
基于关键字密度的XML关键字检索*
2019-05-20 06:56覃遵跃徐洪智
软件学报 2019年4期
覃遵跃,汤 庸,徐洪智,黄 云
1(中山大学 数据科学与计算机学院,广东 广州 510006)
2(吉首大学 软件学院,湖南 张家界 427000)
3(华南师范大学 计算机学院,广东 广州 510631)
1 引 言
XML是互联网中信息表示和交换的事实标准,在电子政务、电子商务、金融、出版、科学数据和各种资源数字化等方面扮演着极其重要的角色.利用关键字检索 XML数据,用户不需要学习复杂的查询语言,并且也无需预先了解XML数据的结构知识,因此研究XML关键字检索是非常迫切和必要的.
XML关键字检索只需要返回XML树片段,该树片段包含了匹配的所有关键字[1,2].文献[3-8]详细介绍了返回 XML树片段的检索方式,通常,这种检索方式的结果包含了每个关键字实例的一棵最小连通树,该树的根节点是包含了所有关键字实例的最低公共祖先LCA(lowest common ancestor).LCA是针对XML关键字检索的所有可能情况,有些LCA可能不符合用户的查询意图.为了返回与用户意图密切的LCA,文献[9-13]采用过滤方法抛弃了与用户意图不相关的 LCA,但这些方法经常过滤掉了用户想要的 LCA,具有低的准确率和召回率[14].针对过滤语义不足的问题,文献[6,15,16]设计了Top-k算法,对查询结果LCA进行排名并优先选择Top-K个结果.对于XML数据进行关键字检索也可以通过TF*IDF和PageRank进行排名[1,9,14,17]以提高用户的检索兴趣.
虽然对 XML关键字检索研究取得了很多研究成果,但仍然存在一些问题.首先是检索质量问题,例如通过过滤语义SLCA[11,18,19]和ELCA[13,20]来产生LCA子集,然后对子集进行排名,这种方法存在丢失相关查询结果的问题.第二是查询效率问题,在检索关键字较多时将返回大量的LCA结果,处理LCA排名主要基于关键字倒排表的规模[8,14],因此,当数据集规模增大时,算法不能很好地满足应用要求.文献[21]提出了一种通用的自上而下(top-down)的处理策略来发现 LCA/SLCA/ELCA 语义的共同祖先重复(CAR)和访问无用节点(VUN)问题,但不能对LCA节点进行排名.
针对上面存在的两个问题,本文提出了对LCA直接进行排名的TopLCA-K方法,该方法综合考虑了查询关键字数量、边的构成和路径等情况,然后计算出每个LCA的大小.
本文主要贡献包括:
(1) 提出了LCA与用户查询意图相关的两个规则.用户查询意图与查询关键字实例到LCA边的数量成反比,以及用户查询意图与LCA子树路径的数量成反比.
(2) 建立了计算LCA分数的公式.根据前面提出的两个规则,利用边密度和路径密度作为衡量LCA值的方法.
(3) 设计了计算LCA值的算法TopLCA-K.为了避免丢失部分满足用户需要的查询结果,提出对所有LCA进行打分.为了提高查询效率,提出了中心位置索引CI.根据LCA分数进行排名,把最可能满足用户查询意图的LCA首先展示给用户.
(4) 利用实际的不同规模数据集对提出的算法进行了测试,实验验证了在查询关键字个数不同的情况下,本文提出的算法具有更高的准确率和召回率,并且返回的K个结果更符合用户需要.
本文第2节介绍研究背景和相关工作.第3节介绍度量LCA大小的概念和方法以及TopLCA-K算法.第4节显示本文提出的算法的实验结果,以及与其他方法的比较情况.第 5节总结本文的工作,并给出未来的研究方向.
2 研究背景与相关概念
2.1 研究背景
因为XML半结构化数据不像关系数据库那样具有严格的模式,因此对这种类型的数据进行关键字检索是一项复杂的任务.很多文献针对XML关键字检索提出了各种类型的查询语义,可以分为基于树模型和基于图模型的查询语义.在基于树模型的关键字查询语义中,LCA 是所有其他语义的基础,其中,SLCA[11]、ELCA[1,13]、MLCA[10]、XSearch[9]、VLCA[12]、TLCA[22]等是基于 LCA 的代表性语义.基于图模型的查询语义主要借鉴关系数据库的关键字查询思想[23],即对于给定的一组查询关键字,返回CN(connected network).
SLCA[11]过滤掉了后裔LCA;在ELCA[1,13]语义定义中,v是一个LCA节点,如果以v为根的子树中过滤掉所有其他以LCA节点为根的子树后,v仍然包含所有关键字,则v是一个ELCA节点;MLCA[10]语义去掉包含了关键字标签相同但路径不同的LCA;VLCA[12]和XSearch[9]在LCA的基础上,将不同关键字到LCA路径上存在的同名节点的结果排除在外.基于树模型的查询语义除了LCA之外,还有MCT(minimal cost tree)语义[15].
基于图模型的查询语义把 XML数据建模为一个图,返回 CN(connected network)[24]作为关键字查询结果.每个CN都是文档树D的一个无环子图T,并且T包含查询Q中的所有关键字至少1次,而T的任何真子图都不包含Q中的所有关键字.基于CN的一种典型查询语义是MCN(meaning connected network)[19],该查询语义找出给定关键字之间有意义的关系.XKeyword[24]和BLINKs[25]也是基于图的查询语义.
