
基于本体的语义相关度研究
2018-12-19 12:44周兵孟慧君王栋
现代计算机 2018年32期
周兵,孟慧君,王栋,2
(1.河南大学,开封 475004;2.中国科学院遥感与数字地球研究所,北京 100101)
0 引言
在当下计算机网络技术飞速发展的信息化时代,人们对计算机信息的存储、传输以及处理能力的要求也迅速增加,而检索作为获取信息的重要方式也越来越受到研究人员的关注。传统的检索方法大多只停留在比较关键字异同的层面,往往忽略了更深层次的语义层面所隐含的信息,从而未能达到用户理想的检索效果。语义检索从搜索语句和检索目标的语义出发,来提高检索的准确性。本文通过对本体中的概念及属性进行研究,试图寻找多个概念之间以及概念的属性之间的多种联系,通过它们之间的相关度来锁定检索目标,并获得最终的检索结果。
1 相关研究介绍
信息检索技术是一个从简单到复杂发展的过程,从以往的基于关键词的信息检索方式发展到现阶段的语义检索,随着用户需求的增加以及研究的深入,语义检索将在信息检索领域发挥越来越重要的作用。
文献[2]提出了一种匹配本体图的语义检索方法,该方法根据本体、关系、本体图三者之间的语义相关性,提出了一种能够计算语义相关性的本体图匹配框架。在此方法中,本体之间的相关度是由两者之间的距离决定的。文献[3]提出的语义检索方法是将传统的搜索技术与传播激活技术相结合。在给定初始的本体集和相应的初始的激活权值下,由传播激活机制系统查询到相关的本体。这些初始的权值是由对与本体相关的本体数据进行经典的搜索得到的[3]。文献[4]利用上述思想进行了实验分析,并证实了方法的正确性,传播激活机制和这种基于本体的方法结合起来得到了令人满意的结果。
2 基于本体的语义相关度研究
在计算机科学与信息科学领域,本体指的是一种“形式化的,对于共享概念体系的明确而又详细的说明”,是一种共享词表,是特定领域中那些存在着的对象类型或概念及其属性和相互关系。或者说,本体实际上就是对特定领域中某套概念及其相互之间关系的形式化表达。本体中概念之间总是存在各种各样的关系,从某一个概念出发总可以找到多个与之相关的概念。
2.1 文档和查询的概念表示
2.2 相关度计算
(1)概念相关度
本体中概念相关度主要由概念或实例之间的距离以及其深度来决定。相同深度下若两个概念间的距离越短则表示概念间的相关度越大,反之相关度就越小。由于在本体中,概念的深度越深表示概念间划分的越来越细,概念间的区别越来越小,所以若两个概念间距离相等,那么概念所处的深度越深则表示两个概念间的相关度越大,反之相关度就越小。
为了便于描述,我们用simc=(ci,cj)表示概念相关度,用dis(ci,cj)表示两个概念ci,cj间的距离,用dep(ci,cj)表示两个概念的深度。当两个概念中一个为另一个的直接子孙概念时,两个概念间的距离dis(ci,cj)=|dep(ci)-dep(cj)|。否则,需要通过两个概念的公共父概
在文档的语义检索过程中,我们将文档具体化为多个概念或实例,用概念或实例来表示文档;同理将用户的检索信息也用概念来表示。以概念为基础,在本体中寻找概念及其属性之间的关系并计算搜索概念与文档中概念的相关度。
