
点差分隐私下图数据的度直方图发布方法
2019-03-22 04:43张宇轩魏江宏刘文芬胡学先
计算机研究与发展 2019年3期
张宇轩 魏江宏 李 霁 刘文芬 胡学先
1(数学工程与先进计算国家重点实验室(中国人民解放军战略支援部队信息工程大学) 郑州 450001)2 (广西密码学与信息安全重点实验室(桂林电子科技大学) 广西桂林 541004) (bigzhangq@163.com)
随着互联网和信息技术的飞速发展,许多组织机构搜集的个人数据规模急剧增长,随之而来的用户隐私保护问题变得日益重要.对这些搜集的数据进行深入挖掘和分析后所能得到的潜在社会效益和经济价值,如精准医疗、智慧城市、广告投放等,又驱使这些组织机构倾向于发布关于这些搜集数据的统计信息.另一方面,在隐私保护下的数据分析领域,其主要目标是安全地发布关于数据集的统计信息,同时又不会泄露数据集中所涉及用户的隐私信息,如医疗数据中的病人基本信息、位置数据中的用户运动轨迹等.显然,发布数据集中数据分布的有用信息和保护数据集中的用户隐私这2个目标是相冲突的,如何在这两者之间形成折衷就成了一个十分具有挑战性的问题,而差分隐私技术[1]被认为是解决该问题最为理想的方案之一,可以保证相邻数据集上查询结果的分布很接近.
图数据作为一种典型的数据类型,随着社交网络、推荐系统、协作网络等信息系统的广泛使用而变得越发常见,如何在保证用户隐私不被泄露的前提下发布这些数据也逐渐受到了学者的关注.早期通用的方法主要是对图数据进行简单的匿名化处理来实现用户隐私的保护,如用无意义的字符表示图中节点、删除/添加某些边等等.但是,对于按照这种匿名化方法处理后的图数据,利用主动攻击和被动攻击[2]仍能恢复出原始图中的节点信息和节点之间边的关系,进而导致用户敏感信息泄露.2009年Hay等人[3]首次利用差分隐私技术来实现图数据的安全发布,并提出了差分隐私在图数据发布领域的2种变体,即边差分隐私和点差分隐私.
在边差分隐私中,2个相邻图仅相差1条边,而在点差分隐私中,2个相邻图相差1个节点以及与此节点相连的所有边.对于一个节点数目为|V|=n的图G=(V,E)(其中V是所有节点的集合、E为所有边的集合),删除1条边只影响这条边上2个节点度的变化,而删除1个节点在最坏情况下会导致n-1条边被删除.因此,图数据中的点差分隐私比边差分隐私更难满足,但却能提供更高强度的隐私保护.
度分布是图的一种重要统计特性,也是图数据发布过程中的保护重点.如何在点差分隐私约束下实现图的度分布发布在近年来得到了广泛关注,其主要目标是要在满足点差分隐私的条件下给出一种尽可能接近图的度的真实分布的近似分布.目前,解决该问题的一种主要技术是将原始图投影到1个节点度数不超过最大值θ的压缩图,以此来降低度发布过程中的敏感度,而这其中的关键又在于如何在投影过程中尽可能多地保留原始图的信息.
在TCC 2013上,Kasiviswanathan等人[4]提出利用截断(truncation, T)的方法对原始图进行投影,即除去原始图中所有度大于给定门限值θ的节点.这种方法虽可降低敏感度,但却删除了许多本没必要删除的边,损失了原始图中大量的有效信息.Blocki等人[5]考虑了通过边移除(edge-removal, ER)的方法来降低敏感度,即任意选择一个边序列作为删边的次序,当边的2个顶点存在deg(v)>θ的情况时删除此边,否则保留此边,最后对保留的边组成的图的度分布进行差分隐私发布.Raskhodnikova和Smith[6]基于指数机制,利用流图的方法将图的度分布映射到一个直方图,但却仍具有较高的敏感度6θ.在SIGMOD 2016上,Day等人[7]提出了一种加边机制πθ来降低敏感度,即首先对原始图的边进行稳定排序(如字典序),然后删除原图中所有的边,只保留节点,再按照稳定排序添加边,当所添加边的2顶点存在deg(v)>θ的情况时跳过此边,最后当所有边被遍历完后对所得到的重构图的度分布进行差分隐私发布.但是,边排序的不确定性导致Day等人[7]提出的方法仍不能最大程度地保留原始图的边信息.
为进一步降低点差分隐私约束下图的度分布发布过程中的敏感度,本文在现有几种投影方法的基础上提出了一种新的投影方法,并基于此给出了2种点差分约束下图的度分布的直方图发布机制.具体而言,本文的主要贡献包括3个方面:
1) 提出了一种基于度排序的边移除(sequence edge-removal, SER)投影方法,通过依节点度的大小删除与该节点相连的边,最终将节点度限制在给定的门限值内.相比已有方法,该方法在降低敏感度的同时,保留了原始图中更多的边,减小了投影图和原始图之间的误差.
2) 基于SER投影方法提出了2种度分布的直方图发布机制,即SER-(θ,Ω)-直方图发布和SER-累积直方图发布,并在理论上证明了这2种度分布发布机制满足点差分隐私的定义.
3) 不同数据集上的仿真测试结果表明,相比已有的点差分隐私约束下图的度分布发布机制,本文提出的基于SER投影方法的度分布直方图发布机制在提供同等隐私保护水平的条件下,更好地刻画了真实数据的度分布,提高了发布数据的可用性.
1 相关工作
差分隐私使用扰动技术对数据集或者查询结果添加随机噪声,使得数据或查询结果失真,但又保持了数据整体良好的统计特性和可用性,以便后续的数据挖掘和发布.具体而言,令X是需要发布统计信息的数据集,f是查询函数,则ε-差分隐私机制就给出一个扰动的输出f(X)+Y,而不是直接输出真实答案f(X),这里面Y就是所添加的噪声.
自2006年Dwork[1]提出差分隐私的概念以来,由于其严谨的数学理论保证和可证明隐私安全性,这种隐私保护技术得到了广泛的认可和关注.相较传统的隐私保护模型(如k-anonymity[8],l-diversity[9]等)需要对攻击者的背景知识和攻击模型给出特定的假设,差分隐私不依赖攻击者的特定背景知识,并且可以提供可量化的隐私保证.近年来,关于差分隐私技术的理论研究[10-13]取得了长足进展,已逐步应用到了数据分析和挖掘的各领域.
