
基于关联群演化相似度的社团追踪算法
2019-07-11 08:30赵亚伟徐杨远翔
复杂系统与复杂性科学 2019年1期
徐 兵,赵亚伟,徐杨远翔
(1.中国科学院大学大数据分析技术实验室,北京 100049;2.北京知因智慧数据科技有限公司AI实验室,北京 100027)
0 引言
随着中国经济的快速增长和信息技术的不断进步,人们生活水平日益提高,人与人之间、企业与企业之间的联系也越来越紧密,这导致各种关系形成的网络越来越多、越来越复杂。网络结构的分析对于洞悉网络背后的复杂关系起到了非常关键的作用。近年来,许多专家、学者在进行复杂网络分析、网络研究时发现,大多真实网络都存在社团结构[1]这一特性——同一社团里成员联系更紧密、交流更频繁,而不同社团成员之间联系相对稀疏、交流较少。社团结构在不同领域里也有不同的称谓,如在社交网络领域,社团结构大多被称为“朋友圈”;在银行业被称为“客户群”;还有组、群、类等称谓。挖掘网络中的社团结构并追踪社团演化的序列模式,对于了解网络功能具有极其重要的意义。社交网络分析也是目前研究的热点之一,作为人类真实世界在网络虚拟世界的一种延伸,群组结构是社交网络的一个重要结构特征,也是中观尺度下观察和理解网络拓扑的一种重要结构,这种结构无论对于学术界还是工业界都有巨大的研究价值[2-3]。社团研究还可应用在银行业中,在银行客户关系网络中,存在着许多具有相关关系的客户。这些客户组成的客户区,因其庞大的规模、巨额的资金需求等因素成为商业银行信贷资金争相追捧的对象,也是银行利润的重要源泉。因此,对于银行客户群的识别与追踪就显得尤为重要。
本文首先提出社团里的成员并非完全对等,而是有核心与非核心成员之分。在某些情况下,核心成员可能对社团产生或消失有着更大的影响。并且社团结构并非是一成不变的,而是处于不断变化中。如社团成员数量的增加或减少、社团核心成员的出现或消失、社团的其他一些属性的变化等。为了追踪这种变化以及社团是如何演化的,本文从普遍意义上的关联群出发,首先对关联群给出了明确定义,并阐述了关键演化事件、演化序列的相关概念。在此基础之上,提出基于关联群演化相似度的社团追踪算法,识别出演化过程中形成的关联群以及演化序列。最后,对上述的算法进行了实验分析。实验结果表明,所提出的算法可实现关联群的精准识别与演化序列的准确生成。
本文剩下内容包括以下4个部分。第2部分主要对社团结构的相关研究进行了分析总结。在第3部分中,对关联群以及相关定义进行阐述说明,并对关联群追踪算法给出详细的描述。第4部分通过一个具体实例对上述算法进行验证分析,并给出了相应的一些结论建议。第5部分对本文进行了总结以及对未来研究进行展望。
1 相关工作
随着Facebook、Twitter、微博、QQ、微信等各种SNS(Social Network Service)的流行与兴起,社团结构的分析变得非常热门。社团结构一直是社会学研究的一个重要课题,而在计算机领域,社团结构的研究主要体现在社交网络的分析上。社交网络分析中最常见的是社交圈的识别。Facebook和微信是关于人与人之间的强关系网络,划分社交圈有助于朋友间相互推荐。微博、Twitter、豆瓣、微信公众号是关于关注与被关注的弱关系网络,划分关联群有助于消息和知识的传播[4-5]。划分社团之后还可以对客户进行精准化营销,与推荐系统中的基于用户的协同过滤算法相结合,为用户推荐个性化的商品和服务;甚至可以识别互联网金融业中的欺诈团伙,进行欺诈团伙检测[6-8];另外,也可以追踪社团的演化规律,对社团进行更细致的分析,从而可以起到指导业务决策的作用。
Junming Shao等人提出了基于距离动力学的静态社团发现算法[9]。算法的核心思想是把目标网络看作是一个自适应的动态系统,系统内的每个节点都受它的邻居的影响。节点间的距离会影响交互,而交互会改变节点间的距离。这样的动态交互最终会形成一个稳定的系统,同属于一个社团的节点会紧密连接,而属于不同社团的节点会尽可能远离。原文作者利用实验说明了该算法有着较低的时间复杂度以及高质量的社团发现效果,值得推广与应用。
