
基于PageRank改进的文献排名算法研究
2019-02-13 01:36王丹
计算机时代 2019年1期
王丹


摘 要: 在文献检索领域,如何更好地检索到与用户检索请求相匹配的文献是一个值得研究的问题。通常,检索系统往往会采用一定的排序算法对与用户检索请求相关的文献进行排序。然而,由于文献数量庞大,文献内容繁多,当前的文献检索系统的性能仍有待提高。文章基于Lucene排序机制及PageRank算法,提出了一种新的文献搜索排序算法。该算法同时考虑了文献的相关性和权威性。通过实验表明,与传统的检索算法相比,该算法的性能有一定程度的提高。
关键词: 文献检索; 排序算法; Lucene; PageRank
中图分类号:G712 文献标志码:A 文章编号:1006-8228(2019)01-59-04
Abstract: In the field of bibliography retrieval, how to retrieve literatures that meet users' need is a complicated problem. Usually, retrieval systems tend to adopt certain sorting algorithm for sorting the user retrieval request related literature. However, the performance of the current literature retrieval system needs to be improved. Based on Lucene sorting mechanism and PageRank algorithm, this paper proposes a new literature search ranking algorithm. The algorithm takes into account both the correlation literature and authority. Experiments show that compared with the traditional retrieval algorithm, the performance of this algorithm has a certain degree of improvement.
Key words: bibliography retrieval; sorting algorithm; Lucene; PageRank
0 引言
人们在撰写科技论文的过程中,往往会查阅大量的文献资料,文献检索系统成为了众多学者不可或缺的工具。然而在文献检索系统中,用户如何很好地检索到符合期望的文献是一个值得研究的问题[1]。当前,文献检索系统种类繁多,存在多种领域,不同类型的检索系统[2]。如CNKI、万方、Google Scholar、Microsoft Academic Research、ArentMiner等。如今,随着科学技术迅猛发展,科技文献数量也在不断增长[1]。文献数量的增长一方面为研究者提供了丰富的资源,另一方面也为研究者在文献检索过程中带来了一些问题。如何较为准确地从众多的文献中找到符合研究者需要的文献资料,显然已成为人们关注的热点问题。