1.1 差分隐私约束下的图数据发布
差分隐私技术在图数据发布领域的应用有2种变体,即边差分隐私和点差分隐私.
在图的边差分隐私中,2个相邻图仅相差1条边.Nism等人[14]为降低查询输出中的噪声,提出了局部敏感度的概念和抽取聚合框架,并应用其解决了边差分隐私约束下图中三角形的计数问题;Rastogi等人[15]通过引入Bayesian攻击者,将原有边差分隐私的定义进行了削弱,提出了边差分隐私定义的变体——边对抗隐私(edge adversarial privacy),并基于此给出了可对任何子图进行计数查询的通用算法;Karwa等人[16]进一步对Nism等人[14]的工作进行了扩展,即对图中的k-stars子图计数实现了ε-差分隐私,对k-triangles子图计数实现了(ε,δ)-差分隐私;Zhang等人[17]提出了用指数机制实现边差分隐私约束下的子图计数的阶梯框架,并在其中给出了定义查询函数含噪输出的概率分布的方法.
在图的点差分隐私中,2个相邻图相差1个节点以及与此节点相连的所有边.鉴于许多针对图数据的查询函数在(最大)度θ较小的图Gθ上具有较低的敏感度,因此一般通过将图G转换为度上界为θ的图Gθ来实现节点差分隐私[4-5],即将图G中度高于θ的节点删除.Chen和Zhou[18]针对节点差分隐私提出了一种迭代机制.给定图G和实值函数f,他们定义了一个具有递归单调性质的实值函数序列0=f0(G)≤f1(G)≤…≤fm(G)=f(G),再利用这种递归方法实现节点差分隐私约束下的任何类型子图的计数.但是,构造这样的函数序列fi(G)通常是NP困难的,因此如何高效地实现这种机制仍然是一个挑战.
1.2 差分隐私约束下的直方图发布
将数据以直方图的形式表示后能够显著降低查询函数的敏感度,为数据发布带来很大便利[19].对于一个具有N条记录的直方图,差分隐私机制可用来保护每条记录的频率.
为减少直方图中添加过多噪声所带来的误差,Xu等人[20]利用最小化查询函数集的均方差的方法给出了2种分割策略.Qardaji等人[21]考虑了直方图上的范围查询函数,以一种分层的方式分割属性值,并将属性值范围分配到一个树上.Hay等人[22]定义了约束推理来调整查询函数的输出,并提出了2种具体的一致性约束.Lin和Kifer[23]将有序直方图集合看作1个Markov链,基于Bayesian决策理论给出了一个新的隐私保护的排序直方图问题的估计算法.张啸剑等人[24]利用Markov链蒙特卡洛方法中Metropolis-Hastings技术与指数机制,提出了一种有效的排序方法,并对排序后的直方图,给出了一种基于懒散分组下界的自适应贪心聚类方法,进一步减少了发布后直方图中的误差.Lee等人[25]将直方图中对加噪数据的后处理过程抽象为带约束的极大似然估计问题,并给出了一种快速、通用的解决方法.
2 基础知识
本文主要考虑边和节点均不带标签和权重的无向图G=(V,E),并用deg(i)表示节点i的度,hist(G)表示图G的度直方图.
2.1 差分隐私基本概念
差分隐私技术的思想源自一个很简单的观察:对于给定的包含个体U的数据集S,进行任何查询操作f(例如计数、求和、平均值等)后所得到的结果为f(S),如果将U的信息从S中移除,查询结果仍然为f(S)或与f(S)十分接近,就可以认为S没有额外地泄漏U的信息.而差分隐私技术就是要保证无论个体数据在或不在数据集中,对最终的查询结果都没有显著影响.基于这种思想,ε-差分隐私的严格定义如下:
定义1[1].ε-差分隐私.若随机算法K对任意一对相邻数据集D,D′及任意输出S⊆range(K)均满足:
Pr[K(D)∈S]≤exp(ε)×Pr[K(D′)∈S],
则称算法K满足ε-差分隐私.
在定义1中,相邻数据集D和D′是指这2个数据集仅相差1条数据记录,即|DD′|=1,并用D≃D′表示这种相邻关系.可以看出,差分隐私的严格数学定义保证了无论数据样本是否存在于数据集D中,算法输出的概率分布几乎不变,而隐私系数ε的大小则反映了隐私保护程度的强弱,即ε的值越小,算法在相邻数据集上的输出的概率分布就越相近,提供更高强度的隐私保护,同时算法输出的可用性也会越低.
2.2 噪声机制
噪声机制是实现差分隐私的主要技术,即在算法输出中加入一定量的噪声,而所添加噪声的多少依赖于具体的噪声机制和查询函数的全局敏感度.Dwork等人[26]提出的Laplace机制是目前应用最广泛的差分隐私机制,其通过向算法输出中添加Laplace噪声实现差分隐私.
定义2[26]. 全局敏感度.对于任意1个实值查询函数f和相邻数据集D,D′,查询函数f的全局敏感度定义为
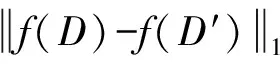
定义3[26]. Laplace机制.对于给定的数据集D和实值查询函数f,令Δf为f在数据集D上的全局敏感度,则随机算法K:K(D)=f(D)+Y满足ε-差分隐私,其中Y~Lap(Δfε)是加入的随机噪声量,服从尺度参数值为b=Δfε的Laplace分布.
在定义3中,Laplace机制的概率密度函数为
Laplace机制通过添加Laplace噪声实现差分隐私,要求查询函数f的输出必须是实数,这在一定程度上限制了其应用.为此,Mcsherry和Talwar[27]提出了指数机制,采用满足特定分布的随机抽样来代替添加噪声,以此来实现差分隐私,从而使得指数机制具有更加广泛的应用范围.
粗略来讲,指数机制定义了效用函数q,使得每一种输出方案都对应着1个由q刻画的效用函数值,而效用函数值最大的输出方案有更大的概率被采用.
