
K叉树地址的模糊匹配研究与实现
2018-10-09 03:05李新放宋转玲陈学业刘海行
测绘通报 2018年9期
李新放,宋转玲,陈学业,贺 彪,刘海行
(1. 国家海洋局第一海洋研究所,山东 青岛 266061; 2. 青岛海洋科学与技术国家实验室区域海洋动力学与数值模拟功能实验室,山东 青岛 266237; 3. 深圳市数字城市工程研究中心,广东 深圳 518040)
数字城市是以空间信息为核心的城市信息系统体系,而在数字城市信息资源的集成和融合中,地名地址匹配是一项非常关键的技术[1]。地名地址匹配又称为地理编码,它是基于空间定位技术的一种编码方式,提供一种把地名地址的地理位置信息转换成可被用于GIS系统的地理坐标方式[2]。应用地名地址匹配技术可以地址数据为基础纽带,使分散的信息资源库之间建立有机的联系,实现不同数据类型、不同系统之间的互操作,满足数据共享的要求[3-5]。
近年来,随着地理信息技术的不断发展和完善,地名地址匹配技术也在不断改进,国内外专家进行了很多深入的研究工作。文献[6]提出了一种基于动态生成矩阵的经典算法解决字符串模糊匹配问题,许多研究人员基于该算法做了一系列的优化改进;文献[7]提出了利用位向量法的BPM算法,但该方法需要的空间正比于字符集的大小,当字符集很大时,需要很高的空间;文献[8]提出了基于过滤方法和位向量法结合的模糊匹配算法,在一定程度上提高了模糊匹配的效率;马照亭等提出了一种基于地址分词的自动地理编码算法[9];习明等提出了一种基于双层哈希表的中文分词优化算法[10];赵阳阳等提出了一种地址要素识别机制的地名地址分词算法[11];陈开渠等基于BPM算法和新的过滤方法,提出了BPM-BM算法,提高了字符集较大时模糊匹配的效率[12];魏金明等利用分词算法和置信度筛选的方法匹配数据,提出了一种基于置信度的地址匹配方法,提高了匹配的准确性[13];亢孟军等提出了一种地址树模型的中文地址提取方法,结合地址间拓扑关系可以从非标准地址中提取标准地址[14]。但目前快速高效准确的地名地址匹配技术并不能完全满足数字城市应用需求,一方面没有形成统一完善的标准,另一方面缺少精准高效的服务,实际上已经成为数字城市普及和推广GIS相关应用的瓶颈。
本文在分析中文地址特点及地址存放方式的基础上,通过一种基于规则和统计组合的中文地址分词方法实现分词,并且以K叉树的方式存储构建地址匹配模型,进一步提高地址匹配的准确度及效率。
1 中文地址分词
中文地址分词是地址匹配的基础,本节详细讨论与中文地址分词相关的问题,基于原始地址库通过规则和统计的组合方法实现中文地址分词。
1.1 中文地址定义
从GIS的角度看,一个中文地址是一个具有空间语义和地址模型结构的连续文本字符串,可以定义如下
