
基于整体相似度的文档主题匹配研究
2018-03-19 12:02魏小锐
网络安全技术与应用 2018年3期
◆魏小锐
基于整体相似度的文档主题匹配研究
◆魏小锐
(东莞理工学院计算机与网络安全学院广东 523808)
基于内容的网络信息过滤需要动态地比较网页与用户模板。传统文档主题匹配算法主要以两两文档间的相似度为基础来计算,这在高维的文档向量空间并不总是合适。超团模式是一种附加了整体相似度约束的频繁项集,其内部文档更有可能属于同一类别。利用超团模式这种特性,提出了基于整体相似度的文档主题匹配方法,只利用同一个超团内部的文档来预测类别。该方法通过在现实世界数据集上与K-最近邻算法进行比较,实验结果证实了超团算法应用于文档主题匹配的优越性。
文本挖掘;文档匹配;整体相似度;超团模式
0 引言
随着因特网迅速发展,互联网已成为一个巨大的信息空间,为用户提供了极具价值的信息资源。但是由于互联网的开放性,人们发布、传播和接收信息几乎不受任何的控制, 人们对网络资源的非正当使用也逐渐成为社会正常生产与生活的威胁。因此,信息过滤技术越来越多地应用在网络上。比如,通过信息过滤技术,家长可以防止自己不在家时孩子访问不健康的网页,教师可以防止学生在实验课上浏览与课堂内容不相关的网页,公司可以防止员工上班时间浏览与工作不相关的内容。
由于网络的动态性,基于内容过滤是当前网络信息过滤系统主要采用的一种方法[1,2]。针对禁止用户访问的主题,选取一些代表性的种子文档作为用户模板。把用户浏览的文档作为测试文档,我们需要从测试文档中找出有可能与种子文档属于同一主题的文档。这种检索要求结果同时具有理想的召回率与准确率。较低的召回率意味着漏掉许多本该禁止访问的文档,而准确率过低则意味着许多正常的文档也被禁止了。可见,基于内容过滤的关键在于从测试文档集中找出与种子文档主题匹配的文档。
本文在传统的信息检索基础上提出将超团模式应用于文档主题匹配,研究如何用关联模式来评估文档间的相似度。通过在给定的文本集中挖掘最大文档超团并计算相关文档的整体相似度,从而找出那些与用户模板里的种子文档最相关的测试文档,并以此为依据对用户所浏览的网络信息进行有效的监控和过滤。
本文接下来组织如下:第1节介绍文档模型与文档检索的相关技术,第2节介绍超团模式以及相应的文档主题匹配算法,第3节报告实验结果,第4节是小结。
1 相关技术
1.1文档向量模型
文档向量空间模型是一个常应用于信息过滤、撷取、索引以及评估相关性的代数模型[3,4]。在该模型中,用D(Document)表示文本,其中文本是泛指各种机器可读的记录。
特征项(Term,用t表示)是指出现在文档D中且能够代表该文档内容的基本语言单位,文本可以用特征项集表示为D(T1,T2,…,Tk, …,Tn),其中Tk是特征项,1<=k<=n。对含有n个特征项的文本而言,通常会给每个特征项赋予一定的权重表示其重要程度。即D=D(T1,W1;T2,W2;…,Tn,Wn),简记为D=D (W1,W2,…,Wn),我们把它叫做文本D的向量表示,其中Wk是Tk的权重(1≤ k ≤n )。
1.2文档相似度计算
两个对象之间的相似度是这两个对象相似程度的数值度量。当文档用向量来表示时,那么向量的每个属性代表一个特定词条在文档中出现的频率。通常一个文档集中拥有数以万计的词条。但是,具体到某一篇文档时,由于它具有相对较少的单词,所以其向量都很稀疏。这就要求文档的相似性度量必须能够处理稀疏向量[5,6]。