定义4[27]. 指数机制.对于给定的数据集D,令q是评估数据集D上所有输出方案的效用函数,如果算法K满足输出为r的概率与exp(εq(D,r)2Δq)呈线性关系,则算法K满足ε-差分隐私,其中Δq为效用函数q的敏感度:
2.3 差分隐私的组合性质
对于一个复杂且困难的隐私保护问题,应根据数据集自身特性多次、分步骤地使用差分隐私机制,进而使得问题得到有效解决,但是总的隐私预算ε却是有限的.因此,为了将整体隐私预算控制在ε内,需要对整个过程的每步合理地分配隐私预算,而这就需要使用差分隐私机制的2个组合性质:
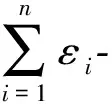
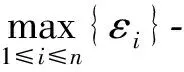
2.4 度量方法
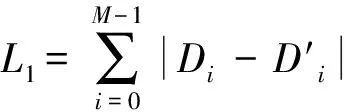
2个度分布之间的KS-距离从另一个角度刻画了它们的接近度.对于度分布D和D′,它们之间的KS-距离定义为
其中,CDFD(i)为分布D上度为i的累积分布函数值.
3 基于度排序的边移除投影方法
为降低度分布发布过程中的敏感度,提高发布后数据的可用性,本节提出一种新的图投影方法,即基于度排序的边移除投影方法(SER).粗略来讲,该方法按照度的大小依次删除图G=(V,E)中与度数较大的节点相连的边,最终将图中每个节点的度限制到给定的门限值θ之内,同时又使得G中原有的边能最大程度地保留,为差分隐私机制在压缩图中的应用提供基础.SER投影方法的细节以算法的形式给出:
算法1. 基于度排序的边移除算法.
输入:图G(V,E)、度限制θ;
输出:限制图SERθ(G).
①sorted_l;*计算deg(i),按从大到小排序[i,deg(i)]*
② while maxdeg(i)>θdo
③sort_list;*找i的所有相邻节点j按deg(j)从大到小排序[j,deg(j)]*
④ whiledeg(i)>θdo
⑤deg(i)=deg(i)-1;
⑥deg(j)=deg(j)-1;*j遍历Sort_list,直到deg(i) =θ*
⑦ end while
⑧sorted_l;*对sorted_l按deg(i)从大到小重排序*
⑨ end while
⑩ returnGθ(V,Eθ).
该算法首先计算图G=(V,E)中所有节点的度并按照从大到小排序;然后找出度最大的节点i,将其相邻节点按度从大到小进行排序,并按照此序列对与节点i相连的边进行删边处理,直到deg(i)=θ时结束本次运算;对所有节点按照度从大到小进行重新排序,重复进行上述操作,直至所有节点都满足条件,结束算法.
为了更直观地说明算法1的流程,图1给出了相关3种图投影方法的例子,门限值θ=2,其中ER使用的边排序为随机序列,我们设边排序为:10,9,8,7,6,5,4,3,2,1;πθ使用的边序列为字典序:1,2,3,4,5,6,7,8,9,10.可以看出,使用文献[5]中的ER方法时,我们按照假设的随机边序列进行减边,当存在构成边的顶点的度大于θ时,我们删除此边,遍历边序列,我们可知最后能保留4条边;使用文献[7]中的πθ方法时,我们首先删除所有的边只保留节点,然后按照边序列进行加边,当存在构成边的顶点的度大于θ时,我们跳过此边,遍历边序列,我们可知最后能保留5条边;而使用我们提出的SER投影方法时,首先对节点按照度大小进行排序,找出度最大的节点d,然后再对d的相邻节点进行排序,当deg(d)>θ时,对d按照相邻节点序列进行删边,直到deg(d)=θ时,结束此次计算,并对节点按照度大小再次进行排序,依照上述方法计算,直到所有节点的度都小于等于θ时,结束算法.通过SER投影方法可知,最后能保留6条边.
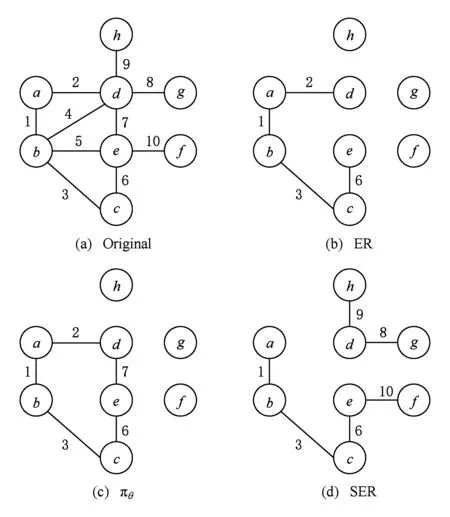
Fig. 1 ER,πθ, SER method example图1 ER,πθ,SER方法举例
从图1简单例子可以看出,ER方法对要删除的边进行随机排序,这虽然保证了算法的运行效率,但却损失了很多原始图的边信息;πθ这种方法从形式上看似是在增加边,但其本质仍还是删除多余的边,进而把图中节点的度限制在给定的门限值内,同样没有对要删除的边做一定规则的排序;而我们提出的SER投影方法,规定了边的排序规则,在限制度的前提下,更多的保留了原始图中的边,减小了投影图和原始图之间的误差,从而提高了差分隐私保护后的数据可用性.
事实上,无论采取何种投影方法,最终目的都是要使得图1中所有节点的度小于给定的门限值θ.基于此,我们可以将图数据中的节点简单地分成2类,即节点度deg>θ和deg≤θ.图2给出了这2类节点在图数据中的所有连接方式,在图2中边依据其顶点度与θ之间的大小关系也相应地分为Ⅰ,Ⅱ,Ⅲ 三类.为了尽可能多地保留原始图中的边,我们希望在降低节点度的过程中所删除的全都是Ⅰ类边.但是,实际应用中的图数据很难满足这种理想情况,此时我们就需要去删除Ⅱ类边.在这种情形下,如果不对要删除的边进行排序,就会在没有删除完Ⅰ类边的情况下去删除Ⅱ类边,造成不必要的信息损失.而本文所设计的算法1,就是在尽可能地把Ⅰ类边删除完的情况下再去删除Ⅱ类边,从而实现尽可能多地保留原始图中边的目的.
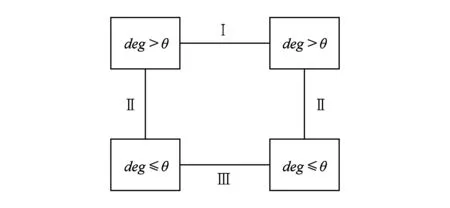
Fig. 2 Two nodes of connection in graph图2 2类节点在图中的连接方式
从上述分析可以看出,本文所提出的基于度排序的边移除算法已经最大程度上逼近了原始图中所能保留边的最大数目.此外,该算法通过不断地更新度排序,在算法运行效率和运行结果之间实现了较好地平衡.下面我们通过定理1说明,图G=(V,E)在SER投影方法处理后,所得到压缩图SER(G)的直方图hist(SER(G))的全局敏感度Δhist被限定在2θ+1的范围内.
