
基于结构正则化方法的半监督降维研究
2018-09-20 08:54张喜莲刘新伟樊明宇
温州大学学报(自然科学版) 2018年3期
张喜莲,刘新伟,樊明宇
(温州大学数理与电子信息工程学院,浙江温州 325035)
随着信息技术的快速发展,许多行业都会涉及到带有大量特征的高维数据,这些高维数据经常包含冗余特征和噪声特征等,传统的机器学习方法难以直接对此类数据进行分析,于是降维就成了机器学习与模式识别领域中的一个关键问题.所谓降维,就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中,从而挖掘出隐藏在高维观测数据中有意义的低维结构,来研究数据属性.在很多模式识别应用中,降维是数据预处理的重要组成部分.
在过去的数十年里,研究学者提出了许多经典而有效的降维方法,如PCA[1]、LPP[2]、SLPP[3]、CLPP[3]、NPE[4]、GNMF[5]、DUDR[6]等.根据数据的有无标签信息,降维方法可分为有监督降维和无监督降维.有监督降维需要数据都有类别标签信息,而标记大量的无标签数据需要花费大量的人力和物力;无监督降维仅利用了无标签数据的信息,无法利用少量有标签数据的信息.在机器学习中,往往会遇到大量无标签的数据和少量有标签的数据,单纯的无监督降维和有监督降维都不能达到令人满意的效果.同时利用这些有标签的数据和无标签的数据可以提高降维的效果,因此,半监督降维就成为了近几年的研究热点.
本文提出一种结构正则化半监督降维算法,主要贡献是:
1)能够学到两种形式的数据结构特征,软数据结构和硬数据结构.成对数据点之间以实数型定义的相似性表达了软数据结构;通过数据分割可以学到数据的分类信息,称为硬数据结构.
2)数据结构化和降维的结果交替优化,更好的数据结构能够保证得到更优的降维结果,同时,更好的降维结果能够帮助得到更好的数据结构.因此,在本文的框架中,数据的结构化学习和降维的每个子任务可以相互促进提升.
3)在降维的回归框架中,软数据结构和硬数据结构被公式化为正则化项,在保证收敛的情况下,这个算法能够有效地优化计算与实现.
1 提出的框架
1.1数据结构化学习
假设在数据子空间的一个联合体中,每个数据点能够被其它数据点线性表出,公式化如下:
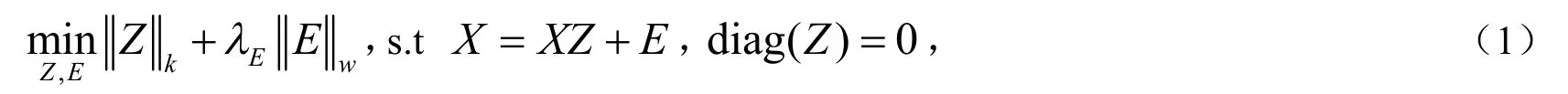
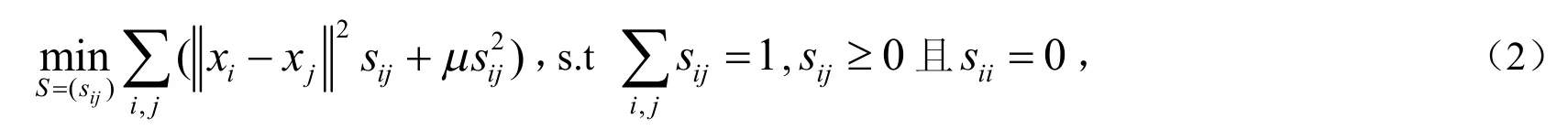
这里μ是正则化项,其目的是使原始数据的先验条件为均匀分布.显而易见,样本较近的数据点对应该有较大的相似性,相似矩阵S的估计能够被当成一种局部的结构化特点.自表述模型(1)是保持全局和稀疏重构数据结构化的,而自适应的邻接模型(2)是以数据的局部相似性为基础且针对数据局部结构化的,一旦找到Z(或者相似矩阵S),通过引入关联矩阵或者,然后应用谱聚类,就能够实现数据分割.假设聚类结果已经给定{t1,t2,… ,tN},ti∈ { 1, 2, … ,C }是xi的类别标签,C是类数,在本文中,使用非负实值描述点对之间相似性的关联矩阵W,作为软数据结构化;而提供数据点类特征的数据分割结果,作为一种硬数据结构化[7].