用W表示待标引的文档集,w表示文档集W中的某个文档。从文档w中可以抽取多个概念,用c表示文档w中的某个概念,概念c在领域本体中包含多个属性(属性是对概念的进一步说明,用 p0,p1,p2..来表示)。文档中概念和属性为一个语义向量,一个文档中可以抽取出多个语义向量,语义向量可表示为[6]:
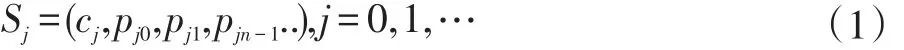
其中Sj表示文档中的一个语义向量,cj表示该语义向量中的某个概念或实例,p表示用于描述该概念或实例的多个属性。
同理,对于用户输入的搜索请求,也可以抽取为一个或多个语义向量来表示:

语义检索是根据文档和查询语句具体化得到的语义向量之间的相关度来确定检索结果集的,语义向量的相关度包括两部分,即概念相关度和属性相关度。在上述表示中,属性是对某个概念的描述,而文档的主要表示元素是概念或实例。我们可以以具体查询中概念和属性的重要性为依据来决定概念和属性的权值来进行最终语义相关度的计算。念来计算两个概念间的距离,用cfar(ci,cj)表示两概念ci,cj的公共父概念。设根结点深度dep(root)=0,相邻两概念边的权值设为1,当ci≠cj时:
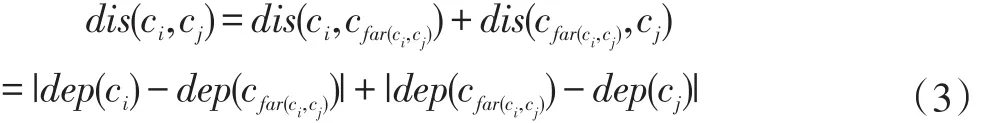
考虑概念深度对相关度的影响,取两个概念深度的平均值作为dep(ci,cj),即:
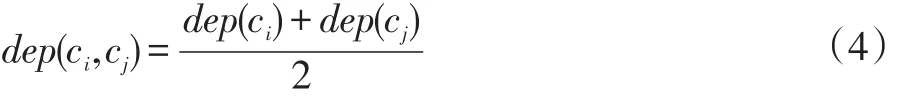
由于文档中有多个概念,每个概念或实例在文档中的重要程度也不尽相同,为了提高检索的查准率,我们对文档中概念的重要性进行计算,并将计算结果作为权值引入概念相关度计算中。用θ表示概念权值,设概念或实例在文档中出现次数为cont,某个文档中出现次数最多的概念的出现次数为contmax,则概念重要性即权值按公式(5)进行计算:

概念相关度值得范围为sim(ci,cj)∈[0,1],由以上公式(3)、公式(4)和公式(5)我们将概念相似度 sim(ci,cj)定义为:
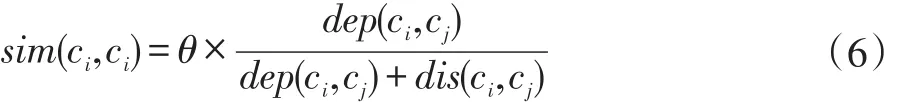
由公式(5)可以知道,当ci,cj为同一概念且文档中概念cj为出现次数最多的概念时,sim(ci,cj)=1。当θ取值相同时,将概念间距离dis(ci,cj)、概念深度dep(ci,cj)和概念相似度如表1表示:
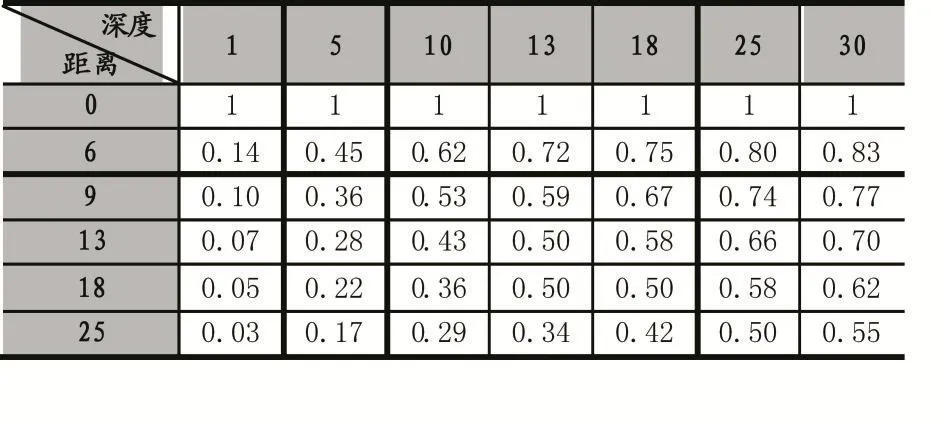
表1 θ=1时相似度与概念距离深度的关系
从表1中信息可以明显看出,当概念权值θ=1时,对于表格中的每一行,两概念距离dis(ci,cj)相同时,深度越深,概念间的相关度就越高;对于表格中的每一列,当深度dep(ci,cj)相同时,两概念间的距离越远则概念间的相关度越小。
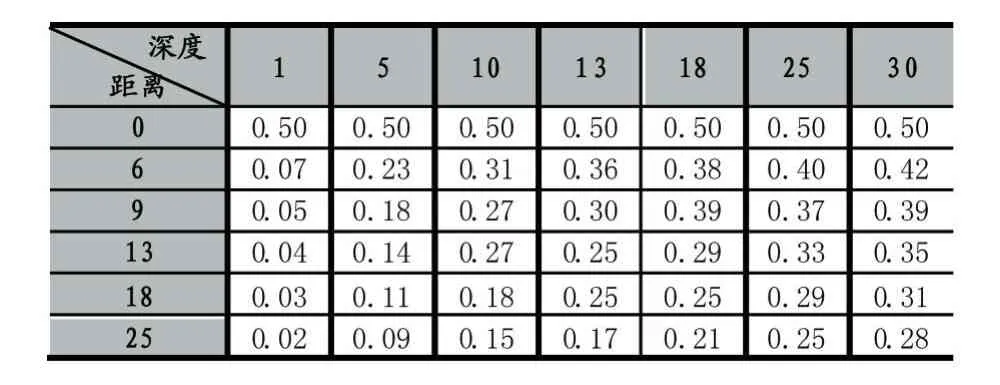
表2 θ=0.5时相似度与概念距离深度的关系
对比表1和表2可以看出,当文档中概念出现的次数越少,即重要性越低θ越小时,计算所得的概念相关度的就越低。通过对文档中概念的重要性进行标记,相同文档中多个概念的相似度有了更加详细的区分,为语义相似度的进一步细化准备了条件。
(2)属性相关度