定理1. 对任意2个仅相差1个节点的图G和G′(相邻图),在经过SER投影方法所生成的度直方图的敏感度为
证毕.
4 基于SER的点差分隐私度直方图发布
在文献[29]中,最早提出了把聚合的思想应用到直方图中来减少误差;Day等人[7]通过结合增边的图投影方法πθ和聚合的思想,提出了2种高效的点差分隐私度直方图发布方法,即(θ,Ω)-直方图发布和累计度直方图发布.在本节,我们基于第3节所提出的SER投影方法和文献[7]中的直方图发布机制,给出2种新的点差分隐私下度分布发布机制,并证明其全局敏感度的大小和隐私安全性.
4.1 SER-(θ,Ω)-直方图
在SER-(θ,Ω)-直方图发布方法中,先用预先设置好的聚合规则Ω和Θ值得出一个由(θi,Ωj)组成的候选集T,并计算质量函数,然后通过指数机制选择(θi,Ωj),再运用提出的SER投影方法和度门限值θi对原始图进行压缩,最后用选择的聚合规则Ωj对压缩图的度直方图进行聚合并加噪,并做尾部处理.在我们的仿真实验中,Θ的值为[1,100]中的整数,聚合规则Ω在文献[7]中给出.
在第3节我们已经证明了SER投影方法在直方图中的全局敏感度为2θ+1,则其质量函数为
其中,eh为创建直方图过程中引入的误差:
eh(G,θi,Ωj)=
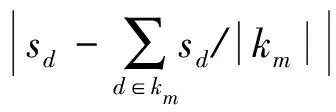
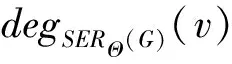
在上述参数约束下,所用指数机制中的全局敏感度为6Θ+4[7].进而,基于SER投影方法的点差分隐私(θ,Ω)-直方图发布机制可通过算法2给出,其中ε1,ε2为进行差分隐私机制中所需隐私预算.
算法2. SER-(θ,Ω)-直方图发布算法.
输入:图G(V,E)、隐私预算ε1,ε2、候选集T;
输出:加噪后的度分布D.
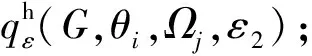
③ 通过算法1来投影图G,得到Gθ*;
⑤ 通过算法5对h做尾部处理,得到h′;
⑥ returnD=h′
该算法中我们首先计算每个候选组(θi,Ωj)所对应的质量函数,其中θi遍历[1,100]中的整数.然后通过指数机制来选择候选组,并用候选组中的θi对输入图G进行压缩得到Gθ*.最后,用聚合规则Ω*对Gθ*的度直方图进行合并,用拉普拉斯机制对合并后的直方图加噪.由于算法1的原因,直方图在靠近θi的部分会明显高于相邻桶,不符合一般度分布的规律,所以我们在第5步设计了尾部处理(这一部分将在4.3节中详细介绍).
4.2 SER-累积度直方图
在SER-累计度直方图发布机制中,第k个桶的计数为cumhistk=|v:deg(v)≤k|,即图中度不超过k的节点的个数.下面我们通过定理2证明在累积度直方图发布机制中,SER投影方法的全局敏感度Δcumhist为θ+1.
定理2. 对任意2个仅相差一个节点的图G和G′(相邻图),在经过SER后所生成的累积度直方图的敏感度为
证毕.
在界定SER投影方法在累积直方图发布机制中的全局敏感度之后,则满足累积度直方图的质量函数可定义为
而用指数机制选择参数时的全局敏感度为2Θ+2.因此,基于SER投影方法的累积度直方图发布机制如算法3所示:
算法3. SER-累积度直方图发布算法.
输入:图G(V,E)、隐私预算ε1,ε2、候选集T;
输出:加噪后的度分布D.
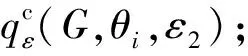
③ 通过算法1来投影图G,得到Gθ*;

⑤ 通过算法4对ch做拆分处理,得到h;
⑥ 通过算法5对h做尾部处理;
⑦ returnD=h′
该算法中我们首先计算每个候选组θi所对应的质量函数,其中θi遍历[1,100]中的整数.然后通过指数机制来选择候选组,并用算法1对输入图G进行压缩得到Gθ*.最后,对Gθ*的累积直方图用拉普拉斯机制加噪.由于我们最后得到是累积度直方图,为了方便实验对比,我们还要用算法4(下面会详细介绍)对直方图进行拆分.同算法2,对拆分后的直方图进行尾部处理.
累积度直方图除了具有添加噪声少的优点外,同时还具有单调性,即直方图中桶的值是递增的.基于此,我们把累积直方图转化为普通直方图,设计了一种校准直方图的算法,对发布结果进行调整,同时也方便进行对照实验.在算法4中,如果前一个桶比后一个桶小,则直接用差值作为当前桶的计数.但是,由于噪声的破坏,有可能会出现前一个桶比后一个桶大的情况,这时就需要在直方图桶i到θ中找到1个大于桶i的桶j,在桶i到桶j中均匀地分配计数(行⑤~).
算法4. 提取累积直方图.
输入:界限为θ噪声累积直方图ch;
输出:界限为θ度直方图h.