1.2 线性判别分析
线性判别分析(LDA)目标是寻求一种方向:在同类中,数据点之间离得较近,在不同类中数据点之间离得较远.对于已经给定的类别标签数据集 X = { x1,x2,… ,xn},LDA的主函数如下:

Tr(·)指矩阵迹算子, A ∈ Rm×d是映射矩阵,和S=b分别是类内离散度矩阵和类间离散度矩阵,nc是样本在第c类中的样本数量,是第c类中的第i个样本,是第c类中样本的均值,是所有样本的均值.定义为全散度矩阵,因此有 St=Sw+Sb.LDA的主函数等价于:
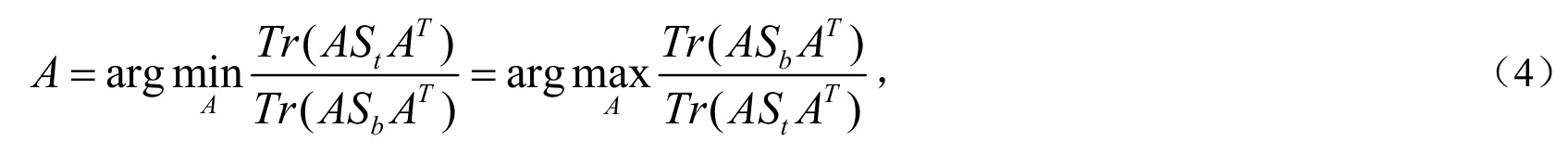
A由广义特征值问题 Sbα =λStα的最大特征值所对应的前m个特征向量组成,其中λ是特征值,α是所对应的特征向量[8],由于它的简单有效性,LDA被广泛应用在机器学习中.
1.3 半监督降维
这里我们公式化半监督降维[9].对于样本数据集它的前l个样本是有标签的,记为第l+1个样本到n个样本是无标签的,记为标签矩阵记为这里.通过数据结构化学习能够获得数据的软标签矩阵,然后通过半监督学习得到硬标签矩阵——硬数据结构化.
此外,我们希望降维后的结论能够影响结构化学习过程.在降维后,当Axi和Axj比较接近时,数据xi和xj的相似度是比较大的;yi和yj比较接近时,标签yi和yj的相似度也是比较大的.在半监督降维中,目的是使投影数据矩阵AX和相似度矩阵W尽可能地相似:
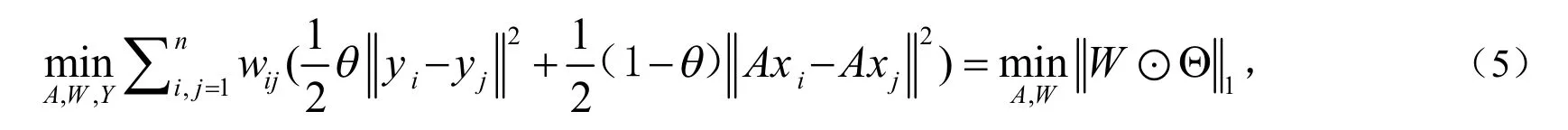
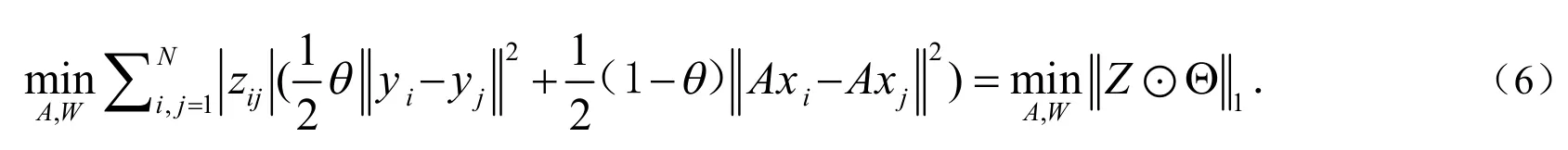
把(4)和(6)结合起来,公式化结构正则化半监督降维(Sr-SSDR)的优化框架如下:

由(7)式可以看到,当Y,A定时,本文的算法学习了映射后数据特征的数据结构(前三项),当Z定时,对于降维问题,硬数据结构化被转化为正则化项.本文的方法在很大程度上减轻了噪声对数据的影响[10].
