
CNN图像标题生成
2019-04-22 07:53成红红梁新彦钱宇华
西安电子科技大学学报 2019年2期
李 勇,成红红,梁新彦,郭 倩,钱宇华
(1.山西大学 大数据科学与产业研究院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3.山西大学 计算机与信息技术学院,山西 太原 030006)
图像标题生成任务的挑战在于学习到不同模态数据之间的关联关系。该任务需要识别出图像中所包含的对象(包括人物、动物甚至背景等),并学习到该图像对应标题语句中的实体和图像中对象两者之间的相关性。针对上述问题,研究人员提出了多种模型,这些模型普遍遵循编码器-解码器框架。在编码阶段,常用递归神经网络(Recurrent Neural Network, RNN)来编码标题信息,由于RNN的“串行特性”导致其在训练和推理阶段耗费较长时间,而卷积神经网络(Convolutional Neural Network, CNN)模型所具有的“并行特性”则使其可以更高效地完成模型的训练和推理。为了提高模型在文本信息编码时的效率,笔者采用CNN代替RNN编码文本数据,构建了一个完全基于CNN的图像标题生成模型。相比基于RNN编码文本数据信息的模型,该模型在不损失结果质量的前提下,提高了模型的训练和推理效率。
图像标题生成是处理图像和文本数据的典型的多模态任务,且深度学习在图像和自然语言处理领域都取得了显著的效果,各种基于深度学习来解决该问题的模型被不断提出。2015年文献[1]提出结合GoogLeNet[2]和长短期记忆网络(Long Short Term Memory Networks, LSTMN)的模型,该模型利用两个网络分别处理图像和文本数据,并很好地解决了单词之间的长期语义依赖问题。随后文献[3]提出另一个结合CNN和RNN的模型,首先利用区域卷积神经网络(Region Convolutional Neural Network,RCNN)来识别得到图像中的实体,并利用双向递归神经网络(Bidirectional Recurrent Neural Network,BRNN)来表示原始的文本数据,将两种数据输入到完整模型中学习到不同模态数据之间的关联性。许强等[4]则提出一种有效的目标识别算法,能够准确地学习到图像中包含的目标信息。文献[5]通过引入“哨兵”增加了模型的自适应性,让模型能够更好地关注于图像中所包含的重要信息。文献[6]提出“骨架关键词”(Skeleton Key,SK)模型,首先通过预训练的“骨架LSTM”(Skeleton-LSTM)网络针对特定的图像生成句子的骨架信息,包括图像中的目标、物体等,接着用“属性LSTM”(Attribute LSTM)网络学习得出相应目标、物体的属性信息,将两部分信息融合从而得到精进的图像描述。另一方面,文献[7]提出的基于深度学习的新模型能够更为准确地把握到图像中所含对象的表情信息,这对于提高生成的标题质量也是非常重要的。文献[8]则给模型中加入了关系推理的功能,进一步提高了生成图像标题的质量。文献[9]将强化学习引入到该领域,通过在模型中加入不同的学习机制来改善实验效果。

图1 图像标题生成完整模型图
笔者则提出了一种完全基于CNN的图像标题生成模型。该模型抛弃了普遍采用RNN网络处理文本信息的模式,转而采用不同的CNN模型来同时处理两个模态的数据,并通过实验很好的说明了该模型针对此问题的有效性,而且也证明了在不损失实验结果质量的情况下,该模型有更快的收敛速度。正是由于图像标题生成是一个极具挑战性的问题,越来越多的学者和研究人员也不断地参与到这个问题的研究中。
1 文中的模型
文中构建的完全基于CNN的模型也遵循编码器-解码器(Encoder-Decoder)这一基本框架,模型完整的结构如图1所示。
图中的符号“N×”代表有多个一样的重叠的运算单元。
1.1 图像特征提取
基于CNN的深度学习网络已经在图像数据的各项任务中都取得了显著成绩,所以文中采用牛津大学视觉组提出的VGG-Net网络来处理图像数据,该网络在ImageNet数据集上得到充分的训练,其结构示意图如图2所示。