由于在一般语义相关度计算中属性相关度所占比重较轻,且语义向量中属性数量较多,在这里我们不在逐向量分析其语义,而是采用相对简单的属性值对比的方法进行相似度计算。同理,在该计算过程中,对属性相似度进行加权处理,其权值同该属性对应的概念或实例的权值θ,属性相关度计算如下:
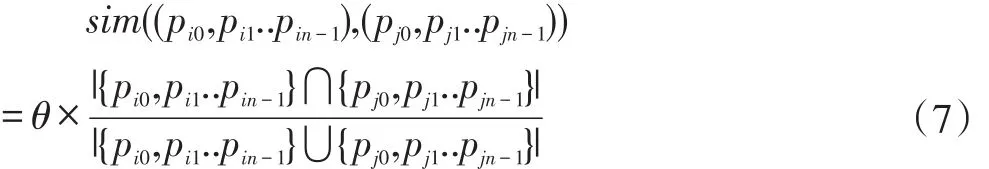
由公式(7)可以看出,属性相关度的范围为 sim((pi0,pi1..pin-1),(pj0,pj1..pjn-1))∈[0,1]。
属性相似度由两个语义向量中相同属性的数量决定,当两个概念 ci=cj时,其属性相关度sim((pi0,pi1..pin-1),(pj0,pj1..pjn-1))=1。
(3)语义相关度
根据前两小节中对概念和属性相关度的计算,将语义相关度计算定义为如下公式:
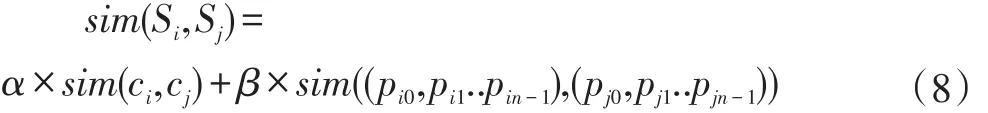
公式(8)中α表示在该语义相关度计算中概念的权值,β表示属性的权值,且α+β=1。α的取值越大表示概念的重要性越高;同理,β越大表示属性所占的比重越高。α和β的值反映了该检索中概念和属性的重要程度,可根据检索需求来决定。
根据公式(8)计算查询向量Si与文档中各个语义向量Sj的相关度,设相关度阈值为δ,若计算所得相关度的最大值simmax(Si,Sj)≥δ,则表示该文档符合检索要求,将该文档放入检索结果集。
3 实验分析
实验从网络获取HTML文件,并进行标记清除和文档核心内容获取等相关处理。以处理后数据为实验数据集进行实验。在该实验中,我们分别去概念和属性的权值α=0.6,β=0.4,取阈值 δ=0.6。将优化后的相似度算法和文献[6]方法进行实验对比,比较二者查准率和查准率,结果如下图1和图2所示:
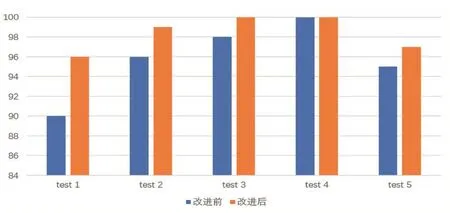
图1 改进前后查准率对比图
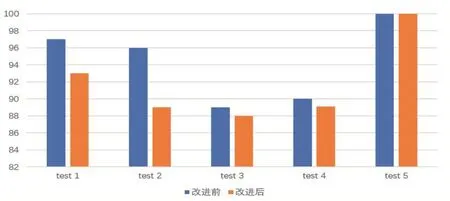
图2 改进前后查全率对比图
当概念和属性的权值以及阈值相同时,从图1可以明显看出优化后算法的查准率高于改进前。图2显示本文提出的算法查全率较另一算法低,这是因为改进的算法对概念以及属性的相关度计算进行了加权处理,且权值θ≤1,这样虽然将概念进行了更加详细的相关度区分,但是也影响了查全率。该问题可通过增大阈值的方法来解决。
4 结语
由于传统检索方式的局限性,语义检索逐渐出现在人们的视野,并且受到了越来越多的重视。通过对已有的语义检索方法进行学习和研究,在基于本体的基础上,研究概念的组织结构形式,在原有概念相似度的计算方法基础上做进一步的优化,并考虑文档中概念和属性的重要程度,提出对相似度加权的计算方法,最终通过实验分析证实了算法的有效性。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
吉林大学学报(信息科学版)(2021年5期)2021-10-26
邮电设计技术(2021年2期)2021-03-13
哈哈画报(2021年10期)2021-02-28
计算机与数字工程(2019年11期)2019-11-29
科技视界(2016年1期)2016-03-30
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