计算文档相似度的方法有很多,其中比较有代表性的是余弦计算法(cosine measure)[7]。在向量空间模型中,两个文本D1和D2之间的内容相关度Sim(D1,D2)可以用向量之间夹角的余弦值表示,公式为:
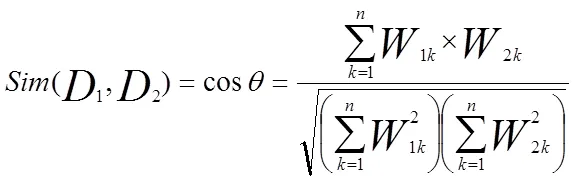
其中,W1k、W2k分别表示文本D1和D2第k个特征项的权值(1≤ k ≤n ) 。
1.3 基于K-最近邻的k文档匹配
K-最近邻(KNN, K nearest neighbors)分类算法常用于文档类别匹配[8,9]。该算法的主要思想是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)样本中的大多数属于某一个类别,则该样本也属于这个类别。
该方法在定类决策上只依据最邻近几个样本与待分样本之间的两两相似度来预测类别。其前提是:
(1)两个样本之间相似度越大,它们越有可能属于同一类别;
(2)所选择的近邻都是已经提前正确分类的对象。
对于文档这种高维数据,该算法计算量非常大,而且前面的前提(1)经常并不成立[10]。当样本所属类别不平衡时,如一个类的样本容量很大,而其他类样本容量比较小时,有可能导致当输入一个新样本时,该样本的k个邻居中大容量类的样本永远占多数。
2 基于整体相似度的文档匹配
2.1超团模式
本算法提出了基于超团的整体相似度概念,在大量的测试文档集中,利用整体相似度检索出最接近于种子文档集主题的文档。接下来介绍“超团”(hyperclique)。
超团是在频繁项集(frequent item set)的基础上提出的一个较新的概念,是一种特殊的频繁项集[11]。下面是H置信度的相关定义:
定义1 关联规则的H置信度
对于频繁项集X={i1,i2,i3,…,ik},h置信度(h-confidence)的公式如下:
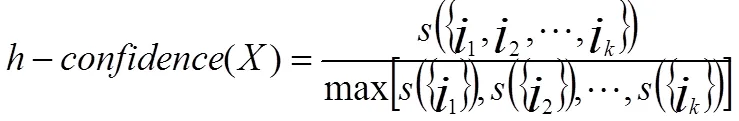
其中,s({ik})表示项集{ik}的支持度。
给定一个用户自定义的支持度和h置信度阈值HC,我们把大于等于这些阀值的项集称作超团。超团模式是一种强关联模式,它的特点是当超团内的某个项目在事务中出现时,该超团的其他全部项在这个事务出现的概率不低于h置信度。如果用0-1矩阵表示事务集数据,用0-1列向量来表示每个项,那么超团内部任意两项的余弦相似度可以由以下公式计算:
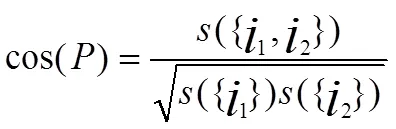
由以上两个公式可知超团内部任意两项的cosine相似度不低于超团的h置信度阀值HC。
2.2整体相似度
传统文档主题类别匹配主要根据所有文档间的两两相似度来计算。本文提出利用超团模式强关联的性质来计算多文档之间的整体相似度,用于文档类别匹配。具体地,相似度的计算只局限于文档超团内部的文档。将超团内的文档分为种子文档子集和测试文档子集,然后为测试文档子集中的每个文档计算其与种子文档子集所有文档的相似度并取最大值,所得值即为该测试文档与整个种子集的整体相似度值。
下面举例说明整体相似度与两两相似度的区别。假设种子文档集O={O1,O2,O3,O4},测试文档集D={D1,D2,D3,D4},其中测试文档集中只有D4与种子集不属同一类别,两个文档集合之间文档的两两相似度如表1所示。

表1 文档两两相似度矩阵
