
国际合作实践项目“挖掘数据挑战”内容分析
2019-03-20 06:52徐志玮天津理工大学图书馆
图书馆理论与实践 2019年2期
徐志玮(天津理工大学图书馆)
大数据时代,人文社科研究数据量增长迅速,如何创新地运用基于计算的研究方法对这些数据进行智能搜索和深度解析,改变和拓宽人文社科的研究思维和方向是目前的重要课题之一。同时,网络化平台连接着世界各地的用户,从国际化的宏观视角探讨人文社科课题,得到新的国际观点,也是目前的重要课题。为此,本文分析了美国国家人文基金会(National Endowment for the Humanities,NEH)专为数字人文研究设立的国际合作项目“挖掘数据挑战”,为我国的相关研究提供参考。
1 国内外研究现状综述
基于数字人文的大数据挖掘研究带有明显的应用性特点,大部分以软件开发和升级、工具使用、算法优化和实验等成果为主,部分已发表在学术期刊上。本文以SCI、SSCI和中国知网为数据来源进行检索,尽管不能涵盖所有研究成果,但也能了解目前的研究现状。
1.1 国外研究现状
① 从学科分布看,国外利用历史数据开展的实证性研究最多。Phillips MG等[1]利用数字技术和传统定性研究方法,挖掘20世纪初澳大利亚妇女通过远程方式进行阅读的特点;Hinrichs U等[2]联合环境历史学家、计算语言学家和可视化专家,挖掘了四个世界知名历史数据集中收藏的商品交易数据;Linn AR[3]利用在线3D虚拟技术,绘制了挪威人移民到美国的历史路径;Van Eijnatten J等[4]解析了1863-1940年间荷兰和德国出版的有关毒品、贩毒和吸毒者内容的报纸,挖掘了整个跨大西洋地区存在的毒品问题;Grubert E等[5]探讨了文本挖掘分析技术在人文环境科学和国家政策相互影响方面的价值。② 从数据来源看,针对社交媒体开展的大数据挖掘是热点之一。Hsu WF[6]以一个著名的朋克乐队Kominas在社交媒体Myspace和Twitter上进行互动的数据为对象,研究音乐数据的地理空间可视化技术的实现,以及数据的标注和分析。③ 从技术层面看,语义元数据成为数据挖掘的关键技术之一。Van Hooland S等[7]探讨了“描述”等非结构化元数据在数据挖掘中的命名实体识别和术语提取方面的问题。
国外图书馆也在尝试实验性的实践研究。Green HE[8]对伊利诺伊大学图书馆研发的数据挖掘软件MONK进行实证研究,揭示人文学者使用数字工具追求创新研究方法的能力;Morgan EL[9]分析了将文本挖掘和其他数字人文计算技术整合到图书馆目录和“发现系统”中的可能性。
1.2 国内研究现状
国内的主要研究者为图书馆馆员。① 历史学科方面,Zhu SL等[10]将地理信息系统应用于我国古代地方志的开发和利用,实现了“广东地方志”产品分布历史数据的挖掘和可视化;赵思渊[11]介绍了《中国地方历史文献数据库》的元数据结构、交叉导航和数据统计等功能。② 古籍方面,欧阳剑[12,13]对古籍文本的数据挖掘进行了探索。③ 艺术史方面,范桢[14]利用计算机自然语言处理工具对《白石老人自传》进行词频统计、高频分布和语义网络的细读,确认《白石老人自传》的核心内容;夏翠娟等[15,16]探讨了家谱和地理数据在图书馆数字人文项目的应用,以及关联数据在家谱服务中的应用。
综上所述,国内外都取得了一些实践成果。国内基本上是以图书馆和历史专业为主导的实践研究,国外涉及的学科范围更加宽泛,数据来源也更加丰富。
2 “挖掘数据挑战”项目概述