已经提出的针对XML关键字查询语义,或者基于LCA进行过滤,例如SLCA、ELCA等,或者基于CN进行过滤,例如 MCN.虽然这些过滤语义可以返回更加贴近用户意图的查询结果,但用户查询往往很复杂,因此这些过滤的查询语义也显示出了低召回率问题[14].为了弥补过滤查询语义存在低召回率问题,对符合条件的查询结果进行排名是一种有效的解决办法.对查询结果进行排名,可以把与用户查询意图更相关的查询结果放在前面.已有排名方法分为两种,一种是根据 XML结构和语义上的相关性进行排名[1,6,9,14,15,26,27],另一种是按照某种统计度量办法对LCA节点进行评分排名[1,6,9,14,15,28-30].例如XRank[1]对PageRank算法进行了改进而适用于XML关键字查询结果排名;XSearch[9]对 TF*IDF函数进行改进使之适用于 XML文档树结构的关键字查询排名;XReal[4]的排序思想基于TF*IDF,考虑的排序因素包括关键字频率、关键字出现顺序、关键字在查询结果中的位置以及结果的大小等.Termehchy和 Winslett[14]通过采用交互信息来计算结果相干性以进行排名;Nguyen和 Cao[31]使用交互信息来比较结果,然后在查询结果之间定义了一个支配关系来进行排名;SAIL[15]定义了最小代价树,并且通过使用链接来分析关键字对之间的相关性,最后返回Top-k查询结果;XBridge[28]在使用打分函数时考虑了查询结果的结构,然后对查询结果进行分类;文献[25]基于图模型数据,提出了一种结合结构大小、PageRank以及TF*IDF这3种排序思想的混合排名机制.文献[26]提出了一个新的对XML数据的关键字查询进行排名和过滤语义的方法XReason语义,该方法基于模式推理,模式记录了查询匹配的结构和语义特征.为了利用模式进行推理,提出了模式之间的同态关系.该方法的优点是从整体的角度考虑查询匹配,避免了以前语义利用局部XML子树比较查询匹配存在的缺陷.
2.2 相关概念
一般情况下,把XML文档建模为一棵有序标签树,树中的节点代表XML元素或者属性,每个节点有一个id号(节点唯一的编号)、一个标签(元素或者属性),有的节点是一个值(对应元素文本值或者属性值).
定义1(XML有向树).一个XML文档建模为一棵带标签的有向树T(V,E,r),其中,V表示节点的集合,E表示边的集合,r是树的根节点.
定义2(关键字匹配集合KMS).对给定的XML有向树T(V,E,r)和查询关键字k,用KMS(k)表示T中所有与关键字k匹配的节点集合,KMS(k)={v|v∈V,k=tag(v)或者k=value(v)}.其中,tag(v)表示节点v的标签,value(v)表示节点v的值.
例如图1中,KMS(A)={4,10,15},KMS(B)={6,11,16},KMS(C)={8,12,17}.
定义3(节点集N的最低公共祖先LCA(lowest common ancestor)).给定XML有向树T(V,E,r)和m个元素节点集N={vi|vi∈V,1≤i≤m},节点v=LCA(N)当且仅当满足以下条件:
(1) 任意的vi∈N,v是vi的祖先节点,v∈V,1≤i≤m.
(2) 不存在节点u(∈V),u是v的后裔,并且u是任意vi(∈N)的祖先节点.
定义4(LCA集合LCASet(T,Q)).针对XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},LCA集合LCASet(T,Q)={v|v∈V且v=LCA(k[1,i],k[2,i],...,k[m,i])},k[1,i]∈KMS(k1),k[2,i]∈KMS(k2),…,k[m,i]∈KMS(km).
例如图 1中,查询Q={A,B,C},LCASet(T,Q)={1,2,9,14},因为节点 1=LCA({4,11,17})(其中的一种情况),节点2=LCA({4,6,8}),节点9=LCA({10,11,12}).
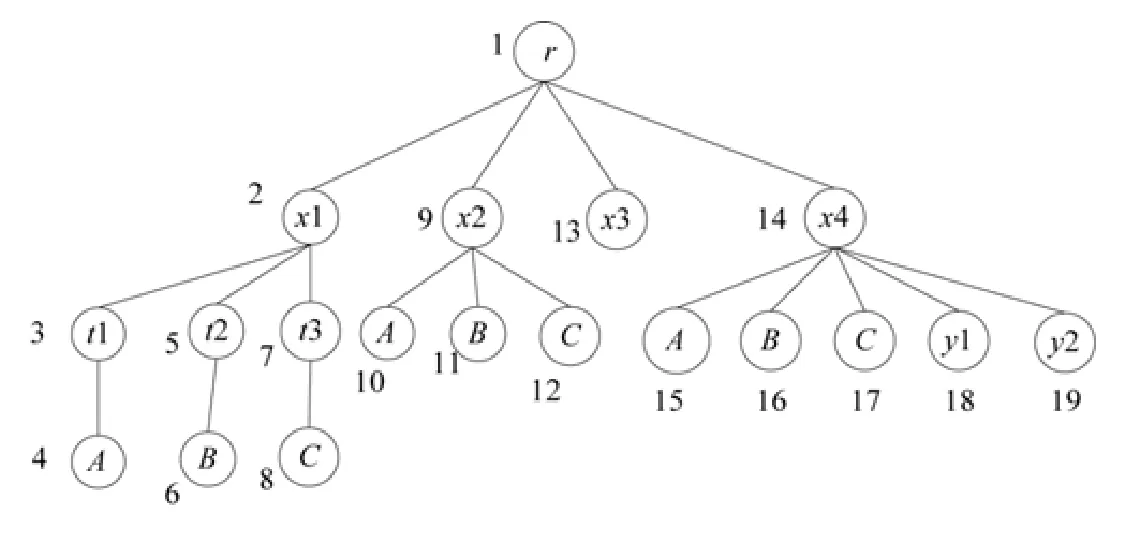
Fig.1 Ordered XML document tree图1 有序XML文档树
3 相关定义
3.1 研究动机
图2表示某图书馆的藏书情况,是一棵XML有序标签树T,圆角矩形中的数字表示节点的Dewey编码,旁边是节点的标签,叶子节点下的字符串表示值,例如tag(1)=booklist,tag(1.2)=book,value(1.3.1.1)=BigDataSystem.
