
基于粒子群优化的FCM-SVM算法的锅炉燃煤结渣预测
2018-09-05 01:02王东风
山东电力技术 2018年8期
任 林,王东风
(华北电力大学,河北 保定 071000)
0 引言
目前,国内煤炭资源紧缺情况日益严重,导致电站燃煤煤质受到很大影响。据有关部门统计,我国的燃煤锅炉中有50%的锅炉属于易结渣型。加之当前电厂锅炉燃烧煤种多变且质量不稳定,经常与锅炉设计出现偏差,如果不实施有效地改进措施,锅炉燃烧受热面积灰结渣问题会日益严重。电站燃煤结渣会严重影响锅炉的安全、经济运行,因此,建立电站燃煤结渣程度预测模型对于每个电站来说都显得尤为重要。
电站锅炉燃煤结渣是一个非常复杂的物理、化学反应过程,还受到温度场、空气动力场及炉膛内设计影响[1],国内外许多专家学者都对电站燃煤结渣预测做了研究,主要有单一指标评判法与多指标评判法。实践表明,单一指标预测方法简单、快速,但准确率非常低。目前,电站燃煤结渣预测的研究主要集中在多指标评判方法。多指标评判方法主要包括模糊数学评判法、人工神经网络评判法、模式识别判别法以及支持向量机判别法等。张奕河,吴小兰[2]将模糊综合评判法应用于电厂的燃煤锅炉结渣预测,通过实例验证了此方法是合理有效的。徐乾[3]应用模糊数学中的最大隶属度原则,根据煤质结渣特性指标以及炉膛运行参数等6个指标,对锅炉结渣程度进行预测。文孝强,徐志明等人[4]以燃煤结渣特性指标以及锅炉运存参数为指标,基于模糊相对权重建立了燃煤锅炉结渣特性预测模型。单衍江等[5]用偏最小二乘回归与神经网络耦合,建立了某燃煤供热锅炉结渣预测模型。徐志明,赵永萍等[6]应用SVM算法对电厂燃煤锅炉结渣问题进行建模,并利用模拟退火算法对SVM模型参数进行了优化。崔震华[7]应用不同的BP神经网络算法,来研究煤灰各组分含量与煤灰熔融特性之间的关系,并且分析影响煤灰熔融特性的因素。文孝强等人[8]将直接模糊模式识别与基于Vague集的距离意义下相似度量理论结合,将上述两种理论引入燃煤锅炉结渣特性的评判中。