
基于分布式网络爬虫的Web空间数据获取方法研究
2019-04-12 01:55曾李阳朱齐华
贵州大学学报(自然科学版) 2019年1期
冯 玲,黄 亮*,曾李阳,朱齐华
(1.昆明理工大学 国土资源工程学院,云南 昆明 650093; 2. 国家测绘地理信息局四川基础地理信息中心,四川 成都 610041)
GIS是一门以数据为基础的学科,空间分析、空间统计和空间数据挖掘等研究都离不开空间数据的支撑,而互联网中存在海量空间数据,这些数据与人们的日常生活活动密切相关并且包含的信息量十分丰富、现势性极强。如果能够对互联网中广泛存在的空间数据高效地进行获取,一方面可以补充基础地理信息的不足,提供丰富的细节和准实时更新,另一方面还能够为GIS空间分析和空间数据挖掘提供信息量丰富、高时效性的数据源。
Web空间数据获取主要采用网络爬虫技术,国内外许多学者在这方面进行了研究。Leasure D R指出,利用网络爬虫技术,可以丰富GIS空间分析的数据来源[1]。 Tezuka T等研究提出的网络爬虫技术降低了Web空间数据获取的难度[2]。Zhang C J提出了基于网络爬虫技术的地名地址库更新方法[3]。Hua-Ping Zhang等研究了从互联网新闻报道中自动提取POI数据的方法[4]。Li W研究了基于网络爬虫的OGC服务发现方法[5]。Chen X基于网络爬虫实现了自动化发现和检索WMS服务[6]。Jiang J研究了检索WFS服务的网络爬虫[7]。王明军在普通网络爬虫技术基础上提出了空间敏感爬虫的思想体系,并从多个方面对其进行了阐述[8]。蔡地在研究开源网络爬虫框架的基础上,提出通过多线程和异步I/O两种策略来优化Web空间数据的获取效率[9]。Ager A则在研究中指出,如果能够对Web空间数据进行有效的利用,将对GIS的发展产生深远的影响[10]。
通过分析国内外研究现状发现,目前基于网络爬虫的Web空间数据获取研究大多数采用单机网络爬虫的形式。然而,Web空间数据广泛分布于不同的网络站点中且更新频率快,依赖单机网络爬虫抓取数据在抓取覆盖率和效率上难以满足需求,难以保证抓取数据的及时性和全面性,因此本文针对单机网络爬虫获取Web空间数据存在的问题,研究基于分布式网络爬虫提高Web空间数据获取效率。
1 分布式网络爬虫实现原理
基于分布式网络爬虫的Web空间数据获取方法不是通过增加单个爬虫系统的负荷而是通过增加更多的爬虫系统成员来提高数据获取性能和效率,即采用多台性能一般的机器来做数据抓取,同时在每台机器上部署多个爬虫,增加数据抓取的并发性。具体的实现方式是采用不同的机器承担不同的角色分工,选取一台性能较好的机器专门负责URL(Uniform Resoure Locator,统一资源定位器)的统一调度和去重,将这台机器称为主节点,主要用来管理和维护待爬取URL队列和已爬取URL队列。采用多台性能一般的机器进行实际的网页下载和数据解析,把这些机器称为爬虫节点。
