
作家写作风格量化分析模型
2018-04-25 06:29吴航天田凯段新春
商品与质量 2018年35期
吴航天 田凯 段新春
中国人民解放军火箭军工程大学 导弹工程学院 陕西西安 710025
在我们的阅读过程中会遇到不同作家的作品,而不同的作家有着不同的写作风格都有所不同。本文以鲁迅、朱自清、张爱玲、古龙四位作家的若干文章为例,选取适当的特征,量化分析不同作家的写作风格,并能分析附录中的文章出自哪位作家之手。
1 特征提取
流程如下:

首先,使用MATLAB编译特征提取程序,其主要功能为:将中文段落中的所有汉字转换Unicode区位码。生成二维矩阵,每一个汉字对应两位UNICODE区位码,例如“吴”对应“52,84”;其次,查找所需特征如虚词(常用虚词“的、地、得、所、吗、呢、吧、啊、且、了”等)在《Unicode区位码对照表》中对应的编码[1]。
2 计算统计
2.1 长度规格化

2.2 比例规格化
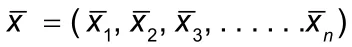
2.3 数据的标准化处理:
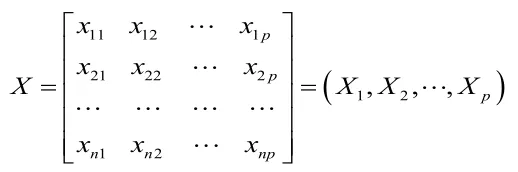
对上述数据进行标准化处理,标准化处理的计算公式如下:
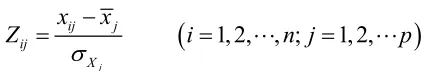
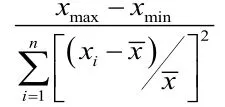
3 统计结果图像拟合
以被测样本的统计数据绘制特征曲线,并将其插入总体特征曲线图进行比对,查找与其相似度最高的特征曲线,该曲线所对应的作者即为被测样本文档的作者。
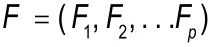
Fi和Fj之间的相关系数定义如下:
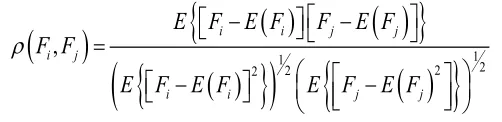
相关系数能够描述两个特征项之间的线性相关度。
4 结果分析
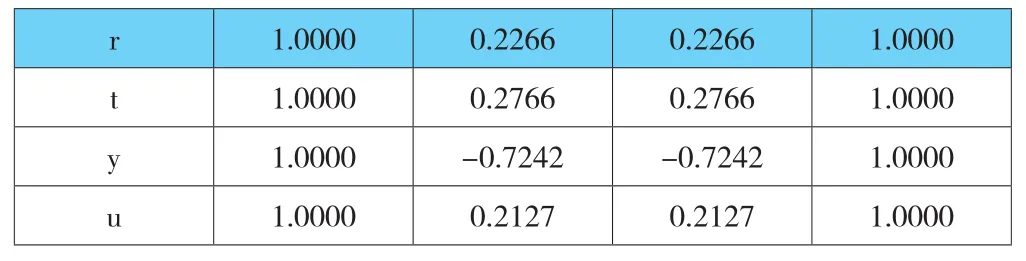
试验的结果还与所选取的特征量有关。例如,仅以文章节奏(即标点符号的使用)作为特征量,其结果如下:
r 1.0000 0.2266 0.2266 1.0000 t 1.0000 0.2766 0.2766 1.0000 y 1.0000 -0.7242 -0.7242 1.0000 u 1.0000 0.2127 0.2127 1.0000
结果表明:在标点符号使用习惯的相似度分析中,选取《背影》第一段作为待测文章与四位作家的相似度分别为22.66%,27.66%,-72.42%(呈现负相关),21.27%,即与作家二(鲁迅)的相似度最大,而真实作者(朱自清)的相似度排名第二,试验结果具有一定程度的有效性。因此,本模型在一定程度上能有效识别文章的作者,但其准确性还需经大量试验来验证[2]。
对此,我们随机抽取了朱自清、鲁迅、张爱玲、古龙四位作家各50篇作品(节选)(总计27.6万宇字),共计200次试验来进行验证。试验表明,该模型对于朱自清、鲁迅、张爱玲、古龙四位作家作品的作者识别成功率分别为61.32%、69.43%、71.89%、73.97%。显然,作者识别率会随试验次数与被检验内容的增加而进一步提高。
猜你喜欢
华人时刊(2022年13期)2022-10-27
小学生学习指导(中年级)(2021年9期)2021-09-27
快乐作文(1.2年级)(2020年4期)2020-09-10
文苑(2018年20期)2018-11-09
剑南文学(2016年14期)2016-08-22
思维与智慧·下半月(2016年4期)2016-04-25
山东青年(2016年1期)2016-02-28
做人与处世(2015年11期)2015-09-10
做人与处世(2015年7期)2015-06-24
小火炬·阅读作文(2009年11期)2009-11-30
