
CNN多位置穿戴式传感器人体活动识别∗
2019-04-18 05:07邓诗卓王波涛杨传贵王国仁
软件学报 2019年3期
邓诗卓,王波涛,杨传贵,王国仁
1(东北大学 计算机科学与工程学院,辽宁 沈阳 110819)
2(北京理工大学 计算机学院,北京 100081)
近年来,随着智能生活概念的普及和可穿戴终端设备技术的快速发展,大量的时序传感器数据为普适计算、人工智能等领域带来了新的研究热点,因此,基于传感器数据的人体活动识别(human activity recognition,简称HAR)[1,2]得到了广泛关注.基于传感器数据的HAR能够有效地避免基于视频数据动作识别[3,4]带来的隐私泄露等问题[5],且计算复杂度比视频数据低,使得基于传感器的HAR研究更加具有现实意义.目前,HAR的研究应用包括健康监控[6-8]、智慧家庭[9-11]、工业环境[12]和运动员监测[13]等,例如:老人通过佩戴智能手环检测是否有走路姿态异常;工人通过佩戴传感器来记录和规范操作动作.因此,准确地识别和记录人体的活动姿态,能够为人们提供更为精确的服务.面对多形态多位置的复杂传感器数据,如何利用传感器数据特点提取具有良好判别力的特征以提高基于传感器数据的的HAR准确率,是具有研究价值和现实意义的研究问题.
基于传感器数据的HAR特征提取方法包括传统特征提取和深度学习特征表达两种方法[1,2].传统方法需人工对划分的数据抽取统计学意义特征向量,包括时域特征[14-16]、频域特征[17]以及其他特征向量[16,18].但是传统方法所抽取的特征都是浅层的,深度学习技术可以直接从原始数据自动地抽取更复杂的深层的特征[19,20],无需人工干预;同时,深度学习可以有效地解决类内差异和类间相似的问题.卷积神经网络(convolutional neural network,简称 CNN)是深度学习方法中研究较多的特征抽取方法[2,21].文献[19]的理论分析和实践证明了 HAR中基于传感器的CNN可以更有效地抽取数据隐藏的特征.
本文基于多位置的传感器数据特点,利用深度学习中卷积神经网络技术,从原始数据中抽取有效的特征来提高 HAR识别准确率.现有的基于传感器的 CNN抽取特征方法根据卷积核维度分为一维卷积核方法1DCNN[13,22-28]和二维卷积核方法 2DCNN[29-37].1DCNN即提取基于时间依赖的特征,在时间轴上面进行卷积.虽然通过一维卷积核可以抽取具有良好分辨能力的特征,但是一维卷积核忽略了原始数据的不同位置传感器之间的空间依赖性.因此研究人员提出了基于传感器数据的二维卷积核,综合考虑了时间依赖性和空间依赖性.但是,这些 2D-CNN方法仅仅是朴素地将不同类别传感器罗列拼接,或者利用一定算法构建传感器动作图片(activity image)作为二维卷积核的输入,并没有考虑不同位置三轴向传感器(三轴加速度、三轴陀螺仪等)的相同轴向数据之间隐藏的空间依赖性.
针对以上不足,为了进一步利用不同位置的三轴传感器之间的相同轴向多位置传感器原始数据的空间依赖性,本文提出了新颖的 CNN二维卷积的输入动作图片构建方法,进而提出了卷积网络结构.为了优化网络结构,进一步提出了卷积层参数优化方法.本文的主要贡献如下:
(1) 提出了基于多位置三轴向传感器二维卷积核输入动作图片构建方法T-2D(triaxial 2 dimension).该方法对来自不同位置传感器的原始数据按照不同轴向划分,生成 3张动作图片.每一轴向动作图片构成二维卷积的输入;在T-2D基础之上,针对非三轴传感器提出M-2D(mixed 2 dimension),构建非三轴传感器数据一维卷积核输入的动作图片,以抽取时间依赖特征,共生成4张动作图片;
(2) 提出了基于T-2D和M-2D多层卷积神经网络模型T-2DCNN和M-2DCNN,将M-2D得到一维特征和T-2D得到的二维特征合并成高层次特征向量,实现了人体活动识别功能;为了减少卷积层训练参数数量,对卷积网络进行优化,进一步提出了基于参数共享的卷积网络TS-2DCNN和MS-2DCNN;
(3) 在公开数据集上进行了对比实验,验证了基于本文所提出的特征抽取方法的 HAR模型识别效果,同时验证了共享参数卷积网络在参数数量减少的情况下,可依然保持其识别效果;从传感器数量变化以及每个类别识别准确性的角度,分别验证了本文所提出的两种卷积输入动作图片构建方法的有效性和稳定性.
本文第1节介绍现有基于CNN的HAR中基于穿戴式传感器的两种典型特征抽取方法,并进行分析对比.第2节描述二维卷积核输入动作图片的两种构建方法和基于本文方法的 HAR模型的卷积网络结构及其优化网络.第3节通过实验和对比分析,证明本文提出的二维卷积输入构建方法的良好性能.最后是总结与展望.
1 相关工作
卷积神经网络已经广泛并成功地应用于图像识别[38,39]和语音识别[40],在无需知道专业领域知识(domain knowledge)的前提下,自动地抽取具有高分辨能力的特征.近年来,CNN在基于传感器数据的人体活动识别方面也取得了一定进展.与图像识别的原始数据不同,在HAR中的原始数据大多为时间序列数据、一维数据.在文献[19]中,从局部依赖(local dependency)和尺度不变性(scale invariance)这两个角度描述了在动作识别领域应用CNN的优势.本文主要从卷积核维度以及对应的输入构造方法对现有工作进行总结和分析.
1.1 HAR中一维卷积核1D-CNN应用
一维卷积核应用于一维时间序列数据,抽取具有时间依赖性的特征.尽管基于可穿戴设备传感器类型多种多样,包括加速度计、陀螺仪等,但是传感器数据或者传感器各通道数据都是一维时序数据,例如加速度计中每一个轴向的时序数据代表一个通道.图1(a)描述了大部分一维卷积核的卷积方式,数据包含具备三轴属性的传感器数据,同时也有可能包含不具备三轴属性的传感器数据,例如心率等.输入矩阵是由滑动窗口(sliding window)大小T和传感器通道总数Chan_num构成的矩阵,一维卷积核方式在各通道数据上面进行卷积操作,因此在滑动窗口固定的情况下,能够自动抽取动作特征.但在具体相关文献中,传感器的选择以及 CNN 的结构略有不同.文献[19]中,作为早期的CNN在HAR中的应用,将三轴加速度计的3个轴向数据看成3个通道,分别在各轴向数据上沿时间轴进行卷积和池化,最后合并成该窗口的特征向量,并提出了局部共享权重的CNN卷积方式.该文献使用一对卷积层和池化层,因此抽取特征属于浅层特征.文献[22]同样利用单一加速度计的三轴向原始数据作为卷积网络的输入,但是通过改变卷积核的大小来适应三轴加速度信号特点.类似地,文献[13]提出了利用手腕传感器采集的三轴加速度识别排球动作.文献[23,24]利用加速度计三轴向数据和陀螺仪三轴向数据组成六通道,对输入使用一维卷积核,多卷积层和池化层抽取深层特征提高了识别准确率.文献[25]中除了使用了三轴加速计和多种传感器数据,将 3个通道扩展成多通道,利用两层一维卷积核和池化抽取特征.文献[26]中提出了将 CNN和长短期记忆循环网络(long short-term memory,简称 LSTM)结合的深度学习模型,利用多层CNN一维卷积核自动抽取特征,且没有池化层,使用 LSTM 进行分类识别,在通用数据集上取得了良好的效果.文献[27]采用一维卷积核抽取特征,结合VGG和LSTM组合模型.文献[28]利用三轴加速度性质,将三轴加速度分看成深度为3的一维输入,经过卷积之后生成180个特征映射,以此来捕捉数据之间的依赖性.

