
量子粒子群优化社区发现方法
2019-07-11 08:43杨忠保楚杨杰江登英
复杂系统与复杂性科学 2019年1期
杨忠保,楚杨杰,洪 叶,江登英
(1.黔南民族师范学院数学统计学院,贵州 都匀 558000;2.武汉理工大学理学院,武汉430070)
0 引言
社区结构是指网络拓扑结构中表现出来的社团化特征,整个网络由若干个社团构成。社区内部连接紧密,社区与社区之间连接比较稀疏[1]。社区发现对研究网络结构有重要的应用价值,社区发现致力于有效地寻找到网络中准确的社区结构[2],静态网络环境下,网络中的非重叠社区发现算法,大约分为三类:划分的非重叠社区发现算法,优化的非重叠社区发算法和其他非重叠社区发现算法。经典的划分的非重叠社团挖掘算法,如GN算法。然而优化的非重叠社区发算法中,其经典算法是遗传方法(GA-net)[3];多目标遗传方法(MOGA-net)[4];离散粒子群方法(DPSO)[5];多目标离散粒子群方法(MODPSO)[6];多目标量子粒子群方法(QDM-PSO)[7]。遗传算法优化社区发现算法将网络的节点与遗传算法中的遗传基因相映射,而(量子)粒子群优化社区发现算法将网络的节点与算法中的粒子相映射。社区发现算法从不同角度出发,结合复杂网络的拓扑结构,解决复杂网络中的社区发现问题。
社区发现算法对初始节点的位置敏感,如果初始节点处于社区边缘,那么效果差,反之,则效果较好,这导致算法稳定性较差。算法的收敛条件缺乏自适应性,从网络的种子节点度出发,每次更新社区节点只需用到社区内部节点和边缘节点的邻节点的信息,算法的时间复杂度较低,但因没考虑全局信息,容易受种子节点影响,这导致算法精度不是很高。本文采用一种离散量子粒子群优化算法的社区发现(NQD-PSO),将核心节点与邻居的普通节点构成模体,该模体为量子粒子群算法的初始值。本文利用了三角形模体来判断社区的稳定性度量问题,从而量化社区结构稳定性。同时,采用压缩因子函数调节全局和局部搜索模型,结合量子粒子群算法,使该算法全局收敛。模拟和真实数据集上的实验结果均表明,相比于其他算法,NQD-PSO算法可以挖掘更高质量的社区结构。
1 基本概念
