1、u2、u3的幅值及速率限制见文献[20]。P、E、H为系统的3个输出变量。

图4 Box-Jenkins煤气炉模型输出与实际输出的比较(case 2)Fig.4 Comparison of model outputs and practical output data for Box-Jenkins gas furnace (case 2)
为了使系统的输出数据能覆盖整个运行工况(典型工况点数据见文献[20]),输入信号必须满足持续激励的条件。这里选择一种宽度和幅值均可调的均匀分布随机数序列生成3个控制输入u1、u2、u3的激励信号,以充分激励各操作子区间,并分别采集了如图5所示的7000组数据样本(采样时间T=1 s)用于模型辨识,相应的系统输出响应见图6~图8。
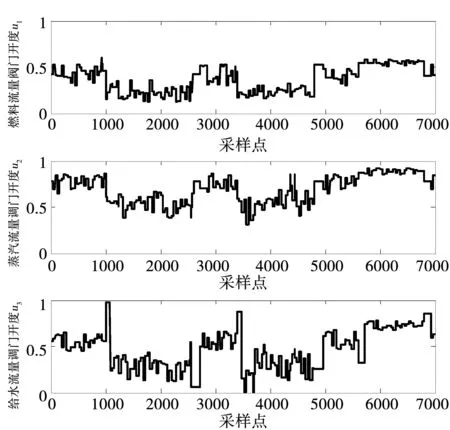
图5 用于锅炉-汽轮机系统模型辨识的激励输入信号Fig.5 Excitation input signals for model identification for the boiler-turbine unit

图6 汽包压力通道模型辨识结果Fig.6 Model identification result for drum pressure
针对该MIMO非线性系统,选择调度向量φ(k)=[P(k-1),E(k-1),H(k-1),u1(k-1),u2(k-1),u3(k-1)]T,用于LMN模型结构辨识的聚类数据样本集由系统的调度向量和输出数据组成{zk=[φT(k),P(k),E(k),H(k)]T,k=1,2,…,6998};在进行局部模型参数辨识时,分解为3个MISO系统:
1)对于汽包压力通道辨识模型,选取样本输入向量为φ1(k)=[P(k-1),u1(k-1),u2(k-1),u3(k-1)]T,样本输出变量为y1(k)=P(k);
2)对于输出电功率通道辨识模型,选取样本输入向量为φ2(k)=[E(k-1),E(k-2),u1(k-1),u2(k-1),u2(k-2),u3(k-1)]T,样本输出变量为y2(k)=E(k);
3)对于汽包水位通道辨识模型,选取样本输入向量为φ3(k)=[H(k-1),u1(k-1),u2(k-1),u3(k-1)]T,样本输出变量为y3(k)=H(k)。
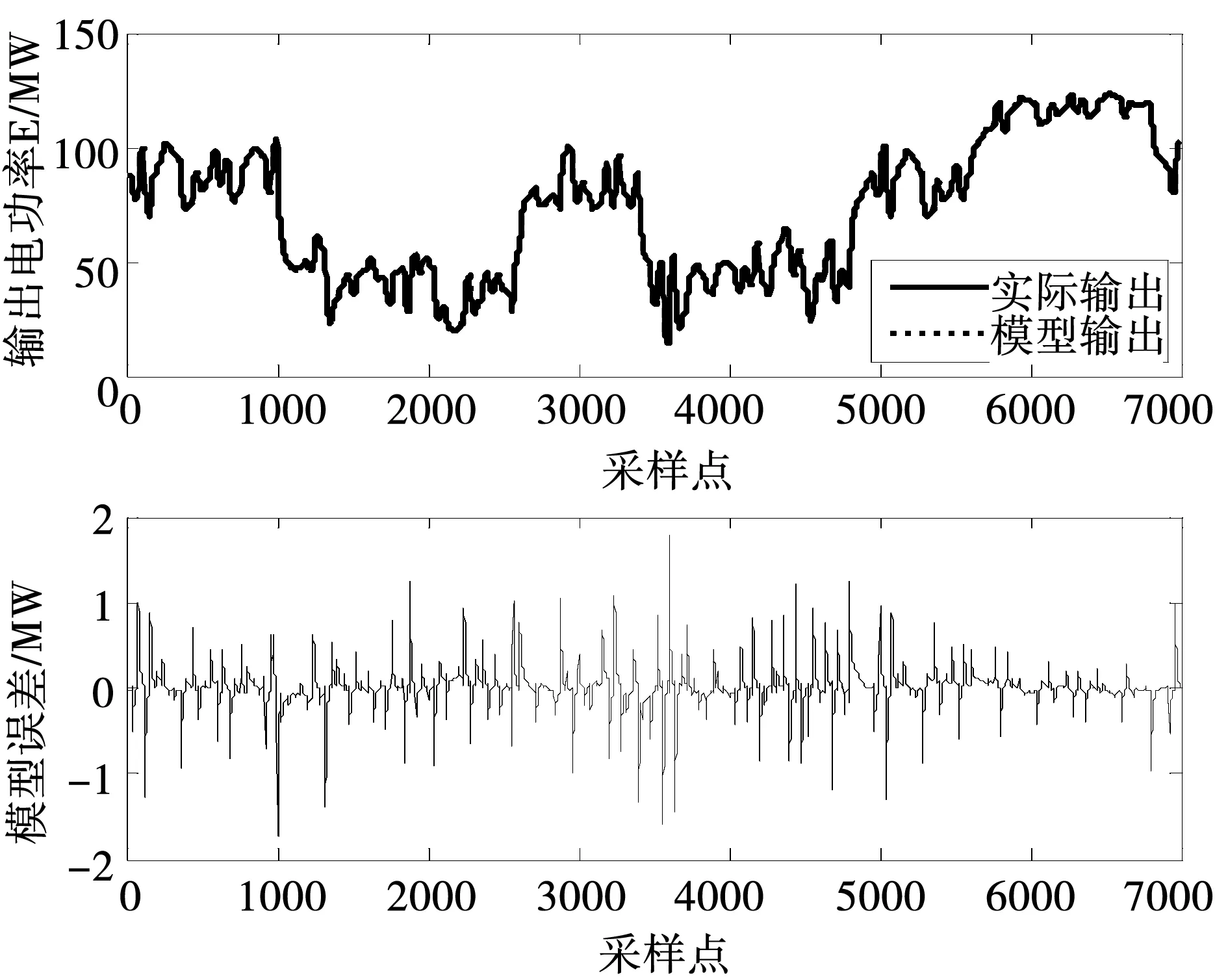
图7 输出电功率通道模型辨识结果Fig.7 Model identification result for Power Output
利用基于满意模糊聚类的多模型建模方法,当局部模型个数即聚类数增加到M=3时就可以得到令人满意的建模精确度,辨识得到的LMN模型为:
LM1:φ(k)∈Γ1(c1,22.96),
c1= [100.93,45.59,0.0133,0.2516,0.5588,
0.3097]T,
P(k)= 0.9997P(k-1)+0.8632u1(k-1)-
0.2495u2(k-1)-0.1543u3(k-1),
E(k)= 1.6897E(k-1)-0.7185E(k-2)-
0.3987u1(k-1)-0.9505u2(k-1)+
3.3904u2(k-2)-0.1706u3(k-1),