本文提出的分布式网络爬虫的运行原理如图1所示,爬虫节点从主节点请求URL进行数据抓取,在抓取数据的同时生成新的URL,并将此URL发送给主节点,主节点负责对爬虫节点提交的URL进行去重,并将其加入待爬取URL队列。爬虫节点之间没有通信联系,每个爬虫节点只和主节点进行通信,主节点通过一个地址列表来保存系统中所有爬虫节点的信息。因此,当分布式网络爬虫系统中的节点有变化的时候(新增爬虫节点,删除某爬虫节点,或爬虫节点地址发生变化),主节点只需调整地址列表中数据,爬虫节点只需要负责抓取数据。同时,主节点负责对分布式网络爬虫系统中各爬虫节点进行负载均衡。

图1 分布式网络爬虫实现原理图Fig.1 Schematic diagram of distributed network crawler implementation
2 系统设计与实现
2.1 系统架构
原型系统是根据上述分布式网络爬虫实现思路,在主节点上部署Redis缓存数据库来管理和维护分布式网络爬虫系统中各爬虫节点共享的已爬取URL队列和待爬取URL队列,爬虫节点之间没有通信联系,每个爬虫节点都会与主节点Redis缓存服务器建立连接,并在每个爬虫节点上部署MongoDB数据库,用来存储和管理抓取到的数据。分布式网络爬虫系统中单个爬虫节点的系统架构如图2所示。
2.2 系统实现
本文通过对开源网络爬虫框架Scrapy进行深度开发来实现面向Web空间数据获取的分布式网

图2 爬虫节点系统架构Fig.2 Crawler node system architecture
络爬虫原型系统。Scrapy是一个爬取网站数据,提取结构性数据而编写的基于python语言的应用框架[11],它基于Twisted异步网络库来管理网络通讯[12]。开发者可以对Scrapy框架进行扩展以完成网络爬虫的定制,本文实现了定制的调度器、解析器、数据过滤器和下载器中间件,而下载器和爬虫引擎则使用Scrapy框架自带的模块。表1为原型系统的开发环境。
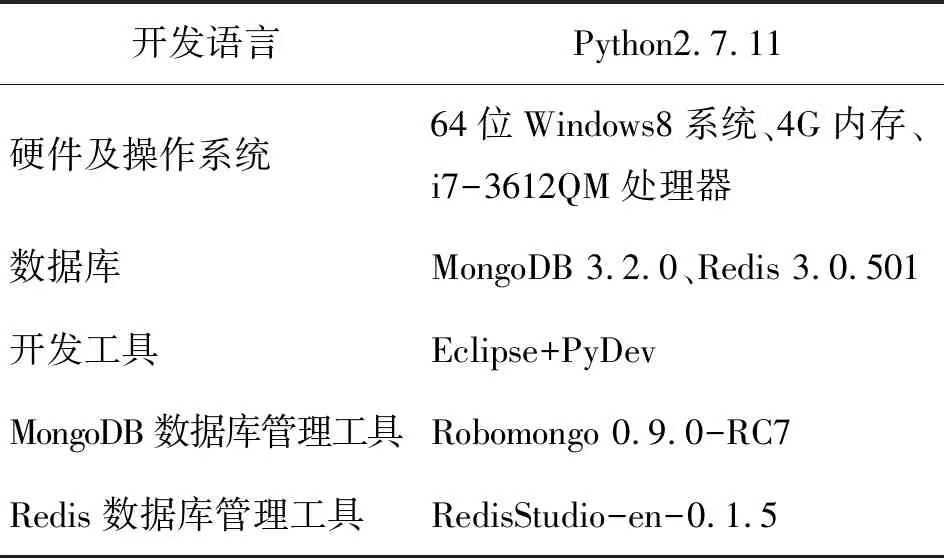
表1 原型系统开发环境Tab.1 Prototype system development environment
3 系统测试与结果分析
3.1 测试环境
本文使用四台配置普通的PC机来进行系统测试,选择其中内存较大的一台部署为主节点,在其上安装Redis缓存数据库用于维护待爬取URL队列和已爬取URL队列。使用另外三台PC机进行实际的网页下载和数据解析,在其上安装python环境和MongoDB数据库,将其作为爬虫节点,测试时的网络带宽为8 Mb/s。
3.2 测试结果分析
为了避免网络流量对实验测试产生影响,将系统测试时间定于晚上10点至次日7点,系统共运行9个小时。分别对单机爬虫和分布式网络爬虫系统进行了测试,单机爬虫的测试结果如表2所示。