对于动态网络演化分析有相关综述[5,10-11]。Chayant等人提出了识别社团结构以及社团的动态变化的框架[12],为以后的研究提供了重要的参考。Derek Greene等人提出了追踪动态社团的模型,并定义了一些社团演化事件[13],对于直观地理解社团的演化有很大帮助。Takaffoli等人提出了元社区的概念,具有生存期m的元社区M包含m个社区,利用基于社团相似度匹配的思想来发现社团演化过程[14]。Bhat等人提出一种基于密度的方法研究社交网络动态变化,并利用日志映射来减少相邻时间社团相似度的比较次数[15]。
上述的算法大多把社团看作一个整体,仅从整体来考虑社团的变化,但是,没有将社团内部成员对社团演化的影响考虑进来。本文首先提出了利用社团内部与整体两方面的信息来衡量社团的演化,对于社团核心成员、社团成员相似度、社团属性等一一进行加权,在提高识别关联群准确率的同时增加了灵活性。最后,以某银行真实业务数据出发来探索社团在动态网络中的变化。由于集团企业组织结构复杂、财务数据不易核实、内部关联交易频繁、连环担保较为普遍,带来多头授信、过度授信等问题,对其进行的研究具有一定的复杂性与困难性。本文从银行业社团固有的一些属性以及社团内部的属性如核心成员、成员组成,来追踪社团的演化序列。应用本文提到的算法能准确地识别出关联群并提取社团演化序列,因此本文的方法具有很高的应用价值。
2 社团追踪算法
2.1 相关定义
为了定量研究网络及网络特性,一般把网络抽象为图(Graph),记为G。一个图G定义为一个对(V,E),即G=(V,E)。V表示图G中节点的集合,E表示图G中边的集合。近年来,对众多实际网络的研究发现,它们存在一个共同的特征,称之为网络中的社团结构。它是指网络中的节点可以分成组,组内节点间的连接比较稠密,组间节点的连接比较稀疏。一般用C(Community)表示社团,如图1是有着3个社团的小型网络。
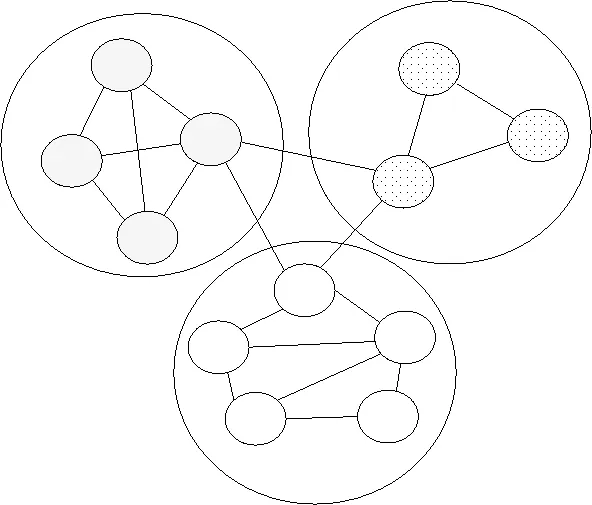
图1 一个小型的具有社团结构性质的网络示意图Fig.1 Schematic diagram of a small network with community structure
小圆表示节点,大圆表示社团,图1表示有3个社团的小型网络。
本小节主要介绍一些相关的定义,以便更好地理解3.2中所提出的算法。
定义1关联群
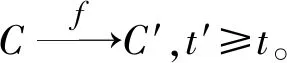
t、t+1、t+2时刻分别有4、4、5个社团,A、B、C分别表示演化过程中不同的关联群,由相邻两个时刻有关联关系的社团构成。
定义2网络快照和动态网络
网络随时间动态变化,在时刻t的网络称为t时刻的网络快照,动态网络则是一系列网络快照的有序序列。在时刻t的网络快照记为St则动态网络则可以表示为

图2 关联群的定义示例Fig.2 Example definition of an associated group
定义3社团集合
对于每个网络快照S,在时间t,利用某种静态社团发现算法进行社团挖掘,得到的社团集合称为t时刻的社团集合,简记为Ct。在1≤t≤T,共有T个网络快照,则相对应有T个社团集合。若根据静态社团发现在St上挖掘出n个社团,t时刻的n个社团可表示为Ct={Ct1,Ct2,…,Ctn}。
定义4社团演化序列
在动态网络中,社团从t=1时刻(或从产生时刻)到t=T时刻(或消失时刻)的社团动态变化的序列(其中1≤t≤T),称为社团演化序列,简记为Seq。社团演化序列的获取方法可以在3.2中关联群追踪算法中看到。图3是一种可能的社团演化情景。
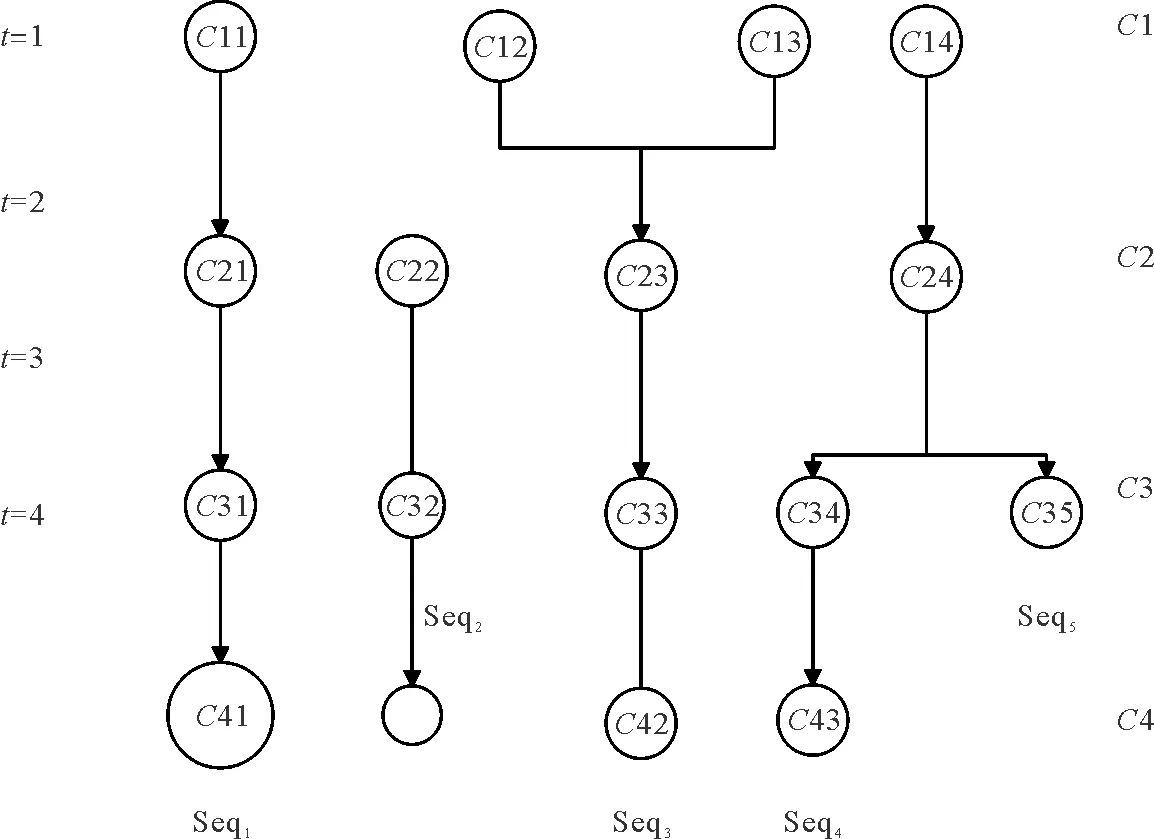
图3 一种可能的社团演化情景Fig.3 A possible scenario of community evolution
Ct为t时刻St中社团的集合。C2={C21,C22,C23,C24},C3={C31,C32,C33,C34,C35},C4={C41,C42,C43,C44}。Seqn表示追踪得到的社团序列,上图中有5个Seq,其中Seq1=(C11,C21,C31,C41),Seq2=(C22,C32),Seq3=(C12,C13,C23,C33,C43),Seq4=(C14,C24,C34,C44),Seq5=(C14,C24,C35)。