考虑对该树的关键字查询Q={BigData,Felix,James},检索目标是查询书名包含 BigData,作者名字中包含Felix或者 James的图书.这些关键字在树中出现多次,例如 1.1.3.1.1.1、1.2.1.1、1.2.4.1.1.1、1.3.1.1和 1.4.1.1这5个节点中出现关键字BigData.按照LCA的定义,有LCASet(T,Q)={1,1.1,1.1.3,1.2,1.2.4.1,1.3,1.4}这7个节点满足查询Q的要求,这些LCA中,只有1.2、1.3、1.4和1.2.4.1满足用户查询要求;1和1.1.3是连接节点,因此不符合查询要求;1.1标签包含Felix和James,但与title对应的书是XML,而不是BigData,因此1.1虽然是书但也不符合用户查询意图.按照已经提出的过滤语义,例如根据SLCA语义则不能返回 1.2而是返回1.2.4.1,按照MLCA语义则不能返回1.3,而根据ELCA语义返回1.1.3节点也有意义,这些过滤语义并不能准确地表达用户的查询意图.
上述查询语义失败的原因是因为那些过滤语义没有充分考虑现实应用的复杂性,直接删除了某些 LCA,导致了低召回率和准确率.
针对已经出现的问题,下面提出了按照查询关键字数量、关键字实例路径、LCA类型以及关键字实例离散度等综合因素对LCA进行度量的新方法,然后按照LCA测量值的大小返回Top-K个结果.

Fig.2 XML for library图2 图书馆藏书XML文档
3.2 LCA与用户意图相关性规则
规则1.用户查询意图与查询关键字实例到LCA节点边的数量成反比.
在 LCA子树中,查询关键字实例离 LCA节点越近,表示 LCA越接近用户的查询意图,查询关键字实例到LCA节点边的数量表示了它们之间的距离.
如图1所示,关键字查询Q={A,B,C},x1和x2节点都是查询Q的LCA,显然,查询关键字的实例距离x2比x1更近,因此,x2比x1更符合用户的查询意图.
该规则确定了查询关键字实例与LCA之间的纵向关系.但在实际情况中,除了纵向关系之外还存在横向关系,即查询关键字实例在整个LCA子树中的占比情况.如图1所示,x2和x4都是查询Q的LCA,根据规则1,它们的度量值是相同的,但x2仅仅包含了3个查询关键字实例,而x4包含了y1和y2两个冗余节点,因此,x2比x4更符合用户查询需求.针对这个问题,提出了规则2.
规则2.用户查询意图与LCA子树路径的数量成反比.
规则2反映了LCA中查询关键字实例的离散度,LCA包含的子树相对于查询关键字越多,表示查询关键字之间的离散度越大,说明该LCA与用户查询的相关度越小.
3.3 基于关键字密度的LCA评分方法
根据规则1和规则2,给出了计算LCA排名的有关定义,并利用这些定义建立了计算LCA分数的公式.
定义5(最小最优LCA路径数MOPSize(Q)).对于XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},与查询Q对应的LCA集合LCASet(T,Q),则最小最优LCA的路径数是关键字的数量,即MOPSize(Q)=|Q|.
对于关键字查询Q,LCA包含了所有查询关键字实例,最小最优情况是LCA节点到叶子节点的每条路径上包含一个查询关键字实例.这种情况在横向轴上没有冗余信息,也不缺少信息.如果 LCA节点到叶子节点的路径数多于关键字数量,则说明LCA有多余信息,这种多余信息可能会对用户产生干扰.例如图2中,节点1.4是关键字查询Q={BigData,Felix,James}的LCA,MOPSize(T,Q)=3,因为3个叶子节点到LCA的路径刚好包含了3个查询关键字;虽然节点1.3也是查询Q的LCA,但它的子树有5条叶子到LCA的路径,说明包含了冗余信息.
定义 6(关键字与 LCA的联系度 CSize(T,Q,u,v)).对于 XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},u∈LCASet(T,Q),v∈KMS(ki)(1≤i≤m),存在一条从u到v的路径p(u,t1,t2,…,tn,v),CSize(T,Q,u,v)=路径p的长度.
定义6表明了LCA与查询Q的关键字实例之间纵向紧密度,CSize越小,表明关键字与LCA越密切.如图2所示,1.1.3和1.3都是关键字查询Q={BigData,Felix,James}的LCA,CSize(T,Q,1.1.3,Felix)=4,表明在1.1.3中,关键字Felix与该LCA的距离是4,而CSize(T,Q,1.3,Felix)=3,表明在1.3中,关键字Felix与该LCA的距离是3,说明后者比前者更接近用户需求.
为了对规则1进行计算,提出了LCA边密度的概念,它表示LCA子树中查询关键字实例到LCA边的数目与查询关键字之间的关系.
定义7(边密度LCAEDen(T,Q,v)).对于XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},某个LCA关键字的边密度为
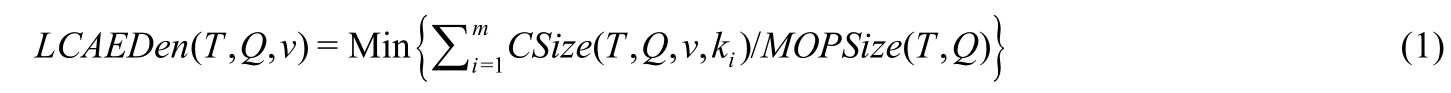
v∈LCASet(T,Q),ki∈Q且是v的后裔,1≤i≤m.
边密度LCAEDen(T,Q,v)表示查询关键字实例与LCA的纵向联系紧密度.该值越小,说明查询关键字实例与LCA联系得越密切,当然,查询结果就越好.如图2所示,节点1.4是Q={BigData,Felix,James}的LCA,它的边密度LCAEDen(T,Q,1.4)=8/3;节点1.1.3也是Q的LCA,它的边密度是LCAEDen(T,Q,1.1.3)=11/3,因此1.4比1.1.3更符合用户查询意图.但是1.3和1.4都是Q的LCA,它们的边密度LCAEDen(T,Q,1.4)=LCAEDen(T,Q,1.3)=8/3,但是显然,1.3比1.4包含了更多的冗余信息,因此1.3没有1.4好.