Fig.1 Architecture of convolutional neural network based on multiple channels图1 基于多通道时序数据的卷积结构
综上所述,一维卷积核的输入通常为一维的原始信号数据.一维卷积核在抽取特征过程中能够较好地挖掘一维信号的时间依赖性,但是往往忽略了不同类别传感器或者是同一传感器不同轴向数据之间的空间依赖性,影响人体动作的识别效果.
1.2 HAR中二维卷积核2D-CNN应用
针对一维卷积核 HAR的不足,绝大多数 2D-CNN对原始数据进行重新排列,形成类似图片一样的输入矩阵,即动作图片.在该矩阵上使用二维卷积核以及相应的池化操作,利用二维卷积核抽取时空依赖性,如图1(b)所示,之后结合不同的学习模型.文献[29]将原始数据多通道输入看作一张图片,第 1层使用二维卷积核,在整张图片上进行卷积形成一维特征映射,再次进行卷积时,应用一维卷积核.文献[30]利用不同位置的相同类型传感器按三轴顺序排序,并以零矩阵填充来分隔不同类型的传感器,同一张动作图片上面包含所有轴,在此输入结构基础上使用二维卷积核.该文献实现了时间依赖性和空间依赖性结合.在文献[30]二维卷积核的基础之上,文献[31]对 CNN卷积核应用了局部权重共享和全局权重共享两种卷积方式.不同于图1(b),文献[32]利用傅里叶变换将一维原始信号数据生成频谱,对三轴加速度计和三轴陀螺仪信号形成频谱,将频谱视为动作图片作为输入进行卷积操作.类似地,文献[33]提出一种算法,可将一维信号转换为二维图片信号,其目的在于让每一通道信号都可以与其他通道信号相连,即使是不同类型的通道信号,抽取每两个信号之间的依赖性.受文献[33]的启发,文献[34]修改了输入图片构造算法,同时调整了同一时刻不同类型三轴传感器之间(x,y,z)轴的数据排列顺序,确保该时刻所有不同类型的传感器数据两两相邻,以及同一类型传感器内的不同轴向数据两两相邻.文献[35]针对单一位置传感器,使用滑动窗口折叠法分别生成三轴动作图片,在每个动作图片上分别卷积.文献[36,37]同样针对手机上传感器中的三轴加速度计,将滑动窗口内三轴数据直接生成同一张方形动作图片,之后采用卷积网络.
相比于一维卷积核只考虑时间域上面的依赖性,二维卷积核应用的角度更多,可以更大限度地利用传感器数据的空间依赖性.基于二维卷积核的HAR依赖于输入数据的组织构造形式,但是现有的工作仅仅是不同传感器数据按照通道朴素排列并直接进行二维卷积或是对三轴向传感器的同一位置的三轴数据进行简单粗暴地排列组合.尽管相较于传统的基于统计学特征的 HAR和基于一维卷积核的 HAR,现有的二维卷积方式可以提高准确率和精确率等评价指标,但是并没有充分利用不同位置的三轴向传感器数据的特点以及充分挖掘空间依赖性,如三轴加速度计.因此,本文根据三轴传感器的数据特点,充分挖掘相同轴向数据之间的空间依赖性和时间依赖性,设计新颖的输入组织形式构造多张动作图片来提高HAR的识别效果.
2 基于二维卷积核的多位置三轴向传感器HAR模型
本文提出了基于二维卷积核的多位置三轴向穿戴式设备HAR模型,该模型虽然沿用了HAR问题中的二维卷积应用的思想,但是增强了对时序数据的空间依赖性的挖掘.因此,结合三轴向传感器特点,本文提出了一种新颖的二维卷积核输入的动作图片构建方法及其改进方法,利用不同位置的三轴向传感器的相同轴向数据构成输入动作图片,将原始数据分别构建成3个或4个动作图片,基于输入动作图片构建卷积神经网络,分别抽取原始数据各轴向数据内部的时空依赖性,进而得到更加具有分辨能力的特征向量,提高模型识别准确率.为了简化模型参数,对卷积网络进行参数优化,提出了基于共享参数的HAR模型.
2.1 问题描述与定义
本文研究的根本问题是如何学习一个具有良好识别效果的人体活动识别模型,即模型参数;关键问题是如何从原始标签数据中抽取具有高分辨能力的特征;核心问题是如何构造用于二维卷积核输入的动作图片,原因在于不同的动作图片组织形式会导致二维卷积核抽取的特征具有不同的依赖性和表达能力.为了方便描述问题,形式化定义如下:
定义1(动作图片).相对于一维时序数据,动作图片是对一维信号通过一定规律进行升维操作所生成的二维信号数据.动作图片是卷积核的输入.
定义2(滑动窗口).滑动窗口是动作图片的时间窗口,是时序传感器数据的时间处理单元,令ws表示滑动窗口大小,如图1中所示,ws=T.
定义3(模型 M).给定时序数据长度N,每时刻原始训练数据X={(l1,x1),…,(lN,xN)}为带有标签数据,时刻数据标签li,其中,i∈[1,N].假设覆盖率为0且ws=T,用于训练的实例数量为N′=N/T,其中,j∈[1,N′].用于训练模型M的数据为D={(t1,d1),…,d1(tN′,dN′)},则:

其中,A,B分别为模型M的权重参数矩阵和偏置参数矩阵,Loss函数为损失函数.即:在输入数据D的条件下求取使得损失函数最小的模型参数A和B.
2.2 HAR模型二维动作图片构建
2.2.1 基于多位置三轴传感器二维动作图片构建原理
传感器形态多样化可分为传感器种类多样化和传感器位置多样化[30],本文中构造二维卷积输入的前提是传感器位置多样化.传感器种类多样化是基于多种类别传感器的动作识别,例如基于加速度计、陀螺仪、磁力计等传感器的识别.传感器位置多样化是基于多种位置的相同类型传感器或者不同类型传感器的动作识别.本文结合三轴向传感器特点,舍弃同一传感器三轴之间的空间依赖性,选择不同传感器的相同轴向数据的空间依赖性,并构建用于卷积网络输入的动作图片,从理论和数据分析两个角度阐释本文动作图片构建原理.
(1) 理论分析
以三轴加速度计为例,其三轴向传感器数值代表了 3个相互垂直方向的加速度值,从空间角度上讲,同一传感器三轴向加速度在加速度方向上是相互独立的,相关性较弱,不同传感器的不同轴向之间相关性更弱.而不同传感器的相同轴向加速度值大致描绘的是同一个方向的整体加速度变化,类比于图片分类中的RGB三通道,每一个轴向具有相同的意义表达,描述的是一个动作在同一个轴向上所有传感器的加速度变化,基于同一个轴方向的加速度矩阵可以通过卷积操作提取更加具有分辨能力的特征,提高识别准确率.
(2) 数据分析
在理论分析的基础上,对原始数据同一传感器不同轴向数据和不同传感器同一轴向数据进行相关性分析.相关系数绝对值在0.3以下为极弱相关性,该相关系数矩阵极弱相关性比例远远高于多传感器同一轴向各个传感器加速度之间的比例.取本文实验中的测试数据集SKODA的5个三轴传感器计算相关性,如图2所示,在105对数据中,该矩阵极弱相关性系数比例达到18.09%;而同一轴向所有传感器数据共有10对数据,3个单轴向的所有传感器中则有30对数据,在30对数据中极弱相关性系数比例仅有6.67%.这是因为该矩阵中存在大量的同一传感器的三轴之间和不同传感器的不同轴之间的相关性计算.

Fig.2 Correlation coefficient matrix of different axises of accelerometer sensors图2 不同轴向数据相关系数矩阵
2.2.2 基于多位置三轴传感器二维动作图片构建方法
根据多位置三轴传感器动作图片构建原理,本文提出了基于多位置三轴传感器输入构建方法T-2D和基于多位置混合传感器输入构造算法M-2D.
(1) 基于多位置三轴传感器输入构建方法算法T-2D.
图3描述了基于多位置三轴传感器动作图片构建方法T-2D.原始时序数据来自于n个位置三轴传感器,将所有位置传感器的数据根据(x,y,z)三轴方向进行抽取,分别得到全部x轴时序数据、全部y轴时序数据和全部z轴时序数据,并且分别对这3组数据进行归一化处理.根据定义2,分别对3组数据以滑动窗口T和预设覆盖率进行滑动窗口划分,获取时序传感器数据的处理单元,该时间单元的传感器数据为动作图片.
3个动作图片均作为二维卷积神经网络的输入,并用于抽取不同位置传感器的相同轴向数据的时间依赖性和空间依赖性.目前,三轴加速度计是在人体活动识别过程中使用较为普遍的传感器,大多数设备中都包含三轴加速度计,如手环、手机等,因此,本文三轴向传感器使用三轴加速度计.

Fig.3 T-2D based on multi-location 3D accelerometer sensors图3 基于多位置三轴传感器输入构建方法T-2D
(2) 基于多位置混合传感器二维输入构建方法M-2D.
大部分设备内置三轴加速度计的同时,也配有其他的传感器,这些传感器一部分与三轴加速度计一样具有三轴特性的,例如陀螺仪、磁力计等;而有一些就是简单的时序数据,例如心率计.因此,针对这种更为实际且广泛存在的情况,在 T-2D的三轴加速度计输入构造算法的基础上,本文扩充了一种混合传感器数据输入构造算法M-2D,在生成三轴加速度的3个动作图片的同时,对其他传感器数据按序排列,构成第4个动作图片.由于该动作图片在卷积过程中采用一维卷积核而非二维卷积核,仅抽取这些时序数据的时间依赖性.
2.2.3 算法实现
算法1描述了本文提出的基于多位置混合传感器二维输入动作图片构建方法M-2DCNN,由于M- 2DCNN是 T-2DCNN的扩充方法,其不同之处在于增加了算法 1中的第 4行和第 7行.算法 1输入为X={(l1,x1),…,(lN,xN)},其中,每个时刻数据xi=(xi1,yi1,zi1,…,xin,yin,zin,ri1,…,rim),n为三轴传感器数量,xin,yin,zin分别表示三轴数据,rim表示非三轴传感器.该算法返回的结果是对输入数据按照滑动窗口大小进行分割之后的动作图片以及相应的标签.
算法1.基于二维输入动作图片构造方法M-2D.
输入:X={(l1,x1),…,(lN,xN)},ws;
输出:所有分割好的动作图片以及该组动作图片对应标签List((Ximag,Yimag,Zimag,Rimag),t).