含权的复杂网络G=(V,E,W)中,V={vij|i,j=1,2,…,n}表示网络中的节点集合,E={eij|i,j=1,2,…,n}表示网络中的边集合,W={wij|i,j=1,2,…,n}表示网络中的边权集合,其中,wij∈{pr,nr}表示相关系数,如果两个节点的相关系数为正数,pr为正相关系数,如果两个节点的相关系数为负数,nr为负相关系数。网络中有节点数为n,边数为m,如果节点vi与节点vj中间有边相接,则eij=1,否则,eij=0,所以节点vi的度ki表示为:ki=∑vj∈Veij。节点vi的点权si定义为与节点i关联的边权之和,也称为点强度。
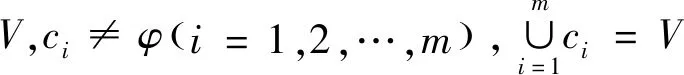
定义2节点vi与节点vj的共同邻居定义为
Cij=neighbor(vi)∩neighbor(vj)
(1)
其中,neighbor(vi)表示核心节点vi的邻居节点集。网络的模体结构介于节点与社区结构之间,少数几个节点连接构成(共同邻居),模体是社区内部成员之间基本的连接模式,,是网络中一种重要的结构特征。模体作为网络的一种连续基元,基元(节点与模体)是网络的基本组成部分,它能揭示网络的演化规律。
定义3设核心节点的标签集为:Ω(t)=(v1,v2,…,vk);则最大核心节点的度定义为:
(2)
(3)
其中,vt为核心节点,则kt,st分别表示重新排序后的节点度和点强度。核心节点对网络社区结构的运行具有主导的作用。网络中的节点的重要程度不同,核心节点具有较高重要性,而普通节点则是网络中的参与者。社区是由核心节点和追随的普通节点构成,划分网络社区结构,必须要找出网络社区的核心节点。如果这样单纯依赖排序结果,选择初始核心节点会带来潜在风险,多个核心节点可能在相同社区,按从大到小的选择,可能会把一个大的社区分解为若个小社区;为了避免这些问题,在核心节点选择上附加一些约束:为了避免核心节点与外界节点连接较少,选择核心节点的点强度必须大于网络中所有的节点的平均点强度。先后选出的若干个网络的模体在同一社区,当前选择的模体必须和已有模体是相邻的。核心节点与普通节点相连接构成模体,把网络划分为k个模体,记为G={u1,u2,…,uk}且ui∩uj=φ。
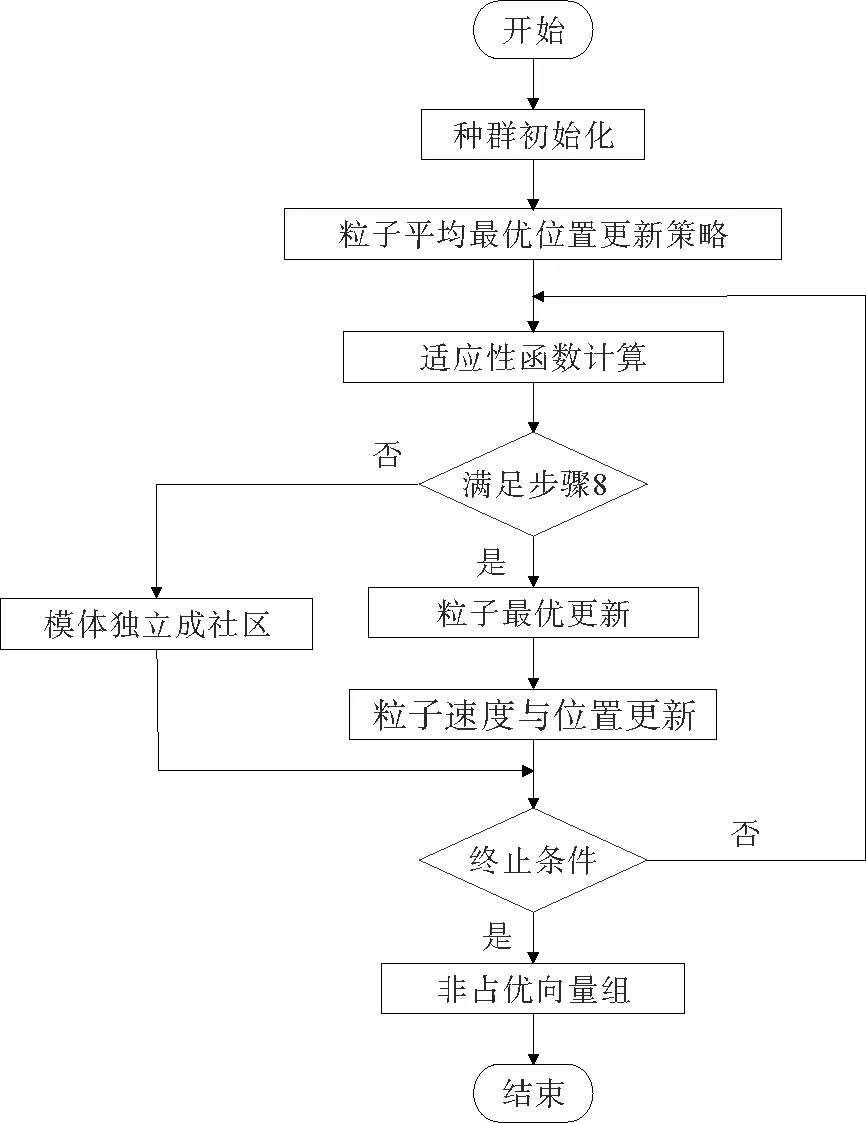
图1 NQD-PSO算法流程图Fig.1 Flow chart of NQD-PSO
2 量子粒子群优化社区发现方法
本文以量子粒子群优化算法为背景知识解决网络的社区发现问题,将核心节点和邻居的普通节点构成的模体当作量子粒子群的粒子,通过量子粒子群算法来改变粒子位置的归属,旨在挖掘出高质量的社区结构。下面是NQD-PSO算法流程图,如图1所示。