“挖掘数据挑战”(Digging into Data Challenge,DiD)是NEH于2009年设立的一个资助数字人文研究的国际合作项目,[17]由美国、英国、加拿大、德国等11个欧美国家的18个国家级别的基金组织提供资助(见表1),基本上每两年举行一轮,目前已经成功举办4轮,共有50个项目获得了大额资金的支持。2016年,DiD被重新命名为“T-AP数据挖掘挑战”,T-AP即根据欧盟第七框架研究与开发框架计划(授权号613167)而建立的“跨大西洋平台Trans-Atlantic Platform”。
3 成功获得资助的50个项目案例总结
DiD会在网站上公布已经完成项目的最终成果白皮书(2016年获得资助的14个项目只有标题和摘要),笔者对全部项目进行了仔细阅读及分析。由于篇幅有限,本文只列出2016年公布的14个最新获奖项目的名称、合作单位和研究内容摘要(见表2)。
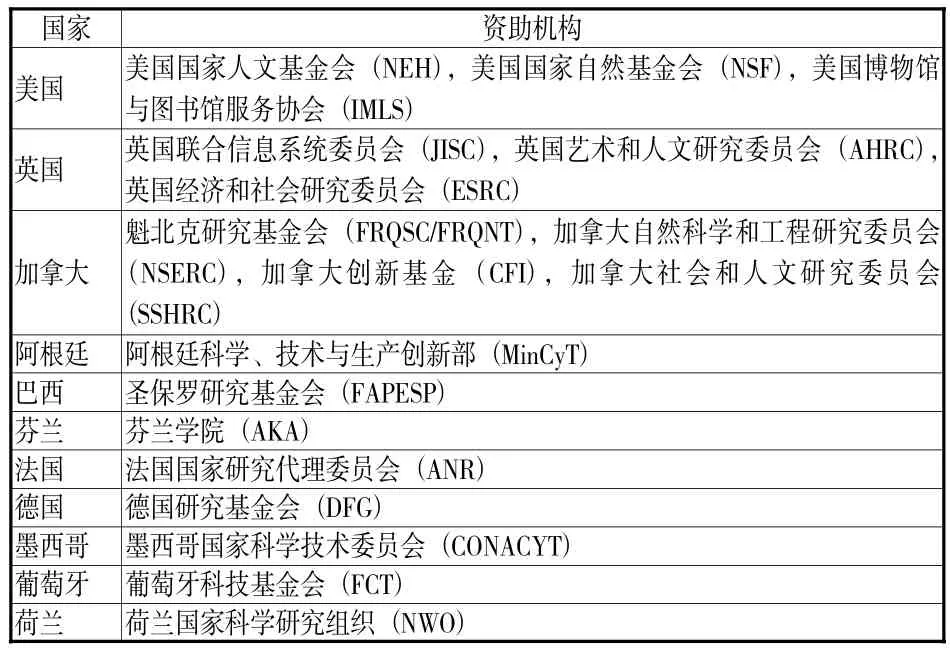
表1 DiD合作国家和资助组织名称表
3.1 跨国学术机构的强强联合,打造世界顶级研究成果
2009年,DiD规定每个项目要有2个及以上国家的3个机构参与,2016年变为每个项目至少需要3个国家的合作。申请机构需要在国际人文社科领域有显著的影响力,且希望项目最终能够达到世界领先水平。如,“挖掘符号:制定针对符号语言数据进行交叉语言量化分析的标准注释实践”项目(Digging into Signs:Developing Standard Annotation Practices for Cross-Linguistic Quantitative Analysis of Sign Language Data)的目的在于打造世界最大的聋哑语言语料库并制定世界标准;“挖掘生物多样性”项目(Mining Biodiversity)对当前世界最大生物多样性系统“生物多样性文献图书馆”(Biodiversity Heritage Library,BHL)进行升级,以期将其打造成下一代生物多样性社会数字资源平台;“Field Mapping:An Archival Protocol for Social Science Research Findings”项目的目标则是构建世界上最全面的全球跨学科科学发现的搜索引擎。
值得一提的是,“中文文本自动化数据抽取”项目 (Automating Data Extraction from Chinese Texts) 是来源于十年前由哈佛大学费正清研究中心、北京大学中国古代史中心和台湾“中央研究院”历史语言研究所联合主持的“中国历代人物传记数据库”的一个子课题,旨在解决数据采集、整理和转换等方面遇到的难点。
3.2 人文研究范式的彻底改变
(1)明显的跨学科研究范式。DiD项目往往由多个学科的专家共同参与。如,“挖掘考古学数据:图像搜索和标记”项目(Digging Archaeological Data:Image Search and Marking,DADAISM)集合了考古学、图像处理和检索、文本挖掘技术等专家,开发了一个序列模型的人机交互系统;“Analyzing Child Language Experiences Around the World(ACLEW)”项目由语言学、语音科学工程、计算机技术等专家参与,开发自动标注大规模婴儿语料库的软件;“Understanding Opinion and Language Dynamics Using Massive Data”项目的研究团队拥有数据科学、物理、语言学、哲学和法律等领域专业人才。
