
基于位置权重的歌词情感分析
2018-02-12 12:24杜敦英竹翠朱文军赵枫朝
软件导刊 2018年12期
关键词:支持向量机
杜敦英 竹翠 朱文军 赵枫朝


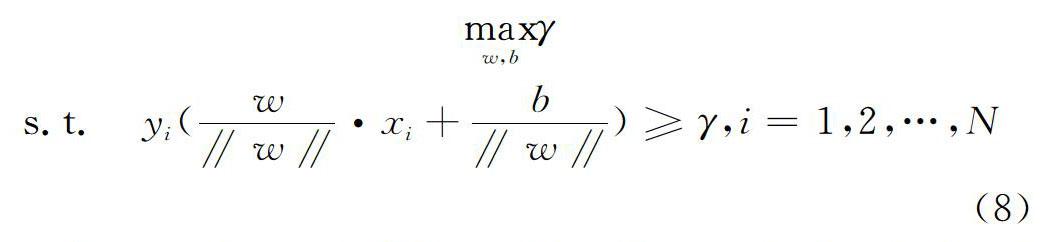
摘要:结合目前从音频和歌词角度对歌曲情感分析的研究以及歌词文本独有特点,提出一种基于文本标题与位置权重相结合的歌词情感分析方法。该方法考虑到出现在不同位置的特征词权值对于歌词分类的影响程度,采用层次分析法计算文本标题、歌词文本前、中、后不同位置特征词的位置权重。通过朴素贝叶斯、最大熵模型、支持向量机等不同分类器的训练实现歌曲快乐、伤感、安静、激昂4种情感分类。实验表明,加入文本标题与位置权重后的最优F1值相比之前提升了4个百分点,证明了该方法在提升歌词情感分类性能方面的有效性。
关键词:歌词情感分析;情感分类;朴素贝叶斯;最大熵模型;支持向量机;位置权重
Research on Lyric Sentiment Analysis Based on Position Weight
DU Dun ying,ZHU Cui,ZHU Wen jun,ZHAO Feng chao
(Department of Informatics,Beijing University of Technology,Beijing 100124,China)
Abstract:Combining the current research on emotional analysis of songs from the perspective of audio and lyrics and the unique characteristics of lyrics text,we propose a method on lyrics sentiment analysis which is based on the text title and position weight.The algorithm takes into account of the influence degree of the feature words appearing in different positions on the classification of the songs. AHP is used to calculate the position weights of the text title, the front, middle and back of the text in different positions and trained by the NB, ME, SVM different classifier ,songs are finally divided into four emotional classification including happiness, sadness, quietness and passion. Experiments show that the optimal F1 value after adding the text title and position weight is increased by 4 percentage points, which proves the effectiveness of this method in enhancing the performance of lyric sentiment classification.
Key Words:lyric sentiment analysis; sentiment classification;NB;ME;SVM; position weight
0 引言
隨着人工智能、模式识别技术的飞速发展和人民生活品质的提高,音乐成为生活中必不可少的交流媒介之一。音乐通常蕴含丰富的情感,由于信息检索系统及音乐推荐系统的需要,情感分类技术[1 4]应运而生并成为当今研究热点。