NQD-PSO算法的第1行至第2行属于核心节点的模体从网络中划分出来;第3行至第16行属于量子粒子群优化社区发现方法,其中,第5行至第14行属于算法的循环过程,第10行属于社区扩展过程,第13行属于模体独立构成新的社区。时间复杂度分析:n表示网络节点数目,m表示社区结构的数目,k表示网络中的模体的数目。NQD-PSO算法的第1行至第2行用时间为O(n),第3行至第16行属于量子粒子群优化社区发现过程,其中,粒子解码用时间为O(k),循环过程用时间为O(m·k),粒子种群为p,迭代次数为g。则NQD-PSO算法时间复杂度为:O(gplog(m+m·k+n))。NQD-PSO算法流程框架如表1所示。
2.1 适应度函数
适应度函数是测量网络拓扑性的目标函数,它是依赖于社区的三角形模体(三个节点的模体)决定该社区的稳定性,从而量化社区结构质量。该系数与适应度系数的关系,即构造模体加权社区聚类定义如下[10]:
(4)
其中,t(u,NP)表示模体u与节点集合NP构成三角形模体的数目;vt(u,V)表示模体u与节点集合V至少构成一个三角形模体的节点数目;|NPu|表示节点集合NP除去节点u的模体的数目。
2.2 粒子群算法基本原理
本文采用的是压缩函数代替加速因子[11],主要调节全局和局部搜索模型。离散粒子群算法的粒子位置更新如下:
(5)
其中,sigmoid(x)为压缩因子函数定义:
(6)

(7)
2.3 量子粒子群更新规则
为了避免粒子群算法收敛于局部极值,结合量子粒子群[12],量子粒子群更新策略保证全局收敛。粒子平均最优位置更新策略数学描述如下:
(8)
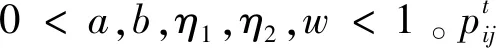
(9)
(10)
2.4 粒子编码与解码
粒子编码采用NQD-PSO中基于模体邻居的有序表的编码方法。计算各个模体的适应性函数,选择模体合并或分离。如果两个模体合并,那么加权社区聚类函数的值会增加,反之,两个模体会分离。采用字符串编码方式来表示社区标签,其初始标签为NP(i)(i=1,2,…,k),设NP(1)=1,如果NP(1)=NP(2),社区与模体合并。如果NP(1)≠NP(2),那么NP(2)=2,模体独立成社区,以此类推,如果此时为k时是算法最大社区标签值才结束。