针对边密度相同而LCA存在冗余信息的情况,根据规则2,提出了路径密度这一概念.它表示LCA子树中查询关键字实例在整个LCA路径中的关系,即查询关键字的横向关系.
定义 8(LCA的实际路径数量 RPSize(T,Q,u)).对于 XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},u∈LCASet(T,Q),RPSize(T,Q,u)=等于u的叶子节点数量.
定义8表明了对于关键字查询Q,从LCA到叶子节点的路径数量.如图2所示,节点1.4是关键字查询Q={BigData,Felix,James}的一个 LCA,RPSize(T,Q,1.4)=3,说明该 LCA无冗余信息,而RPSize(T,Q,1.3)=5,说明节点1.3存在冗余信息.
定义9(路径密度LCAPDen(T,Q,v)).对于XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},某个LCA节点的路径密度LCAPDen(T,Q,v)=RPSize(T,Q,v)/MOPSize(Q),其中,v∈LCASet(T,Q).
路径密度LCAPDen(T,Q,v)表示了在整个 LCA子树中,查询关键字实例路径存在的稀疏度.该值越大,表示越稀疏,说明该LCA中的冗余信息越多,可能更不符合用户的查询意图.如图2所示,节点1.4是Q={BigData,Felix,James}的LCA,它的路径密度LCAPDen(T,Q,1.4)=3/3;节点1.3也是Q的LCA,它的路径密度LCAPDen(T,Q,1.3)=5/3,因此1.4比1.3更符合用户查询意图.
定义7和定义9分别从纵向和横向的角度来考虑LCA与用户查询意图的相关度.但存在另一种情况,如果两个不同LCA的边密度和路径密度都相同,我们如何区别它们?XML文档节点分为连接节点、实体节点、属性节点和值节点[32].不同节点的含义不同,连接节点表示不同实体之间或者实体与属性之间的连接关系,相当于关系数据系统中的连接表,实体节点表示现实世界的对象,相当于关系数据库系统中的实体关系,属性节点相当于关系数据库系统表中的属性,值相当于属性的记录值.在实际查询中,用户往往对实体比较感兴趣,因此在LCA排名中,实体节点比连接节点、属性节点和值节点更重要.
LCA节点与用户查询意图的契合度是综合性的因素,定义7和定义9考虑了LCA节点与查询关键字的纵向和横向关系,定义10建立了综合考虑各种情况下的LCA评分公式.
定义 10(LCAValue(T,Q,v)).对于 XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},v∈LCASet(T,Q),LCA的分值为
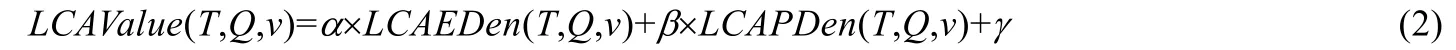
式(2)中,α表示边密度的权重,β表示路径密度的权重,γ表示节点类型权重.这里,α和β取值为1.

其中,|LCA|表示LCA的孩子节点个数,t表示与根节点类型相同的节点个数.
在如图2所示的XML文档中,对于查询Q={BigData,Felix,James},计算每个LCA所得分数见表1.
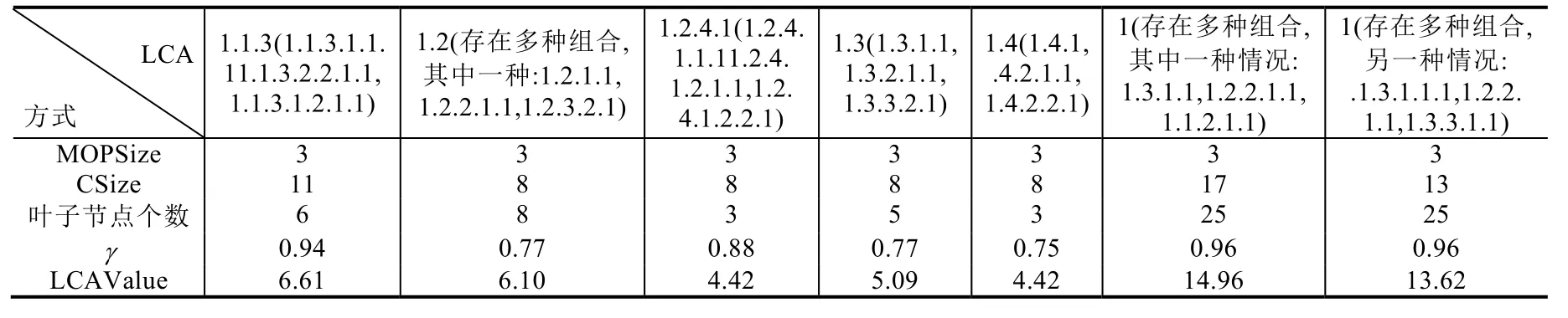
Table 1 LCAValue ofQ corresponding to the XML shown in Fig.2表1 图2所示XML文档对应的查询Q的LCAValue
表1中,查询Q有3个查询关键字,因此节点1.1.3的MOPSize为3,以1.1.3为根的实际路径数(叶子节点数)为6,关键字BigData、Felix和James与LCA节点1.1.3的联系度分别为CSize(T,Q,1.1.3,BigData(1.1.3.1.1.1))=3、CSize(T,Q,1.1.3,Felix(1.1.3.2.2.1.1))=4 、CSize(T,Q,1.1.3,James(1.1.3.1.2.1.1))=4,γ=0.94,利 用 公 式 (2)计 算 出LCAValue(T,Q,1.1.3)=6.61;同理,节点1.2也是LCA节点,关键字与1.2的联系度之和为8,叶子节点数是8,利用公式(2)计算出LCAValue(T,Q,1.2)=6.10;同理,LCAValue(T,Q,1.4)=4.42;对于节点 1,存在多种组合情况,表 1列出其中的两种,第 1种对应的节点为 1.3.1.1(Bigdata),1.2.2.1.1(James),1.1.2.1.1(Felix),它们的LCAValue(T,Q,1)=14.96,而另一种组合的节点为 1.1.3.1.1.1(Bigdata),1.2.2.1.1(James),1.3.3.1.1(Felix),它们的LCAValue(T,Q,1)=13.62.
