
一种结合评分时间特性的协同过滤推荐算法
2016-12-15 02:47李圣秋吴伟明谷勇浩
软件 2016年11期
李圣秋,吴伟明,谷勇浩
(北京邮电大学 计算机学院,北京市 100876)
一种结合评分时间特性的协同过滤推荐算法
李圣秋,吴伟明,谷勇浩
(北京邮电大学 计算机学院,北京市 100876)
用户评分是协同推荐算法实现未知评分预测的主要依据,传统协同推荐算法一般只利用评分的数值,而忽视评分产生时间对推荐的作用,但是评分时间特性对推荐系统准确性的影响不容小觑。本文针对这个问题,以传统协同过滤推荐算法为基础,从评分时间角度对推荐算法的相似度计算和评分预测过程进行改进,提出了一种结合评分时间特性的协同过滤推荐算法。算法依据用户对项目的评分及时间计算出一个时间因子,并将时间因子融入到相似度的计算中, 使推荐给目标用户的项目更加合理。通过实验进行该算法与现有协同推荐算法的对比,验证了该算法在提高推荐准确性方面的有效性。
推荐系统;协同过滤;时间权重;评分预测
本文著录格式:李圣秋,吴伟明,谷勇浩. 一种结合评分时间特性的协同过滤推荐算法[J]. 软件,2016,37(11):142-145
0 引言
互联网的迅速发展将人们带入了一个崭新的信息时代,网络中的信息资源越来越丰富,当用户面对海量的数据信息时,如何在茫茫的信息海洋中快速、准确地找到需要的信息成为用迫切需要解决的问题。搜索引擎的出现在一定程度上缓解了用户的信息负担,但搜索引擎往往呈现给用户同样的搜索结果,无法针对用户的兴趣爱好主动提供个性化服务。在此背景下,推荐系统应运而生。概括来说,推荐系统以用户为中心,通过研究用户的行为、偏好和环境等因素,过滤与用户偏好不相关的内容,为用户推荐更具针对性、满足其个性化需求的信息。常用的推荐方法有基于内容的推荐、基于知识的推荐、协同过滤推荐以及组合推荐等,其中协同过滤推荐是迄今为止应用最成功的个性化推荐技术之一[1],
其基本思想是:通过计算用户对项目评分之间的相似性,搜索目标用户的最近邻居,然后根据最近邻居的评分向目标用户产生推荐。
然而用户的兴趣偏好是随着时间动态变化的,这就需要推荐系统能实时地向用户推荐新颖的资源[2]。但传统的协同过滤推荐算法并没有考虑用户的兴趣随时间的推移而发生变化,导致推荐的信息可能是过时的或不是用户当前最感兴趣的信息,影响了算法的准确性。因此,本文在传统协同过滤算法的基础上,提出了一个改进的结合了评分时间特性的协同过滤推荐算法,并利用实验对传统算法和本文提出的改进算法的准确度进行了比较。实验结果表明,结合了评分时间特性的推荐算法提高了推荐的准确度。
1 基于项目的协同过滤推荐算法
协同过滤算法根据用户的历史评分数据进行推荐,一般来说分为基于用户的协同过滤(User Based Collaborative Filtering,UserCF)和基于项目的协同过滤(Item Based Collaborative Filtering,ItemCF)。
UserCF从用户角度出发,按照“相似用户共享兴趣”的思想;为了确定相似用户,UserCF需要根据用户对不同信息项目的历史评分,计算不同用户之间的相似度,但用户相似性较不稳定,用户相似度一般需要在线计算和更新,这导致UserCF的在线性能难以保证,限制了UserCF在大型信息服务系统中应用。ItemCF从项目角度出发,服从“用户未来兴趣与历史兴趣相似”的假设,为确定与目标用户已访问项目的相似项目,ItemCF需要计算项目间相似度,较之于用户相似度,项目相似性更为稳定,ItemCF的相似度计算可离线计算,ItemCF可提供比UserCF更高的响应速度[3]。相似度模型是决定算法推荐效果好坏的关键,传统的相似度度量方法有余弦相似度(Cosinimilarity,Cosin)、Jaccard 相似度(Jaccard Similarity,Jaccard)和皮尔逊相关系数[4]等。
鉴于ItemCF的性能优势,其在学术和实际应用中得到了大量研究和实践,本文的研究内容将以ItemCF作为基准协同过滤推荐算法。