歌曲可以通过演唱风格、音乐编曲形式、歌词等多角度表达歌曲情感。歌曲情感分类研究主要基于音频分析[5]、歌词分析以及两者相结合的研究形式。对于一首广为流传的歌曲,副歌部分往往传唱度最高,强烈的情感从该处体现,因此每首歌不同词的位置对于整首歌曲情感的表达有重要作用。本文将歌词文本分为开头、中间、结尾3个部分以区分不同位置的特征词,然后结合标题与歌词文本开头、中间、结尾4个不同位置,通过计算位置因子,采用不同分类模型融合探究歌词情感分类问题。
1 相关研究
目前,对歌曲情感的分类研究大都从音频和歌词的角度进行分析,在音频研究中,常见通过从音乐节奏、旋律音频数据中提取相关情感特征进行歌曲情感分析。Lee J Y等[6]在2014年提出基于音乐高光检测的音乐情感分类方法,应用高斯混合模型和AdaBoost算法,将节奏特征与音色特征相结合并基于音乐高光片段改善音乐情感分类性能。2015年,赵伟[7]以多音轨角度为出发点,提取声学5个方面的特征,利用BP神经网络模型进行100多次训练,最后将音乐情感分为8个类别,在给定误差范围内准确率大于90%,取得了较好效果。2017年,Lin 等[8]提出基于two-level的支持向量机模型的音乐情感识别系统,以二分法为每个音乐剪辑分配一个情感类别,将流行、摇滚、爵士、蓝调等不同类型的音乐进行快乐、悲伤、平静、愤怒4种类别的情感分类,也取得了不错的效果。在歌词研究方面,2008年He 等[9]着眼于如何在歌词本文中提取有意义的语言特征以辅助进行音乐情感分类,在著名的n-gram语言模型框架下,提出了3种预处理方法和一系列具有不同阶数的语言模型以提取更多的语义特征。王静[10]在基于歌词的音乐情感分析中采用ME、SVM、LDA 3种分类模型研究歌词对情感分类的影响。Turney[11]提出了无监督学习逐点互信息情感分类方法,通过把每篇文本中的所有具有情感倾向的短语的情感倾向值相加,根据平均情感倾向判断文本整体情感倾向。夏云庆等[12]提出基于情感向量空间模型的歌词情感分析方法,该模型考虑了特征定义中的情感单元,采用更具有区分性的支持向量进行歌曲情感分类研究,结果显示基于文本的方法比基于音频的方法更有效[13]。在结合歌词分析与音频分析的研究中,2011年,孙向琨[14]提出基于向量夹角的多标记k近邻算法,将该方法与TF-IDF算法结合,以情感词多义性为研究对象进行音乐情感分类研究。2012年,程一峰[15]提出基于TF-IDF音频和歌词特征融合模型的音乐情感分析研究,首先利用单一模态的歌词特征对音乐进行情感分析,再通过融合歌词和音频两种模态,构建SVM分类器进行音乐情感分析。2017年,Abburi等[16]演示了一种使用歌词和音频信息提取歌曲情感的方法,研究发现通过整首歌曲表现情感的情况非常少见,因为完整的歌曲将包含更多令人困惑的信息(特征),而在音频方面,一首歌曲的前30秒对于检测歌曲的情感比歌曲的最后30秒或从整首歌曲中获得的效果都好。
以上研究思路都未考虑特征词位置信息这一重要因素。歌词文本不同于微博短文本、淘宝评论等文本,歌词文本的明显特征是文本中有重复特征词,特别是副歌部分,往往含载了丰富的情感,所以不同特征词的位置对情感分类具有影响。因此从文本角度出发,采用朴素贝叶斯、最大熵模型、支持向量机3种模型研究特征词位置对歌词情感分析的影响。
2 算法框架与原理
2.1 歌词情感分析流程
在了解中文文本分类方法基本原理和相关技术并明确中文文本分词的基础上,进行歌词情感分析,流程包括:①通过基于方差的卡方检验CHI进行合理的特征选择,以挑选出有效的、能够表达情感的词汇作为研究特征项;②详细分析中文歌词与情感的关系,结合CHI构建适用于本研究的情感词汇表;③引入位置因子概念表示该位置特征词对情感分类的影响程度,基于TF-IDF算法采用统计的方法,对特征词进行词频统计,并结合位置因子计算各特征词位置权重;④在纯歌词文本加上文本标题并结合位置权重的基础上依次进行递进实验,采用NB、ME、SVM训练多个二值分类器,并基于投票机制确定歌词最终的情感类别。
歌词情感分析整体架构如图1所示。
图1 歌词情感分析流程
2.2 朴素贝叶斯算法
朴素贝叶斯算法(Naive Bayes,NB)是基于贝叶斯定理与特征条件独立性假设的分类方法[17]。随机变量X表示输入特征向量,随机变量Y表示输出类别标签,给定训练数据集:
其中, x i=(x(1) i,x(2) i,…,x(n) i)表示第i个样本有n维,y i={c 1,c 2,…,c k}表示共有k个类别。
计算训练集所有样本中每个类别的先验概率:
对每个特征属性取值,分别计算所属类别条件概率:
其中,x(j) i表示第i样本中的第j个特征;a jl表示第j个特征可能取的第l个值;I是一个指示函数。
对于未知标签的数据样本,通过学习到的模型计算后验概率分布,设x=(x(1),x(2),…,x(n)) T ,则:
因分母对所有 C k 相同,可省略,将后验概率最大的类作为当前文本情感类别:
当概率值为0时会对后验概率计算结果造成偏差,影响最终分类性能,因此在实验计算过程中引入拉普拉斯平滑的贝叶斯估计方法解决该问题。
2.3 最大熵模型
最大熵原理由Jaynes提出,他认为在学习概率模型时,在所有可能的概率模型分布中,熵最大的模型为最佳模型。其中熵又称为自信息,是衡量一个随机变量的不确定性指标。随机变量熵值越大,表示不确定性越大。如果X是一个离散型随机变量,取值空间为 R,其概率分布为P(X=x i)=p i,i=1,2,…,N,则X熵H(p)定义为:
最大熵模型(Maximum Entropy Model,ME)是基于最大熵原理提出的,学习目标是用最大熵原理选择最好的分类模型[17]。最大熵分类寻找一个关于p(y|x)的模型,使模型在满足相关约束条件下,使条件熵最大。ME的学习过程是求解最大熵模型的过程,对于给定的训练数据集 T={(x 1,y 1),(x 2,y 2),…,(x N,y N)}(其中x i為训练样本,y i为样本x i类别)以及特征函数fi(x,y),i=1,2,…,n ,ME的学习可以形式化为约束最优化问题。
为简化问题求解,通过构造拉格朗日函数将带约束的原始问题转换为无约束的最优化对偶问题,求解出ME一般形式。
2.4 支持向量机
支持向量机(Support Vector Machine,SVM)是经典机器学习算法处理分类问题时使用最广泛的机器学习模型之一,在解决小样本、非线性及高维模式识别中表现出独特优势。SVM的基本思想是在向量空间中寻找一个分类超平面,超平面需让所有样本点中距离超平面最近的训练样本点具有最大几何间隔,从而使超平面具有唯一性[17]。利用该平面对两类数据进行正确划分,给定数据集为:
其中 x i ∈R n,y i∈{-1,+1},i=1,2,3,…,N。
寻找几何间隔最大的超平面可以表示为带约束的最优化问题。
其中γ表示最大化超平面关于训练集的几何间隔,约束条件表示超平面关于每个训练样本点的几何间隔至少是γ。通过函数间隔与几何间隔γ=/‖w‖的关系,取=1,最大化1/‖w‖等价于最小化‖w‖ 2/2,使最优化问题变为:
线性可分支持向量机最优化问题,以它作为原始最优化问题,应用拉格朗日对偶性引入拉格朗日乘子 α 构造拉格朗日函数,其中最优化问题变为:
通过SMO算法求得最优解,然后计算:
最后求得“最大间隔”超平面为:
分类决策函数为:
2.5 CHI特征选择方法
卡方检验CHI[18]是一种常用的特征选择方法,假设特征词 t与类别c相互独立,通过观察理论值与实际值的偏差确定假设是否正确,以此度量特征词t与类别c的相关程度。二者之间的卡方值计算公式为:
其中参数N为数据集中歌词文本总数,A为包含特征词t且属于类别c的文本数,B为包含特征词t但不属于类别c的文本数,C为不含特征词t但属于类别c的文本数,D为不含特征词t且不属于类别c的文本数。
可以看出,N是不变的,所以式(14)分子中的N和分母中的(A+C)(B+D)可以省略。
卡方值越小,说明特征词t与类别c相互独立性越大,即假设正确,二者不相关;反之若卡方值越大,则表示假设错误,说明特征词t与类别c紧密相关。
2.6 TF-IDF传统权重算法
词频-逆向文件频率(Term Frequency-Inverse Document Frequency,TF_IDF)用以评估特征词对于训练数据集中的某个文本的重要程度。其主要思想是:若某个特征词在当前文本中出现得频率高,同时在其它文本中很少出现,那么认为该特征词具有很好的类别区分能力。TF ID F由两部分组成,词频(Term Frequency,TF)表示特征词在文档d中出现的频率。对于在某一特定文本的特征词来说,其重要性可表示为:
其中n i,j是该特征词t i在文件d j中出现的次数,分母表示在文件d j中所有特征词出现的次数之和。
逆向文件频率(Inverse Document Frequency,IDF)的主要思想是:如果包含特征词t的文本越少,则说明特征词t具有很好的类别区分能力。逆向文件频率是一个特征词普遍重要性的度量。某一特征词的IDF可以由总文本数目除以包含该特征词的文本数目,再将得到的商取对数得到,表示为:
其中log的分子表示数据集文本总数,分母表示包含词语 t i 的文本数目,一般情况下以分母加1的形式防止分母为0 。
IDF结构简单,不能有效反映单词重要程度和特征词分布情况,即未考虑位置信息,无差别处理在文本不同位置的词语,但对于歌词文本来说,文本标题特征词的重要程度跟文本中间或文本前后特征词重要程度不同。因此可以将处于文本不同位置的特征词赋予不同的权重。
3 基于位置权重算法分析
3.1 基本思想
鉴于传统的特征权重计算算法TF-IDF认为文本中出现靠前的特征词和靠后的特征词重要性相同,无法体现特征词位置信息的特点,基于位置权重算法提出一种新的特征权重算法,在歌词情感分析场景中,考虑到歌词文本不同于微博短文本、淘宝评论等文本,歌词文本最不可忽略的一点就是文本中有重复的特征词,特别是副歌部分,或对情感分类产生影响。基于此将歌词文本分为前、中、后3个部分以区分不同位置特征词,然后结合文本标题与歌词文本前、中、后4个不同位置,利用AHP分别置于不同位置因子,面向不同位置特征词的位置因子进行分组实验。
3.2 AHP位置權重算法
借鉴TF-IDF中词频思想,对特征词进行词频统计,加入文本标题,利用文本前、中、后不同位置的位置因子计算每个特征词权重,通过位置因子表示不同位置特征词对最终情感分类的贡献程度。定义TTFL为基于文本标题和位置权重的算法,其中TTFL=T*TF*L,TF表示特征词在当前文本中的词频,T代表文本标题的位置因子,L代表文本歌词文本前、中、后不同位置的位置因子。在计算位置因子时,根据AHP[19]求解。AHP算法原理是将复杂评价指标排列为一个有序、递阶层次结构的整体,然后在各评价指标间进行两两比较、判断,计算各评价指标的相对重要性系数,即权重。具体步骤如下:
(1)构建两两比较的判断矩阵。判断矩阵合理性受标度合理性影响的程度。标度是指评价者对各个评价指标重要性等级差异量化概念。针对歌曲情感分类,假设比较n个位置因子X={x 1,x 2,…,x n}对歌曲最后情感类别C的影响大小,两两比较建立判断矩阵A=(rij)n×n。
x i与x j对C的影响之比为r ij,判断矩阵A=(r ij)n×n满足:
上述矩阵为正互反矩阵,参考1-9标度比例标度法判断矩阵构建,如表1所示。
其中n为4,假设用x 1、x 2、x 3、x 4表示文本标题和歌词文本前、中、后的位置因子,则判断矩阵A为:
(2)层次单排序。计算判断矩阵A的最大特征根λ和其对应的归一化后的特征向量:
由此得到特征向量是文本标题和歌词文本前、中、后的位置因子。λ和W的计算方法为:
步骤1:矩阵每一列归一化得到新矩阵B:
步骤2:对按列归一化的矩阵B再按行求和:
W i=∑nj=1B ij,i=1,2,…,n(20)
步骤3:将向量归一化得到最终的特征向量:
步骤4:计算最大特征根:
(3)检验判断矩阵 A 的一致性。检验判断矩阵一致性是指当需要确定权重的指标较多时,矩阵内初始权数可能出现矛盾,对于阶数较高的判断矩阵,难以直接判断其一致性,需要进行一致性检验。但本文由于指标个数较少,故不作一致性检验。
经过AHP算法计算后的位置因子将分别作为TTFL中的T和L进行实验验证,当某个特征词属于文本标题的特征词时,公式中T代入为相应的位置因子,而L取值为1,反之L代入歌词文本前、中或后的特征词位置因子,此时T取值为1。
4 实验验证与结果分析
4.1 实验数据来源与预处理
由于本文研究对象是中文歌曲的多情感分类问题,为保证数据可信度,抓取酷狗音乐、酷我音乐4个类别下的歌词文本,其中去除中混杂或居多的歌词文本后,各类别分别计300篇,共计1 200篇歌词文本作为实验最终数据集。