H(k)= 0.9858H(k-1)+0.0075u1(k-1)-
0.0019u2(k-1)+0.0005u3(k-1),
LM2:φ(k)∈Γ2(c2,15.17)
c2= [112.98,74.32,0.0033,0.3863,0.7122,
0.4723]T,
P(k)= 0.9982P(k-1)+0.9474u1(k-1)-
0.1360u2(k-1)-0.1162u3(k-1),
E(k)= 1.3497E(k-1)-0.4335E(k-2)+
0.0793u1(k-1)+0.8488u2(k-1)+
7.4967u2(k-2)+0.6694u3(k-1),
H(k)= 0.9992H(k-1)+0.0003u1(k-1)-
0.0050u2(k-1)+0.0085u3(k-1)。
LM3:φ(k)∈Γ3(c3,22.55),
c3= [123.70,101.84,0.0433,0.4856,0.8287,
0.6427]T,
P(k)= 1.0005P(k-1)+0.7323u1(k-1)-
0.3451u2(k-1)-0.2141u3(k-1),
E(k)= 1.7281E(k-1)-0.7529E(k-2)+
1.2306u1(k-1)-0.2023u2(k-1)+
2.4586u2(k-2)+0.2365u3(k-1),
H(k)= 0.9921H(k-1)+0.0184u1(k-1)-
0.0068u2(k-1)-0.0056u3(k-1)。
图6~图8分别给出了汽包压力通道、输出电功率通道、和汽包水位通道的建模效果。为进一步验证所建模型的精确度,进行开环阶跃扰动响应测试,结果如图9所示。图中模型输出与实际输出信号几何完全重合(实线:对象实际输出;点线:模型输出),所建的LMN虽然只用了3组局部线性模型,就已具有了很高的预测精确度,能够很好地描述锅炉-汽轮机系统的动态特性,为机炉协调控制系统的优化设计提供了良好的模型基础。

图9 输入信号阶跃扰动下的测试结果Fig.9 Testing result for step variations of the input signals
5 结 论
本文从系统输入输出数据出发,研究了一种新的多模型建模方法并将其应用于建立锅炉-汽轮机系统的控制模型。针对现有方法在初始聚类中心选取和建模过程终止条件设置等方面的不足进行了改进,提出了基于样本数据协方差矩阵奇异值分解来确定初始和新增聚类中心的方法及利用模型性能指标和聚类有效性指标结合的建模终止条件来确定最佳聚类数的方法。基于改进的满意模糊聚类可快速确定出局部模型网络的结构参数,采用基于加权性能指标的多模型辨识算法可得到合适的局部模型参数,最终得到的LMN模型具有良好的全局特性和局部拟合能力。对某静态非线性系统和Box-Jenkins煤气炉系统的建模仿真,验证了这种多模型建模方法的优越性。针对Bell-Åström锅炉-汽轮机系统,利用提出的多模型建模方法建立了其局部模型网络,建模过程中不需要预先指定局部模型的个数,且辨识得到的模型结构简单、精确度高。可见,本文方法可为复杂热工过程的整体优化控制奠定良好的模型基础。