表1最后一行显示,最符合用户查询意图的节点1.4和1.2.4.1的LCAValue值最小,节点1.3次之,值较大的节点1表明该节点最不符合用户查询意图.因此,可以按照LCAValue值从小到大排名,把最符合用户查询意图的LCA节点优先返回给用户.
4 主要算法
4.1 计算LCA分值的算法TopLCA-K
为XML文档树中的每个节点赋予一个体现结构关系的Dewey编码,通过该编码仅计算公共前缀即可求出任意两个节点的LCA.如图2所示,节点1.1.2.1.1和节点1.1.3.2.2.2.1,它们的公共前缀是1.1,因此,节点1.1是这两个节点的LCA.
为了提高计算LCAValue的效率,对于XML文档树T(V,E,r)的关键字查询Q={k1,k2,…,km},为每个查询关键字建立倒排索引,并根据它们的 Dewey编码从小到大排序,按照匹配集合中实例节点个数从小到大的顺序对每个查询关键字进行排序.表2对查询Q={BigData,Felix,James}建立了倒排索引表,BigData关键字实例有5个节点,Felix关键字实例有7个节点,James关键字实例有6个节点,按照关键字实例个数从小到大排序,并且每个查询关键字的 Dewey编码也根据从小到大的顺序排序.此外,还需要为每个非叶子节点建立该子树包含叶子节点数的索引表,见表3,为1,1.1,1.1.1,1.1.2和1.1.3建立非叶子节点索引表.

Table 2 Inverted index table forQ={BigData,Felix,James}表2 查询Q={BigData,Felix,James}的倒排索引表

Table 3 Number of leaf nodes in subtree表3 子树包含的叶子节点数
基于倒排表算法计算LCAValue值的基本思想是利用贪心算法计算所有查询关键字对应节点的各种组合,利用公式(2)计算该组合的LCA值并进行排名,输出TopLCA-K的查询结果给用户.假设有t个查询关键字,则该算法时间复杂度为O(nt),当查询关键字多并且XML文档规模很大时,该算法效率很低.
4.2 改进的TopLCA-K算法
为了提高TopLCA-K算法效率以适应大规模XML文档的环境,对TopLCA-K算法进行改进.
定义11(节点集V′的中间路径MidP(T,V′,u)).XML有向树T(V,E,r),节点集,节点u到根节点r构成的路径p(u,p1,p2,…,pn,r)把节点集Vʹ分为左右两部分子集Vʹl和Vʹr,Vʹl∩Vʹr=∅,Vʹl∪Vʹr=Vʹ,MidP(T,Vʹ,u)=p(u,p1,p2,…,pn,r).
定义12(节点集V′中离节点u最近节点Nearest(T,Vʹ,u)).XML有向树T(V,E,r),节点集,节点u∈V但u∉Vʹ.Vʹ中离u最近的节点为Nearest(T,Vʹ,u),计算Nearest(T,Vʹ,u)的过程如下.
(1) 中间路径MidP(T,Vʹ,u)把Vʹ分为Vʹl和Vʹr,Vʹl∩Vʹr=∅,Vʹl∪Vʹr=Vʹ;
(2)Vʹl中最大 Dewey编码节点为vl_max,Vʹr中最小 Dewey编码节点为vr_min;
(3)LCA(u,vl_max)=x,LCA(u,vr_min)=y;
(4) 如果x是y的祖先,则vr_min为基于u的Vʹ的中心节点,即Nearest(T,Vʹ,u)=vr_min;如果y是x的祖先,则vl_max为基于u的Vʹ的中心节点,即Nearest(T,Vʹ,u)=vl_max;
(5) 如果x和y是同一个节点,则vl_max为基于u的V′的中心节点,即Nearest(T,Vʹ,u)=vl_max.
图 1中,设V={3,4,5,7,10,11,13,15,16},中间路径p(12,9,1)把V分为Vl={3,4,5,7,10,11},Vl中最大编码为 11,Vr={13,15,16},Vr中最小编码为13,LCA(11,12,)=9,LCA(12,13)=1,根据定义12(4),则有Nearest(T,V,12)=11.
定义 13(中心节点 CenterNode(T,V,u)).XML有向树T(V,E,r),为T的每个节点根据深度优先赋予一个Dewey 编码,节点集Vʹ={v1,v2,…,vm}(vi∈V),Vʹ的m个节点按照 Dewey 编码从小到大排序后,节点u∈V但u∉Vʹ,则CenterNode(T,Vʹ,u)=Nearest(T,Vʹ,u).
性质1.XML有向树T(V,E,r)的m个节点u1,u2,…,um,x=LCA(u1,u2,…,um);T中的m+1个节点u1,u2,…,um,uʹ,LCA(u1,u2,…,um,uʹ)=y,如果uʹ是x的后裔,则y是x本身,否则y是x的祖先.
性质2.XML有向树T(V,E,r)的节点x和y,如果y是x的祖先,则y子树的叶子节点数大于等于x子树的叶子节点数,即leafNum(T,y)≥leafNum(T,x).
性质 3.XML有向树T(V,E,r),节点集Vʹ的m个节点按照 Dewey编码从小到大排序,Vʹ={v1,v2,…,vm}(vi∈V,1≤i≤m),u∈V但u∉Vʹ.CenterNode(T,Vʹ,u)=vj(vj∈Vʹ),则leafNum(T,LCA(u,vj))≤leafNum(T,LCA(u,vjʹ))(vj≠vjʹ,vjʹ∈Vʹ).