基于物品的协同过滤推荐算法主要分为两步[5]:
1)计算物品之间的相似度;
2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
具体的过程是首选需要获取用户代理捕获并记录用户对已访问项目的评分数据,并以用户描述向量形式表示用户兴趣,所有用户描述向量按行构造为用户-项目评分矩阵;根据用户-项目评分矩阵,采用特定的相似性度量标准,计算不同项目之间的相似度;参考项目间相似度计算的结果,确定与目标项目相似的邻居项目;针对目标用户的每一未评分目标项目,根据其邻居项目的评分,以邻居项目与目标项目的相似度为权重,对邻居项目评分进行加权求和预测用户对目标项目的评分;依据对目标项目所预测的评分值大小,对目标用户的所有未评分项目进行降序排序,进而选择Top-N项目构成推荐列表,并主动推荐给目标用户。
一个m*n的用户-项目评分矩阵Rm*n,见表1。
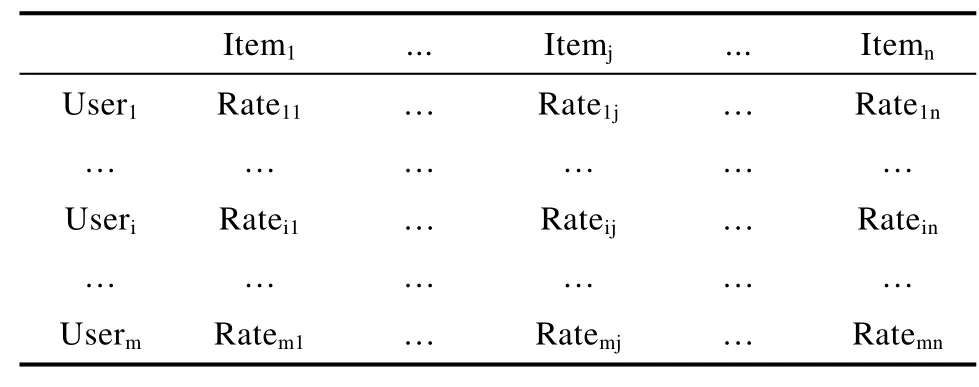
表1 用户-项目评分矩阵示例Tab.1 An Example of User-Item Rating Matrix
其中,Useri表示第i个用户,Itemj表示第j个项目,Rateij表示第i个用户对第j个项目的评分,总共有m个用户n个项目。
为了确定目标项目的邻居项目,ItemCF通过一定的相似度来度量项目间的相似性,常用的相似度计算方法有夹角余弦相似度和皮尔逊相关系数,鉴于皮尔逊相关系数不受评分分布的影响,其在实际应用中使用更为广泛[6],故本文采用皮尔逊相关系数计算项目间的相似度。
对于两个项目Itemi与Itemj,其皮尔逊相关系数sim(i,j)可表示为:

其中Uij指的是Itemi与Itemj的公共评分用户集,和分别表示Itemi与Itemj的平均评分值。在得到项目之间的相似度后,ItemCF通过如下公式计算用户ui对一个项目sj的兴趣:
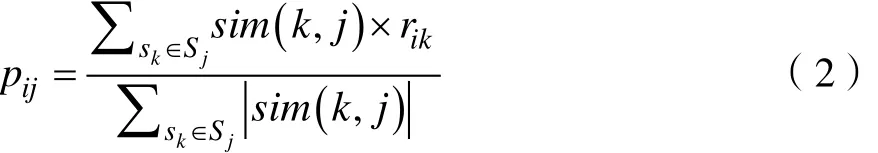
其中sim(k,j)即是Itemk和Itemj的相似度,Sj是用户喜欢的项目的集合,rik是用户ui对项目Itemk
的兴趣度。使用公式(2)这样处理的结果是和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
2 改进算法
2.1 时间效应
传统协同过滤算法在寻找用户的最近邻居时,将用户不同时间的项目评分同等对待,没有考虑用户对各个项目的评分不是在同一时间段进行的实际情况[7]。一般来说,用户近期访问过的项目对推荐该用户未来可能感兴趣的项目起比较重要的作用,而早期的访问记录对生成推荐结果影响相对较小,这是因为用户的兴趣偏好随时间发生改变,而在较短的一段时间间隔内用户的兴趣相对稳定。因此一个用户感兴趣的项目最可能和他近期访问过的项目相似。也就是说,虽然所有评价都对推荐结果有影响,但最新评价贡献更大,旧数据反映用户以前的喜好,它在推荐的预测上应占较小的权值。
2.2 评分时间因子
根据前面的讨论,传统ItemCF算法在实现相似度计算和评分预测过程中只参考了评分的数值信息,对于可从时间角度反映用户兴趣变化的评分时间信息并未充分利用,过期的历史评分数据不仅不能反映用户的当前兴趣,还干扰了当前的相似度计算和评分预测,导致ItemCF无法产生满足用户当前信息需求的推荐[8]。针对上述问题,应对传统ItemCF算法的关键计算过程进行改进和修正,引入对评分时间特性的应用,针对用户ui对项目Itemj产生的评分rij,可采用公式(3)形式的评分时间因子wij对该评分在时间方面的重要性加以区分。
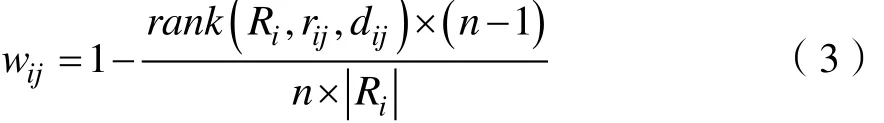