1.4 优化算法的步骤
这一部分,我们提出一种有效的优化模型.优化算法具体步骤:1)当Y和A定时,优化Z和E直到收敛;2)当Z和E定时,优化Y和A.当标签矩阵Y和映射矩阵A(初始化为I)给定时,通过优化下列结构化问题求解出矩阵Z和E:
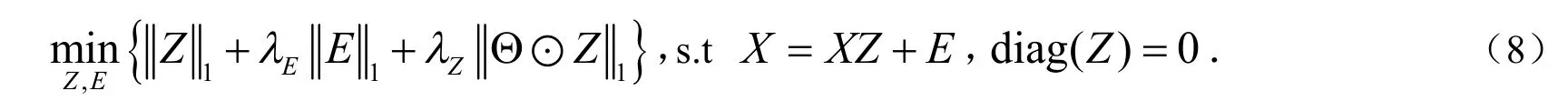
对于问题(8),用ADMM(Alternating Direction Method of Multipliers)算法,通过引入增广矩阵 Q = Z - d iag(Z),问题(8)就等价于:
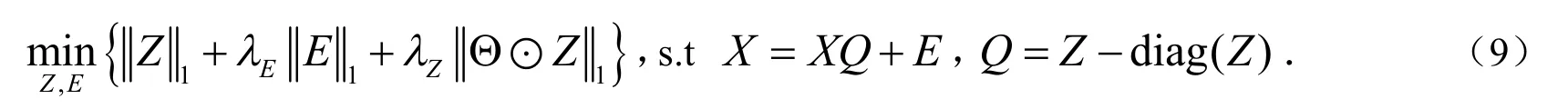
进一步,可得到上述优化问题的增广的拉格朗日函数如下:

其中Y1,Y2是拉格朗日乘子矩阵,μ>0是一个自适应参数.对于(10)中Z的子问题,通过ADMM算法,得到Z的闭式解:
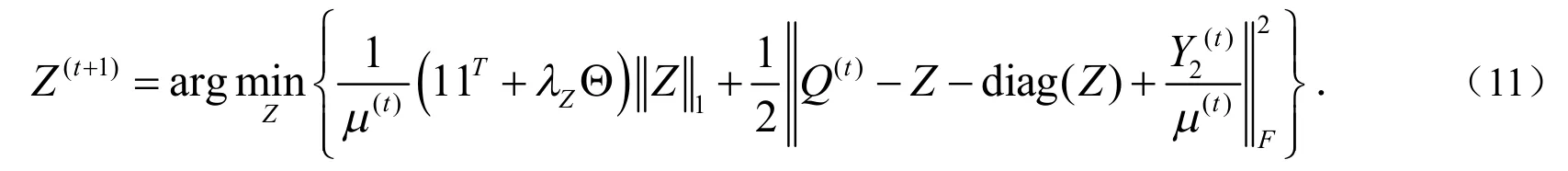
Z的闭式解可以简化为:

为了优化(10)中的Q,对(10)关于Q求导,令导函数为0,得出的Q值就是最优解.
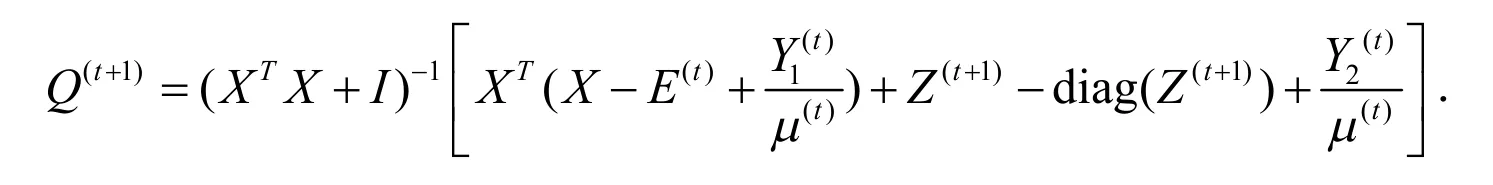
当其它的变量都固定时,求解噪声E:
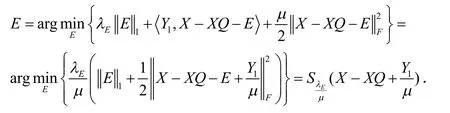
求解结构正则化半监督降维.