2.3 基于二维卷积核的HAR模型
在基于传感器时序数据的活动识别领域,与传统基于统计学特征不同,CNN能够在无需专业领域知识的前提下自动地从原始数据中提取具有高分辨能力的特征,因此,CNN在该领域得到了广泛应用.本文在构建动作图片的基础上,使用卷积神经网络提取特征并分类.
2.3.1 二维卷积网络结构
由于基于多位置混合传感器的二维卷积结构是基于多位置加速度计传感器二维卷积结构的改进方法,图4既可以描述T-2DCNN又可以描述M-2DCNN卷积模型结构,虚线框内为T-2DCNN的二维卷积操作.

Fig.4 M-2DCNN architecture of 2D CNN based on multi-location mixed sensors图4 基于多位置混合传感器的二维卷积模型网络结构M-2DCNN
该网络结构包括输入层在内共11层,其中,卷积层4层,池化层1层,数据转化层2层,全连接层2层,连接分类器 1层.本文中,卷积层和全连接层的 feature map的数量同文献[26],为 C(64)-C(64)-C(64)-C(64)-D(128)-D(128).多层卷积可以提取出更加具有分辨能力的特征,二维卷积核是为了得到原始数据每个轴向的时间和空间的依赖性,再使用一维卷积核降低参数数量.同时增设最大值池化层用来减少特征数量和训练参数,抽象数据轮廓特征.如图4所示,
· 第1层为输入层,从上到下依次为x轴、y轴和z轴数据构成的3个动作图片,其中,T为滑动窗口大小,TriSen_num为三轴加速度计的数量;
· 第2层~第5层均为卷积层,其中,前两层使用二维卷积核,卷积核(过滤器)大小为Kh×Kw,针对每一个动作图片分别进行卷积操作时,提取原始数据时间和空间的依赖性;同时,为了减少参数数量,第4层和第5层采用一维卷积核,卷积核大小为Kh×1;
· 卷积之后进行池化(第6层),本文采用最大值池化可降低由于卷积层参数误差引起的估计均值的偏移;
· 第7层和第8层均为对池化后的矩阵进行重新整理和融合特征,第7层将池化后的矩阵数据沿时间轴方向将特征映射进行拼接,池化层每个轴向数据尺寸为64@hl×wl,则第7层数据尺寸为64@hl×(wl×3);第 8层将数据平铺变成一维向量,作为全连接层的输入(第 9层),两层全连接层抽取更为抽象的特征,实现特征非线性组合,方便连接分类器Softmax(第11层).
如图4所示,当处理非三轴加速度计数据时(虚线外),基于M-2D共生成4个动作图片.在卷积层,针对由非三轴全部使用一维卷积核,其工作同文献[25]卷积操作类似.当传感器中也包含三轴向数据时,将该数据看做 3个通道,依次排列.由于各个卷积层使用的卷积核在时间维度上的尺寸是相同的,因此在第7层串联时,可以与三轴加速度计产生的3个特征映射在时间轴上面进行拼接,此时,第7层特征维度为64@hl×(wl×3+Sen_num),其中,Sen_num为第4张动作图片的传感器数量,之后的操作则与多位置加速度计传感器二维卷积结构的后四层操作相同.
2.3.2 基于参数共享二维卷积网络结构
尽管卷积网络与传统全连接网络相比极大地降低了参数数量,但 M-2DCNN和 T-2DCNN在训练过程中,卷积操作依然产生大量的参数,原因在于每一张动作图片都需要单独的卷积操作.
每一个动作图片的前向传播的卷积过程如图5所示,其中,卷积核大小为,第l层共有个feature maps,第l-1层共有个feature maps.

Fig.5 Computation of 2D CNN kernals图5 二维卷积计算过程
因此,每一个动作图片卷积过程中的第l-1层和第l层之间需要训练的参数见公式(2):

根据图4所示的卷积网络训练模型,每个动作图片的卷积操作过程中模型参数都是独立的,那么 3个动作图片的每层卷积操作中共需要3×Pnum数量的参数,且参数数量是随着卷积核大小以及feature map数量的增加而增加的.
因此,本文在T-2DCNN和M-2DCNN的基础上提出了基于共享卷积层参数的卷积网络模型TS-2DCNN和MS-2DCNN.结合本文中动作图片单一轴向数据的特点以及模型的特点,将利用共享同一组参数对 3组动作图片进行特征提取,即:在图4之中的x_axis,y_axis和z_axis这3个方向使用同一组模型参数取代之前的3组模型参数.可以共用同一组参数的原因在于该卷积操作中训练 3组不同参数与同一组参数都可以达到在各个方向上提取数据特征的目的,因此可在保证识别效果的同时减少训练参数数量.采用表4中的卷积核参数,利用公式(2),对图4的网络结构中卷积层之间的参数数量进行计算,见表1,其中,Input_X表示输入层中X轴的动作图片,Cov2_X表示通过X轴动作图片获取的第2层卷积层,则第2层中Cov2_X与上一层Input_X之间需要训练的参数数量为3×3×64+64=640,以此类推.TS-2DCNN和MS-2DCNN在卷积层能够将参数数量缩减至原来的三分之一.