证明:因为vj=CenterNode(T,Vʹ,u),根据定义 12 和定义 13,则vjʹ≠vj,LCA(u,vjʹ)=LCA(u,vj)或者LCA(u,vjʹ)是LCA(u,vj)的祖先.根据性质 2,leafNum(T,LCA(u,vjʹ))≥leafNum(T,LCA(u,vj)). □
图 2中,按照 Dewey编码从小到大排序后,Vʹ={1.1.2.1.1,1.1.2.2.1,1.1.3.1.1.1,1.1.3.1.2.1.1,1.1.3.2.1.1,1.1.3.2.2.1,1.1.3.2.2.1.1,1.1.3.2.2.2.1},对于节点 Bob(1.1.3.1.1.2.1),Vʹ的中心点CenterNode(T,Vʹ,1.1.3.1.1.2.1)=1.1.3.1.2.1.1,根 据 性 质 3,leafNum(T,LCA(1.1.3.1.1.2.1,1.1.3.1.2.1.1))≤leafNum(T,LCA(1.1.3.1.1.2.1,v))(v∈Vʹ且v≠1.1.3.1.2.1.1).例 如 ,leafNum(T,LCA(1.1.3.1.1.2.1,1.1.3.1.2.1.1))(=2)≤leafNum(T,LCA(1.1.3.1.1.2.1,1.1.3.2.2.1.1))(=6).同理,leafNum(T,LCA(1.1.3.1.1.2.1,1.1.3.1.2.1.1))(=2)≤leafNum(T,LCA(1.1.3.1.1.2.1,1.1.3.1.1.1))(=3).
在TopLCA-K算法中,如何确定K是一个重要问题.如对于图2中的Q={BigData,Felix,James},KMS(BigData)={1.1.3.1.1.1,1.2.1.1,1.2.4.1.1.1,1.3.1.1,1.4.1.1}共有 5个节点;KMS(Felix)={1.1.2.1.1,1.1.3.1.1.1.1,1.2.3.2.1,1.2.4.1.2.1.1,1.3.2.1.1,1.3.3.1.1,1.4.2.1.1}共有 7个节点;KMS(James)={1.1.2.2.1,1.1.3.2.2.1.1,1.2.2.1.1,1.2.4.1.2.2.1,1.3.3.2.1,1.4.2.2.1},共有6个节点.按照LCA的概念共有5×7×6=210种组合情况,但是满足用户查询意图的LCA比这个数值要小得多.实际上,真正满足用户意图的LCA的个数由min{|KMS(BigData)|,|KMS(Felix)|,|KMS(James)|}的值确定,即具有最少关键字实例的个数就是用户需要寻找的LCA个数.
规则 3.对于 XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},满足用户查询意图的 LCA 个数,即LCANum(T,Q)≤min{|KMS(k1)|,|KMS(k2)|,…,|KMS(km)|},ki∈Q,1≤i≤m.
证明:设ki的|KMS(ki)|具有最小值t,则当kj∈{k1,k2,…,ki-1,ki+1,…,km}时,|KMS(kj)|≥t.对于KMS(ki)中的任意查询实例节点u∈KMS(ki),LCAValue(T,Q,v)的最小值为α,v为包含了u的一个LCA,该LCA是满足用户查询意图的LCA.由于|KMS(ki)|的值为t,因此这样的 LCA 不多于t个,即LCANum(T,Q)≤min{|KMS(k1)|,|KMS(k2)|,…,|KMS(km)|}. □
备注:如果多个LVAValue(T,Q,v)的值相同,则看作是同一个LCA.
利用规则 3能够解决过滤语义,如 SLCA、MLCA 和 ELCA 等查不全的问题.例如,针对图 2中的查询Q={BigData,Felix,James},按照SLCA语义,不能返回1.2节点,但是根据规则3,能够把节点1.2作为满足查询意图的一个节点返回给用户.
规则3确定了TopLCA-K算法中K的值,利用定义13确定搜索倒排表的起始位置,利用性质3能够对搜索的倒排表进行剪枝,从而提高算法效率.
改进后的 TopLCA-K算法的思想是:首先建立每个查询关键字的倒排表,对查询关键字实例的个数从小到大排序,并把每个倒排表中的Dewey编码按照从小到大的顺序排序,逐层建立中心位置索引,根据中心位置索引逐层寻找LCA并进行评分,一直完成最少个数的查询关键字实例的搜索.
建立中心位置索引CI(center index)的方法是:对于XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},查询关键字k1的实例KMS(k1)={a[1,1],a[1,2],…,a[1,t1]},查询关键字k2的实例KMS(k2)={a[2,1],a[2,2],…,a[1,t2]},查询关键字km的实例KMS(km)={a[m,1],a[m,2],…,a[m,tm]}.每个查询关键字实例按照 Dewey编码从小到大排序,即a[j,1]≤a[j,2]≤…≤a[j,tj](1≤j≤m),且t1≤t2≤…≤tm.构建如下的中心位置索引如图3所示.第1层存储了k1实例,第2层存储了CenterNode(T,KMS(k2),a[1,j])节点,第 3层到第m层存储了CenterNode(T,KMS(ki),CenterNode(T,KMS(ki-1),a[i-1,j]))节点.
例如,对于图2所示的XML文档树T和查询Q={BigData,Felix,James},按照前面的方法建立的中心位置索引如图4所示.