图2 文中采用的特征提取模型
利用该网络来处理图像数据,表示如下:
v=Wm[Cθc(Ib)]+bm,
(1)
其中,Ib为需要处理的图像,C为图像经过的深度神经网络,θc则表示该网络所对应的所有参数。假设通过C网络提取到的图像特征维度为df,则变换矩阵Wm∈Rh×df可以将网络学习到的特征转换到h维,bm∈Rh,为偏置向量,所以可得到最终的图像特征v∈Rh。
1.2 文本特征提取
1.2.1 文本的嵌入表示
为了对文本数据进行特征提取,首先将单词通过嵌入表示为带有语义信息的向量。对于长度为m的句子而言x=x1,x2,…,xm,则xi,i∈[1,m]为句子中的第i个单词,接着将单词xi进行嵌入运算,可得到一个维的向量。此时得到了该句子对应的词向量矩阵D∈Rm×f,Di表示矩阵中的一行。文中采用一维卷积的CNN网络对词向量矩阵进行卷积运算来提取文本特征。但是考虑到CNN天然具有“旋转不变性”这一特性,需要在词向量中编码单词的位置信息来保留不同词语间的依赖关系。假设有一个长度为m的句子x=x1,x2,…,xm,文中通过sin和cos函数来编码不同单词的位置信息,
(2)
(3)
其中,s代表句子中单词所在的位置,j为单词嵌入的维度,dm的默认值为512,该函数的波长的取值范围为[2π,10 000×2π]。假设该函数能够较好地学习到句子中单词间的相关关系,对于任意一个固定的偏移量k而言,有Ps能够表示成Ps的线性函数。将编码到的单词位置信息表示为p=p1,p2,…,pm,并加入到原始的词向量矩阵中,即D+P=[d1+p1,d2+p2,…,dm+pm],用E=D+P表示最终的词向量矩阵。
1.2.2 文本的卷积特征运算
对于词向量矩阵E的第i行而言,Ei,i∈[1,m]包含了每个单词的词向量信息和该单词在句子中的位置信息,接下来采用Yoon Kim等人提出的文本卷积神经网络(Text-CNN,图3)对词向量矩阵进行运算,提取该数据所对应的特征:

图3 文本卷积神经网络运算过程
由上可知,词向量矩阵E=(e1,e2,…,ei),其中ei∈Rf,i∈[1,m],f为词向量的维度。为了不破坏每个单词的表示信息,采用的卷积核大小为W∈Rk×h,k代表参与卷积运算的单词个数,即参与卷积运算的单词为e(i∶i+k-1),运算方式为
ui=f(W·ei∶(i+k-1)+b) ,
(4)
其中,b代表偏置项,f则代表该Text-CNN模型所学习得到的非线性函数。为了能获取到更充分的文本特征信息,采用不同大小的卷积核对词向量矩阵E中e1∶k,e2∶k+1,…,e(n-h+1)∶n进行卷积运算,得到相应的特征图(Feature Map),c=[c1,c2,…,cn-h+1]∈Rn-h+1。由于在文本数据的预处理阶段采用“0”元素进行填充,为了避免卷积运算得到的特征图过于稀疏,文中直接将特征图c平铺拼接,作为最后的输出,来保证该特征保留下更多的文本信息。
1.3 图像和文本特征的结合
下面简要介绍论文算法的流程来说明两个模态数据的特征的融合。