定义5关键演化事件
关键演化事件是指在社团随时间变化的过程中社团自身出现的一些较为明显的变化行为。关注关键演化事件,对于研究关联群的演化有着重要作用。除了社团不变这一极少发生的特殊事件外,关键演化事件一般有以下6类事件:
1)社团膨胀:社团演化到T时刻,在T时刻的规模明显大于它上一时刻的规模并且增大的程度大于10%时,即认为社团发生了膨胀,记为E。如图3中C31→C41。
2)社团收缩:社团演化到T时刻,在T时刻的规模明显小于它上一时刻的规模并且减小的程度大于10%时,即认为社团发生了收缩,记为R。如图3中C22→C32。
3)社团合并:T时刻的2个或多个社团在T+1时刻合并为一个社团,定义为社团的合并,记为M。如图3中的C12、C13→C23。
4)社团分裂:T时刻的1个社团在T+1时刻分裂为2个或多个社团,定义为社团的分裂,记为S。如图3中的C24→C34、C35。
5)社团新生:社团演化序列的起点均为新生社团。特别地,在T=1时刻的社团都为新生社团。
6)社团死亡:T时刻的社团演化到T+1时刻不再存在,定义为社团死亡。如图3中的C32发生了社团死亡事件。
2.2 社团追踪算法
由上3.1节定义可知,关联群是相邻时刻存在关联关系的社团或群。如何确定其关联关系是本节的重点。每个社团都有一些特性,传统方式衡量两个社团间的相关关系如演化相似性通常以局部特性或整体特性来衡量,本节则以加权的综合特性来衡量社团间的演化相似度,当演化相似度大于一定阈值,则定义为两者存在关联关系,也即形成关联群;反之,两者不能形成关联群。在形成关联群的过程中,会有一些关键的演化事件发生,本算法不仅能追踪到关联群,也能观测到关键演化事件。
2.2.1 核心成员
本文中所研究的对象是社团,社团是由社团成员所组成。以往研究社团时,大都把社团成员同等看待,本文将社团成员分为核心成员与非核心成员两类。在一个社团中,核心成员往往对整个社团的存在或消亡起着决定性的作用。
核心成员的识别首先要寻找到该社团成员的特征属性,这些所选择的特征属性能较明显的反映每个成员的基本性质,比如存款数量、借款金额等等。本文利用专家评分法[19],对社团中的每个成员的综合评分进行量化,所选取的综合评分最高的节点为社团核心成员。该核心成员的特点是基于所选择的特征属性,按照该方法计算的综合得分最高。社团成员的特征经过特征提取后得到特征集合,如:X=[x1,x2,…,xn]。利用选定的专家评分表,从而得到核心成员的综合评价得分。
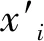
(1)
其中a、b分别为t和t+1时刻的某一社团,KMa表示社团a的核心成员。则式(1)表示社团a中的核心成员是否在社团b中。如果在,则KernelMember(a,b)为1,若不在,则KernelMember(a,b)为0。
2.2.2 成员相似度
社团的成员是社团的重要属性,也是社团演化中需要着重关注的属性,如社团的膨胀、萎缩都根据社团成员规模来衡量。而两个社团成员之间的相似度,往往能反映后一个社团是否由前一个社团演化而来,相似度越大,越有把握确定两者之间的演化关系,越可能形成关联群。社团成员的相似度用Jaccard相似系数[17]来衡量。
(2)
其中,Member(a)指社团a的成员,Member(b)指社团b的成员。分子部分取两者共有的成员个数,即a与b交集的元素个数;分母部分取a与b并集的元素个数。
2.2.3 社团相似度
社团相似指在相邻的两个时间截面,T时刻中的社团与T+1时刻社团的相似程度。确定社团演化序列时,需要计算两个社团之间的相似程度。样本的线性相关性会干扰对样本点相似性的度量,而利用余弦相似度度量样本点的相似程度可以有效地避免样本点线性相关的干扰。利用基于夹角余弦的相似度计算方法是进行社团分析的常用方法之一。社团a,b的余弦相似度[18]计算如式(3):
