
基于集成神经网络的短文本分类模型
2018-07-19 02:31高云龙左万利
吉林大学学报(理学版) 2018年4期
高云龙, 左万利, 王 英, 王 鑫
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012;3. 长春工程学院 计算机技术与工程学院, 长春 130012)
0 引 言
深度学习网络在计算机视觉、语音识别等领域中已取得许多成果[3]; 在自然语言处理领域, 深度学习网络虽没有取得系统性的突破, 但也受到广泛关注[4]. 卷积神经网络(convolutional neural networks, CNN)通过结合局部感知区域、共享权重、空间或时间上的降采样, 充分利用数据本身包含的局部性等特征优化网络结构, 并保证一定程度上的位移及变形的不变性; 相比于前馈深层神经网络, 递归神经网络(recurrent neural networks, RNN)更重视网络的反馈作用, RNN通过增加当前状态与过去状态之间的联系, 具有一定的记忆功能, 从而有利于捕获短文本内部结构之间的依赖性.
短文本分类模型的构建本质上是学习文本数据中所包含的特征[5], 按照提取特征及分类策略的不同, 本文将短文本分类模型分为两种: 基于语义分析的短文本分类模型和基于神经网络的短文本分类模型. 基于语义分析的短文本分类模型通常通过更多关注文本内在的语义结构、内容及文本间的关联, 实现对短文本逻辑结构建模, 提取语义特征, 降低特征空间的维度. 在目前基于语义分析的分类模型中, 通常采用词的分布式表示以及基于LDA(latent Dirichlet allocation)主题模型进行特征提取两种策略. 在词的分布式表示算法中, 短文本中的每个词以词向量的方式表示[6]. Ma等[7]利用Word2Vec工具在语料库上进行训练, 得到了短文本中词的分布式表示, 并假设词向量分布服从高斯分布, 利用Bayes框架得到了良好的分类效果. 文献[8]提出了一种用于表示词向量的全新方案: 将词向量分为两个子向量, 分别用于提取形态以及句法、语义方面的特征, 并通过实验证明其具有较好的表达效果. 使用LDA主题模型提取语义特征是基于语义分析的短文本分类模型中主要的一种策略, Phan等[9]通过使用pLSA和LDA在主题特征空间构造短文本的特征向量, 并结合最大熵和支持向量机(SVMs)模型进行分类, 取得了较好的实验结果. Chen等[10]提出了提取多粒度主题的方案, 可更好地描述短文本语义信息, 从而提高分类效果. Kim[11]首次将CNN应用到句子模型的构建中, 并提出了几种变形. Socher等[12]提出了基于递归自编码的半监督学习模型, 该模型可有效学习短文本中多词短语及句子层次的特征向量表示, 在预测情感分析中取得了较好的效果. He等[13]采用多种不同类型的卷积和池化, 实现对句子的特征表示, 并利用所学习到的特征表示构建句子相似度模型. Socher等[14]提出了RNTN模型, 该模型通过使用解析树中低层的词向量组合, 计算解析树中高层节点的向量表示, 根节点即代表短文本的特征向量, 从而提取出短文本的语义特征. 基于神经网络的分类模型由于使用词向量数据, 并且不依赖于特定语言的句法, 因此在不同类型的数据集或不同的语言中都显示出了良好的扩展性和有效性. 基于以上研究, 本文提出一个基于集成神经网络的短文本分类模型C-RNN, 主要贡献包括: 1) 用CNN构造扩展词向量, 从而使数值词向量可有效描述短文本中形态、句法及语义特征; 2)利用RNN网络对短文本语义进行建模, 进一步构造短文本的高级抽象特征.
1 短文本分类模型C-RNN框架
本文提出的基于集成神经网络的短文本分类模型(C-RNN)可分为如图1所示的三部分.
1) 按文献[8]的扩展词向量构造方式, 利用CNN网络将短文本中的词转换为长度固定的词向量;
2) 利用LSTM网络进一步对短文本语义信息进行抽象, 并利用隐含节点之间的联系编码短文本内部结构之间的依赖关系;
3) 将LSTM网络的输出作为softmax分类层的输入, 计算短文本中词对于目标类别的概率, 从而分析短文本所属的目标类别.