Table 1 Comparison of the number of the CNN parameters表1 卷积层参数数量对比
2.3.3 模型训练与实现
· 前向传播过程
本文中使用了二维卷积核和一维卷积.结合图5,二维卷积在前向传播过程中的计算见公式(3):

第kl个特征映射的输出为

其中,σ(x)为激活函数.为了加快求导数速度并防止梯度弥散,本文中使用修正线性单元 ReLU(rectified linear unit)作为激活函数,在池化层,即子采样层,选取卷积层子区域内所有神经元的最大值构成池化层神经元.
· 反向传播过程
本文中的神经网络结构中包含两种情况:卷积层连接卷积层和卷积层连接池化层.当l层为卷积层时,第l-1层第特征映射的残差项来自于l层的所有神经元单元,定义⊗为卷积操作,那么第特征映射中坐标为(i,j)的残差项为

在得到残差项计算公式之后,第l-1层的第个特征映射神经元卷积核的梯度公式为

· 模型实现
算法2描述了基于二维卷积动作图片的HAR模型训练过程:分别对每个动作图片进行4次卷积和一次池化操作(第4行、第5行),并将特征映射进行串联拼接和扁平处理(第6行).第7行、第8行对应全连接层和输出层的操作,全连接层的输入为第6行处理之后的一维特征向量.第9行包含对所有层反向传播计算,当参数变化小于阈值或者训练完全部数据时,可以得到该模型的参数.值得注意的是:在实际运算过程中,是将训练数据划分成批次,以矩阵形式进行计算.
算法2.基于二维卷积输入动作图片的HAR模型训练.

算法 3描述 HAR模型预测过程.对于输入无标签数据,使用 M-2DCNN(MS-2DCNN)或者 T-2DCNN(TS-2DCNN)方法对输入进行处理生成相应动作图片,利用训练好的参数预测每个时间窗口数据的标签类别pi.
算法3.HAR模型预测过程.

3 实验与分析
为了验证本文提出的两种二维输入构造算法 T-2DCNN(TS-2DCNN)和 M-2DCNN(MS-2DCNN)的特征提取的有效性,本文在公开数据集上对比了现有典型且特征提取效果较好的两种算法的姿态识别效果,即传统的一维卷积输入 1DCNN[26]和现有的二维卷积输入 2DCNN[30].文献[26,30]中所述的两种卷积方式是目前在相同公开数据集上表现较好且利用不同数据组织形式和卷积方式提取特征的方法,具有一定代表性.此外,本文重心不是测试现有 CNN网络结构以及 CNN和不同分类模型融合的混合模型,而是侧重于对特征的提取效果的验证,因此选取1DCNN和2DCNN两种对比方法.同时,分类模型全部使用softmax进行分类.
3.1 实验数据集描述
在基于传感器信号的人体活动识别领域,根据传感器位置,用于测试的公开数据集通常分为两类:一种是仅用测试者身上的传感器收集的数据;另一种是包含周边环境和物体传感器的数据,例如在抽屉、茶杯之类的物品上面放置传感器,结合身上的传感器一起识别动作.本文中使用的公开数据集属于第 1种类型的数据——OPPORTUNITY[41]数据集和SKODA数据集[42].
· OPPORTUNITY数据集(https://archive.ics.uci.edu/ml/datasets/opportunity+activity+recognition)
OPPORTUNITY数据集收集场景为日常生活,主要活动范围在厨房.该数据集数共有 4名测试者,3种类型传感器分别为:测试者身上传感器(body-worn sensors)、物体传感器(object sensors)和周围环境传感器(ambient sensors).本文利用身上传感器识别测试者的动作,包括7个IMU(inertial measurement unit)、12个三轴加速度传感器,其分布见表2.对于每一个测试者记录了6个文件,其中5个ADL和1个Drill.ADL是测试者在自然状态下的活动记录,包括在椅子上躺着、在房间走动以及准备咖啡、三明治等一些列活动;Drill是对一系列动作的20次重复,包括开关冰箱、开关抽屉等活动.对于活动类别,该数据进行了等级划分,分为运动模式识别(modes of locomotion)和姿态识别(gesture recognition),姿态识别分为高层次活动[43]、中层次活动[25,26]和低层次活动[44].高层次活动为抽象活动,例如咖啡时间、三明治时间等;中层次活动为高层次活动细化,例如咖啡时间中包含开关抽屉等活动;低层次活动为中层次活动的活动单元.本文选择中层次动作作为识别的标签.而运动模式识别中描述运动的状态,如站立、躺、坐等.为了描述实验方便,用GR和 LM来代表姿态识中层次标签识别任务和运动模式标签识别任务,标签描述见表3.在原始数据中存在很多缺失值,因此利用线性插值对缺失数据进行填充.数据采样频率为30HZ.

Table 2 Location of the sensors in OPPORTUNITY dataset表2 OPPORTUNITY数据集传感器位置分布

Table 3 Details of OPPORTUNITY and SKODA表3 OPPORTUNITY 和 SKODA数据集描述
· SKODA数据集(http://www.ife.ee.ethz.ch/research/activity-recognition-datasets.html)
SKODA数据集描述汽车工人对汽车进行操作的场景,该数据集总共包含19个USB传感器,每个传感器包含三轴加速度传感器,其中,在右臂和左臂上分别放置10个和9个传感器,其具体位置见文献[42].在本文中,我们仅适用右臂中的10个传感器进行测试,传感器编号从手腕到大臂依次为{2,27,16,29,1,18,14,24,22, 21},该数据集包含10类标签,具体动作见表3.
3.2 实验设置
· 参数设置
本文实验环境为Google Colaboratory提供的GPU.编程语言为Python 2.0,框架为Keras.本文中实验过程所需参数见表4.为了验证本文所提算法在不同滑动窗口下的性能,因此设计了滑动窗口参数范围,在没有明确指出滑动窗口参数时缺省值为24,即24个时刻数据作为一个数据单元进行训练和预测,该窗口最后一个时刻数据作为该数据单元的标签,窗口覆盖率为 50%.由于 SKODA采样频率较大,为了实现实验参数共享并且方便与OPPORTUNITY数据集对比,对SKODA数据进行降采样,降采样之后频率为32HZ,与OPPORTUNITY数据集采样频率相当.当滑动窗口为24时,OPPORTUNITY数据集和SKODA数据集各类训练样本数量见表3,并对各类标签进行了符号化表示.结合数据传感器类型特点,本文利用 OPPORTUNITY数据集验证 M-2DCNN(MS-2DCNN)识别效果,利用SKODA验证T-2DCNN(TS-2DCNN)识别效果.

