
基于人工智能算法的催化裂化装置汽油收率预测模型的构建与分析
2019-07-31 10:10戴超男
石油学报(石油加工) 2019年4期
杨 帆,周 敏,戴超男,曹 军
(1.联想数据智能应用实验室,四川 成都 610041;2.四川理工学院 过程装备与控制工程四川省高校重点实验室,四川 自贡 643000;3.华东理工大学 机械与动力工程学院,上海 200237)
催化裂化是重质油在酸性催化剂存在下,在500 ℃左右、1×105~3×105Pa的压力下发生以裂化反应为主的一系列化学反应生成轻质油、气体和焦炭的过程。目前,我国催化裂化装置生产的柴油和汽油约占成品柴油和汽油总量的30%和70%左右,已经成为重油加工的最重要方法之一[1-5]。催化裂化的工艺过程和产品收率优化的建模分析一直是石油加工领域研究的热点和难点。目前常用的催化裂化过程建模方法有机理建模法[6-8]和统计建模法[9-11]。由于催化裂化是一个高度非线性和相互强关联的系统,其中原料油性质、反应再生催化剂性质,以及反应操作工况条件等因素都会影响到反应过程和产物收率,使用传统的机理模型很难全面地去描述,大数据技术则是解决这一问题的有力工具。
目前,大数据技术正处于其应用的高速发展期,并已经在电子商务[12]、电力[13]、航空[14]以及医疗[15]等领域取得了巨大的成功。随着石化行业生产过程的自动化控制水平日益提高和工艺流程控制系统的不断完善,各种原料数据、催化剂性能数据以及操作工况参数等都能从装置的数据库平台中实时采集。这些数据记录了反应过程的特征、性能和变化,反映了反应过程的本质,大大改进了原来数据收集的不完整。已经积累的海量过程数据为数据挖掘技术在石化领域的应用提供了良好的基础条件。将数据挖掘技术应用于石化反应过程,建立完善的统计学分析模型,可缩短新工艺的开发研究周期、优化工程设计方案、优化装置操作和实现装置的在线优化,多角度全方位地对反应过程及其影响机制进行分析,从而可进一步提高原料利用率和所需产品的产率,具有传统机理分析优化方法无法比拟的优势[16]。这一优势在催化裂化工艺操作工况的优化和产品收率的预测方面体现的更为明显。
目前,已有研究者将神经网络、支持向量机等人工智能算法应用于优化催化裂化工艺。Zahedi等[17]使用误差反向传播神经网络和径向基神经网络建立了催化重整的预测模型,并采用单变量优化方法优化了温度和压力等工艺参数,使汽油收率从80%增加到82%。李鹏等[18]在中国石化开发的炼油技术分析与远程诊断平台上,运用大数据数据处理技术和积累的海量的催化运行数据进行数据挖掘与分析,对催化裂化装置报警、结焦等问题进行深入探索研究与分析,解决了催化裂化装置报警问题、结焦问题和收率问题,从而进一步提升了催化裂化装置运行水平。陈露[19]通过整理大量原油评价数据,建立了原油性质和催化裂化反应产物分布数据之间的模型,并采用化学计量学校正了该模型,结果表明所建立的原油评价模型具有较好的适用性。孔金生等[20]对催化裂化数据进行了预处理并建立了粗汽油干点的神经网络模型,结果证明该模型具有可靠性。方伟刚[21]以中国石化九江分公司催化裂化装置提供的实时过程数据为基础,进行了产品收率优化的研究,建立了合适的原料油性质聚类模型和产品收率神经网络模型,并使用优化算法对操作条件进行了优化。