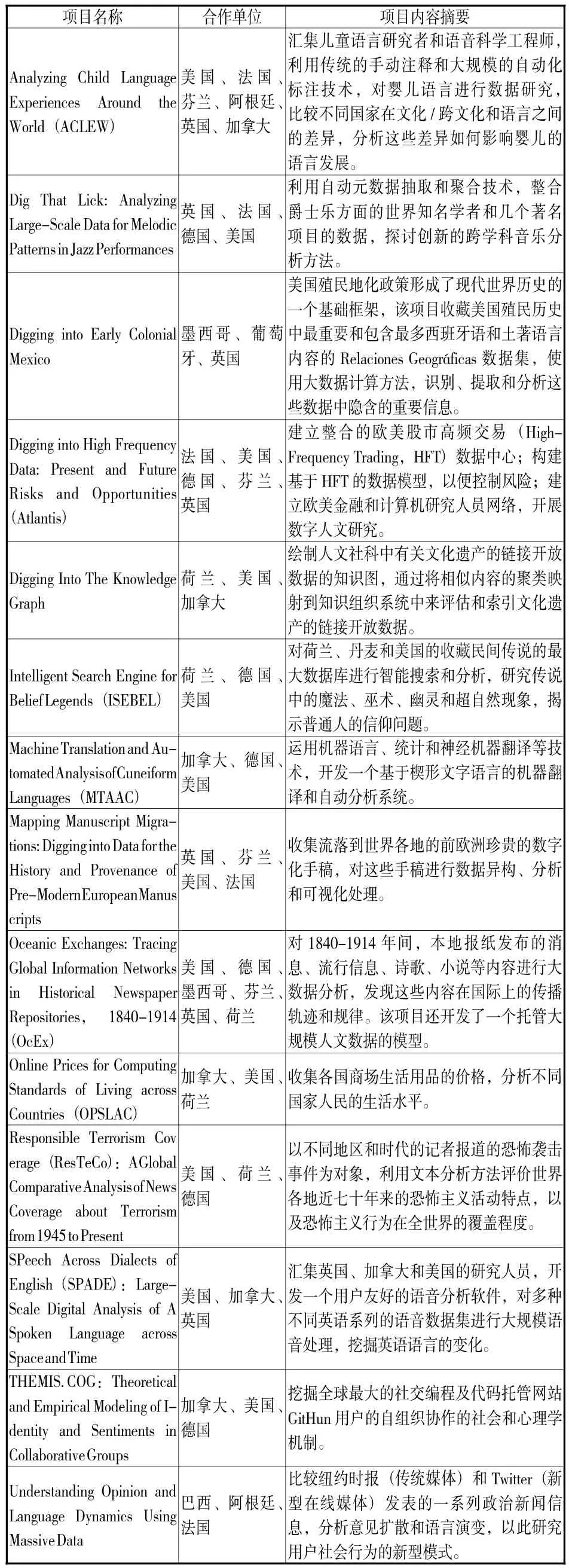
表2 获得2016年DiD资助的14个项目
(2)开拓人文社科研究的创新思路和方法。研究人员将数字技术运用到人文社科研究中,就是希望得到手工模式无法获得的信息。如,“Analyzing Child Language Experiencesaround the World(ACLEW)”项目挖掘海量婴儿语言,探讨文化/跨国文化和语言之间的相互关系,并预测这种关系对婴儿语言成长过程中所造成的影响和差异;“Cascades,Islands,or Streams?Time,Topic,and Scholarly Activities in Humanities and Social Science Research”项目挖掘社交媒体上那些被忽视、但有价值的非正式学术活动数据,预测未来的创新研究课题;“全球趋势:文学网络文化(1050-1900)”项目 (Global Currents:Culturesof Literary Networks(1050-1900))运用图像处理技术和社会网络分析方法,研究不同文化时期的知识交流网络特点,揭示世界文化的差异;“Digging by Debating”项目运用主题建模和半形式的话语分析技术,自动抽取HathiTrust学术论文中的论据,并以可视化方式标识哲学和科学之间的关系。
3.3 承诺项目研究成果的开放获取
NEH要求数字人文项目的申请者承诺免费公开研究成果。NEH认为,研究成果的开放获取有助于其他学者开展相似研究,同时,能够培养公众的人文素养,提高其哲学批判思维的能力。获得DiD资助的已完成项目开发的软件都可以免费下载,且研究者必须在项目结束后公开一份详细说明研究成果的白皮书。如,“Trees and Tweets:Mining Billions to Understand Human Migration and Regional Linguistic Variation”项目允许公众免费使用研发的软件Word Mapper,并承诺会公开完整的定量数据集。
3.4 积极开展国家层面的宏观比较分析
DiD是一个跨大西洋的国际合作专项基金,因此,探讨欧美在文化、经济、法律等人文社科方面的国家级问题是其主要研究课题之一。如,“Digging into High Frequency Data:Present and Future Risks and Opportunities(Atlantis)”项目建立了一个整合的欧美股市高频交易数据模型,以便在全球范围内控制股市风险;“Intelligent Search Engine for Belief Legends(ISEBEL)”项目对荷兰、丹麦和美国三国收藏的本国最大的民间传说数据库进行搜索和分析,比较三国民众在文化信仰方面的差异;“SPeech Across Dialects of English(SPADE):Large-Scale Digital Analysis of A Spoken Language across Space and Time”项目对英国、加拿大和美国三国不同的英语系语言的语音数据进行大数据分析,探讨英语语言的变化规律;“Trees and Tweets:Mining Billions to Understand Human Migration and Regional Linguistic Variation”项目分析英国和美国在社交媒体上的语言变化,了解英美两国语言变迁的形成过程和原因,以及语言变化和移民之间的关系,“Digging into Linked Parliamentary Data”项目对加拿大、荷兰和英国的议会数据进行分析,阐述不同国家在政治和制度方面的发展和异同。