Table 4 Experiment parameters表4 实验参数
同时,本文从传感器数量角度对提出的卷积网络模型以及共享参数模型的特征抽取效果进行了验证,对于OPPORTUNITY数据集,添加部分IMU传感器并按照传感器在人体分布情况逐次添加传感器,总共有4组传感器,默认缺省值为最后一组包含16类传感器.类似地,对于SKODA数据集,按照传感器分布位置区域进行添加,共有3组:第1组包含小臂传感器3类,第2组包含大小臂传感器8类,最后一组包含10类,默认为最后一组.
在使用OPPORTUNITY和SKODA数据集的文献中,由于各种参数设置不同以及衡量标准不同,无法统一衡量,因此本文结合参考文献中的方法,统一了输入数据参数进行对比实验.结合第 2.3节中所提出的卷积框架,卷积层和池化层的卷积核参数见表4.对于第2层和第3层卷积层,该结构在梯度下降过程中学习速率为0.01.本文中用于对比实验的一维卷积 1DCNN输入构造和网络结构来自文献[26],为了使实验对比结果更加令人信服,将原文献中前两个卷积层的卷积核定义3×1,网络架构与原文相同.二维卷积2DCNN输入构造来自文献[30],还原了文献中的二维卷积输入构造和卷积网络结构.
· 评价指标
本文使用F1值作为识别效果的评价指标,F1同时受到精确率和召回率的影响,计算公式为

其中,Pi和Ri分别为第i类的精确率和召回率,wi为该类样本占所有样本比例,目的是解决类间样本数量不平衡问题.
· 训练集和测试集选取
对于SKODA数据集,训练集和测试集比例为4:1.对于OPPORTUNITY数据集,结合文献中的实验源码,训练数据包括测试者1的所有ADL和Drill、测试者2和测试者3的ADL1,ADL2,ADL3和Drill,测试数据为测试者2和测试者3的ADL4和ADL5.所有数据均没有进行数据类间均衡.在OPPORTUNITY数据集中,尽管IMU传感器数据中包含多维度数据,我们仅仅抽取其中的三轴加速度与ACC的三轴加速度结合,按照三轴方向构造3组二维输入,IMU传感器剩余数据包括三轴陀螺仪和磁力器均作为一维卷积输入.
3.3 实验结果与分析
·F1对比分析
表5和表6分别描述了本文提出的两种输入构造法以及经过优化参数的网络在OPPORTUNITY数据集和SKODA数据集上面的表现.对于OPPORTUNITY数据中GR标签和LM标签,均分为两种情况:一种是包含Null class类,一种是不包含Null class类.

Table 5 F1-value on OPPORTUNITY dataset表5 OPPORTUNITY数据集F1值

Table 6 F1-value on SKODA dataset表6 SKODA数据集F1值
在表5中,加粗数字表示同等实验参数和环境下最高F1值.通过表5亦可知:滑动窗口取48时,GR和 GR(null)的F1值与窗口为24时相比均有降低.无论窗口取24还是48,基于本文提出的输入构造方法的卷积神经网络M-2DCNN和MS-2DCNN与现有方法1DCNN和2DCNN的F1值相比,在绝大多数情况下表现效果良好.这是因为 OPPORTUNITY传感器遍布全身且动作具有连续性,本文所述动作图片构建方法能够有效地卷积出单一轴方向上的数据特征,其时空特征表现良好.在默认参数情况下,针对4种分类任务,利用2DCNN实现GR分类时,MS-2DCNN的F1提升值最大为6.68%,M-2DCNN次之为6.07%;在利用1DCNN实现GR(null)时,F1提升值最小,为0.38%.而在窗口取48时,LM(null)分类效果中,本文方法略占劣势,与最高值相比经降低了1.57%.其原因在于1DCNN和 2DCNN更依赖于时序数据的时间特征,而本文方法需要较多的训练样本.在这 4种方法中,LM识别F1值总体上比GR的高.这是因为LM识别种类少,包括Null class在内共5种类别,而GR包含Null class在内共有18种类别,相比于LM,GR类间差异会相对不明显,因此整体F1值低于LM.在GR中,由于Null class数量相对于其他类别数据数量明显增多,占GR样本总数的71.9%,因此包含Null class的GR的识别效果要好于不包含Null class的GR.在LM(null)识别任务中,Null class仅占总样本数17.2%,Null class的加入会造成整体F1值降低.
表6描述了本文算法在SKODA数据集上的表现,由表可知:T-2DCNN和TS-2DCNN表现良好,在默认参数情况下,T-2DCNN的F1高达95.18%,与相同条件下使用朴素2DCNN0相比提高了1.09%.该数量级F1值提升非常有意义,说明本文提出的二维卷积输入构建方法可以更高层次地抽取传感器数据之间的空间依赖性;同样与1DCNN相比,比单纯的抽取时间依赖性提高了0.27%.当超过采样频率之后即窗口取 48时,在默认传感器数量情况下,整体F1值有所下降.其原因在于训练样本随着窗口增加而减少,训练样本不足导致.同时, T-2DCNN和TS-2DCNN依然保持优势.这是因为样本不足时,1DCNN时间特征不足,2DCNN空间特征表达没有 T-2DCNN和TS-2DCNN明显.
· 传感器数量与F1关系分析
为了更好地说明本文提出的输入组织形式可以有效地抽取数据的空间依赖特征和时间依赖特征,并在不同传感器数量以及输入数据窗口的情况下保持整体的平均识别效果,本节从传感器数量角度出发,采用表4中传感器数量参数,对基于4种卷积网络的识别效果进行验证.OPPORTUNITY数据集和SKODA数据集传感器添加方式均是将不同区域的传感器按照逐一区域添加.
图6描述了OPPORTUNITY中GR和GR(null)F1传感器数量之间的关系.随着传感器数量增加,不同滑动窗口大小的F1趋势不同,甚至出现反复现象.由此可以说明传感器数量越多,其计算效果不一定越好.原因在于识别效果和传感器空间分布以及滑动窗口的变化有关,同时,传感器较多容易引起过拟合,如ws=48时 GR中M-2DCNN,1DCNN和2DCNN.从整体上讲,GR中的M-2DCNN和MS-2DCNN可以有效地兼顾数据时间和空间的特征,在传感器数量较少时,能够有从单一轴向动作图片中挖掘时间依赖性;在传感器数量较多时,本文描述的动作图片可以挖掘同一轴向上的不同位置传感器的空间依赖性.相对于1DCNN和2DCNN的F1提升较大.但在 GR(null)中,虽然F1值也有提升,但提升没有 GR中明显.其原因在于 null类在训练过程中所占比例较高.随着传感器数量增多,F1值先下降后上升,这是因为新加入的传感器属性能够更好地表达特征,降低了之前加入传感器数造成的数据干扰.