如图2中,选择节点1与节点7为核心节点。确定模体数目,如果核心节点1与节点2,3,4,8相连,构成模体,则核心节点1的邻居节点集合为{2,3,4,8};则该模体的加权社区聚类函数的值为:5/7。另一个模体的加权社区聚类为:1.两个模体合并后,加权社区聚类函数的值会减少,所以分离成为两个社区,不同社区的节点所属的颜色不同。这样的编码方式可以保证每一个粒子都是有效的。解码步骤是将编号进行排序形成邻居有序表,将该表转化为与图相应的社区结构,保证参与到同一个组中的节点被分配在一个集合中[13]。解码操作可以在线性时间内完成。该表示方法的主要优点:社区的数目将在解码时自动确定;避免非法粒子产生,能减少优化问题中的约束条件,并且保证社区结构的稳定性。对粒子的编码和解码操作如图2所示。
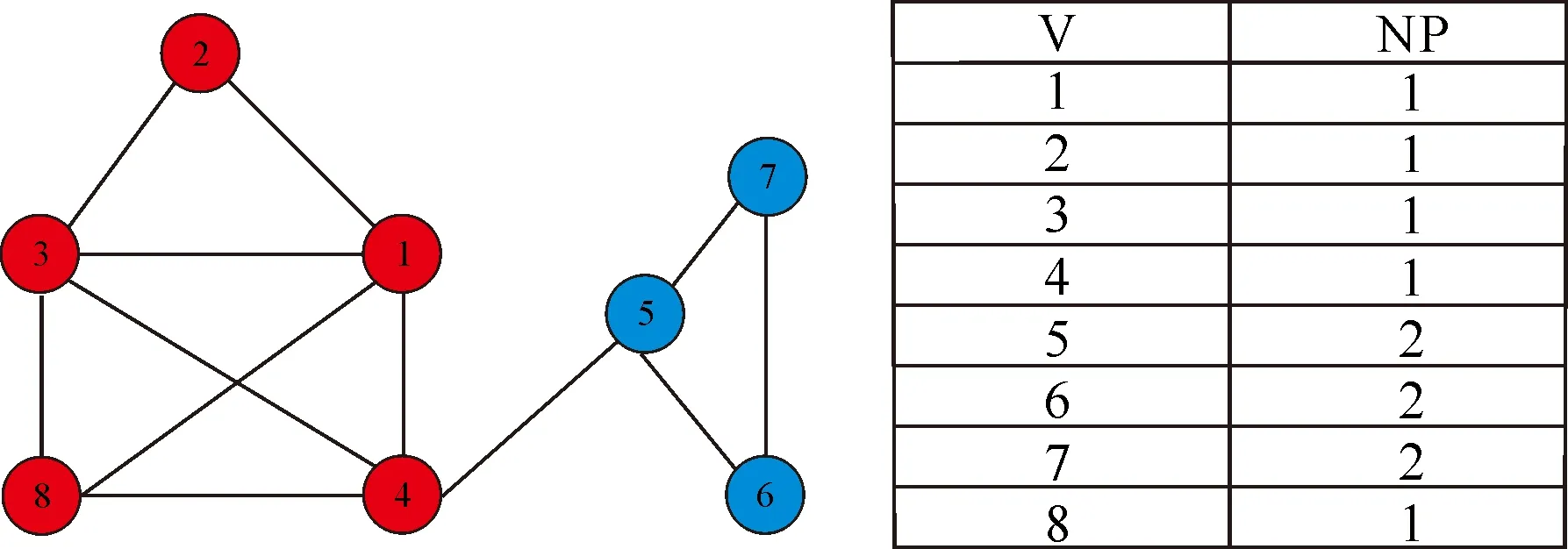
图2 粒子编码方式和解码方式Fig.2 Particle′s coding and idecoding
3 实验结果与分析
实证量子粒子群优化算法的社区发现算法的性能评价,实验环境设置为:windows 7操作系统,AMD A-82.10GHz,500GB内存。根据量子粒子群算法参数实验设置可知:它的控制参数β采用固定值:0.6或0.8时,对多数函数取得较好的优化结果[12];控制参数β的变化对规范互信息量和模块度没有影响[7]。所以本文控制参数β采用固定值为0.8.设置实验参数与QDM-PSO算法相同,方便对比算法性能,实验参数设为:N=Tmax=100,c1=c2=2,η1=η2=0.15,所有的算法均在Matlab(R2010b)编码实现,各种算法的结果为运行50次取平均值。
3.1 评价标准
采用2种常用的社区发现算法评价指标,包括规范互信息量(normalized mutual information,NMI)和模块度(modularity)。
规范互信息量用来描述划分结果与真实结构之间的相关性,它的取值范围为[01],NMI的值越接近1表示划分结果越好。数学描述如下:
(11)
其中,A表示真实网络社区;B表示实验得到的社区;cA与cB分别表示真实网络社区个数和实验得到的社区个数;N是混淆矩阵,Nij代表了ci(ci⊂cA)和cj(cj⊂cB)的公共节点数,Ni.与N.j分别代表该矩阵中第i行和第j列中的元素的和,且Nt=∑i∑jNij.