A= {Xi∈A|R(Xi,Xj)≠Ф,Xi≠Xj}
(1)
式中,A为一个中文地址;Xi为中文地址要素,可以被看作是指示地理实体的最小空间语义单元;R(Xi,Xj)为地址要素Xi、Xj之间的空间约束关系;Ф为空值。定义式(1)中的地址要素Xi为
Xi={WNWF|WN∈CN,WF∈CF}
(2)
式中,WN为地址实体名称的字符串;WF为地址模型特征的字符串;CN为语料库中的地址实体名称集合;CF为语料库中地址模型特征的集合。中文地址定义如图1所示。
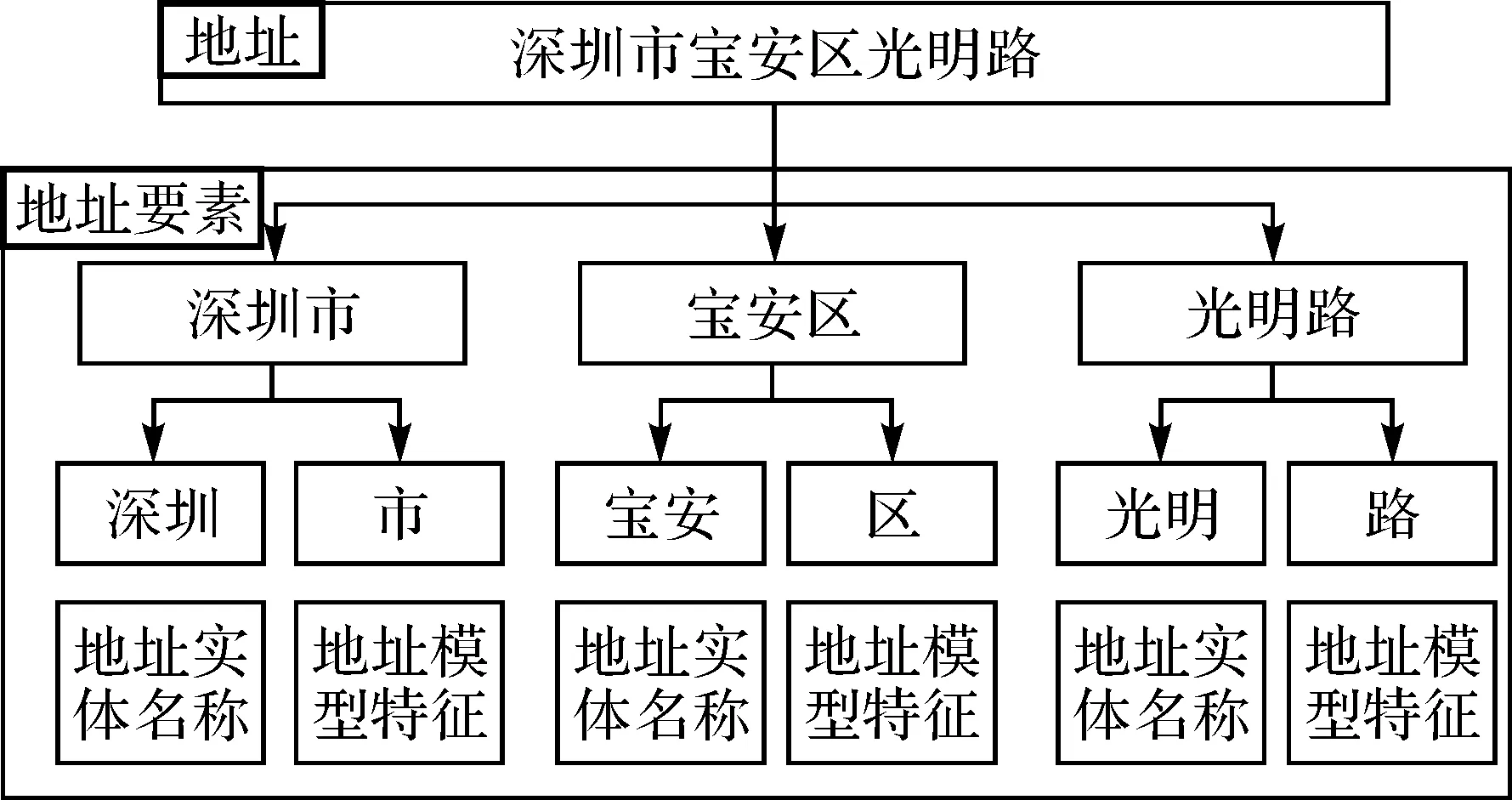
图1 中文地址定义
1.2 中文地址要素采样
中文地址中的最小语义单元是地址要素,它不仅仅是一个单词,而是由地址实体名称和地址模型特征共同组成的,在采样过程中必须考虑语料库中所有可能长度的单词,基本的遍历采样方式会产生大量具有不正确空间语义的字段,正确字段的数量与n(即地址长度)成正比,不正确字段的数量与2n成比例,如图2所示。

图2 地址采样过程
本文在研究中文地址命名规范和特点基础上,基于中文地址语言模型通过新的优化采样方法进行采样,基本采样过程如图3所示。优化的采样方法基于地址中的地址要素之间存在的空间约束关系,保证被采样的所有字段具有正确的空间语义,优化采样方法计算一个地址中所有字段的计算时间与n成正比,提高了分词效率,可以采样具有正确语义关系的地址段。

图3 单一地址的优化采样模型
1.3 基于规则和统计的组合分词
基于优化的采样模型,通过抽取语料库中的地址计算单词的重复地址频率为
AF(Si|S1S2…Si-1,Corpus)=Frequency(Si|S1S2…
Si-1,Corpus)
(3)
式中,Si为地址中位置i处的字符;Corpus为地址语料库;Frequency(Si|S1S2…Si-1,Corpus)为语料库中字符序列“S1S2…Si-1”的重复频率。通过字与字之间不同频率的变化获取中文地址不同字段的边界,基于统计结果可以很明显得出具有正确语义关系的地址要素之间的边界,实现优化的中文地址分词,如图4所示。

图4 地址语料库的AF
分词方法主要包括以下具体步骤:①通过统计学方法提取词的特征值,选取一个或多个特征值作为分词参考;②针对每一个特征值分别设计分词算法,根据算法对地址进行分词处理,得到地址分词结果集合;③对于多个分词结果集合的情况,设计合并算法求解最优分词结果;④提取分词结果,利用地址要素完善初步分词结果,得到最终分词结果。
2 基于K叉树的地址匹配
2.1 中文地址K叉树原理