(3)
其中,A为关联群a的属性构成的属性向量,同理,B是b的属性向量。
2.2.4 演化相似度
前后两个社团之间是否形成关联群与上述核心成员、成员相似度、社团相似度都有着不可分割的关系。最终演化相似度可以用式(4)来衡量。
(4)
其中,α,β,γ是超参数,取值范围为[0,1],控制某一个分量的重要程度,且α+β+β=1。λ是拉普拉斯平滑系数,为了平滑KernelMember(a,b)为0的情况,本文取值为1。KernelMember(a,b)指a中的核心成员是否仍在b中;Jaccard(a,b)表示社团a与社团b中个体成员的相似度;Cos(a,b)表示a,b两个社团属性之间的余弦相似度。Esim(a,b)指两个社团之间的演化相似度。当Esim(a,b)>θ(某一阈值),则a与b形成关联群,并将b加入到a的演化序列中。
2.2.5 社团追踪算法
对于如何追踪社团演化序列的问题,本文提出了一种“多部图”匹配的方法。多部图是一种分层的图,每一层表示一个时刻的社团集合,层中的一个节点表示一个社团。多部图也可以看作多个二部图的集合,相邻时刻的社团集合作为二部图的两个子部分,图4是一个简单的多部图示例。
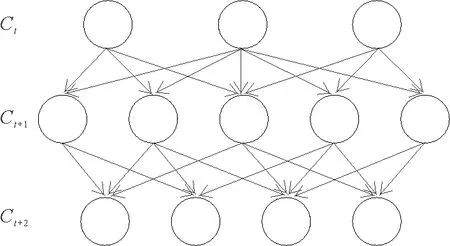
图4 简单多部图示例Fig.4 Simple multi-image example
t、t+1、t+2时刻的社团集合中的社团连接形成的简单多部图。每个节点表示一个社团,每一层表示一个时刻的社团集合,上图为3个时刻的社团集合形成的3部图。
利用多部图进行社团追踪,生成演化序列的方法如下:
1)初始时,不同层之间进行全连接,所有边权重赋值为一个极小的值。
2)利用式(4)中的演化相似度公式重新更新权重。
3)删除边权重小于阈值θ的边。
4)提取图中所有的路径,即为演化序列。
关联群表示有关联关系的社团集合,本节针对关联关系进行了深入分析。利用综合加权的演化相似度来衡量社团之间的关联关系。不同领域关注的影响关联关系的因素不同,利用权重可以方便地调节各因素的比重,具有较好的灵活性。提出多部图的思想对演化序列进行提取,是社团序列追踪的一种新方法。综合加权的演化相似度和多部图两者结合在一起,能有效且准确地进行社团追踪。
社团追踪算法描述如下:
输入:网络快照、α、β、γ、θ
输出:社团演化序列Seqs
1) for 1<=t<=T:
Ct( 社团挖掘(St)
end for;
2) Order(Ct);
3) 每个Ct对应多部图一个子图;
4) 多部图中的相邻两层节点进行全连接;
5) 初始化边权重:
for edge inG:
weightedge( 0
end for
6) forCainCt:
forCbinCt+1:
计算核心成员相似度KernelMember(a,b);
计算成员相似度Jaccard(a,b)
计算社团属性相似度Cos(a,b);
计算演化相似度Esim(a,b)
weightedge(Esmin(a,b)
end for
7) for edge inG:
ifweightedge<θ:
将边删除
end if
end for
8) 提取剩余多部图中的有向路径,得到最终的演化序列Seqs。
3 实验验证
基于上文提出的综合加权的演化相似度以及社团追踪算法,利用多部图进行社团的追踪。本节主要阐述了实验流程,并对使用的数据以及数据的预处理做了简单介绍,最终利用预处理之后的数据进行社团追踪算法的验证分析。
3.1 实验流程
利用已有数据,结合上述所提出的社团追踪算法以及多部图思想,进行社团演化序列的提取。根据伪代码以及每一步所需数据,设计实验流程如图5所示。
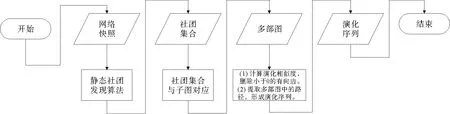
图5 实验流程图Fig.5 Experimental flow chart
前期是数据准备阶段,当数据准备完成后便可利用3.2节所提出的算法便可进行社团的追踪。在进行社团追踪的同时,还可观察到各种演化事件随超参数的变化而变化。社团追踪算法的具体步骤如下:
令网络快照表示为St,1≤t≤T.