笔者以某炼化公司催化裂化装置提供的实时过程数据为基础,建立了合适的原料油性质聚类模型和产品收率预测模型,然后使用优化算法对操作条件进行优化。计算分析的结果有助于进一步提升催化裂化装置的汽油收率,进而增加企业经济效益,并为工业操作提供可靠的技术支持。
1 某炼化公司催化裂化装置实时过程数据预处理
笔者使用的数据均采集自某石化企业的LIMS(Laboratory information management system)及DCS(Distributed control system)系统。通过LIMS系统可采集到原料油和再生催化剂性质的相关数据,其分析频次为1次/周。为了采集到足够多的样本,LIMS数据采集时间段从2016年8月4日至2018年3月20日共近2年。通过DCS系统可采集到操作变量和系统物料平衡数据,每隔15 s记录1次,装置数据采集时间段从2017年10月21日至2018年 4月25日共6个月。将DCS和LIMS的数据按“时间戳[分割符]指标值”的格式整理,每条数据由时间戳和指标值两个字段构成。为了方便进一步清洗以及计算,将所有数据按时间戳升序进行排序。
1.1 数据清洗
由于一些客观的装置条件以及人为因素,例如数据采集系统出现问题、数据存储/传输过程中发生错误等,采集到的数据可能存在部分数据缺失、重复、不完整、噪音、异常等情况;除此之外,原始数据中还存在部分冗余数据。为了保证训练数据的正确性和有效性,同时提高模型运算的效率,需要对数据进行清洗。对于不同类型的数据异常,相应的清洗方法如下:
①数据格式错误。每条数据必须满足给定的格式,其中第一个字段是timestamp类型,第二个字段是float类型。可以直接删除格式错误的数据。
②数据值异常。计算每个指标的均值μ和标准差σ,使用莱特准则,将(μ±3σ)范围外的数据定义为异常值,并使用时间临近的数据做加权平均作为替代。
③数据重复。同一指标的数据中可能存在多条相同的时间戳记录,需要选择其中合法的数值并取均值。
④数据缺失。缺少某些应有时刻的数据,可以将缺省数据点看作异常值,使用时间临近的数据做加权平均。
1.2 数据时间对齐
针对不同的分析指标,其监控采集频率可能不同。为了便于数据分析与计算,需要将这些数据在时间上对齐:即对所有分析指标使用统一的时间间隔。通过分析数据的特点,笔者将60 min作为参考时间间隔。对于采集时间间隔小于60 min的数据,需要做采样处理,通过设置60 min大小的时间窗口,取该时间窗口里的数值的均值。对于采集时间间隔大于60 min的参数,需要做插值处理。根据不同系统的采集频率,一般DCS系统采集到的数据需要进行采样处理,而由LIMS系统收集到的数据则需要进行插值处理。笔者采用3种插值方法:
①直接使用前一次的测量值插值。
②线性插值。
③二阶B样条插值。
以监测点指标数据“混合原料密度(20 ℃)”在2016年11月至2017年3月30日之间的数据为例,该数据的原始分布如图1所示。