①ch0=0,i=1;
② ifch1<0 then
③ch1=0;
④ end if
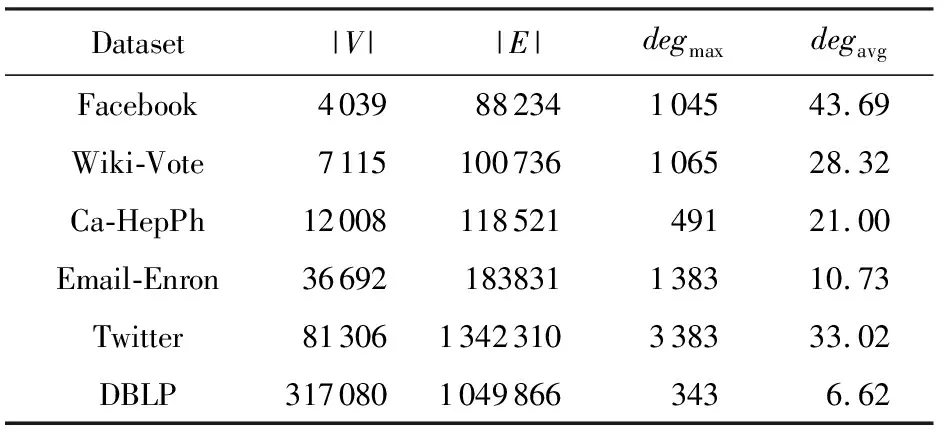
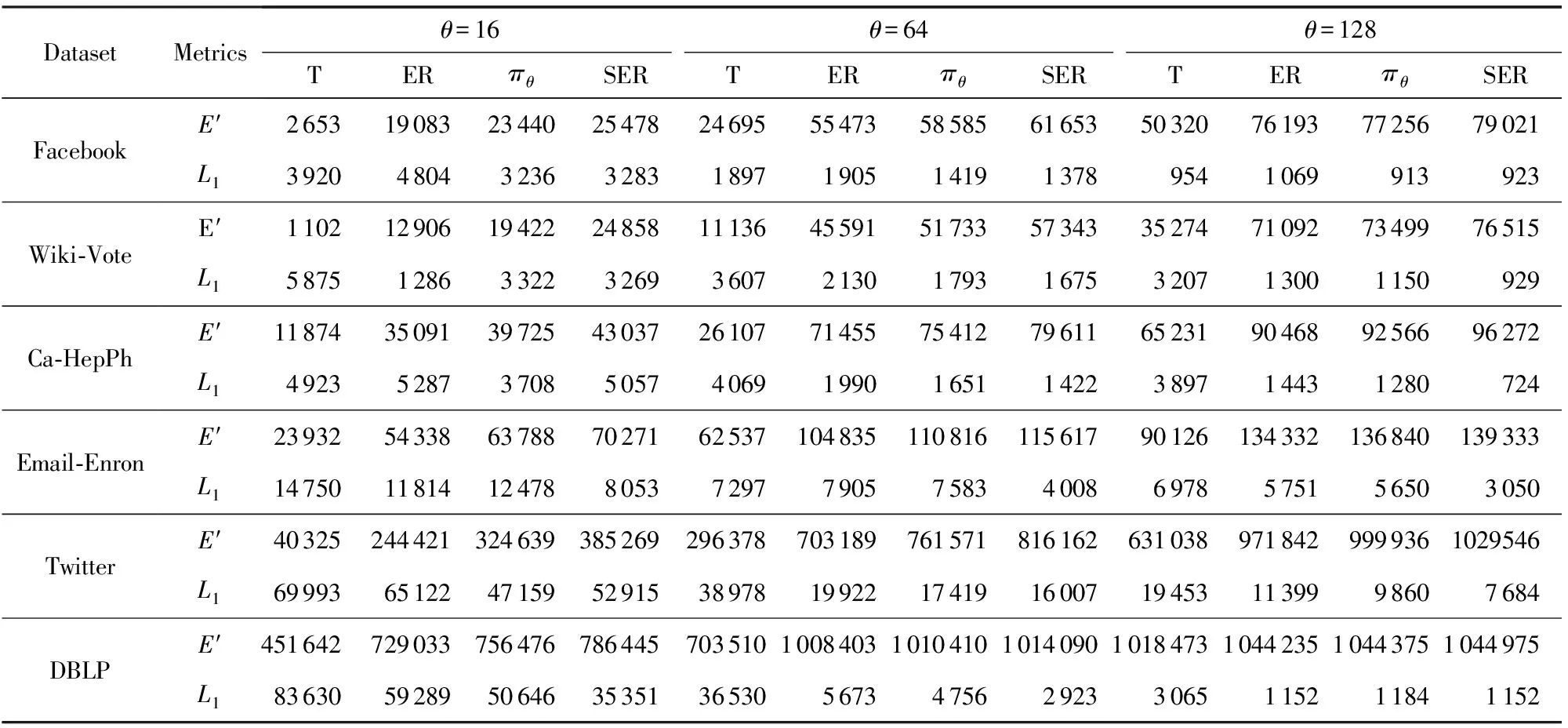
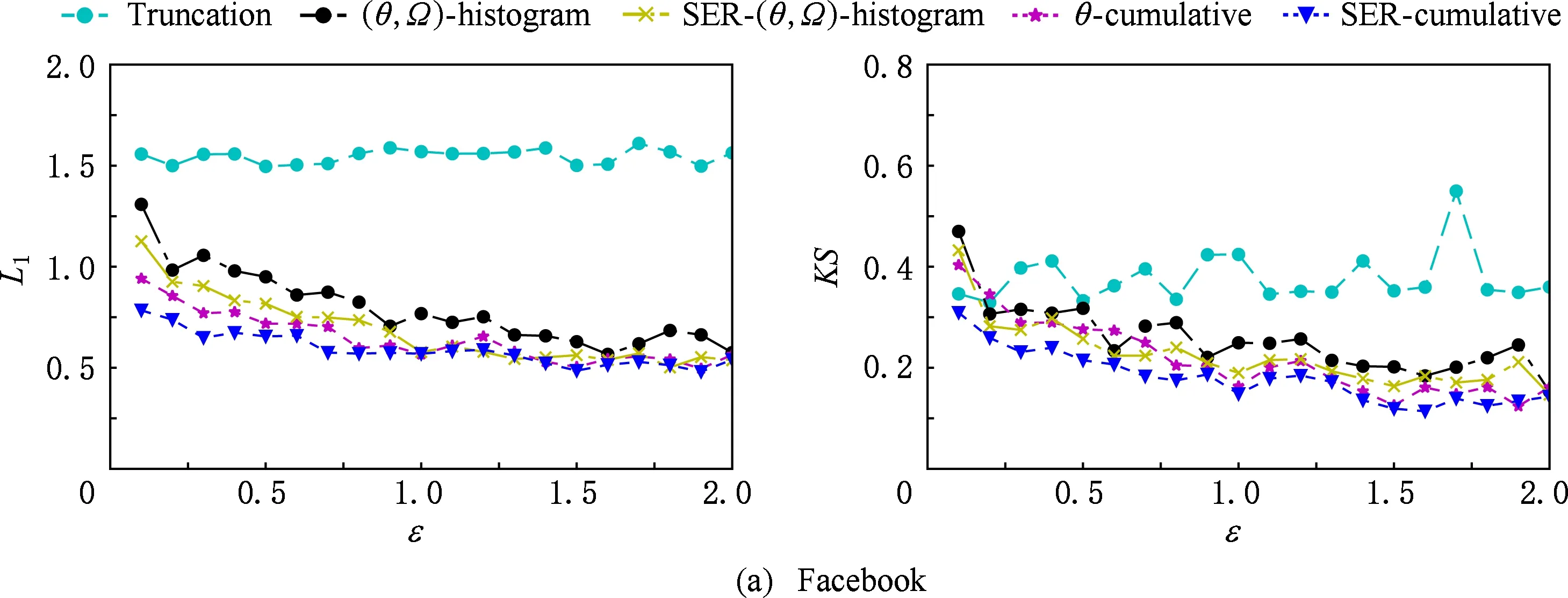
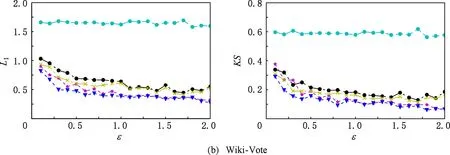
⑤ whilei≤θdo
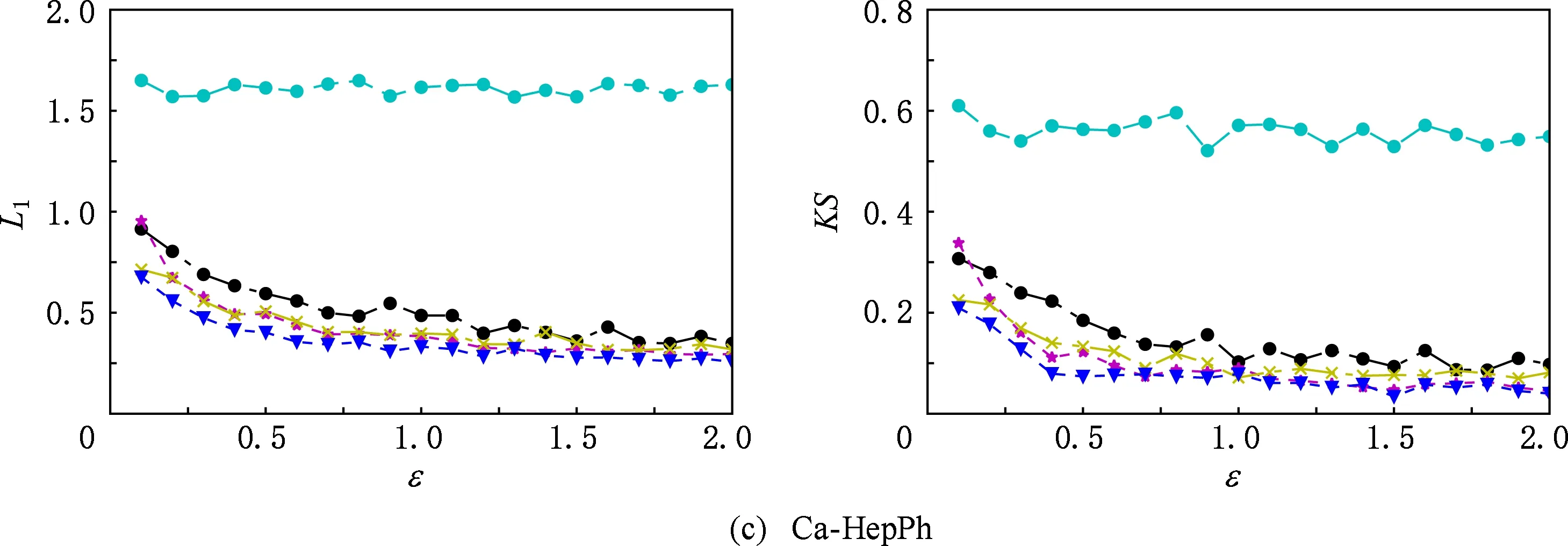
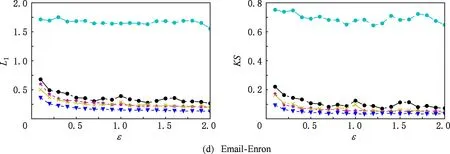
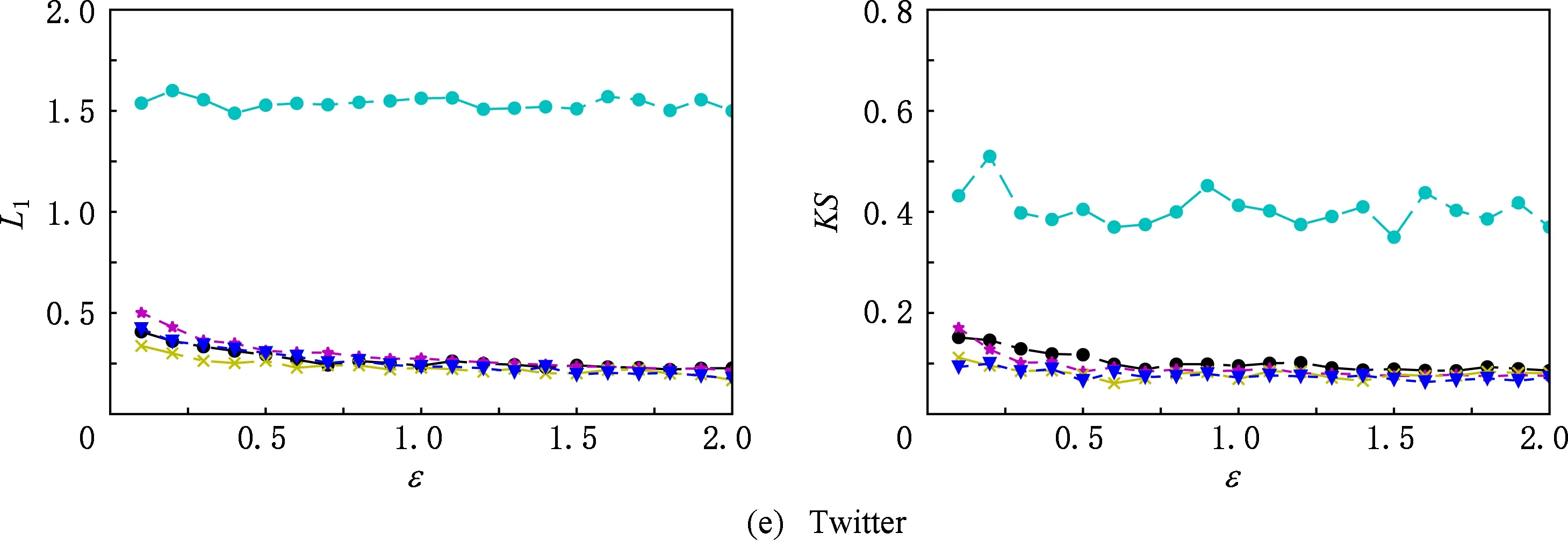
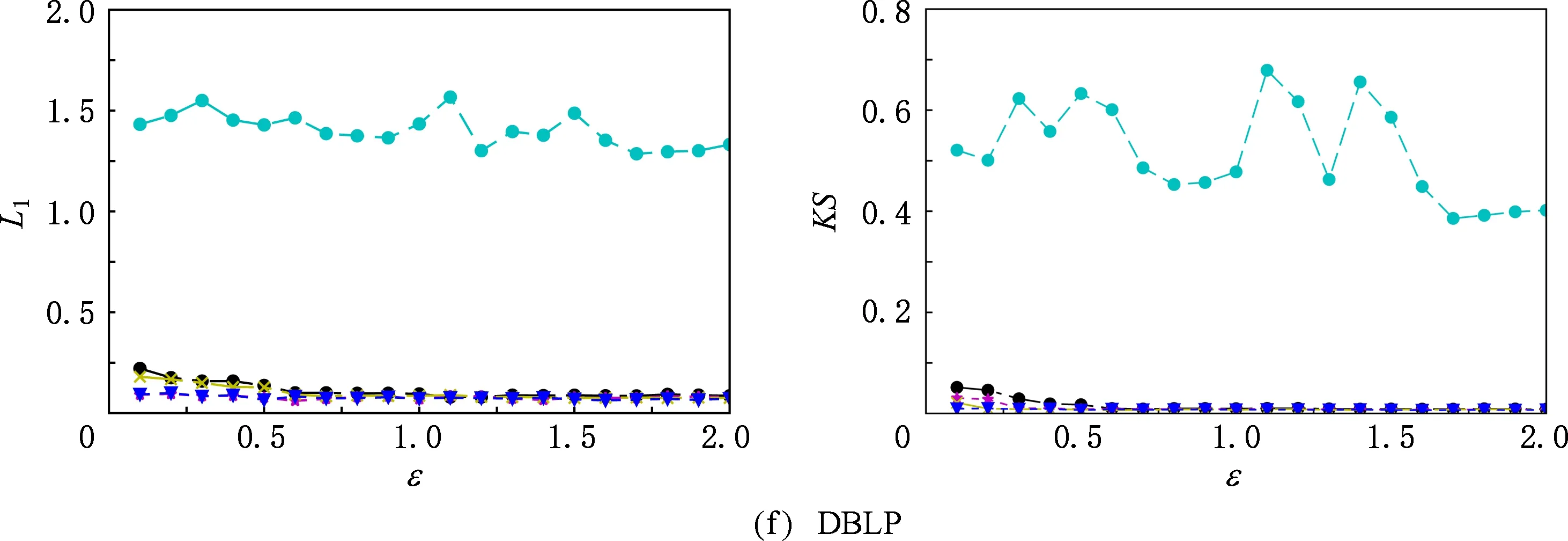
⑥ ifchi ⑦hi=chi-chi-1; ⑧i=i+1; ⑨ else ⑩j∈[i,θ],从i到θ遍历集合找到第1个使得chi 通过观察原始图可以发现,度分布一般遵循长尾分布,低度节点的计数通常较大,高度节点的计数通常较小且作出的直方图类似于长尾.但是,经过投影后的图的度分布却与此不符:在度为θ的节点周围的计数很大.这就导致最后发布的度分布与原始分布有较大的差异,并且当噪声不够大时,很有可能造成隐私泄露.事实上,这是由于所设计投影算法把度大于θ的节点全部投影在了度等于θ的节点周围,进而导致θ周围桶的计数过大.针对此类问题,一般采用基于线性回归的尾部处理方案,即通过直方图中除去θ的后半部分进行学习,得出线性回归的斜率k和截距b,然后对加噪后的分布进行处理. 结合所提SER投影方法的细节,下面给出适用于基于SER投影方法的2种度分布发布机制的尾部处理方法: 算法5. 基于线性回归的尾部处理. 输入:直方图H={h1,h2,…,hθ},n=|V|; 输出:处理过的直方图h. ①H′={hθ2,hθ2+1,…,hθ-1,hθ}; ② 根据H′拟合出二次函数F,并找出二次函数的拐点j; ③budget=sum([hj+1,hj+2…,hθ]);*设直方图中度从拐点j开始到θ的计数为预算* ④H={hθ2,hθ2+1,…,hj};*取直方图中除去预算的部分作为回归学习的样本* ⑥ 根据H学习出线性回归的斜率k和截距b. ⑦ fori=jton ⑧ ifk<0 then ⑨hi=k×i+b; ⑩ else 算法5的主要思想根据前半段符合长尾分布的直方图学习出线性回归的斜率和截距,然后把靠近θ的异常桶计数按照学习出的参数进行分配.