兰泽全等[9]采用模式识别方法,在模糊数学的基础上,将燃煤结渣的四个常规指标与综合指数R结合,构成一个评判因素集,对锅炉不同部位的结渣样本进行结渣程度倾向性分析。文献[10]将支持向量机应用于电站燃煤结渣预测,实现了预测正确率的提升。王晓文[11]采用支持向量机实现了电站的燃烧优化控制。文献[12]应用模糊C均值聚类与支持向量机预测电站燃煤结渣程度。文献[13]以混合粒子群优化支持向量机算法,同时优化算法结构,使SVM算法预测精度提高。
在此基础上,提出一种基于模糊C均值聚类预处理数据,并应用粒子群优化的支持向量机(particle swarm optimization support vector machine,PSO-SVM)建立电站燃煤结渣预测模型,并以真实的电站燃煤结渣数据测试其准确性。
1 锅炉结渣特性影响因素分析
锅炉燃煤结渣过程不是简单的线性问题,而是多因素互相影响的复杂性问题[14]。当前,判断电站锅炉燃煤结渣的因素主要有:1)根据燃煤煤灰的组成特性来确定,比如燃煤灰质中的硅铝比m(SiO2/Al2O3)、硅比 G、碱酸比 m(B/A)、铁钙比 m(Fe2O3/CaO)及氧化铁含量等。2)根据燃煤的物理特性来确定,比如软化温度t2、煤灰的烧结特性、煤灰黏度特性。3)根据锅炉设计与工况特性来确定,如无因次炉膛实际切圆直径Dw、无因次炉膛最高温度tw以及过量空气系数a等。本文选取了影响锅炉燃煤结渣的7个关键影响因素:软化温度t2、硅铝比m(SiO2/Al2O3)、碱酸比 m(B/A)、硅比 G、综合指数 R、无因次炉膛实际切圆直径Dw以及无因次炉膛最高温度tw。表1为各影响因素的结渣判别界限。
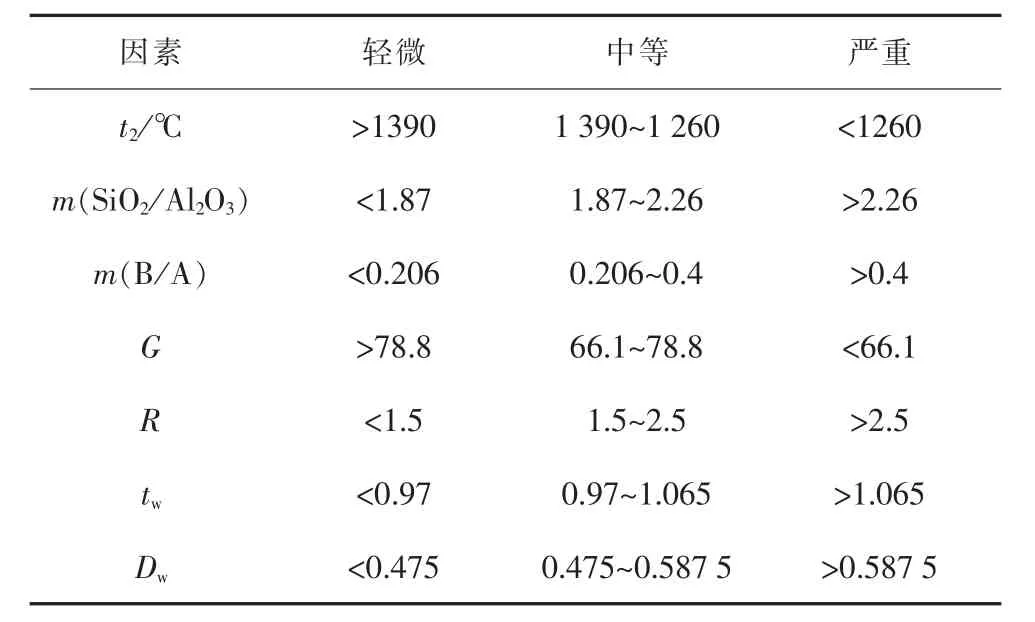
表1 7个影响因素的结渣判别界限
2 方法介绍
2.1 模糊C均值聚类算法