步骤1 利用静态社团发现算法[9],挖掘出每个网络快照中St的社团。
步骤2 对于步骤1挖掘出的社团,按照时间顺序排列,形成社团集合序列
步骤3 每个时间截面上社团集合对应多部图的一个子图。
步骤4 多部图的每一层的每一个节点与下一层进行全连接,形成全连接的有向多部图。
步骤5 对于多部图中有向边权重初始化为0。
步骤6 利用式(4)计算每条边的演化相似度,并将有向边权重更新为演化相似度。
步骤7 删除多部图中有向边的权重小于阈值θ的边。
步骤8 对于多部图的剩余部分,提取图中的路径,形成演化序列。
3.2 数据准备
本实验数据来源于某金融机构2011年1月—2011年12月一整年的数据,数据已经过脱敏、匿名化处理。利用静态社团发现算法得到的结果,每月大约有4万左右社团。各月社团数量统计图如图6所示。
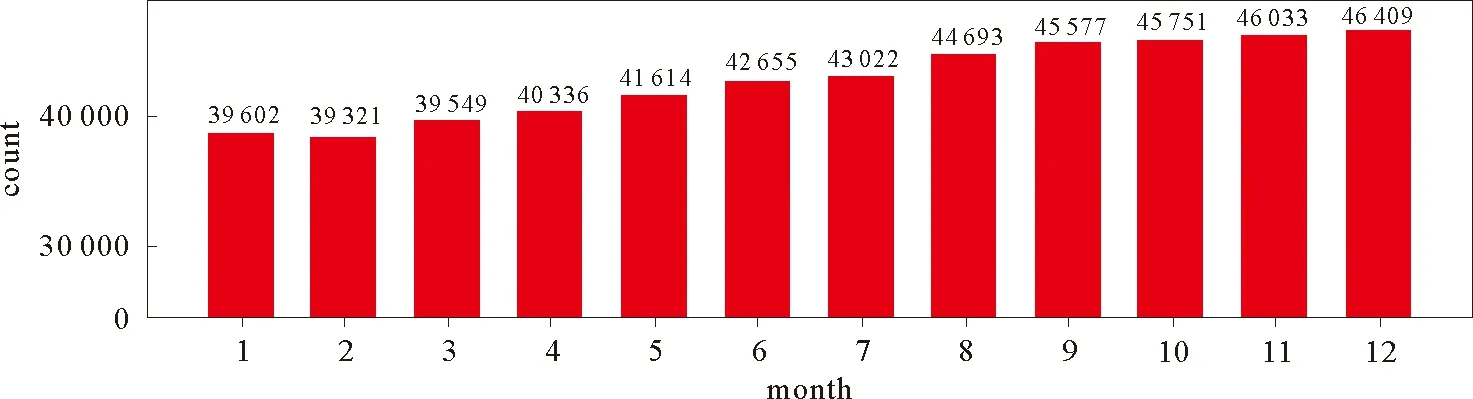
图6 各月社团数量统计Fig.6 Statistics on the number of associations in each month
由图6可知,该金融机构每个月社团数量在不断地增加。由于其用户数在不断地增长,基本符合实际情况。本文主要研究的是成员数大于3的社团,利用这些数据对上述算法进行实验验证。
1)社团发现与社团过滤。分别输入2011年1月—2011年12月12个月的网络快照,根据静态社团发现算法[9]来进行社团的识别与检测,再过滤掉社团成员数量不大于3的社团,得到12个社团集合。
2)信息提取。对12个社团集合进行信息提取,得到了以下几个表的信息。其中社团信息表中成员的详细信息包含在成员信息表中;成员信息表中每个成员的属性包含在成员属性表中,即成员信息表是社团信息表中具体成员的展开,成员属性表是成员信息表中成员的属性。