中文地址的模型特点决定了它具有一定的层级关系,标准地址模型的层次关系一般为:省(直辖市)—市(地级市)—区(县、县级市)—镇(乡、街道)—村(路)—门牌号。参考标准地址模型的层次关系,数字城市中中文地址树体系的构建过程可以表述为构建一棵逻辑意义上层次结构的地址树,树的节点对应实际地理空间中的地理实体,节点之间的关系表述空间实体之间的关系。地址树的上层节点表示城市的行政区划单位,中层节点表示城市的各个功能单元,最下层节点具体对应数字城市空间目标体系中的一栋建筑等目标点。基于K叉树的特殊结构,建立不同层次之间的节点关联,抽取地址树主干索引表优先完成地址模型上层节点的搜索匹配,可以最大效率地提高搜索匹配的效率,如图5所示。
2.2 基于原始地址分词库的K叉树构建
应用原始地址数据经分词后得到的分词库作为基本词典,对原始地址库中每个地址进行分词建树,将其构建成以层次化树形结构存储的地址树。该树的节点代表实际地址数据中具有实际地理意义的实体,节点的父子关系表达了地理空间实体在空间中的上下级关系(大小关系)。地址树构建技术方法可以快速根据分词地址要素的约束关系自动构建带有空间层次关系的地址要素结构树,可用于生成标准地址库,进而避免人为构建标准地址库,具有快速、准确的特点,可服务于地址编码技术。

图5 空间目标体系与K叉树
中文地址层次结构树构建技术主要包括以下步骤:①根据原始地址数据构建初始地址树;②将树每层节点按照节点名称的第一个字符的英文字母进行升序排列;③利用正向最大字数匹配方法提取层次节点共名的部分,作为新的节点更新树结构;④遍历树,统计地理实体要素之间的层次关系,生成地址要素关系表;⑤构建地址树节点名称索引;⑥根据地址要素关系表矫正地址要素层次关系错误情况;⑦处理重名节点之间错误的上下层次关系。
2.3 搜索匹配方法
基于字典的查询匹配规则有很多种,根据扫描方向的不同,可以分为正向匹配和逆向匹配,按照不同长度优先匹配的情况,可以分为最大最长匹配和最小最短匹配。目前最常用的是最大匹配法,有正向和逆向两种方式。由于汉语单字成词的特点,最小匹配法一般很少使用。试验表明,逆向匹配的切分精度相对于正向匹配要略高,而且歧义现象也较少,本文在初步分词基础上,应用逆向匹配方式将地址要素对应到地址树节点中,实现地址匹配查询并最优地址树路径。将待匹配地址与已构建的地址树进行比较匹配,获取正确的匹配节点,对于不存在匹配节点的中文地址创建新的树节点,作为树结构更新参考。对于模糊匹配的地址,引入置信度作为权重参考,参考权重值大的作为地址匹配的优选路径构建树节点。具体算法流程包括以下步骤:
(1) 对待匹配地址进行数据清洗及预处理,主要包括去除地址中字母、标点及特殊符号等。
(2) 利用地址模型的特征名称对待匹配地址进行初步地址分词处理。
(3) 根据地址模型的关系,对分割后的待匹配数据进行验证,纠正地址要素的模型关系问题。
(4) 采用逆向匹配算法,优先从分割出来的地址要素集合的右侧开始,依次将地址要素名称与地址树进行全局的精确查找,将每一个地址要素对应查找到的地址树节点组成一个节点名称的集合,然后根据验证节点之间的层次关系,得到一条与原始待匹配地址符合度最高的地址路径。