模块度用来对社区划分的整体质量做出一个定量的评价,根据正负相关的边权情况,采取合适性能的模块度,根据文献[14]改进定义如下:
(12)
3.2 算法比较结果评价
N=128,k=kmax=16,u=0.1,cmin=cmax=32,On=Om=0
这就是生成Girvan和Newman所提出的GN基准网络数据[16],该数据集含有节点128个,含有1024条边,而每个节点的平均点强度为8和平均度数为16,将所有的节点平均的划分成4个社区,每个社区中含有32个节点。真实数据集的基本信息如下表:
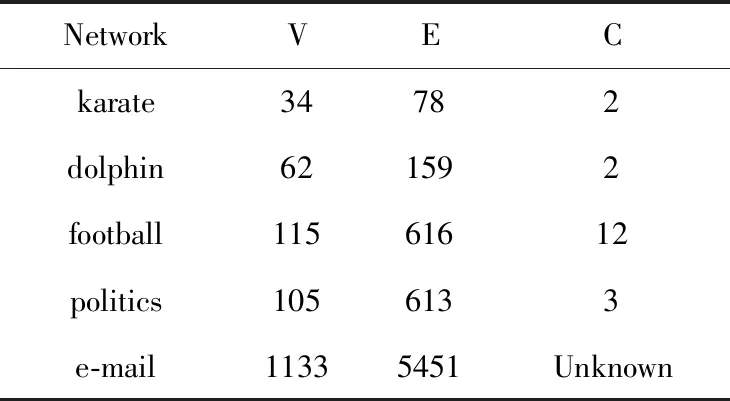
表2 5个真实数据集的基本信息[6]Tab.2 Basic information for 5 real data sets[6]
网络中含有一个模糊参数u,表示为任一节点vi与社区外节点vj形成的链接占节点vi之度的比率,每个节点vi和同一个社区内的其他节点有1-u的连接率,和网络其他社区的节点的连接率为u。该人工数据集在模糊参数u为增长0.05时,间隔随机生成了11个不同的社区结构。随着该值的增大,则网络社区结构的模糊程度越高,越不易划分社区结构。本文设u值在0到0.5之间,表示所划分的社区为强社区结构。网络中的社区的真实划分情况是已知的,所以分别采用规范互信息量(NMI)和改进的模块度(SQ)作为评价算法准确性的指标。本文所提的算法和其他算法得到平均NMI值比较结果、SQ值最大时对应的网络划分社区结构、SQ值比较结果和真实数据NQD-PSO算法与QDM-PSO算法的SQ值比较如图3所示。
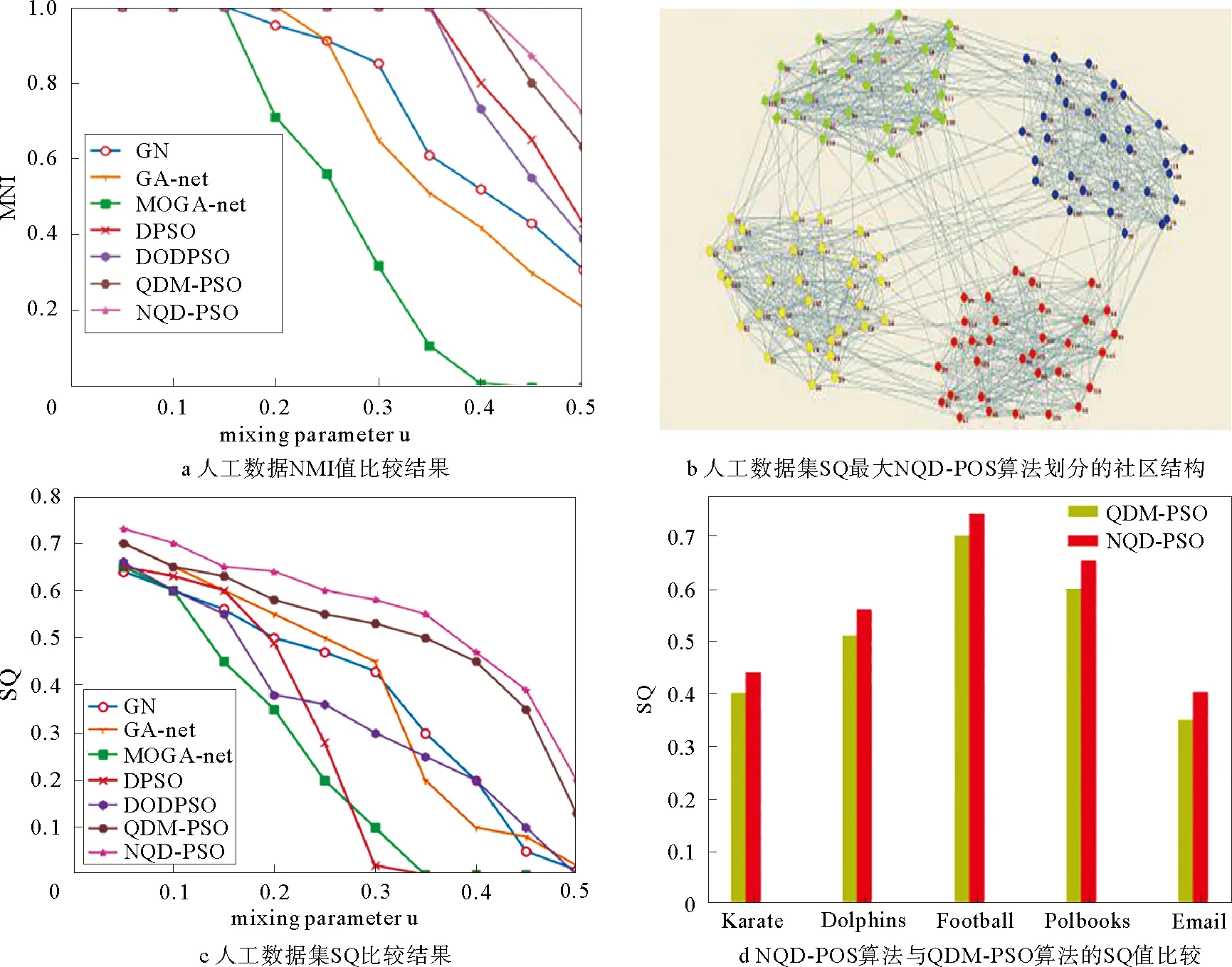
图3 NQDM-PSO算法与其他算法比较结果Fig.3 Comparison between NQDM-PSO and other algorithms