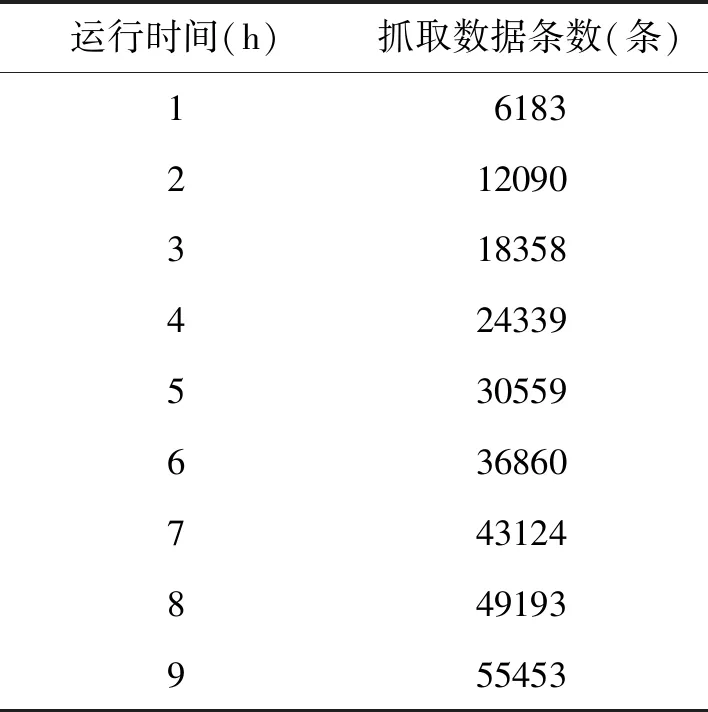
表2 单机爬虫测试结果Tab.2 Single crawler test results
分布式网络爬虫的测试结果如表3所示。

表3 分布式网络爬虫测试结果Tab.3 Test results of distributed network crawler
将实验数据结果绘制成折线图,实验结果如图3所示。
由图3可知,分布式网络爬虫系统中三个爬虫节点抓取数据的总数与运行时间可近似视为正比例关系,这说明原型系统能够稳定地运行。分析此图的横纵坐标可以得出,每条线的斜率就是数据爬取效率,采用分布式网络爬虫抓取数据的效率远高于单机爬虫,这说明本文设计实现的分布式网络爬虫系统具有良好的扩展性。测试过程中,每个爬虫节点抓取数据的情况如图4所示。
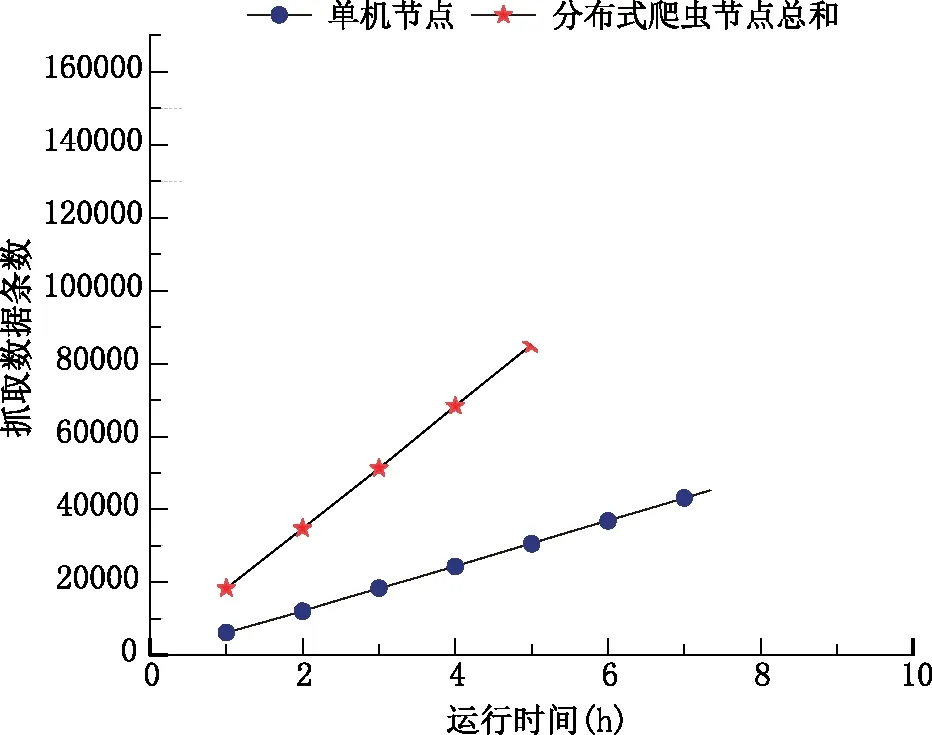
图3 分布式网络爬虫测试结果图Fig.3 Test results of distributed web crawler

图4 单机与并行节点性能对比图Fig.4 Comparison of performance between stand-alone and parallel nodes
由图4可知,当采用分布式网络爬虫系统进行爬取时,其所包含的每个节点的爬取效率同单机爬虫相比有所下降,但是这个下降是在正常范围之内,因为多个节点同时运行时共用同一条对外网络接口,网络带宽成了并行爬行的主要瓶颈。同时从图4中还可以得知,节点一、节点二、节点三的所承担的爬取任务数量基本相同,这说明本文设计和实现的分布式网络爬虫系统能够实现系统各个节点之间负载均衡。
4 结束语
本文针对单机网络爬虫获取Web空间数据在抓取覆盖率和抓取效率上受到限制,难以保证抓取数据的及时性和全面性的问题,研究了基于分布式网络爬虫的Web空间数据获取方法。通过实验分析对比证明,本文提出的基于分布式网络爬虫的Web空间数据获取方法能够提高Web空间数据获取效率,设计和实现的Web空间数据获取原型系统能够稳定运行,并且系统具有良好的扩展性,系统各个节点之间能够实现负载均衡。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
新疆钢铁(2021年1期)2021-10-14
现代信息科技(2021年21期)2021-05-07
炎黄地理(2019年1期)2019-09-10
航天工业管理(2019年11期)2019-04-20
电子制作(2018年2期)2018-04-18
能源(2017年9期)2017-10-18
电子制作(2017年9期)2017-04-17
华东理工大学学报(自然科学版)(2015年5期)2015-02-27
科技传播(2011年8期)2011-08-15