按照以上思路分别使用3种插值方法计算,结果数据如图2、3及4所示。其中:图2为直接使用前一次的测量值插值所得数据;图3为线性插值处理结果;图4为二阶B样条插值处理结果。3种插值方法都可以弥补时间间隔内的缺省值,且处理得到的结果相似。

图3 对图1数据线性差值处理结果Fig.3 Results of processing linear interpolation for data of Fig.1
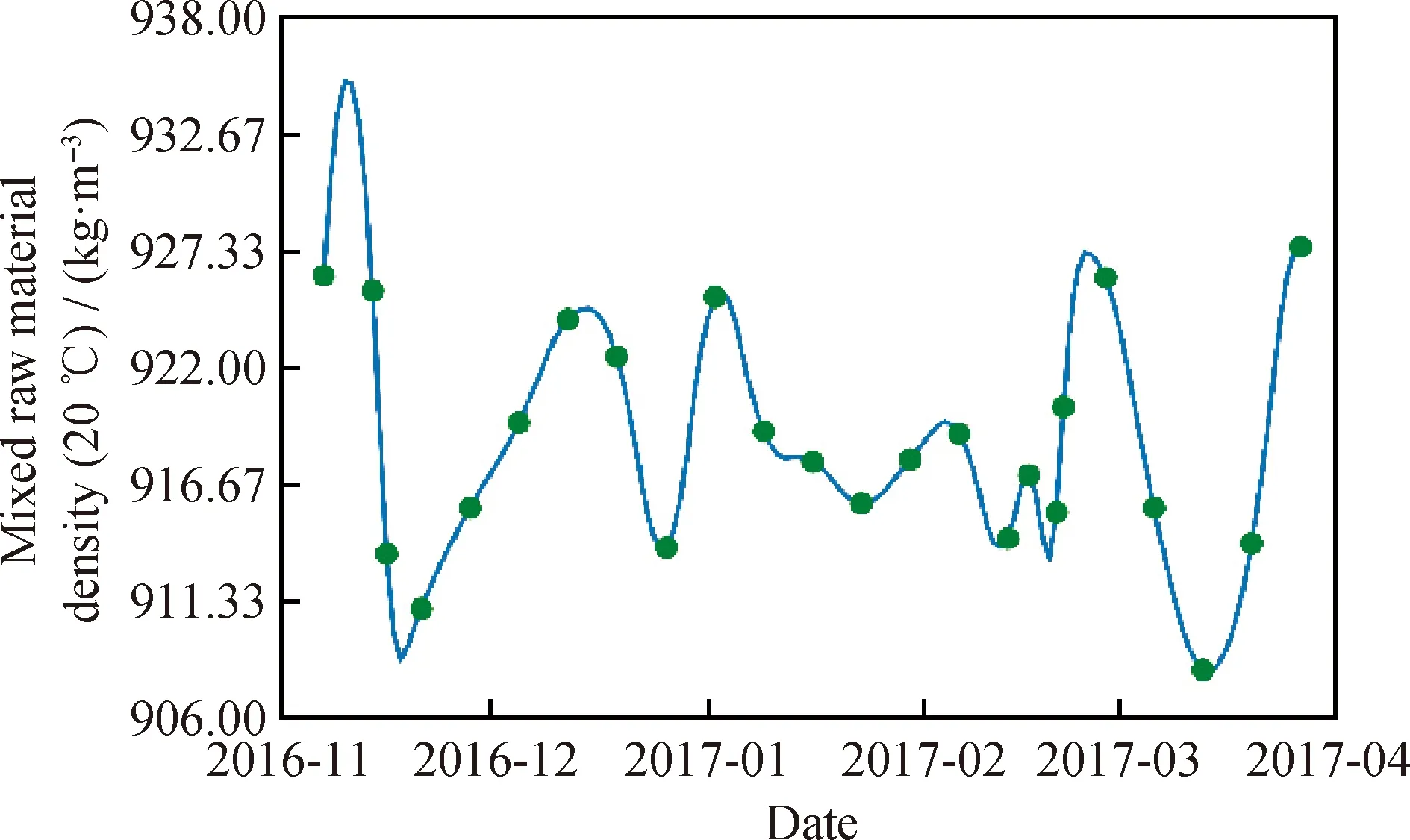
图4 对图1数据二阶B样条插值处理结果Fig.4 Results of processing quadratic B-spline interpolation for data of Fig.1
2 针对已处理的某炼化公司数据构建预测模型
2.1 预测模型的选用
利用机器学习模型预测产品收率的方法已经被一些文献提及或使用,其中较大比例采用神经网络构建模型[20]。神经网络的优点在于拟合能力非常强,理论上能逼近任意非线性映射,且自学习与自适应性强。另一方面,由于在神经网络模型中有较多超参数需要确认,往往需要较长时间的反复调参,才能取得好的效果;同时,其可解释性较差,不利于研究输入向量各分量之间以及它们与输出的相关性。
根据以上分析,笔者决定采用另一种拟合能力较强的模型:由多棵决策树构成的集成学习模型。树模型对于真实分布的拟合效果较好,具有一定的可解释性,且可以用于特征筛选。多决策树模型的典型代表是使用bagging方式集成的随机森林模型和通过boosting方式集成的梯度提升决策树(Gradient boosting decision tree,GBDT)模型。通过对比这两种模型在实际数据集上的应用,发现GBDT在产品收率上的表现更好。因此,本研究选择使用GBDT构建预测模型。
GBDT是一种迭代的决策树算法,通过采用加法模型(即基函数的线性组合),不断减小训练过程产生的残差来完成数据分类或者回归。在训练过程中,每轮迭代开始时,计算损失函数的负梯度在当前模型的值,将其作为残差的估计去拟合一个回归树;每次迭代都会生成一颗新的决策树,将每轮训练得到的树加权求和,可以得到输出的最终模型。GBDT的主要特点,即是通过在每轮训练中让损失函数尽可能快地减小,以便尽快地收敛达到局部最优解或者全局最优解。
2.2 模型特征的选取
筛选DCS与LIMS系统中与汽油产率正负相关性较强的指标是一个优化模型特征选择的过程。它们的测量值变化与汽油收率线性相关系数较高,一定程度上可以更好地反映或逼近真实收率的变化趋势,可能是影响汽油收率的关键指标。在模型的构建中,考虑将这些潜在的关键指标作为特征,可以有效降低训练数据集的维度,同时提高模型的学习性能。
采集到的LIMS和DCS数据中包括近2000个分析指标,其中大部分不适用于产品收率预测,因此需要对已有的分析指标进行筛选。首先,使用大数据分析的方法,筛选出与产品收率相关性较高的指标。使用Pearson系数作为考察相关性的依据,将采集到的指标与汽油收率按60 min的时间粒度,依照2.2节中介绍的方法进行时间对齐后,计算Pearson相关系数。其中,DCS数据中与汽油收率正相关性较高的27个指标如表1所示,负相关性较高的22个指标如表2所示。