针对文献检索过程中的问题,一些学者提出了不同的解决方法,主要表现在两个方面:针对文献相关性算法的研究以及针对文献影响力排名的研究[2]。文献相关性算法主要是基于对文献的基本特征提出,通过一定的算法对文献的主题相关性进行计算,如一些文献检索系统即采用了传统的Lucene[1]搜索引擎的排序算法[2]。此外,也有一些研究者针对文献的关键信息的提取和分析,提出了一些算法,如Steven Bethard[2]等人对影响文献排名的不同因素进行了分析,提出了一种基于多因素的文献相关排序方法[2]。柳泉波[3]等人则提出了一种基于链接分析的文献排名方法。刘欣[4]等人基于文献价值对文献排名算法进行了改进。刘松涛[5]则基于科技文献按关键词检索后得到的引文网络系统,提出了一种引文排序算法。
对文献影响力排名的研究十分广泛。通常,文献影响力可以采用被引次数来计算。也有一些学者采用PageRank来计算文献的排名。如Chen P[2]等人基于PageRank算法对文献进行了排序,并讨论了PageRank在不同参数值下得到的排名情况。Ma N[6]等人也基于PageRank算法提出了一种改进的文献排名算法,并对文献排名的结果进行了分析。
为了更好地提高文献检索的效果,本文基于Lucene的排名机制及PageRank算法,提出了一种新的文献搜索排名算法。该算法一方面考虑了检索结果和用户查询请求的相关性,另一方面也考虑了文献的实际影响力。
本文的基本结构如下:第二部分介绍了算法的主要思想,第三部分给出了对比实验结果,对算法的有效性進行了验证。第四部分对本文的工作进行了总结。
1 提出的算法
1.1 问题定义
定义全部文献集为:,定义全部的作者构成的集合为,作者和文献撰写关系为,文献之间的引用关系为。此外,可以定义会议和期刊的集合为:。而会议和期刊跟文献的关系即可定义为:,其中。
定义全部查询请求的集合,定义查询,其中term表示将查询内容进行分词之后得到的词汇单元,一个查询请求由若干个词汇单元构成。
那么,实际上由作者、文献及其之间的关系可以构成一个六元组。我们研究的问题即找到一种方法,对于查询请求q,能够基于G给出最为合理的结果列表X。
1.2 PageRank算法
PageRank[1]算法是由Larry Page等人于1999年提出的一种网页排序算法。该算法同时考虑了网页的流行性和权威性。也即,如果一个页面P被更多的页面引用,如{C1,C2,C3…},同时,当这些页面{C1,C2,C3…}也都是被很多其他页面引用的优质网页的时候,那么网页P则是一个优质的网页。
由于文献引用网络和网页引用网络的结构是非常相似的,而PageRank算法作为一种链接关系排序算法,所以,PageRank被移植到文献网络中用于文献和作者的排序。一般认为,一篇文章引用另一篇文章,往往表示一种认同关系(这里,我们假定所有的文献引用都是一种认同,不考虑文献之间相互批判的情况)[5]。如果一篇文献M能得到非常多的文献的引用,且如果这些引用M的文献也是质量很高的文献,那么显然M应该是一篇非常优秀的文献。此外由于文献之间的引用关系相比网页之间的引用关系而言,更加严谨,不会像网页引用那样随意,所以将PageRank应用与文献价值排序是比较可行的。
1.3 Lucene排序机制
Lucene[2]是由Apache基金会支持和提供的一款用于全文检索的开源工具。由于其使用的便捷性和灵活性,以及Lucene在全文检索中表现出的优异性能,Lucene已经被广泛地用于众多的检索系统中。一些图书馆、文献检索系统也都直接采用了Lucene作为其检索工具。
Lucene的主要内容包括了分词、倒排索引、排序机制等。其中,Lucene排序机制的研究也十分广泛。已有一些学者在Lucene现有的排序机制上进行扩展和改进,以优化其排序结果。本文基于Lucene的排序机制,结合PageRank算法,提出一种新的文献排序方法。
