
H-K-ELM在滚动轴承故障诊断中的应用
2018-08-28 09:12孙国栋王建国
机械设计与制造 2018年8期
秦 波,孙国栋,王建国
1 引言
滚动轴承是现代旋转设备中最具关键的组成部件之一,但由于工作条件差与工况多变,造成其寿命相差性很大与易损坏[1]。滚动轴承发生故障而导致旋转机械不能正常运转的情况约占30%[2],因此对滚动轴承的状态进行识别具有重大意义。
目前,基于人工智能的状态识别方法是滚动轴承故障诊断领域的研究热点。如文献[3]设计了一种基于BP神经网络的故障自动识别方法,其通过计算平均迭代次数和均方误差的近似值得到最优隐层单元数。仿真结果表明,诊断效率和准确度较高。文献[4]先对振动信号进行小波包降噪,然后对去噪信号进行EMD分解并求解各分量的瞬时能量变化,取瞬时能量变化的熵值组成特征向量,最后将其作为支持向量机的输入实现滚动轴承故障分类。上述方法具有一定的有效性,但BP神经网络的学习时间过于长、且具有欠拟合和局部最优解等固有的缺点。SVM支持向量机与BP相比具有了更好的泛化能力,能够确保局部和全局最优解完全相同。但SVM模型的低稀疏度使其不适合大规模训练样本的场合。文献[5]提出的极限学习机,具有运算速度快、泛化能力强、不易过拟合的优点,但隐含层节点的输入权值和阈值随机生成,且只有一个隐含层,致使模型的精度低,鲁棒性差。文献[6]提出核集极限学习机算法处理数据量较大的分类问题,其中泛化核向量集找出大训练集的核集,然后利用ELM进行分类。文献[7]提出了一种基于快速留一交叉验证的在线核极限学习机,方法逐次增加新样本与删除旧样本的方式进行在线训练。有效避免了由随机划分所引起的较大统计误差,避免过拟合和欠拟合问题。但数据量较大时,所造成的计算开销就会急剧加大,导致效率低。
针对上述问题,提出基于分层核极限学习机在滚动轴承故障诊断方法,将测得信号经EEMD分解处理后得到一系列IMF分量,并提取各分量的排列熵PE值组成高维特征向量集;利用高斯核函数的内积来表达ELM算法的隐含层输出函数并使用自动编码器对其分层,从而隐含层节点数自适应确定和隐含层阈值与输入权值满足正交条件;最后,将所得高维特征向量集作为HK-ELM算法的输入,通过训练建立核函数极限学习机滚动轴承故障分类模型,进行滚动轴承不同故障状态识别。
2 相关工作
2.1 极限学习机
ELM算法[8]的结构:由输入层、隐含层和输出层组成,层与层之间通过神经元连接。n个隐含层节点,ωi和βi分别为连接输入层和隐含层、连接隐含层和输出层的权重矩阵,xi,yi分别为输入和输出,bi是隐含层的阈值。
算法原理如下:给定 P 个不同的数据样本(xj,tj)∈Rn×Rm,对于含有N个隐含层节点,且激活函数为g(x)的单隐含层前馈神经网络(SLFNs),给定 P 个不同的数据样本(xj,tj)∈Rn×Rm,其输出表达式如下:
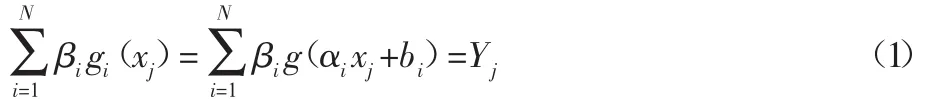
式中:bi—隐含层阈值随机生成;βi—连接输入层和隐含层的权值矩阵,j=1,2,…,N。若 g(x)无限可微,输出能够零误差的逼近输入样本的真实输出值,用公式可以表达为:

其中H为隐含层输出矩阵:
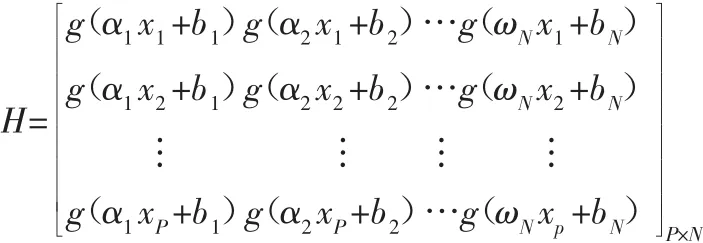
根据最小二乘法计算输出权重:β=H*T,H*表示H的Moerr-Penrose广义逆矩阵。为了提高算法的泛化能力和稳定性,Huang等在β的基础上增加参数I/C公式如下:

2.2 分层核极限学习机
在极限学习机算法中,使输入样本数据等于输出样本数据;并使随机生成的隐含层节点的权值α和阈值b都满足正交条件,这就是ELM自动编码器[9],下面叫做ELM-AE。
在ELM-AE中生成的正交隐含层权值α和阈值b把输入样本数据映射到高维空间中,如由Johnson-Lindenstrauss引理[10]得到如下计算公式:

ELM-AE的输出权值β使特征空间到输入数据的学习转换,根据以下公式计算输出权值β:

采用的高斯核函数满足Mercer核理论[11]可以作为核函数应用到极限学习机中,其表达式如下:

在ELM的算法中,隐层节点输出函数g(x)是不知道具体形式的函数,那么就可以把g(x)的内积形式用核函数表示出来。所以核ELM算法中,隐层节点输出函数g(x)的具体形式不用给出,只需要知道核函数K(x,xi)的具体形式就可以求出输出函数的值,且隐层节点数能够自适应确定。
H-K-ELM是在ELM-AE的基础上进行堆叠而形成的一个分层神经网络。H-K-ELM不需要微调,其隐含层参数通过ELMAE进行初始化,使得参数满足正交条件,并利用高斯核函数的内积表示激活函数。网络结构,如图1所示。圆圈表示神经元节点,每一层的输出会作为下一层的输入依次进行,直到达到满意的精度和合适的测试时间,最后一个隐含层与输出层的输出矩阵用最小二乘法进行计算。H-K-ELM算法流程,如图2所示。
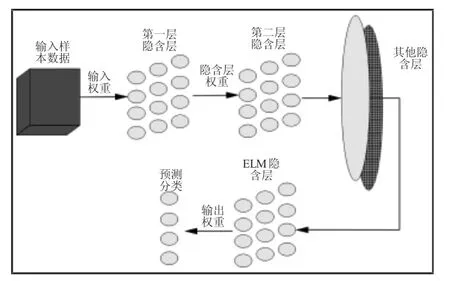
图1 H-K-ELM的网络结构图Fig.1 Network Structure Diagram of H-K-ELM

图2 H-K-ELM算法流程图Fig.2 Flow Chart of H-K-ELM Algorithm
3 仿真实验
借助美国Spectra Quest公司机械故障综合模拟试验台来验证所提方法的有效性,如图3所示。该实验台由电机、变频器、联轴器与转子等组成。加速度传感器分别布置在靠近电机轴承座的水平径向、垂直径向和水平轴向三个方向上采集信号,所采集的振动信号经由LMSTest.Lab数据采集仪接入计算机进行分析、保存,如图4所示。滚动轴承的转速为2100r/min,采样频率为5120Hz,数据的采样点数为5120个。

图3 机械故障综合模拟试验台Fig.3 Comprehensive Simulation Test Bed for Mechanical Failure

图4 LMS Test.Lab数据采集仪Fig.4 LMS Test.Lab Data Acquisition Instrument
通过依次对图3中轴承的正常、外圈故障、内圈故障、和滚动体故障4种状态件进行更换,并采集上述四种状态下的振动加速度信号,分别获得每种状态30组数据,每组数据包含5120个采样点。抽取每种状态20组作为训练样本,余下10组作为测试样本。首先对训练样本和测试样本数据进行EEMD分解得到其IMF分量,选用前五个包含主要故障信息的IMF分量,如图5内圈故障的IMF分量,如图5所示。然后求取四种状态信号IMF分量的排列熵值,组成特征向量作为H-K-ELM滚动轴承故障诊断模型的输入。测试样本的四种状态下的部分排列熵值,如表1所示。