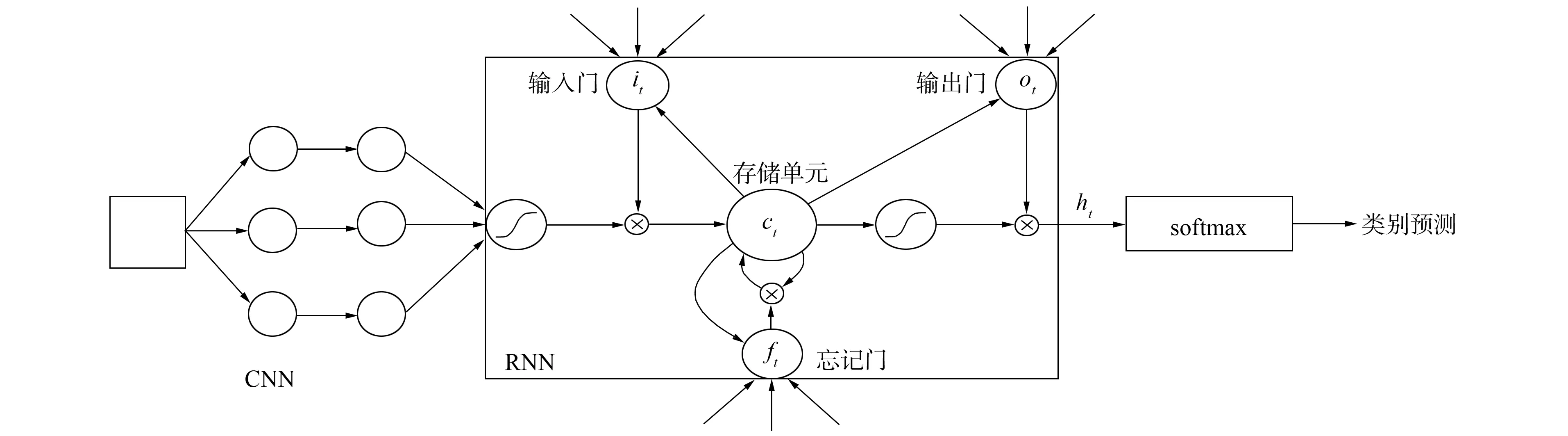
图1 C-RNN模型结构Fig.1 Structure of C-RNN model
2 构建短文本分类模型C-RNN
2.1 词向量模型
文献[8]提出一种全新的词向量形式, 即对于短文本中每个词w, 其词向量表示为u=(rw,rch), 其中: rw为词语级别的词向量, 用于捕获句法、语义层次的特征; rch为字符级别的词向量, 用于捕获词汇形态层次的特征. 本文采用类似的扩展词向量表示方式, 即对于短文本中的每个词w, 其词向量表示为u=(rw2v,rch), 其中rw2v是由Word2Vec工具在语料库上训练得到的词汇数量特征表示[15].
假设用于描述语料库中字符特征的词汇量为Vchr. 对于包含T个字符特征{ch1,ch2,…, chT}的词汇w, 首先按下式将特征cht转换为其对应的向量表示:
仅可通过线性化误差模型辨识的误差包括仅可过测量辨识的误差包括δl21,δl23,δl33,δl43;仅可通过间接计算所得的误差项包括δλ2x,δλ2z,δλ3z,δλ4z;可通过线性化误差模型和测量辨识的误差包括δl13,δθ13y,δθ13x,δθ21z,δθ21y,δθ23y,δθ23x,δθ33y,δθ33x,δθ43y,δθ43x。
rchr=Wchrvch,
(1)
其中: Wchr∈dchr×|Vchr|为转换矩阵; vch∈|Vchr|为标识向量, 对应特征位置元素为1, 其他位置元素置0. 此时, 词w对应的向量组为将该向量组作为卷积层的输入, 进一步提取特征向量:
(2)
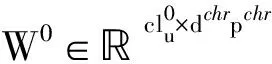
2.2 LSTM提取短文本语义信息
LSTM(long short-term memory)是一种典型的RNN网络, 不同于普通的RNN网络, LSTM模块具有忘记门、输入门、输出门和记忆存储单元4个主要部分, LSTM模型的结构如图3所示. LSTM通过各部分的协作, 实现信息的记忆及长短期依赖信息的提取。短文本内部空间区域之间存在大范围的相互依赖性, 编码这种依赖关系对短文本的句法、语义分析具有重要作用.