1.4 文献检索排序算法
1.4.1 评价文献的价值
对于用户而言,检索的到的文献能容十分相关,并不意味着这篇文献是用户想要的。因为对于研究者而言,我们往往希望去阅读更有价值的文献。而文献的价值一般可以通过被引次数、作者水平、文献所在的期刊或会议的级别等来认定,所以,我们主要从如下三个方面对文献进行评价。
⑴ 文献的PageRank值
我们采用PageRank值而非被引次数的原因在于,PageRank值的衡量结果比被引次数更为合理。如前所述,PageRank是一种链接排序算法,在文献系统中,我们可以基于文献之间的引用关系构建一个引用关系矩阵,基于该矩阵来运行PageRank算法。
首先,我们构造文献引用数据集。然后,基于该数据集,采用如下公式进行PageRank迭代计算:
其中,表示文献pj的PageRank得分,N表示全部文献的数量,p表示某一篇文章,pi表示引用文章p的其他文章,Citation(pi)表示文章pi的参考文献数,d为参数,可以设置为0.85。
最后,基于公式⑴进行迭代,计算每一篇论文的PageRank值,即为该片论文的价值。
PageRank值和单纯的引用值有一个较为明显的差异,即一篇文献的价值的衡量不仅仅是通过被其他论文引用的次数来决定,同时,每一个引用的质量也将被考虑。
⑵ 作者研究水平
目前,衡量作者研究水平往往可以从作者被引用次数、发文量、合作者数等角度来衡量,而当前最为流行且认可度较高的是采用h-index来衡量作者的研究水平。这里我们直接采用作者的h-index的值来评估作者的研究水平。定义作者研究水平为:,其中ai∈A。由于一篇文献往往有多位作者,我们将某一篇文献的作者影响力为:AImpact(pj),且:
⑶ 期刊或会议级别
当前,衡量期刊或会议级别存在多种不同的衡量方法,如SCI的影响因子IF、被引次数等、平均。由于影响因子近年来多被人诟病,且其确实存在对期刊评价的不合理处,而被引次数显然是一种非常不合理的指标(该指标和刊物的发文量非常相关),且当前不同排名机制尚存争议。这里,我们采用了一种折衷方法,即基于CCF的推荐排名[12]来计算期刊和会议的得分。由于CCF的《中国计算机学会推荐国际学术会议和期刊目录》当前已经被广泛地认同,且本身非常权威,所以比较适合用于期刊和会议的评价。
这里,由于这里我们并不需要得到实际的期刊和会议排名,只需要做一定的区分,所以,我们将CCF排名映射为不同的数值,其中CCF中的A类排名,我们取值为4,B类为3,C类为2,没有出现在CCF上的为1。那么,可以将期刊和会议的影响力定义为:CImpact(Ji),其中Ji∈J。
⑷ 文献发表的年限
在文献检索中,检索用户往往希望查询较为新近的文章,因为研究者需要了解最新的研究情况,掌握最新的科研动态。所以,一般而言,研究者在使用检索系统的过程中,往往偏好于较新的文献。所以,我们将文献发表的年限融入文献价值评定的指标,并将其定义如下:
其中,tc为当前的时间,为文献pj的发表时间。显然,越久远的文献,其获得的值越小;而越新近的文獻,其获得的值越大。
基于以上四个指标,我们将文献价值定义如下:
其中,且。
1.4.2 文献评分函数
前面小节中,我们对文献的价值评价方法进行了分析和定义。实际上,影响文献最终得分的因素非常之多,比如,文献和查询请求的相关度,文献本身的价值,文献发表的年限等。为了综合衡量文献和查询请求的相关性以及文献本身的价值,我们将文献评分函数定义如下:
idf(t)表示逆词频,它表达了词汇单元在所有文档中的频率。即,如果一个词汇出现的次数越少,那么那就应该更加重要,所以idf(t)的定义如下:
其中,numPub表示文献数量,而pubFreq则表示词频。
coord(q,d)衡量的查询请求中的词汇单元,有多少个出现在了这个文档d中。coord(q,d)的定义如下:
其中,overlap表示查询请求的全部词汇单元在给定文献中都有多少个命中了,而maxoverlap则表示查询请求q的全部词汇单元个数,即|q|。
实际上,我们可以将公式⑷代入公式⑸,即可得到最终的文献检索排序公式,定义如下:
基于该函数,我们可计算每个查询请求所对应的结果集,以及结果集中的文献排序。
2 实验
2.1 实验数据集
作者从ArnetMiner爬取了Semantic Web、Information Retrieval、Fuzzy System以及Data Mining领域的4个文献数据集。数据集中包含了作者、作者单位、标题、摘要、引用等信息。
2.2 评价指标
为了对算法的有效性进行验证,我们采用了P@N指标来进行评估。P@N是指返回的前N个结果中,相关文献所占的比率。其定义形式如下:
其中,Rn为返回的前n个结果构成的集合,他们的得分是最高的。而Cn则表示与该查询实际相关的结果构成的集合。P@N的值越大,则表示该算法更为有效。
2.3 实验结果
这里,我们选取了传统的Lucene算法作为对比对象。我们分别在爬取到的Semantic Web、Information Retrieval、Fuzzy System以及Data Mining领域的4个文献数据集上进行了实验。
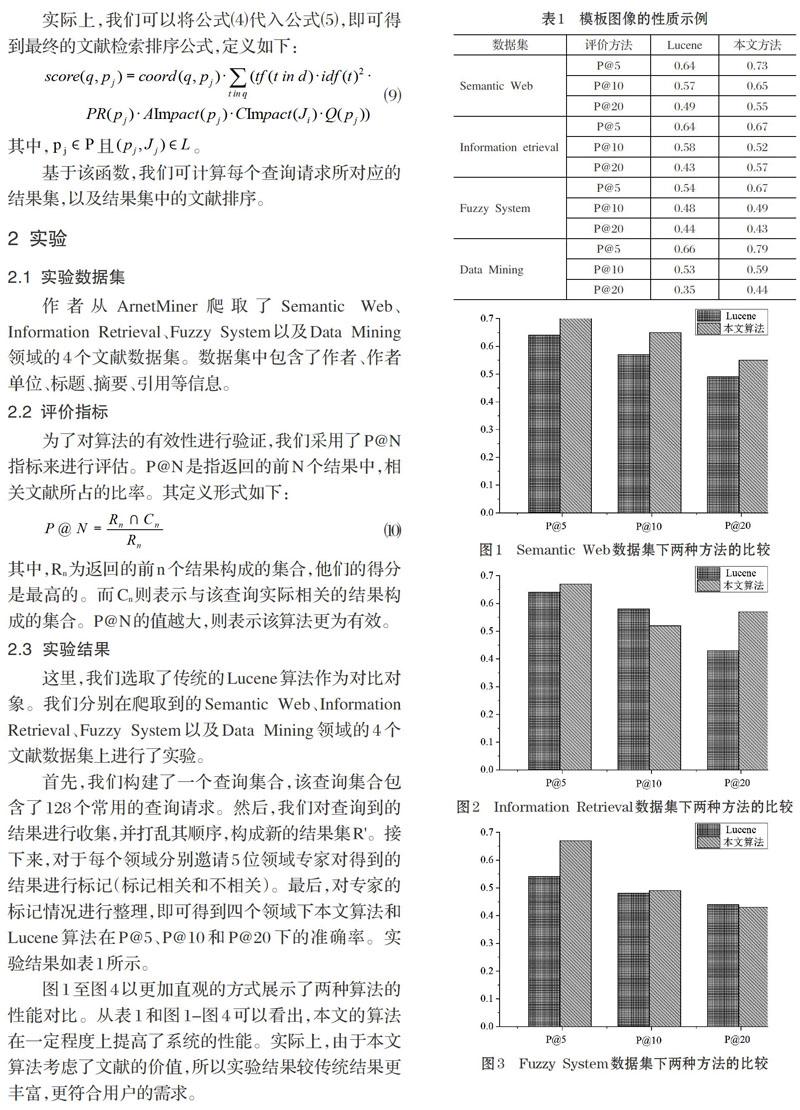
首先,我们构建了一个查询集合,该查询集合包含了128个常用的查询请求。然后,我们对查询到的结果进行收集,并打乱其顺序,构成新的结果集R'。接下来,对于每个领域分别邀请5位领域专家对得到的结果进行标记(标记相关和不相关)。最后,对专家的标记情况进行整理,即可得到四个领域下本文算法和Lucene算法在P@5、P@10和P@20下的准确率。实验结果如表1所示。
图1至图4以更加直观的方式展示了两种算法的性能对比。从表1和图1-图4可以看出,本文的算法在一定程度上提高了系统的性能。实际上,由于本文算法考虑了文献的价值,所以实验结果较传统结果更丰富,更符合用户的需求。
3 结束语
本文针对文献检索排序问题,分析了文献检索过程中用户关注的要点,即用户不仅仅只是关注返回的结果是否与查询是相关的,同样关注文献的质量和文献的新旧程度。基于文献的相关性和文献的重要性,本文提出了一种新的文献检索排序算法。该算法综合考虑了文献的重要性和相关性。最后,通过实验验证了该方法的有效性。
参考文献(References):
[1] 宋京京,潘云涛,苏成.基于PageRank算法的图书影响力评价[J].中华医学图书情报杂志,2015.12(24):9-14
[2] 曾玮.文献排名预测算法及作者影响力评估算法研究[D].西南大学,2014.
[3] 柳泉波,许骏.基于链接分析的科学文献个性化排序算法[J].中山大學学报:自然科学版,2008.47(6):87-92
[4] 刘欣.基于阅读价值的科技文献排序方法研究[D].大连理工大学,2010.
[5] 刘松涛.基于引文排序的科技文献检索研究[D].东北师范大学,2010.
[6] 李稚楹,杨武,谢治军.PageRank 算法研究综述[J].计算机科学,2011.38(B10):185-188