Fig.6 F1-values of GR with different number of sensors on OPPORTUNITY图6 OPPORTUNITY数据集不同数量传感器的GR任务的F1值
图7描述了OPPORTUNITY中LM和LM(null)中的动作识别效果随着传感器数量变化的的趋势.在LM中,M-2DCNN和MS-2DCNN在窗口为24时的F1值整体上随着传感器数量增加而提高,在窗口为48时小范围波动,而其他两种方法在窗口为24时整体低于M-2DCNN和MS-2DCNN并呈现下降趋势.这说明M-2DCNN和MS-2DCNN在小窗口时可以有效地从少量多个位置、多种传感器中抽取空间特征.当 LM(null)分类任务窗口为48时,1DCNN识别效果较为稳定,这说明1DCNN能够在大窗口传感器数据中得到时间特征.而2DCNN的F1值范围波动较大,M-2DCNN和MS-2DCNN也有小范围波动,说明在该窗口下数据空间特征受传感器分布影响较大,不能够在逐一区域添加传感器过程中得到稳定的时空特征.当加入null class之后,4种方法对于特征学习能力下降,这是因为在LM标签中null class学习样本较少,增大了误差.
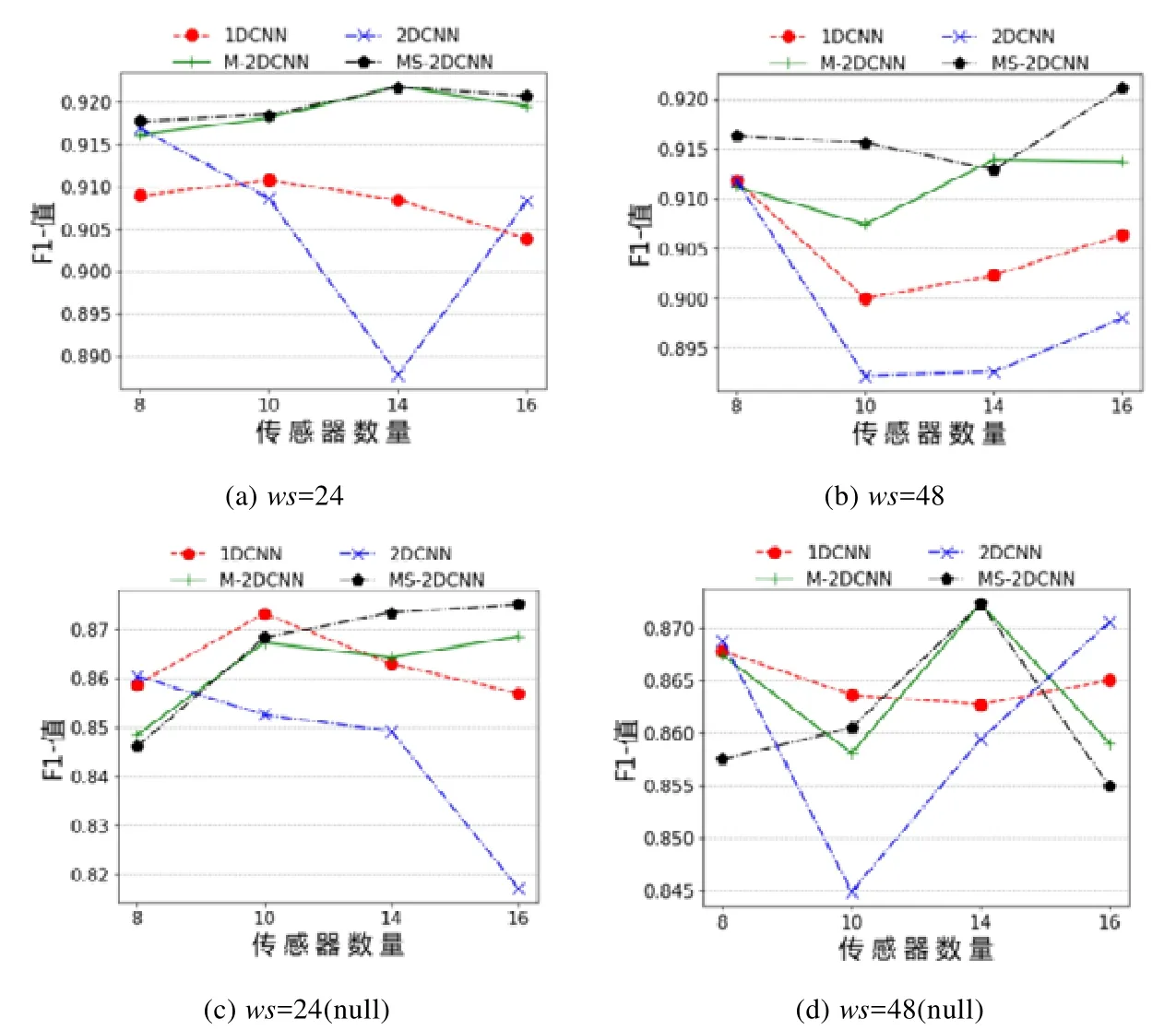
Fig.7 F1-values of LM with different number of sensors on OPPORTUNITY图7 OPPORTUNITY数据集不同数量传感器的LM任务的F1值
图8描述了SKODA数据集上不同滑动窗口情况下F1随着传感器数量变化.