3.5 深度挖掘纸本资源隐含的信息
手稿、古籍和报纸等纸质资源是人文社科研究中最有价值的纸本资源,也是DiD项目的主要数据来源。如,“An Epidemiology of Information:Data Mining the 1918 Influenza Pandemic,”项目对美国国会图书馆和阿尔伯塔省图书馆收藏的1918年发表的有关西班牙流感疫情的100多份报刊进行数据挖掘,探索疾病和信息传播之间的关系;“Digging into the Enlightenment:Mapping the Republic of Letters”项目对18世纪以纸质信件进行通讯的数据进行分析,得到知识史网络图,并解析知识传播的轨迹;“Oceanic Exchanges:Tracing Global Information Networks in Historical Newspaper Repositories,1840-1914(OcEx)”项目对 1840-1914年,美国、德国、墨西哥、芬兰、英国、荷兰六国报纸上的消息、流行信息、诗歌和小说等内容进行大数据分析,探索文化的世界传播特点。
3.6 鼓励有学术价值的数字资源的解析
除了对纸本资源进行数据挖掘,DiD还非常重视两类网络资源的研究:学术数据库和网络化社交媒体。
数字图书馆、档案馆和博物馆是创建、存储、管理和保存学术性数字数据的重要平台,是数据挖掘的重要数据来源,DiD一直鼓励申请者对这些重要的且已经数字化的数据库进行深度挖掘。为此,DiD专门在网站上发布了重要数据仓库的列表:ARTstor、Biodiversity Heritage Library、 JSTOR、 National Library of Medicine(NLM)、National Science Digital Library(NSDL)、National Technical Information Service(NTIS)、Pro ject MUSE等。如,“Digging by Debating”项目以Hathi Trust Digital Library收藏的数字资源为数据来源;“Integrating Data Mining and Data Management Technologies for Scholarly Inquiry”项目对JSTOR进行分析;“Mining Biodiversity”项目对Biodiversity Heritage Library平台进行升级改造;“THEMIS.COG:Theoretical and Empirical Modeling of Identity and Sentiments in Collaborative Groups”项目对世界上最大的社交编程和托管平台GitHub的用户进行研究,“Dig That Lick:Analysing Large-Scale Data for Melodic Patternsin Jazz Performances”项目对世界知名爵士乐数据库开展跨学科的音乐分析。