根据相似度从高到低排列,测试集中的文档排列为D2、D3、D4和D1。若采用K-最近邻算法,当选取出相似度最高的3个测试文档时,D4被视为与种子集属于同一类别,但实际上它与种子集不属同一类别。
当运用超团模式,通过设置一定的参数阀值挖掘得出的文档超团为{ D1,D4,O1,O3}和{ D2,D3,O2,O4},那么文档之间所需计算的相似度如表2所示。

表2 文档超团相似度矩阵
如表2所示,D1只需计算跟O1和O3的相似度,并取他们的最大值0.51作为测试文档D1与种子集的整体相似度。根据相似度从高到低排列原则,测试集中的文档排列为D3、D2、D1和D4。当选取出相似度最高的3个测试文档时,所得文档均与种子集同属一个类别。在表2中,尽管D1与种子集的相似度为0.51,该值小于表1中D4与种子集的相似度0.73,但D1却与种子集同属一个类别。这就说明了在某些情况下通过计算多个文档间的整体相似度对于文档类别预测,要优于计算文档两两间的相似度。
2.3算法描述
图1是将超团运用到文档类别匹配中的一个高层描述。输入包括:测试文档集D、用户模板存储的种子集O、超团的参数最小支持度阀值、最小H置信度阀值,以及用户期待的输出文档数量K。输出为从测试文档集D选出的最有可能与种子集O属于同一类别的K篇测试文档。

图1 基于超团的文档类别匹配算法描述
在该算法中,步骤1-2首先将测试集与种子集两两文档之间的相似度初始化为零;接着根据测试集、种子集以及用户输入条件(包括最小支持度阀值、最小H置信度阀值)挖掘出最大超团集。步骤3-11对最大超团集中的所有集合进行遍历,把每个集合划分为测试集和种子集,若其中一个子集为空则对下一个最大超团进行划分,否则计算出划分后测试集中所有文档与划分后种子集的相似度。在遍历完最大超团集中所有最大超团后,步骤12根据文档相似度从大到小的原则排列测试集中所有文档,根据用户选择输出的文档数量输出前K篇文档,而这K篇文档就被视为最有可能与种子集O属于同一类别。
3 实验评估
3.1实验设计
为了比较基于超团的算法和K-最近邻算法对于文档类别匹配的效果,在实验过程中我们采用了各种主题的文档集。文档集来源于中文文本分类语料库 。语料库包括财经、电脑、房产、教育、科技、汽车、人才、体育、卫生和娱乐十个主题的文档集。按照类别大小比例,把语料库随机地划分为种子集与测试集。每次在种子集选取一个主题的文档作为当前种子集(用户模板),计算测试集中文档与它匹配的情况。
具体地,令D表示测试文档中属于当前主题的文档集,P表示结果文档集(总共K 篇),可以分别计算输出结果的召回率(rec)、准确率(pre)和F1值如下:
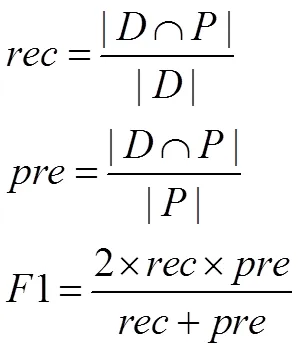
3.2实验结果
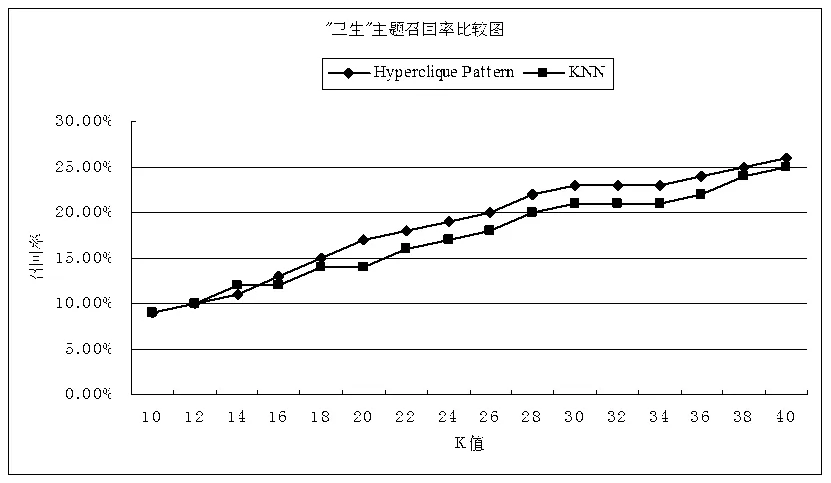
限于篇幅,下面只给出部分结果。当在种子集中选取“卫生”主题进行文档类别匹配,超团算法中支持度及H-置信度值分别取0.001及0.002时实验的比较结果如图2所示:
当在种子集中选取“人才”主题进行文档类别匹配,超团算法中支持度及H-置信度值分别取0.001及0.002时实验的比较结果如图3所示:
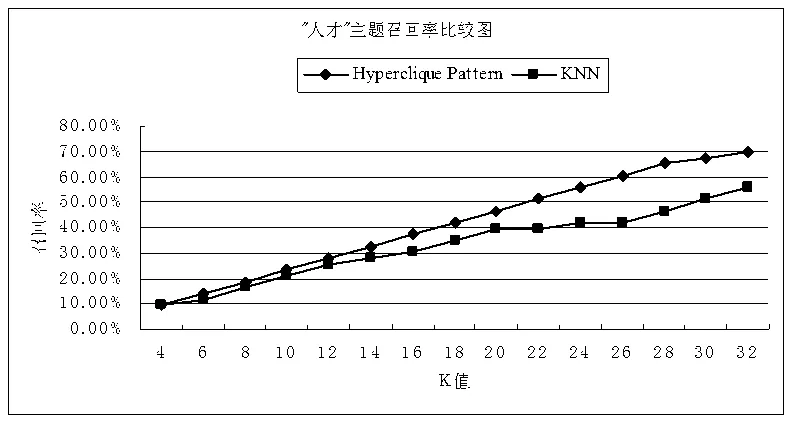
在图2和图3中我们可以看到两种算法随着K的取值的不断变化,召回率、准确率和F1值都有所变化,但总体的趋势是运用超团的算法的各个评测指标比KNN算法的要高。