对于LIMS系统中的数据,由于无法明确LIMS数据中各个指标在监测间隔里的变化过程,基于现有数据无法比较3种不同插值方法的优劣。考虑到仅采用一种插值方法得到的数据可能有一定偏差,笔者选择同时使用3种插值方法分别处理数据。LIMS系统中计算得到的正相关性较强的21个指标如表3所示,负相关性较强的25个指标如表4所示。
除此之外,由于催化裂化反应的特性,可以从工业经验角度考虑,筛选出影响产品收率的关键指标作为模型特征。根据催化裂化产品的生成过程,并结合工业经验,可以筛选出部分线性相关性不高,却对产品收率有重要影响的经验指标,包括提升管反应器出口温度、原料中饱和烃与胶质含量、汽提蒸汽流量、催化剂活性指数等[20]。将这些重要指标作为参照指标,计算其与产品收率的相关性作为参照相关性,用于从以上正负相关性较强的指标中筛选出相关性大于或接近参照相关性的指标。作为参考的重要因素的相关性如表5、6所示。
经过筛选的指标的因变量需要进行人工去除。整理筛选出的正负相关性较强指标,并结合工业经验参考指标,共同作为候选原始特征。通过对所得的原始特征做尺度变换、多项式交叉、差分等特征工程处理,得到可以应用于GBDT算法模型的新的特征。

表1 DCS数据中与汽油收率正相关性较高的指标Table 1 Factors with high positive correlations for gasoline yield in DCS data

表2 DCS数据中与汽油收率负相关性较高的指标Table 2 Factors with high negative correlations for gasoline yield in DCS data

表3 LIMS数据中与汽油收率正相关性较高的指标Table 3 Factors with high positive correlations for gasoline yield in LIMS data

表4 LIMS数据中与汽油收率负相关性较高的指标Table 4 Factors with high negative correlations for gasoline yield in LIMS data

表5 DCS数据中参照指标与汽油收率的相关性Table 5 The correlations between reference factors and gasoline yield in DCS data

表6 LIMS数据中参照指标与汽油收率的相关性Table 6 The correlations between reference factors and gasoline yield in LIMS data
2.3 预测模型的构建
目前普遍用于构建产品收率预测模型的算法都为神经网络算法,少有研究使用树类模型对收率进行预测。相比之下,树类模型的可解释性与对模型特征的筛选作用,使得其在解释特征在模型中的重要性与工业优化方面更有潜力与优势。笔者选择树类模型中的GBDT算法构建预测模型,模型构建的框架如下所示,其中模型输入为训练数据集T={(x1,y1),(x2,y2),…,(xN,yN)},xi∈Rn,yi∈R,迭代的次数为t,损失函数为L(y,f(x)),输出GBDT模型:
(1)特征选择:根据特征的权重w从特征集中抽取p比例的特征。
(2)初始化基学习器:
(1)
(3)对于迭代次数t=1,2,…,T:
a.对训练样本i=1,2,…,N,计算负梯度(rti):
(2)
b.利用rt拟合1个回归树,得到第t棵回归树 (Treet),并对于叶子区域计算最佳拟合值。
c.更新模型ft(x)=ft-1(x)+Treet。
(4)得到模型:
(3)
GBDT算法的主要特点在于在训练中将损失函数的负梯度在当前模型的值作为残差估计,并利用线性搜索估计回归树叶结点区域的值,使损失函数最小化,从而更新回归树并得到最终的模型。它的每一次迭代都会在残差减少的梯度方上建立新模型,因此GBDT算法会更关注梯度比较大的样本。
笔者采用GBDT模型的开源模块实现lightGBM回归方法进行学习。为了保证筛选出的所有特征指标都有合理的数据,截取2017年10月21日至2018年3月20日的数据作为整体数据集,选择前4个月的特征数据和实测收率值作为训练样本,剩余的数据作为预测样本用以验证模型的准确性。通过经验与局部网格搜索的方式调整其超参数并对比其交叉验证的结果,最终使用平均绝对误差MAE作为目标函数进行训练,设置回归树棵数为106,对应学习率为0.065,其余参数使用默认数值。其中,可由式(4)计算MAE:
(4)
使用现有采集监控数据,对相对于训练集的未来时间节点进行预测,并对比预测值与真实值,可以有效检验构建模型的拟合程度。如果需要对真实未来的产品收率进行预测,同样需要对相同时间段内的指标数据进行采集。
3 结果与讨论

(5)
2016年9月至2017年11月之间真实汽油收率和处理掉其中的异常值后汽油收率的分布如图5所示,图6为图5(b)的数值分布。由图6可以看出,真实汽油收率主要分布在47%左右,基本呈现左右平衡的态势,近似正态分布,且分布相对较为集中,说明汽油收率的整体输出范围较小。在这种情况下,即使使用汽油收率的均值来进行预测,其准确率也能够达到98%左右。
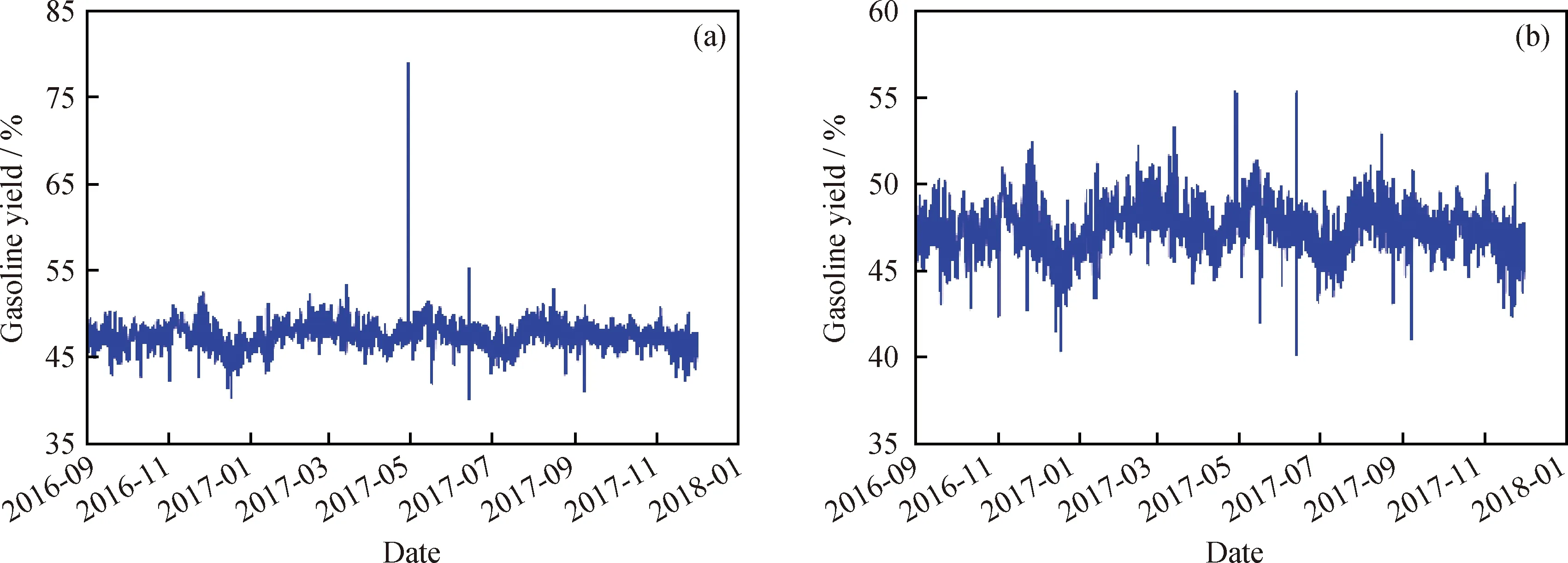
图5 2016年9月至2017年11月之间实际的汽油收率和去掉异常值后的汽油收率Fig.5 Actual gasoline yield and gasoline yield without outliers between September 2016 and November 2017(a)Actual gasoline yield;(b)Gasoline yield without outliers
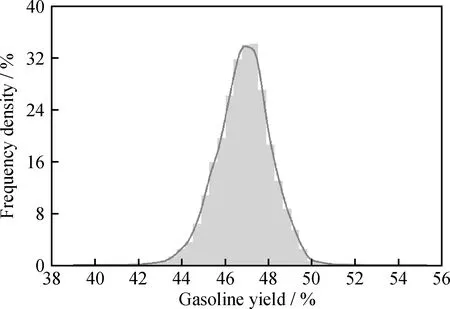
图6 对图5(b)的统计收率分布Fig.6 Statistical yield distribution for Fig.5(b)
针对真实汽油收率的整体输出特点,通常意义的回归准确率,并不能很好地反映预测模型的拟合效果。结合原评估方法,考虑去掉收率的均值对变化程度的影响来考察模型对收率变化的预测能力。笔者选择同时使用决定系数R2作为评估标准,R2是对模型进行回归后,评价回归模型系数的拟合优度,其计算方法如式(6)所示。