[1] MURRAY S R,JOHANSEN T A.Multiple model approaches to modeling and control[M].Taylor and Francis Ltd,1997.
[2] FERRARI T G,MUSELLI M,LIBERATI D,et al.A clustering technique for the identification of piecewise affine systems[J].Automatica,2003,39(2): 205-217.
[3] GHOSH S,MAKA S.A fuzzy clustering based technique for piecewise affine approximation of a class of nonlinear systems[J].Communications in Nonlinear Science and Numerical Simulation,2010,15(9): 2235-2244.
[4] SUGENO M,YASUKAWA T.A fuzzy logic based approach to qualitative modeling[J].IEEE Transactions on Fuzzy Systems,1993,1(1): 7-31.
[5] KIM E,PARK M,JI S,et al.A new approach to fuzzy modeling[J].IEEE Transactions on Fuzzy Systems,1997,5(3):328-337.
[6] CHEN J Q,XI Y G,ZHANG Z J.A clustering algorithm for fuzzy model identification[J].Fuzzy Sets and Systems,1998,98(3):319-329.
[7] LEE S J,OUYANG C S.A neuro-fuzzy system modeling with self-constructing rule generation and hybrid SVD-based learning[J].IEEE Transactions on Fuzzy Systems,2003,11(3):341-353.
[8] WU X,SHEN J,LI Y,et al.Data-driven modeling and predictive control for boiler-turbine unit using fuzzy clustering and subspace methods[J].ISA Transactions,2014,53(3): 699-708.
[9] 林金星,沈炯,李益国.基于递阶G-K聚类的热工过程多模型建模方法[J].中国电机工程学报,2006,26 (11):23-28.
LIN Jinxing,SHEN Jiong,LI Yiguo.Multi-model Modeling Method based on hierarchical G-K clustering for thermal process[J].Proceedings of the CSEE,2006,26 (11): 23-28.