中文分词采用的是结巴分词中的精确模式,切分歌词文本最精确部分,并去掉停用词、消除歧义词。在特征提取方面,利用CHI计算特征词与类别卡方值,排序构建固定维度的情感词典以将每个歌词文本转成统一维度的词向量。
4.2 实验过程
本文基于歌词文本和文本标题以及位置权重进行歌曲情感分类。在分类器训练过程中以二值分类器为基准,基于4种类别训练 C 2 4个二分类器,将数据样本分别在C 2 4个分类器进行训练,最后利用C 2 4 个分类器投票,投票最高的类别作为当前样本的最终情感类别。实验中选用的分类器模型是朴素贝叶斯、最大熵模型、支持向量机,其中ME的最大迭代次数max_iter和SVM目标函数惩罚参数 C 设置为50,SVM使用默认径向基核函数。
4.3 实验结果与分析
对不同特征维度、文本标题和位置权重进行多组对比实验。在对分类器性能进行评测时,应用最常用的K折交叉验证随机将数据划分为K个大小相同的子集,使用(K-1)个子集数据作为训练集,剩下的子集作为测试集进行多组实验,最后选用性能最好的模型作为最终结果。以准确率、召回率、F 1值作为评价指标进行衡量。
实验1将中文歌词文本分词后,通过CHI算法构建不同维度情感词典,并将歌词文本按照词频转成相应维度词向量,对文本标题不作考虑,并且认为歌词文本中每一位置的特征词重要程度相同,实验结果如图2所示。
图2中横坐标轴代表3种不同分类器,纵坐标轴表示4种情感类别最终分类准确率,实验从不同特征维度分别进行3个分类器的训练,可知取特征数为5 000时的效果优于其它维度时的效果,其中SVM分类效果最好。
标题是对一篇文章内容的高度概括,代表文章主体意思,歌词标题亦然,因此实验2在之前基础上将文本标题也作为特征词加入,实验结果如图3所示。
分析结果可知,相比于之前只考虑纯文本歌词的情况,在加入文本标题的特征词后分类结果较之前有一定提升。
实验3综合考虑歌词文本结合文本标题,对不同位置特征词位置因子进行实验,设文本标题特征词位置因子和歌词文本中间位置的特征词位置因子相等,且大于其它两个位置特征词位置因子,其中位置因子表示权重,具体值由AHP算法计算得到。实验表明,在考虑文本标题的同时衡量位置权重,在一定程度上影响了歌曲情感,此时经AHP计算出的位置因子只有两个值,分别代表文本标题、歌词文本中间特征词和歌词文本前、后特征词的权重。当特征数是5 000时,属于NB持平的状况,而ME提高了1个百分点,SVM精确率达到了88%。
与实验3相比,实验4认为文本标题的特征词位置因子最大,歌词文本中间位置的特征词位置因子次之,其它两个位置的特征词位置因子最小且相等,特征數为5 000,实验结果如图4所示。
本次实验显示,经AHP计算的4个位置因子及朴素贝叶斯分类器分类效果明显提高,整体效果仍然优于不考虑位置权重时的情况。
基于实验1、实验2、实验4的比较如表2和图5所示。表2和图5分别展示的是不同分类器在加入不同考虑因素时, F 1值和精确率的比较,其中表2中x轴表示分类器,y 轴表示递进增加的考虑因素。可以看出本文提出的基于位置权重的歌词情感分类方法将歌曲类别分为快乐、伤感、安静、激昂,比只用歌词文本的分类性能[20 21]有明显提升,进一步说明特征词位置因素对最终歌词情感分类情况是有影响的。
5 结语
本文提出利用融合文本标题和基于位置权重的歌词情感分析方法,衡量不同位置特征词对分类的影响,并通过实验证明了相对于现有特征权重计算方法和歌词情感分析研究,加入特征词位置权重后不仅节省执行时间,对于歌词情感分类效果也明显提升。后续研究将对位置权重进行更加深入的分析,扩大场景应用范围。在影评、诗歌、商品评论等领域场景及微博热搜榜词条、新闻标题党检测方面也可借鉴位置权重以提高情感分类性能。
参考文献:
[1] WU H, LI J, XIE J. Maximum entropy based sentiment analysis of online product reviews in Chinese[C].International Conference on Automotive Engineering, Mechanical and Electrical Engineering, 2017:559 562.