公式(3)中用户ui产生的所有评分构成其评分集合Ri={rik|rik≠0∧k∈n},dij为评分rij对应的产生时间,为了克服不同用户评分在绝对物理时间上存在的差异,公式(3)采用rank函数将评分绝对物理时间映射为评分在评分时间序列上的相对位置编号,公式(3)按照历史评分产生的时间对评分的重要性进行了线性衰减,其取值为(0…1)之间的小数。
2.3 ItemCF算法集成评分时间因子
通过在传统ItemCF算法中引入评分时间因子,可以更全面地利用用户评分信息改善相似度的计算和评分预测过程。改进后的皮尔逊相关系数和评分预测方法如公式(4)和公式(5)所示。
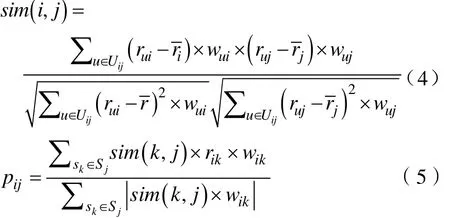
改进后算法的流程如下:
输入:
用户集合U={ui|1≤i≤m}
项目集合S={sj|1≤j≤n}
用户-项目评分矩阵Rm*n
输出:
目标用户u的Top-N项目推荐列表
Step1:根据用户-项目评分矩阵R利用公式(3)计算评分rij对应的评分时间因子wij;
Step2:根据项目集合S,利用公式(4)计算项目si与sj的相似度sim(i,j);
Step3:统计项目si所获得的非0评分数量ci,根据与项目si的相似度,对所有其他项目进行降序排序,并选择前K个项目作为项目si的邻居项目集合Si;
Step4:根据公式(5)预测用户ui对项目sj的评分pij
Step5:将步骤4中项目的预测评分按照降序从大到小的排列,最后选择排在最前面评分最高的前n个项目推荐给用户u。
3 实验与结果分析
3.1 实验数据及实验环境
本文采用由 Minnesota大学的GroupLens研究小组创建的MovieLens数据集中的100K的数据集进行实验。该数据集记录共943个用户对1 682部电影的10万条评分[9]。评分的分值在[0-5]之间不等,用户对电影的喜爱程度随着分值的增加而递增[10]。从数据集中随机抽取80%作为训练集,剩余20%作为测试集。
实验软硬件环境是Intel(R) Pentium(TM) CPU G2030 3 GHz,4 GB内存,Microsoft Windows10操作系统,算法使用Matlab实现。
3.2 检验指标
本文采用平均绝对误差(MAE)评价该系统的推
荐质量[11]。MAE 通过计算实际评分与预测评分之间的差值来衡量算法的好坏。MAE值越小说明该算法就越好。MAE值的计算如公式(6)所示。
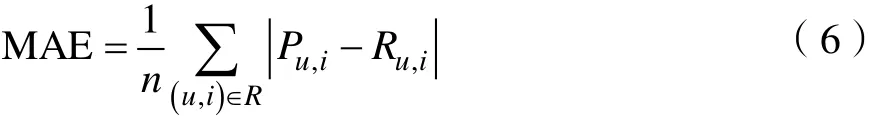
其中,Pu,i表示用户u对项目i的预测评分,Ru,i表示用户u对项目i的真实评分,n表示Pu,i或者Ru,i的数量。
3.3 结果与分析
为了验证本文提出的基于用户评分时间改进的协同过滤推荐算法的有效性,进行实验对比。在MovieLens数据集上对改进的算法与传统的基于项目的协同过滤推荐算法的推荐准确性进行了比较。MAE值随不同的最近邻数目的变化情况如图1所示。
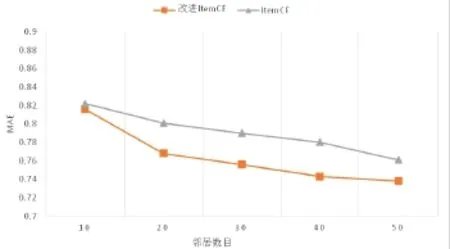
图1 不同邻居数目下ItemCF和改进算法的MAE对比Fig.1 MAE comparison of ItemCF and improved algorithm with different number of neighbors
从图1中可以看出,结合评分时间特性改进的协同过滤推荐算法在最近邻项目个数分别为10、20、30、40、50的MAE值均小于传统的基于项目的协同过滤推荐算法。MAE值平均降低2%。由此可见,在相似度的计算中结合用户的评分时间特性后推荐效果的准确性得到了提高。
4 结束语
本文针对传统ItemCF算法没有对评分的时间信息加以利用的不足,提出了结合评分时间特性的协同过滤推荐算法。该算法通过在相似度计算和评分预测中引入评分时间因子,从时间特性角度对用户历史评分的重要性加以区分,充分体现了评分时间特性对协同过滤推荐的重要影响。本文也通过实验验证了改进后的算法在提高推荐准确性方面的有效性。
[1] 项亮. 推荐系统实践[M], 北京: 人民邮电出版社, 2012.