Fig.8 F1-values of recognition with different number of sensors on SKODA图8 SKODA数据集不同数量传感器的活动识别F1值
随着传感器数量的增加,T-2DCNN,TS-2DCNN呈现上升趋势.这是因为动作图片构建需要一定数量的传感器,在不受噪音传感器干预的情况下,传感器数量越多,则在每一个轴向的动作图片中所提取动作的空间依赖性越强.在窗口为48时,1DCNN和2DCNN呈现了先上升后下降的趋势,其原因是在该参数情况下,训练数据较少,且传感器数量较多,产生了过拟合现象.同时可观测到,TS-2DCNN和T-2DCNN在传感器数量为3时F1值很低.这是由于该数量传感器构成的3个动作图片的空间特征分辨力不足,但随着传感器数量增多,F1值逐渐提高.
为了更加清晰地描述基于这4种方法的在各种传感器分布情况下的卷积网络效果,我们对图6~图8获取最高F1值的方法出现的次数进行了统计,见表7和表8.该统计的目的在于说明这4种方法在不具体指出传感器位置分布的情况下的总体识别效果,即该算法的通用性,而不针对于某一种情况下作比较.在 OPPORTUNITY上,M-2DCNN和MS-2DCNN获取最高F1值的频次较高;SKODA数据集上,本文所述方法频次最高.因此说明我们提出的方法对实验参数和数据集的变化具有较好的的适应能力,可以有效地从多位置传感器组合中抽取有效的特征.同时,通过图6~图8也可以看出:基于共享参数的卷积网络MS-2DCNN和TS-2DCNN与M-2DCNN和T-2DCNN达到同等效果,即使F1在某些情况下略有降低,但整体好于2DCNN和1DCNN.

Table 7 Frequency of the largestF1-value on OPPORTUNITY表7 OPPORTUNITY数据集最高F1值次数

Table 8 Frequency of the largest F1-value on SKODA表8 SKODA数据集最高F1值次数
· 相同类别F1值对比分析
本文未采用混淆矩阵对每一类的识别效果进行分析,而是纵向对比了每一类采用不同方法的F1差值.可以更清晰和直观地观测到不同的输入构造和卷积对每一类识别效果的影响.图9描述了 OPPORTUNITY中M-2DCNN和MS-2DCNN每个类别F1值与待对比方法法F1值差异,横坐标为类别标签符号,其符号与类别之间对应关系见表3,纵坐标为不同方法F1值之间的差值.

Fig.9 F1-values’ difference of GR in different CNN architectures on OPPORTUNITY (ws=24)图9 OPPORTUNITY数据集GR各类别不同输入构造方法F1值差异(ws=24)
在GR的17类动作中,M-2DCNN在11个动作中的识别效果均优于其他两种方法,完全低于其他两种方法的有4类动作(G3,G6,G10和G17).在MS-2DCNN中,不存在完全低于其他两种方法的动作标签,对于类间差异较小的动作,如开关不同的抽屉和门,本文方法能够有效地进行区分,同时说明了OPPORTUNITY数据集中传感器分布使得同一轴向的动作图片数据特征表达较好,即使共享卷积参数,依然在各类别的识别过程中表现良好.但对于G17(clean table)的动作识别效果不如2DCNN,这是因为G17不同于其他动作,该动作持续时间长,因此在同一轴向小窗口数据上的空间依赖性表达不如2DCNN明显.
图10描述了 SKODA数据集中,默认情况下使用 T-2DCNN和 TS-2DCNN与待对比方法F1值的差异.T-2DCNN在9种动作中的识别效果均优于其他两种方法;TS-2DCNN可以较好地识别出8种动作;而1DCNN在第6类动作识别效果略好,这是因为S6动作样本数量较少,且该动作完全由左臂完成,文中所使用SKODA传感器均佩戴在右臂,在完成动作时右臂动作幅度不大,使用一维卷积核时能够完整地抽取传感器各个轴向的时间特征,该动作空间特征不明显,出现了本文方法识别效果不如1DCNN,但却优于2DCNN的现象.

Fig.10 F1-Values’ difference in different CNN architectures on SKODA (ws=24)图10 SKODA数据集各类别不同输入构造方法F1值差异(ws=24)
4 结 论
本文针对现有二维卷积输入构建方法中对多位置三轴向传感器相同轴向数据之间的空间依赖性挖掘不足的现象进行研究并提出解决方案.本文提出了 T-2DCNN和 M-2DCNN两种网络结构,其核心是利用 T-2D和M-2D构建方法将多个位置的三轴加速度计的数据划分成 3张独立的动作图片用于二维卷积核的输入,同时,结合非三轴传感器构建一维卷积核输入的动作图片,融合多张动作图片所得的特征映射来抽取高层次特征,实现了以本文所提方案为特征抽取方法的HAR模型.同时,提出了基于共享参数TS-2DCNN和MS-2DCNN的网络结构,在保证识别准确率的同时,减少了卷积层训练参数数量,并通过设置不同实验参数验证了本文所述方法的识别效果.在未来研究工作中,将结合项目研究组采集的数据对真实环境建模和动作识别.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
火箭推进(2020年6期)2021-01-05
电子制作(2019年11期)2019-07-04
奥秘(创新大赛)(2018年8期)2018-11-29
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
北京航空航天大学学报(2018年1期)2018-04-20
商情(2017年38期)2017-11-28
北京航空航天大学学报(2017年4期)2017-11-23