模糊C均值聚类法(FCM),即众所周知的模糊ISODATA,是由 Dunn J[15]和 Bezdek J C[16]提出的一种采用隶属度矩阵U确定每个样本点属于某个聚类中心的程度的一种聚类算法。
给定数据集 X={x1,x2,…,xn},设定聚类中心个数为 c,(c≥2),a1,a2,…,ac为 c 个聚类中心。将数据集X分为k类,可以用一个模糊矩阵U表示,U=μj(xi)。U=μj(xi)表示第 i个数据属于第 j类的隶属度大小。则基于隶属度函数的聚类损失函数Jf可写为

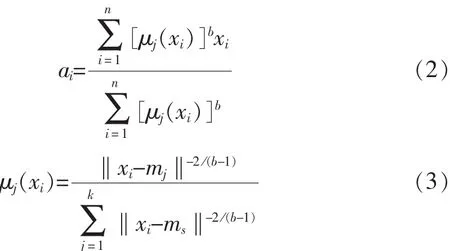
采用迭代的方法解(2)、(3)式,直至满足收敛条件,得到最优解。
模糊C聚类算法步骤如下:
给定模糊C聚类的分类类别数k,并设定迭代过程的收敛条件,将聚类中心初始化;重复下面的A、B运算过程,直至各隶属度稳定:A:采用已经计算出的聚类中心ai根据公式(3)计算隶属度函数U;
B:用当前的隶属度函数U按照公式(2)重新计算各个聚类中心ai。
当算法收敛稳定时,就得到了所需要的聚类中心a与各数据的隶属度U,模糊化过程随之结束。
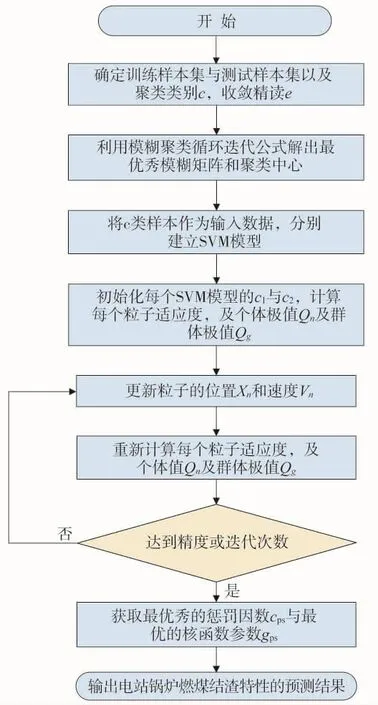
图1 模型流程
2.2 粒子群优化的支持向量机
SVM预测效果受到自身的核函数参数和惩罚系数参数的影响,传统的SVM网络采用交叉验证法选择参数往往达不到理想效果[17]。传统的SVM对电站燃煤结渣的预测正确率不太理想,此外,燃煤结渣还受到空气动力场等客观因素的影响,不确定性较高。粒子群优化(particle swarm optimization,PSO)在处理多目标优化中能以较大概率找到问题的全局最优解,且相比于传统随机方法计算效率高、鲁棒性好,能有效适应不确定性较高的样本序列[18]。因此,本文中采用粒子群优化算法对支持向量机中的核函数与惩罚系数进行优化,建立基于模糊C聚类预处理数据的PSO-SVM预测电站燃煤结渣特性预测模型。