[2] 曹一鸣. 协同过滤推荐瓶颈问题综述[J]. 软件, 2012, 12: 315-321.
[3] 蔡雄峰, 艾丽华, 丁丁. 一种缓解协同过滤算法数据稀疏性的方法[J]. 软件, 2015, 03: 41-47.
[4] 刘青文. 基于协同过滤的推荐算法研究[D]. 北京: 中国科学技术大学, 2013.
[5] 颜龙杰. 基于近邻评分预测的协同过滤推荐算法[J]. 软件, 2013, 34(8): 63-66.
[6] 郭清菊, 周让明, 马俊涛. 基于学习兴趣的个性化推荐算法研究[J]. 软件, 2013, 34(9): 51-53.
[7] 李源鑫, 肖如良, 陈洪涛, 等. 时间衰减制导的协同过滤相似性计算[J]. 计算机应用系统, 2013, 22 (11): 129-133.
[8] Zhu Min, Yao Shuzhen. A Collaborative Filtering Recommender Algorithm Based on the User Interest Model. Computational Science and Engineering(CSE), 2014 IEEE 17th International Conference on 19-21 Dec. 2014.
[9] 严冬梅, 鲁城华. 基于用户兴趣度和特征的优化协同过滤推荐[J]. 计算机应用研究, 2012, 29(2): 497-500.
[10] 吴月萍, 郑建国. 改进相似性度量方法的协同过滤推荐算法[J]. 计算机应用与软件, 2011, 28( 10) : 7-8, 42.
[11] 文俊浩, 舒珊. 一种改进相似性度量的协同过滤推荐算法[J]. 计算机科学, 2014, 41(5): 68-71.
A Collaborative Filtering Recommendation Algorithm in Combination with Rating Time Characteristic
LI Sheng-qiu, WU Wei-ming, GU Yong-hao
(School of Computer Science, Beijing University of Posts and Telecommunications, Beijing 100876, China)
User rating is the main basis for cooperative recommendation algorithm to achieve the unknown score prediction. Traditional collaborative recommendation algorithm usually only use the score value while ignoring the effect of score generation time on recommendation. However the impact of scoring time characteristics on the accuracy of recommendation system can not be underestimated. In this paper, we propose a new collaborative filtering recommendation algorithm based on the traditional collaborative filtering recommendation algorithm, which improves the similarity calculation and the score forecasting process of the recommendation algorithm from the scoring time angle. The algorithm calculates a time factor based on the user’s score and time of the project, and integrates the time factor into the calculation of the similarity, which makes the recommendation to the target user more reasonable. The experiment is compared with the existing collaborative recommendation algorithm to verify the effectiveness of the algorithm in improving the recommendation accuracy.
Recommendation system; Collaborative filtering; Time weight; Rating prediction
TP391
A
10.3969/j.issn.1003-6970.2016.11.031
李圣秋(1993-),男,硕士研究生,主要研究方向:现代网络管理、移动互联网;吴伟明,女,教授,主要研究方向:现代网络管理、移动互联网;谷勇浩,男,讲师,主要研究方向:移动互联网、网络安全。
吴伟明,教授,主要研究方向:现代网络管理、移动互联网。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
商用汽车(2016年11期)2016-12-19
中国卫生(2016年5期)2016-11-12
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
创业家(2015年5期)2015-02-27