输入:原始图像Img和该图像对应的标题句子S={S1,S2,…,Sn}1:将原始图像Img通过预训练的VGG16/VGG19网络,提取得到该图像的特征v。2:将原始的图像标题句子S经过Embedding和Position Encoding运算,得到新的句子表示为E={e1,e2,…,em},m为句子的长度,也是句子中所含单词的个数。3:利用句子E构建训练数据Et以及对应的标签Et,填充值pm,m∈[1,n-1],默认为“0”。Ete1,p1,p2,…,pn-1e1,e2,p1,…,pn-2…e1,e2,e3,…,en-1,p1ìîíïïïïïï,El=e2e3…emìîíïïïïïï,将句子中对应的下一个词看作标签信息。4:把数据送入Text-CNN网络进行运算,将得到每个训练样本对应的特征表示为ci,i∈[1,m],m为训练数据的样本数,接着再与图像的特征进行拼接操作,如下所示:Et=v,c1v,c2…v,cm-1ìîíïïïïïï,对应的标签数据为El=e2e3…emìîíïïïïïï,将该数据输入到模型的融合层,继续运算。
该数据经过网络运算后,将最后模型的输出结果与训练数据的真实标签计算交叉熵损失,并通过反向传播算法来不断调整网络权重,最终学习得到一个较优的模型。
2 数据集,实验设置和展示
数据集:文中采用两个公开的数据集Flickr8k和Flickr30k。两个数据集分别包含8 000和30 000张图,每张图片均通过Amazon Mechanical Turk进行人工标注得到5个标题句子,数据预处理阶段对数据集按表中所示进行划分。
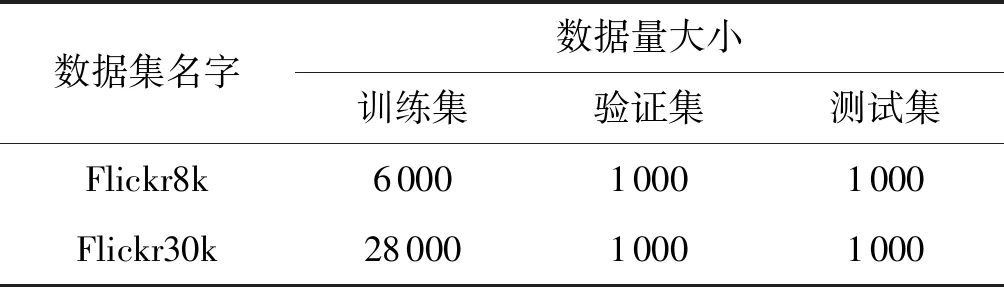
表1 数据集划分比例展示
参数设置:设定图像特征为4 096维,单词嵌入词向量为256维。而Text-CNN网络则采用2×256,3×256和4×256三个不同大小的卷积核对嵌入矩阵进行运算,其中卷积核的通道数也为256,经过卷积运算后能得到3个不同大小的特征图,为了保证信息的完整性,直接将得到的3个特征图进行拉伸后拼接作为最后输出的文本数据特征。
优化器:采用的优化器是RMSprop,学习率为0.000 5,数据的批大小为64。其中RMSprop通过公式r←ρr+(1-ρ)g⊙g缓解了Adagrad算法学习率下降较快的问题,能更好地指导模型学习。
实验评价:采用BLEU和CIDEr两个指标来衡量图像生成标题的质量优劣。
BLEU:是一种文本评估算法,计算方式如下,此处用K表示,
(5)
其中,模型生成的标题为ci∈C,数据集中真实的图像标题为Si={si1,si2,…,sim},m为参考caption的数量,S为全部Si构成的集合,hk(ci)为某个n-gram出现在句子ci中的次数。
CIDEr:是一种度量待评测语句与其他人工描述句之间的相似性的方法。首先将n-gram在参考句中的出现频率进行编码,n-gram在数据集中出现的越频繁,其权重就越小,通过TF-IDF计算每个n-gram的权重,将句子表示为向量,并利用余弦距离来计算向量之间的相似性,用E表示,
(6)
其中,gn(cij)和gn(sij)是TF-IDF向量表示。
将文中的方法与另外两个经典方法进行了对比,可以看到在两个评价指标上都有一定程度的提升,也说明文中模型能够更好地学习到不同模态数据间的相关性。两个评价指标均是通过将模型生成结果与真实结果进行相似性比较,从而指导模型生成更贴近和符合人类自然语言的标题句子。而Flickr30k数据集上的提升则更为明显,是因为该数据集与Flickr8k相比有更丰富的数据,能让模型得到更充分的训练,从而达到更好的效果。

表2 数据集评价指标值

图4 损失值和训练批次之间的关系
(1)实验损失曲线,损失值随着模型的迭代次数的增加在不断减少。
图4中,淡色的曲线为每次迭代过程中每个小批次数据计算得到的损失值,黑色的曲线则是通过原始的损失值拟合得到的损失变化曲线,展示了实验随着训练批次的增加,模型的损失值也在不断地减小且趋于平稳,说明该模型是收敛的,模型也得到了充分的训练。
(2)图文结果的展示如图5所示。

(a) 生成结果:一只小狗在草地上奔跑真实标签:一只小狗在绿色的草地上奔驰

(b) 生成结果:一个男人和一个小孩站在广场前真实标签:一个男人在一个空旷的地方和小男孩对话

(c) 生成结果:一条黑色的狗正跳入水中真实标签:一条湿漉漉的狗正跃入湖中

(d) 生成结果:一个人背着书包站在石头上真实标签:一个女子坐在石头上,眺望远方
从上述实验得出的结果和真实数据标签相比可以看出,该模型可以高质量地生成针对特定图像的标题句子,能够较为准确地识别出图像中的人物和物体,以及图像中实体间的动作和所描述的场景。但是该模型还存在场景识别较为单一的问题,复杂的场景还没法达到较为准确的结果。同时根据实验结果,观察到该模型对于图像中的实体具有的动作,如跳和跑,站和坐等姿态,估计并不准确,需要进一步的提高。
3 结束语
笔者通过利用CNN网络来取代RNN对于文本数据进行信息编码,构建了一个完全基于CNN的图像标题生成模型,而且在不损失结果质量的前提下,得益于CNN运算的并行特性,能很好地在GPU上并行运算,显著地提升了模型训练和推理所耗费的时间。但是该模型对于给定图像的内容实体的目标数量统计、空间位置关系、人体姿态等信息把握不够准确,接下来的工作则需要增加模型对于相应辅助信息的学习,进一步改善模型对于图像场景的理解深度,提升实验效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学小灵通(1-2年级)(2020年6期)2020-06-24
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
高中生学习·高三版(2016年9期)2016-05-14