表1显示的是2011年1月份部分社团的信息,主要包括社团群号、时间、社团成员数以及其他属性。
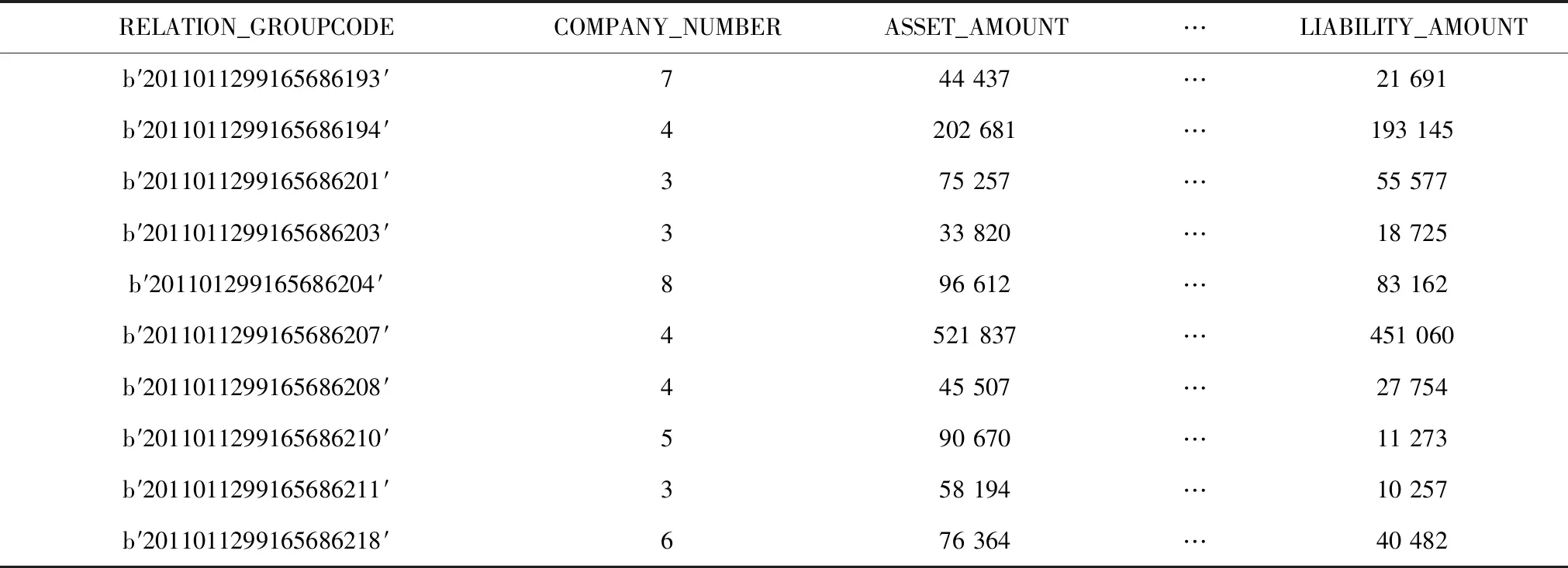
表1 2011年01月社团信息表Tab.1 Information sheet of associations for January 2011
表2是2011年1月份的3个社团,主要包括社团ID、时间、社团成员ID。关联群ID分别为′201101-1-152318-1299165686073′,′201101-1-152332-1299165686088′,′201101-1-152333-1299165686089′。每个社团包含的成员数量分别有5个,3个,3个。
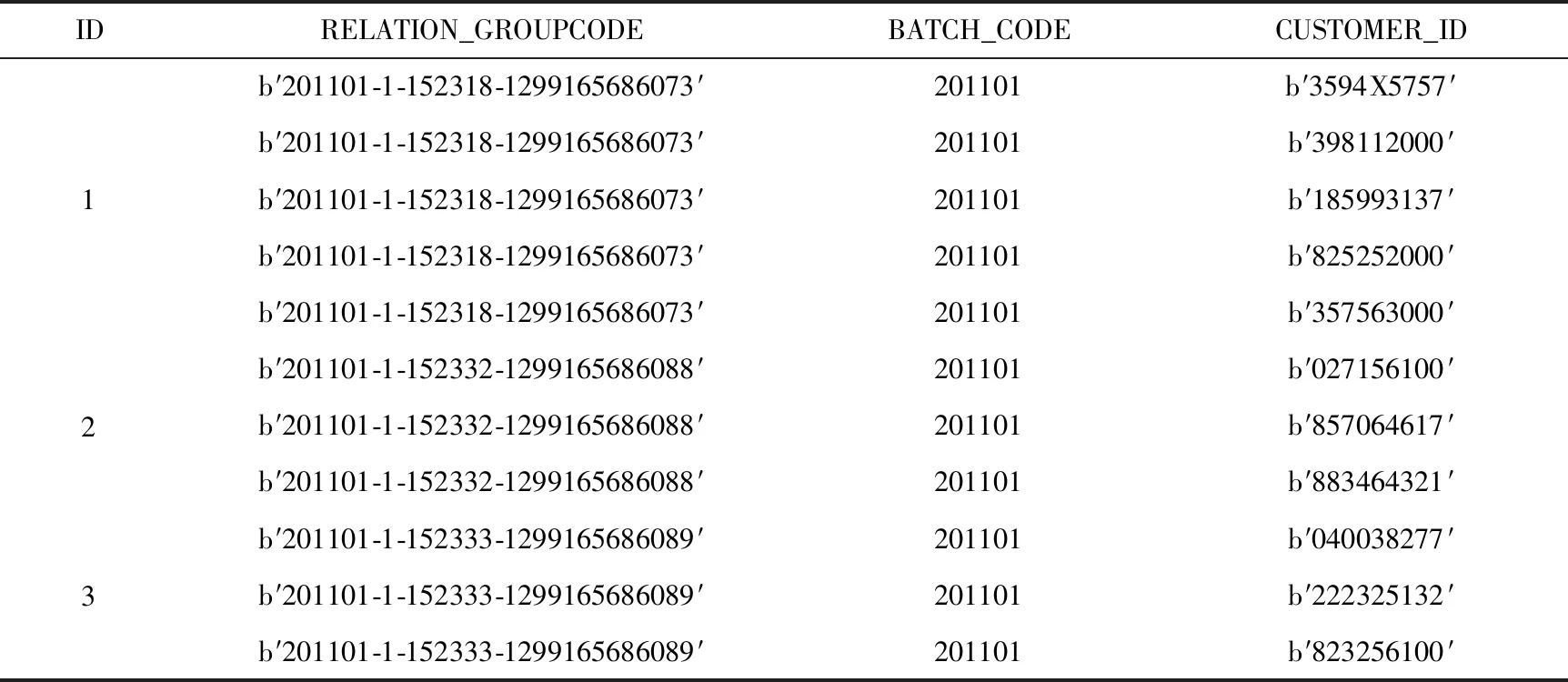
表2 2011年1月成员信息表Tab.2 Information sheet of member for January 2011
每个成员都有其自身的属性,表3展示了社团成员的属性。
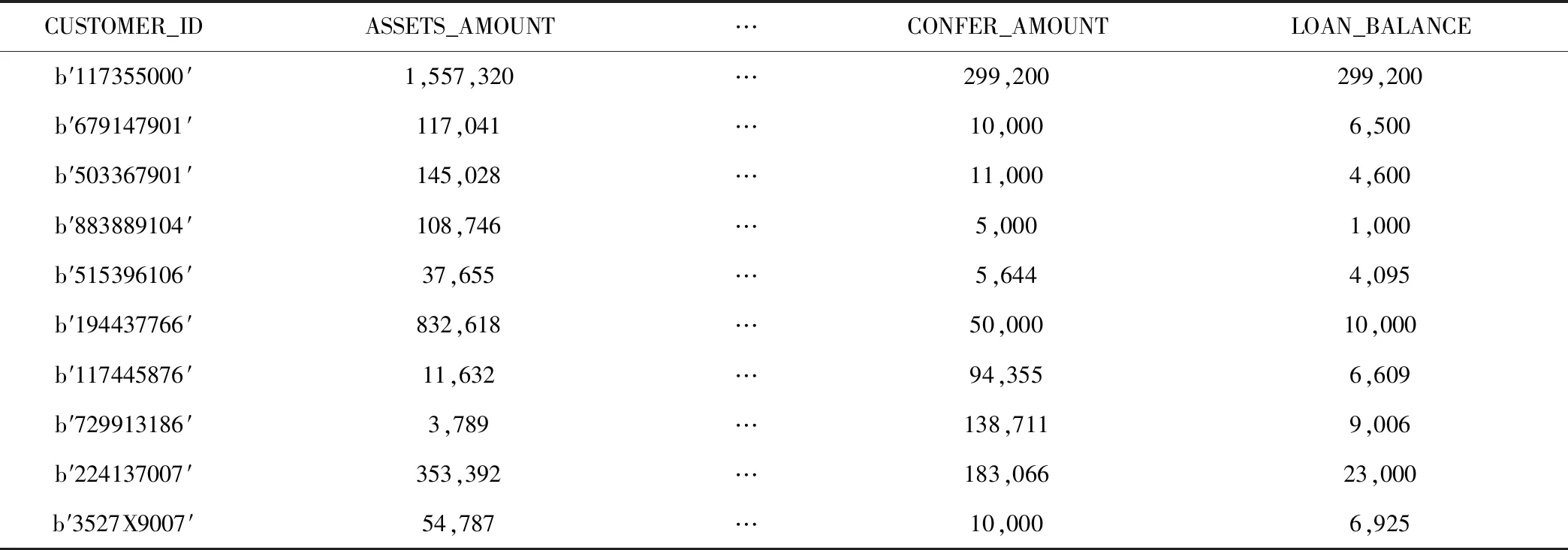
表3 成员属性表Tab.3 Information sheet of member attribute
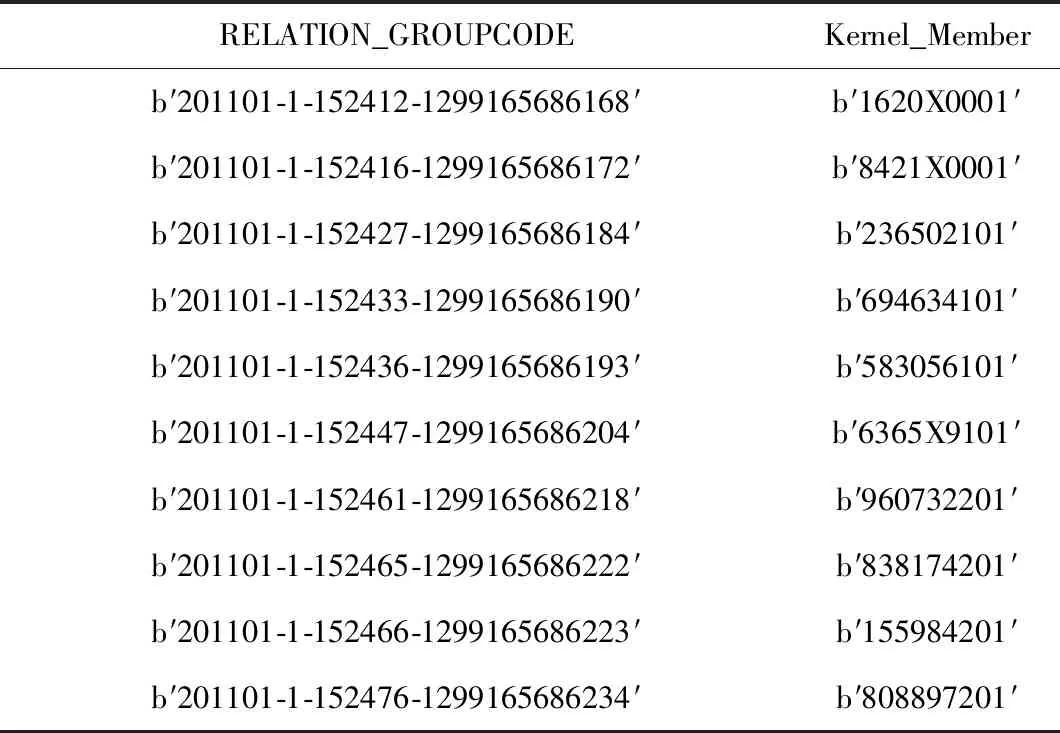
表4 核心成员表Tab.4 Information sheet of core member
利用前文提到的专家评分法,通过计算从而确定每个社团的核心成员。社团与核心成员表如表4所示。
3.3 实验分析
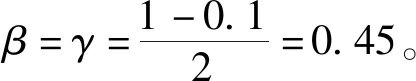
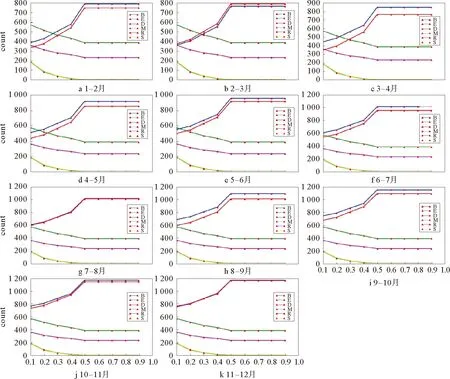