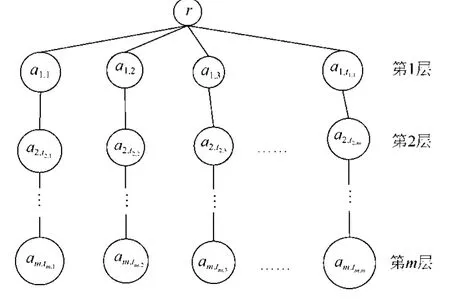
Fig.3 Central location index图3 中心位置索引

Fig.4 Central location index corresponding to Fig.2 andQ={BigData,Felix,James}图4 与图2和查询Q={BigData,Felix,James}对应的中心位置索引
推论1.XML有向树T(V,E,r)的关键字查询Q={k1,k2,…,km},对应的中心位置索引CI,第i层的中心位置a[i,ci],LCA(a[1,c1],a[2,c2],…,a[m,cm])=C,a[1,c1],a[2,c2],…,a[m,cm]是 CI树中一条从叶子节点到第 1层的路径;LCA(a[1,x1],a[2,x2],…,a[i,ci+k])=R(ci+k≤ti,ti是第i层的关键字实例个数),LCA(a[1,x1],a[2,x2],…,a[i,ci-j])=L(ci-j≥0),则如下公式成立:
根据推论1,可以快速寻找出最小LCA的值.图4显示了图2、Q={BigData,Felix,James}的CI.通过树的第1个分支计算出 LCA为 1.1.3,该节点有 6个叶子,关键字与 LCA的联系度为 11,LCAValue(T,Q,1.1.3)=(6+11)/3=17/3;在第 3层以 1.1.3.1.2.1.1为出发点,从两边搜索其他 Felix节点的组合情况,左边的 Felix节点1.1.2.1.1,则前面两个节点与1.1.2.1.1的LCA为1.1,现在考虑只有BigData和James两个节点的情况下LCAValue(T,Q,1.1)=(9+9)/3=18/3,则LCAValue(T,Q,1.1)≥18/3>LCAValue(T,Q,1.1.3)(=17/3),根据推论 1,可以不用考虑1.1.2.1.1左边的节点;再观察右边的情况,右边的Felix为1.2.3.2.1,则前面两个节点与1.2.3.2.1的LCA为1,这种情形下叶子节点有 25个,LCAValue(T,Q,1)=(25+4)/3>LCAValue(T,Q,1.1.3)(=17/3),根据推论 1,可以不用考虑1.2.3.2.1右边的节点.因此,利用中心位置索引可以对搜索空间进行快速剪枝,提高了搜索效率.
针对有序XML文档树T的关键字查询Q,按照深度优先遍历T并为每个节点赋予Dewey编码,然后建立每个查询关键字ki对应的实例节点倒排表,并按照Dewey编码从小到大地对该倒排表进行排序;建立每个子树的叶子节点数列表;建立中心位置CI.寻找最佳K个LCA方法,见算法1和算法2.

算法1.getMinLcaValue(T,Q)//取得最小的LCA值.

算法2.getLcaValue(ciT,IL,col,direction); //根据倒排表IL和CI计算第col个的LCA值.

5 实验分析
我们设计了一套全面的实验来评估本文提出的TopLCA-K算法的性能,采用真实数据集SIGMODRECORD、Mondial和DBLP作为测试数据,比较了与XReal、XReason和SLCA等算法在查全率、查准率和时间性能等方面的效果.所有实验在CPU为Intel双核3.6GHz,RAM为4GB,操作系统为Windows 7的机器上运行,实现语言为Java SE,通过使用dom4j-1.6.1.jar来解析XML文档.
5.1 数据集与查询测试
我们选取了来自于现实情况的SIGMODRECORD、Mondial和DBLP作为测试数据集.表4显示了这些数据集的统计信息,它们具有不同特征,SIGMODRECORD节点数和不同标签数最小,Mondial数据集的节点数处于中间水平,使用这两个测试数据集的主要目的是测试算法的查全率和查准率.DBLP①的规模很大,节点数超过1亿,我们选择的测试数据仅仅是其中的一部分,但也保持了一定的规模,该数据集主要测试在数据规模较大情况下各算法的时间性能.本实验没有考虑数据集中ID/IDREF的关联情况.

Table 4 Data sets表4 测试数据集的基本信息