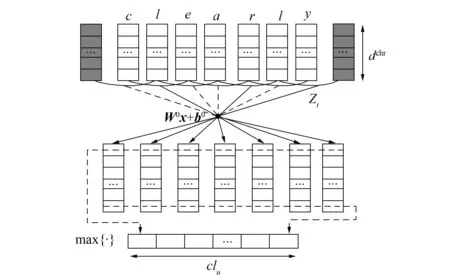
图2 构造字符级别特征向量模型的结构Fig.2 Structure of constructing char-level feature vector model
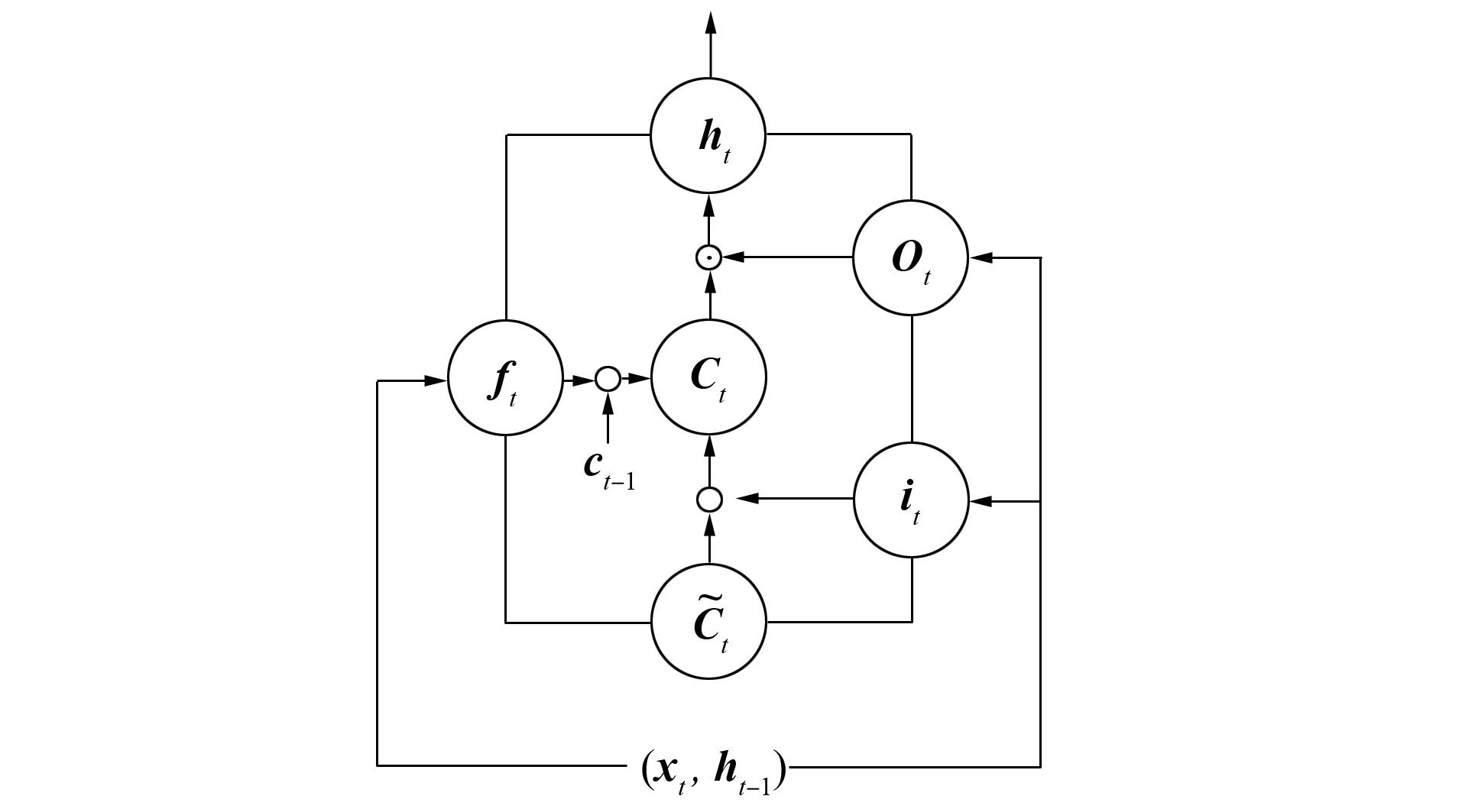
图3 LSTM模型结构Fig.3 Structure of LSTM model
LSTM通过称为“门”的结构去除或增加信息到细胞状态. 门是一种使信息选择式通过的方法, 其定义为
2.3 C-RNN模型分类层
对于词个数为N的短文本ST中的每个词wn, 利用LSTM网络得到其语义表示hn, 并作为softmax分类器的输入. 对于目标类别j, 得到的概率为
pj=p(j|hn;θ),
(9)
其中θ为C-RNN模型的参数. 则短文本ST属于类别j的概率为
(10)
通过以上计算可得短文本ST所属的类别为
(11)
3 实验分析
3.1 实验数据集
为验证模型的有效性, 本文采用如下几种标准数据集进行实验, 语料库均可通过开源网站获得.