此过程扩展了直方图的横轴,使得经过差分隐私后的度直方图更加符合原始图的分布. 我们需要说明基于SER投影方法的(θ,Ω)-直方图和累积直方图的隐私安全性并通过定理给出. 定理3. 基于SER投影方法的(θ,Ω)-直方图发布机制满足(ε1+ε2)-点差分隐私. 证明. 在算法2中,行①②计算质量函数并通过指数机制来选择参数.相当于n个查询,这n个查询记为Q1.由4.1节可知,删除图G中的1个节点,最多影响图G中的6Θ+4个节点的度,则ΔQ1=6Θ+4.根据定义4可知行①②满足ε1-差分隐私.行③④对压缩图的聚合直方图利用拉普拉斯机制添加噪声.由于聚合组的大小已知,相当于查询每个组的计数总和,该类查询记为Q2.由定理1可知,ΔQ1=2θ+1.根据定义3可知行③④满足ε2-差分隐私.根据引理1及1.1节中对图的点差分隐私描述可知,基于SER投影方法的(θ,Ω)-直方图发布机制满足(ε1+ε2)-差分隐私. 证毕. 同理可知基于SER投影方法的累积直方图也满足(ε1+ε2)-点差分隐私,其隐私安全性证明与定理3类似,不再赘述. 为评估本文所提SER投影方法以及基于该算法的直方图度发布机制的性能,本节将SER投影方法和已有的3种图投影方法Truncation,ER,πθ[4-5,7]在不同数据集上的运行效果做一对比.仿真实验所用的数据集包括社交网络(Facebook,Twitter)、选举投票(Wiki-Vote)、电子邮件(Email-Enron)、协作网络(Ca-HepPh,DBLP)6个现实世界中的真实数据集,均来自Stanford Large Network Dataset Collection网站[30].表1给出了这6个数据集的部分特征,其中degmax表示图中节点的最大度,degavg表示图中节点的平均度.实验平台采用Intel®CoreTMi5-7400 CPU、8GB内存主机. Table 1 Information About Dataset表1 数据集信息 由于把节点度限制到门限值θ时,大量度大于θ的节点投影成了度小于等于θ的节点,进而导致了度等于θ的节点的计数增加,从而影响L1误差的计算结果,掩盖了投影方法的其他特性.因此,在表2的对比结果中,为了更好地反映出投影方法的优劣,我们在计算L1误差时删除了度等于θ的节点计数. 