在自表述矩阵Z和噪声矩阵E达到收敛的情况下,优化类别标签Y和投影矩阵A.当Z和E,A定时,优化Y,目标函数如下:
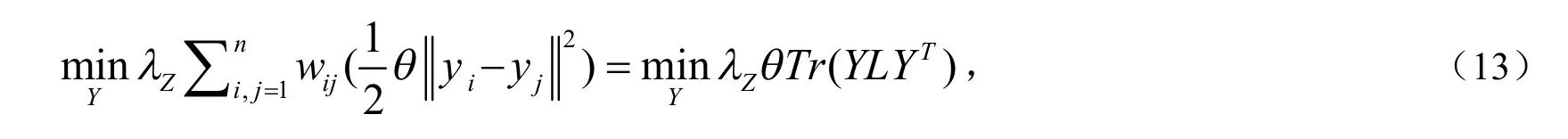
其中L是拉普拉斯矩阵,L=D+W, D = d iag()(i=1,…,n)是度矩阵且是一个对角线上元素为的对角矩阵.为计算方便,令则优化(13)就相当于优化下式:
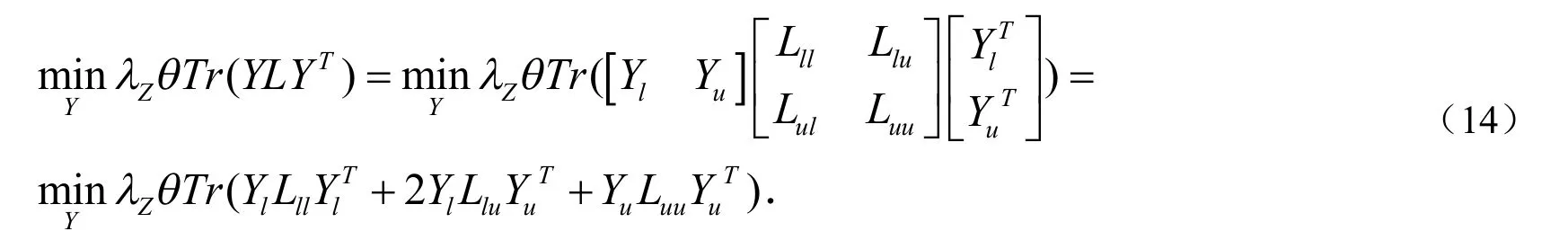
由于在 Y =[Yl, Yu]中,Yl是已知标签,所以求解Y实际只需求解未知标签Yu即可.为了求解这一问题,对(14)式关于Yu进行求导,令导函数为0得的闭式解为:

给出标签Y,问题(7)化简为下列问题:
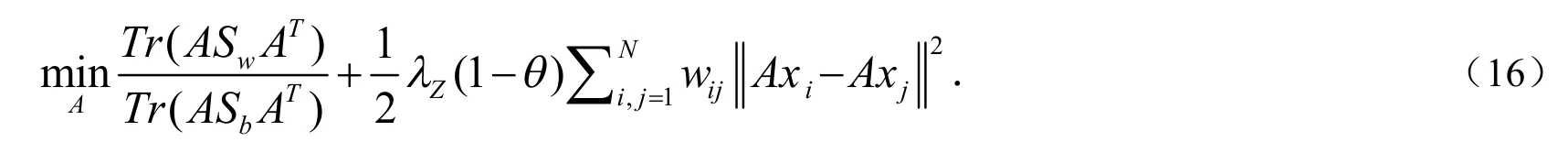
基于标签Y,可估计出类内散度矩阵Sw和类间散度矩阵Sb.由于A存在于分子、分母和条件项中,很难直接去求解(16),这里采用谱回归把复杂问题(16)转化为一种等价的回归形式,使A更容易求解出来.令是中心化的数据矩阵,类间散度矩阵
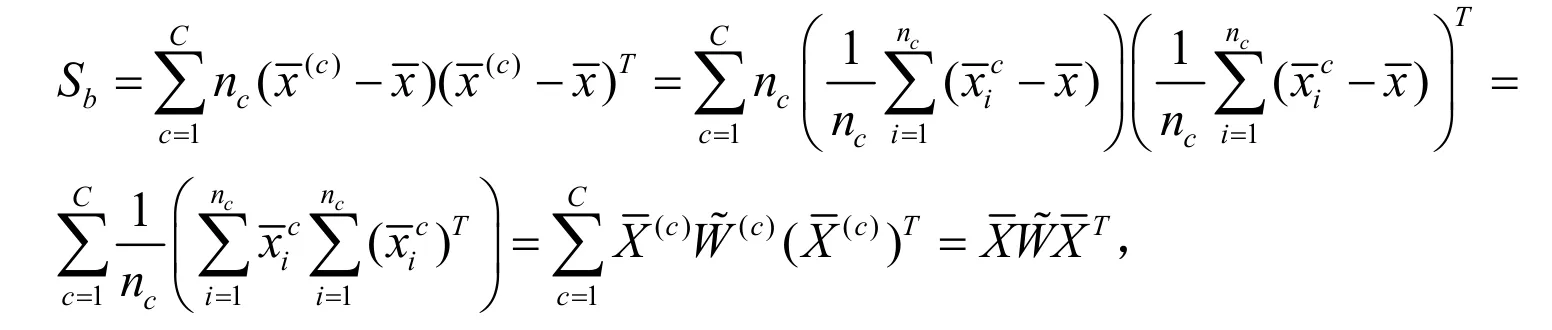

定理1表明我们并不用解决(17)中的特征值问题,而是通过以下两步求解LDA问题:
2 讨 论
本文方法(SSrDR)使用了交替优化的算法——同时优化Z和E直到收敛,接着优化Y和A,交替优化,直到Z,E,Y,A都达到收敛.这里优化Z和E是一个内循环,优化Y和A是外循环.采用本文方法求解投影矩阵A时,把复杂的特征值求解问题转化为一种等价的回归问题,其收敛速度更快,更容易求解,大大缩短了计算时间.
3 实 验
用两个图像数据集(COIL20,Mpeg)做实验来测试本文所给方法.我们用分类精确度作为性能度量,把最近邻分类器应用在无标签样本的嵌入中去计算分类精确度,所有的实验都独立实验 50次以上.实验采用最近邻分类器的分类精确度作为评价指标,使用交叉验证法估计最终的实验结果,见图1、图2、图3、图4.
由实验结果可以看出,在每一种降维算法下,随着维度的增加,分类精确度都是逐渐上升的,在分类精确度达到稳定时,本文的算法在两种数据集上的分类精确度都是最高的.
4 结论与前景展望
本文提出了一种结构正则化半监督降维算法——同时降维和学习数据的结构特征.在本文的半监督降维方法中,通过交替优化和半监督分类,可以学到两种数据结构——软数据结构和硬数据结构,把两种数据结构当成正则化项,这种算法是一种高效的算法.大量的实验验证了本文算法的有效性.
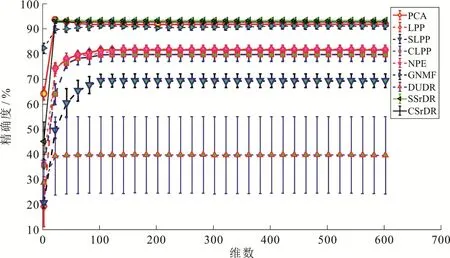