[10] TSEKOURAS G E.On the use of the weighted fuzzy c-means in fuzzy modeling[J].Advances in Engineering Software,2005,36(5):287-300.
[11] BAGIS A.Fuzzy rule base design using tabu search algorithm for nonlinear system modeling[J].ISA Transactions,2008,47(1):32-44.
[12] LI C,ZHOU J,LI Q,et al.A new T-S fuzzy-modeling approach to identify a boiler-turbine system[J].Expert Systems with Applications,2010,37(3):2214 -2221.
[13] 李柠,李少远,席裕庚.基于满意聚类的多模型建模方法[J].控制理论与应用,2003,20(5):783-787.
LI Ning,LI Shaoyuan,XI Yugeng.Multi-model modeling method based on satisfactory clustering[J].Control Theory & Applications,2003,20(5):783-787.
[14] XUE Z,LI S.A muti-model identification algorithm based on weighted cost function and application in thermal process[J].Acta Automatica Sinica,2005,31(3):470-474.
[15] 薛振框,李少远.MIMO非线性系统的多模型建模方法[J].电子学报,2005,33(1):52-56.
XUE Zenkuang,LI Shaoyuan.A Multi-model modeling approach to MIMO nonlinear systems[J].Acta Electronica Sinica,2005,33(1):52-56.
[16] JOHANSEN T A,FOSS B A. A NARMAX model representation for adaptive control based on local models[J].Modeling,Identification and Control,1992,13(1):25-39.
[17] TESLIC L,HARTMANN B,NELLES O,et al.Nonlinear system identification by gustafson-kessel fuzzy clustering and supervised local model network learning for the drug absorption spectra process[J].IEEE Transactions on Neural Networks,2011,22(12):1941-1951.
[18] XIE X L,BENI G.A validity measure for fuzzy clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1991,13(8):841-847.
[19] BOX G E P,JENKINS G M.Time series analysis,forecasting and control[M].San Francisco,CA: Holden Day,1970.
[20] BELL R D,ASTROM K J.Dynamic models for boiler-turbine alternator units: data logs and parameter estimation for a 160 MW unit[R].Lund Institute of Technology,Sweden,Report:TFRT-3192,1987.
(编辑:贾志超)
Satisfactory fuzzy clustering-based multi-model modeling method for thermal process
ZHU Hong-xia1,2, SHEN Jiong2, LI Yi-guo2
(1.School of Energy and Power Engineering,Nanjing Institute of Technology,Nanjing 211167,China;2.School of Energy and Environment,Southeast University,Nanjing 210096,China)
Due to the genuine nonlinearity and uncertainty,it is challenging to precisely present the complex dynamics of thermal process with traditional linear modeling strategies.To solve this problem,a multi-model modeling method based on an improved satisfactory fuzzy clustering technique is proposed.Without knowing the number of local models (i.e.,cluster number) as a priori,the initial cluster centers and the incoming new cluster centers were first created by using singular value decomposition of the covariance matrix of samples,where the optimal clustering number was determined according to the combination of model accuracy requirement and cluster validity index.Then,the structure of local model network was determined directly from the clustering results,and the local model parameters were estimated with weighted performance function based identification algorithm.To outperform the proposed method well,some simulations were conducted on two popular nonlinear systems and Bell-Åström boiler-turbine system.The results suggest that the proposed method achieves high identification accuracy with less number of local models.
model identification; multi-model; local model network; satisfactory fuzzy clustering; thermal process
2015-07-05
国家自然科学基金(51476027);教育部高等学校博士学科点专项科研基金(20130092110061);南京工程学院青年基金(QKJA201303)
朱红霞(1980—),女,博士,副教授,研究方向为热力系统建模及先进控制理论应用;
沈 炯(1957—),男,博士,教授,博士生导师,研究方向为热工过程优化控制;
朱红霞
10.15938/j.emc.2016.10.013
TP 273
A
1007-449X(2016)10-0094-10
李益国(1973—),男,博士,教授,博士生导师,研究方向为热工过程优化控制。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
云南教育·中学教师(2020年11期)2021-01-07
山东煤炭科技(2020年1期)2020-03-06
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
铁道通信信号(2019年6期)2019-10-08
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