在点差分隐私约束下直方图度发布算法的对比实验中,由于存在拉普拉斯噪声,为了更好地反映算法的优势,我们对每个ε取值计算30次,最后取平均值作为输出.同时,取候选集的大小为100,即Θ∈[1,100]. Table 2 The Results on Different Datasets表2 Truncation,ER,πθ,SER方法在5个数据集上的实验结果 表2给出了Truncation[4],ER[5],πθ[7]3种图投影算法和本文所提出的SER投影方法在6个不同数据集上,θ取16,64,128时的实验结果,其中E′为经过投影后保留的原始图的边个数,L1为定义的L1误差,越小表示数据可用性越好. 从表2中可以看出,随着度门限值θ的增加,这4种算法中保留边的数目都在不断增加,同时L1不断减小.但是,与其他3种已有算法相比,本文所提SER投影方法能在保留边最多的情况下,同时也能保持较好的L1误差.这说明SER方法在投影后能更好的保证原始图的度分布的形状,使其更加接近真实分布,为后续的数据分析和处理奠定基础.图3比较了在L1,KS这2种不同的度量指标下,本文提出的方法与文献[4]、文献[7]提出的方法在刻画节点度分布时的差异.其中图3(a)~(f)左半部分是用L1度量的结果,图3(a)~(f)右半部分为用KS度量的结果.从图3可以看出,随着数据集的变化,截断算法下的L1,KS一直是所有方法里面最大的,说明截断算法的效果最差.这是由于算法本身删除了许多本没必要删除的边,损失了原始图中的大量有效信息,造成了度分布的误差过大.(θ,Ω)-直方图发布方法和累积度直方图发布方法的结果表明:对不同数据集,随着规模的增大,2种方法的误差呈现减小趋势;对于相同的数据集,随着隐私预算的增大,2种方法的误差呈现减小趋势,这符合我们一般的规律. Fig. 3 Comparison of two histogram publishing methods图3 2种直方图发布方法实验 从表1可以看出,Twitter和DBLP这2个数据集的边个数差距不大,但是DBLP有更多的节点,Twitter有更大的最大度和平均度,这说明DBLP所构成的图相较Twitter来说更加分散.反映到图3中就是在2种直方图发布方法下,DBLP相较Twitter的误差更小,这说明了分散图的度分布更好去刻画.这是由于分散图存在大量的节点p,其中deg(p)≤θ.而我们提出的方法能更好地保留度小于θ的节点所连接的边,所以出现这种情况.