当混合参数u值很小时,意味网络中的社区结构是较清楚的。无论是传统GN算法,还是其他算法,本文提到的NQD-PSO算法的性能均能比这些算法有更高的准确值。当u值在(0,0.4)之间,NQD-PSO算法得到的平均NMI均为1,模拟数据集和真实数据集得到的SQ值都在0.4以上,具有较清楚的网络划分社区结构。当u>0.4时,网络中的社区结构相对的模糊,探测的难度更高,MOGA-net算法得到的NMI值接近为0,它已经不能检测出网络中的社区结构,但本文所提的算法依然比其他算法具有较高地平均NMI值。整体上,随着模糊参数的增大,网络社区结构模糊度就越高,所有的算法的性能表现就越低;但实验结果表明了本文所提出的算法性能比其他算法社团划分效果较强。
4 结语
本文提出一种以模体为初始值的离散量子粒子群优化算法的社区发现,构造模体加权社区聚类函数为算法的适应性函数;加权社区聚类函数评价模体与社区的稳定性,从而量化社区的稳定性。NQD-PSO算法在模拟网络数据集和真实数据集进行性能实验,NQD-PSO算法比其他算法划分网络社区结构较为清楚并且效果更好。但没有考虑到重叠节点[17]的作用,重叠社区发现算法将是下一个重点研究的方向。
猜你喜欢
橡塑技术与装备(2022年3期)2022-03-17
量子电子学报(2022年1期)2022-02-25
小学科学(学生版)(2020年1期)2020-01-19
科学大众(中学)(2019年2期)2019-04-08
智能计算机与应用(2019年1期)2019-01-11
测控技术(2018年10期)2018-11-25
浙江工业大学学报(2017年5期)2018-01-22
西安工程大学学报(2016年6期)2017-01-15
自动化学报(2016年5期)2016-04-16