图5 内圈故障的IMF分量Fig.5 IMF Component of Inner Circle Fault
为验证上述方法的优越性。分别将表1中的特征向量输入到SVM、K-ELM与H-K-ELM中进行训练与测试,其中SVM中惩罚参数C与核宽度系数σ人为设为2与0.2;H-K-ELM中首先确定各多层极限学习机的层数。先从测试时间来看,H-K-ELM模型进行轴承故障识别,当网络结构超过5层时,测试时间迅速增长,效率偏低,因此舍弃超过5层以上的网络结构。再从测试正确率来看,4层要比3层的测试正确率要高。因此H-K-ELM模型的网络结构选择4层。利用核函数自适应确定各层的神经元节点数口分别为 41,37,100,2。
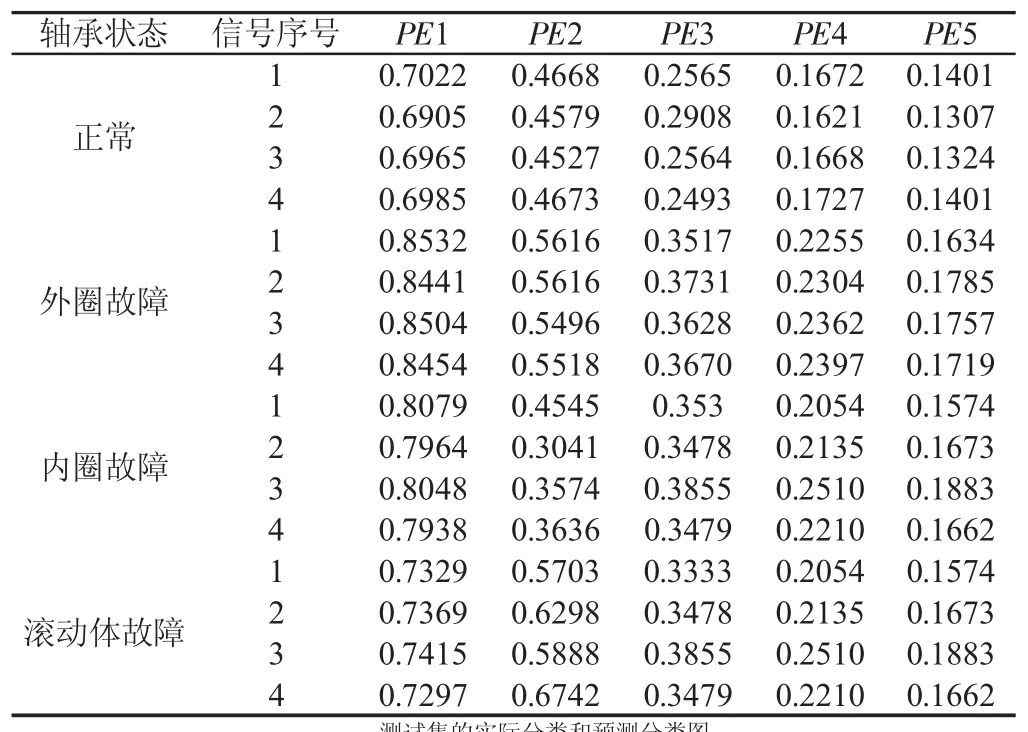
表1 滚动轴承四种排列熵值特征向量Tab.1 Four Characteristic Vectors of Permutation Entropy Value of Rolling Bearing
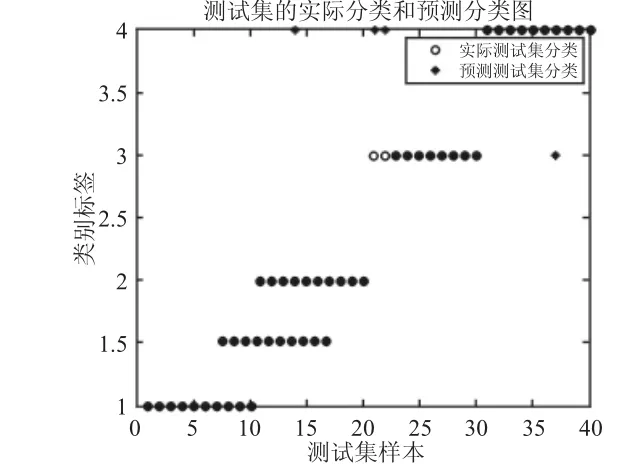
图6 SVM的测试样本分类结果Fig.6 SVM Test Sample Classification Results
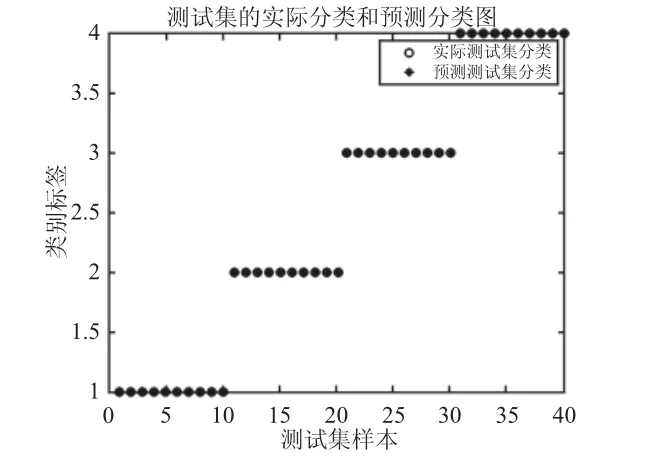
图7 H-K-ELM的测试样本分类结果Fig.7 H-K-ELM Test Sample Classification Results

表2 SVM、K-ELM、H-K-ELM三种诊断模型性能比较Tab.2 Performance Comparison of SVM,K-ELM and H-K-ELM Diagnostic Models
三种算法的测试样本分类结果分别,如图6、图7所示。从图6中看出SVM对于轴承故障分类精度达到90%(36/40);从图7中看出,H-K-ELM对于轴承故障分类精度达到100%(40/40)。上述四种方法的对比结果,如表2所示。
4 结语
针对滚动轴承振动信号的不规则性和复杂性,导致轴承状态难以有效识别的问题,提出基于分层核极限学习机的滚动轴承故障诊断方法。将提取的各IMFs分量的排列熵作为本模型的输入,进行轴承故障的分类和识别。通过实验结果分析,得出所用方法对比SVM、K-ELM具有良好的效果以及更高的模型的精度与鲁棒性,在轴承故障诊断领域有广泛的应用前景。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
成都信息工程大学学报(2022年3期)2022-07-21
保定学院学报(2022年2期)2022-04-07
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
数学大世界(2019年7期)2019-05-28
江苏通信(2018年4期)2018-12-04
自动化学报(2018年2期)2018-04-12
北京航空航天大学学报(2017年6期)2017-11-23
制造技术与机床(2017年4期)2017-06-22
中华建设(2017年1期)2017-06-07