其中,B为社团新生(Birth)、D为社团死亡(Death)、M为社团合并(Merge)、S为社团分裂(Split)、E为社团膨胀(Expand)、R为社团收缩(shRink)。图7 1-12月份相邻两个月之间社团演化事件随α的变化统计Fig.7 Statistical changes of association evolution events with α between adjacent months in January-December
图7表示,当α从0.1到0.9变化时,相邻两个月之间发生的6类关键社团演化事件的统计。共有11个图,分别表示1-2月,2-3月,…,11-12月关键演化事件随α的变化。相邻两个月社团演化事件随β、γ的变化与图7类似。
结合银行已有的真实数据,发现当α为0.7-0.8左右,本算法所追踪到的社团演化与已有的社团演化相似度最大,说明核心成员对最终结果影响较大。分析原因是因为在银行业中,核心成员多为龙头企业,而这种个体有较大概率影响到他所在的社团。所以,在本文所提出的算法中核心成员的权重较大。当α=0.70,β=γ=0.15,综合加权的演化相似度所识别的关联群的准确率分别与非加权的核心成员、成员相似度、社团属性相似度的关联群识别准确率如图8所示。
由图8可以看出,综合加权识别准确率平均在86%左右,达到了较高的识别率。只用核心成员识别关联群的准确率高于其他两个低于综合加权的识别率,说明核心成员影响较大,但也有其他因素影响,如成员相似度。社团的属性识别率对于关联群的识别效果最差,且识别结果波动较大,说明在银行业中识别关联群此类指标重要程度最低。修改各指标中的超参数便可应用于其他的领域,因此,本文所提出的算法具有较强的灵活性。表5是当α取0.7时,β=γ=0.15时,从1月份到12月份一直存在的一些社团所构成的演化序列。