社交媒体是最大的公众在线交流平台,对这些大数据进行用户行为研究,能从公众视角分析世界格局。DiD主要采用三种研究方法。① 传统媒体和社交媒体的比较研究。“Understanding Opinion and Language Dynamics Using Massive Data”项目比较了传统杂志《纽约时报》和新型在线媒体Twitter上发表的政治新闻数据,探讨大数据信息环境改变人类的活动、行为和决策过程,尤其是意见扩散和语言演变的轨迹。② 专业学者的用户研究。“Digging by Debating”项目对学术书目数据库和专家撰写的综述论文进行研究,分析学者在跨学科研究方面的行为特点;“Cascades,Islands,or Streams?Time,Topic,and Scholarly Activities in Humanities and Social Science Research”项目探讨了学者使用Twitter社交媒体开展非正式学术活动的特点,探讨社交媒体对学术研究的影响。③ 一般公众的用户行为研究。“Treesand Tweets:Mining Billionsto Understand Human Migration and Regional Linguistic Variation”项目比较了美国和英国公众利用Twitter的语言差异,探讨语言和移民之间的关系。
4 国内人文社科管理部门的启示
4.1 宏观规划
目前,国内还没有一个国家级别的数字人文资助机构,没有统一的宏观布局,缺乏国际合作的条件和资金支持。国家自然科学基金委员会在2015年设立了“大数据驱动的管理与决策研究”重大研究基金,2017年该基金在指南中指出:“在大数据背景下,传统的管理与决策正从以管理流程为主的线性范式逐渐向以数据为中心的扁平化范式转变,管理与决策中各参与方的角色和相关信息流向更趋于多元和交互”,[18]这说明,国家已经意识到大数据研究的重要性,只是该基金主要面向自然科学研究领域。笔者也查询过国家人文社科基金,有关数字人文和大数据的项目近年来增长较快,但是还没有基于人文社科的数据挖掘实践内容的基金立项,更没有国际合作项目。为此,需从国家层面进行宏观规划,建立国际合作专项基金,有效利用全球的数字资源,打造国际化的创新团队,增强国家层面的人文社科研究实力。
4.2 建立评估机制
数据挖掘研究一般以实践应用为目标,软件是最普遍的研究成果,如何对这种成果进行学术评价,国内还没有一套完善的评价标准,也就难以鼓励研究者开展相关的实践探索。2017年9月,浙江大学颁布了《优秀网络文化成果认定实施办法(试行)》,提出将优秀网络文化成果纳入学校科研成果统计、各类晋升评聘和评奖评优范围,但这也只是少数高校的尝试性做法,还未普及,不足以激励技术人员和人文社科研究者的合作意向。因此,需要改变国内学术评价机制,并鼓励跨学科的研究者开展创新性实践探索。
4.3 设立“数据管理计划”
数字资源的长期保存、复用和增值日益受到学术界的重视。数据挖掘研究势必产生大量计算生成的非线性、多维度的“大数据”,需要对这些数据进行合理的管护。美国国立卫生研究院要求,2003年开始,申请经费在50万美元以上的申请者必须提交一份数据共享管理计划;美国国家科学基金会在2011年要求申请者提交“数据管理计划”;[19]NEH在资助数字人文项目时,明确提出申请者需要附上2页的“数据管理计划”。在数据管护越来越受到重视的学术研究背景下,国内基金管理部门应积极设立类似的数据保护计划。
4.4 鼓励共享研究成果
开放获取模式对培养公众的人文素养有积极作用,基于数字人文的数据挖掘项目往往涉及公众的文化、生活、经济、法律等内容,这些研究成果对公众开放,可以提高公众对人文社科问题的批判思维能力,也能了解公众对这些问题的认知程度,还能掌握学者和公众对这些问题的理解差异。同时,对人文社科学者也有帮助。大部分数据挖掘项目的研究成果是软件和工具,这些成果可以帮助其他学者分析数据,而无需投入精力开发系统,起到了事半功倍的效果。