图1 COIL20数据集(有标签的数据占20%)在各种降维算法中分类精确度的比较Fig 1 The Comparison of Classification Accuracy of COIL20 Data Set (Labeled Data Account for 20%) in Various Dimensionality Reduction Algorithms
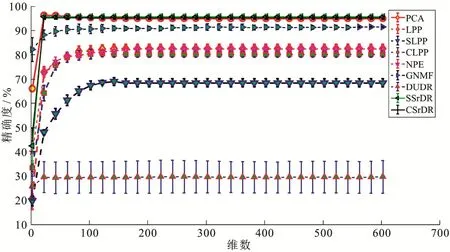
图2 COIL20数据集(有标签的数据占25%)在各种降维算法中分类精确度的比较Fig 2 The Comparison of Classification Accuracy of COIL20 Data Set (Labeled Data Account for 25%) in Various Dimensionality Reduction Algorithms
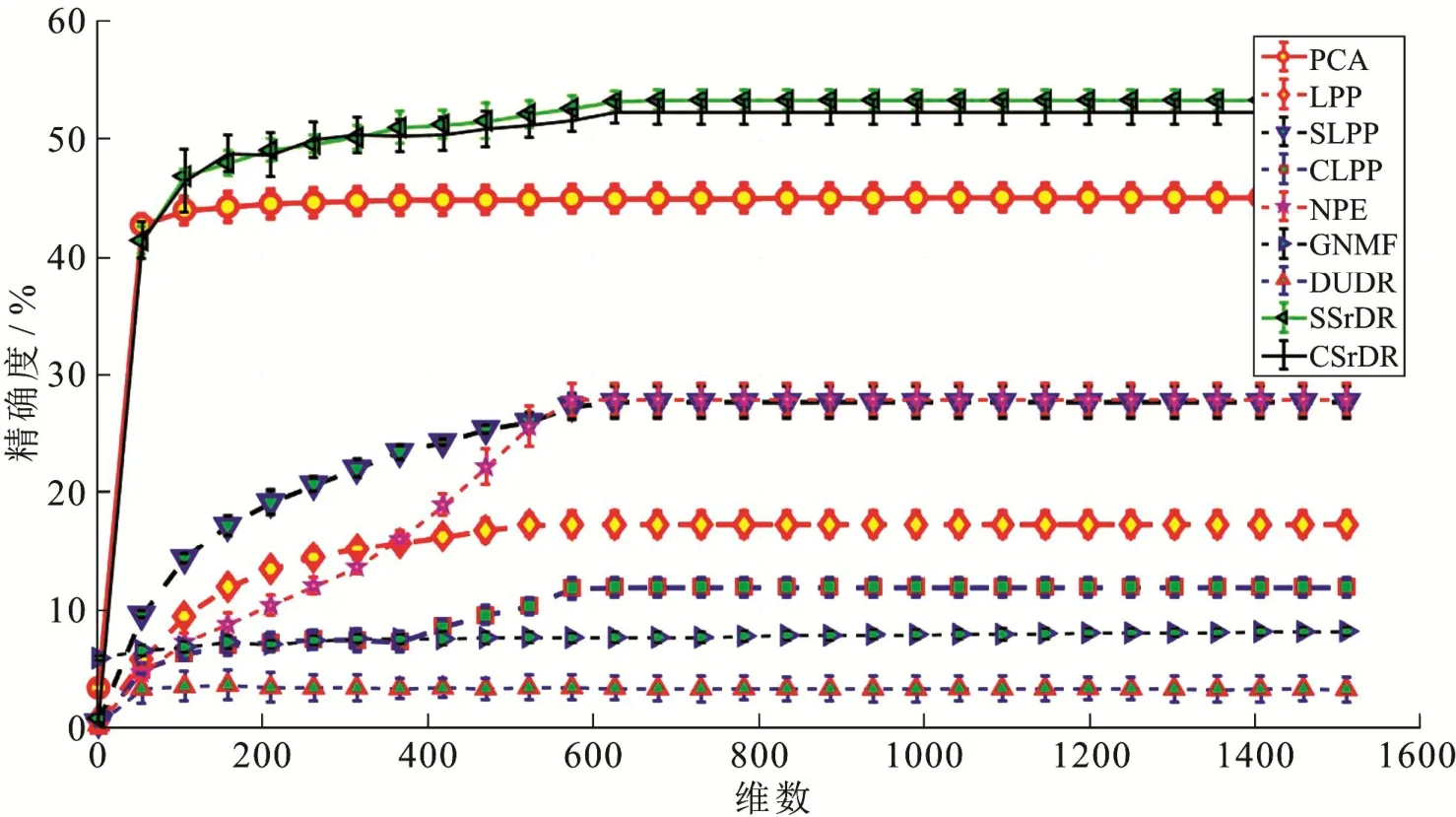
图3 Mpeg数据集(有标签数据占35%)在各种降维算法中分类精确度的比较Fig 3 The Comparison of Classification Accuracy