PSO-SVM预测电站燃煤结渣的主要思想是随机产生一个SVM的惩罚因子CS与核函数参数gS,并将其最为粒子群的初始位置,在利用粒子群算法搜寻最优的SVM参数,建立SVM新的模型,进而预测出电站燃煤结渣特性。其具体流程如图1所示。PSO算法每一次寻优的过程中,通过比较前后两次的适应度值和极值来更新自己的速度,寻找最优的粒子的位置,即惩罚参数、核函数参数的最优解CPS和gPS。算法如式(4)~(6)所示:
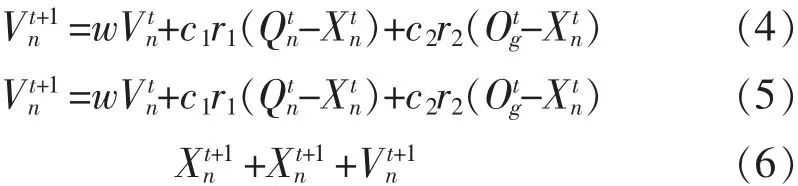
式中:t为迭代次数;c1、c2为加速因子;r1、r2为随机函数在[0,1]区间的随机数;w为惯性权重;Qn为群体极值;Vn为第n个粒子的速度;Xn为粒子n的位置。
3 燃煤结渣特性预测实例分析
3.1 数据及模型参数设置
统计文献[19,20]中的燃煤结渣数据,共得到39组结渣样本,以其中前30组作为训练样本,后9组作为测试样本,验证本文所述方法的有效性。所有数据如表2所示。
以第1~30组样本数据为训练样本,分别建立SVM、FCM-SVM和FCM-PSO-SVM预测模型,以第31~39组样本为测试样本。SVM模型中直接将7个影响燃煤结渣特性的因素指标作为模型输入,结渣程度作为输出FCM-SVM模型中,先判别出每个测试样本所属的类别,再用该类别所建立的支持向量机预测模型进行预测。SVM与FCM-SVM模型的惩罚因子与核函数采用交叉验证方法获得。
FCM-PSO-SVM电站燃煤结渣预测模型中惩罚参数C和核函数参数g应用粒子群算法进行多目标寻优。PSO种群大小设为30,最大迭代次数为500,惯性权重 w初始为 1,粒子初始速度为[0,1]之间的随机数,并取SVM计算的初始参数为粒子初始位置。
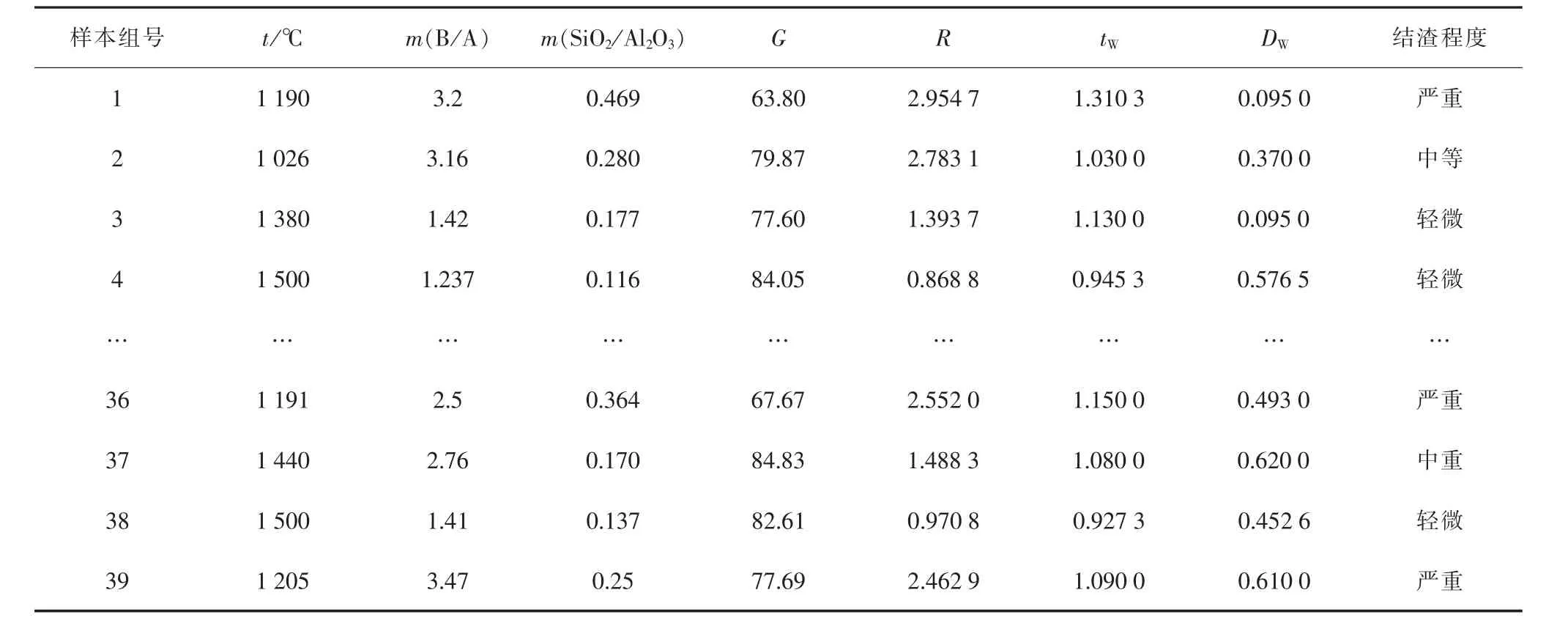
表2 39组电站锅炉燃煤结渣数据
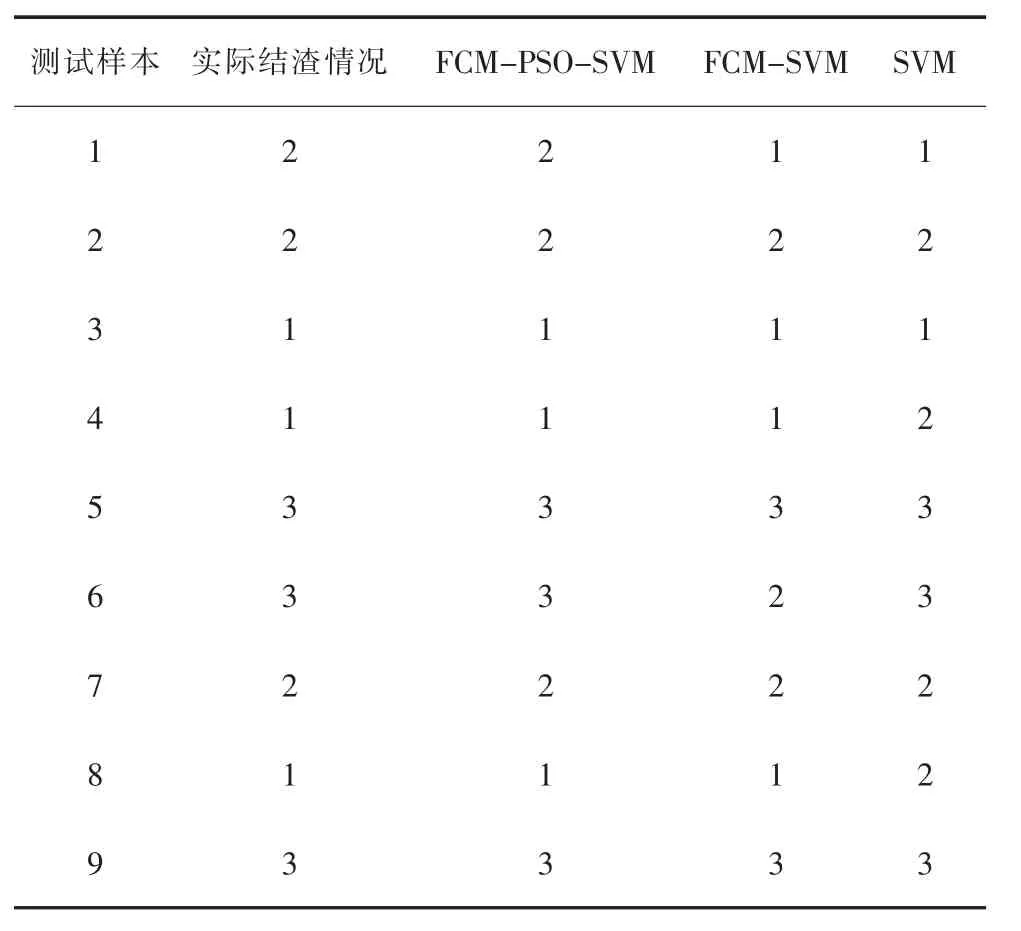