同时为了方便对比,我们把同一类型的纵坐标取到相同的范围,这使得最后2个数据集的效果不能很好地区分,不过从原始数据来看,我们提出的2种基于SER投影方法的直方图发布方法效果要好于文献[7]中的方法,这也符合前4种数据集的实验结果. 总的来说,累积直方图发布方法要优于(θ,Ω)-直方图发布方法,基于SER投影方法的2种直方图发布方法在不同数据集上的效果优于基于πθ的直方图发布算法和截断算法.特别地,当隐私预算ε≤1时,这种优势更为明显.这说明本文所提点差分隐私约束下度分布发布算法适用于对隐私预算控制很严格的情况,更符合隐私保护的相关要求. 随着社交网络、推荐系统等新型信息系统的广泛使用,图数据在大数据处理领域变得越发常见.大数据分析技术在图数据上的广泛应用可以带来巨大的经济价值和社会效益,这又促使各种组织机构开始搜集和发布大规模的图数据集.另一方面,所搜集的图数据中又包含用户的敏感信息,如何在保护用户隐私的前提下发布这些数据变得尤为迫切. 本文重点关注点差分隐私约束下的图的度分布发布机制的设计,首先提出了一种基于度排序的边移除(SER)算法,通过将原始图投影到一个压缩图来降低发布机制中的全局敏感度.进一步地,基于所提SER投影方法给出了2种满足点差分隐私的度直方图发布机制,并证明了其隐私安全性.仿真实验表明:相比已有方法,在相同的约束条件下,本文所提SER投影方法能最大程度地保留原始图中的边信息,为后续的数据处理奠定了良好的基础.与已有度分布发布方法相比,基于SER投影方法的度直方图发布机制在L1误差和KS-距离这2个评估指标上均具有优势,使得发布后的度分布更接近原始图的度分布,可用性也越高.4.3 直方图尾部处理
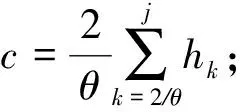
4.4 隐私安全性证明
5 实验与结果
5.1 实验设置
5.2 结果分析
6 总 结
猜你喜欢
数学杂志(2022年5期)2022-12-02湘潭大学自然科学学报(2022年2期)2022-07-28中华骨与关节外科杂志(2021年8期)2021-11-30新世纪智能(数学备考)(2021年5期)2021-07-28西安邮电大学学报(2021年6期)2021-05-10安徽电子信息职业技术学院学报(2020年5期)2020-11-13摄影之友(影像视觉)(2018年12期)2019-01-28初中生世界·八年级(2017年3期)2017-03-24医学研究杂志(2015年9期)2015-07-01太空探索(2014年1期)2014-07-10