针对每个测试数据集,我们选取了具有不同查询意图的测试查询,并且每个查询测试的查询意图是明确的.为每个数据集设计了7个测试查询,S1~S7、M1~M7和D1~D7分别表示针对SIGMODRECORD、Mondial和DBLP数据集的测试查询.具体见表5.
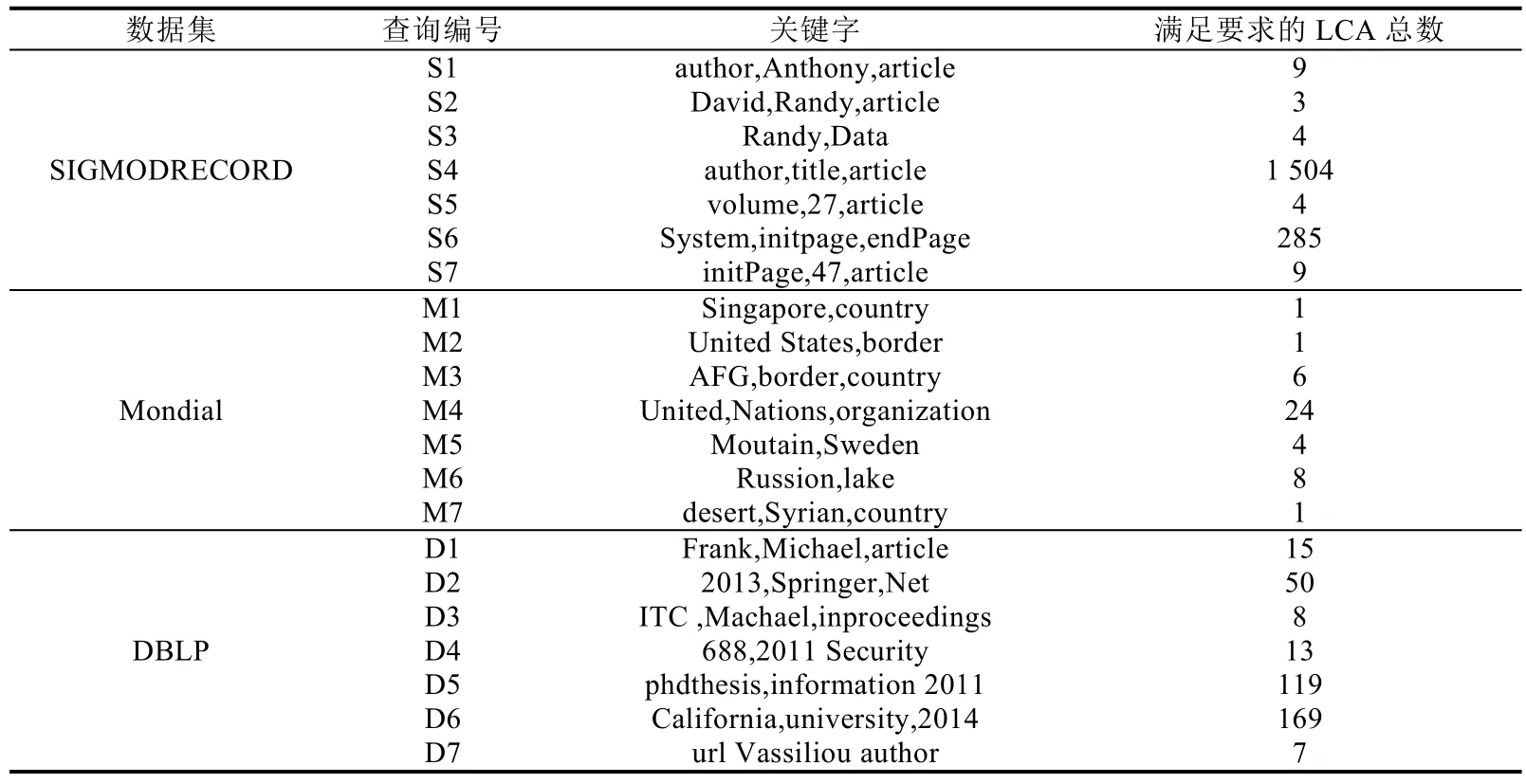
Table 5 Keyword query case表5 关键字查询案例
5.2 查询质量
把本文提出的TopLCA-K算法与已有XReason、Xreal和SLCA等方法在查准率和查全率进行对比来比较它们的查询质量.
图5显示了本文提出的TopLCA-K与其他方法在查询准确率方面的比较情况.
图5显示,在查准率方面,一般情况下,TopLCA-K要高于其他3种方法,因为该算法考虑了LCA中横向关键字密度和纵向关键字密度两方面的情况,因此排在前面的更符合用户查询意图.但在某些查询情况下,准确率也不能达到100%,主要是因为查询关键字存在一些歧义,例如关于DBLP数据集的D4查询,查询意图是查询688页,2011年出版的标题中含有Security的论文、书籍或者会议出版的文章,但是由于688不仅仅出现在page中,而且在节点ee中也出现了该关键字.同理,2011不仅仅出现在year节点中,而且在incollection的url中也出现了2011.
图6显示了召回率的比较情况.
很明显,TopLCA-K的召回率为100%,不存在漏检问题,其他方法都不能达到100%,XReal采用扩展网页排名方法进行排名,在关键字歧义情况下,很容易漏检;SLCA由于去掉了父 LCA,显然会丢失一些符合要求的结果;而TopLCA-K返回了所有的LCA,包括有歧义的LCA,然后从深度和广度计算LCA的值,把排名小的优先返回,当K值合理时,将返回所有可能满足查询意图的LCA.

Fig.5 Precision rate图5 比较查准率
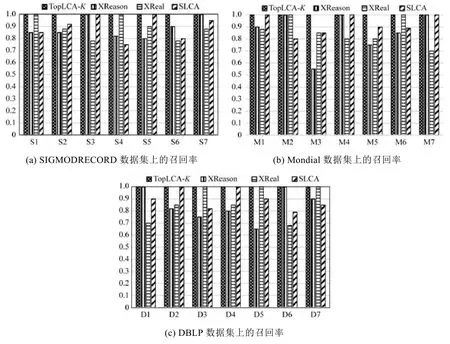
Fig.6 Recall rate图6 比较召回率
5.3 查询性能
图7显示了3个数据集上算法运行时间情况,为了准确记录查询时间,每个关键字查询执行5次,取它们的平均值作为查询时间,根据规则3设置了TopLCA-K中K的值.从图7可以发现,TopLCA-K的算法时间性能明显优于XReason和XReal,与SLCA比较接近.因为TopLCA-K算法利用CI能够对查询空间树进行有效剪枝,例如在D6中,共有8 849个节点包含关键字2014,其中year节点值有4 051个,其他节点,如ee包含的2014有520个.这种情况对XReason产生有效结构模式形成了很大干扰,这种情况也对采用TF*IDF排名的XReal方法形成了很多干扰信息.
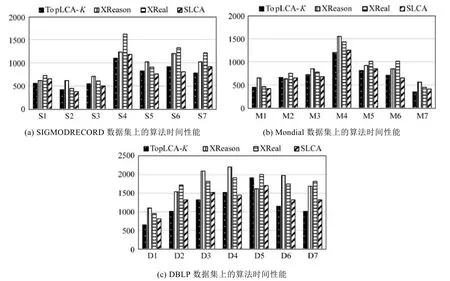
Fig.7 Time performance图7 算法时间性能对比
6 结束语
本文首先介绍了LCA过滤语义和结果排名方法,指出了在XML关键字查询中LCA过滤语义存在漏报问题,提出了用户查询意图与查询关键字在纵向和横向方面的两个规则,建立了利用边密度和路径密度对LCA节点进行评分的公式,采取中位节点索引CI来提高TopLCA-K算法效率.实验结果表明,本文提出的对LCA进行评分排名的方法在查准率和召回率方面效果较好,并且查询时间性能也较好,但需要进一步优化提高.下一步的研究重点考虑当在LCA之间存在包含、重复和交叉关系情况时,如何对 LCA进行排序以及结果展示的问题,同时进一步优化算法.在未来的工作中,将研究如何减少编码长度以及基于新编码方案的 XML关键字查询处理.
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
华人时刊(2022年1期)2022-04-26
法律方法(2021年3期)2021-03-16
动漫界·幼教365(大班)(2019年10期)2019-10-28
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
延河(下半月)(2014年3期)2014-02-28
环球时报(2009-11-25)2009-11-25