5 对国内图书馆理论和实践研究的启示
5.1 对数据管护的研究
网络时代,图书馆需要把数字资源的管护纳入自己的服务范围。数字人文研究让数据管护工作变得更加重要,尤其是人文社科研究者经常使用计算建模方法开展数字人文研究,会产生很多数据,对这些数据进行合理的存档、保存、监护和管理,是图书馆参与数字人文实践研究的一个重要职责。另外,图书馆一直承担着信息素养的培训工作,有丰富经验。大数据时代,数据素养教育可以作为图书馆的一个服务方向。首先,对馆员进行数据素养教育,鼓励馆员学习信息技术知识,有条件的图书馆可以设立数据馆员职位,与其他专业的学者进行数据管护合作;其次,对人文社科研究者和公众进行数据素养培训,帮助用户提高数据管护的能力。另外,高校图书馆还可以拓宽学科服务范围,如搜集整理学科科研数据、分析学科的学术发展态势等。
5.2 对数据来源的研究
社交网络平台是目前大数据研究的重要数据来源。社交媒体将人类信息传播的速度带入了一个崭新的时代,也为人文社科研究贡献了大量的网络数据。为此,图书馆可以拓宽以下两方面的研究。①社交媒体环境下的学术性评价研究。目前,大量学术活动通过社交媒体进行传播,这些数据能洞察创新性学术内容的最初端倪,属于有学术价值的早期指标。但是,至今还没有太多的科学证据对此予以证明。因此,对于社交媒体产生的非正式性学术传播数据进行学术性评价研究,可以在一定程度上成为网络资源评价机制的依据。② 社交媒体情景下的公众舆情研究。公众利用社交媒体发表大量有关人文社科问题的数据,社交媒体成为学者和公众知识分享的平台。通过数据挖掘,可以获得公众对人文社科问题的认知,掌握学者与公众在人文社科问题理解上的差异。
同时,图书馆也要加强对已有数字语料库的研究。开放获取数据库、企业数据库、数字图书馆、档案馆和博物馆等都保存了大量有学术价值的数字资源,图书馆不仅要对这些资源进行合理管理,还需要加强对这些数据的分析研究,开展知识发现的咨询服务和情报分析。为此,图书馆主管部门可以列出一些高质量的数字语料库,尤其是具有中国特色的语料库,鼓励人文社科专家、计算机专家和图书馆等合作开展数字人文挖掘研究。
5.3 对数字技术的研究
目前,图书馆与信息技术的关系越来越紧密,图书馆的技术人员和管理者需要了解数字技术的内容和发展趋势,才能更好地开展创新的服务工作。笔者对DiD项目运用的数字技术进行归类,发现常用的技术包括文本挖掘、机器学习、数据模型、聚类、神经机器翻译、光学字符识别、可视化、图像处理技术、地理信息系统和关联数据等,机器学习技术中的自然语言处理和自动语义标注是关键技术。这些技术的专业性很强,图书馆需要与专业人员开展合作才能开展数字人文研究。同时,图书馆可以在元数据技术方面开展研究,如,元数据的自动标注技术、异构元数据的互操作技术、关联数据技术等。
猜你喜欢
山西高等学校社会科学学报(2022年10期)2022-10-25
九江学院学报(自然科学版)(2022年2期)2022-07-02
初中生之友·中旬刊(2022年5期)2022-05-25
初中生之友·中旬刊(2022年5期)2022-05-25
西安交通大学学报(社会科学版)(2021年2期)2021-04-06
大众投资指南(2021年35期)2021-02-16
西安航空学院学报(2020年4期)2020-08-18
中国交通信息化(2020年1期)2020-07-27
中国三峡(2017年3期)2017-06-09
电子技术与软件工程(2016年24期)2017-02-23