图8 关联群识别准确率Fig.8 Accuracy of association group identification
表5 1-12月份的一直存在社团序列Tab.5 The ever-presenting community sequence from January to December
4 结论
本文提出了一种动态社团追踪算法,通过对社团相似度、成员相似度以及核心成员相似的加权来衡量相邻时刻的社团相似度。随后引入多部图,以相似度为边权重,与超参数θ进行比较,来确定边是否保留。最终提取多部图中的有向路径,从而得到演化序列。并以实验证明了该方法的有效性与可行性,实验结果也说明了本文的算法具有较强的灵活性,当核心成员特别重要时,可以将核心成员的权重加大,而更关注社团的整体属性时,可以将社团的属性权重增大。缺点是当数据规模庞大时,由于O(N2)的复杂度,计算开销会很大,这是以后改进的重点。利用机器学习方法进行超参数的自动调整,也是进一步的研究方向。
在真实网络中,社团结构大量存在,本文是以银行业务数据进行了验证。也可以把这种追踪算法进行推广,应用在其他领域,如社交网络。所提出的社团追踪算法还可以进行反向推广,如可用于社团循迹。
猜你喜欢
作物学报(2022年8期)2022-05-29
环球人物(2022年4期)2022-02-22
新世纪智能(数学备考)(2021年9期)2021-11-24
小资CHIC!ELEGANCE(2021年32期)2021-09-18
高等继续教育学报(2020年3期)2020-03-14
当代陕西(2019年15期)2019-09-02
教育教学论坛(2018年19期)2018-07-24
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
商(2016年4期)2016-03-24