(5) 若步骤(4)未找到符合条件的地址,根据原始地址树的统计特征值,推测待匹配地址可能的分词组合,根据节点间层次关系及单词匹配率进行置信度计算,重复步骤(4)计算合适的模糊匹配地址返回最佳匹配路径。
3 试验与验证
3.1 数据准备
利用深圳市2015年人口普查数据,共获得40余万个地址。原始数据都属于深圳辖区,但不是标准的地址格式,测试数据使用过滤器进行预处理,主要预处理工作如下:①删除重复的地址;②从地址中删除所有的符号和标点;③删除太短的地址。其中试验数据是从预处理后的地址数据中随机选择了10 000个地址数据,部分地址数据及分段例子见表1。

表1 地址数据及分段示例
3.2 系统原型
原型系统开发硬件环境为:PC台式机电脑(CPU i7-4790k,8 GB内存,1T硬盘);软件环境:Windows 7 专业版,开发平台VS2012,C#编程语言。
本文开发了基本的原型系统并基于预处理后的地址数据进行地址匹配查询,试验结果根据待匹配地址不同均可在5 s内给出优化匹配结果,原型系统如图6所示。
利用文中所提出的方法能够实现较好的分词并具有较高的准确性,但是测试过程中同时发现在处理测试地址时仍然存在一些缺陷,对于同音字、错别字等的匹配效率和准确度有待进一步完善。

图6 基于K叉树的模糊地址匹配
4 结 语
地名地址匹配是数字城市系统建设中一项非常关键的技术,中文语义和地名地址描述的复杂性对地名地址编码匹配均提出了更高的要求。本文应用基于规则和统计的组合方法进行中文地址分词,保证了主体地理空间要素、地址特征名称分割正确,应用K叉树的方式实现地址存储和匹配查询,地址匹配算法具有较好的匹配度。但是地址匹配的准确度和效率尚待进一步研究提高,可以进一步改进相关匹配算法,如引入神经网络等机器学习方法,在中文地址匹配中加入拼音模型、查询次数统计等提高匹配准确度,对于匹配速度方面引入Hadoop等大数据分布式架构,以提升匹配的效率。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
文化创新比较研究(2020年13期)2021-01-14
当代水产(2020年4期)2020-06-16
天津外国语大学学报(2020年1期)2020-03-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
山东青年(2016年2期)2016-02-28
债券(2015年9期)2015-09-29
外语教学理论与实践(2014年4期)2014-06-13
中学生英语·外语教学与研究(2008年4期)2008-03-18