在实验过程中,我们分别选取种子集中的十个主题的文档集进行检测,发现在绝大多数情况下,采用超团算法的检测结果的各项评价指标整体上都优于采用KNN算法的检测结果。这也在一定程度上证实了将超团应用于文档类别匹配总体性能上要优于采用K-最近邻算法。
4 总结
本文重点研究了如何用关联模式评估文档间的相似度,匹配文档主题。基于超团模式的概念,提出利用整体相似度来找出那些与用户模板主题最相关的测试文档。大量的实验结果也证实了基于超团的文档主题匹配在准确性上要优于传统基于两两相似度的KNN算法。虽然初步达到了预期的目标,但在超团模式参数选取等方面有待进一步完善。另外,如何自动学习具有代表性的种子集,以及如何解释并展示检测出的结果文档,这些都是值得进一步研究的方向。
[1]刘宗仁.网上内容过滤技术的现状及面临的问题[J].现代情报,2005.
[2]白宁.基于特征选择融合的垃圾邮件过滤方法[J].计算机应用与软件,2014.
[3]Baeza-Yates, R, Ribeiro-Neto, B. Modern Information Retrieval. Addison-Wesley, 1999.
[4]潘俊辉,王辉.一种基于模糊VSM和神经网络的文本分类方法[J].科学技术与工程,2011.
[5]张翔,周明全,董丽丽,闫清波.结合粗糙集与集成学习的中文文本分类方法研究[J].计算机应用与软件,2011.
[6]郭颂,马飞.文本分类中信息增益特征选择算法的改进[J].计算机应用与软件,2013.
[7]France, S. L., Carroll, J. D., Xiong, H.. Distance metrics for high dimensional nearest neighborhood recovery: Compression and normalization[J]. Information Sciences,2012.
[8]杨梦雄, 杨贯中.基于K-最近邻算法的话务智能预测技术[J].科学技术与工程, 2007.
[9]罗辛, 欧阳元新,熊璋等.通过相似度支持度优化基于K 近邻的协同过滤算法[J].计算机学报,2010.
[10]Vadapalli, S, Valluri, S. R., Karlapalem, K. A simple yet effective data clustering algorithm[J]. Proceedings of the 6th IEEE International Conference on Data Mining,2006.
[11]Xiong, H., Tan, P.-N., Kumar, V. Hyperclique pattern discovery[J]. Data Mining and Knowledge Discovery,2006.
本文受广东省东莞市科技计划项目(批准号:东科[2015]16-2014106101003)资助。
猜你喜欢
客联(2022年3期)2022-05-31
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
中国新闻周刊(2021年26期)2021-07-27
机电产品开发与创新(2020年2期)2020-05-07
计算机应用(2018年5期)2018-07-25
民族古籍研究(2018年1期)2018-05-21
信息安全研究(2016年4期)2016-12-01
新校长(2016年8期)2016-01-10