(6)
R2的取值范围一般为负无穷到1,预测值与真实值的残差平方和越小,该值越接近1,表明预测值对真实值的拟合优度越大,可解释程度越高。该标准可以反映模型输出对真实产率的拟合程度。与Pearson相关系数不同的是,相关系数一般用来描述变量间的线性关系,其绝对值越接近1,表明变量间的相关性越显著;但R2可以用于描述非线性的相关关系。当R2小于0的时候,需要借助其他评估方法来评价拟合程度。
利用GBDT算法构造的预测模型对催化裂化的汽油收率进行预测,得到的汽油收率预测结果与实际工业数据的对比如图7所示。由图7可以看出,模型的预测值总体趋势与工业数据吻合较好,少有出现偏差较大的预测值。
由式(5)和式(6)计算预测结果的准确率和R2系数,并与参考准确率对比分析。计算得到,预测模型的准确率达到98.9%,明显高于98%即参考准确率,验证了该模型的可行性和有效性;预测模型的R2系数为0.236,而该指标的参考值为0,表明预测模型对汽油收率的拟合程度较好,分析得到的特征指标可以用来解释汽油收率的变化程度。同时,根据以上结果,由式(4)计算平均绝对误差(MAE)。

图7 利用GBDT算法得到的汽油收率预测结果与实际工业数据的对比Fig.7 Comparisons between gasoline yield predictions of GBDT and actual gasoline yield
计算可得,基于模型计算得到的汽油产率预测值和实际值的平均绝对误差为0.531%。因此,无论是从预测结果的准确性还是拟合度上来看,由GBDT构建的预测模型对汽油产率能够起到良好的预测效果。
4 结 论
基于某石化企业的LIMS及DCS系统中的工业生产数据,通过分析监控指标与实际汽油收率的相关性,筛选出了相关性高的分析指标,进一步明确了影响催化裂化装置汽油收率的因素。在此基础上,利用梯度提升决策树GBDT算法构建了催化裂化汽油收率的预测模型,并预测了相应的汽油收率。结果发现,由GBDT算法构建的汽油收率预测模型预测结果的准确率为98.9%,R2系数为0.236,平均绝对误差为0.531%。模型预测结果与实际汽油收率相比,误差率小于1%,表明构建的模型能精确预测催化裂化装置中汽油等产品收率,对装置操作工况的优化改进具有良好的指导意义,有助于在实际生产中进一步提升催化裂化装置的经济性。
猜你喜欢
世界农药(2022年10期)2022-11-10
当代化工研究(2022年11期)2022-06-27
导航定位学报(2022年3期)2022-06-10
电子乐园·下旬刊(2022年5期)2022-05-13
能源化工(2021年2期)2021-12-30
石油石化绿色低碳(2019年6期)2019-01-14
石油石化绿色低碳(2019年6期)2019-01-14
新生代(2018年16期)2018-10-21
北京航空航天大学学报(2017年2期)2017-11-24
应用化工(2015年12期)2015-04-14