[2] WANG C, JIA Y, HUANG J M, et al. Retweet prediction in Sina Weibo based on entity level sentiment analysis[C]. International Conference on Artifial Intelligence,2017:343 350.
[3] KAUTER M V D, BREESCH D, HOSTE V. Fine grained analysis of explicit and implicit sentiment in financial news articles[J]. Expert Systems with Applications, 2015, 42(11):4999 5010.
[4] YANG H L, CHAO A F. Sentiment analysis for Chinese reviews of movies in multi genre based on morpheme based features and collocations[J]. Information Systems Frontiers, 2015, 17(6):1335 1352.
[5] 张伟,谢湘.基于HMM的音乐情感识别研究[C].全国人机语言通讯学术会议, 2007:1 5.
[6] LEE J Y, KIM J Y, KIM H G. Music emotion classification based on music highlight detection[C].International Conference on Information Science and Applications, 2014:1 2.
[7] 赵伟.基于BP神经网络的音乐情感分类及评价模型[J]. 电子设计工程, 2015(8):71 74.
[8] LIN C, LIU M, HSIUNG W, et al. Music emotion recognition based on two level support vector classification[C]. International Conference on Machine Learning and Cybernetics, 2017:375 389.
[9] HE H, JIN J, XIONG Y, et al. Language feature mining for music emotion classification via supervised learning from lyrics[C]. Third International Symposium on Advances in Computation and Intelligence,2008:426 435.
[10] 王静.基于歌词的音乐情感分类技术研究[D].沈阳:东北大学, 2012.
[11] TURNEY P D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews[C].Meeting on Association for Computational Linguistics, 2002:417 424.
[12] XIA Y, WANG L, WONG K F, et al. Sentiment vector space model for lyric based song sentiment classification[C]. Meeting of the Association for Computational Linguistics on Human Language Technologies: Short Papers,2008:133 136.
[13] 夏云庆,杨莹,张鹏洲,等.基于情感向量空间模型的歌词情感分析[J].中文信息学报,2010,24(1):99 104.
[14] 孙向琨.音乐内容和歌词相结合的歌曲情感分类方法研究[D].苏州:苏州大学, 2011.
[15] 程一峰.基于TF IDF的音频和歌词特征融合模型的音乐情感分析研究[D].重庆:重庆大学, 2012.
[16] ABBURI H, SAI E, GABGASHETTY S V, et al. Multimodal sentiment analysis of Telugu songs[C].Proceedings of the 4th Workshop on Sentiment Analysis where AI meets Psychology ,2016: 48 53.
[17] 李航.统计学习方法[M].北京:清华大学出版社, 2012.
[18] 邱云飛,王威,刘大有,等.基于方差的CHI特征选择方法[J].计算机应用研究,2012,29(4):1304 1306.
[19] 王学军,郭亚军,兰天.构造一致性判断矩阵的序关系分析法[J]. 东北大学学报:自然科学版, 2006, 27(1):115 118.
[20] DAKSHINA K, SRIDHAR R. LDA based emotion recognition from lyrics[M].Newyork:Springer International Publishing, 2014.
[21] YANG D, LEE W S. Music emotion identification from lyrics[C]. IEEE International Symposium on Multimedia, 2009:624 629.
猜你喜欢
现代电子技术(2016年23期)2017-01-12
现代电子技术(2016年23期)2017-01-12
中国水运(2016年11期)2017-01-04
科学与财富(2016年28期)2016-10-14
考试周刊(2016年53期)2016-07-15