1) SST(stanford sentiment treebank)[14], 情感分类语料库, 每个句子作为1条影评, 共有5种类别标签, 分别为very positive, positive, neutral, negative, very negative;
2) WSD(Web snippet dataset)[9], Web片段数据集, 共有8种类型, 包括商业、体育、健康等.
语料库的参数列于表1, 其中:C表示目标类数;L表示平均句子长度;N表示数据集大小; |V|表示词的规模; Test表示测试集大小.

表1 语料库参数
3.2 卷积层隐含节点个数K对模型的影响
卷积层隐含节点作为特征提取层, 通过与前一层的局部感受相连, 并提取该局部的特征, 该局部特征一旦被提取后, 其与其他特征间的位置关系也随之确定; 由于每个节点都提取一种特征, 因此卷积层节点个数K决定CNN所提取的特征总数.K值对于C-RNN模型的影响如图4所示. 由图4可见, 在两组数据集中, 实验结果一致: 当K值较小时, 由于无法提取足够的特征, 从而导致无法准确描述短文本的信息; 而当K值较大时, 通常出现特征提取冗余的现象, 此外, 隐含节点个数的增加即模型参数的增长, 对于时间、空间的需求也相应提高.
3.3 稀疏化系数q值选取对模型的影响
CNN模型通过增加稀疏性约束调节模型的复杂度, 在降低模型复杂度的同时, 提高模型的分类精度. 在经验范围内, 通过设置不同的q值, 得到的实验结果如图5所示. 由图5可见, 当q取值过大或过小时, 模型的复杂度也随之改变, 从而模型的分类精度也依次发生变化. 当q值过大时, 模型过于稀疏; 当q值过小时, 模型容易出现过拟合现象.

图4 K值选取对泛化误差的影响Fig.4 Influence of value K selection on generalization error

图5 q值选取对泛化误差的影响Fig.5 Influence of value q selection on generalization error
3.4 采用扩展词向量对模型的影响

图6 扩展词向量与普通词向量对模型的影响Fig.6 Influence of extended word vectors and common word vectors on models
C-RNN模型采用扩展词向量作为模型的输入, 相比于采用Word2Vec工具生成的普通词向量, 扩展词短文本中词的形态级别特征的数值抽象, 从而使扩展词向量可作为短文本形态、句法及语义多层次的特征描述. 相对于K值和q值的最优解, 本文分别采用扩展词向量及由Word2Vec工具生成的普通词向量作为C-RNN的输入, 得到的实验结果如图6所示. 由图6可见, 扩展词向量通过多层次的特征抽象, 相比于普通词向量, 可更好地反映短文本的特征, 从而有利于提高模型的分类准确率.
3.5 C-RNN与其他模型的比较
将C-RNN模型与其他短文本分类模型进行对比, 对于数据集SST和WSD, 实验结果列于表2. 由表2可见, 本文提出的C-RNN模型在短文本分类问题上具有较好的泛化能力, 实验结果优于大部分模型.相比于CharSCNN模型[16], C-RNN模型通过使用LSTM网络增加信息记忆功能, 从而有利于捕获短文本内部结构之间的依赖性, 实现了对短文本语义信息的建模, 提高了分类的准确性; 相比于RNTN模型[14], C-RNN模型在判别短文本类别时不需要构造句法分析器, 不依赖于某一特定语言, 具有良好的鲁棒性; 相比于Multi-L[10]和Proposed[7]等基于语义分析的分类模型, C-RNN模型通过集成CNN和LSTM模型, 可有效地提取从词到短文本的数值特征, 从而构造出更有效的抽象特征, 提高了分类精度.
综上可见, 本文提出的C-RNN模型通过使用扩展词向量, 可有效描述短文本中的特征信息; 通过使用LSTM网络增加信息记忆功能, 从而有利于捕获短文本内部结构之间的依赖性, 实现了对短文本语义信息的建模, 提高了模型的分类效果.

表2 模型分类精度对比(%)
猜你喜欢
开放教育研究(2020年2期)2020-03-31
天津外国语大学学报(2020年1期)2020-03-25
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
语言与翻译(2015年4期)2015-07-18
外语教学理论与实践(2014年4期)2014-06-13
阅读与作文(英语高中版)(2013年12期)2013-12-11