表3 三种模型预测结果与实际结渣程度对比
3.2 实验结果与分析
在三个模型中,关于各样本的输出,实际结渣程度用数字1、2和3,其中1为轻微结渣,2为中等结渣,3为严重结渣。
三类模型的输入结果与实际结渣程度的对比如表3所示。可以看出,模糊C聚类处理后的应用粒子群优化的支持向量机模型正确率最高,达到100%,而单纯的SVM模型的正确率最低,只有66.67%,FCM-SVM的正确率介于二者之中,为77.78%。这是由于支持向量机虽然具有良好的泛化能力,但传统支持向量机的参数选择具有一定的随机性和主观性,影响拟合的准确度,经常出现过拟合的现象。而基于FCM的SVM可以有效地将过拟合程度降低,故经过模糊C聚类预处理SVM模型的预测正确率高于传统的SVM模型。而在支持向量机模型中,惩罚因子c与核函数g的选择同样能影响模型预测的准确程度,本文算法在基于粒子群算法对参数选择优化后,拟合效果又有了进一步的显著提升。
4 结语
提出了基于FCM预处理的PSO-SVM电站燃煤结渣特性预测模型,通过对实际燃煤结渣数据的拟合,表明了该模型能够有效提升电站燃煤结渣特性的预测精度。
为电站燃煤结渣特性的预测提供了理论支撑,能够更好地指导电厂根据煤质改变预测燃煤结渣情况,从而提前为处理锅炉结渣做准备。对降低因燃煤结渣而引起的经济效益损失有重大意义。
猜你喜欢
电力科技与环保(2022年3期)2022-07-15
能源工程(2022年2期)2022-05-23
中学生数理化·中考版(2021年12期)2021-12-31
建材发展导向(2019年5期)2019-09-09
科学与财富(2017年30期)2018-01-01
农业科技与装备(2017年6期)2017-11-09
科技创新与应用(2017年6期)2017-03-23
通信电源技术(2016年3期)2016-03-26
中国资源综合利用(2016年1期)2016-02-03
中国新技术新产品(2012年21期)2012-12-28