of Mpeg Data Set (Labeled Data Account for 35%) in Various Dimensionality Reduction Algorithms
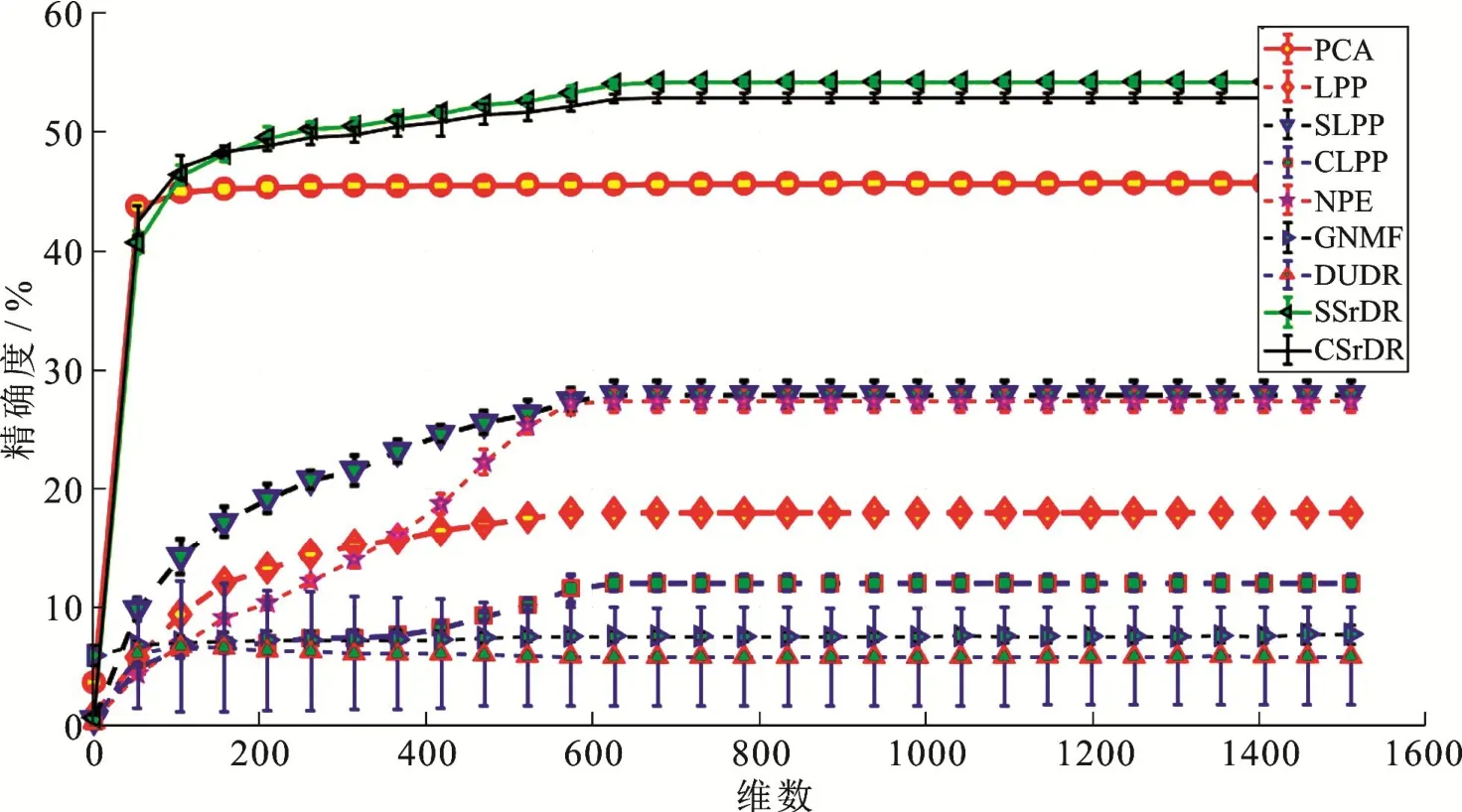
图4 Mpeg数据集(有标签数据占40%)在各种降维算法中分类精确度的比较Fig 4 The Comparison of Classification Cccuracy of Mpeg Data Set (Labeled Data Account for 40%) in Various Dimensionality Reduction Algorithms
猜你喜欢
车主之友(2022年4期)2022-08-27
课程教育研究(2021年23期)2021-04-13
云南教育·中学教师(2020年11期)2021-01-07
山东煤炭科技(2020年1期)2020-03-06
海峡姐妹(2019年12期)2020-01-14
计算机教育(2019年1期)2019-12-20
中国市场(2016年45期)2016-05-17
火控雷达技术(2016年1期)2016-02-06
中国教育技术装备(2015年21期)2015-03-11
